1. Introduction
Nowadays, with the rapid development of China’s urbanization and industrialization, the environmental problem has become increasingly severe. Although the government has tried hard to increase the monitoring and protection of the ecological environment, the deterioration of the overall environment has never been curbed. To deal with this ecological crisis, the ecological redline (Eco-redline, ECR) policy is proposed, which aims to maintain vital ecosystem services needed for sustainable social development through coordinated nationwide planning. The policy defines key ecological protection areas where five necessary national ecosystem services [
1] should be maintained: flood disaster mitigation, sandstorm disaster prevention, water resources protection, soil resources conservation, and biodiversity conservation. To sum up, the Eco-redline represents an attempt to establish strict criteria for assessing ecosystem services in land-use planning, and is defined as “the minimum ecological area for the protection of the safety and functioning of the ecological environment and the maintenance of a country’s biodiversity.” [
2].
To properly regulate the Eco-redline areas, large amounts of data and advanced technology are needed. In recent years, remote sensing datasets acquired by multiplex spaceborne and airborne sensors with rich temporal, spatial, spectral, and radiometric resolution characteristics have largely increased [
3]. Due to the rapid development of sensors and the advancement of image processing technology, the increasing trend of remote sensing big data will surely continue [
4].
Based on the ever-increasing data, change detection using remote sensing images has surpassed the means of manual field exploration and has become one of the most common research techniques. This technology can function in pixel-level and grid-level research, which leads to wide use in urban monitoring, environmental monitoring, and post-disaster damage assessment [
5,
6]. Since it can quickly and accurately explore changes in natural landscapes, it can provide real-time feedback on changes in mountainous areas and woodlands, which perfectly fits the research needs of detecting human-induced changes in Eco-redline areas.
Therefore, many remote sensing change detection methods have been proposed, some of which have been tested and validated in many studies [
7,
8,
9,
10]. For example, traditional methods such as principal component analysis (PCA) [
11], independent component analysis (ICA) [
12], and multivariate alteration detection (MAD) [
13] have been successfully applied to many change detection studies. However, given the interference of many internal factors on change detection, these methods still cannot be reliably applied to practical situations. Moreover, since the purpose of change detection is to quantitatively analyze and determine the surface changes in different periods through remote sensing data, the following problems cannot be avoided: firstly, there are too many land cover categories, and the similarity between different sorts and the diversity between the same sorts will disturb the research. Secondly, systematic errors such as the interference of the imaging environment and the sensing system will lead to huge differences in the remote sensing data obtained from different sensors in the same area. Finally, there are seasonal changes in the land cover itself, such as various grasslands and woodlands changing with the seasons, and these irrelevant changes will no doubt hinder the extraction of research targets. Therefore, it is quite difficult to obtain highly accurate change results to meet the requirements of Eco-redline monitoring.
Fortunately, the recent remarkable achievements of neural networks in the field of computer vision have contributed to the rise and development of deep learning-based change detection methods [
14,
15,
16,
17,
18,
19,
20]. Such methods have strong feature expression capabilities and can extract more key information from images. Depending on whether the dataset has labels, there are two types of deep learning methods, unsupervised and supervised. The purpose of the change detection method based on the unsupervised neural network is to learn a new feature space through the neural network so as to shorten the distance between different time-phase feature spaces. Although unsupervised learning improves the discriminative ability of new feature spaces to some extent by introducing pseudo-labels [
20,
21,
22], the problem of detecting changes that are not related to the problem of interest still arises in the real application. Compared with unsupervised methods, the rich label information possessed by supervised neural network-based change detection methods can better distinguish the specific change types of interest in the whole scene but will need much more effort to finish the labeling job. Therefore, sometimes these two approaches are combined to achieve better results with less workload.
The following question is about the information fusion method used when constructing a change detection network. Generally, there are three levels of information fusion, namely data-level fusion, feature-level fusion, and decision-level fusion [
23]. Among them, data-level fusion is the easiest way. It straightly concatenates the pre- and post-phases as the input of the network. This is the strategy adopted when applying many typical semantic segmentation networks to the field of change detection. However, sometimes this method may receive unexpectedly low-precision results [
24]. Moreover, since two inputs only produce one output in change detection, decision-level fusion can not be possible [
25]. Therefore, to achieve high-performance networks, more and more researchers have begun to use the idea of feature-level fusion, thus, giving birth to the Siamese network. The Siamese network inputs data of different phases into different network branches to complete feature extraction. These high-level features will then be combined to achieve feature-level information fusion, and finally, the combined information will be used to identify the changes. The Siamese neural network proposed in this theory is usually regarded as the basic network structure for acquiring high-level features [
26,
27].
