
Image to Image Deep Learning for Enhanced Vegetation Height Modeling in Texas



Abstract
:
1. Introduction
2. Materials and Methods
2.1. Study Area
2.1.1. Location, Species, Physiography
2.2. Data
2.2.1. National Agriculture Imagery Program (NAIP) Data
2.2.2. Airborne Lidar Data and Canopy Height Models (CHM)

2.2.3. Existing Canopy Height Models (CHM) Datasets
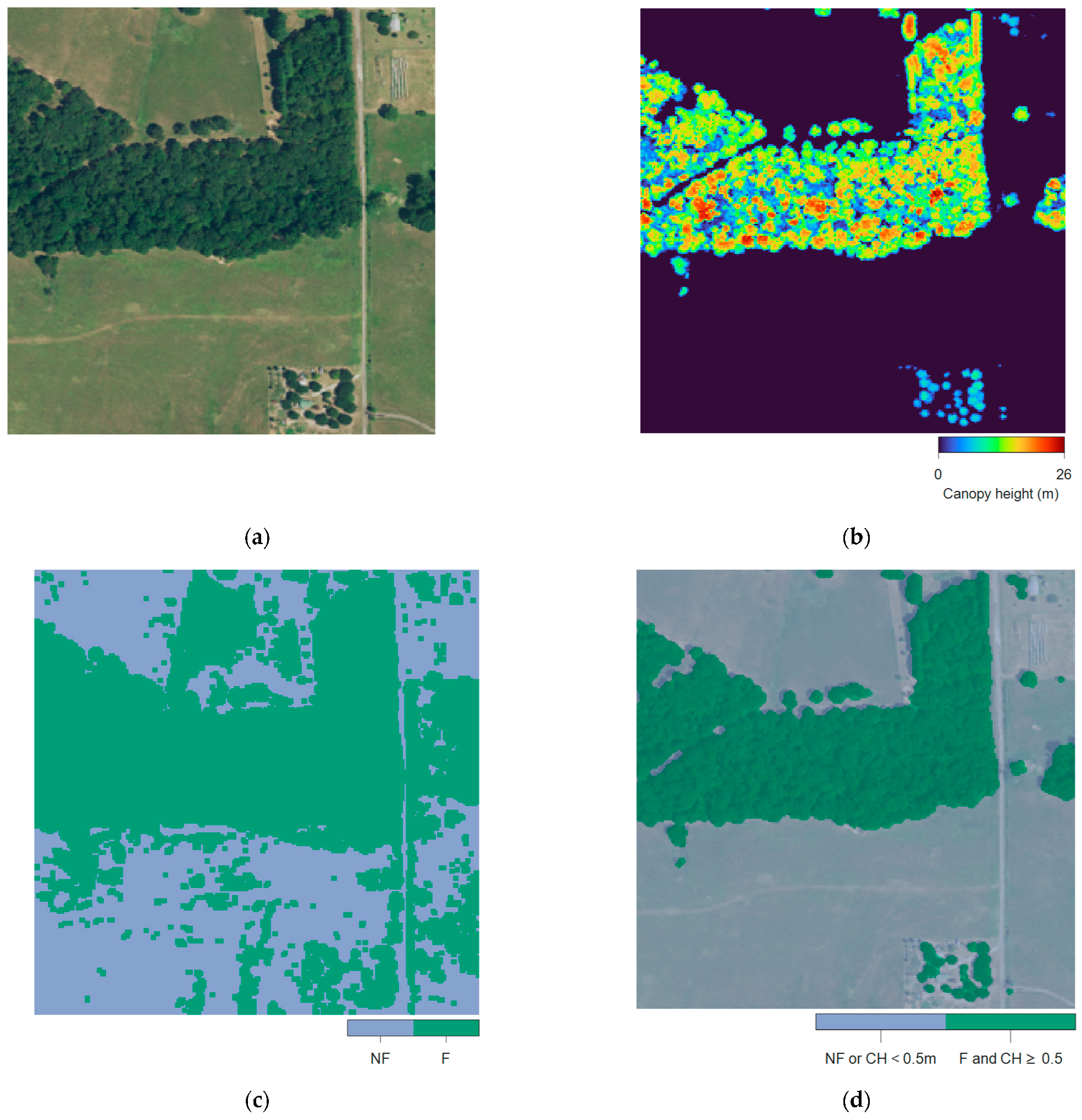
2.3. Model Development and Canopy Height Mapping
2.3.1. U-Net Model Architecture
2.3.2. Training Data Preparation
2.3.3. Model Training and Validation
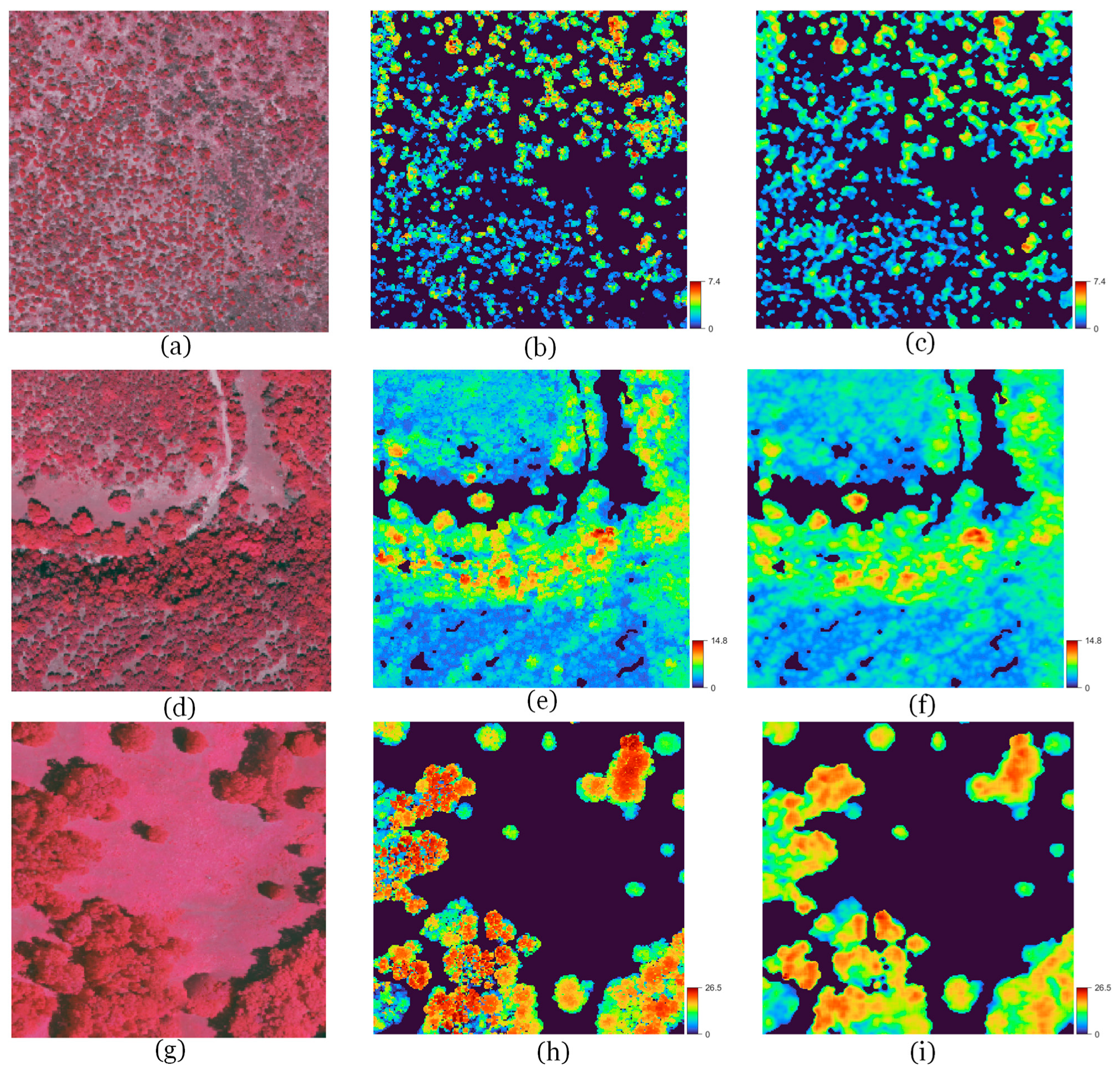
2.3.4. Model Testing on an Independent Test Set
2.4. Comparative Analyses with Existing Canopy Height Products
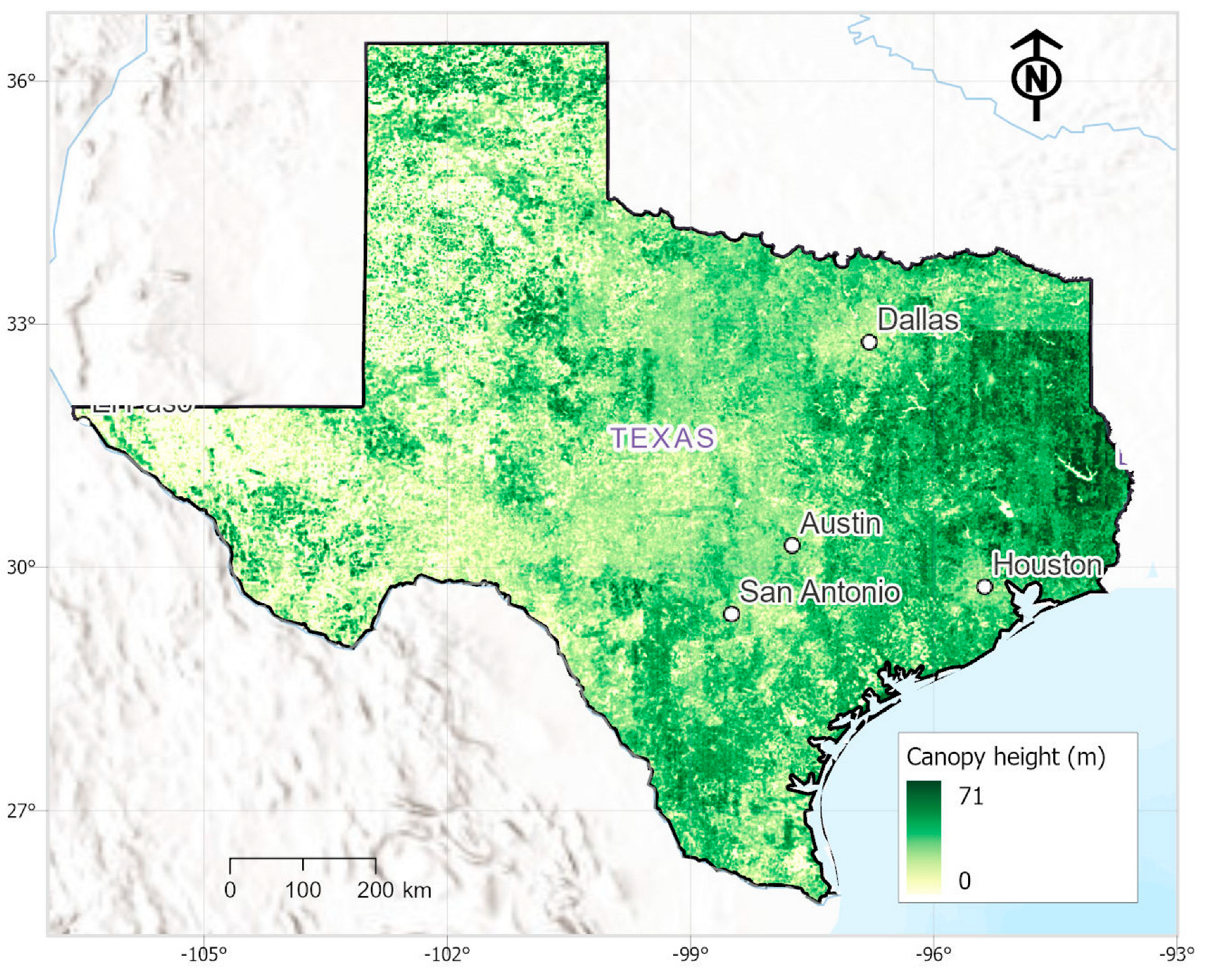
2.5. Canopy Height Mapping across Texas
3. Results
3.1. Validation Model Performance
3.2. Model Performance on Independent Test Set
3.3. Comparison with Existing CHMs
3.4. Canopy Height Product across Texas
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Overall | DXS | TBMF | TCF | TGSS | TSGSS | |
|---|---|---|---|---|---|---|
| STUDY | ||||||
| N | 22,832 | 4898 | 3683 | 4866 | 4694 | 4691 |
| R2 | 0.92 | 0.78 | 0.42 | 0.26 | 0.56 | 0.56 |
| Bias | 1.78 | 1.19 | 1.58 | 1.49 | 1.95 | 2.67 |
| MAE | 2.66 | 1.48 | 3.05 | 3.08 | 2.21 | 3.63 |
| GCHM | ||||||
| N | 22,832 | 4898 | 3683 | 4866 | 4694 | 4691 |
| R2 | 0.89 | 0.53 | 0.43 | 0.34 | 0.38 | 0.35 |
| Bias | −1.08 | −0.20 | −0.33 | −4.88 | 1.65 | −1.39 |
| MAE | 2.99 | 1.54 | 2.56 | 5.08 | 2.24 | 3.41 |
| GLAD | ||||||
| N | 22,832 | 4898 | 3683 | 4866 | 4694 | 4691 |
| R2 | 0.75 | 0.48 | 0.19 | 0.22 | 0.00 | 0.20 |
| Bias | −6.04 | −5.89 | −6.67 | −9.02 | −1.84 | −6.80 |
| MAE | 6.34 | 5.89 | 7.03 | 9.03 | 2.40 | 7.40 |
| LFCH | ||||||
| N | 22,832 | 4898 | 3683 | 4866 | 4694 | 4691 |
| R2 | 0.55 | 0.08 | 0.16 | 0.06 | 0.02 | 0.12 |
