1. Introduction
Hyperspectral object tracking is a challenging task emerging recently [
1,
2,
3], which can be applied in video surveillance camouflage targets, autonomous driving, and so on. Its purpose is to estimate the object’s state (e.g., position, size, etc.) in subsequent frames by that of the object in the initial frame in the hyperspectral video. Currently, most tracking algorithms are developed for RGB video research and have made some achievements [
4,
5,
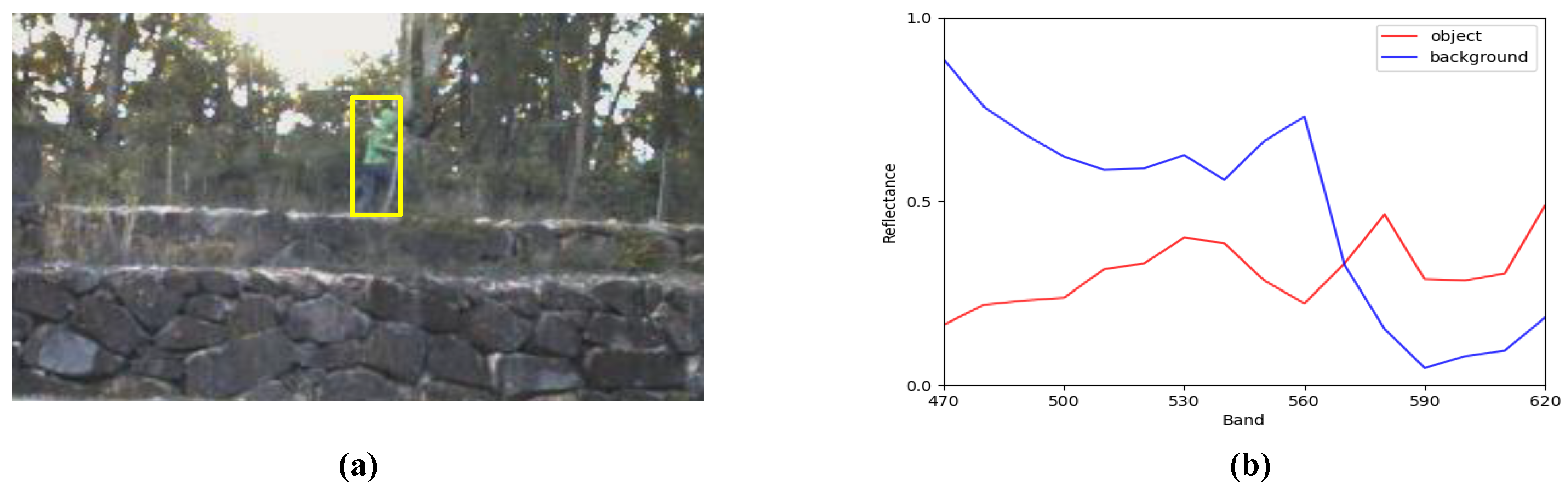
6]. However, the RGB modality image has inherent limitations in describing the physical characteristics of objects, making it easy to cause RGB-based tracker drifts in some complex but common scenarios, such as the object and backgrounds’ colors being similar. Compared with the RGB image that describes visual information only by red, green, and blue channels, the hyperspectral image (HSI) with a three-dimensional structure can record the location of the object space and the continuous spectral information simultaneously. As shown in
Figure 1, HSI can provide additional spectral information to break through the limitations of visual characteristics, which proves that HSI has the potential to cope with the challenges in the tracking process. Therefore, using hyperspectral video to perform the tracking task can offer more opportunities for achieving high-performance tracking, which has significant research value.
Some works have preliminary explored hyperspectral object tracking methods [
1,
7,
8,
9,
10] in recent years. Similar to the RGB object tracking method, the hyperspectral object tracking algorithm can be divided into two kinds; one is based on correlation filtering, and the other is based on deep learning (DL) [
11,
12]. The MHT [
1] method proposed by Xiong et al. is a representative correlation filtering-based hyperspectral object tracking method. MHT adopts two feature descriptors to characterize material information of HSIs and further embeds them into the background-aware correlation filter, yielding the tracking based on material. However, compared with the deep features obtained by deep neural networks, the handcrafted features usually adopted by the correlation filtering method have difficulty with fully describing hyperspectral information, which often limits the hyperspectral object tracking performance. Therefore, applying the DL method in the hyperspectral object tracking field is more competitive for accurately predicting the object’s state in the tracking process.