Then, the sampling method will also need to be considered. The traditional convolution is constrained by the limited receptive field and lacks the utilization of local information. To further optimize the network performance, many researchers have introduced Visual Transformer (ViT). The Multi Self-Attention (MSA) module of traditional ViT can well utilize global information based on ensuring parallel computing [
28]: for example, Wang et al. combined the convolutional neural network with the CBAM attention mechanism to improve the feature learning performance of radar image change detection [
29]. Peng et al. optimized and improved the UNet++ network by replacing the original upsampling unit using the attention mechanism [
30]. This approach enhances spatial and channel attention guidance and achieves better results than the original network. Chen et al. propose an attention information module AIFM and combine it with the Siamese ResNet [
25]. As a bridge of feature fusion, this module improves the performance of the network for feature extraction of changes in remote sensing images.
Since the self-attention mechanism is quite successful, how to effectively apply and further improve it has become a popular direction. Recently, the Hierarchicle Vision Transformer using Shifted Windows (Swin Transformer, Swin-T) was proposed and rapidly achieved remarkable results on many experimental tasks [
31]. It uses the window-based multi-self-attention (W-MSA) module to replace the traditional ViT MSA module, which greatly reduces the amount of computation. To ensure the utilization of information, Swin-T additionally designs and adds a shifted window-based multi-self-attention (SW-MSA) module. The combination of W-MSA and SW-MSA can guarantee the interaction of global information. In addition, Swin-T introduces a relative position offset to increase the overall accuracy of the network further. Based on the idea of Swin-T, Swin-UNet was proposed in 2021 and was famous for its high efficiency as well as high performance [
32]. It constructs a symmetric encoder-decoder structure with skip-connections based on Swin-T.
Given the excellent performance of Swin-UNet, our experiment considers modifying and applying it as the backbone to devise change detection networks. Actually, we use the feature-level fusion method and build a Siamese Swin-UNet for change detection called SWUNet-CD. However, to achieve the goal of obtaining higher-precision change results, the following problems will still need to be solved: firstly, the traditional pooling layers (such as the max pooling layer and average pooling layer) can inevitably lose some key features when applied to more complex remote sensing images [
33,
34,
35]. Secondly, public pre-trained models are trained on the ImageNet dataset, and these images can be quite dinstinct from remote sensing images due to geographic information and shooting angles. Thirdly, to better deal with the problem of large-scale unbalanced distribution, especially in our research regions, we need to pay more attention to the research area and the aimed objects of our experiment. To solve the problems listed above, we make two major improvements: (1) we combine the W-MSA/SW-MSA mechanism with the idea of multi-scale fusion, and design a swin-based pyramid pooling module (SPPM) with a more complex structure. The purpose is to improve the feature expression ability of the network and retain more key features when applied to complex remote-sensing images. (2) We construct a self-supervised network using the idea of the contrastive method. The purpose of this network is to provide a more suitable pre-trained model for our downstream tasks. This network is trained on a large amount of unlabeled data in the study area, where pseudo-labels are produced by employing data augmentation. Its purpose is to reduce the influence caused by the differences between the datasets where negative samples are much more when compared to positive samples, and keep closer to our research area and aimed objects.
In summary, we build SWUNet-CD, a Siamese change detection network based on Swin-UNet. To better apply it in the remote sensing field, we design SPPM, a special pooling module to replace the traditional pooling layer, and construct a self-supervised network that is used to obtain specialized pre-trained models. The main contributions of this paper are as follows:
A Siamese self-supervised learning network is constructed using the idea of contrast. The original image and the data-augmented image are used as two inputs to the network, and the classification of each data augmentation is the output. By training with a large amount of unlabeled remote sensing data from the study area, a set of pre-trained models for loading into subsequent supervised networks is finally obtained. We have verified through experiments that this method helps the proposed network better adapted to remote sensing change detection;
Based on the idea of Swin-T and multi-scale fusion, a self-attention mechanism-based pyramid pooling module SPPM is constructed and applied to the Siamese Swin-UNet network adopted in this experiment. The self-attention module can better utilize global information to obtain more complete features, while the multi-scale fusion method can maximize the use of the information of each pixel and reduce the loss of key features;
We apply the Siamese Swin-UNet network using a special pre-trained model and improved pooling module SPPM to the problem of remote sensing change detection for ecological redline monitoring and verify the performance of this change detection method through experiments.
The following contents are organized as follows.
