
A Semantics-Guided Visual Simultaneous Localization and Mapping with U-Net for Complex Dynamic Indoor Environments


 ,
,
Abstract
:1. Introduction
- (1)
- Built upon the original ORB-SLAM2 framework, we have developed a dynamic object-aware visual SLAM algorithm specifically designed for highly dynamic indoor environments. Our algorithm integrates a semantic segmentation network into ORB-SLAM2, effectively enhancing the accuracy and robustness of the system.
- (2)
- Considering the semantic characteristics of dynamic objects, we have implemented a semantic segmentation algorithm using U-Net to achieve pixel-wise segmentation of potentially movable objects. Consequently, the effect of moving objects on camera pose estimation is alleviated by filtering out the feature points from dynamic objects.
- (3)
- Quantitative and qualitative experiments were conducted to validate the effectiveness and robustness of the proposed method. The experiments were carried out using the TUM public dataset as well as a real scenario dataset captured from Kinect 2.0.
2. Related Works
3. Methodology
3.1. System Overview
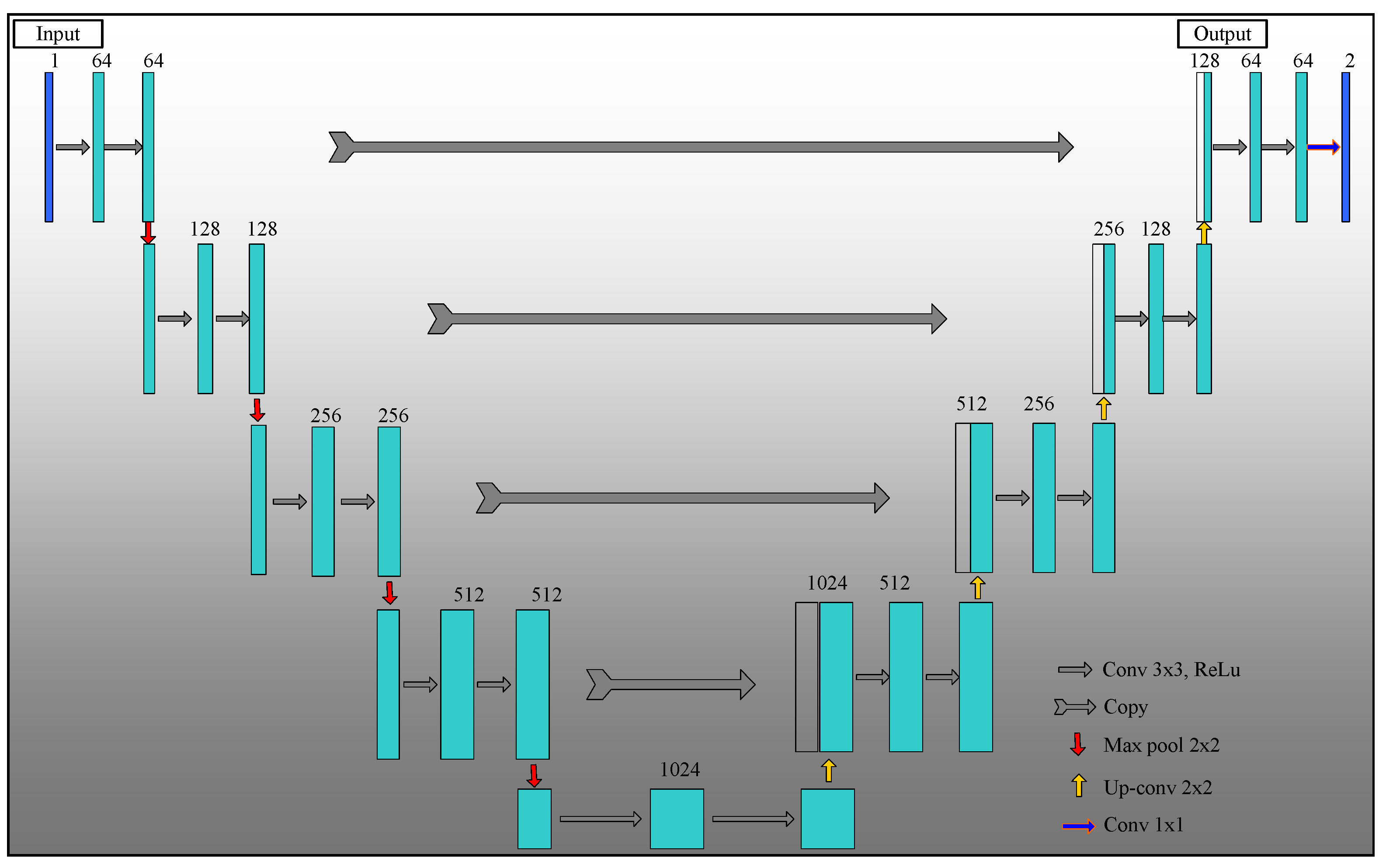
3.2. Semantic Segmentation Module
3.3. Tracking and Mapping
4. Experimentation and Analysis
4.1. Experimental Dataset
4.2. Experimental Details
4.3. Semantic Segmentation Results
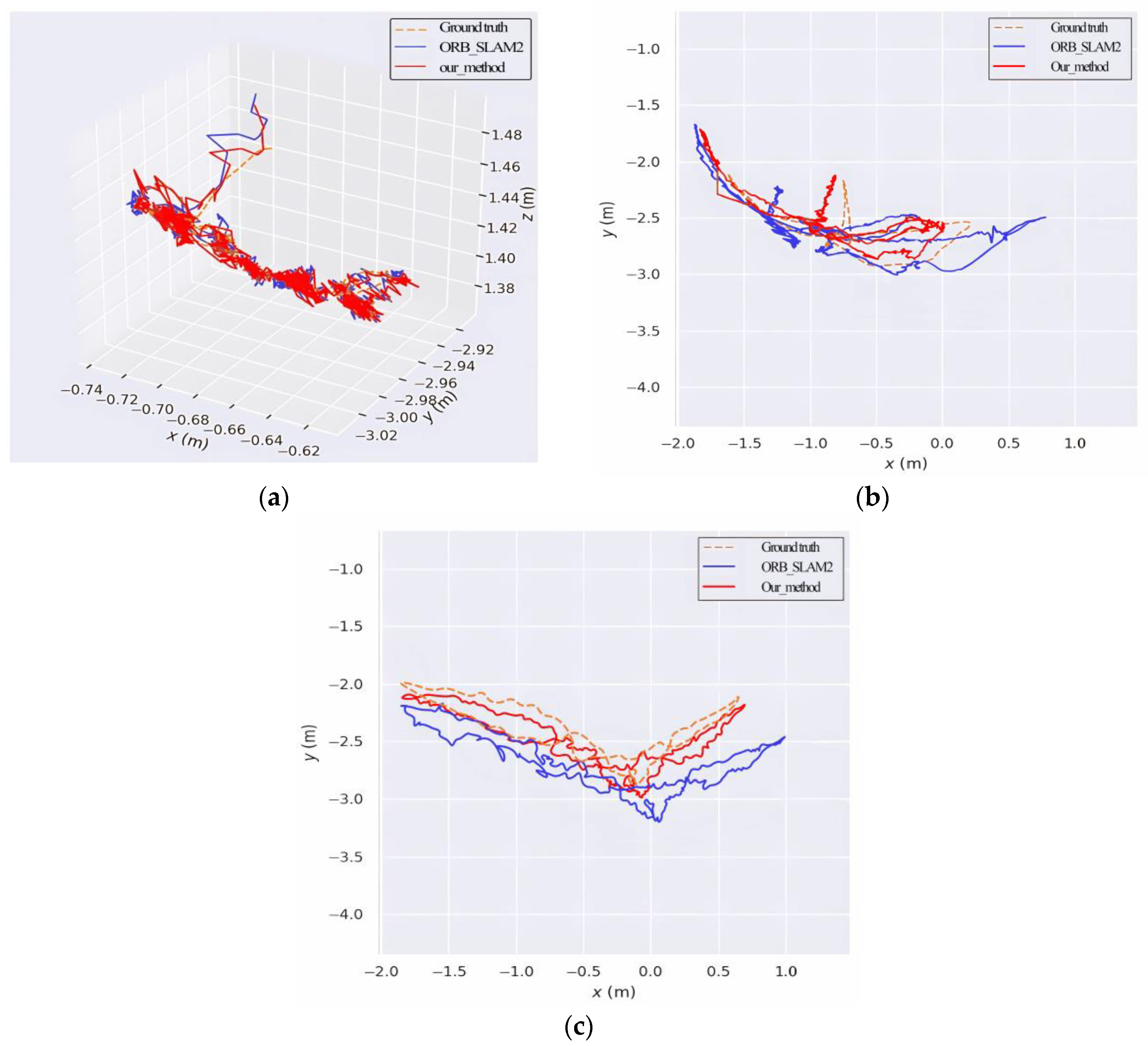
4.4. TUM Public Datasets
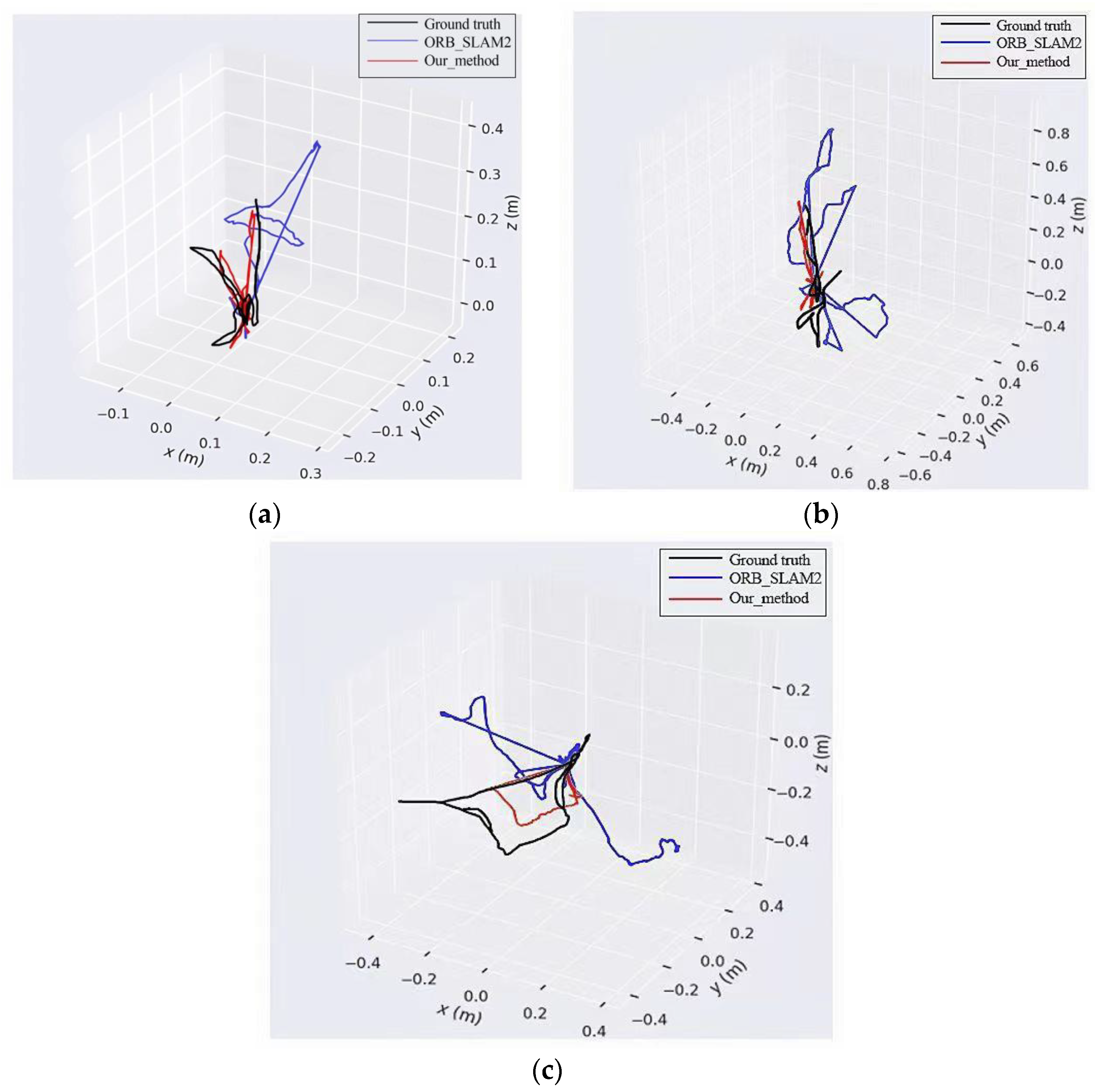
4.5. Real Scenario Datasets
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SLAM | simultaneous localization and mapping |
| TUM | Technical University of Munich |
| GNSS | global navigation satellite system |
| LiDAR | light detection and ranging |
| RGB-D | red green blue-deeply |
| IMU | inertial measuring unit |
| ORB-SLAM2 | oriented FAST and rotated BRIEF SLAM II |
| LSD SLAM | large-scale direct SLAM |
| DSO | direct sparse odometry |
| SLAMMOT | simultaneous localization, mapping, and moving object tracking |
| MonoSLAM | monocular SLAM |
| DATMO | detection and tracking of moving objects |
| MHT | multi-hypothesis tracking |