However, the limited amount of hyperspectral image sequences cannot meet the requirements of deep learning for large-scale training samples, which undoubtedly makes it difficult to promote the development of DL-based hyperspectral tracking algorithms [
13,
14]. Compared with HSI sequences, RGB image sequences have massive labeled samples and richer visual details (such as texture, color, and so on). Thus, the RGB object tracking method based on DL often has higher tracking accuracy. Therefore, exploring how to transfer the advantages of the DL-based RGB modality tracking method to hyperspectral tracking to alleviate the problem of low model accuracy and insufficient generalization ability caused by the shortage of training sample data in hyperspectral tracking is crucial for effectively using the DL method to improve the performance of hyperspectral modality object tracking.
At present, the method of successfully transferring the advantages of the RGB modality tracking method based on DL to the field of hyperspectral object tracking is to process hyperspectral modality data using the RGB tracking model based on DL trained by large-scale datasets to capture robust visual-similar features from the hyperspectral modality. These methods improve tracking performance by successfully transferring the robust RGB modality information in the hyperspectral object tracking process [
2,
3,
15]. The BAE-Net [
2] method proposed by Li et al. is an excellent and representative DL-based work. BAE-Net first introduces a band attention module to learn the relationship among hyperspectral bands for generating band weights and divides the hyperspectral image into multiple three-channel images according to these weights. Then, these images are input into a deep RGB tracking model, transferring multiple visual-similar information from hyperspectral data for the integrated prediction of the object position. Consistent with the idea of BAE-Net, the SST-Net [
3] method proposed by Li et al. also divides HSI bands and uses the depth tracker for integrated tracking. The difference is that SST-Net considers the spatial–spectral–temporal information in the hyperspectral video when acquiring the importance of bands, which can model the relationship between bands of HSIs better, thus converting HSIs into more valuable three-band images for depth tracking. Unlike the above methods, the HA-Net [
15] method proposed by Liu et al. is another meaningful and representative work of the DL-based hyperspectral object tracking task. HA-Net leverages the dual Siamese network framework to perform hyperspectral object tracking, using the hyperspectral information to improve the performance of the RGB Siamese tracking network, which can make the model more discriminative. Specifically, the RGB Siamese network is used to obtain visual-similar features from false-color images converted from hyperspectral data and then get classification and regression response maps of the false-color data. The hyperspectral Siamese network is used to obtain the classification response map of the hyperspectral data. Two classification response maps are merged to enhance the network’s ability to distinguish the object and the background. Unfortunately, although they have achieved preliminary success in transferring the RGB tracking advantages to hyperspectral tracking by using the DL-based RGB tracking model to transfer the RGB modality information, they still do not fully play the role of hyperspectral information to improve object tracking performance.
Effective use of the pretrained RGB tracking model based on DL to transfer RGB modality information in hyperspectral object tracking while fully using hyperspectral data information is essential to achieve high-performance hyperspectral tracking. Multimodality fusion tracking tasks have become popular recently [
16,
17,
18], which can improve tracking performance by efficiently combining the information of different modalities to supplement the inherent defects of single-modality. It is well known that extracting any three bands from hyperspectral data can form pseudocolor images. Therefore, the hyperspectral object tracking task can be regarded as multimodality object tracking based on the hyperspectral and pseudocolor video. Thus, while using the pre-trained RGB model to transfer RGB modality information, it is worth to explore that introducing the idea of multimodality tracking into the object tracking field based on the single hyperspectral modality, which can realize the full utilization of hyperspectral data by effectively transferring the fusion information of multimodality data composed of RGB and hyperspectral, thereby improving the performance of hyperspectral tracking. In addition, the successful application of the Transformer model in multimodality tasks [
19,
20,
21] shows that the model can achieve the purpose of information combination by efficiently capturing different modality relations to fuse information. Therefore, it has great potential to improve the performance of the tracking task by using the Transformer model to combine different modality information.