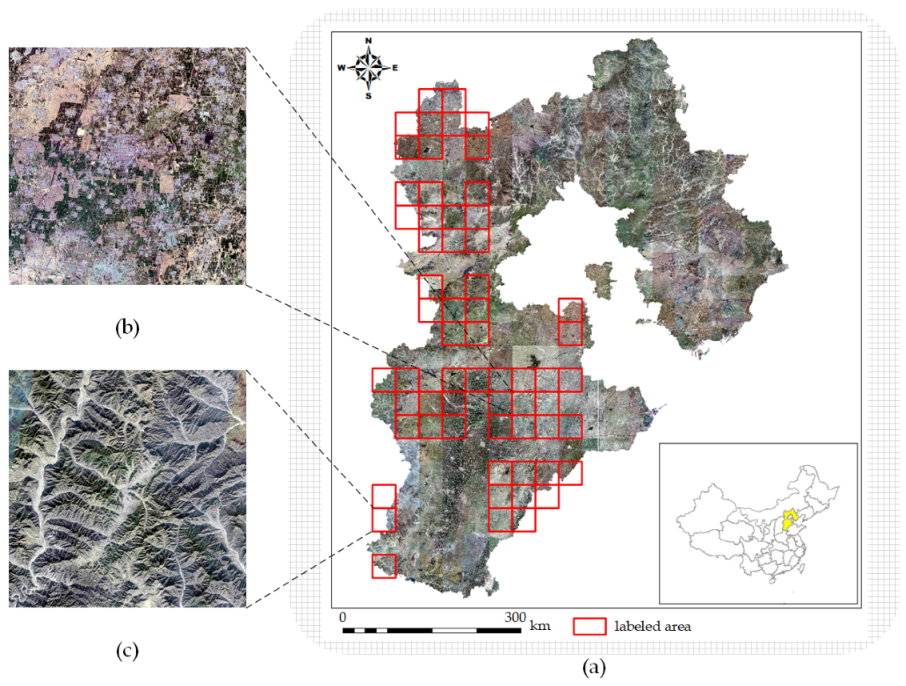
Section 2 clarifies the study area and the preparation of the dataset in detail.
Section 3 provides a quite detailed theoretical introduction to the change detection method proposed.
Section 4 contains ablation experiments, contrast experiments, and the calculation of intersection recall rate for large-scale prediction results. These are all used to justify the validity and the superiority in terms of performance.
Section 5 is a refined conclusion of our research work.
3. Proposed Methods
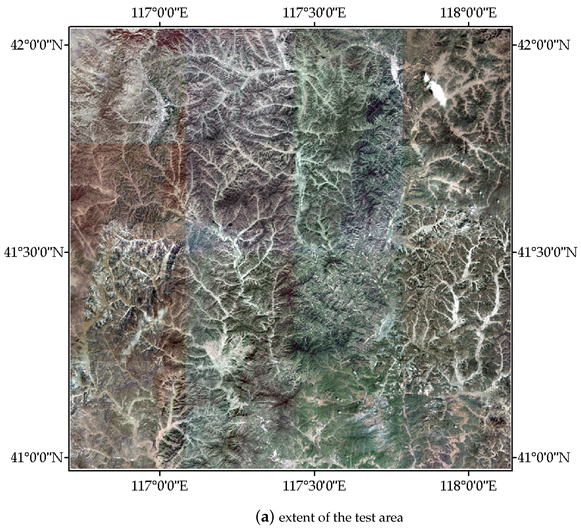
In this work, we propose a deep learning network called SWUNet-CD for the change detection of the Eco-redline in Hebei Province using the GF-1 satellite images. Moreover, we devise a special pooling module and a dual-stream self-supervised network to improve its performance further. The detailed information is listed below.
3.1. SWUNet-CD
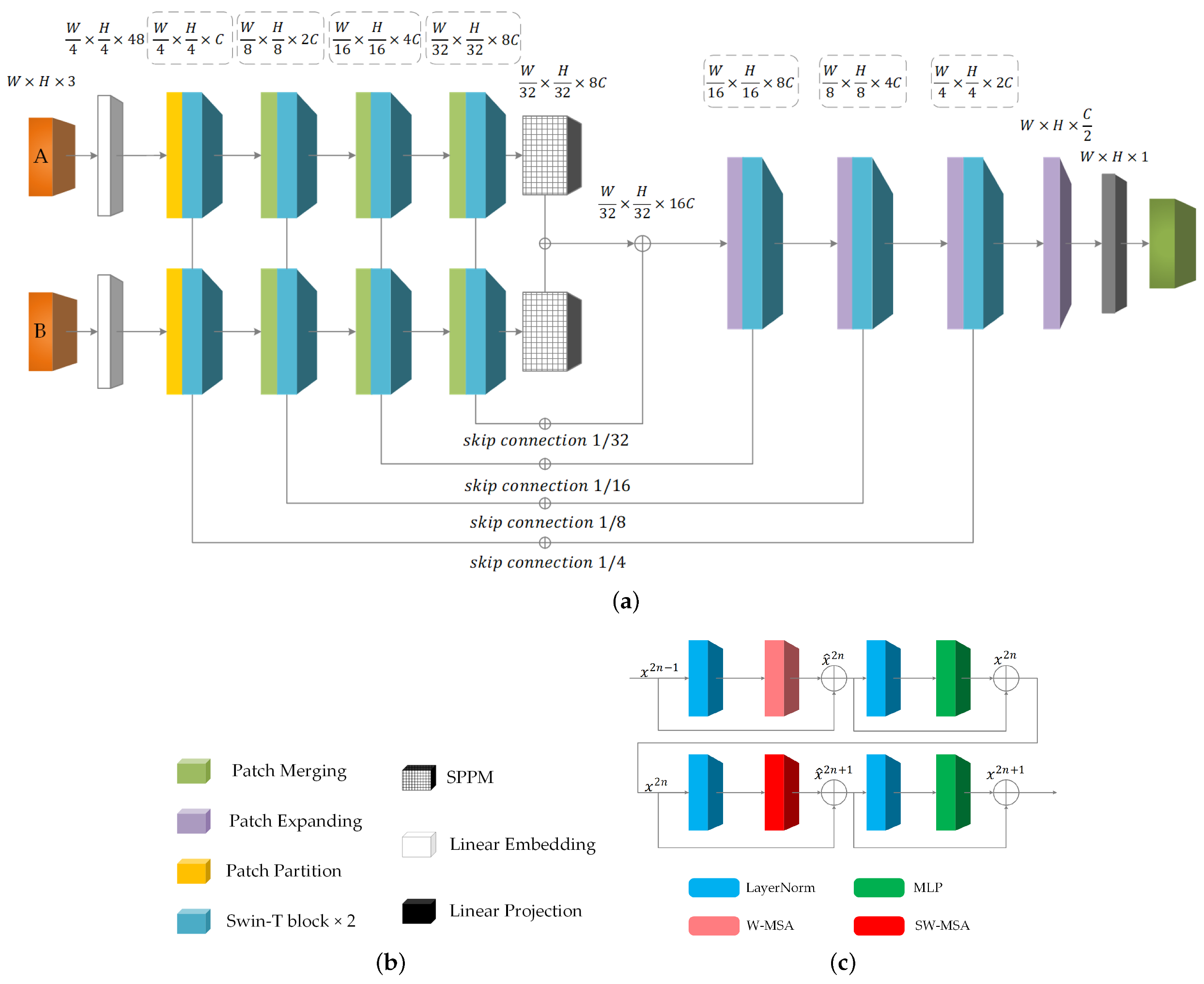
We convert the Swin-UNet into Siamese form for change detection, and apply the designed SPPM (mentioned in
Section 3.2) to it. The main network structure of SWUNet-CD is shown in
Figure 2a,b is a statistical summary of the names of different modules in it. The backbone of the network has four downsampling layers; each contains two consecutive Swin-T blocks, as shown in
Figure 2c. Each Swin-T block consists of a normalization layer (LayerNorm), a MSA, a residual connection, and a Multilayer Perceptron (MLP). Among them, the Swin-T block in the front part uses W-MSA, and the latter part uses SW-MSA. The two consecutive Swin-T blocks can be expressed by the following formula:
among them, n represents the
nth downsampling process, which includes the
th Swin-T block and the
th Swin-T block.
represents the output of the
th MSA in the Swin-T Block, and
represents the output of the
MLP in the Swin-T Block. Self-attention is calculated as shown in Formula (
5), where Q, K, and V denotes the query, key, and value matrixes, respectively. Dimension represents the dimension of the query or key, and the values in Bias are obtained from the bias matrix.
