
Exploring Self-Supervised Learning for Multi-Modal Remote Sensing Pre-Training via Asymmetric Attention Fusion


Abstract
:1. Introduction
2. Related Work
2.1. Self-Supervised Learning
2.2. Multi-Modal Learning
3. Methodology
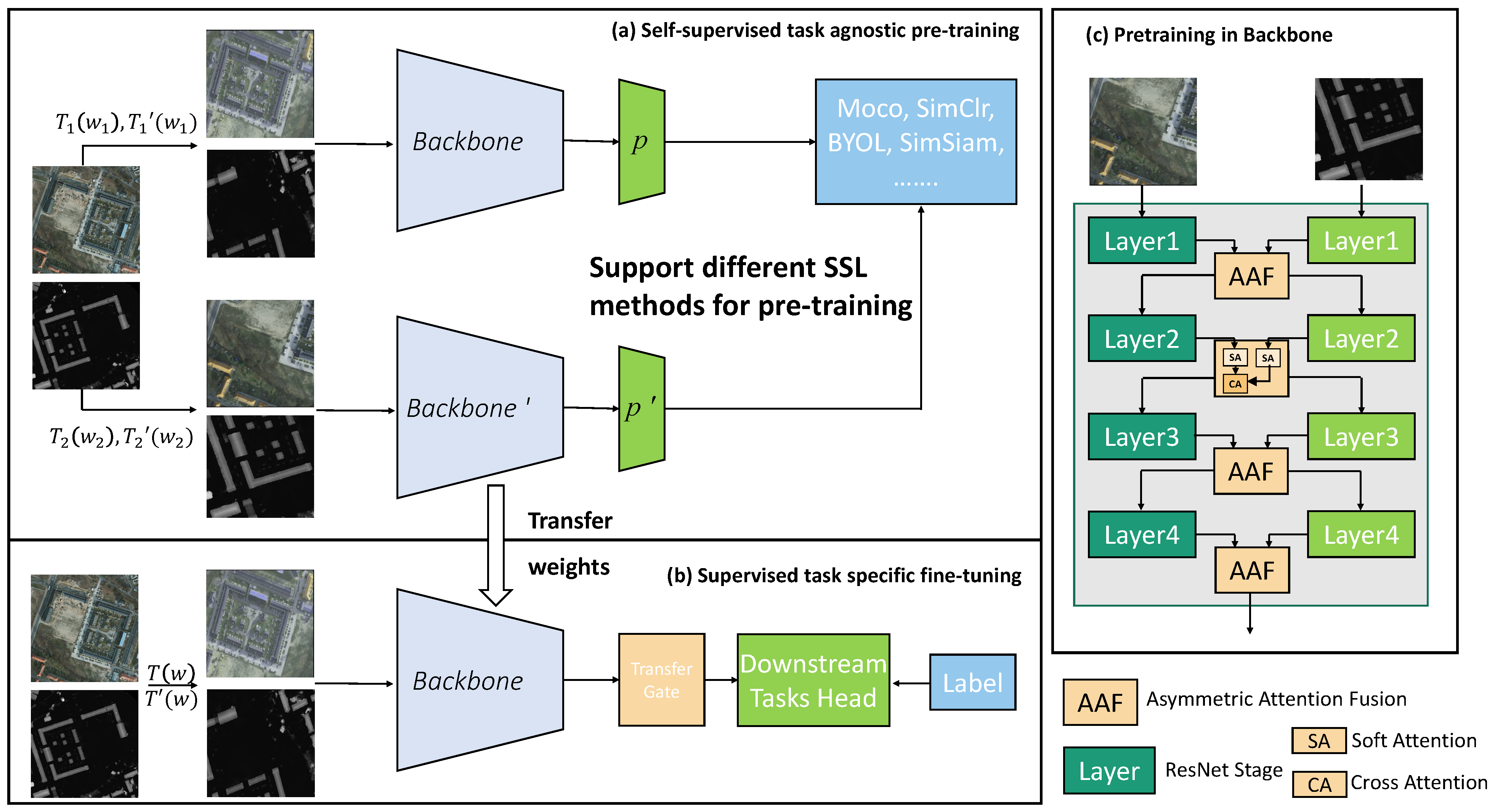
3.1. View Generation
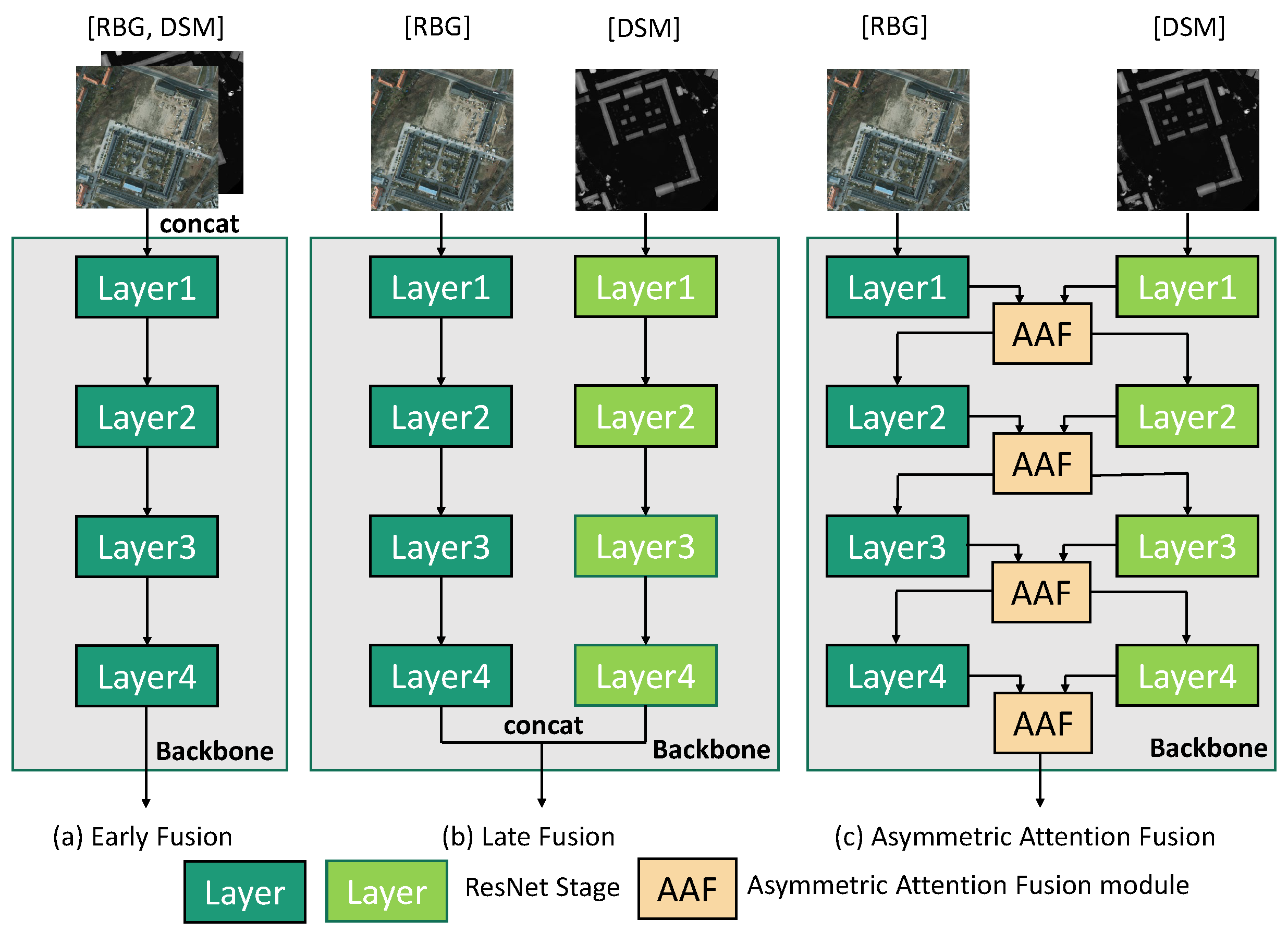
3.2. Backbone for Multi-Modal Fusion
3.3. Transfer Gate Module
3.4. Loss Function
4. Experimental Results
4.1. Datasets Description
4.2. Evaluation Metrics
4.3. Experimental Settings
4.4. Main Results
4.5. Ablation Studies
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wellmann, T.; Lausch, A.; Andersson, E.; Knapp, S.; Cortinovis, C.; Jache, J.; Scheuer, S.; Kremer, P.; Mascarenhas, A.; Kraemer, R.; et al. Remote sensing in urban planning: Contributions towards ecologically sound policies? Landsc. Urban Plan. 2020, 204, 103921. [Google Scholar] [CrossRef]
- Lehmann, E.A.; Caccetta, P.; Lowell, K.; Mitchell, A.; Zhou, Z.S.; Held, A.; Milne, T.; Tapley, I. SAR and optical remote sensing: Assessment of complementarity and interoperability in the context of a large-scale operational forest monitoring system. Remote Sens. Environ. 2015, 156, 335–348. [Google Scholar] [CrossRef]
- Huang, Y.; Chen, Z.X.; Tao, Y.; Huang, X.Z.; Gu, X.F. Agricultural remote sensing big data: Management and applications. J. Integr. Agric. 2018, 17, 1915–1931. [Google Scholar] [CrossRef]
- Schumann, G.J.; Brakenridge, G.R.; Kettner, A.J.; Kashif, R.; Niebuhr, E. Assisting flood disaster response with earth observation data and products: A critical assessment. Remote Sens. 2018, 10, 1230. [Google Scholar] [CrossRef]
- Rolnick, D.; Donti, P.L.; Kaack, L.H.; Kochanski, K.; Lacoste, A.; Sankaran, K.; Ross, A.S.; Milojevic-Dupont, N.; Jaques, N.; Waldman-Brown, A.; et al. Tackling climate change with machine learning. ACM Comput. Surv. (CSUR) 2022, 55, 1–96. [Google Scholar] [CrossRef]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised learning of visual features by contrasting cluster assignments. Adv. Neural Inf. Process. Syst. 2020, 33, 9912–9924. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap your own latent-a new approach to self-supervised learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Chen, X.; He, K. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 15750–15758. [Google Scholar]