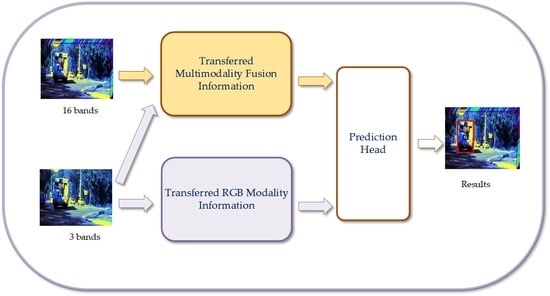
Based on these have been mentioned, we propose a Transformer-based multimodality information transfer network (TMTNet) for hyperspectral object tracking, aiming to fully transfer the information of multimodality data composed of RGB data and hyperspectral data to enhance the object tracking’s performance based on single hyperspectral modality. In this work, the multimodality information that needs to be transferred mainly includes the fusion information of multimodality data composed of RGB and hyperspectral and the RGB modality information. The information transfer is realized through the corresponding pretrained network to alleviate the deep model’s low accuracy and insufficient generalization ability caused by the lack of hyperspectral training samples. The RGB pretrained network is trained through tens of millions of RGB training samples, which can predict the object location robustly in unknown scenes. However, relative to the RGB data scale, no large-scale dataset containing RGB and hyperspectral video data pairs can be used to provide the training samples required for the pretrained multimodality fusion network. To this end, we adopt the dual branch fusion structure, which uses the DL-based pretrained RGB model as the RGB branch to process RGB data and uses the RGB branch to guide the training of the hyperspectral branch to realize that modeling the general representation ability of hyperspectral features with a small number of training samples, thus obtaining the pretrained RGB-hyperspectral multimodality fusion model with certain generalization ability. It is worth noting that the existing combination of RGB and hyperspectral video data is not entirely ideal (it has some differences, such as a spatial resolution difference), but this does not affect the construction of the relation of RGB and hyperspectral video data using the Siamese network based on the known two modality ground truth. This is because, in the training process, the template patch and the search region as the actual input of the Siamese network are all clipped based on the ground truth of each modality data, and the size of the corresponding area after the clipping of the two modality data is fixed and the same. Therefore, even if the two modality data are not entirely matched, it has little effect on the Siamese network-based fusion model for training the two modalities.
It is well known that multimodality fusion information not only contains the advantages of each modality data but also complements the shortcomings of single-modality data, which is conducive to improving tracking performance. To fully utilize hyperspectral information from the perspective of multimodality fusion information transfer, we construct a multimodality fusion information transfer subnetwork (trained by the multimodality data composed of RGB and hyperspectral) in TMTNet, to predict the object position in the hyperspectral video by capturing the multimodality-similar fusion information from hyperspectral data in the testing process. The critical parts of the subnetwork include a dual Siamese network-based branch structure and a multimodality fusion module, which are used to process different modality data and fuse their semantic information, respectively. Specifically, a pretrained RGB Siamese network model based on DL is used as the RGB branch to process pseudocolor data to obtain general, robust, and descriptive visual-similar features. Then, a Siamese 3D CNN is designed as the hyperspectral branch to process hyperspectral data. The Siamese 3D CNN obtains the hyperspectral modality-specific information by adopting the 3D convolution kernel to slide jointly between the spatial and spectral dimensions of the hyperspectral data. In addition, given the Transformer model’s advantage in combining multimodality information, the multimodality fusion module is designed based on the Transformer model. This module (termed TIIM) adopts the self-attention mechanism of the Transformer to interact the semantic information generated by different modality branches adaptively to achieve multimodality information fusion. Therefore, the constructed multimodality fusion information transfer subnetwork can obtain multimodality-similar fusion information from hyperspectral data by effectively combining pseudocolor and hyperspectral information based on ensuring a certain generalization ability to achieve accurate prediction of the object location.