The functions of each module in the network are as follows: The function of the Patch Partition layer is to divide the input tensor into smaller pieces and then concatenate them in channel dimensions to shorten the tensor’s length and width. The role of the Linear Embedding layer is to transform the channel size of the feature map obtained in the previous step to the size required by the network. The function of the Patch Merging module is to reduce the length and width of the feature map by half and double its channel size to form multi-level features. The Patch Merging module and the two consecutive Swin-T blocks jointly constitute a downsampling layer. The role of SPPM is to trim the downsampling results to remove the influence of overfitting while preserving the features as much as possible. The function of the Patch Expanding module is to double the length and width of the feature map and reduce the channel size by half to restore the feature map hierarchically. The Patch Expanding module and the two consecutive Swin-T blocks together form an upsampling layer, where the feature information is fused by the corresponding downsampling layer through a skip connection. The role of the Linear Projection layer is to convert the feature map to a single channel for pixel-level change detection.
The overall process of our network is as follows: we input the pre- and post-phase images into the network. During the process of forward propagation, four downsampling operations and an SPPM-based pooling operation are performed on them, respectively. As a result, we obtain the features with downsampling four times, eight times, sixteen times, and thirty-two times. We then fuse the features of the same stage and use them as the input of the upsampling part. It is worth mentioning that the SWUNet-CD adopts the information fusion method of feature-level fusion instead of simple data-level fusion. Although this does increase a certain amount of parameter calculations, it can use deeper features to better train the network for the shallow features of remote sensing images that may usually be hard to detect and identify.
