5.1. Experimental Setup
The model utilizes the PyTorch framework version 2.0.0 and operates on the Windows 10 operating system. The operating system’s CPU is an Intel Core i7-11700k, and the GPU is a GeForce RTX 4090. When conducting experiments on the radiative characteristic dataset, the model employs a learning rate of 0.001. It is trained using the cross-entropy loss function. Within the CNN-GRU architecture, the Skip-GRU sampling interval is set to 12. The weight parameters are randomly initialized and iteratively updated during backpropagation in the training process. We used the accuracy, recall, and F1 score to evaluate the classification performance of the model. The formulas are as follows:
M is the total number of samples in the dataset,
is the indicator function,
represents the predicted class for the i-th data, and
denotes the true class of the data.
F1 is the harmonic mean of precision and recall. The true positive (TP) represents the number of samples that are detected as positive samples and are correctly classified. FP (false positive) represents the number of samples that are detected as positive samples but are incorrectly classified. The FN false negative (FN) represents the number of samples that are detected as negative samples but are incorrectly classified, indicating that these samples are actually positive samples. Therefore, precision represents the proportion of positive samples detected by the classifier that are actually positive. Recall represents the proportion of correctly predicted positive samples by the classifier out of all positive samples. Compared to precision, we pay more attention to recall because we believe that when the recall rate is too low, the system may miss some important flying targets, resulting in the inability to detect potential threats in a timely manner.
In order to quickly and accurately distinguish high-altitude flying objects and explore the optimal recognition time, we conducted experiments using ACGRU on self-built radiation characteristic data with different time intervals. After analyzing the required time for optimal recognition, we selected the most suitable dataset for the next experiment. To verify the effectiveness of the network model, we conducted ablation experiments on the ACGRU algorithm, classifying the radiation characteristic dataset. At the same time, we selected four publicly available algorithms and compared them with the ACGRU algorithm in our self-built infrared radiation characteristic dataset to validate the effectiveness of the algorithm in completing the classification task of high-altitude flying objects.
In addition, in the subsequent research work, we will incorporate other flying objects. With the increasing variety of high-altitude flying objects, the radiometric characteristics of time-series data types obtained through inversion will become more complex. Therefore, it is necessary to verify the classification ability of the proposed model for time-series data and the generalization of the model. To this end, we conducted more comparative experiments, selecting 17 publicly available datasets from UEA for verification and comparing them with four other publicly available algorithms. The four algorithms are FCN, ResNet, Inception-Time, and ConvTran.
FCN uses one-dimensional convolutional layers to extract local and global features, preserving temporal information, and then transforms them into fixed-length representations for classification using a classifier; ResNet achieves deeper temporal classification networks through residual learning and skip connections to solve the problems of gradient vanishing and network degradation, while directly passing and accumulating input and output. Both of these algorithms are reported as among the best algorithms in the field of multidimensional time series data classification in the literature [
33]; Inception-Time improves the performance and generalization ability of temporal data classification by fusing multi-scale convolutions and temporal convolutions to extract features from temporal data. It is also one of the best models for multi-dimensional temporal data classification reported in [
34]; ConvTran improves the encoding part of Transformer to enhance the position and data embedding of the time series data, improving its performance and demonstrating remarkable results in [
35].
Among these four algorithms, FCN and ResNet are considered classic algorithms. Inception-Time mainly utilizes convolutional techniques. The essence of the ConvTran algorithm lies in its use of Transformer technology, which enables parallel computing and efficient training. It can handle long-term dependencies and has flexible modeling capabilities to adapt to different tasks and data requirements. It is not constrained by sequence length and has the advantage of efficient inference speed. We compared these four classes of algorithms, which perform well on the time series datasets, with the algorithm proposed by us through comparative experiments. The comparative experiments were conducted in the same experimental environment, with each model being tested three times on each dataset. The experimental results with the median performance were taken as the experimental results for that model on that dataset. Subsequently, the experimental results were analyzed.
5.2. Experiment on Classification of High-Altitude Flying Objects
The rapid and accurate categorization of high-altitude flying objects can provide important value for subsequent air space early warning and response plans. In our image acquisition of high-altitude flying objects using infrared cameras, the time required to obtain images for the inversion of radiation characteristics and subsequent categorization is a question we need to consider. To address this, we prepared 5 self-built infrared radiation characteristic datasets with different time intervals during the dataset preparation phase.