| IMM | interactive multiple model |
| EKF | extended Kalman filter |
| DynaSLAM | dynamic SLAM |
| DS-SLAM | a semantic visual SLAM toward dynamic environments |
| BA | bundle adjustment |
| AG | attention gate |
| CNNs | convolutional neural networks |
| ReLU | rectified linear unit |
| PASCAL | pattern analysis statistical modeling and computational learning |
| VOCs | visual object classes |
| PTAM | parallel tracking and mapping |
| IOU | intersection over union |
| RMSE | root-mean-square error |
| ATE | absolute trajectory error |
| RAE | relative attitude error |
| SD | standard deviation |
| DNNs | deep neural networks |
References
- Macario Barros, A.; Michel, M.; Moline, Y.; Corre, G.; Carrel, F. A Comprehensive Survey of Visual SLAM Algorithms. Robotics 2022, 11, 24. [Google Scholar] [CrossRef]
- Ni, J.; Gong, T.; Gu, Y.; Zhu, J.; Fan, X. An improved deep residual network-based semantic simultaneous localization and mapping method for monocular vision robot. Comput. Intell. Neurosci. 2020, 2020, 7490840. [Google Scholar] [CrossRef]
- Qin, T.; Chen, T.; Chen, Y.; Su, Q. Avp-slam: Semantic visual mapping and localization for autonomous vehicles in the parking lot. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 5939–5945. [Google Scholar]
- Chaplot, D.S.; Salakhutdinov, R.; Gupta, A.; Gupta, S. Neural topological slam for visual navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognitio, Washington, DC, USA, 16–20 June 2020; pp. 12875–12884. [Google Scholar]
- Chen, J.; Li, Q.; Hu, S.; Chen, Y.; Hiu, S.; Chen, Y.; Li, J. Global Visual And Semantic Observations for Outdoor Robot Localization. In Proceedings of the 2020 5th International Conference on Advanced Robotics and Mechatronics (ICARM), Shenzhen, China, 18–21 December 2020; pp. 419–424. [Google Scholar] [CrossRef]
- Li, B.; Zou, D.; Sartori, D.; Ling, P.; Yu, W. TextSLAM: Visual SLAM with Planar Text Features. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 2102–2108. [Google Scholar]