3.2. Swin-Based Pyramid Pooling Module
The idea of multi-scale fusion is innovative and has been proven to work well on the improvement work of the pooling layer, such as the Pyramid Pooling module (PPM) and the Atrous Spatial Pyramid Pooling (ASPP) [
36,
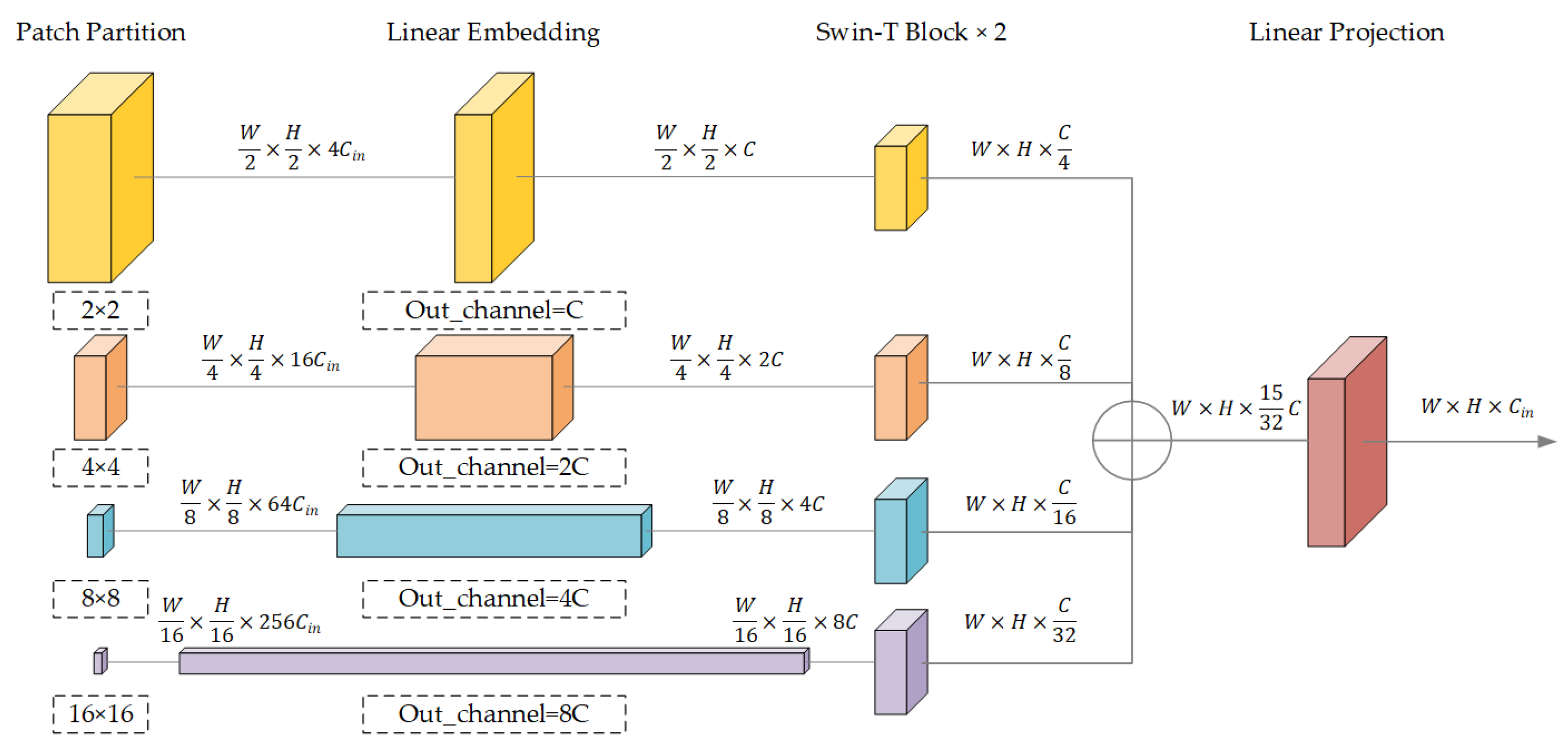
37]. Based on the multi-scale fusion idea and the excellent performance of W-MSA, we devise a Swin-based pyramid pooling module (SPPM), as shown in
Figure 3. The pyramid consists of four feature extraction layers and one Linear Projection layer. Each feature extraction layer consists of a Patch Partition layer, a Linear Embedding layer, and two consecutive Swin-T blocks. The overall process of the entire SPPM is as follows: The Patch Partition layer downsamples the input feature map by two times, four times, eight times, and sixteen times, respectively. After that, these feature maps will go through the Linear Embedding layer in which their channel size will be transformed to C, 2 × C, 4 × C, and 8 × C (C is defined by the hyperparameter as a channel size that the module can accept), respectively. These preprocessed feature maps are then input into the two consecutive Swin-T blocks, where the self-attention calculation is conducted on a window with a length and width of 7 × 7, defined by hyperparameters for each feature map. The windows’ working mechanism is as follows: firstly, a self-attention calculation for a standard window is done. After that, another self-attention calculation is done for different partitions after the window is moved. The purpose is to achieve information exchange between different locations to maintain the utilization of global information after partitioning. Secondly, a mask calculation is used so that the self-attention between the moved part and the original part will not be taken into account. After passing through the Swin-T block, the output feature map of each layer structure will restore the length and width to the input size by reshaping operation. Later, they will be concatenated in the channel dimension. At the end of the module, the concatenated feature map goes through a Linear Projection layer to restore the channel size to the input size. In this way, SPPM can retain more deep features extracted by the network during the downsampling process, thus, avoiding losing some important information.
