1. Introduction
As a fundamental task in remote sensing image understanding, arbitrary-oriented-object-detection (AOOD) is attracting the attention of researchers more and more. At the same time, with the rapid development of convolutional neural network (CNN)-based methods [
1,
2,
3,
4,
5], many outstanding AOOD detectors stand out [
6,
7,
8,
9,
10,
11,
12]. However, different from object detection in natural images, AOOD is more challenging mainly due to the following two reasons:
Objects in remote sensing images tend to have random orientation and larger aspect ratios, which increase the feature representation complexity of detectors.
Remote sensing images, due to their wide imaging range, contain complex and diverse ground objects and scenes, resulting in increased interference targets and features.
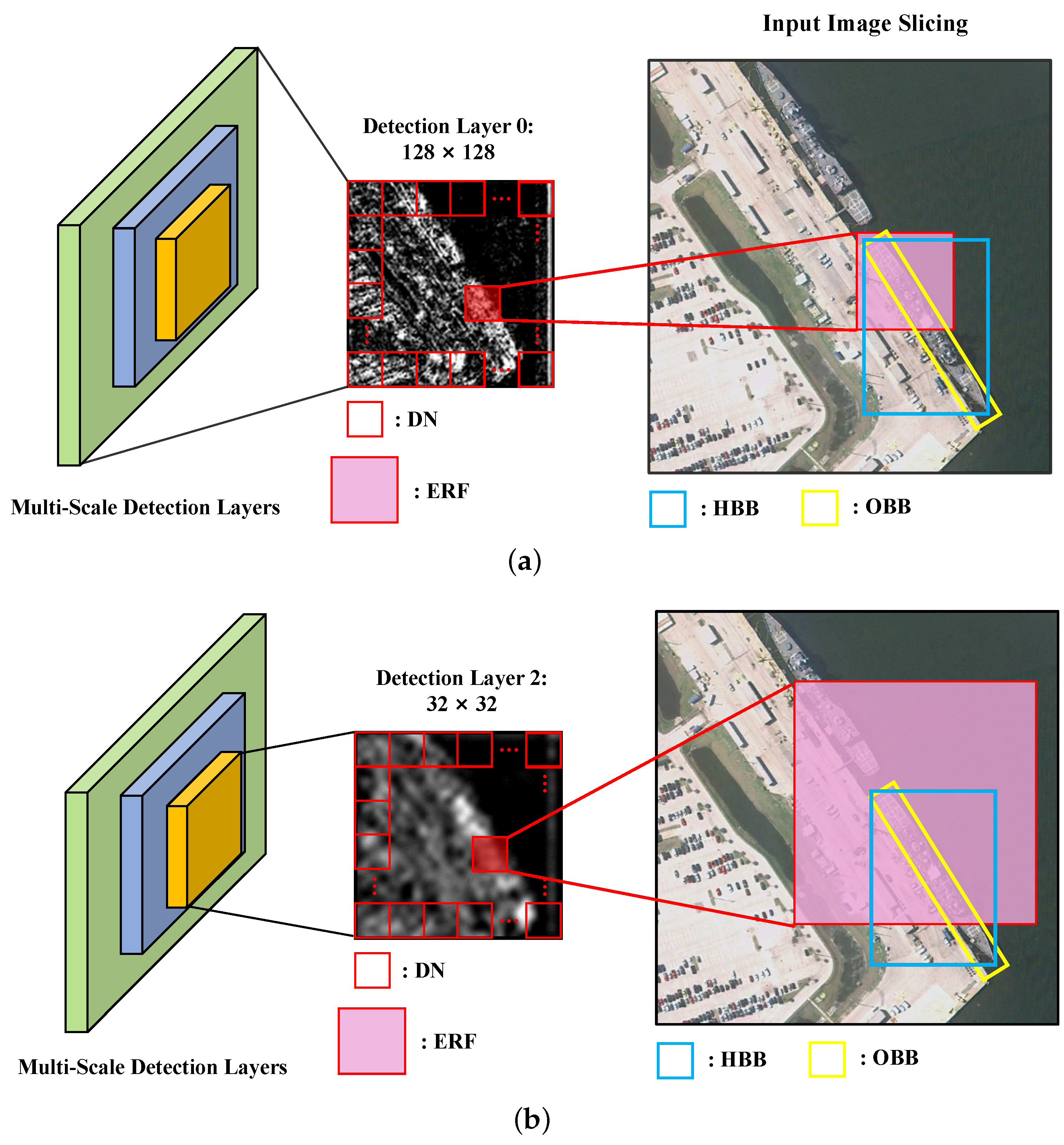
However, the existing design of AOOD detectors cannot adapt to the feature representation of remote sensing objects very well. Although AOOD detectors use the oriented bounding box (OBB) as the object’s marker, which can better fit the object’s spatial contour, the feature representation ability of each detection unit (DN) (i.e., feature point in multi-scale detection layers) does not change.
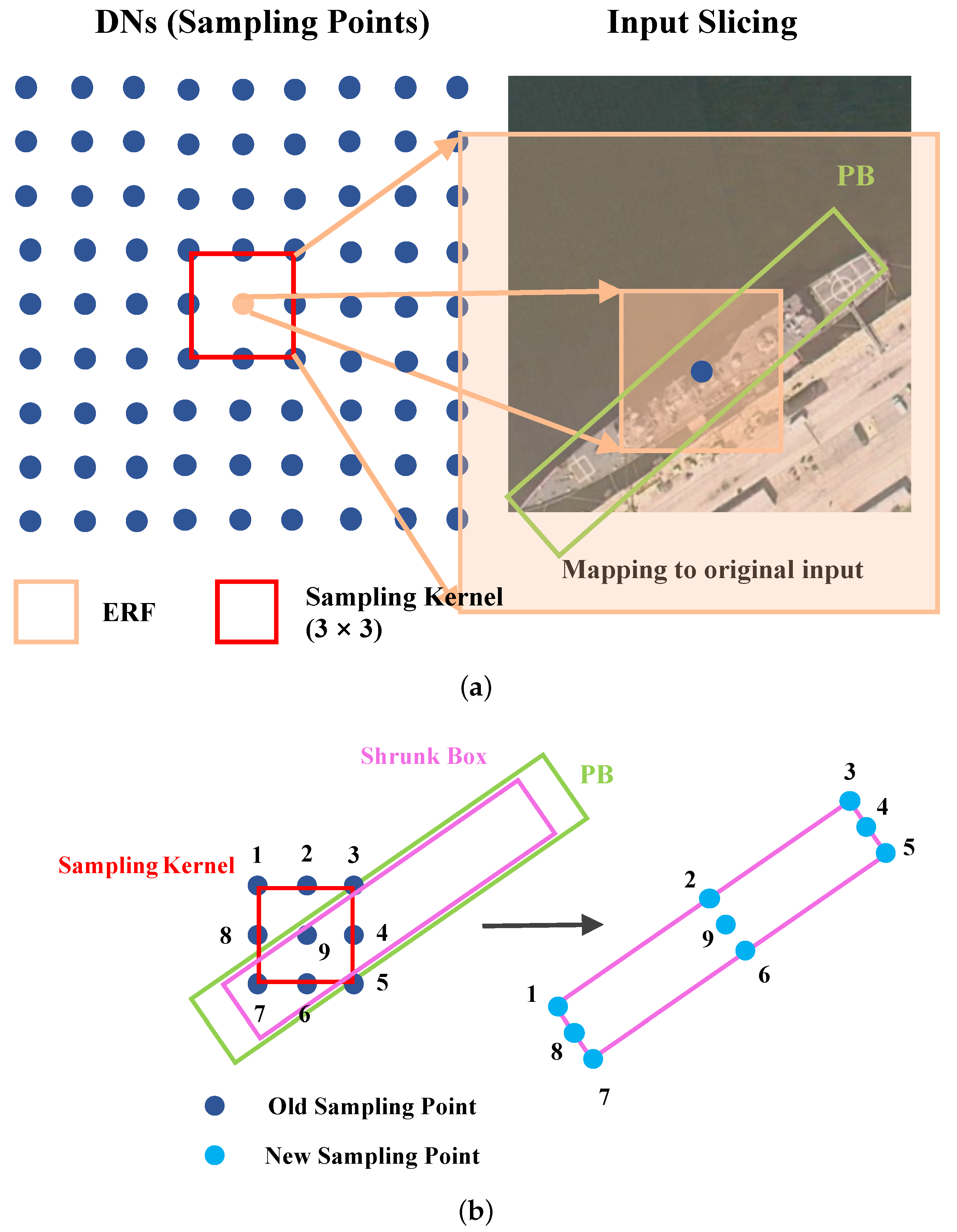
Take the classic anchor-based object detector as an example, as shown in