- Manas, O.; Lacoste, A.; Giró-i Nieto, X.; Vazquez, D.; Rodriguez, P. Seasonal contrast: Unsupervised pre-training from uncurated remote sensing data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9414–9423. [Google Scholar]
- Ayush, K.; Uzkent, B.; Meng, C.; Tanmay, K.; Burke, M.; Lobell, D.; Ermon, S. Geography-aware self-supervised learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10181–10190. [Google Scholar]
- Li, W.; Chen, K.; Chen, H.; Shi, Z. Geographical knowledge-driven representation learning for remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef]
- Jiang, X.; Li, G.; Liu, Y.; Zhang, X.P.; He, Y. Change detection in heterogeneous optical and SAR remote sensing images via deep homogeneous feature fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1551–1566. [Google Scholar] [CrossRef]
- Bermudez, J.; Happ, P.; Oliveira, D.; Feitosa, R. Sar to Optical Image Synthesis for Cloud Removal with Generative Adversarial Networks. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 4, 5–11. [Google Scholar] [CrossRef]
- Gbodjo, Y.J.E.; Montet, O.; Ienco, D.; Gaetano, R.; Dupuy, S. Multisensor land cover classification with sparsely annotated data based on convolutional neural networks and self-distillation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 11485–11499. [Google Scholar] [CrossRef]
- Ienco, D.; Interdonato, R.; Gaetano, R.; Minh, D.H.T. Combining Sentinel-1 and Sentinel-2 Satellite Image Time Series for land cover mapping via a multi-source deep learning architecture. ISPRS J. Photogramm. Remote Sens. 2019, 158, 11–22. [Google Scholar] [CrossRef]
- Chen, Y.; Bruzzone, L. Self-supervised SAR-optical Data Fusion and Land-cover Mapping using Sentinel-1/-2 Images. arXiv 2021, arXiv:2103.05543. [Google Scholar]
- Wang, M.; Gao, F.; Dong, J.; Li, H.C.; Du, Q. Nearest Neighbor-Based Contrastive Learning for Hyperspectral and LiDAR Data Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Lin, J.; Gao, F.; Shi, X.; Dong, J.; Du, Q. SS-MAE: Spatial-Spectral Masked Auto-Encoder for Multi-Source Remote Sensing Image Classification. arXiv 2023, arXiv:2311.04442. [Google Scholar]