In the SWUNet-CD built for our change detection experiment, we use this SPPM in its bottleneck layer. The purpose is to use the excellent performance of the self-attention mechanism in the field of feature extraction to make greater use of local and global information to retain multi-level information. As a matter of fact, we expect that this structure can further improve the function of the network compared with typical multi-scale fusion modules (such as PPM, ASPP, etc.) and obtain experimental results with higher accuracy.
3.3. Pre-Trained Model Obtained by Self-Supervised Network
Although our team has done some labeling work, it is still very scarce when compared to the overall remote sensing data. Therefore, we consider designing a self-supervised learning method. This method aims to construct several reasonable artificial labels for the unlabeled remote sensing images and guide the network to learn more feature expressions that are helpful for the overall experimental task [
38,
39,
40,
41,
42].
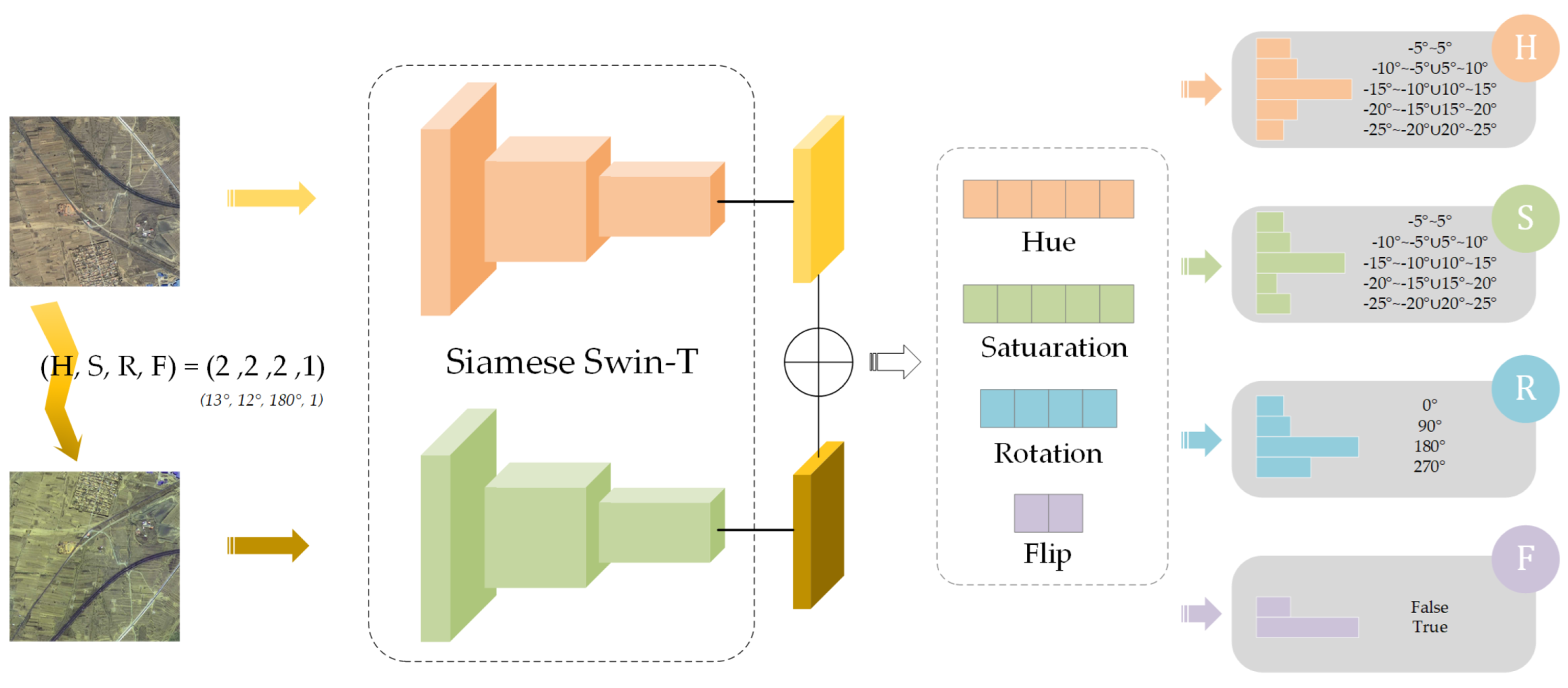
There exist two kinds of methods when constructing the self-supervised network: the generative method as well as the contrastive method. The former has many redundant parameters and is hard to optimize, so we adopt the latter. The contrastive method does not require pixel-by-pixel reconstruction of the input data. It only needs that the model can distinguish between different inputs in the feature space. Therefore, the network constructed in this way does not need a decoder. In fact, only a fully connected layer is acquired to judge the features obtained by the encoder. To better fit the downstream task, we construct a weight-sharing Siamese network, using Swin-T as its encoder, as shown in
Figure 4. We construct artificial labels based on data augmentation. This idea is mainly derived from the phenomenon that the ground objects (forest, mining areas, illegal buildings, etc.), which are the objects of the study, are more distinguishable in color and texture. The original data and the augmented data are used as the dual-stream input of the Siamese self-supervised network. After acquiring both feature maps and comparing the differences, the predictive ability of the network is trained. Ultimately, the network can improve its ability to express features and produce a pre-trained model for the latter task.