Figure 1, at each position of the multi-scale detection layers, a certain number of anchors will be preset for overlap calculation with GT (ground truth). When an anchor and GT meet certain position and overlap conditions (i.e., label assignment strategy), it will be determined as positive or negative. However, no matter whether HBB (horizontal bounding box) or OBB (oriented bounding box) is used as the labeling of GT, the effective receptive field (ERF) [
13] of each DN does not change; that is, no matter what shape and aspect ratio of the object appears at the current position, existing detectors use a fixed feature vector to represent it. This means that for the red high potential DN in shallow feature layers shown in
Figure 1a, its feature learning area is limited and does not coincide with the space occupied by the target. This issue has been discussed by some scholars [
14,
15] and summarized as a feature misalignment problem; however, these researches have not conducted in-depth summary and analysis of internal causes.
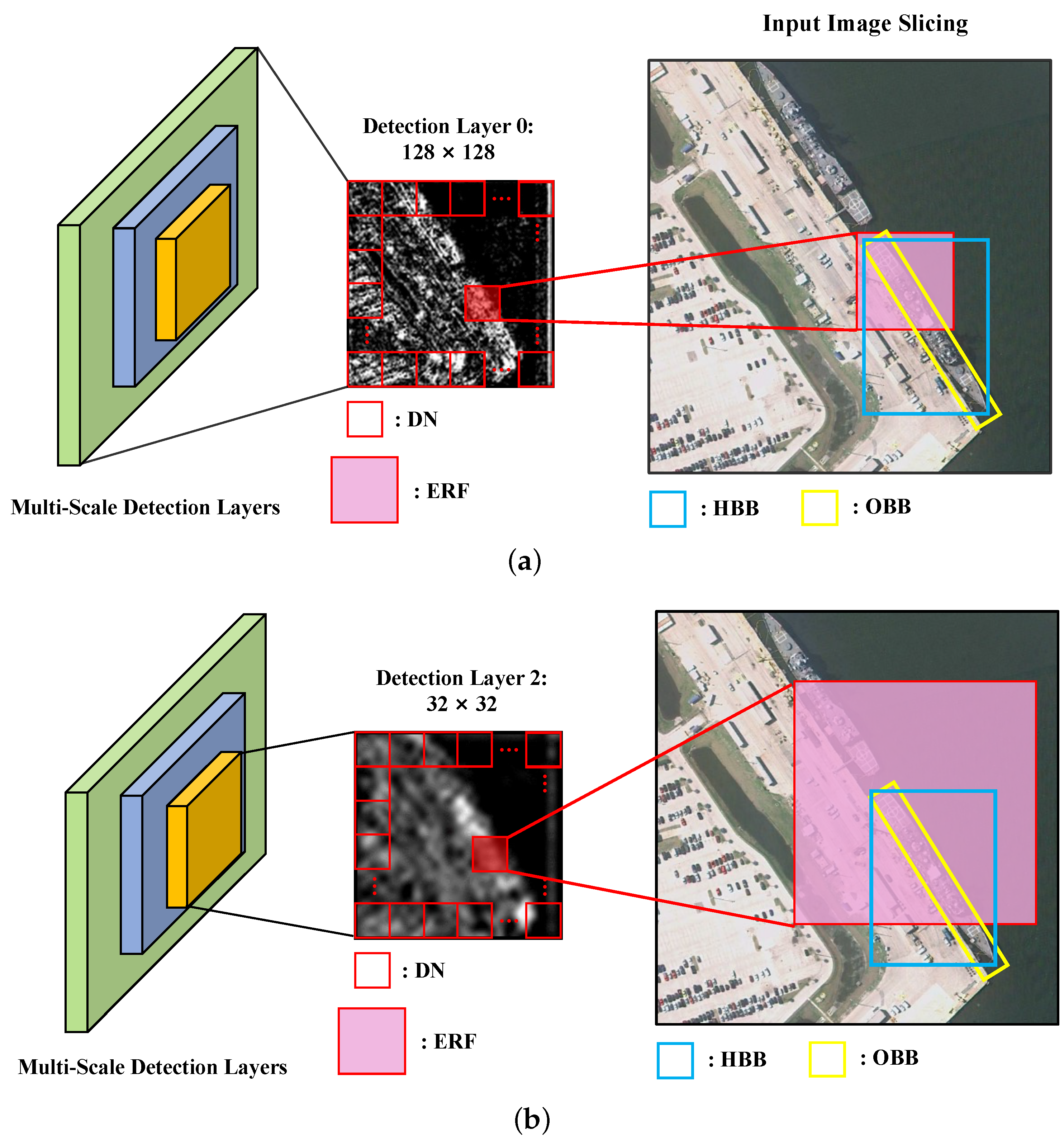
For this issue, one intuitive solution is using multi-scale feature representations to compensate for the uncertainty caused by the change of image and target size. However, another problem arises, as shown in
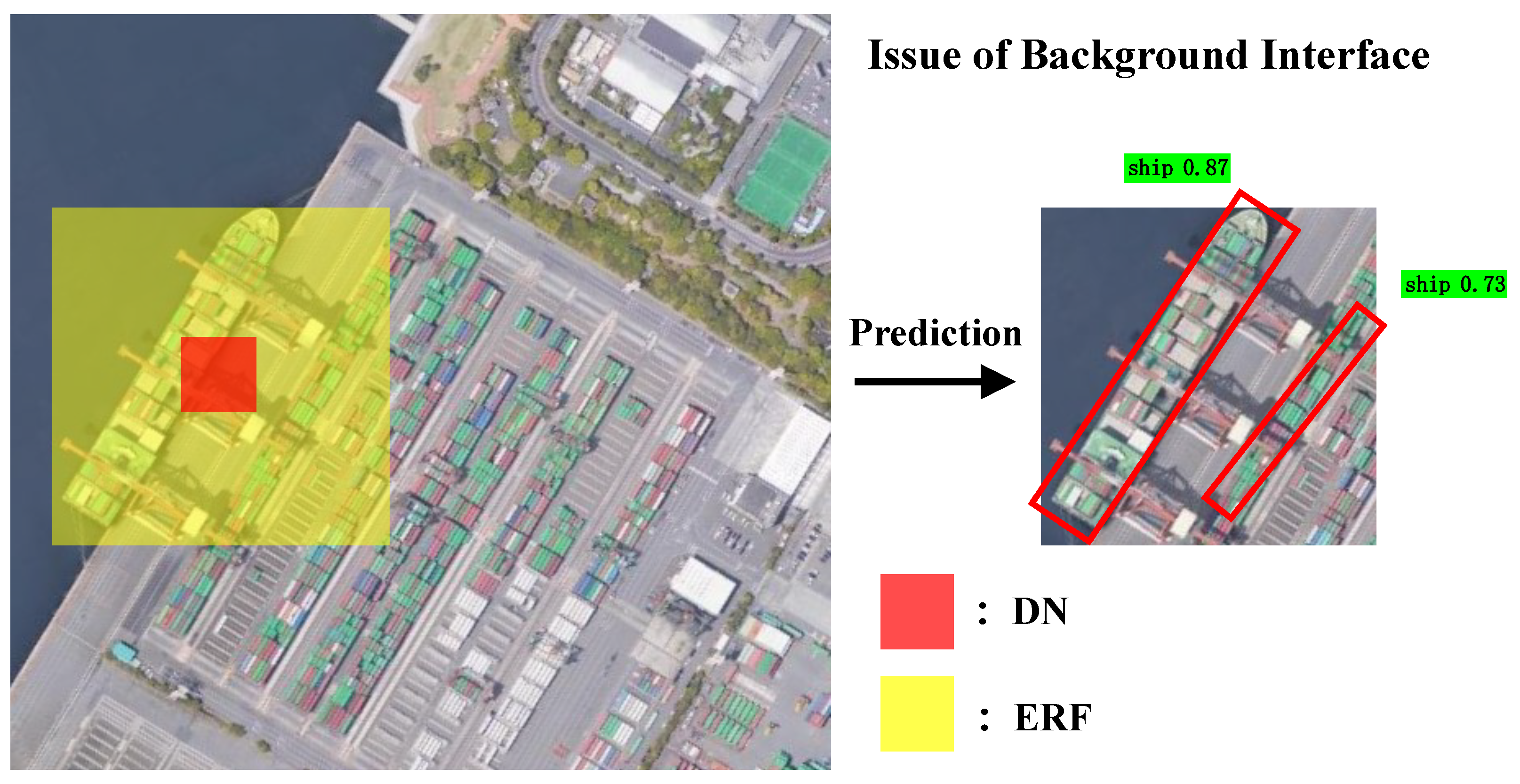
