Abstract
Object detection (OD) in remote sensing (RS) images is an important task in the field of computer vision. OD techniques have achieved impressive advances in recent years. However, complex background interference, large-scale variations, and dense instances pose significant challenges for OD. These challenges may lead to misalignment between features extracted by OD models and the features of real objects. To address these challenges, we explore a novel single-stage detection framework for the adaptive fusion of multiscale features and propose a novel adaptive edge aggregation and multiscale feature interaction detector (AEAMFI-Det) for OD in RS images. AEAMFI-Det consists of an adaptive edge aggregation (AEA) module, a feature enhancement module (FEM) embedded in a context-aware cross-attention feature pyramid network (2CA-FPN), and a pyramid squeeze attention (PSA) module. The AEA module employs an edge enhancement mechanism to guide the network to learn spatial multiscale nonlocal dependencies and solve the problem of feature misalignment between the network’s focus and the real object. The 2CA-FPN employs level-by-level feature fusion to enhance multiscale feature interactions and effectively mitigate the misalignment between the scales of the extracted features and the scales of real objects. The FEM is designed to capture the local and nonlocal contexts as auxiliary information to enhance the feature representation of information interaction between multiscale features in a cross-attention manner. We introduce the PSA module to establish long-term dependencies between multiscale spaces and channels for better interdependency refinement. Experimental results obtained using the NWPU VHR-10 and DIOR datasets demonstrate the superior performance of AEAMFI-Det in object classification and localization.
1. Introduction
Object detection (OD) is a widely explored area within computer vision and digital image processing, with applications in robot navigation, intelligent video surveillance, industrial inspection, and various other domains. With the refinement of satellite launching technology and the continuous development of spatial sensors, remote sensing (RS) technology has made marvelous progress. OD also plays an important role in processing large-scale optical RS images, and its influence extends to the field of spatial observation, which finds extensive application in environmental monitoring, ocean monitoring, precision agriculture, and urban planning, among others [1,2]. OD has received great attention because of its important scientific research value and wide application prospects [3]. In general, the purpose of remote sensing object detection (RSOD) is to automatically identify and localize objects of interest, such as buildings, vehicles, etc. [4]. The rapid advancement of convolutional neural networks (CNNs) has greatly enhanced the performance of OD in processing natural images. This progress has further stimulated the advancement of RSOD [5,6].
The development of deep learning has driven the rapid advancement of algorithmic models in various fields, such as image classification [7,8,9,10,11], behavioral recognition [12], and object detection. Prior to the widespread adoption of deep learning (DL) in computer vision, traditional OD algorithms [13,14,15,16,17], such as HOG [18], SIFT [19], and Adaboost [20], were considered relatively mature. However, they were often insensitive to variations in object scale, angle, and shape, which limited their effectiveness in handling diverse object instances. DL has emerged as a fundamental pillar in the field of OD owing to its exceptional feature extraction and representation capabilities [21,22,23]. This rapid development has led to the proliferation of OD frameworks based on DL, which are broadly classified into two-stage algorithms and one-stage algorithms. In two-stage algorithms [24,25,26], candidate boxes or regions are initially generated, and then object classification and positional regression are performed for each candidate. This type of algorithm has high computational complexity but high detection accuracy. One-stage algorithms [27,28,29] perform object detection and localization directly in the image without an explicit candidate box generation step. This approach has the advantages of good real-time performance, simplicity, and efficiency. However, the accuracy of these algorithms decreases in some complex scenes. Through continuous development, generalized OD methods have achieved remarkable success in processing natural images. However, when applied directly to RS images, the results have been less than satisfactory [30].
Many large open-sourced datasets, including DOTA [31], DIOR [32], NWPU VHR-10 [33], HRRSD [34], and HRSC2016 [35], have been used to delve further into RSOD algorithms based on DL. Normal cameras take natural images from a horizontal perspective, whereas RS images are taken by satellite or high-altitude airborne cameras from an overhead perspective. Because of the unique imaging perspective, the RSOD task is more challenging. This is because RS images are featured with complex backgrounds, dense instances, and significant scale variations, resulting in the features captured by the network not being aligned with the real objects.
RS images tend to exhibit higher levels of complexity than regular images. They often contain intricate backgrounds and densely cluttered instances of objects. Such complexity can result in a network’s focus that does not correspond to the actual objects of interest within the images. To address this problem, SCRDet [36] introduces a joint supervised pixel attention and channel attention network. This method aims to enhance detection performance by effectively addressing the challenges posed by cluttered scenes and small objects in RS images. ABNet [37] proposes an enhanced effective channel attention mechanism to enhance feature discriminative power by focusing on interactions between channels, which captures local cross-channel correlations and mitigates the obstruction of foreground objects by complex backgrounds. Liu et al. [38] propose a center-boundary dual attention mechanism for RSOD that captures features from specific regions. However, since convolutional kernels use a fixed receptive field for feature sampling, the features captured by the above attention methods are localized [39,40,41]. Most of the mainstream network models for RSOD nowadays ignore the important feature of the object’s edge features. Although objects within RS images will have various sizes of scales, the same class of objects shares almost the same geometric features and structural patterns when viewed from a top-down perspective, exhibiting similar edge characteristics. Huang et al. [42] proposed nonlocal-aware pyramid attention (NP-Attention) to capture multiscale long-distance dependencies of features. NP-Attention directs the neural network model to focus more on effective features and suppresses background noise, but it cannot fit the object’s shape well because of the limitations of the edge features it captures using traditional operators. Therefore, for OD tasks, the improved attention mechanism should be better able to learn multiscale nonlocal dependencies and acquire effective edge features of the object.
Second, RS images exhibit a notable characteristic where objects possess a considerable scale variation that surpasses the scale variation found in natural images. Consequently, this causes the extracted features to be inconsistent with the scale of the actual objects in the image. Feature pyramid networks (FPN) [43] are commonly employed to solve the multiscale problem in OD tasks. However, FPN follows a top-down pyramid structure and cannot propagate shallower features containing position and texture information to deeper layers. SME-Net [44] introduces the feature split-and-merge module. This module aims to eliminate the prominent features of large objects, allowing for better feature capture of small objects. It also transfers the feature information of large objects to deeper feature maps, thereby alleviating feature confusion. FGUM [17] uses a novel stream warping to align features in an upsampling operation, thus improving cross-scale feature fusion. However, these detectors do not consider long-range modeling and focus only on acquiring local features of the object. In addition, in RSOD, there are still challenges related to missing semantic information and correlation noise during the multiscale feature aggregation process. This occurs because the coarse-grained features extracted by the backbone network can be affected by noise arising from intra-class diversity and inter-class similarity, leading to potential interference. The contextual information contains important information that depicts the detected object. Especially for the detection of small-scale objects, context information is particularly important. Huang et al. [45] used a pyramid pool to summarize context information from various regions. This module constructs a global scene representation by incorporating contextual cues from different areas of the images. GCWNet [46] proposed a global context-aggregation module that combines contexts into a feature representation, thereby improving feature discrimination and accuracy. Similarly, SRAF-Net [47] is a scene-enhanced multiscale feature fusion network that enhances the discriminative power of the model by incorporating scene context information into the feature extraction process. Although these obtain richer feature information by obtaining contextual information, they also inevitably bring noise interference. Consequently, a better feature pyramid should use self-attentive modulation and effective context to learn global information about an object, capture the correlation between the object and the global scene, and fuse multiscale features more effectively [48,49,50].
In summary, the misalignment challenges associated with RS images may limit detector performance. To tackle the mentioned challenges, we developed a novel one-stage detection framework for the adaptive fusion of multiscale features, and we propose a novel adaptive edge aggregation and multiscale feature interaction detector (AEAMFI-Det) for RSOD. First, considering the effective assisting role of edge information, we design an adaptive edge aggregation (AEA) module that includes an edge enhancement mechanism. This mechanism facilitates adaptive focusing on multidirectional edge features, allowing the module to learn the spatial multiscale nonlocal dependencies effectively. Next, we developed a new context-aware cross-attention feature pyramid network (2CA-FPN) to enhance multiscale feature interactions. 2CA-FPN adopts a level-by-level feature fusion approach that fully fuses the features of various scales through multiscale feature interaction, effectively alleviating the problem of scale inconsistency between the extracted features and the actual objects. 2CA-FPN includes a feature enhancement module (FEM) designed to transform the self-attention of individual features into the cross-attention of pairs of features. Local and nonlocal context information [45] is first mined as auxiliary information to enhance the feature representation by interacting information between multiscale features in a cross-attention manner. Then, we introduce the pyramid squeeze attention (PSA) module [51] to process the spatial information of multiscale features further and establish long-term dependencies among multiscale channel attentions effectively for better interdependency refinement. Extensive experiments with challenging DIOR [32] and NWPU VHR-10 [33] datasets provide compelling evidence for the superiority of AEAMFI-Det. The paper’s key contributions are highlighted as follows:
- We propose a novel end-to-end one-stage framework for RSOD called AEAMFI-Det, whose most significant feature is multiscale feature adaptive fusion. Because of the framework’s characteristic of feature adaptive fusion, AEAMFI-Det can achieve high detection accuracy and robustness.