The contruction method is as follows: we use four data enhancement parameters as the judgment criteria, namely Hue, Saturation, Rotation, and Flip. Hue represents the relative lightness and darkness of the image, and its value ranges from 0° to 360°. Five types of transformation are used for Hue, and the ranges are , respectively. These five types of ranges are labeled as 1–5. Saturation represents how close a color is to a spectral color when viewed as the spectral color mixed with white, and its value ranges from 0° to 100°. Five types of transformations are used for Saturation, and the ranges are , respectively. These five types of ranges are labeled as 1–5. Rotation represents the rotation of the image by a certain angle. Four different rotation angles are used, namely 0°, 90°, 180°, and 270°. These four types of ranges are labeled as 1–4. Flip stands for flipping the image left and right. There are only two cases, including not flipping and flipping. These two types of ranges are labeled as 1 and 2.
The training process of the network is as follows: the original image and the data-augmented image are input synchronously into the network. After the down-sampling operation of Swin-T, two feature maps of the same size can be obtained. They are concatenated in the channel dimension to obtain the change information, which represents the data augmentation, and then this mixed feature map passes through a 1 × 1 size adaptive average pooling layer to extract the global information. Finally, four different classification results are acquired through four different fully connected layers. The results are four distinct probability distributions, corresponding to the transformations of Hue, Saturation, Rotation, and Flip. We use them as criteria to compute the loss function, enabling backpropagation and parameter tuning. Finally, we obtain a set of parameters with high accuracy that can be a perfect fit for the latter training of SWUNet-CD. Therefore, we use this set of parameters as a pre-trained model to replace the normal one, hoping to achieve better experimental results for change detection in the research area.
5. Conclusions
The change detection method combining remote sensing data with neural networks is a useful and necessary research direction in the current society. At present, it has been widely used in urban construction, disaster assessment, nature protection, and other fields. In our study, we used this kind of method to detect changes in Eco-redline area, aiming to meet the urgent needs of environmental monitoring.
