
An Inverse-Occurrence Sampling Approach for Urban Flood Susceptibility Mapping

 ,
, 
Abstract
:
1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Dataset
2.2.1. Flood Inventory
2.2.2. Conditioning Factors
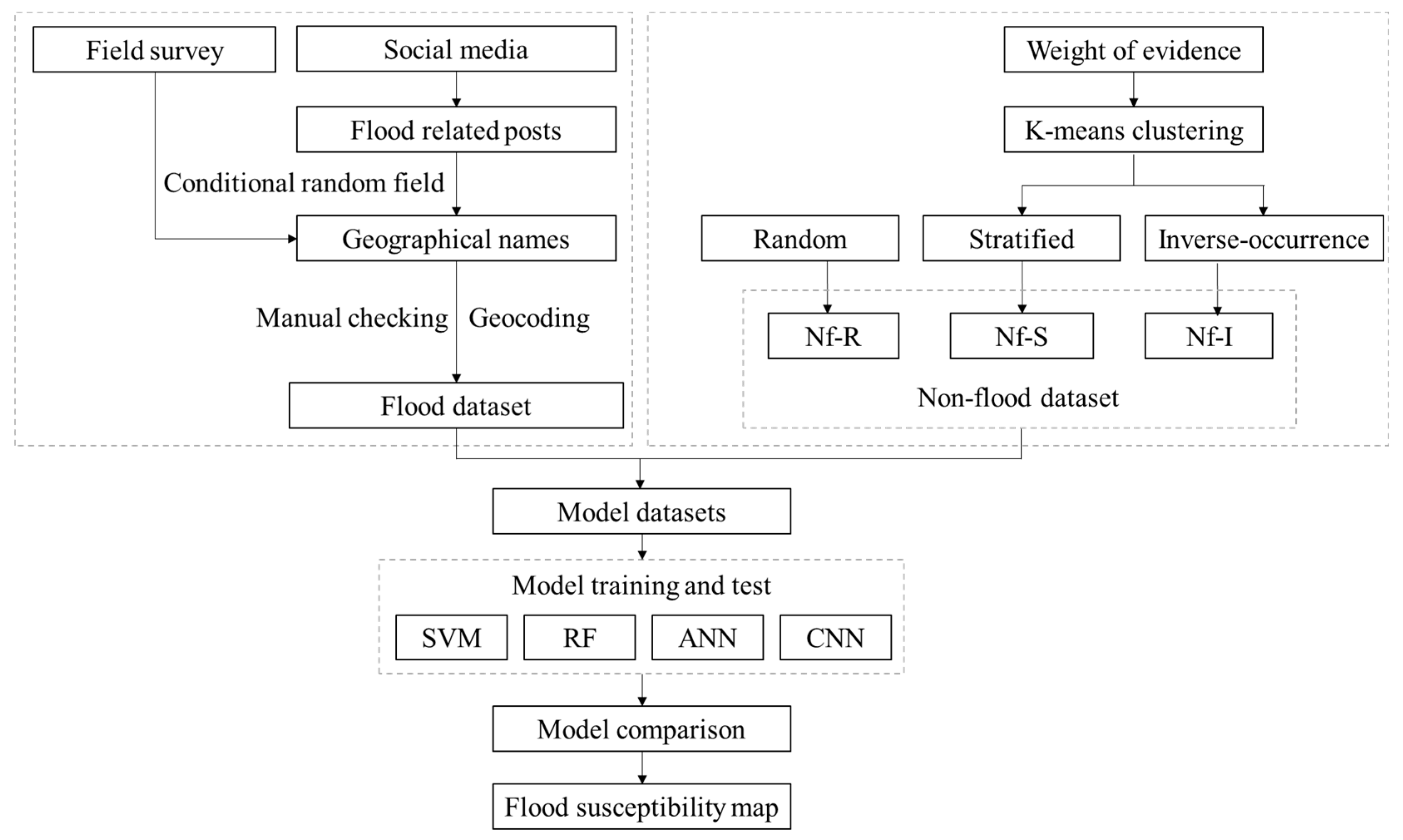
2.3. Research Framework
2.4. Non-Flood Sampling Approach
2.4.1. Random Sampling
2.4.2. Stratified Sampling
2.4.3. Inverse-Occurrence Sampling
2.4.4. Sampled Non-Flood Data
2.5. Learning Technique
2.5.1. Support Vector Machine (SVM)
2.5.2. Random Forest (RF)
2.5.3. Artificial Neural Network (ANN)
2.5.4. Convolutional Neural Networks (CNNs)
2.6. Model Assessment
3. Results
3.1. Sampling Approach Comparison
3.2. Learning Technique Comparison
3.3. Interaction between Sampling Approach and Learning Technique
3.4. Flood Mechanisms
3.5. Flood Susceptibility
3.5.1. Flood Density Order
3.5.2. Flood Density Outlier
3.5.3. Flood Susceptibility Map
4. Discussion
4.1. Flood Susceptibility Learning in Underreported Areas
4.2. Flood Susceptibility Model Evaluation
4.3. Uncertainties and Limitations
4.4. Benefits and Future Work
5. Conclusions
- (1)
- Sampling approaches have a greater impact on model performance than learning techniques. The AUC variations caused by learning techniques ranged from 0.04 to 0.09, whereas the AUC variations caused by sampling approaches were between 0.15 and 0.22 and were all larger than 0.1.