Figure 1b. With the deepening of the network and the down sampling operation, the ERF of DN has expanded. In the detection layer 2 with the size of 32 × 32, the marked DN expands its knowledge learning range but also receives more complex background information. The case in
Figure 2 shows the negative impact of the disorderly expansion of ERF, which occurs in a real application scenario. Because the containers and cargo ships in the port have very similar characteristics, they are easily confused when they appear in the ERF of the same DN. Therefore, the container on the shore is also mistakenly identified as a ship with a high confidence. To deal with those problems, an ideal situation is that the field of vision focused by each DN is the whole body of the target, and does not contain additional background. However, due to the randomness of target size and input image size, it is difficult to achieve the above situation. More importantly, through the above case study, we observed that multi-scale feature fusion and feature extraction units are mutually constrained and auxiliary, because they jointly affect the ERF of each DN.
In summary, we need multi-scale fusion models to provide rich feature information to meet the size transformation of the target, and feature extraction operators to achieve the adaptive adjustment of ERF to suppress background information and highlight the key areas. However, the existing feature fusion models, such as FPN [
17] and FPN-variants [
18,
19,
20,
21], cannot realize the information supplement between neighbor-scale features. The existing feature adaptive learning operators based on deformable convolution (DCN) [
14,
22,
23] cannot achieve the synergy between the capture of key areas and background suppression, and their design is mostly separated from the fusion model, which does not form a good chemical reaction.
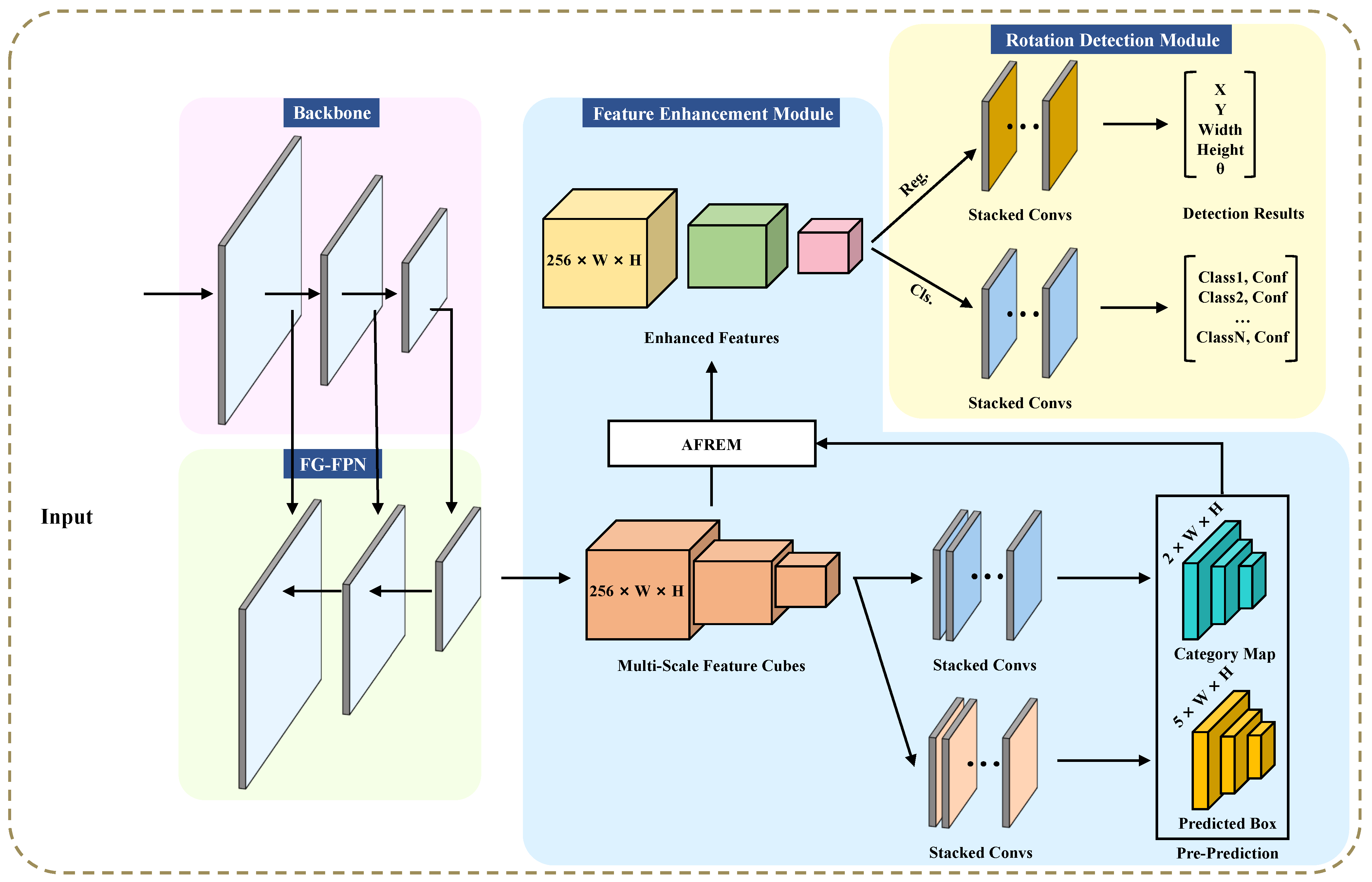
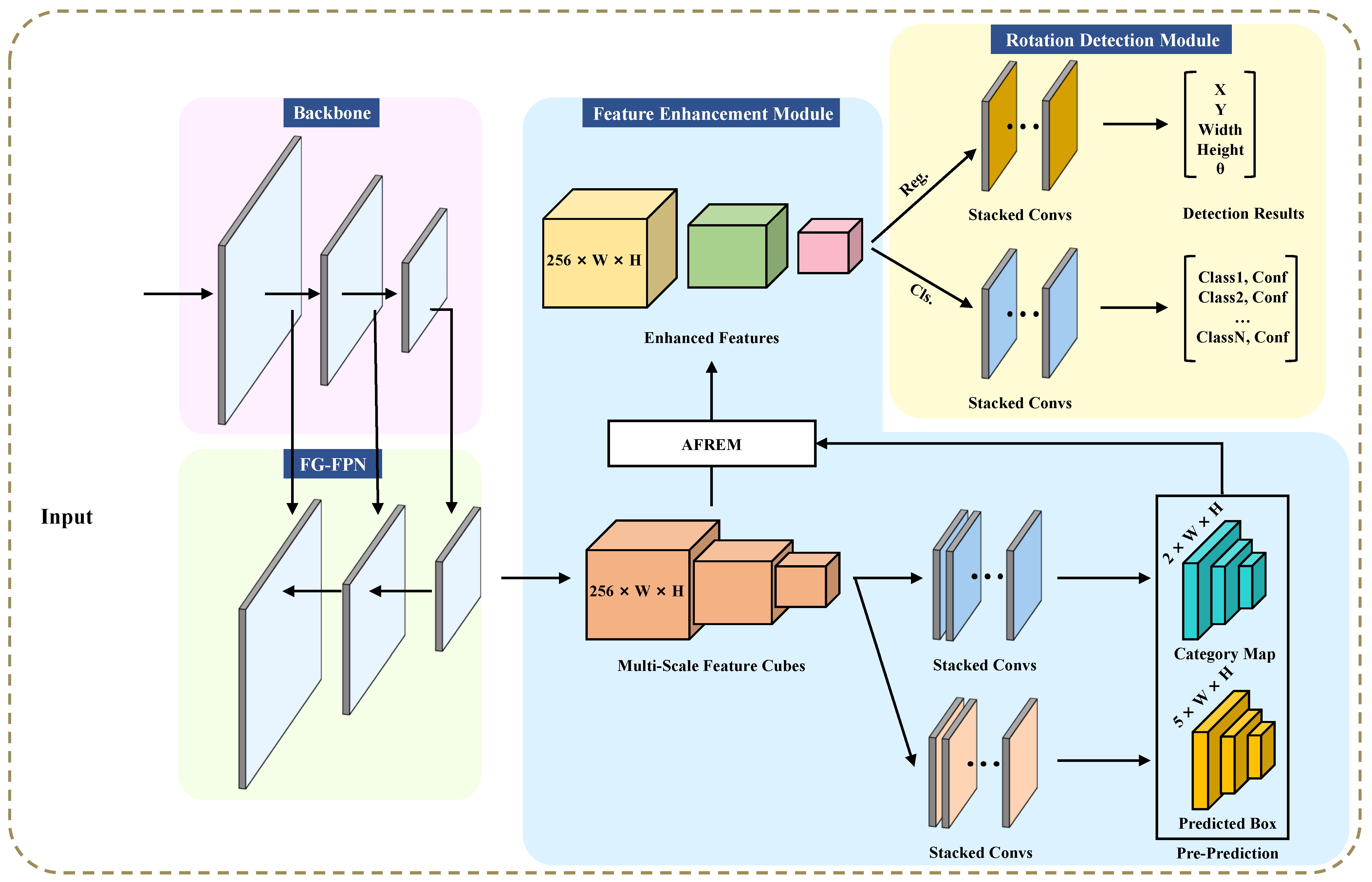
Seeing the above challenges, we propose an innovative AOOD detector called AFRE-Net (adaptive feature representation enhancement network), which effectuates adaptive feature representation enhancement for DNs in multi-scale detection layers. AFRE-Net is committed to achieving feature relevance learning between adjacent scales and end-to-end ERF transformation, so as to strengthen the feature representation in the detection layer. The overall architecture of the proposed AFRE-Net is shown in
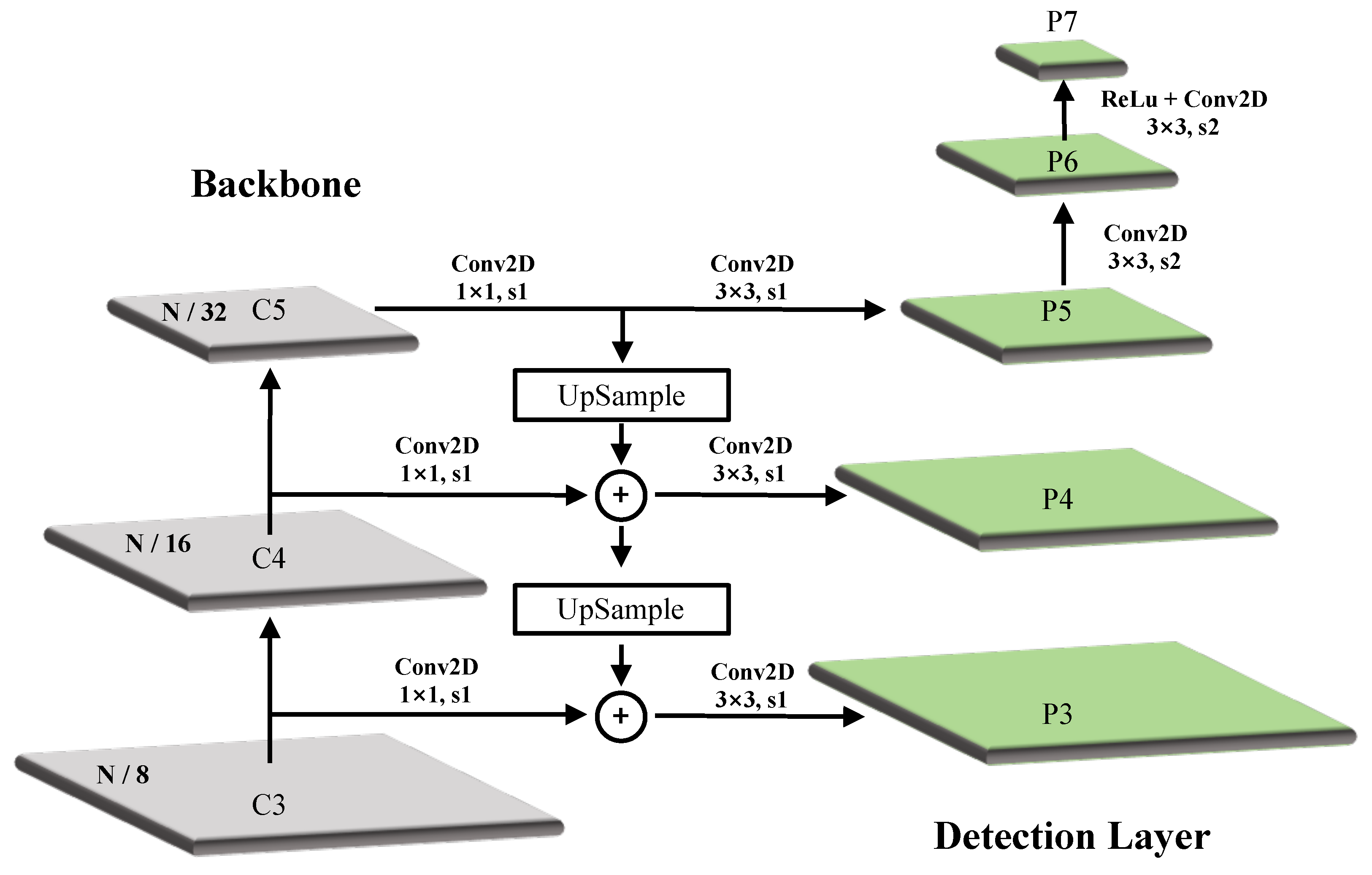
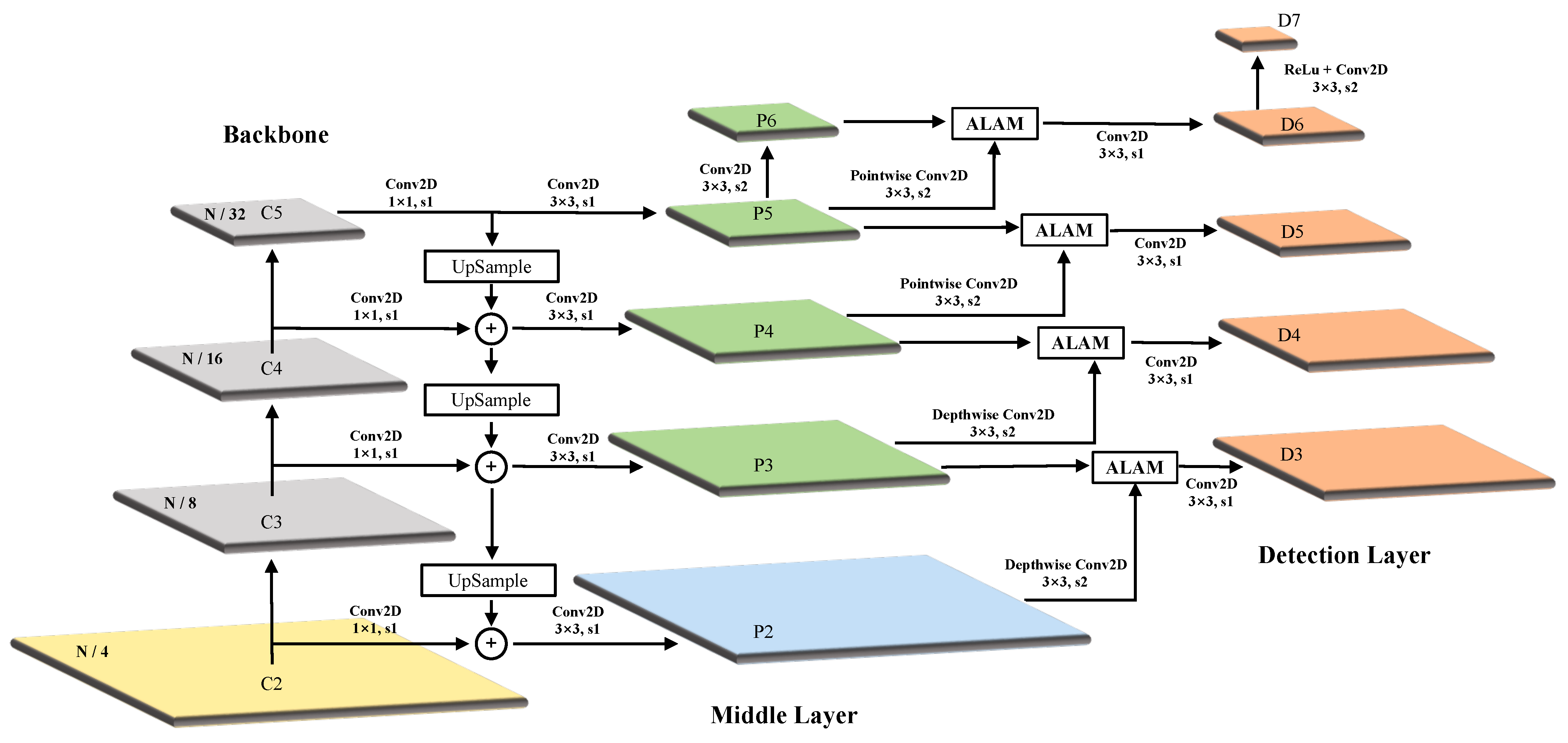
Figure 3, which consists of four modules: (1) The backbone for basic feature extraction; (2) An FG-FPN (fine-grained feature pyramid network) for providing finer multi-dimensional feature maps and performing feature fusions; (3) A feature enhancement module (FEM) and (4) a rotation detection module for category prediction (CP) and bounding box regression (BBR). As opposed to the regular feature pyramid network (FPN) [