Table 4 shows the quantities of different types of targets in the datasets with varying temporal lengths. We trained the ACGRU algorithm on the training set and tested it on the testing set.
Table 5 shows the performance of our proposed model ACGUR on five self-built infrared radiation characteristic datasets. For all classes in the datasets, the classification accuracy of the model increases with the increase in the time series length. The best accuracy of 94.9% is achieved on the dataset with a time series length of 300. However, upon careful observation of the experimental results, when the time series length of the dataset exceeds 200, the classification accuracy for flying objects remains relatively stable. It reached 94.8% at a time series length of 200, which is only 0.1% lower than the best accuracy. As the time series length increases, the recall for samples with sufficient data, such as birds, balloons, and special aircraft, also increases. However, the recall for samples with relatively fewer data, such as civil aviation and helicopters, decreases. We believe that, as the time series length increases, the corresponding increase in target information content allows the model to quickly learn more information about the targets in the sequence, such as when the sequence length is between 50 and 200. However, when the length continues to increase, the model’s understanding of target information gradually reaches its peak, making it difficult to further improve. Regarding the decrease in recall for civil aviation and helicopters, we believe that, as the time series length increases, the already small sample size classes become even smaller, resulting in a decrease in the training samples. This makes it difficult for the model to learn comprehensively about these classes, resulting in a poorer performance on the test set. This is a problem of insufficient training samples and does not mean that the classification performance of flying objects decreases with the increase in sequence length. The infrared camera imaging times corresponding to different time series lengths, such as 50–400, are 0.5, 1, 2, 3, and 4 s, respectively. We believe that the effect of performing radiation inversion and classification on the infrared radiation characteristic dataset is not significantly enhanced when the infrared camera imaging time exceeds 2 s (corresponding to a time series length of 200). Considering the need for rapid classification, we consider 2 s as the optimal imaging time for classification. Next, we will use the infrared radiation characteristic dataset with a time series length of 200 (corresponding to a 2 s imaging time) for further research.
Table 6 presents the experimental results of the ACGRU algorithm on the classification of high-altitude flying objects with a time series length of 200 for infrared radiation characteristics. Our overall F1 score for the classification of high-altitude flying objects reached 93.9%. Among them, birds had the highest F1 score, reaching 96.2%, while civil aviation had the lowest F1 score, reaching 91.8%. When observing the data volume of each category of flying objects, it can be seen that categories with larger data volume showed good performance after training, such as birds, balloons, and special aircraft. Categories with a smaller data volume showed a subpar training performance. However, we also found that, although the data volume of balloons is more than three times that of UAVs, the F1 score of balloons is only 0.4% higher than that of UAVs. This is because, during high-altitude flights, the radiation intensity of balloons is low, making them easily confused with birds and UAVs. Meanwhile, despite having a smaller data volume than birds and balloons, special aircraft achieved an F1 score of 96.1% due to their large size and strong radiation characteristics. Finally, in the classification experiment of high-altitude flying objects, our accuracy reached 94.8%. Based on these experimental results, our method has certain value for practical applications such as air defense.
We invert the infrared images with a time length of 2 s into radiation characteristic samples with a sequential length of 200 using the infrared radiation measurement technique. We classify them using the ACGRU algorithm. Meanwhile, based on the classification results, we find a frame of the infrared image corresponding to the classification result, as shown in
Figure 7. These images are infrared images before inversion at a specific moment in the time series samples correctly classified by the algorithm. From the images, it can be observed that our algorithm accurately classifies targets such as birds, balloons, and helicopters with insufficient morphological information. Our method provides a new approach for high-altitude object identification. The F1 score on the entire dataset reaches 93.9%, and the accuracy reaches 94.8%, further demonstrating the effectiveness of our method.
5.4. Experiments of ACGRU with Other Algorithms on Different Datasets
As we continue to incorporate more flying objects in our research, the overall radiation characteristic dataset will undergo changes, including the inclusion of a greater variety of datasets that differ from the six flying object datasets covered in this study. Therefore, we believe it is necessary to validate the proposed model’s ability to classify time-series data and its generalization in order to provide a reference for future research on classifying more high-altitude flying objects.