To further improve the tracking network’s generalization and accuracy, on the basis of the multimodality fusion information transfer subnetwork, we introduce a good-performance RGB tracking model as the other tracking subnetwork into TMTNet, for transferring the robust RGB modality information. The RGB modality information transfer subnetwork maximizes the ability of the network to track objects in unknown complex scenes by adding robust visual-similar features of the pseudocolor data to the tracking model. Then, two sets of response maps generated by two subnetworks are employed to jointly predict the object’s position to make the tracking results more accurate. The mentioned above are essential components of the subject network in TMTNet. In addition, to obtain a higher-quality estimation bounding box of object tracking, we also add a spatial optimization module (SOM) to TMTNet, which further optimizes the object position predicted by the subject network by fully retaining and utilizing detailed spatial information. The experimental results on the only available hyperspectral tracking benchmark dataset currently [
1] show that our method achieves leading performance, outperforming advanced trackers. The proposed TMTNet is an extension of our previous work TrTSN [
22], in which TrTSN is the champion scheme of the Hyperspectral Object Tracking Competition 2022. Compared with TrTSN, TMTNet employs the independent RGB tracking model trained by large-scale datasets as the RGB modality information transfer subnetwork and adds a spatial optimization module to optimize the tracking performance, achieving a similar tracking accuracy to that of TrTSN, which indicates that the hyperspectral object tracking method designed from the perspective of multimodality information transfer is flexible, simple, and effective. The main contributions of this paper are summarized as follows.
We propose a multimodality information transfer network for hyperspectral object tracking, which improves the tracking performance based on the single hyperspectral modality by efficiently transferring the information of multimodality data composed of RGB and hyperspectral. This is the first time that the idea of multimodality tracking is introduced into single-modality object tracking, which provides a new idea for achieving high-performance hyperspectral object tracking.
We construct two subnetworks in the subject network of TMTNet to transfer the semantic information of multimodality data from different angles in the hyperspectral tracking process, thus improving the network’s ability to predict the object’s location. Among them, one subnetwork is used to improve the tracking performance by transferring the multimodality fusion information containing the complementary features of RGB and hyperspectral data. The other subnetwork is used to enhance the tracking network’s generalization and accuracy by transferring robust RGB visual features using the deep-learning-based RGB model trained by large-scale datasets.
We design an information interaction module based on Transformer (TIIM) in the multimodality fusion subnetwork of the subject network, which uses the Transformer’s self-attention mechanism to adaptively capture the potential interactions between the semantic information generated by different modality branches to achieve multimodality information fusion. As far as we know, this is the first application of the Transformer model to combine different semantic information in hyperspectral object tracking.
The rest of this paper is organized as follows. In
Section 2, we describe the Transformer-based multimodality information transfer network in detail. The experimental detail is presented in
Section 3. In
Section 4, we present the experimental results and analysis, and finally, in
Section 5, we conclude the paper.
4. Results and Analysis
4.1. Comparison with State-of-the-Art Trackers
In this section, we compare and analyze the performance of the TMTNet tracker with that of the advanced depth color tracker and hyperspectral tracker using the AUC score and the DP_20 value.
Comparison with State-of-the-art Depth Color Trackers. The performance of the TMTNet tracker is compared with that of some advanced color trackers based on deep learning, including TransT [
29], SiamCAR [
23], SiamGAT [
25], and ECO [
41], to evaluate the influence of hyperspectral data on tracking performance and the effectiveness of the TMTNet tracker. The TMTNet tracker was run on the hyperspectral video, and the color tracker was run on the false-color video. As shown in
Figure 10 and
Table 2, the TMTNet tracker’s performance is significantly better than that of the compared color tracker and reaches the highest AUC score of 0.699. In addition,
Table 3 shows that the TMTNet tracker achieves the best AUC performance compared with the depth color tracker in most challenging scenarios, such as OCC, LR, and BC. In particular, the AUC score of TMTNet is 10.0% higher than that of the best comparative depth color tracker in the BC scenario. It exhibits that hyperspectral data can offer more robust features for the tracking process and also proves that the proposed TMTNet can effectively use hyperspectral data to enhance the ability to cope with challenging scenarios, which indicates the TMTNet’s effectiveness.
Comparison with Hyperspectral Trackers. We also compare the performance of TMTNet with some new hyperspectral object trackers to further verify the proposed method’s effectiveness. MHT [
1] and BAE-Net [
2], excellent hyperspectral trackers, are chosen for comparative experiments. It can be observed from
Figure 10 and
Table 2 that compared with other hyperspectral trackers, the TMTNet tracker obtained the highest AUC score and DP_20 value. In addition, the AUC score of the TMTNet tracker is also higher than that of the HA-Net tracker (68.7%) [
15] that won the Hyperspectral Object Tracking Challenge 2020. Besides,
Table 3 also shows that the AUC score of the TMTNet tracker outperforms that of the comparative hyperspectral trackers in 11 challenging scenarios. The results show that the proposed TMTNet can better leverage hyperspectral data to provide robust features under these challenges in the tracking process, enhancing the tracking performance. Moreover, TMTNet is also an extension of our previous work TrTSN [
22], the champion scheme of the Hyperspectral Object Tracking Competition 2022, and has achieved similar performance to TrTSN, indicating that the hyperspectral object tracking method designed from the perspective of multi-modality information transfer is flexible, simple, and effective.