- A new 2CA-FPN is proposed to achieve multiscale perceptual aggregation with level-by-level feature fusion to mitigate the scale misalignment between extracted features and real objects effectively. The context-aggregated FEM in 2CA-FPN was designed to mine contextual information as auxiliary information to enhance feature representation by relating the information among the multiscale features in a cross-attention manner.
- We propose an AEA module with an edge enhancement mechanism to direct attention to focus adaptively on multidirectional edge features. The AEA module can learn spatial multiscale nonlocal dependencies and reduce the misalignment between the network’s focus and real objects.
The remainder of this paper is organized as follows. Section 2 describes the two RSOD modules. Section 3 describes the proposed AEAMFI-Det. The details and results of the experiments are presented in Section 4. Section 5 discusses the experimental results. The study effort, results, and conclusions drawn are presented in Section 6.
2. Related Work
2.1. Contextual Transformer (CoT) Block
Relying solely on an object’s features often falls short of achieving satisfactory results in RSOD. The contextual information surrounding an object contains important information depicting the object [15] and using contextual information can improve the accuracy and robustness of OD. Therefore, contextual enhancement in FEM is used to facilitate the contextual information interaction of multiscale features. We use a contextual transformer (CoT) block [52] to capture valid local and nonlocal contextual information.
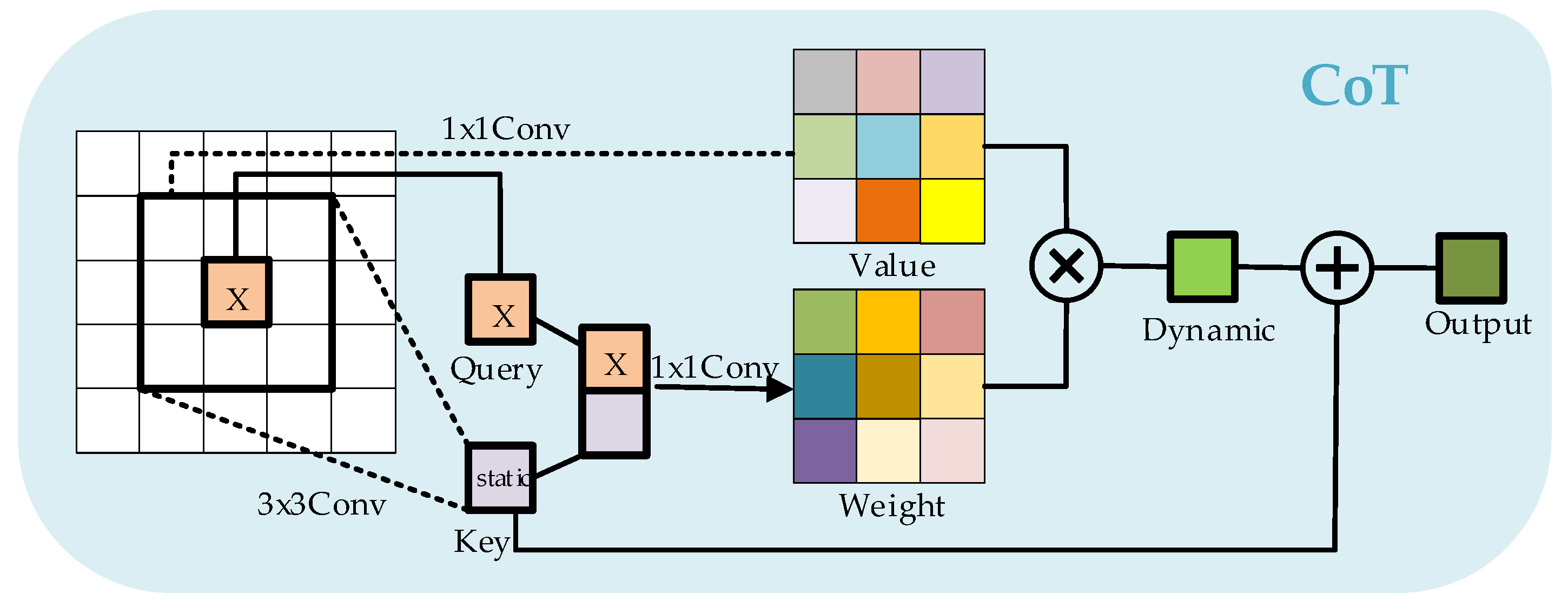
As Figure 1 shows, the CoT block employs a convolutional operation to encode the input keys contextually to obtain the static contextual feature . This encoding process enhances the input representation by incorporating contextual information, thus capturing the contextual relationships within the encoded features. We connect and query to learn the dynamic multi-headed attention matrix via two successive convolutions:
where and are convolutions with and without ReLU activation functions, respectively, represents the concatenation of operations along the channel dimension. We guide self-attention learning through . We impose contextual attention to value to compute feature :
where is a dynamic context feature that represents the adaptive feature interaction across the inputs containing the context. The final output is the fusion of static context features and dynamic context features.
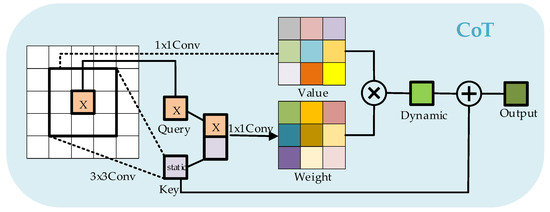
Figure 1.
Framework of the CoT block.
2.2. Pyramid Squeeze Attention (PSA) Module
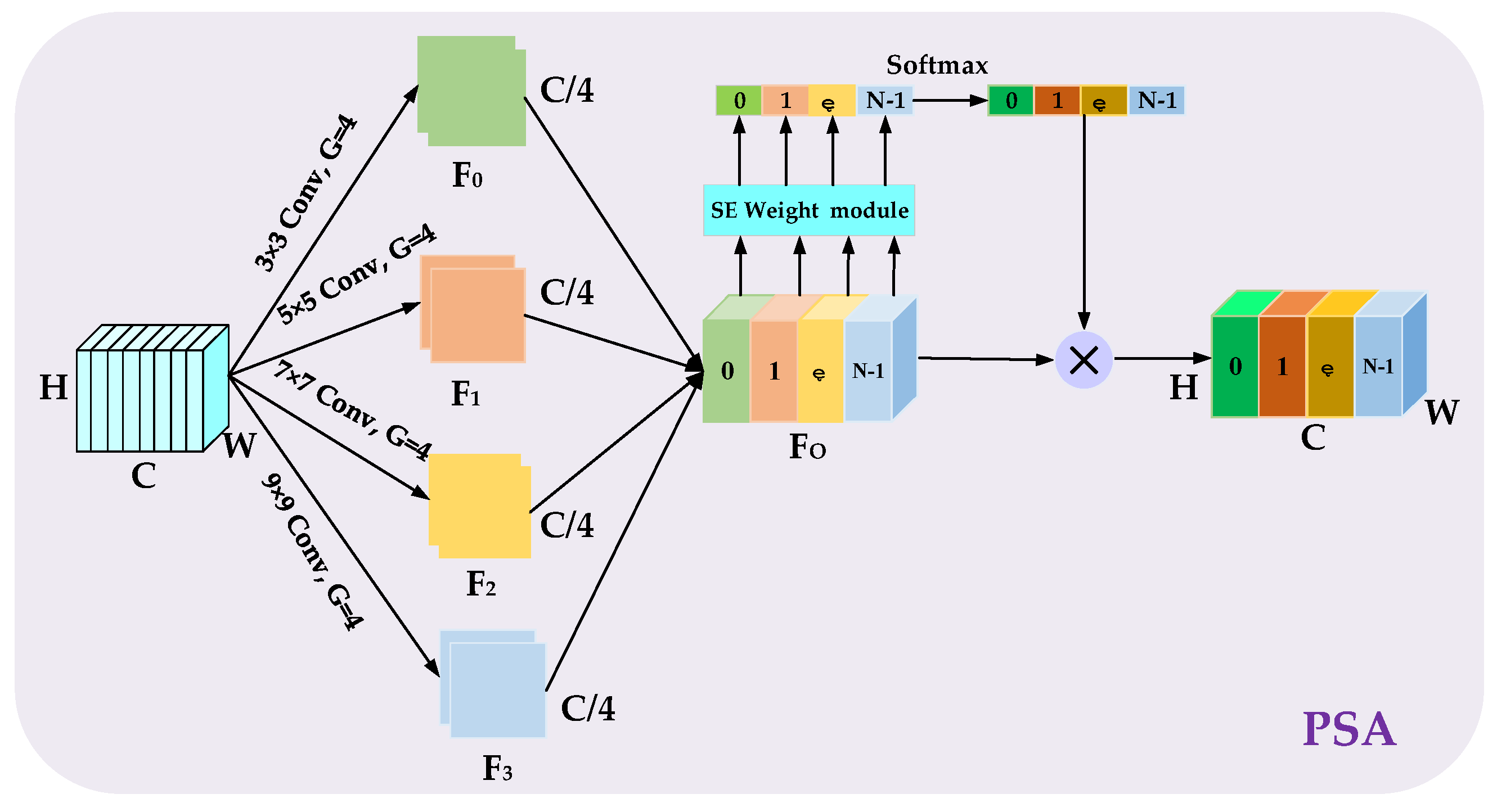
A pyramid squeeze attention (PSA) module [51] is introduced at the end of AEAMFI-Det to fuse the obtained multiple features and perform information interaction between the channel attentions for better interdependence refinement. As Figure 2, the PSA module has two main parts: multiscale feature extraction and channel attention weight acquisition. First, features of different spatial resolutions containing different levels of information can be obtained using grouped convolutions of different sizes in the pyramid structure to extract key information from feature maps at different scales. Through the compression of channel dimensions in each branch and the execution of local cross-channel interactions, the approach effectively extracts multiscale spatial features from the channel-level feature maps. For computational convenience, we set the number of grouped convolutions to four.
where represents the dimensions of the convolution kernel used in group convolution, represents the feature map with channel in each branch, and represents the overall multiscale feature map output in the four branches. is passed through the SE weight acquisition module along the channel dimension. This module calculates attention weights for feature maps of various scales. The weights are then normalized using the function to assign importance to each feature map. Finally, the weights of each channel are concatenated along the channel dimension and multiplied by to obtain the final output. The whole process can be written as follows:
where represents the overall multiscale feature of each channel, represents the weight acquisition operation in SENet, and represents the multiplication between channels.