- Scheibenreif, L.; Hanna, J.; Mommert, M.; Borth, D. Self-supervised vision transformers for land-cover segmentation and classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1422–1431. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful image colorization. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part III 14. Springer: Amsterdam, The Netherlands, 2016; pp. 649–666. [Google Scholar]
- Doersch, C.; Gupta, A.; Efros, A.A. Unsupervised visual representation learning by context prediction. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1422–1430. [Google Scholar]
- Wang, X.; Gupta, A. Unsupervised learning of visual representations using videos. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2794–2802. [Google Scholar]
- Gidaris, S.; Singh, P.; Komodakis, N. Unsupervised representation learning by predicting image rotations. arXiv 2018, arXiv:1803.07728. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved baselines with momentum contrastive learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Chen, X.; Xie, S.; He, K. An empirical study of training self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9640–9649. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Bao, H.; Dong, L.; Piao, S.; Wei, F. Beit: Bert pre-training of image transformers. arXiv 2021, arXiv:2106.08254. [Google Scholar]
- Dong, X.; Bao, J.; Zhang, T.; Chen, D.; Zhang, W.; Yuan, L.; Chen, D.; Wen, F.; Yu, N. Peco: Perceptual codebook for bert pre-training of vision transformers. arXiv 2021, arXiv:2111.12710. [Google Scholar] [CrossRef]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9650–9660. [Google Scholar]
- Tao, C.; Qi, J.; Lu, W.; Wang, H.; Li, H. Remote sensing image scene classification with self-supervised paradigm under limited labeled samples. IEEE Geosci. Remote Sens. Lett. 2020, 19, 1–5. [Google Scholar] [CrossRef]
- Kang, J.; Fernandez-Beltran, R.; Duan, P.; Liu, S.; Plaza, A.J. Deep unsupervised embedding for remotely sensed images based on spatially augmented momentum contrast. IEEE Trans. Geosci. Remote Sens. 2020, 59, 2598–2610. [Google Scholar] [CrossRef]
- Chen, W.; Zheng, X.; Lu, X. Hyperspectral image super-resolution with self-supervised spectral-spatial residual network. Remote Sens. 2021, 13, 1260. [Google Scholar] [CrossRef]
- Li, K.; Qin, Y.; Ling, Q.; Wang, Y.; Lin, Z.; An, W. Self-supervised deep subspace clustering for hyperspectral images with adaptive self-expressive coefficient matrix initialization. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3215–3227. [Google Scholar] [CrossRef]