Table 8 displays the accuracy performance of five models on a self-constructed infrared radiation characteristic dataset with a time series length of 200 and 17 datasets from UEA. Inception-Time is represented as IT. From the table, it can be seen that, among the five algorithms, ACGRU performs the best in our self-constructed dataset based on infrared radiation characteristics, with a 5.6% higher accuracy than FCN and a 3.3% higher accuracy than ConvTran. For the high-altitude flying object classification task, ACGRU is the most suitable algorithm among the five algorithms. At the same time, the ACGRU algorithm ranks first in the other 13 datasets, especially in cases where each category has a higher average training sample quantity. Except for the performance on the heartbeat dataset, which is not as good as ConvTran, ACGRU’s performance is better than the other models as the training volume increases. Furthermore, in the EigenWorms and EthanolConcentration datasets, when the time lengths are 17,984 and 1751, respectively, which is significantly higher than other datasets, ACGRU’s accuracy is noticeably higher than those of the other four algorithms. This indirectly validates ACGRU’s ability to focus on the long-term correlation information of time series data with longer time intervals. However, when the sample size is insufficient, ACGRU’s performance is not as good as the Transformer-based ConvTran algorithm. For example, in Cricket, despite the long time series length, the number of training samples is too small. Similarly, when both the number of training samples and time series length are insufficient, ACGRU’s performance is poor, as seen in the Libras dataset. Therefore, when performing different tasks, it is advisable to choose the appropriate algorithm based on the dataset conditions. In terms of high-altitude flying object classification tasks, ACGRU has the best performance, surpassing FCN by 5.6% and ConvTran by 3.3%.
In order to further analyze the performance of the ACGRU algorithm compared to the other four algorithms, we conducted significance tests. The Friedman test was used to determine whether the performance of the five algorithms was the same. A post hoc test, the Nemenyi test, was used to determine whether there were significant differences between the different algorithms [
36]. The formula for conducting the Friedman test is described as follows:
In this equation,
represents the statistical value of the Friedman test that follows a
distribution,
N represents the total number of data sets,
K represents the number of algorithms, and
represents the average ranking value of the
i-th algorithm.
represents the statistical value of the Friedman test that follows an F-distribution. The Friedman test in Equation (
30) is overly conservative, so we usually use the Friedman test that follows an F-distribution [
36].
has
and
degrees of freedom. The critical values table can be found in any statistical textbook.
The formula describing the Nemenyi test is shown as Equation (
32):
Among them,
is the critical domain for the average rank difference of the algorithm. The value of
is shown in
Table 9.
represents the significance level, which indicates the probability of rejecting the null hypothesis. In this case, we set it to 0.05. When conducting the Nemenyi test, if the difference between the average values of the algorithms is greater than
CD, we can conclude that there is a significant difference between these algorithms.
In Friedman’s test, the null hypothesis states that the performance of all algorithms is the same. According to Equations (
30) and (
31):
Using 5 algorithms and 18 datasets, is distributed according to the F distribution with (5 − 1) = 4 and (5 − 1) × (18 − 1) = 68 degrees of freedom. For = 0.05, the critical value of F(4, 68) is 2.51. Since 15.20 > 2.51, we reject the null hypothesis. There are differences among the 5 algorithms.