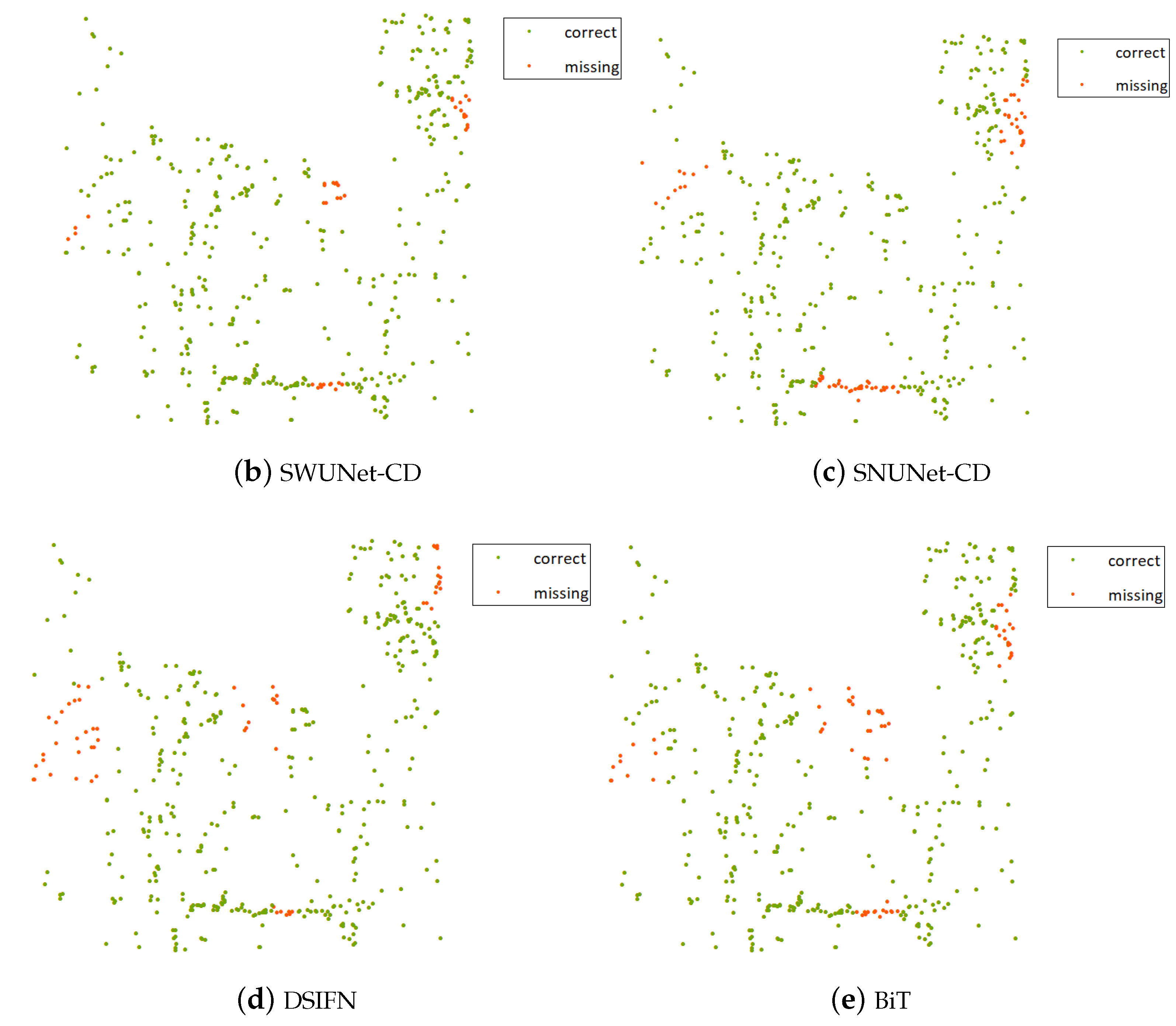
To get better results, we have adopted three methods. Firstly, we constructed a Siamese network called SWUNet-CD. This structure will pay more attention to the use of deeper features in remote sensing images, which will help to learn the differences that cannot be easily identified. Secondly, we devised a special pooling module called SPPM. This module is used to maintain features of different levels, which will ensure that the network does not miss any key information. Finally, we constructed a self-supervised network based on the contrastive method, and trained it to obtain a pre-trained model. This model is used to partly solve the uneven distribution problem due to large negative samples and small positive samples, and will be more suited to remote sensing research. It can preliminarily be seen from the experimental results that our research method has achieved good results, reaching an F1 score of 0.7235 and 0.5668 in IoU, which is much better than the baseline and other comparable networks. Moreover, we continue to verify the performance through practical ways, predicting and calculating intersection spots which can serve as the direct basis of Eco-redline monitoring. By reaching 91.33% in its intersection recall rate, this stage also proves the great performance of our method.
However, there still exist some drawbacks that cannot be overlooked: (1) the change detection results of mining areas are much worse than the results of the buildings. To solve the problem, we have thought about two ways. Firstly, we can investigate more about the types of mining areas. For example, some are located on the ground while others are below, and some may be accompanied by water. So it may be very meaningful to make a precise subdivision about the mining areas. Secondly, we can improve the self-supervised network. By manually adding some mining areas to the image, we can insert some supervised information, helping to improve the network’s ability to identify the mining areas. (2) The performance of the pre-trained model. Although we have thought of ways to obtain a model which better fits the remote sensing images and our change detection task, it still lacks a degree of change information, and, therefore, its ability may be prohibited. (3) The quality and the usability of the data. We need more supervised data to train the network, but the labeling work is a huge and hard task and will be easily disturbed by the nearby environment.
Therefore, our future research will mainly focus on the following aspects: (1) doing more research about the type of mining areas and applying it in the labeling work; (2) studying other self-supervised methods and trying to obtain a pre-trained model, especially, for change detection task; (3) bringing in other datasets and testing our network’s ability to detect changes in other research areas like rural areas and urban areas.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}