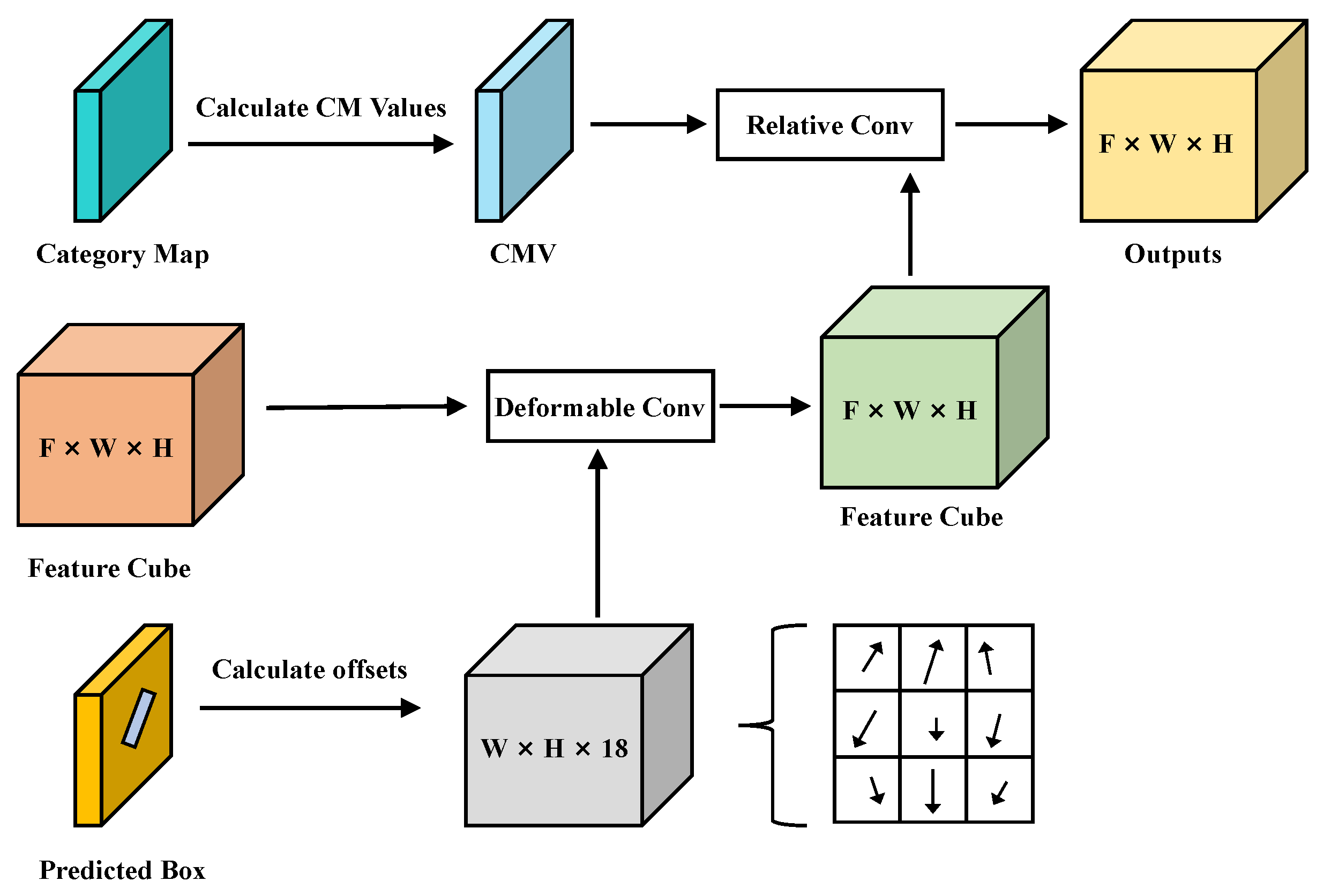
17], FG-FPN is designed to make better use of the low-dimensional feature maps rich in spatial information, and it uses a more fine-grained fusion method to provide a basis of features for subsequent FEM. In FEM, we apply the ERF transformation based on DCN, and invented a background suppression and foreground enhancement algorithm named relative-Conv, to achieve automatic and adaptive object representation enhancement. Extensive experimental tests on three benchmark remote sensing datasets (DOTA, HRSC2016, UCAS-AOD), as well as a text recognition dataset (ICDAR2015) demonstrate the state-of-the-art performance of our AFRE-Net.
The contributions of our work can be concluded as follows:
Our systematic analysis has mined three aspects that need to be considered together to improve the detector’s feature representation ability: fusion module, receptive field adjustment, and background suppression.
We propose a novel FG-FPN to provide finer features and fuse them in a more efficient manner. Different from FPN and its modifications, we focus on neighbor-scale information supplement to fullfil all-scale features.
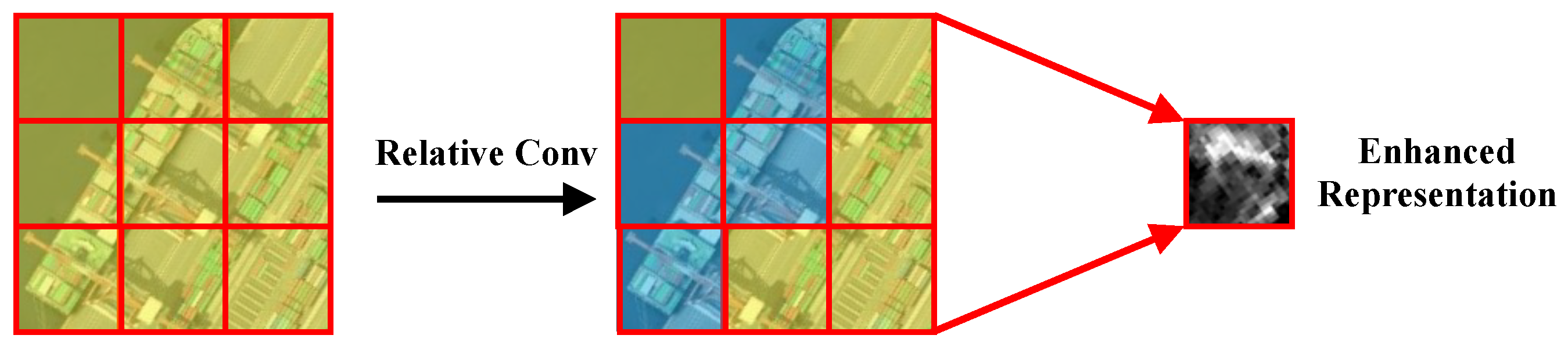