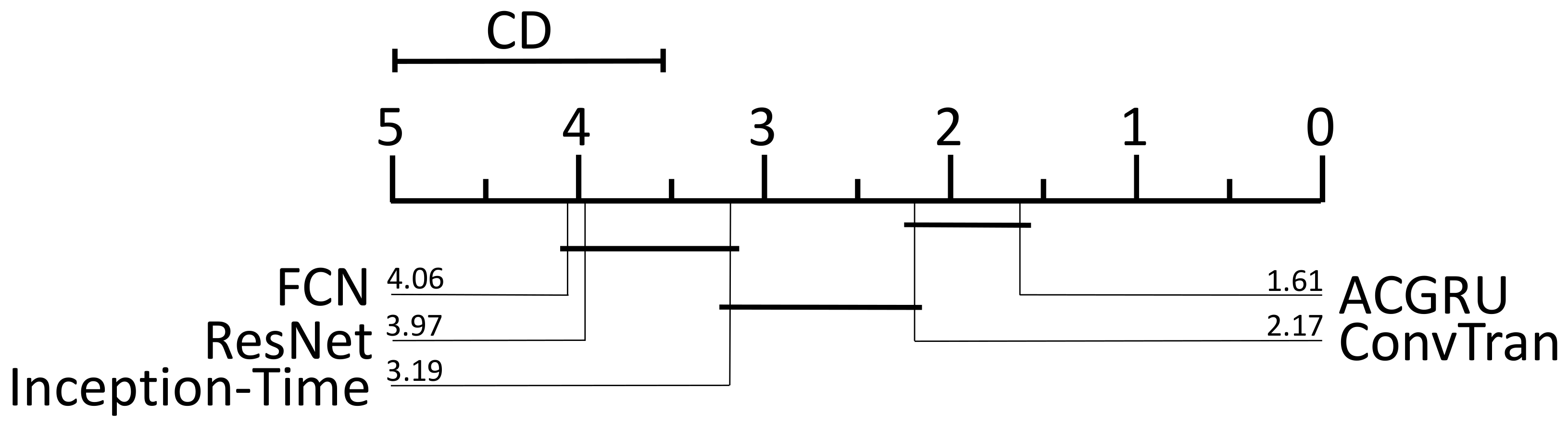
To further explore the differences between specific algorithms, we conducted the Nemenyi post hoc test. Based on
Table 9, the value of
is 2.728, which means that CD is equal to
, with a value of 1.44. Therefore, ACGRU performs significantly better than Inception-Time (3.19 − 1.61 = 1.58 > 1.44), FCN (4.06 − 1.61 = 2.45 > 1.44), and ResNet (3.97 − 1.61 = 2.36 > 1.44). There is no significant difference between ACGRU and ConvTran (2.17 − 1.61 = 0.56 < 1.44). The significance differences between each classifier are shown in
Figure 8, with the average rankings of each algorithm across all datasets plotted on the x axis.
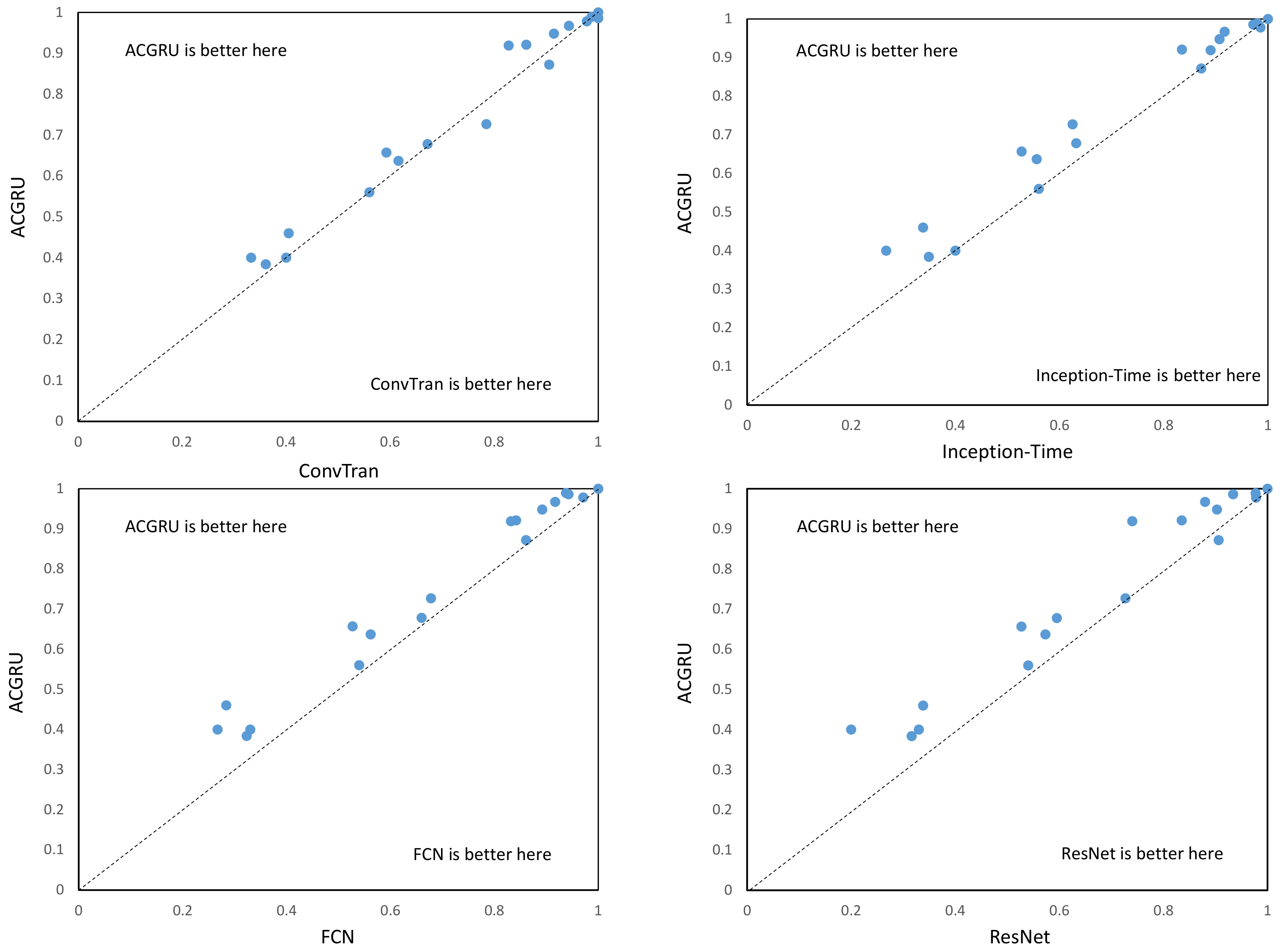
Based on the results of the significance analysis, we plotted the ACGRU algorithm separately with four other algorithms to further analyze the differences between ACGRU and these algorithms. The scatter plot shown in
Figure 9 represents the accuracy of each classifier on the shared dataset, with each data point representing the accuracy difference between two classifiers. The larger the distance from the diagonal line, the greater the difference in accuracy between the two classifiers. Data points above the diagonal line indicate that the ACGRU algorithm outperforms the other models in terms of accuracy, while data points below the diagonal line indicate that the ACGRU algorithm is not as accurate as the other models. Although there is no significant difference between ACGRU and ConvTran, since ConvTran adopts Transformer technology that is fundamentally different from CNN and RNN, and Transformer is considered an advanced algorithm for processing sequential data, we consider the significant detection results between ACGRU and ConvTran to be acceptable. By observing
Figure 8, we found that, for certain specific tasks, the accuracy of ACGRU is higher than that of ConvTran, especially for our high-altitude flying object classification task, where the accuracy of ACGRU is 3.3% higher than that of ConvTran. Thus, for the field of spatial governance, the ACGRU algorithm seems to be the more reasonable choice. On the other hand, ConvTran performs better than ACGRU in tasks with a smaller sample size and a longer-term dependency. From
Figure 9, we can see that, for the majority of the datasets, ACGRU outperforms Inception-Time, FCN, and ResNet algorithms, indicating that ACGRU has a clear advantage over them.