- (2)
- The inverse-occurrence sampling approach representing spatial dependence outperformed the two other commonly used sampling approaches, not only for high AUC values but also for small AUC variations. This finding is robust in regard to multiple learning techniques and different flooding mechanisms. AUCs in the inverse group have a narrower range, that is, 0.14–0.18 in Tianhe, and 0.35–0.39 in Panyu, than in the random group, that is, 0.24–0.28 in Tianhe, and 0.43–0.53 in Panyu; and the stratified group, which was 0.23–0.30 in Tianhe, and 0.42–0.48 in Panyu.
- (3)
- The most accurate learning technique measured by the AUC was CNN-RF, followed by SVM, CNN-SVM, RF, CNN, and ANN.
- (4)
- Flood density order and outliers should be applied to assess the quality of flood susceptibility models. ANN- and CNN-based models tended to produce polarized patterns in flood susceptibility maps, contradicting the ascending order of flood density with increasing susceptibility levels. Moreover, flood density outliers tended to appear in the models derived using RF and CNN-RF.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- UNDRR (United Nations Office for Disaster Risk Reduction). Human Cost of Disasters: An Overview of the Last 20 Years 2000–2019. 2020. Available online: https://www.undrr.org/publication/human-cost-disasters-overview-last-20-years-2000-2019 (accessed on 7 May 2020).
- Ahmad, T.; Pandey, A.C.; Kumar, A.; Tirkey, A. Understanding the role of surface runoff in potential flood inundation in the Kashmir valley, Western Himalayas. Phys. Chem. Earth 2023, 131, 103423. [Google Scholar] [CrossRef]
- Rentschler, J.; Avner, P.; Marconcini, M.; Su, R.; Strano, E.; Vousdoukas, M.; Hallegatte, S. Global evidence of rapid urban growth in flood zones since 1985. Nature 2023, 622, 87–92. [Google Scholar] [CrossRef] [PubMed]
- Delgado, C.D.; Iniestra, J.G. Flood Risk Assessment in Humanitarian Logistics Process Design. J. Appl. Res. Technol. 2014, 12, 976–984. [Google Scholar] [CrossRef]
- Kimuli, J.B.; Di, B.; Zhang, R.; Wu, S.; Li, J.; Yin, W. A multisource trend analysis of floods in Asia-Pacific 1990–2018: Implications for climate change in sustainable development goals. Int. J. Disaster Risk Reduct. 2021, 59, 102237. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Flood susceptibility analysis and its verification using a novel ensemble support vector machine and frequency ratio method. Stoch. Environ. Res. Risk Assess. 2015, 29, 1149–1165. [Google Scholar] [CrossRef]
- Sahana, M.; Patel, P.P. A comparison of frequency ratio and fuzzy logic models for flood susceptibility assessment of the lower Kosi River Basin in India. Environ. Earth Sci. 2019, 78, 289. [Google Scholar] [CrossRef]
- Saha, S.; Sarkar, D.; Mondal, P. Efficiency exploration of frequency ratio, entropy and weights of evidence-information value models in flood vulnerabilityassessment: A study of raiganj subdivision, Eastern India. Stoch. Environ. Res. Risk Assess. 2022, 36, 1721–1742. [Google Scholar] [CrossRef]
- Cao, Y.; Jia, H.; Xiong, J.; Cheng, W.; Li, K.; Pang, Q.; Yong, Z. Flash Flood Susceptibility Assessment Based on Geodetector, Certainty Factor, and Logistic Regression Analyses in Fujian Province, China. ISPRS Int. J. Geo-Inf. 2020, 9, 748. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Flood susceptibility mapping using a novel ensemble weights-of-evidence and support vector machine models in GIS. J. Hydrol. 2014, 512, 332–343. [Google Scholar] [CrossRef]