A novel background suppression and foreground enhancement convolution module called relative conv is proposed to encourage DNs to learn the key areas adaptively.
We propose a new ERF transformation algorithm to make the sampling position more accurately located on the main body of the target, obtaining stronger semantic features.
4. Experimental Results and Analysis
4.1. Datasets
Our AFRE-Net was assessed on three publicly available and challenging datasets, namely DOTA [
49], HRSC2016 [
50], and UCAS-AOD [
51].
DOTA is an extensive dataset consisting of aerial images that capture complex scenes relevant to AOOD. It comprises a total of 2806 aerial images, with 1411 images for training, 458 images for validation, and 937 images for testing. These images contain a total of 188,281 instances belonging to 15 categories. The image size ranges from 800 × 800 to 4000 × 4000, and all instances are labeled with OBB, which exhibit variations in scales, aspect ratios, and orientations. To facilitate training, we divided the images into regular 1024 × 1024 patches with a stride of 200. The categories and corresponding IDs are as follows: Plane (PL), Baseball diamond (BD), Bridge (BR), Ground track field (GTF), Small vehicle (SV), Large vehicle (LV), Ship (SH), Tennis court (TC), Basketball court (BC), Storage tank (ST), Soccer-ball field (SBF), Roundabout (RA), Harbor (HA), Swimming pool (SP), and Helicopter (HC).