| Bias | −3.42 | −7.07 | −5.47 | −1.97 | 1.54 | −4.49 |
| MAE | 7.17 | 7.11 | 6.71 | 8.98 | 2.88 | 10.00 |
References
- McMahan, C.A.; Frye, R.G.; Brown, K.L. The Vegetation Types of Texas; Texas Parks and Wildlife Department: Austin, TX, USA, 1984.
- Elliott, L. Descriptions of systems, mapping subsystems, and vegetation types for texas. In Texas Parks and Wildlife Ecological Systems Classification and Mapping Project; Texas Parks and Wildlife Department: Austin, TX, USA, 2014. [Google Scholar]
- Malambo, L.; Popescu, S.; Liu, M. Landsat-scale regional forest canopy height mapping using icesat-2 along-track heights: Case study of eastern texas. Remote Sens. 2023, 15, 1. [Google Scholar] [CrossRef]
- Simard, M.; Pinto, N.; Fisher, J.B.; Baccini, A. Mapping forest canopy height globally with spaceborne lidar. J. Geophys. Res. Biogeosci. 2011, 116, G4. [Google Scholar] [CrossRef]
- Olariu, H.G.; Malambo, L.; Popescu, S.C.; Virgil, C.; Wilcox, B.P. Woody plant encroachment: Evaluating methodologies for semiarid woody species classification from drone images. Remote Sens. 2022, 14, 1665. [Google Scholar] [CrossRef]
- USGS EROS Center. Usgs Eros Archive—Aerial Photography—National Agriculture Imagery Program (NAIP). Available online: https://www.usgs.gov/centers/eros/science/usgs-eros-archive-aerial-photography-national-agriculture-imagery-program-naip?qt-science_center_objects=0#qt-science_center_objects (accessed on 21 January 2023).
- Potapov, P.; Li, X.; Hernandez-Serna, A.; Tyukavina, A.; Hansen, M.C.; Kommareddy, A.; Pickens, A.; Turubanova, S.; Tang, H.; Silva, C.E. Mapping global forest canopy height through integration of gedi and landsat data. Remote Sens. Environ. 2021, 253, 112165. [Google Scholar] [CrossRef]