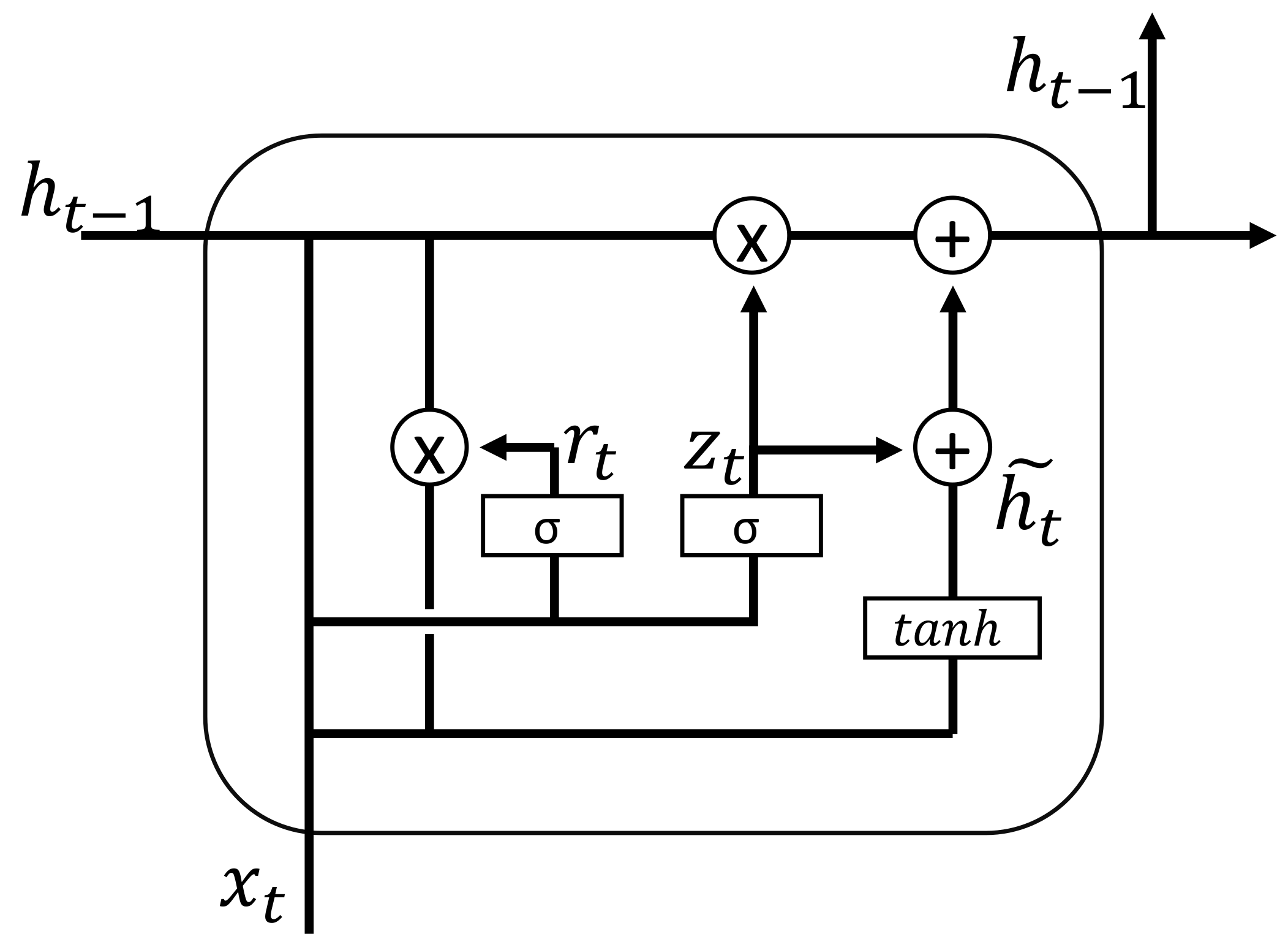
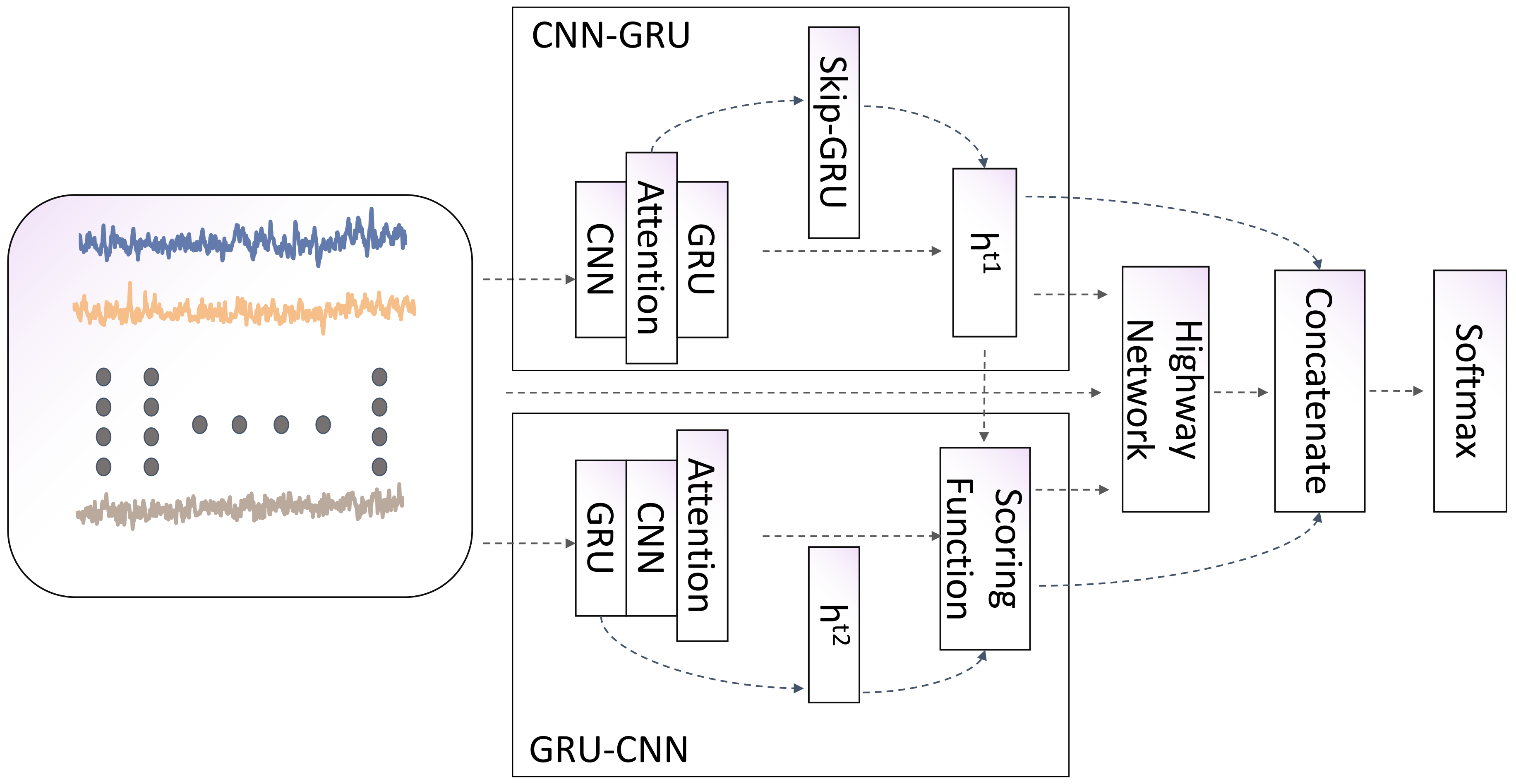
The ACGRU algorithm combines the attention mechanism and constructs three pathways: CNN-GRU, GRU-CNN, and Highway Network, fully leveraging the advantages of convolutional neural networks (CNNs) and recurrent neural networks (RNNs). CNN is capable of extracting local and global temporal features, while RNN captures the temporal relationships of time series. The synergistic effect of the CNN-GRU and GRU-CNN components further enhances the information extraction capacity of the original data, while the Highway Network alleviates the gradient vanishing problem and prevents the excessive abstraction of data. Compared to the FCN and ResNet algorithms, ACGRU can preserve more temporal information because GRU can process and memorize features at each time step. The ACGRU model reorganizes the temporal data, draws inspiration from the temporal data convolution idea of Inception-Time, but incorporates the exchange and combination of GRU and the attention mechanism to more effectively extract temporal information. Through significance analysis, the ACGRU algorithm significantly outperforms Inception-Time, FCN, and ResNet. Although there is no significant difference compared to ConvTran, both algorithms have their own advantages. ConvTran performs better in handling small sample datasets, while ACGRU excels in handling our self-made high-altitude flying object classification dataset. Therefore, we believe that ACGRU is suitable for high-altitude flying object classification tasks, as it can effectively model the long-term dependencies and local features in time series data, improve the modeling ability of time series data, and demonstrate a certain level of generalization. This will help in the subsequent addition of more high-altitude flying objects and the construction of more complex infrared radiation datasets to achieve accurate classification.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}