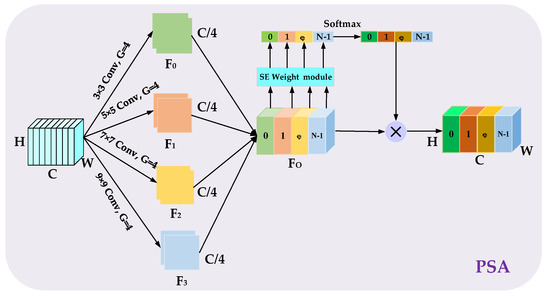
Figure 2.
The framework of the introduced PSA module.
3. Proposed Method
Substantial scale variations, dense distribution, and complex backgrounds in RS images introduce challenges in accurately detecting objects. These factors often result in misalignment between features extracted by the network and the actual objects in the images. This misalignment is manifested as a misalignment between the focus of the network and the actual objects in RS images and a scale misalignment between the extracted features and the actual objects. Previously proposed object detectors, especially one-stage frameworks, cannot produce satisfactory detection performance in this case. Several approaches have been proposed to address these problems, but they use coarse-grained features for learning and prediction, which may lead to incorrect classification and regression due to the lack of rich semantic features and necessary feature interactions.
This paper proposed a novel end-to-end one-stage framework for RSOD called AEAMFI-Det that detects objects in RS images. This framework combines context-awareness and cross-attention to establish dependencies between multiscale features. It employs an edge enhancement mechanism to adaptively focus on multidirectional edge features, which enables the object detector to capture more discriminative and informative aspects of the objects and thus improves the accuracy of the object detector. This section presents an outline within the suggested framework, following which two crucial components are mainly described: AEA and 2CA-FPN with embedded FEM. These components help to solve the problems of feature misalignment and coarse-grained feature noise interference extracted by the OD model and thus improve the accuracy and robustness of RSOD.
3.1. Framework Overview
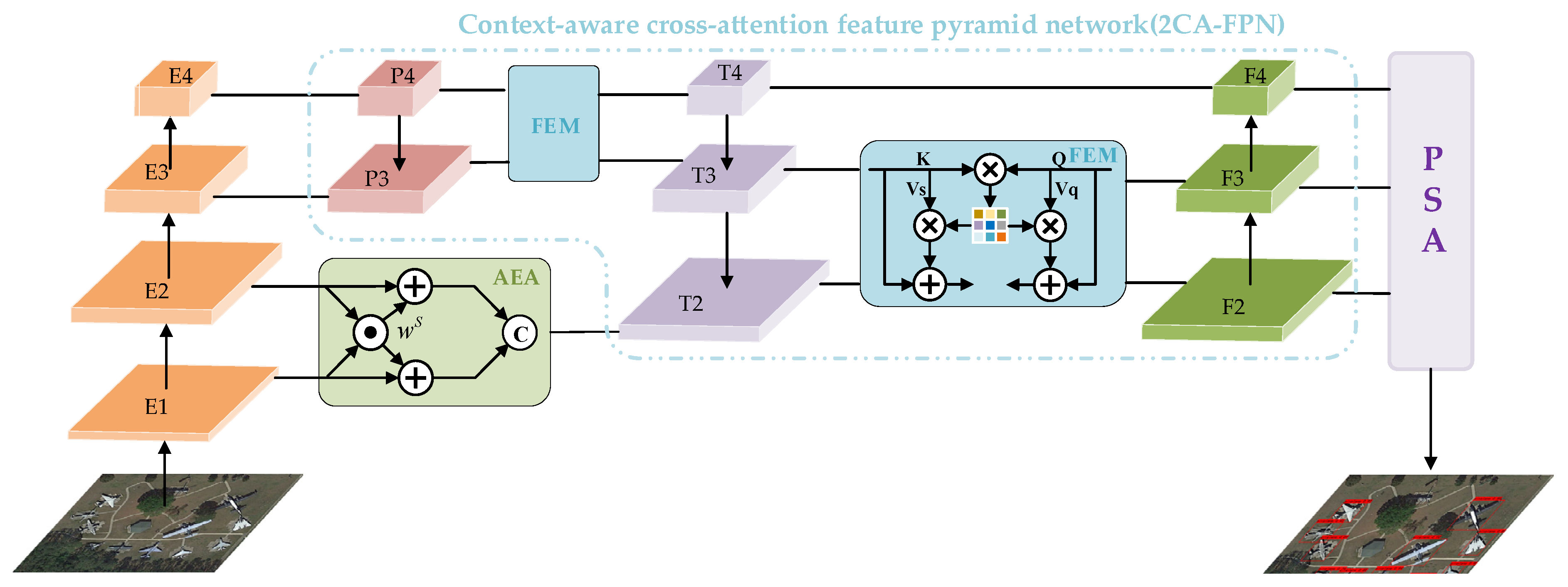
AEAMFI-Det is a one-stage framework that combines CNN and cross-attention for multiscale RSOD in realistic scenarios. The framework enables long-range modeling while suitably retaining the inductive bias of CNNs, which allows for superior accuracy while keeping the computational effort relatively low. As Figure 3 shows, the RS image is provided as input. Four feature layers, from low levels to high levels , are first extracted using the CSPDarknet53 [53] backbone, containing coarse-grained features. Next, a new aggregation strategy, AEA, is used to fuse low-level edge features adaptively. This aggregation strategy uses an edge enhancement mechanism to attend adaptively to multidirectional edge features and enables the model to learn and incorporate spatial dependencies across multiple scales. Then, in an attempt to enhance the multiscale feature interactions, a new fusion architecture, 2CA-FPN, is designed. The 2CA-FPN fully fuses the feature information of different scales by adopting a level-by-level feature fusion approach. In 2CA-FPN, we design FEM, which first mines effective local and nonlocal contextual information as auxiliary information to acquire semantic similarities and differences across multiscale features through information interaction at the spatial level in a cross-attention manner. After effectively extracting the multiscale spatial feature information at a finer granularity level, the PSA module is presented to process spatial information with multiscale features further to establish the long-term dependency between multiscale channel attentions effectively to achieve better refinement of the spatial and channel dimensional interdependencies. Finally, the detection head of the framework consists of two compact and parallel sub-networks: one for classification and the other for regression. These sub-networks work in tandem to generate the final detection results.
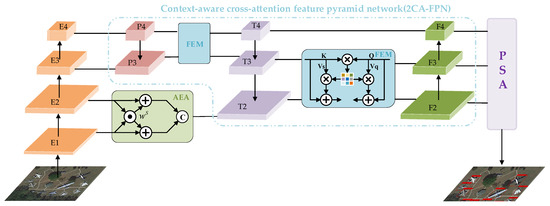
Figure 3.
Overview of the proposed AEAMFI-Det. The framework consists of a backbone, a detection head, and three critical branches: AEA, 2CA-FPN, and PSA.