- Muthu, S.; Tennakoon, R.; Rathnayake, T.; Hoseinnezhad, R.; Suter, D.; Bab-Hadiashar, A. Motion segmentation of rgb-d sequences: Combining semantic and motion information using statistical inference. IEEE Trans. Image Process. 2020, 29, 5557–5570. [Google Scholar] [CrossRef] [PubMed]
- Xie, W.; Liu, P.X.; Zheng, M. Moving object segmentation and detection for robust RGBD-SLAM in dynamic environments. IEEE Trans. Instrum. Meas. 2020, 70, 1–8. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Mur-Artal, R.; Tardos, J.D. Visual-Inertial Monocular SLAM With Map Reuse. IEEE Robot. Autom. Lett. 2017, 2, 796–803. [Google Scholar] [CrossRef]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-Scale Direct Monocular SLAM; Springer International Publishing: Cham, Switzerland, 2014; pp. 834–849. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct sparse odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 611–625. [Google Scholar] [CrossRef]
- Shakhnoza, M.; Sabina, U.; Sevara, M.; Cho, Y.-I. Novel Video Surveillance-Based Fire and Smoke Classification Using Attentional Feature Map in Capsule Networks. Sensors 2022, 22, 98. [Google Scholar] [CrossRef] [PubMed]
- Bowman, S.L.; Atanasov, N.; Daniilidis, K.; Pappas, G.J. Probabilistic data association for semantic slam. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1722–1729. [Google Scholar]
- Aslan, M.F.; Durdu, A.; Yusefi, A.; Sabanci, K.; Sungur, C. A Tutorial: Mobile Robotics, SLAM, Bayesian Filter, Keyframe Bundle Adjustment and ROS Applications. In Robot Operating System (ROS); Koubaa, A., Ed.; Studies in Computational Intelligence; Springer: Cham, Switzerland, 2021; Volume 962. [Google Scholar] [CrossRef]
- Saputra, M.R.U.; Markham, A.; Trigoni, N. Visual SLAM and structure from motion in dynamic environments: A survey. ACM Comput. Surv. 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Wang, C.C.; Thorpe, C.; Thrun, S.; Hebert, M.; Durrant-Whyte, H. Simultaneous localization, mapping and moving object tracking. Int. J. Rob. Res. 2007, 26, 889–916. [Google Scholar] [CrossRef]