- Hong, H.; Tsangaratos, P.; Ilia, I.; Liu, J.; Zhu, A.; Chen, W. Application of fuzzy weight of evidence and data mining techniques in construction of flood susceptibility map of Poyang County, China. Sci. Total Environ. 2018, 625, 575–588. [Google Scholar] [CrossRef]
- Nandi, A.; Mandal, A.; Wilson, M.; Smith, D. Flood hazard mapping in Jamaica using principal component analysis and logistic regression. Environ. Earth Sci. 2016, 75, 465. [Google Scholar] [CrossRef]
- Ali, S.A.; Parvin, F.; Pham, Q.B.; Vojtek, M.; Vojteková, J.; Costache, R.; Linh, N.T.T.; Nguyen, H.Q.; Ahmad, A.; Ghorbani, M.A. GIS-based comparative assessment of flood susceptibility mapping using hybrid multi-criteria decision-making approach, naïve Bayes tree, bivariate statistics and logistic regression: A case of Topľa basin, Slovakia. Ecol. Indic. 2020, 117, 106620. [Google Scholar] [CrossRef]
- Bunmi Mudashiru, R.; Sabtu, N.; Abdullah, R.; Saleh, A.; Abustan, I. Optimality of flood influencing factors for flood hazard mapping: An evaluation of two multi-criteria decision-making methods. J. Hydrol. 2022, 612, 128055. [Google Scholar] [CrossRef]
- Vilasan, R.T.; Kapse, V.S. Evaluation of the prediction capability of AHP and F-AHP methods in flood susceptibility mapping of Ernakulam district (India). Nat. Hazards 2022, 112, 1767–1793. [Google Scholar] [CrossRef]
- Kanani-Sadat, Y.; Arabsheibani, R.; Karimipour, F.; Nasseri, M. A new approach to flood susceptibility assessment in data-scarce and ungauged regions based on GIS-based hybrid multi criteria decision-making method. J. Hydrol. 2019, 572, 17–31. [Google Scholar] [CrossRef]
- Gudiyangada Nachappa, T.; Tavakkoli Piralilou, S.; Gholamnia, K.; Ghorbanzadeh, O.; Rahmati, O.; Blaschke, T. Flood susceptibility mapping with machine learning, multi-criteria decision analysis and ensemble using Dempster Shafer Theory. J. Hydrol. 2020, 590, 125275. [Google Scholar] [CrossRef]
- Rafiei-Sardooi, E.; Azareh, A.; Choubin, B.; Mosavi, A.H.; Clague, J.J. Evaluating urban flood risk using hybrid method of TOPSIS and machine learning. Int. J. Disaster Risk Reduct. 2021, 66, 102614. [Google Scholar] [CrossRef]
- Chen, Y. Flood hazard zone mapping incorporating geographic information system (GIS) and multi-criteria analysis (MCA) techniques. J. Hydrol. 2022, 612, 128268. [Google Scholar] [CrossRef]
- Zhao, G.; Pang, B.; Xu, Z.; Yue, J.; Tu, T. Mapping flood susceptibility in mountainous areas on a national scale in China. Sci. Total Environ. 2018, 615, 1133–1142. [Google Scholar] [CrossRef]
- Norallahi, M.; Seyed Kaboli, H. Urban flood hazard mapping using machine learning models: GARP, RF, MaxEnt and NB. Nat. Hazards 2021, 106, 119–137. [Google Scholar] [CrossRef]
- Tang, X.; Machimura, T.; Liu, W.; Li, J.; Hong, H. A novel index to evaluate discretization methods: A case study of flood susceptibility assessment based on random forest. Geosci. Front. 2021, 12, 101253. [Google Scholar] [CrossRef]
- Mangukiya, N.K.; Sharma, A. Flood risk mapping for the lower Narmada basin in India: A machine learning and IoT-based framework. Nat. Hazards 2022, 113, 1285–1304. [Google Scholar] [CrossRef]