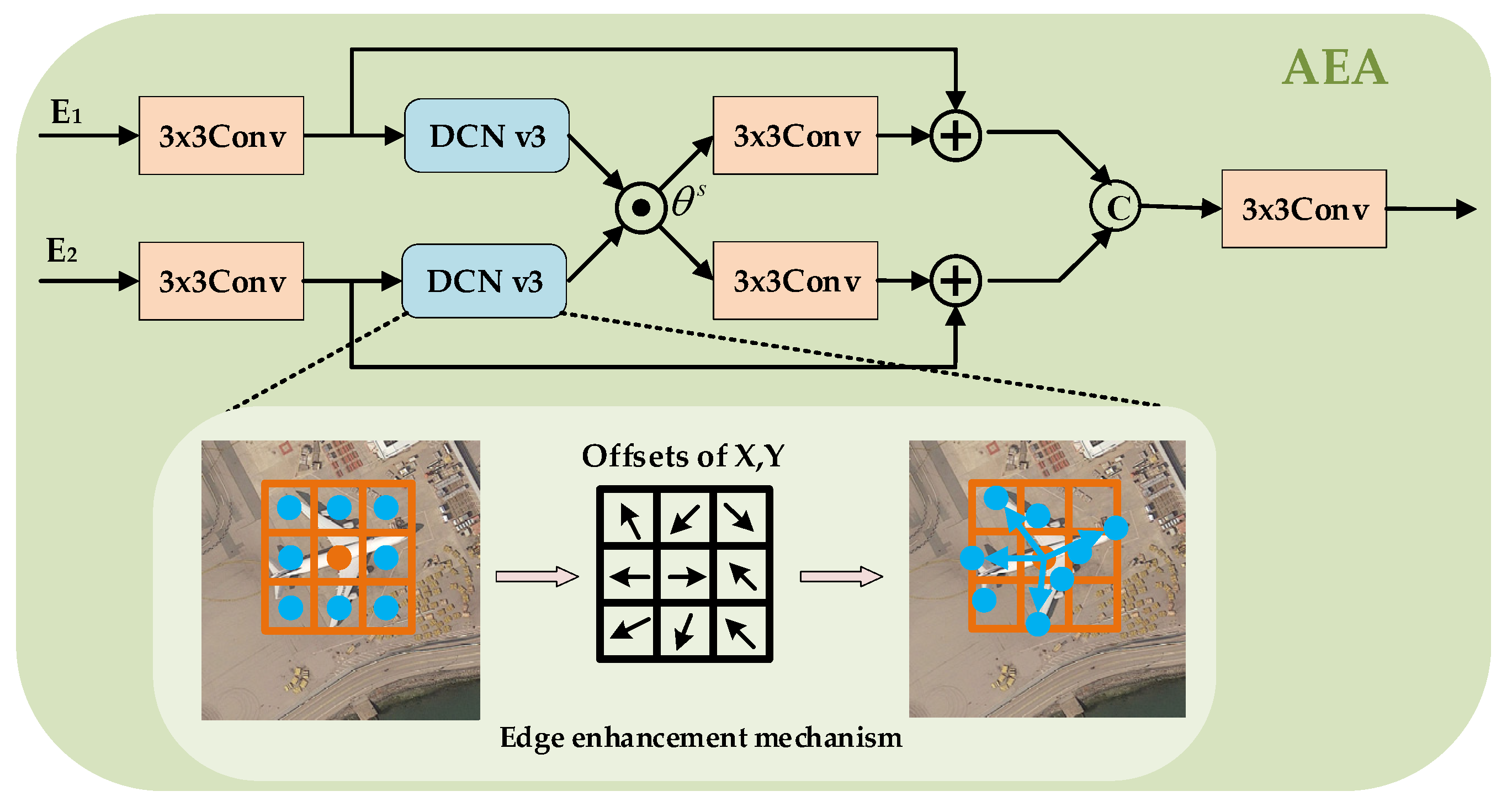
3.2. AEA Module
We include edge information as auxiliary clues in the model to enhance the network’s ability to capture fine-grained features. We employ the DCN v3 [54] method to integrate the extraction of edge features seamlessly into the CNN. This method uses convolutional layers to effectively extract edge features, allowing for a cohesive integration within the overall network architecture. In the traditional convolution operation, a fixed convolutional kernel is used for sampling and cannot adapt to different object shape and size variations. In contrast, deformable convolution allows the convolution kernel to deform within a certain range, thus effectively capturing object’s shape and contour information [55] and enabling the study of more accurate feature representations. By incorporating the DCN v3 operator, the model can capture long-range dependencies more effectively, and it can dynamically adjust the aggregation of features based on the specific spatial characteristics of the objects being detected.
In general, low-level features encompass a mix of visual clues and noise, including edges, corners, and lines, as well as uncorrelated high-frequency signals [56]. However, this amalgamation can lead to a misalignment of the network’s attention with the actual objects in RS images. To address this issue, we introduce the AEA module, specifically designed for the low-level feature map . The module uses an edge enhancement mechanism to capture edge information between features at different scales. We aim to selectively emphasize the relevant visual cues while suppressing noise and irrelevant information.
As Figure 4 shows, AEA consists of two branches that receive input from the encoder and then adjust the number of channels by convolving block by , which can be expressed as follows:
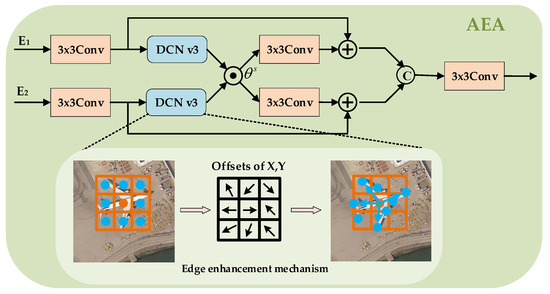
Figure 4.
Framework of the proposed AEA module.
and effectively capture the nonlocal edge features of the object by DCN v3:
where denotes the convolution operation of the edge extraction operator. We designed a selectively weighted switcher to learn adaptively how to weigh different attentions at different levels :
The primary function of this switcher is to suppress background noise and emphasize discriminative edge features by mutually weighting them, thereby preserving and incorporating the valuable cues. However, this process carries the risk of disregarding valuable clues. To address this concern, we developed a residual aggregation process that combines features as follows:
where and denote the convolution operation and the cascade operation, respectively. This process addresses the above issue well using residual learning [57]. Finally, we obtain the output feature map , which contains rich edge information.
3.3. 2CA-FPN Module
The variation in object size can result in scale misalignment between the extracted features and the actual object. To address this misalignment, FPN introduces a hierarchical structure that combines high-resolution features from lower levels with semantically rich features from higher levels, but FPN only fuses with a simple convolution operation on lateral connections. Furthermore, FPN does not propagate low-level features containing more location and edge information from shallow to deep layers, and shallow features are not fully fused with deep features. In addition, the current approach in the multiscale feature fusion network focuses primarily on merging features at different scales without fully considering the contextual relationships within the object. As a result, the network may struggle to capture the holistic understanding of the object and exploit the contextual cues that can aid in accurate detection.
To address the above problems, firstly, we design a FEM that mines local and nonlocal valid contextual information as auxiliary information to enhance the feature representation by interacting information between multiscale features in a cross-attention manner. Meanwhile, we propose a new 2CA-FPN and embed FEM into it to enhance multiscale perception. Unlike FPN, the 2CA-FPN incorporates a level-by-level feature fusion strategy. This strategy aims to capture semantic similarities and differences across multiple scales.
3.3.1. 2CA-FPN
To enhance the representation of multiscale features, 2CA-FPN employs a level-by-level feature fusion method in a top-down path. Specifically, in the FEM, the input features and undergo a process of capturing semantic similarities and differences. This is achieved through the interaction of information at the level of space, where contextual auxiliary information is incorporated to enhance the feature representation of the output feature maps and . is obtained from after convolutions, and is upsampled and concatenated with after convolution to obtain .
where and denote the fusion of features through the FEM module and upsampling operations, respectively. Similarly, and are input into the FEM module for information interaction to enhance cross-image semantic similarity and mitigate the effect of correlated noise to obtain the enhanced output feature maps and . is upsampled and concatenated with and then convolved to obtain ; is upsampled and concatenated with the AEA output of , and then convolved to obtain .
Then, the bottom-up path is further fused to obtain and .
where denotes a downsampling operation.
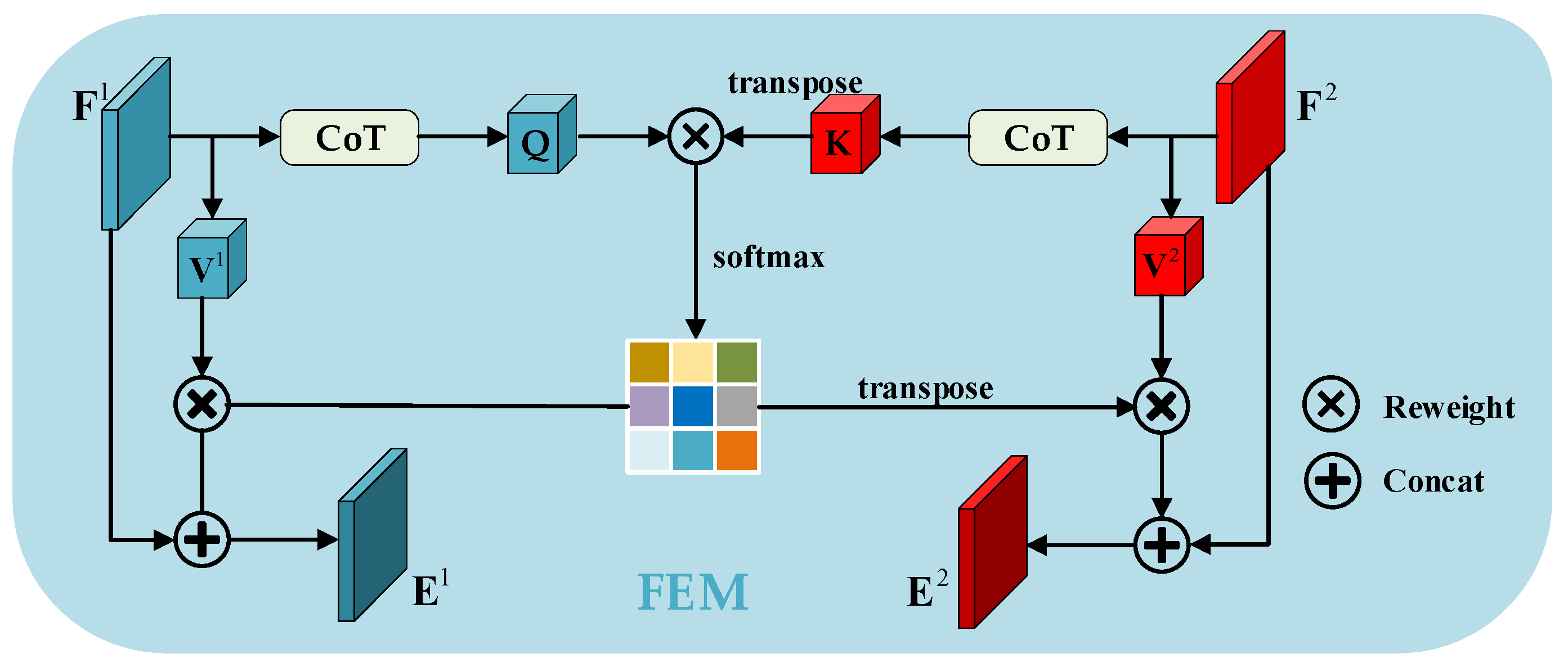
3.3.2. FEM Module
Inspired by the concept of nonlocal blocks that are recognized for their ability to capture a broader context of contextual information [58], we propose a novel FEM module. This FEM module adopts a similar principle by prioritizing contextual enhancement to obtain rich features through the exchange of information between features at various scales. Unlike the self-attention mechanism, the proposed FEM facilitates information exchange between features at various scales through spatial-level information communication, which enables the module to understand and use the semantic relations among features better.