- Migliore, D.; Rigamonti, R.; Marzorati, D.; Matteucci, M.; Sorrenti, D.G. Use a single camera for simultaneous localization and mapping with mobile object tracking in dynamic environments. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009. [Google Scholar]
- Lin, K.-H.; Wang, C.-C. Stereo-based simultaneous localization, mapping and moving object tracking. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 3975–3980. [Google Scholar]
- Vu, T.-D.; Burlet, J.; Aycard, O. Grid-based localization and local mapping with moving object detection and tracking. Inf. Fusion 2011, 12, 58–69. [Google Scholar] [CrossRef]
- Azim, A.; Aycard, O. Layer-based supervised classification of moving objects in outdoor dynamic environment using 3D laser scanner. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium Proceedings, Dearborn, MI, USA, 8–11 June 2014; pp. 1408–1414. [Google Scholar]
- Chang, C.-H.; Wang, S.-C.; Wang, C.-C. Exploiting Moving Objects: Multi-Robot Simultaneous Localization and Tracking. IEEE Trans. Autom. Sci. Eng. 2016, 13, 810–827. [Google Scholar] [CrossRef]
- Bescos, B.; Fácil, J.M.; Civera, J.; Neira, J. DynaSLAM: Tracking, mapping, and inpainting in dynamic scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef]
- Yu, C.; Liu, Z.; Liu, X.J.; Xie, F.; Yang, Y.; Wei, Q.; Fei, Q. DS-SLAM: A semantic visual SLAM towards dynamic environments. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1168–1174. [Google Scholar]
- Civera, J.; Gálvez-López, D.; Riazuelo, L.; Tardós, J.D.; Montiel, J.M.M. Towards semantic SLAM using a monocular camera. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 1277–1284. [Google Scholar]
- Zhi, S.; Bloesch, M.; Leutenegger, S.; Davison, A.J. SceneCode: Monocular Dense Semantic Reconstruction using Learned Encoded Scene Representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11776–11785. [Google Scholar] [CrossRef]
- Chang, J.; Dong, N.; Li, D. A Real-Time Dynamic Object Segmentation Framework for SLAM System in Dynamic Scenes. IEEE Trans. Instrum. Meas. 2021, 70, 1–9. [Google Scholar] [CrossRef]
- Cheng, J.; Wang, Z.; Zhou, H.; Li, L.; Yao, J. DM-SLAM: A Feature-Based SLAM System for Rigid Dynamic Scenes. Isprs Int. J. Geo-Inf. 2020, 9, 202. [Google Scholar] [CrossRef]