- Liu, X.; Su, Y.; Hu, T.; Yang, Q.; Liu, B.; Deng, Y.; Tang, H.; Tang, Z.; Fang, J.; Guo, Q. Neural network guided interpolation for mapping canopy height of china’s forests by integrating gedi and icesat-2 data. Remote Sens. Environ. 2022, 269, 112844. [Google Scholar] [CrossRef]
- Hudak, A.T.; Lefsky, M.A.; Cohen, W.B.; Berterretche, M. Integration of lidar and landsat etm+ data for estimating and mapping forest canopy height. Remote Sens. Environ. 2002, 82, 397–416. [Google Scholar] [CrossRef]
- Xiao, R.; Carande, R.; Ghiglia, D. A neural network approach for tree height estimation using ifsar data. In IGARSS’98. Sensing and Managing the Environment. 1998 IEEE International Geoscience and Remote Sensing. Symposium Proceedings, Seattle, WA, USA, 6–10 July 1998; (Cat. No. 98CH36174); IEEE: Piscataway, NJ, USA, 1998; pp. 1565–1567. [Google Scholar]
- Lang, N.; Kalischek, N.; Armston, J.; Schindler, K.; Dubayah, R.; Wegner, J.D. Global canopy height regression and uncertainty estimation from gedi lidar waveforms with deep ensembles. Remote Sens. Environ. 2022, 268, 112760. [Google Scholar] [CrossRef]
- Lang, N.; Schindler, K.; Wegner, J.D. Country-wide high-resolution vegetation height mapping with sentinel-2. Remote Sens. Environ. 2019, 233, 111347. [Google Scholar] [CrossRef]
- Illarionova, S.; Shadrin, D.; Ignatiev, V.; Shayakhmetov, S.; Trekin, A.; Oseledets, I. Estimation of the canopy height model from multispectral satellite imagery with convolutional neural networks. IEEE Access 2022, 10, 34116–34132. [Google Scholar] [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Salehi, B.; Rezaee, M.; Mohammadimanesh, F.; Zhang, Y. Very deep convolutional neural networks for complex land cover mapping using multispectral remote sensing imagery. Remote Sens. 2018, 10, 1119. [Google Scholar] [CrossRef]