Since the inputs to the FEM are paired feature maps, we uniformly denote the input feature pairs of different scales as , where . As Figure 5 shows, the more representative features and are first obtained using CoT blocks to capture both local and nonlocal context information of the input for and , respectively, where , is the channel count of the low-dimensional feature map. We then reshape and into the , where . The and communicate across image information through feature interaction. Therefore, we designed two branches to augment the feature representation for each of the two inputs. We multiply query and the transpose of key to obtain the first feature map and transpose that feature map to obtain the second feature map. Then, we compute the attention maps and using layers.
where is the correlation degree between the pixel position of and the pixel position of . The degree of similarity between these positions determines the strength of the observed correlation. Meanwhile, and are passed through the same convolution layer to generate two new features, and , respectively, where . Next, we reshape them into , where . We then do a matrix multiplication of and and reshape it into the shape of . We do the same for and . We feed them into convolutional block layers and , respectively. Finally, we use residual connections to prevent valuable clues from being lost, resulting in the final results in Figures and . They are calculated as follows:
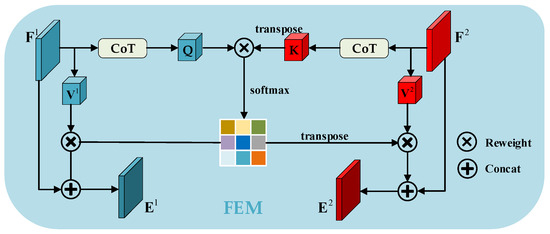
Figure 5.
The framework of the proposed FEM module.
Incorporating global contextual information into enhanced feature graphs allows for selective aggregation of contextual information using attention graphs. This selective integration is based on the attention weights assigned to different regions. As a result, similar semantic features gain mutual benefit, enhancing intra-class relevance and promoting semantic consistency.
4. Experiments and Analysis
In this section, we present an overview of the experimental dataset, evaluation metrics, and practical implementation details. We then evaluate the effects of AEA and 2CA-FPN with FEM on AEAMFI-Det via ablation experiments. Finally, we present the results of a comparison of the performance of AEAMFI-Det with the performance of state-of-the-art methods, illustrating the superiority of AEAMFI-Det.
4.1. Dataset and Evaluation Metrics
We validated our proposed method using two datasets: NWPU VHR-10 [33] and DIOR [32]. NWPU VHR-10 is an open dataset that has been widely used in RSOD research. It consists of 715 RGB color images from Google Earth and 85 infrared images after pan-sharpening. It has ten object categories: airplane (AL), baseball diamond (BB), basketball court (BC), bridge (BD), ground track field (GTF), harbor (HB), ship (SP), storage tank (ST), tennis court (TC), and vehicle (VH). The NWPU VHR-10 dataset is challenging, with similarities between object categories, small visual differences in object backgrounds, and varying object sizes. Of all the samples in the database, 150 unlabeled negative samples were excluded from consideration in the experiment. We randomly selected 80% of the 650 positive sample images as the training set and used the rest for testing.
The DIOR dataset, released by Northwestern Polytechnical University in 2019, is currently the largest large-scale benchmark dataset for object detection of optical remote sensing images. DIOR contains 23,463 images and 192,472 instances. It has 20 object categories: airplane (AL), airport (AT), baseball field (BF), basketball court (BC), bridge (BD), chimney (CH), dam (DM), expressway service area (ESA), expressway toll station (ETS), golf course (GC), ground track field (GTF), harbor (HB), overpass (OP), ship (SP), stadium (SD), storage tank (ST), tennis court (TC), train station (TS), vehicle (VH), and windmill (WD). The DIOR dataset has more object categories than the NWPU VHR-10 dataset, more complex backgrounds, and larger scale variations. We randomly selected 11,731 images as the training set and 3910 images as the validation set and used the remaining 7822 images for testing.
The mean average precision (mAP) is a commonly used evaluation metric in OD tasks that can be used to evaluate the detection performance of a model comprehensively. The average precision (AP) for the category is obtained by calculating the area under the precision–recall curve. AP is an averaging of the area under the curve that takes into account the variation in precision at different recall rates. To account for the model’s performance on different categories, the APs of all the object categories were averaged to obtain the final mAP. The mAP is calculated as follows:
where represents the number of categories included and and represent the accuracy rate and recall rate belonging to category , respectively.
4.2. Implementation Details
We executed the algorithms using the widely used PyTorch1.7.1 framework and a 16-GB RAM Nvidia GeForce RTX 4080 GPU. First, we randomly flipped 50% of the images in the dataset horizontally to increase the amount of data. The input image size of this calculation model was . SGD was used as the optimization algorithm, and the momentum, weight decay, and batch size were 0.9, 0.0001, and 4, respectively. The NWPU VHR-10 dataset was trained for 100 iterations. The learning rates were set to for the first 30 iterations that constituted the warm-up phase, for iterations 31–70, and for iterations 71–100. The DIOR dataset was trained for 150 iterations. The learning rates were set to for the first 30 iterations that constituted the warm-up phase, for iterations 31–90, and for iterations 91–150.
4.3. Ablation Evaluation
To assess the effects of the two proposed modules, i.e., AEA and 2CA-FPN with FEM, on the performance improvement of the AEAMFI-Det model, we performed ablation experiments on the NWPU VHR-10 dataset. These experiments aimed to investigate various network models, primarily focusing on the following architectures.
- (1)
- Baseline: We used the CSPDarknet53 backbone network, classical FPN, and universal OD head as the baseline network.
- (2)
- Baseline + AEA: baseline network with the addition of AEA.
- (3)
- Baseline + 2CA-FPN with FEM: We replaced the original FPN with 2CA-FPN with FEM on top of baseline.
- (4)
- AEAMFI-Det: The proposed multiscale featured adaptive fusion network, assembling AEA, 2CA-FPN with FEM and PSA on baseline network.
Table 1 shows the results of each category in the ablation experiments for various models. From Table 1, it can be concluded that the baseline model has a mAP of only 85.43%. In contrast, both our proposed AEA and 2CA-FPN modules with FEM improve the model performance, thus improving the detection precision compared to the baseline model. With the addition of AEA, the mAP obtains an improvement of 5.78%, and the APs of each category are well improved, indicating that the use of edge enhancement mechanism to guide the network to learn the spatial multiscale nonlocal dependence adaptively significantly improves the detection accuracy. Baseline +2CA-FPN with FEM improves the mAP by 7.35%, proving that information interaction demonstrates the effectiveness of information interaction through cross-attention with the help of contextual information in RSOD. Finally, compared with the baseline, AEAMFI-Det increases mAP from 85.43% to 95.36%, a greater improvement than is achieved by adding either module alone. These results suggest that the combined use of AEA and 2CA-FPN with the FEM module in AEAMFI-Det synergistically enhances the model’s detection capabilities.

Table 1.
Ablation studies of model components. The highest values in each row are indicated by bold numbers (%).
From an individual category perspective, the proposed model composed of a single module and AEAMFI-Det shows enhancements compared to the baseline. For example, the mAP of vehicle (VH) and storage tank (ST) are improved by 12.47% and 9.24%, respectively, which suggests that AEAMFI-Det is effective in accurately detecting and localizing small objects and effectively solves the misalignment between the focus of the network and the real objects in RS images. In addition, the features of harbor (HB) and bridge (BD) have some similarities. By adding context enhancement, the mAP of the two are improved by 21.77% and 9.76%, which proves that the proposed AEAMFI-Det effectively suppresses the noise caused by interclass similarity and enhances the intraclass correlation. Therefore, the proposed AEAMFI-Det can effectively solve the scale misalignment problem the extracted features have with the actual objects.