- Chen, L.; Jiang, X.; Li, Z.; Liu, X.; Zhou, Z. Feature-Enhanced Speckle Reduction via Low-Rank and Space-Angle Continuity for Circular SAR Target Recognition. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7734–7752. [Google Scholar] [CrossRef]
- Schmitt, M.; Zhu, X.X. Data fusion and remote sensing: An ever-growing relationship. IEEE Geosci. Remote Sens. Mag. 2016, 4, 6–23. [Google Scholar] [CrossRef]
- Ghamisi, P.; Rasti, B.; Yokoya, N.; Wang, Q.; Hofle, B.; Bruzzone, L.; Bovolo, F.; Chi, M.; Anders, K.; Gloaguen, R.; et al. Multisource and multitemporal data fusion in remote sensing: A comprehensive review of the state of the art. IEEE Geosci. Remote Sens. Mag. 2019, 7, 6–39. [Google Scholar] [CrossRef]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef]
- Hazirbas, C.; Ma, L.; Domokos, C.; Cremers, D. Fusenet: Incorporating depth into semantic segmentation via fusion-based cnn architecture. In Proceedings of the Computer Vision–ACCV 2016: 13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Revised Selected Papers, Part I 13. Springer: Amsterdam, The Netherlands, 2017; pp. 213–228. [Google Scholar]
- Ma, X.; Zhang, X.; Pun, M.O. A crossmodal multiscale fusion network for semantic segmentation of remote sensing data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 3463–3474. [Google Scholar] [CrossRef]
- Amarsaikhan, D.; Blotevogel, H.; Van Genderen, J.; Ganzorig, M.; Gantuya, R.; Nergui, B. Fusing high-resolution SAR and optical imagery for improved urban land cover study and classification. Int. J. Image Data Fusion 2010, 1, 83–97. [Google Scholar] [CrossRef]
- Geng, J.; Wang, H.; Fan, J.; Ma, X. Classification of fusing SAR and multispectral image via deep bimodal autoencoders. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 823–826. [Google Scholar]
- Wang, Y.; Albrecht, C.M.; Zhu, X.X. Self-supervised vision transformers for joint SAR-optical representation learning. In Proceedings of the IGARSS 2022–2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 139–142. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Contributors. MMSelfSup: Openmmlab Self-Supervised Learning Toolbox and Benchmark. 2021. Available online: https://github.com/open-mmlab/mmselfsup (accessed on 16 June 2020).