- Csurka, G.; Perronnin, F. An efficient approach to semantic segmentation. Int. J. Comput. Vis. 2011, 95, 198–212. [Google Scholar] [CrossRef]
- Ji, T.; Wang, C.; Xie, L. Towards Real-time Semantic RGB-D SLAM in Dynamic Environments. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 11175–11181. [Google Scholar] [CrossRef]
- Ran, T.; Yuan, L.; Zhang, J.; Tang, D.; He, L. RS-SLAM: A Robust Semantic SLAM in Dynamic Environments Based on RGB-D Sensor. IEEE Sens. J. 2021, 21, 20657–20664. [Google Scholar] [CrossRef]
- Bescos, B.; Campos, C.; Tardos, J.D.; Neira, J. DynaSLAM II: Tightly-Coupled Multi-Object Tracking and SLAM. IEEE Robot. Autom. Lett. 2021, 6, 5191–5198. [Google Scholar] [CrossRef]
- Yuan, X.; Chen, S. SaD-SLAM: A Visual SLAM Based on Semantic and Depth Information. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 4930–4935. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, Y.; Zhu, D.; Feng, Y.; Coleman, S.; Kerr, D. EAO-SLAM: Monocular Semi-Dense Object SLAM Based on Ensemble Data Association. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 4966–4973. [Google Scholar] [CrossRef]
- Lin, X.; Yang, Y.; He, L.; Chen, W.; Guan, Y.; Zhang, H. Robust Improvement in 3D Object Landmark Inference for Semantic Mapping. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 13011–13017. [Google Scholar]
- Zhang, J.; Yuan, L.; Ran, T.; Tao, Q.; He, L. Bayesian nonparametric object association for semantic SLAM. IEEE Robot. Autom. Lett. 2021, 6, 5493–5500. [Google Scholar]
- Qian, Z.; Patath, K.; Fu, J.; Xiao, J. Semantic slam with autonomous object-level data association. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 11203–11209. [Google Scholar]
- Muksimova, S.; Mardieva, S.; Cho, Y.-I. Deep Encoder–Decoder Network-Based Wildfire Segmentation Using Drone Images in Real-Time. Remote Sens. 2022, 14, 6302. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. arXiv 2021, arXiv:2104.00298. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems. Adv. Neural Inf. Process. 2019, 32, 8024–8035. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. Medical Image Computing and Computer-Assisted Intervention—MICCAI. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; Volume 9351. [Google Scholar] [CrossRef]