- Al-Najjar, H.A.; Kalantar, B.; Pradhan, B.; Saeidi, V.; Halin, A.A.; Ueda, N.; Mansor, S. Land cover classification from fused dsm and uav images using convolutional neural networks. Remote Sens. 2019, 11, 1461. [Google Scholar] [CrossRef]
- Malambo, L.; Popescu, S.; Ku, N.-W.; Rooney, W.; Zhou, T.; Moore, S. A deep learning semantic segmentation-based approach for field-level sorghum panicle counting. Remote Sens. 2019, 11, 2939. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Lu, H.; She, Y.; Tie, J.; Xu, S. Half-unet: A simplified u-net architecture for medical image segmentation. Front. Neuroinform. 2022, 16, 911679. [Google Scholar] [CrossRef] [PubMed]
- Fan, Y.; Ding, X.; Wu, J.; Ge, J.; Li, Y. High spatial-resolution classification of urban surfaces using a deep learning method. Build. Environ. 2021, 200, 107949. [Google Scholar] [CrossRef]
- Engle, D. Oak Ecology. Available online: https://texnat.tamu.edu/library/symposia/brush-sculptors-innovations-for-tailoring-brushy-rangelands-to-enhance-wildlife-habitat-and-recreational-value/oak-ecology/ (accessed on 12 December 2021).
- Tolleson, D.R.; Rhodes, E.C.; Malambo, L.; Angerer, J.P.; Redden, R.R.; Treadwell, M.L.; Popescu, S.C. Old school and high tech: A comparison of methods to quantify ashe juniper biomass as fuel or forage. Rangelands 2019, 41, 159–168. [Google Scholar] [CrossRef]
- Krishnan, S.; Crosby, C.; Nandigam, V.; Phan, M.; Cowart, C.; Baru, C.; Arrowsmith, R. Opentopography: A services oriented architecture for community access to lidar topography. In Proceedings of the 2nd International Conference on Computing for Geospatial Research & Applications, Washington, DC, USA, 23–25 May 2011; pp. 1–8. [Google Scholar]
- Dinerstein, E.; Olson, D.; Joshi, A.; Vynne, C.; Burgess, N.D.; Wikramanayake, E.; Hahn, N.; Palminteri, S.; Hedao, P.; Noss, R.; et al. An ecoregion-based approach to protecting half the terrestrial realm. Bioscience 2017, 67, 534–545. [Google Scholar] [CrossRef]