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Representative Methods | Description |
|---|---|---|
| Pre-text Tasks | colorization [23], patch orderings [24], tracking [25], rotation prediction [26] et al. | Tasks designed to learn by predicting some defined properties or transformations of the input data. |
| Augmentation-Invariance | MocoV1 [6], MocoV2 [27], MocoV3 [28], SimClr [7], BYOL [9], SwAV [8], SimSiam [10] et al. | Techniques that learn robust features by encouraging consistency between differently augmented views of the same image. |
| Masked Image Modeling (MIM) | MAE [29], Beit [30], Peco [31], DINO [32] et al. | Methods where parts of the input images are masked and the model is trained to predict the masked content. |
| SSL in RS | In-painting [33], SauMoCo [34], seasonal changes [11], geographical knowledge [12,13] et al. | SSL approaches adapted for RS, addressing the specific challenges and characteristics of RS imagery. |
| Dataset | Ground Resolution | Crop Size | SSL Training Set | SL Training Set | SL Testing Set |
|---|---|---|---|---|---|
| Potsdam | 0.05 m | 256 × 256 | 13,824 | 138 | 1500 |
| Random Baseline | SSL Pre-Trained | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RGB | DSM | EF | LF | AAF | RGB | DSM | EF | LF | AAF | |
| low vege. | 38.13 | 12.77 | 43.01 | 42.74 | 42.61 | 52.47 | 18.6 | 51.46 | 55.24 | 63.21 |
| trees | 57.74 | 43.22 | 67.11 | 64.31 | 65.83 | 68.75 | 44.34 | 62.24 | 69.81 | 72.44 |
| buildings | 23.59 | 20.64 | 31.07 | 36.07 | 34.18 | 35.97 | 36.36 | 49.48 | 51.62 | 52.23 |
| imperv. | 56.80 | 72.64 | 75.84 | 80.37 | 80.11 | 73.43 | 79.03 | 62.99 | 83.82 | 83.87 |
| cars | 14.17 | 0.10 | 15.63 | 16.42 | 14.22 | 10.56 | 3.16 | 21.96 | 26.65 | 29.46 |
| others | 35.60 | 13.00 | 26.45 | 30.51 | 42.20 | 42.43 | 13.67 | 52.81 | 57.18 | 56.59 |
| mIoU (%) | 37.67 | 27.06 | 43.19 | 45.07 | 46.52 | 47.11 | 32.53 | 50.16 | 57.39 | 59.63 |
| OA (%) | 59.76 | 55.84 | 66.16 | 67.59 | 70.26 | 69.39 | 59.34 | 71.04 | 78.29 | 79.08 |
| K (%) | 48.20 | 40.02 | 56.12 | 58.52 | 61.41 | 60.35 | 45.48 | 62.51 | 71.81 | 72.78 |
| Random Baseline | SSL Pre-Trained | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RGB | DSM | EF | LF | AAF | RGB | DSM | EF | LF | AAF | |
| low vege. | 67.75 | 66.71 | 67.63 | 67.30 | 68.35 | 75.36 | 66.38 | 75.82 | 76.97 | 79.54 |
| trees | 83.49 | 80.52 | 81.33 | 80.19 | 84.12 | 82.17 | 82.49 | 85.65 | 85.99 | 86.14 |
| buildings | 61.42 | 61.48 | 66.18 | 63.78 | 65.72 | 65.56 | 65.71 | 73.19 | 71.96 | 72.13 |
| imperv. | 74.84 | 62.27 | 72.94 | 69.93 | 71.32 | 78.26 | 76.67 | 81.49 | 79.44 | 85.65 |
| cars | 47.58 | 47.26 | 50.74 | 55.67 | 55.13 | 55.31 | 51.79 | 56.06 | 60.62 | 61.63 |
| others | 71.98 | 72.15 | 71.97 | 71.95 | 72.84 | 71.09 | 70.89 | 73.02 | 75.07 | 76.13 |