- Xiong, J.; Li, J.; Cheng, W.; Wang, N.; Guo, L. A GIS-Based Support Vector Machine Model for Flash Flood Vulnerability Assessment and Mapping in China. ISPRS Int. J. Geo-Inf. 2019, 8, 297. [Google Scholar] [CrossRef]
- Zhao, G.; Pang, B.; Xu, Z.; Peng, D.; Xu, L. Assessment of urban flood susceptibility using semi-supervised machine learning model. Sci. Total Environ. 2019, 659, 940–949. [Google Scholar] [CrossRef] [PubMed]
- Sahana, M.; Rehman, S.; Sajjad, H.; Hong, H. Exploring effectiveness of frequency ratio and support vector machine models in storm surge flood susceptibility assessment: A study of Sundarban Biosphere Reserve, India. Catena 2020, 189, 104450. [Google Scholar] [CrossRef]
- Andaryani, S.; Nourani, V.; Haghighi, A.T.; Keesstra, S. Integration of hard and soft supervised machine learning for flood susceptibility mapping. J. Environ. Manag. 2021, 291, 112731. [Google Scholar] [CrossRef]
- Chen, W.; Li, Y.; Xue, W.; Shahabi, H.; Li, S.; Hong, H.; Wang, X.; Bian, H.; Zhang, S.; Pradhan, B.; et al. Modeling flood susceptibility using data-driven approaches of naïve Bayes tree, alternating decision tree, and random forest methods. Sci. Total Environ. 2020, 701, 134979. [Google Scholar] [CrossRef]
- Tang, X.; Li, J.; Liu, M.; Liu, W.; Hong, H. Flood susceptibility assessment based on a novel random Naïve Bayes method: A comparison between different factor discretization methods. Catena 2020, 190, 104536. [Google Scholar] [CrossRef]
- Khosravi, K.; Panahi, M.; Golkarian, A.; Keesstra, S.D.; Saco, P.M.; Bui, D.T.; Lee, S. Convolutional neural network approach for spatial prediction of flood hazard at national scale of Iran. J. Hydrol. 2020, 591, 125552. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, Z.; Hong, H.; Peng, L. Flood susceptibility mapping using convolutional neural network frameworks. J. Hydrol. 2020, 582, 124482. [Google Scholar] [CrossRef]
- Zhao, G.; Pang, B.; Xu, Z.; Peng, D.; Zuo, D. Urban flood susceptibility assessment based on convolutional neural networks. J. Hydrol. 2020, 590, 125235. [Google Scholar] [CrossRef]
- Saha, S.; Gayen, A.; Bayen, B. Deep learning algorithms to develop Flood susceptibility map in Data-Scarce and Ungauged River Basin in India. Stoch. Environ. Res. Risk Assess. 2022, 36, 3295–3310. [Google Scholar] [CrossRef]
- Ullah, K.; Wang, Y.; Fang, Z.; Wang, L.; Rahman, M. Multi-hazard susceptibility mapping based on Convolutional Neural Networks. Geosci. Front. 2022, 13, 101425. [Google Scholar] [CrossRef]
- Shahabi, H.; Shirzadi, A.; Ronoud, S.; Asadi, S.; Pham, B.T.; Mansouripour, F.; Geertsema, M.; Clague, J.J.; Bui, D.T. Flash flood susceptibility mapping using a novel deep learning model based on deep belief network, back propagation and genetic algorithm. Geosci. Front. 2021, 12, 101100. [Google Scholar] [CrossRef]
- Fang, Z.; Wang, Y.; Peng, L.; Hong, H. Predicting flood susceptibility using LSTM neural networks. J. Hydrol. 2021, 594, 125734. [Google Scholar] [CrossRef]
- Al-Abadi, A.M.; Pradhan, B. In flood susceptibility assessment, is it scientifically correct to represent flood events as a point vector format and create flood inventory map? J. Hydrol. 2020, 590, 125475. [Google Scholar] [CrossRef]