- Rollins, M.G. Landfire: A nationally consistent vegetation, wildland fire, and fuel assessment. Int. J. Wildland Fire 2009, 18, 235–249. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Malambo, L.; Popescu, S.C. Assessing the agreement of icesat-2 terrain and canopy height with airborne lidar over us ecozones. Remote Sens. Environ. 2021, 266, 112711. [Google Scholar] [CrossRef]
- Schimel, D.; Pavlick, R.; Fisher, J.B.; Asner, G.P.; Saatchi, S.; Townsend, P.; Miller, C.; Frankenberg, C.; Hibbard, K.; Cox, P. Observing terrestrial ecosystems and the carbon cycle from space. Glob. Chang. Biol. 2015, 21, 1762–1776. [Google Scholar] [CrossRef] [PubMed]
- Hansen, M.C.; Potapov, P.V.; Goetz, S.J.; Turubanova, S.; Tyukavina, A.; Krylov, A.; Kommareddy, A.; Egorov, A. Mapping tree height distributions in sub-saharan africa using landsat 7 and 8 data. Remote Sens. Environ. 2016, 185, 221–232. [Google Scholar] [CrossRef]
- Borders, B.E.; Bailey, R.L. Loblolly pine—Pushing the limits of growth. South. J. Appl. For. 2001, 25, 69–74. [Google Scholar] [CrossRef]


| Model Parameters | Validation Set | Independent Test Set | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Training Time (h:min:s) | Image Resolution | Encoder Depth | N Patches | R2 | Bias (m) | MAE (m) | N Patches | R2 | Bias (m) | MAE (m) |
| 46:47:49 | 1 m | 2 | 400 | 0.70 | −0.03 | 2.21 | 500 | 0.82 | −0.13 | 2.57 |
| 60:18:24 | 1 m | 3 | 400 | 0.75 | −0.04 | 2.00 | 500 | 0.82 | −0.28 | 2.49 |
| 77:55:24 | 1 m | 4 | 400 | 0.74 | 0.04 | 2.01 | 500 | 0.82 | −0.10 | 2.49 |
| 50:01:24 | 2 m | 2 | 400 | 0.85 | 0.06 | 1.60 | 500 | 0.88 | −0.46 | 2.18 |
| 77:32:56 | 2 m | 3 | 400 | 0.88 | −0.01 | 1.40 | 500 | 0.90 | −0.28 | 1.87 |
| 98:01:12 | 2 m | 4 | 400 | 0.89 | 0.01 | 1.34 | 500 | 0.90 | 0.12 | 1.78 |