HRSC2016 is a high-resolution ship detection dataset that contains images collected from six international harbors. It consists of 1061 images, with image sizes ranging from 300 × 300 to 1500 × 900. The dataset includes 436 images for training, 541 images for validation, and 444 images for testing. All ship objects are labeled with OBB, and the substantial variation in ship sizes poses a significant challenge for detection.
UCAS-AOD is an aerial image dataset specifically designed for oriented aircraft and car detection. It comprises 1510 images, including 1000 airplane images and 510 car images. We randomly divided the dataset into training, validation, and test sets in a ratio of 5:2:3.
Additionally, to assess the scenario generalization capabilities of our AFRE-Net, we utilized the ICDAR-2015 [
52] dataset as a benchmark for testing. This dataset consists of 1000 training images and 500 test images. The text boxes in this dataset are labeled with OBB and exhibit a very large aspect ratio, making them particularly challenging for detection.
4.2. Implementation Detail
For all datasets, we only set one horizontal anchor with aspect ratios of {1}, and resize all images to 1024 × 1024. Data augmentation techniques, such as random flip, rotation, and HSV color space transformation, are employed. The training optimizer used is Adam, with the initial learning rate set to
. At each decay step, the learning rate is divided by six. We utilize ResNet50 as the backbone network, which has been pre-trained on ImageNet. For DOTA, the models are trained on a single RTX 3090, and the batch size is set to two. Regarding HRSC2016, the detector undergoes a total of 12 K iterations during training, with the learning rate decaying at 8 K and 11 K, respectively. We evaluate the performance using average precision (AP) as the metric, following the same definition as the PASCAL VOC 2012 object detection challenge [
53]. Unless explicitly stated, mAP refers to
.
4.3. Ablation Studies
In this section, we conduct a series of experiments on DOTA and HRSC2016 to test our proposed AFRE-Net. We first verify the progressiveness of FG-FPN at the entire detector. Then, FEM is disassembled from the model to analyze its vital impact on overall performance. Finally, the respective capabilities of FRF expansion and RC are verified separately. Our ablation experiments demonstrate that when FG-FPN is combined with our meticulously designed FEM, our detector can achieve greater efficacy, thereby demonstrating the advantages of AFRE-Net.
To ensure fair comparisons, our baseline model adopts the same configuration as described in
Section 4.2. Furthermore, we set the depth of the detection head (i.e., the rotation detection module in
Figure 3) to a uniform value of 2, as it has a significant impact on the final detection result. In contrast to our AFRE-Net, which only utilizes one preset anchor with an aspect ratio of {1}, our baseline model employs three horizontal anchors with aspect ratios of {0.5, 1, 2} for matching objects. The results presented in
Table 1 and
Table 2 demonstrate that our baseline model achieves an mAP of 68.2% on DOTA and 86.32% on HRSC2016.
4.3.1. Effectiveness of Hyper-Parameter
The parameter
in our model is used to deal with the weight imbalance caused by strengthening the learning of key areas in relative conv. As shown in
Table 3, when
is around −0.2, negative compensation can achieve better performance by relative conv.
4.3.2. Effectiveness of FG-FPN
Our baseline detector applies FPN as the neck to fuse multi-scale feature maps. As shown in
Table 4, when replacing FPN with FG-FPN alone, the detector achieves accuracy gains of +1.01 and +0.92 on two datasets, respectively, proving that FG-FPN has a stronger feature fusion ability than FPN. In particular, it can provide low-level spatial information, which is very friendly for small targets. As can be seen in
Table 1, the detection accuracy of SV has been greatly improved. However, at the same time, the replacement of FG-FPN also increased the number of parameters in the model, and we calculated that the size of the weight checkpoint file increased by 6.5 M. The detailed FG-FPN complexity is shown in
Table 5. It can be seen that the introduction of FG-FPN has brought about a certain increase in model complexity, mainly caused by ALAM, as a large number of intermediate parameters are generated during the calculation process of this attention mechanism, also leading to an increase in inference time. It should be noted that this group of testing experiments did not use any feature enhancement modules, including AFREM. As shown in
Table 5, when FG-FPN is used alone, it can only slightly improve the overall detection accuracy of the model. However, when FG-FPN is combined with our proposed AFREM, it can fully release the model performance, as AFREM can utilize the features rich in low-level spatial information provided by FG-FPN, obtaining more robust target feature representations.
4.3.3. Effectiveness of FEM
FEM consists of two parts: ERF expansion and Relative ConV. We first verified how the overall detection accuracy of the detector changes when the entire FEM module is removed. As shown in the third and fourth control experiments in
Table 4 (third and fourth columns), the use of different combinations of embeddings in detectors results in varying levels of detection accuracy. The combination of FG-FPN and FEM resulted in an astonishing mAP gain of +6.92 for the detector on DOTA, while FPN plus FEM achieves a +4.91 mAP improvement, which is also satisfactory. However, the former cannot be compared to the latter. Similar results also occurred on HRSC2016, where the combination of FG-FPN plus PEM achieves better performance, and improves the mAP by 5.12%.
In addition, to verify the contributions made by ERF transformation and Relative Conv in FEM, we conducted two comparative experiments, as shown in
Table 6. It should be noted that both FG-FPN and DAL are used in these two comparative experiments. Inside FEM, since the size of feature cubes does not change, we only need to remove the other embedding when testing only one embedding. The experimental results show that when the two are combined, they can play a greater role. This is because by combining the two embeddings, DN not only can obtain the self-learning changes of the ERF, but also can adaptively learn the key areas in it and suppress the background information, thus obtaining better feature expression ability.
4.3.4. Effectiveness of Label Assignment Strategy
In order to eliminate the impact of LAS in our experiment, we also conducted comparative experiments to verify the universality of our proposed methods. As shown in
Table 6, when using DAL in the baseline, the accuracy of the detector on DOTA increased by 1.54% and on HRSC06 by 1.26%, indicating that the optimization of LAS is significantly helpful in improving the overall detection accuracy. However, the experimental results show that the use of LAS does not affect the improvement of the model detection accuracy brought by FG-FPN and FEM. On the contrary, when the three are combined, the maximum gain can be achieved.