Figure 6 demonstrates the visualization effect of 2CA-FPN with FEM and AEA module. The baseline model accurately detects the storage tank but fails to detect the ship. By incorporating the AEA module into the baseline, the network successfully detects two ships of similar scales by leveraging the edge enhancement mechanism. It captures the edge information of the objects and learns the spatial multiscale nonlocal dependency. Furthermore, with the addition of 2CA-FPN with FEM on the baseline, the network effectively explores both global and local contextual information of the objects. It employs cross-attentive interactions to fuse information, enabling the capture of cross-image semantic similarity between multiscale features. This approach effectively suppresses matching noise caused by local similarity between classes and enhances intra-class correlation. As a result, the network successfully detects the small-scale ship. However, due to the limited number of samples in the NWPU VHR-10 dataset, the transformer-based improved FEM could not be adequately trained, resulting in the unsuccessful detection of another ship. In contrast, our AEAMFI-Det model combines the AEA module and 2CA-FPN with FEM, benefiting from their synergistic effects and achieving the best detection results.
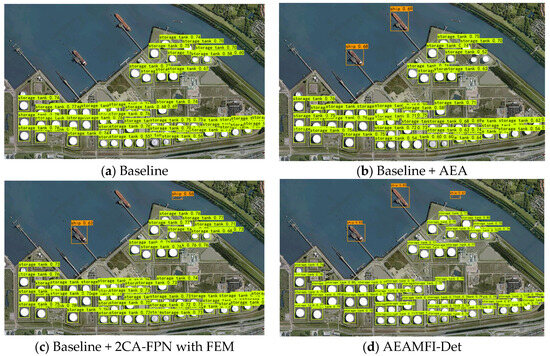
Figure 6.
Visualization results of ablation experiments (a–d).
4.4. Comparison Experiments
To evaluate the superiority of AEAMFI-Det, AEAMFI-Det was evaluated using the proposed excellent RSOD algorithms, and comparative experiments were performed on representative RSOD datasets. The selected control groups for comparative experiments include not only popular methods in computer vision such as Faster R-CNN [59], Faster R-CNN with FPN [43], Mask R-CNN, SSD [60], YOLOv4, YOLOv5, and YOLOX [61], but also RSOD-based methods such as NPMMR-Det [42] and SME-NET [44]. These OD algorithms encompass both one-stage and two-stage methods, providing a comprehensive representation of different approaches in OD.
(1) Comparative experiments with the NWPU VHR-10 dataset: More specific experimental values of the excellent detectors with respect to the NWPU VHR-10 dataset are provided in Table 2. The best values are shown in bold. Since some papers report only the detection precision (mAP), not the detection speed (FPS), we re-implemented them and tested the algorithms in a fair environment.
Table 2.
Comparison of object detection with other methods on NWPU VHR-10 (%), the highest values in each row are indicated by bold numbers.
The experimental results suggest that AEAMFI-Det achieved a mAP of 95.36%, which was better than the mAPs achieved by the other object detectors considered in the study. The mAP of the proposed approach was 2.36% better than that of SME-NET. The FPS of the proposed method is moderate because our approach adds AEA, 2CA-FPN with FEM, and PSA modules to the baseline, which significantly enhances the detection ability of the network, although this increases the amount of computation necessary and slightly affects the efficiency of the model. AEAMFI-Det achieved the top AP performance in 7 of 10 categories, and its mAP was the best among the methods compared. In conclusion, comparative experiments with the NWPU VHR-10 dataset confirm that AEAMFI-Det achieves the best performance.
Figure 7 displays the visualization results of the proposed AEAMFI-Det for the NWPU VHR-10 dataset. As the figure shows, vehicles (VH) obscured by surrounding objects and shadows are correctly detected, thanks to the inclusion of contextual information and enhanced intra-class correlation through cross-attention. For tennis court (TC), ship (SP), etc., which are affected by complex and variable backgrounds, we achieve correct detection by the action of the edge enhancement mechanism.
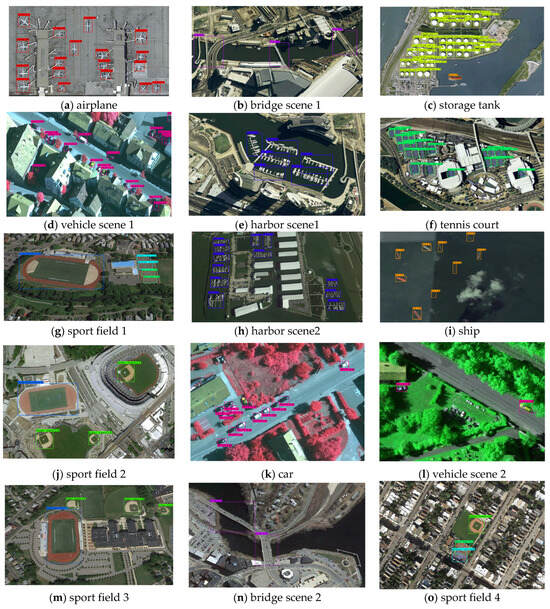
Figure 7.
NWPU VHR-10 part of the object visualization results (a–o).
(2) Comparative experiments with the DIOR dataset: To validate the detection capability and generality of AEAMFI-Det for RSOD tasks more, comparative experiments were conducted using the DIOR dataset.
As Table 3 shows, AEAMFI-Det achieves the highest mAP of 77.82% of all one-stage detectors (e.g., YOLOX, NPMMR-Det, and SME-NET) when applied to the DIOR dataset and also outperforms some two-level detectors, such as Faster R-CNN, Mask R-CNN and Faster R-CNN with FPN. There are 16 categories with an AP of more than 70% and 10 categories with an AP of more than 75%. However, the performance of the proposed method in detecting objects in the overpass (OP) category in the DIOR dataset was unsatisfactory. This is because the training sample size for overpasses was small, which greatly increased the possibility of misidentifying overpasses as bridges.
Table 3.
Comparison of object detection with other methods on DIOR (%), the highest values in each row are indicated by bold numbers.
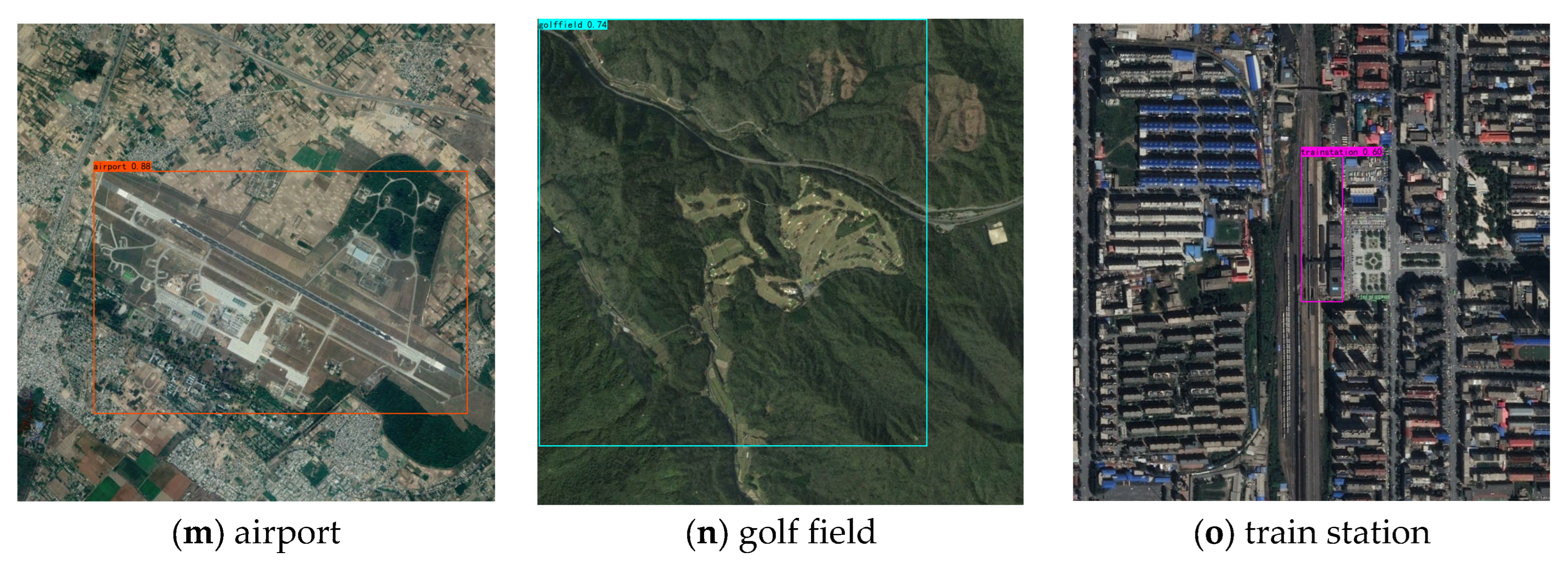
To illustrate the detection capability of AEAMFI-Det, a visualized view of the DIOR dataset is shown in Figure 8. As the figure shows, AEAMFI-Det performs well in detecting not only small and dense objects, such as ship (SP), windmill (WD), storage tank (ST), and airplane (AL), but also large objects, such as ground track field (GTF), chimney (CH), and dam (DM). For classes with large variations in scale and shape, such as airplane (AL) and ship (SP), the problem of scale inconsistency between extracted features and actual objects is effectively solved by filtering noise interference caused by intra-class diversity and enhancing intra-class correlation through a cross-attention mechanism.