- Klein, G.; Murray, D. Parallel tracking and mapping for small AR workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; pp. 225–234. [Google Scholar]
- Yang, J.; Kang, Z.; Yang, Z.; Xie, J.; Xue, B.; Yang, J.; Tao, J. Automatic Laboratory Martian Rock and Mineral Classification Using Highly-Discriminative Representation Derived from Spectral Signatures. Remote Sens. 2022, 14, 5070. [Google Scholar] [CrossRef]
- Rünz, M.; Agapito, L. Co-fusion: Real-time segmentation, tracking and fusion of multiple objects. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4471–4478. [Google Scholar]
- Jaimez, M.; Kerl, C.; Gonzalez-Jimenez, J.; Cremers, D. Fast odometry and scene flow from RGB-D cameras based on geometric clustering. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3992–3999. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Class IoU | Class Accuracy |
|---|---|---|
| Pedestrian | 83.02% | 90.73% |
| Chair | 33.85% | 45.01% |
| Table | 60.09% | 65.66% |
| TV | 70.59% | 80.06% |
| Background | 93.51% | 96.53% |
| Average | 75.11% | 86.46% |
| Overall accuracy | 94.17% | |
| Sequence | System | Absolute Trajectory Error (In Meters) | ||||||
|---|---|---|---|---|---|---|---|---|
| RMSE | S.D. | MAX | MIN | MEAN | MEDIAN | |||
| Low-dynamic scene | Sitting static | ORB SLAM2 | 0.0242 | 0.0129 | 0.0962 | 0.0020 | 0.0205 | 0.0183 |
| Our system | 0.0226 | 0.0118 | 0.0850 | 0.0017 | 0.0193 | 0.0172 | ||
| Improvement | 6.61% | 8.53% | 11.64% | 15.00% | 5.85% | 6.01% | ||
| Sitting half | ORB SLAM2 | 0.0084 | 0.0039 | 0.0355 | 0.0003 | 0.0075 | 0.0068 | |
| Our system | 0.0077 | 0.0038 | 0.0275 | 0.0010 | 0.0067 | 0.0060 | ||
| Improvement | 8.33% | 2.56% | 22.54% | −233.33% | 10.67% | 11.76% | ||
| High-dynamic scene | Walking half | ORB SLAM2 | 0.4175 | 0.2160 | 1.4238 | 0.0257 | 0.3573 | 0.2957 |