- Fang, L.; Huang, J.; Cai, J.; Nitivattananon, V. Hybrid approach for flood susceptibility assessment in a flood-prone mountainous catchment in China. J. Hydrol. 2022, 612, 128091. [Google Scholar] [CrossRef]
- Tang, X.; Li, J.; Liu, W.; Yu, H.; Wang, F. A method to increase the number of positive samples for machine learning-based urban waterlogging susceptibility assessments. Stoch. Environ. Res. Risk Assess. 2022, 36, 2319–2336. [Google Scholar] [CrossRef]
- Ekmekcioğlu, Ö.; Koc, K.; Özger, M.; Işık, Z. Exploring the additional value of class imbalance distributions on interpretable flash flood susceptibility prediction in the Black Warrior River basin, Alabama, United States. J. Hydrol. 2022, 610, 127877. [Google Scholar] [CrossRef]
- Dodangeh, E.; Choubin, B.; Eigdir, A.N.; Nabipour, N.; Panahi, M.; Shamshirband, S.; Mosavi, A. Integrated machine learning methods with resampling algorithms for flood susceptibility prediction. Sci. Total Environ. 2020, 705, 135983. [Google Scholar] [CrossRef]
- Tang, X.; Hong, H.; Shu, Y.; Tang, H.; Li, J.; Liu, W. Urban waterlogging susceptibility assessment based on a PSO-SVM method using a novel repeatedly random sampling idea to select negative samples. J. Hydrol. 2019, 576, 583–595. [Google Scholar] [CrossRef]
- Rajabi, A.; Shabanlou, S.; Yosefvand, F.; Kiani, A. Exploring the sample size and replications scenarios effect on spatial prediction of flood, using MARS and MaxEnt methods case study: Saliantape catchment, Golestan, Iran. Nat. Hazards 2021, 109, 871–901. [Google Scholar] [CrossRef]
- Tobler, W.R. A Computer Movie Simulating Urban Growth in the Detroit Region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Winters, B.A.; Angel, J.R.; Ballerine, C.; Byard, J.; Flegel, A.; Gambill, D.; Jenkins, E.; McConkey, S.A.; Markus, M.; Bender, B.A.; et al. Report for the Urban Flooding Awareness Act; Illinois Department of Natural Resources: Springfield, IL, USA, 2015. [Google Scholar]
- Cherqui, F.; Belmeziti, A.; Granger, D.; Sourdril, A.; Le Gauffre, P. Assessing urban potential flooding risk and identifying effective risk-reduction measures. Sci. Total Environ. 2015, 514, 418–425. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.; Chen, X.; Zhu, Z.; Xie, Y.; Liu, L.; Wang, X.; Wang, X.; Liu, K. The changing pattern of urban flooding in Guangzhou, China. Sci. Total Environ. 2018, 622–623, 394–401. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.; Pan, Y.; Wang, C.; Wang, X. Nonlinear Flood Responses to Tide Level and Land Cover Changes in Small Watersheds. Land 2023, 12, 1743. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study Area | Flood Records | Area (km2) | Flood Density (1/km2) | Cluster Analysis (p-Value) | Population 2021 (Million) | GDP 2021 (Billion Yuan) | Average Slope (Degree) |
|---|---|---|---|---|---|---|---|
| Tianhe | 238 | 158.35 | 1.50 | 0.00 | 2.24 | 601.2 | 9.02 |
| Panyu | 80 | 516.34 | 0.15 | 0.41 | 2.82 | 265.4 | 4.55 |
| Data | Source | Format | Resolution |
|---|---|---|---|
| Stream network | Open street map | Polyline, shape file | - |
| Land use | SinoLC-1, 2023 | Raster | 1 m |
| DEM | ASTER GDEM | Raster | 30 m |
| Remote sensing imagery | Landsat 8, 2020 | Raster | 30 m |
| Gaofen 1, 2020 | Raster | 8 m |
| Clusters | Flood Number | Flood Percentage (%) | Area Percentage (%) | Non-Flood Number (Inverse) | Non-Flood Number (Stratified) | |