Table 2 also shows the FPS of various trackers. It can be found that the proposed tracker’s speed is relatively the fastest among the hyperspectral trackers, which can also prove the superiority of the proposed hyperspectral tracker. In addition,
Figure 11 shows the qualitative tracking results of some trackers on the sequences of pedestrian2, student, car3, and fruit, which can intuitively compare the tracking performances. These sequences mainly involve the challenging scenes of OCC, IV, SV, DEF, BC, and LR. The above examples show that the proposed TMTNet provides the most accurate boundary frame, which fully demonstrates the TMTNet tracker can effectively deal with various challenging scenarios, proving its effectiveness in hyperspectral tracking.
4.2. Effectiveness of the Transferred Multi-Modality Information
In this work, we propose a Transformer-based multimodality information transfer network (TMTNet) for hyperspectral object tracking, aiming to fully transfer the information of multimodality data composed of RGB data and hyperspectral data to enhance the hyperspectral tracking performance. The transferred multimodality information includes the fusion information of multimodality data composed of RGB and hyperspectral and the RGB modality information. The multimodality fusion information is transferred by the multimodality fusion information transfer subnetwork, which can obtain multimodality-similar fusion information of hyperspectral data to improve tracking performance. The RGB modality information is transferred by the RGB modality information transfer subnetwork, which is used to get robust visual-similar features of hyperspectral data to improve the network’s ability to predict the object location in unknown complex scenes. Then, the transferred multimodality fusion information and the RGB modality information are used to predict the object’s position jointly.
To prove that the network performance of transferring the multimodality information consisting of the multimodality fusion information and the RGB modality information (achieved by two subnetworks) is better than that of transferring the multimodality fusion information or RGB modality information (using only one subnetwork), we design two TMTNet models without the multimodality fusion information transfer subnetwork or the RGB modality information transfer subnetwork and compare their performance with that of the TMTNet model with two subnetworks (TMTNet). Among them, the TMTNet model that lacks the multimodality fusion information transfer subnetwork but contains the RGB modality information transfer subnetwork is termed as TMTNet_RGB, and the other TMTNet model that does not include the RGB modality information transfer subnetwork but has the multimodality fusion information transfer subnetwork is called TMTNet_fusion.
The experimental results are listed in
Table 4. It can be found that the AUC score of the TMTNet tracker (69.9%) is higher than that of the TMTNet_RGB tracker (68.0%) by 1.9%, and the DP_20 value of the TMTNet tracker (92.8%) is more than that of the TMTNet_RGB tracker (88.7%) by 4.1%. It also can be seen that the AUC score and the DP_20 value of the TMTNet tracker outperform these of the TMTNet_fusion tracker. The above results show that using the transferred multimodality information composed of the multimodality fusion information and the RGB modality information (achieved by two subnetworks) to predict the object’s position jointly is conducive to the improvement of the performance of hyperspectral tracking, indicating that the transferred multimodality information in the hyperspectral object tracking is effective.
4.3. Effectiveness of the Transformer-Based Information Interaction Module
Fully fusing different modality information is the key to effectively using the transferred multimodality fusion information to improve the hyperspectral tracking performance. To achieve the multi-modality information fusion, we design an information interaction module based on Transformer (TIIM) in the multimodality fusion information transfer subnetwork to combine the semantic features obtained from Siamese 3D CNN and Siamese 2D CNN branches, which can utilize the Transformer’s self-attention mechanism to adaptively obtain the relationship between different modality data for fusing mutimodality information.
To further verify the effectiveness of TIIM, we use the concatenation-based fusion method proposed by Zhu et al. [
42] and the cross-based fusion method proposed by Zhang et al. [
43] to replace the TIIM in the multimodality fusion information transfer subnetwork respectively and test their performance. The concatenation-based fusion method combines multimodality information by concatenating different modality features, denoted as TMTNet_concat. The cross-based fusion method gets more compact feature representations of multimodality by interactively connecting the depth features from different modalities, termed TMTNet_cross.