| Our system | 0.3838 | 0.1324 | 0.7351 | 0.0779 | 0.3602 | 0.3488 | ||
| Improvement | 8.07% | 38.70% | 48.37% | −203.11% | −0.81% | −17.96% | ||
| Walking rpy | ORB SLAM2 | 1.0034 | 0.5387 | 2.1407 | 0.0351 | 0.8466 | 0.8244 | |
| Our system | 0.5539 | 0.1819 | 1.0368 | 0.0529 | 0.5231 | 0.5225 | ||
| Improvement | 44.80% | 66.23% | 51.57% | −50.71% | 38.21% | 36.62% | ||
| Walking static | ORB SLAM2 | 0.4201 | 0.1710 | 0.6821 | 0.0603 | 0.3838 | 0.3388 | |
| Our system | 0.3292 | 0.0999 | 0.5657 | 0.0475 | 0.3136 | 0.2861 | ||
| Improvement | 21.64% | 41.58% | 17.06% | 21.23% | 18.29% | 15.55% | ||
| Sequence | RMSE (In Meters) | ||||
|---|---|---|---|---|---|
| ORB SLAM2 | VO-SF | Co-Fusion | Our System | ||
| Low-dynamic scene | Sitting static | 0.0242 | 0.0290 | 0.0110 | 0.0226 |
| Sitting half | 0.0084 | 0.1800 | 0.0360 | 0.0077 | |
| High-dynamic scene | Walking half | 0.4175 | 0.7390 | 0.8030 | 0.3838 |
| Walking rpy | 1.0034 | 0.8740 | 0.6960 | 0.5539 | |
| Walking static | 0.4201 | 0.3270 | 0.5510 | 0.3292 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, Z.; Lin, H.; Kang, Z.; Xie, X.; Yang, J.; Li, C.; Zhu, L. A Semantics-Guided Visual Simultaneous Localization and Mapping with U-Net for Complex Dynamic Indoor Environments. Remote Sens. 2023, 15, 5479. https://doi.org/10.3390/rs15235479
Zeng Z, Lin H, Kang Z, Xie X, Yang J, Li C, Zhu L. A Semantics-Guided Visual Simultaneous Localization and Mapping with U-Net for Complex Dynamic Indoor Environments. Remote Sensing. 2023; 15(23):5479. https://doi.org/10.3390/rs15235479
Chicago/Turabian StyleZeng, Zhi, Hui Lin, Zhizhong Kang, Xiaokui Xie, Juntao Yang, Chuyu Li, and Longze Zhu. 2023. "A Semantics-Guided Visual Simultaneous Localization and Mapping with U-Net for Complex Dynamic Indoor Environments" Remote Sensing 15, no. 23: 5479. https://doi.org/10.3390/rs15235479
APA StyleZeng, Z., Lin, H., Kang, Z., Xie, X., Yang, J., Li, C., & Zhu, L. (2023). A Semantics-Guided Visual Simultaneous Localization and Mapping with U-Net for Complex Dynamic Indoor Environments. Remote Sensing, 15(23), 5479. https://doi.org/10.3390/rs15235479