|---|---|---|---|---|---|---|
| Tianhe | 1 | 171 | 71.8 | 40.8 | 17 | 97 |
| 2 | 58 | 24.4 | 33.2 | 45 | 79 | |
| 3 | 8 | 3.4 | 8.4 | 57 | 20 | |
| 4 | 1 | 0.4 | 10.5 | 59 | 25 | |
| 5 | 0 | 0.0 | 7.1 | 60 | 17 | |
| Panyu | 1 | 44 | 55.0 | 18.3 | 9 | 14 |
| 2 | 27 | 33.8 | 23.4 | 13 | 19 | |
| 3 | 7 | 8.8 | 22.8 | 18 | 18 | |
| 4 | 1 | 1.3 | 20.8 | 20 | 17 | |
| 5 | 1 | 1.3 | 14.8 | 20 | 12 |
| Method | Tianhe | Panyu | Average Rank | AUC Change S | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Random | Stratified | Inverse | Rank | Random | Stratified | Inverse | Rank | |||
| SVM | 0.6974 | 0.7037 | 0.9018 | 4.0 | 0.7828 | 0.7824 | 0.8392 | 1.0 | 2.5 | 0.2044 |
| RF | 0.6949 | 0.6983 | 0.9114 | 4.0 | 0.7625 | 0.7579 | 0.8243 | 3.0 | 3.5 | 0.2165 |
| ANN | 0.6636 | 0.6653 | 0.8760 | 6.0 | 0.7186 | 0.7164 | 0.7827 | 6.0 | 6.0 | 0.2124 |
| CNN | 0.7359 | 0.7382 | 0.8846 | 3.7 | 0.7510 | 0.7470 | 0.8047 | 5.0 | 4.3 | 0.1487 |
| CNN-SVM | 0.7403 | 0.7420 | 0.9065 | 2.3 | 0.7608 | 0.7565 | 0.8155 | 4.0 | 3.2 | 0.1662 |
| CNN-RF | 0.7543 | 0.7583 | 0.9176 | 1.0 | 0.7748 | 0.7737 | 0.8274 | 2.0 | 1.5 | 0.1633 |
| AUC change L | 0.0907 | 0.0930 | 0.0416 | — | 0.0642 | 0.0660 | 0.0565 | — | — | — |
| Tianhe | Panyu | ||
|---|---|---|---|
| ISP | 1000 | ISP | 1000 |
| NDVI | 1000 | Elevation | 461 |
| Rainfall | 358 | NDVI | 436 |
| Elevation | 41 | Rainfall | 92 |
| DD | 40 | DD | 81 |
| DR | 0 | DR | 46 |
| NDBI | 0 | NDBI | 18 |
| RE | 0 | STDE | 12 |
| Slope | 0 | RE | 10 |
| SPI | 0 | Slope | 8 |
| STDE | 0 | SPI | 1 |
| TWI | 0 | TWI | 1 |
| Study Area | Sampling Approach | SVM | RF | ANN | CNN | CNN-SVM | CNN-RF |
|---|---|---|---|---|---|---|---|
| Tianhe | Random | √ | √ | × | √ | √ | √ |
| Stratified | √ | √ | × | × | √ | √ | |
| Inverse | √ | √ | × | √ | √ | √ | |
| Panyu | Random | √ | √ | × | × | √ | √ |
| Stratified | √ | √ | × | √ | √ | √ | |
| Inverse | √ | √ | × | × | √ | √ |
| Study Area | Sampling Approach | SVM | RF | ANN | CNN | CNN-SVM | CNN-RF |
|---|---|---|---|---|---|---|---|
| Tianhe (1.5/km2) | Random | — | 1 (7.89) | — | — | — | 1 (239.2) |
| Stratified | — | 1 (17.82) | — | — | — | 2 (7.27, 575.05) | |
| Inverse | — | — | — | — | — | — | |
| Panyu (0.15/km2) | Random | — | — | — | — | — | 1 (262.55) |
| Stratified | — | 1 (8.18) | — | — | — | 1 (848.8) | |
| Inverse | — | — | — | — | — | 1 (13.61) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Lin, Y.; Tao, Z.; Zhan, J.; Li, W.; Huang, H. An Inverse-Occurrence Sampling Approach for Urban Flood Susceptibility Mapping. Remote Sens. 2023, 15, 5384. https://doi.org/10.3390/rs15225384
Wang C, Lin Y, Tao Z, Zhan J, Li W, Huang H. An Inverse-Occurrence Sampling Approach for Urban Flood Susceptibility Mapping. Remote Sensing. 2023; 15(22):5384. https://doi.org/10.3390/rs15225384
Chicago/Turabian StyleWang, Changpeng, Yangchun Lin, Zhiwen Tao, Jiayin Zhan, Wenkai Li, and Huabing Huang. 2023. "An Inverse-Occurrence Sampling Approach for Urban Flood Susceptibility Mapping" Remote Sensing 15, no. 22: 5384. https://doi.org/10.3390/rs15225384
APA StyleWang, C., Lin, Y., Tao, Z., Zhan, J., Li, W., & Huang, H. (2023). An Inverse-Occurrence Sampling Approach for Urban Flood Susceptibility Mapping. Remote Sensing, 15(22), 5384. https://doi.org/10.3390/rs15225384