In
Table 5, the AUC score of the TMTNet tracker (69.9%) outperforms that of the TMTNet_concat tracker (67.6%) and the TMTNet_cross tracker (68.3%) after using the TIIM, while the DP_20 value of the TMTNet tracker (92.8%) is more than that of the TMTNet_concat tracker (88.9%) and the TMTNet_cross tracker (89.5%) by 3.9% and 3.3%, respectively. Experimental results show that the proposed TIIM can effectively fusion different modality information.
4.4. Effectiveness of the Response-Level Fusion Method
In the hyperspectral tracking process, selecting an appropriate method to use the multimodality-similar fusion information and visual-similar information obtained from hyperspectral data to predict the object location jointly is important for effectively utilizing the transferred multimodality information to improve the tracking performance. In this work, we adopt the response-level fusion method to integrate the two sets of response maps obtained by the multimodality-similar fusion information and the visual-similar information into a set of average response maps to predict the object position by using the transferred multimodality information jointly.
To prove the effectiveness of the response-level fusion method, we use the decision-level fusion method, which needs to directly average the final prediction results of the two subnetworks to replace the response-level fusion method in TMTNet to combine the multimodality-similar fusion information and visual-similar information and compare its performance with that of using the response-level fusion method. Among them, the TMTNet model with the decision-level fusion method is termed TMTNet_dec, and the TMTNet model with the response-level fusion method is termed TMTNet_res, which is the actual TMTNet model. The performance of the TMTNet model with different fusion methods is shown in
Table 6.
It is evident that the AUC score of the TMTNet_res tracker (69.9%) is over than that of the TMTNet_dec tracker (68.0%) by 1.9%, and the DP_20 value of the TMTNet_res tracker (92.8%) is higher than that of the TMTNet_dec tracker (90.7%) by 2.1%. Experimental results show that using the response-level fusion method in TMTNet to combine the transferred multimodality fusion information and the RGB modality information can effectively improve the tracking network’s performance.
4.5. Ablation Study
In this work, the proposed multimodality information transfer network for hyperspectral object tracking mainly includes the subject network and the spatial optimization module, which are adopted to transfer multimodality information and optimize object boundary estimation. There are two subnetworks in the subject network, including the multimodality fusion information transfer subnetwork and the RGB modality information transfer subnetwork, which are used to obtain multimodality-similar fusion information and visual-similar information from hyperspectral data, respectively, and then use the information mentioned above to predict the object location jointly. In this section, we validate the impact of each critical component of TMTNet on final performance. Among them, the multimodality fusion information transfer sub-network is labeled as
, the RGB modality information transfer subnetwork is labeled as
, and the spatial optimization module is marked as
. The ablation study results are listed in
Table 7. The model contains
,
, and
in
Table 7 is the complete TMTNet model.
It can be seen that the TMTNet model with and that adds the RGB modality information based on the transferred mutimodality fusion information, is 2.3% higher than the TMTNet only with , which only transfers the multi-modality fusion information in terms of the AUC score and 3.5% higher in terms of the DP_20 value. The AUC score of the TMTNet model that is adding to the TMTNet model with and (69.9%) outperforms the AUC score of the TMTNet model with and (67.7%) by (2.2%), and the DP_20 value of the TMTNet model with , and (92.8%) is more than the DP_20 value of the TMTNet model with and (92.7%) by (0.1%).
The results show that the proposed TMTNet model with the multimodality fusion information transfer subnetwork, the RGB information transfer subnetwork, and the spatial optimization module can effectively transfer the multimodality information in the hyperspectral tracking task and optimize object boundary estimation, indicating the designed critical components in the TMTNet model are useful for achieving the performance of the hyperspectral tracking improvement. Although adding components to the tracking model increases the computational complexity of the model and reduces the FPS, it is worth sacrificing a certain amount of calculation and running speed to achieve the model’s accuracy improvement in the preliminary exploration stage of hyperspectral object tracking. In the future, we will further explore hyperspectral tracking methods that reduce the model’s computational complexity while improving the algorithm’s accuracy performance, thus promoting the vigorous development of hyperspectral object tracking.





 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}