4.4. Comparison with State-of-the-Art Detectors
4.4.1. Results on DOTA
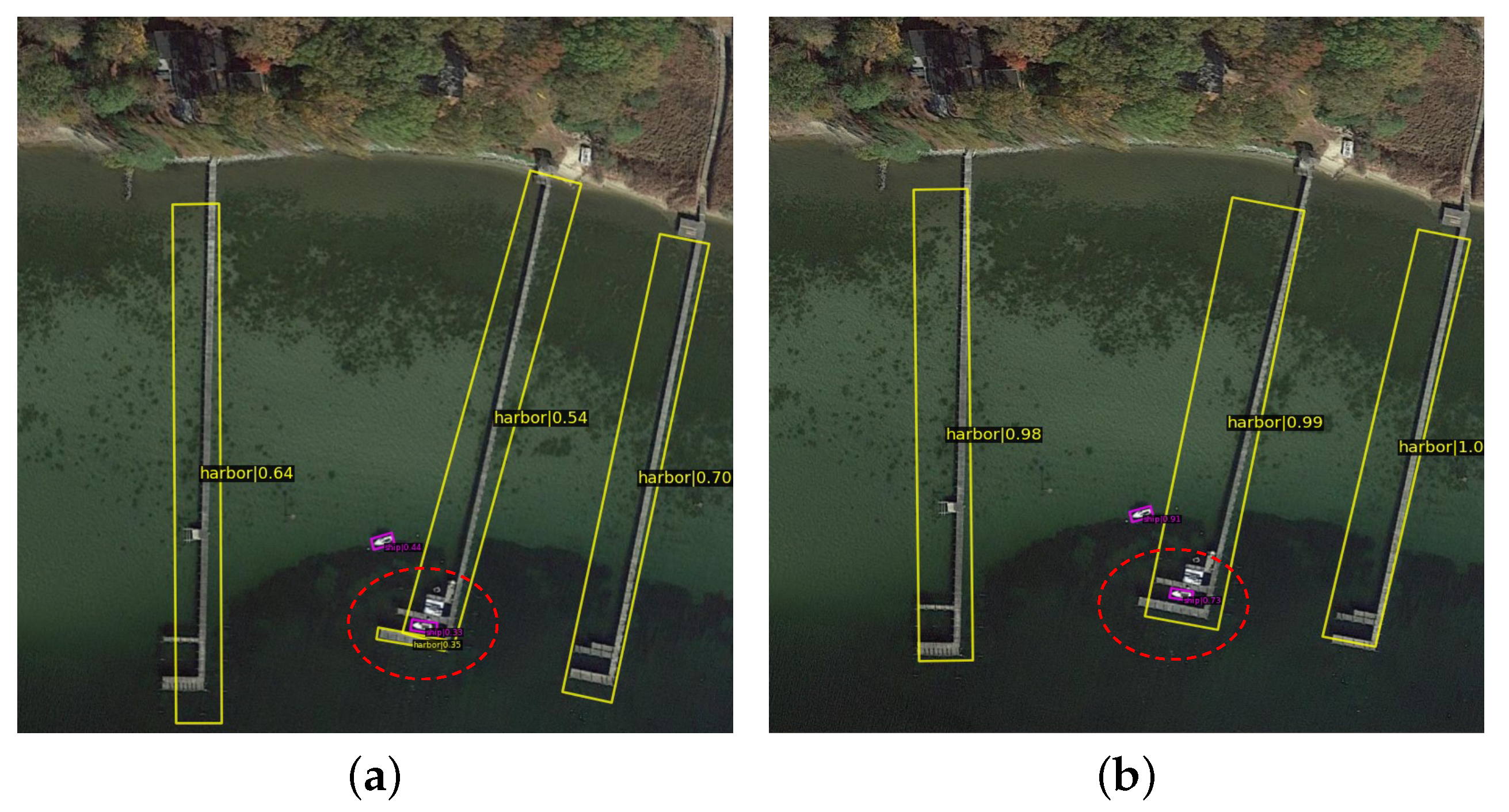
We select some difficult scenarios as a demonstration of AFRE Net’s detection capabilities. As shown in
Figure 10 and
Figure 11, because our detector has improved the ability of feature expression, its confidence in the predicted output of the target has been greatly improved, and error detection has been effectively avoided (red circle in
Figure 10a). Moreover, the detection ability for small targets has also been greatly improved.
Figure 12 also shows some tough detection scenarios in AOOD (dense, small, large aspect ratio, chaotic, and orientation random). It can be seen that AFRE-Net is able to better cope with the above challenges. Compared with other state-of-the-art AOOD detectors shown in
Table 1, our model outperforms the best
[
61] by an mAP of 1.6%, and achieves mAP improvement of 9.01% over the baseline detector. Compared with the anchor-free reppoints, our AFRE-Net achieves better performance on most categories.
Surprisingly, the accuracy improvement ability of AFRE-Net on specific objects is impressive. For SP, HA, RA, SBF, and ST, AFRE-Net achieves improvements of 3.39%, 13.95%, 6.73%, 11.2%, and 12.76%, respectively over the baseline. This suggests that our proposed method has a more significant and prominent effect on improving the feature expression of targets with large aspect ratio scales. The first reason is that the target with a large aspect ratio is more likely to contain more area of background information within the rectangular box of its outer contour, increasing the likelihood of interference; Secondly, the original regular feature sampling mode makes it impossible to accurately collect all the spatial scale features of the target when representing the target with a large-scale aspect ratio. AFREM achieves finer feature extractions by accurately changing the sampling points. Lastly, it can be seen that AFRE-Net has a good accuracy improvement effect on small targets, because the application of FG-FPN improves the ability of the detector to capture features in a small space range.
4.4.2. Results on HRSC2016
We evaluate the performance of our AFRE-Net on HRSC2016 with existing state-of-the-art AOOD detectors, which are divided into two categories, i.e., two-stage methods, such as
[
36], RRPN [
55],
[
65], RoI Trans. [
57], and Gliding Vertex [
66], and single-stage methods, such as DCL [
9], DAL [
31], DRN [
59], and S2A-Net [
14]. As shown in
Table 2, our AFRE-Net outperforms all the detectors, especially towards two-stage methods, by a large gap up to 4.16%. Our AFRE-Net obtains an mAP of 92.36% under the condition that only ResNet50 is used, meaning that our model can achieve better feature extraction and detection results with fewer parameters of backbones. Compared with the baseline model, we improve 6.04% mAP with only one preset anchor in the FEM and RDM. In addition,
Table 2 also shows the performance of our method in terms of model complexity and efficiency. The FG-FPN and AFREM has greatly improved the complexity of the model and increased the inference time of the detector, but extensive experiments have proved that our method is powerful in improving the detection performance. We have achieved 15.8FPS inference speed on a single RTX3090, proving that the model has maintained certain efficacy while improving its performance.
4.4.3. Results on UCAS-AOD
The distribution of vehicle targets in UCAS-AOD is relatively dense, and the spatial size is small, making detection difficult. As shown in
Table 7, our baseline detector only achieved an accuracy performance of 83.22% on car detection. However, after AFRE-Net is applied, the mAP is improved to 90.62%, and the overall mAP is promoted to 91.34%, which surpasses all other comparison methods.
4.4.4. Results on ICDAR2015
To assess the robustness and generalization capability of our proposed AFRE-Net algorithm across various application scenarios, as well as to tackle annotation boxes with larger aspect ratio scales, we conducted training and testing on the ICDAR2015 dataset.
ICDAR2015 comprises challenging targets with significant variations in length and width, annotated in the oriented bounding box (OBB) format. As depicted in
Table 8, our baseline model achieved an F-measure of 80.72 and a recall of 80.23%. Compared with other text detectors, such as EAST [
67],
[
36], and
[
37], AFRE-Net obtains the best recall performance at 88.82% and the best F-measure score at 86.27%, proving that our proposed solution has good migration application capabilities.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}