| AA (%) | 67.84 | 65.01 | 68.47 | 68.14 | 69.58 | 71.29 | 68.99 | 74.21 | 75.01 | 76.87 |
| Methods | Task | RGB | DSM | EF | Late | AAF |
|---|---|---|---|---|---|---|
| Rand. | seg. | 37.67 | 27.06 | 43.19 | 45.07 | 46.52 |
| Simsiam | 47.33 | 27.96 | 43.40 | 52.65 | 54.98 | |
| MocoV2 | 47.11 | 32.53 | 50.16 | 57.39 | 59.63 | |
| rand. | cls. | 67.84 | 65.01 | 68.47 | 68.14 | 69.58 |
| Simsiam | 71.80 | 67.23 | 71.00 | 72.10 | 73.30 | |
| MocoV2 | 71.29 | 68.99 | 74.21 | 75.01 | 76.87 |
| Methods | Task | mIoU (%) | OA (%) | K (%) | AA (%) |
|---|---|---|---|---|---|
| DINO-MM | seg. | 54.51 | 74.37 | 67.54 | - |
| SSLTransformerRS | 57.50 | 76.50 | 70.42 | - | |
| AAF | 59.63 | 79.08 | 72.78 | - | |
| DINO-MM | cls. | - | - | - | 72.82 |
| SSLTransformerRS | - | - | - | 74.75 | |
| AAF | - | - | - | 76.87 |
| Methods | Task | Gate | mIoU (%) | OA (%) | K (%) | AA (%) |
|---|---|---|---|---|---|---|
| Simsiam | seg. | w/o | 54.03 | 73.82 | 66.15 | - |
| w/ | 54.98 | 74.36 | 66.91 | - | ||
| cls. | w/o | - | - | - | 72.92 | |
| w/ | - | - | - | 74.30 | ||
| MocoV2 | seg. | w/o | 57.43 | 77.26 | 70.51 | - |
| w/ | 59.63 | 79.08 | 72.78 | - | ||
| cls. | w/o | - | - | - | 75.21 | |
| w/ | - | - | - | 76.87 |
| mIoU (%) | OA (%) | K (%) | |||
|---|---|---|---|---|---|
| ✓ | 59.63 | 79.08 | 72.78 | ||
| ✓ | 59.06 | 78.56 | 72.10 | ||
| ✓ | ✓ | 57.82 | 77.13 | 70.34 | |
| ✓ | ✓ | ✓ | 57.22 | 76.82 | 69.91 |
| Attention Methods | mIoU (%) | OA (%) | K (%) |
|---|---|---|---|
| None | 57.43 | 77.26 | 70.51 |
| Channel | 58.53 | 78.06 | 71.41 |
| Channel + Spatial | 59.13 | 78.56 | 72.41 |
| Channel + Spatial + Scale | 59.63 | 79.08 | 72.78 |
| Channel & Spatial & Scale | 59.13 | 78.68 | 72.18 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, G.; Jiang, X.; Li, X.; Zhang, Z.; Liu, X. Exploring Self-Supervised Learning for Multi-Modal Remote Sensing Pre-Training via Asymmetric Attention Fusion. Remote Sens. 2023, 15, 5682. https://doi.org/10.3390/rs15245682
Xu G, Jiang X, Li X, Zhang Z, Liu X. Exploring Self-Supervised Learning for Multi-Modal Remote Sensing Pre-Training via Asymmetric Attention Fusion. Remote Sensing. 2023; 15(24):5682. https://doi.org/10.3390/rs15245682
Chicago/Turabian StyleXu, Guozheng, Xue Jiang, Xiangtai Li, Ze Zhang, and Xingzhao Liu. 2023. "Exploring Self-Supervised Learning for Multi-Modal Remote Sensing Pre-Training via Asymmetric Attention Fusion" Remote Sensing 15, no. 24: 5682. https://doi.org/10.3390/rs15245682
APA StyleXu, G., Jiang, X., Li, X., Zhang, Z., & Liu, X. (2023). Exploring Self-Supervised Learning for Multi-Modal Remote Sensing Pre-Training via Asymmetric Attention Fusion. Remote Sensing, 15(24), 5682. https://doi.org/10.3390/rs15245682