| Pixel Size × Encoder Depth Parameter Combination | |||||||
|---|---|---|---|---|---|---|---|
| Biome | Metric | 1 m × 2 | 1 m × 3 | 1 m × 4 | 2 m × 2 | 2 m × 3 | 2 m × 4 |
| DXS | R2 | 0.65 | 0.69 | 0.69 | 0.81 | 0.83 | 0.84 |
| Bias (m) | 0.13 | −0.14 | 0.05 | 0.22 | −0.07 | 0.01 | |
| MAE (m) | 1.26 | 1.18 | 1.18 | 0.83 | 0.75 | 0.73 | |
| TBMF | R2 | 0.46 | 0.54 | 0.55 | 0.69 | 0.74 | 0.74 |
| Bias (m) | −0.10 | −0.20 | 0.21 | −0.13 | −0.02 | −0.12 | |
| MAE (m) | 3.43 | 3.08 | 3.00 | 2.56 | 2.29 | 2.32 | |
| TCF | R2 | 0.44 | 0.42 | 0.41 | 0.64 | 0.68 | 0.69 |
| Bias (m) | −0.68 | −0.35 | −0.26 | −2.50 | −0.97 | 0.49 | |
| MAE (m) | 4.41 | 4.37 | 4.39 | 4.27 | 3.43 | 3.12 | |
| TGSS | R2 | 0.68 | 0.61 | 0.66 | 0.67 | 0.69 | 0.75 |
| Bias (m) | 0.10 | 0.08 | −0.12 | 0.08 | 0.32 | 0.08 | |
| MAE (m) | 0.80 | 0.84 | 0.78 | 0.77 | 0.76 | 0.62 | |
| TSGSS | R2 | 0.28 | 0.58 | 0.57 | 0.57 | 0.75 | 0.77 |
| Bias (m) | −2.40 | 0.05 | −0.58 | −0.50 | 0.22 | −0.26 | |
| MAE (m) | 4.70 | 3.12 | 3.17 | 3.19 | 2.51 | 2.39 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Malambo, L.; Popescu, S. Image to Image Deep Learning for Enhanced Vegetation Height Modeling in Texas. Remote Sens. 2023, 15, 5391. https://doi.org/10.3390/rs15225391
Malambo L, Popescu S. Image to Image Deep Learning for Enhanced Vegetation Height Modeling in Texas. Remote Sensing. 2023; 15(22):5391. https://doi.org/10.3390/rs15225391
Chicago/Turabian StyleMalambo, Lonesome, and Sorin Popescu. 2023. "Image to Image Deep Learning for Enhanced Vegetation Height Modeling in Texas" Remote Sensing 15, no. 22: 5391. https://doi.org/10.3390/rs15225391
APA StyleMalambo, L., & Popescu, S. (2023). Image to Image Deep Learning for Enhanced Vegetation Height Modeling in Texas. Remote Sensing, 15(22), 5391. https://doi.org/10.3390/rs15225391