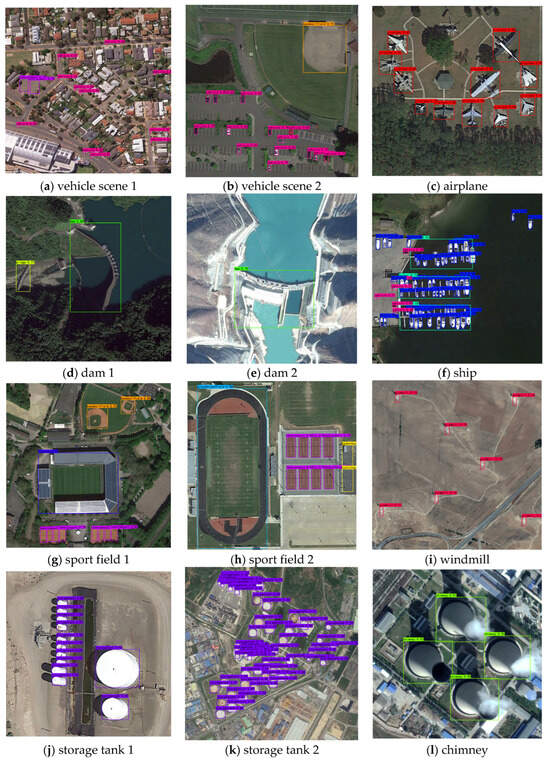
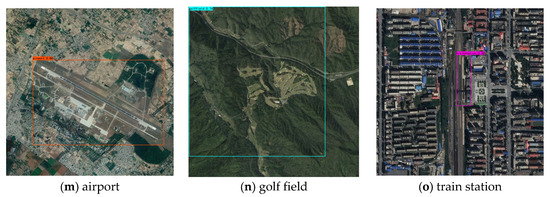
Figure 8.
DIOR partial-object visualization results (a–o).
5. Discussion
Based on the analysis of the results of the ablation experiments in Section 4.3 and the results of the comparison experiments in Section 4.4, we conduct a discussion of the experimental results in this section.
First, ablation experiments are conducted on the NWPU VHR-10 dataset to investigate different network models, and based on the experimental results of different models, it can be seen that all of our proposed modules are able to improve detection accuracy to different degrees. The addition of the AEA module gives a good improvement in the AP of each category, indicating that the use of the edge enhancement mechanism to guide the network to adaptively learn the spatial multiscale nonlocal dependencies significantly improves the detection accuracy. Moreover, 2CA-FPN with FEM enhances the feature representation with the help of contextual information through cross-attention information interaction. The PSA module further processes the spatial information of multiscale features and effectively establishes the long-term dependency relationship between the attention of multiscale channels for better interdependency refinement. AEA, 2CA-FPN with FEM and PSA gain from each other, and AEAMFI-Det shows absolute advantages over adding either module alone.
AEAMFI-Det employs a level-by-level feature fusion strategy to capture semantic similarities and differences between multiscales, and effectively solves the scale misalignment between network-extracted features and real objects by mining global and local valid contextual information to interact information between multiscale features in a cross-attentive manner, suppressing the noise caused by interclass similarity. Meanwhile, the edge enhancement mechanism is used to learn the spatial multiscale nonlocal dependency and enhance the detection accuracy of small targets. The combination of the two effectively solves the misalignment between the focus of the network and the real objects in the image. The results of the ablation experiments illustrate our motivation well.
Comparing the detection performance of AEAMFI-Det and the state-of-the-art methods on the NWPU VHR-10 dataset and the DIOR dataset, it can be concluded that AEAMFI-Det is optimal based on the detection results of each detection algorithm. On the NWPU VHR-10 dataset, AEAMFI-Det obtained the best AP performance in 7 out of 10 categories, and the AP difference with other detectors was within 1% in 2 out of the other three categories. We added the cross-attention module to AEAMFI-Det, which is an improvement based on self-attention due to the large amount of image data required to train the transformer, resulting in slightly poorer detection results for ground track field categories with insufficient samples. From some of the visualization results, it can be concluded that vehicles that are occluded by surrounding objects and shadows are correctly detected, thanks to the inclusion of contextual information and the enhancement of intraclass correlation through cross-attention. For tennis courts, ships, and other cases affected by complex and variable backgrounds, we achieve correct detection through the action of the edge enhancement mechanism.
On the DIOR dataset, AEAMFI-Det had 16 categories with APs above 70% and 10 categories above 75%. Thirteen of the 20 categories had the highest AP performance, and six of the other seven categories had APs within 1.5% of the APs of the other detectors. The small number of training samples for bridges and the interclass similarity between the samples for bridges and overpasses greatly increases the likelihood of confusing bridge and overpasses detections. As can be concluded from some of the visualization results, AEAMFI-Det has excellent detection results for small and large objects. For objects with large-scale variations, such as airplanes and ships, satisfactory detection performance is obtained by filtering the noise interference caused by intraclass diversity and enhancing intraclass correlation through the cross-attention mechanism.
Overall, the proposed AEAMFI-Det effectively captures spatial and channel dependencies from both global and local perspectives, achieves feature capture through edge enhancement, context-assisted, and cross-attention, and employs a level-by-level feature fusion strategy to achieve multiscale perceptual aggregation, which effectively solves the misalignments between features extracted from the target model and the real object.
6. Conclusions
This paper proposes a novel one-stage detection mechanism with adaptive fusion in multiscale features called AEAMFI-Det for RSOD to address the misalignment between the model features extracted and the actual object. The mechanism can be used to locate and identify instances in RS images accurately. The AEA module uses an edge enhancement mechanism to bootstrap multiscale nonlocal dependencies in the network learning space and improve the misalignment of the network’s attention with actual objects. The 2CA-FPN enhances multiscale perception with level-by-level feature fusion, embedded FEM captures the effective context, and enhances the feature representation by interacting information between multiscale features in a cross-attention manner to effectively improve the scale misalignment between the features and the actual object. Long-term dependencies between channels are established by introducing PSA for better interdependent refinement of spatial and channel dimensions.
The structural design of the proposed method is complicated, resulting in a relatively high computational complexity. In the next few years, we will adjust the network with guaranteed precision and design a lighter, more general, and more effective modular structure to calibrate objects for RSOD better.
Author Contributions
Conceptualization, W.H. and Y.Z.; methodology, W.H.; software, Y.Z.; validation, W.H. and L.S.; formal analysis, W.H. and L.G.; investigation, Y.Z.; writing—original draft preparation, Y.Z.; writing—review and editing, W.H., L.G. and L.S.; visualization, Y.Z.; supervision, W.H., L.S. and Y.C.; project administration, Y.C.; funding acquisition, Y.C. and L.S. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the National Natural Science Foundation of China (Grant No. 61971233) and Youth Innovation Promotion Association of Chinese Academy of Sciences (Grant No. 2020377).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The data are available online at: http://m6z.cn/5UAbEW.
Acknowledgments
The authors would like to thank the editors and reviewers for their advice.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The abbreviations for all key terms in this article are explained below:
| AEAMFI-Det | Adaptive edge aggregation and multiscale feature interaction detector |
| AEA | Adaptive edge aggregation |
| FEM | Feature enhancement module |
| 2CA-FPN | Context-aware cross-attention feature pyramid network |
| PSA | Pyramid squeeze attention |
| OD | Object detection |
| RS | Remote sensing |
| RSOD | Remote sensing object detection |
| CNNs | Convolutional neural networks |
| DL | Deep learning |
| HOG | Histogram of orientation gradient |
| SIFT | Scale-invariant feature transform |
| Adaboost | Adaptive boosting |
| YOLO | You only look once |
| SSD | Single shot multiBox detector |
| NPMMR-Det | Nonlocal-aware pyramid and multiscale multitask refinement detector |
| SME-NET | Feature split–merge–enhancement network |
| DIOR | Object detectIon in optical remote sensing images |
| FPN | Feature pyramid networks |
| CoT | Contextual Transformer |
| DCN v3 | Deformable convolution v3 |
| FPS | Frame per second |
| AP | Average precision |
| Map | Mean average precision |
References
- Liu, K.; Huang, J.; Xu, M.; Perc, M.; Li, X. Density Saliency for Clustered Building Detection and Population Capacity Estimation. Neurocomputing 2021, 458, 127–140. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A Survey on Object Detection in Optical Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Lu, X.; Zhang, Y.; Yuan, Y.; Feng, Y. Gated and Axis-Concentrated Localization Network for Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 2020, 58, 179–192. [Google Scholar] [CrossRef]
- Zhang, W.; Jiao, L.; Li, Y.; Huang, Z.; Wang, H. Laplacian Feature Pyramid Network for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5604114. [Google Scholar] [CrossRef]
- Li, J.; Zhang, H.; Song, R.; Xie, W.; Li, Y.; Du, Q. Structure-Guided Feature Transform Hybrid Residual Network for Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5610713. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Zhu, P.; Chen, P.; Tang, X.; Li, C.; Jiao, L. Foreground Refinement Network for Rotated Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5610013. [Google Scholar] [CrossRef]
- Fu, L.; Li, Z.; Ye, Q.; Yin, H.; Liu, Q.; Chen, X.; Fan, X.; Yang, W.; Yang, G. Learning Robust Discriminant Subspace Based on Joint L2, p- and L2, s-Norm Distance Metrics. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 130–144. [Google Scholar] [CrossRef] [PubMed]
- Ye, Q.; Huang, P.; Zhang, Z.; Zheng, Y.; Fu, L.; Yang, W. Multi-view Learning with Robust Double-sided Twin SVM with Applications to Image Recognition. IEEE Trans. Cybern. 2022, 52, 12745–12758. [Google Scholar] [CrossRef]
- Ye, Q.; Li, Z.; Fu, L.; Zhang, Z.; Yang, W.; Yang, G. Nonpeaked Discriminant Analysis for Data representation. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3818–3832. [Google Scholar] [CrossRef]
- Yu, Y.; Fu, L.; Cheng, Y.; Ye, Q. Multi-view distance metric learning via independent and shared feature subspace with applications to face and forest fire recognition, and remote sensing classification. Knowl. Based Syst. 2022, 243, 108350. [Google Scholar] [CrossRef]
- Fu, L.; Zhang, D.; Ye, Q. Recurrent Thrifty Attention Network for Remote Sensing Scene Recognition. IEEE Trans. Geosci. Remote Sens. 2021, 59, 8257–8268. [Google Scholar] [CrossRef]
- Ma, L.; Zheng, Y.; Zhang, Z.; Yao, Y.; Fan, X.; Ye, Q. Motion Stimulation for Compositional Action Recognition. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 2061–2074. [Google Scholar] [CrossRef]
- Li, X.; Chen, M.; Nie, F.; Wang, Q. Locality Adaptive Discriminant Analysis. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; International Joint Conferences on Artificial Intelligence Organization: Melbourne, Australia, 2017; pp. 2201–2207. [Google Scholar]
- Zhu, C.; Zhou, H.; Wang, R.; Guo, J. A Novel Hierarchical Method of Ship Detection from Spaceborne Optical Image Based on Shape and Texture Features. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3446–3456. [Google Scholar] [CrossRef]
- Han, J.; Zhang, D.; Cheng, G.; Guo, L.; Ren, J. Object Detection in Optical Remote Sensing Images Based on Weakly Supervised Learning and High-Level Feature Learning. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3325–3337. [Google Scholar] [CrossRef]
- Han, J.; Zhou, P.; Zhang, D.; Cheng, G.; Guo, L.; Liu, Z.; Bu, S.; Wu, J. Efficient, Simultaneous Detection of Multi-Class Geospatial Targets Based on Visual Saliency Modeling and Discriminative Learning of Sparse Coding. ISPRS J. Photogramm. Remote Sens. 2014, 89, 37–48. [Google Scholar] [CrossRef]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. Additive Logistic Regression: A Statistical View of Boosting (With Discussion and a Rejoinder by the Authors). Ann. Stat. 2000, 28, 337–407. [Google Scholar] [CrossRef]
- Han, Y.; Liao, J.; Lu, T.; Pu, T.; Peng, Z. KCPNet: Knowledge-Driven Context Perception Networks for Ship Detection in Infrared Imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5000219. [Google Scholar] [CrossRef]
- Zhang, C.; Lam, K.-M.; Wang, Q. CoF-Net: A Progressive Coarse-to-Fine Framework for Object Detection in Remote-Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5600617. [Google Scholar] [CrossRef]
- Li, Z.; Li, E.; Xu, T.; Samat, A.; Liu, W. Feature Alignment FPN for Oriented Object Detection in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2023, 20, 6001705. [Google Scholar] [CrossRef]
- Lin, Q.; Zhao, J.; Fu, G.; Yuan, Z. CRPN-SFNet: A High-Performance Object Detector on Large-Scale Remote Sensing Images. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 416–429. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Zhang, K.; Wang, J.; Wang, Y.; Wang, Q.; Li, Q. CDD-Net: A Context-Driven Detection Network for Multiclass Object Detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8004905. [Google Scholar] [CrossRef]
- Zhang, H.; Leng, W.; Han, X.; Sun, W. MOON: A Subspace-Based Multi-Branch Network for Object Detection in Remotely Sensed Images. Remote Sens 2023, 15, 4201. [Google Scholar] [CrossRef]
- Huang, Z.; Li, W.; Xia, X.-G.; Wang, H.; Jie, F.; Tao, R. LO-Det: Lightweight Oriented Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 223373–223384. [Google Scholar] [CrossRef]
- Jian, J.; Liu, L.; Zhang, Y.; Xu, K.; Yang, J. Optical Remote Sensing Ship Recognition and Classification Based on Improved YOLOv5. Remote Sens 2023, 15, 4319. [Google Scholar] [CrossRef]
- Zhang, X.; Gong, Z.; Guo, H.; Liu, X.; Ding, L.; Zhu, K.; Wang, J. Adaptive Adjacent Layer Feature Fusion for Object Detection in Remote Sensing Images. Remote Sens 2023, 15, 4224. [Google Scholar] [CrossRef]
- Ming, Q.; Miao, L.; Zhou, Z.; Dong, Y. CFC-Net: A Critical Feature Capturing Network for Arbitrary-Oriented Object Detection in Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5605814. [Google Scholar] [CrossRef]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object Detection in Optical Remote Sensing Images: A Survey and a New Benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-Class Geospatial Object Detection and Geographic Image Classification Based on Collection of Part Detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Zhang, Y.; Yuan, Y.; Feng, Y.; Lu, X. Hierarchical and Robust Convolutional Neural Network for Very High-Resolution Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5535–5548. [Google Scholar] [CrossRef]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A High Resolution Optical Satellite Image Dataset for Ship Recognition and Some New Baselines. In Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods, Porto, Portugal, 24–26 February 2017; SCITEPRESS—Science and Technology Publications: Porto, Portugal, 2017; pp. 324–331. [Google Scholar]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated Objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8232–8241. [Google Scholar]
- Liu, Y.; Li, Q.; Yuan, Y.; Du, Q.; Wang, Q. ABNet: Adaptive Balanced Network for Multiscale Object Detection in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5614914. [Google Scholar] [CrossRef]
- Liu, S.; Zhang, L.; Lu, H.; He, Y. Center-Boundary Dual Attention for Oriented Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Tian, S.; Kang, L.; Xing, X.; Tian, J.; Fan, C.; Zhang, Y. A Relation-Augmented Embedded Graph Attention Network for Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5603914. [Google Scholar] [CrossRef]
- Zhu, X.; Cheng, D.; Zhang, Z.; Lin, S.; Dai, J. An Empirical Study of Spatial Attention Mechanisms in Deep Networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6688–6697. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. FcaNet: Frequency Channel Attention Networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 783–792. [Google Scholar]
- Huang, Z.; Li, W.; Xia, X.-G.; Wu, X.; Cai, Z.; Tao, R. A Novel Nonlocal-Aware Pyramid and Multiscale Multitask Refinement Detector for Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5601920. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 2117–2125. [Google Scholar]
- Ma, W.; Li, N.; Zhu, H.; Jiao, L.; Tang, X.; Guo, Y.; Hou, B. Feature Split–Merge–Enhancement Network for Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5616217. [Google Scholar] [CrossRef]
- Huang, W.; Li, G.; Jin, B.; Chen, Q.; Yin, J.; Huang, L. Scenario Context-Aware-Based Bidirectional Feature Pyramid Network for Remote Sensing Target Detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6505005. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, K.; Wang, J.; Wang, Y.; Wang, Q.; Li, X. GCWNet: A Global Context-Weaving Network for Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5619912. [Google Scholar] [CrossRef]
- Liu, J.; Li, S.; Zhou, C.; Cao, X.; Gao, Y.; Wang, B. SRAF-Net: A Scene-Relevant Anchor-Free Object Detection Network in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5405914. [Google Scholar] [CrossRef]
- Yu, L.; Hu, H.; Zhong, Z.; Wu, H.; Deng, Q. GLF-Net: A Target Detection Method Based on Global and Local Multiscale Feature Fusion of Remote Sensing Aircraft Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4021505. [Google Scholar] [CrossRef]
- Zhou, Y.; Hu, H.; Zhao, J.; Zhu, H.; Yao, R.; Du, W.-L. Few-Shot Object Detection via Context-Aware Aggregation for Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6509605. [Google Scholar] [CrossRef]
- Zhang, G.; Lu, S.; Zhang, W. CAD-Net: A Context-Aware Detection Network for Objects in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10015–10024. [Google Scholar] [CrossRef]
- Zhang, H.; Zu, K.; Lu, J.; Zou, Y.; Meng, D. EPSANet: An Efficient Pyramid Squeeze Attention Block on Convolutional Neural Network. In Proceedings of the Asian Conference on Computer Vision, Macau, China, 4–8 December 2022; pp. 541–557. [Google Scholar]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Contextual Transformer Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 1489–1500. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A New Backbone That Can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Wang, W.; Dai, J.; Chen, Z.; Huang, Z.; Li, Z.; Zhu, X.; Hu, X.; Lu, T.; Lu, L.; Li, H.; et al. InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 14408–14419. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Ji, G.-P.; Zhu, L.; Zhuge, M.; Fu, K. Fast Camouflaged Object Detection via Edge-Based Reversible Re-Calibration Network. Pattern Recognit. 2022, 123, 108414. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Patt. Anal. Mach. Learn. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).