1. Introduction
Rubber, a tropical evergreen broad-leaved vegetation, originates from the Amazon basin forest of South America. As the only renewable green energy material among the four major industrial raw materials, rubber is known for its economic values and carbon sequestration potential [
1,
2]. With the increasing demand for rubber in national defense and latex production, the planting area of artificial rubber plantations has shown a trend of substantial growth and continuous expansion in tropical rainforest areas worldwide [
3,
4,
5,
6]. As of June 2022, the Association of Natural Rubber Producing Countries (ANRPC) reported that the global natural rubber production is 1.113 million tons, with an increase of 3.8% over the same period in 2021, while global consumption is expected to grow at a faster pace of 5.8% over the same period, to 1.206 million tons. Driven by market demand and the economy, rubber planting areas have been transplanted from traditional growing areas to and is now cultivated in almost all tropical zones (Malaysia, Laos, Myanmar, Thailand, Vietnam, Cambodia, etc.) in the past 20 years, with a transplanting area over 1 million square hectares [
7,
8,
9].
Xishuangbanna Dai Autonomous Prefecture (XSBN) lies in the core area of the “One Belt and One Road” policy, and its strategic location has constantly drawn attention. Moreover, short-term economic incentives, weak enforcement of regulations and suitable climate of rainy and hot conditions make XSBN the most important rubber cultivation area in China. Meanwhile, the Sloping Land Conversion Program (SLCP) in China clearly banned slope shifting cultivation and encouraged planting of trees, which also accelerated the replacement of shifting cultivation with rubber plantations from the valleys onto progressively higher and steeper slopes, and even into the Nature Reserves. During the last decades, the rubber plantation area ratio in XSBN has climbed from 1.3% in 1976 to 22.14% in 2014, and has become the most dominant land use type in the region [
10]. Compared with natural forests, commercial monoculture rubber plantations on steep highlands have many characteristics conducive to land degradation and environmental problems. First, it is more difficult for newly reclaimed rubber plantations on slopes to achieve long-term vegetation cover stability; since rubber has only one species and a simple vegetation structure, the interception of rainfall by covers becomes weak, leading to high soil erosion risk and reduced soil productivity. Second, the low water keeping capacity of the soil makes it vulnerable to climate change and human activities. Third, exotic monoculture rubber plantations are ’forests’ indeed, but are intensively managed, treated with fertilizers, herbicides and fungicides and negative to biodiversity [
11,
12,
13]. Despite the fact that cultivation of rubber could act as a carbon sink by sequestering carbon in biomass and indirectly in soils; however, for most cases, the sharp growth of rubber and the drastic land use change process (mainly from natural forests to rubber plantations) also resulted in a series of ecological and environmental problems, such as the weakening ecosystem deforestation, fragmentation of the remaining forest, land degradation and biodiversity loss [
14,
15]. Therefore, it is of great significance to acquire accurate information on the dynamic expansion process and spatial-temporal distribution pattern on rubber plantations to achieve a sustainable development goal.
Traditional monitoring approaches for rubber plantations are mainly based on field investigation, which are expensive and time-consuming, and continuous monitoring is difficult to achieve due to the poor timeliness of the data [
16]. Remote sensing is a science and technology that detects, analyzes and studies the earth’s resources and environment based on the interaction between electromagnetic waves and the earth’s surface materials, and reveals the spatial distribution and dynamic change characteristics of various elements on the earth’s surface [
17]. Due to the advantages of strong timeliness and little human interference, it has been frequently employed in research such as LUCC, crop identification and vegetation phenology monitoring [
18,
19,
20,
21,
22,
23,
24]. Although remote sensing technology has become a widespread approach in rubber plantations mapping [
25], the majority of studies are still in the exploratory stage and the following obstacles remain unsolved: (1) Rubber is an evergreen broad-leaved vegetation, the spectral characteristics of which are easily mixed with other vegetation types such as natural forests, tea plantations, orchards and shrubs [
26], and both supervised and unsupervised classification methods rely on spectral characteristics, which are fraught with uncertainty [
7,
27]. (2) It has been demonstrated that for rubber in the tropical northern fringe area, south of the Tropic of Cancer, a unique phenomenon of leaf fall will take place under low temperature environment during the dry season [
28,
29,
30]. The emergence of this phenology feature provides a new idea for the effective identification of rubber plantations. Relevant studies have been conducted and many results have been achieved based on phenology characteristics of MODIS time series data [
31,
32,
33]. However, the coarse spatial resolution (250 m–1000 m) of MODIS data has great limitations in plateau mountainous areas with complex terrain fragmentation, and difficult to identify rubber plantations with scattered distribution [
34,
35]. (3) The appearance of medium and high spatial resolution remote sensing images provides a new way to identify rubber plantations. Although Landsat series images were used to establish time series data for rubber information acquisition in some studies [
30,
36,
37,
38], still, frequent cloudy and rainy weather greatly reduces the availability of images since most rubber plantations are distributed in tropical or subtropical rainforest areas with mixed vegetation [
29,
35,
39]. It is unrealistic to establish long time series data only through optical images of a single sensor.
Compared with optical images, Synthetic Aperture Radar (SAR) is not affected by cloud and fog weather, possesses the properties of penetration and anti-interference, and can gather efficient ground observation data all day long [
40]. Some scholars extracted forests distribution according to different polarization modes of HH (horizontal emission and horizontal reception) and HV (horizontal emission and vertical reception) between forests and other vegetation types [
19,
28,
41,
42,
43,
44], confirming that SAR data have significant advantages in identifying tropical forests.
At present, the emergence of the cloud computing platform represented by Google Earth Engine (GEE) breaks the traditional way of remote sensing data acquisition and preprocessing. GEE has a powerful parallel computing ability and massive online remote sensing datasets, making it possible to conduct remote sensing research of large area, long time series and high spatial-temporal resolutions [
45].
Low spatial resolution remote sensing images have obvious limitations in mountainous regions with fragmented and complex terrain, making it difficult to identify rubber plantations with small planting area. Besides, affected by cloudy and rainy weather, a single satellite sensor cannot establish complete time series data. In this paper, we aim to address the above challenges of mapping rubber plantation areas in topographically and climatically complex settings. The specific objectives of this study are twofold: (1) Creating a rubber plantation map with a spatial resolution of 10 m using a pixel-based classification method integrated with phenology windows; (2) By combining the data with SAR, we hope to improve the mixing of different height vegetation (such as tea plantations and rubber plantations) and provide a reference for high-precision mapping and ecological protection of rubber plantations in southwestern China and Southeast Asian countries.
2. Materials and Methods
2.1. Study Area
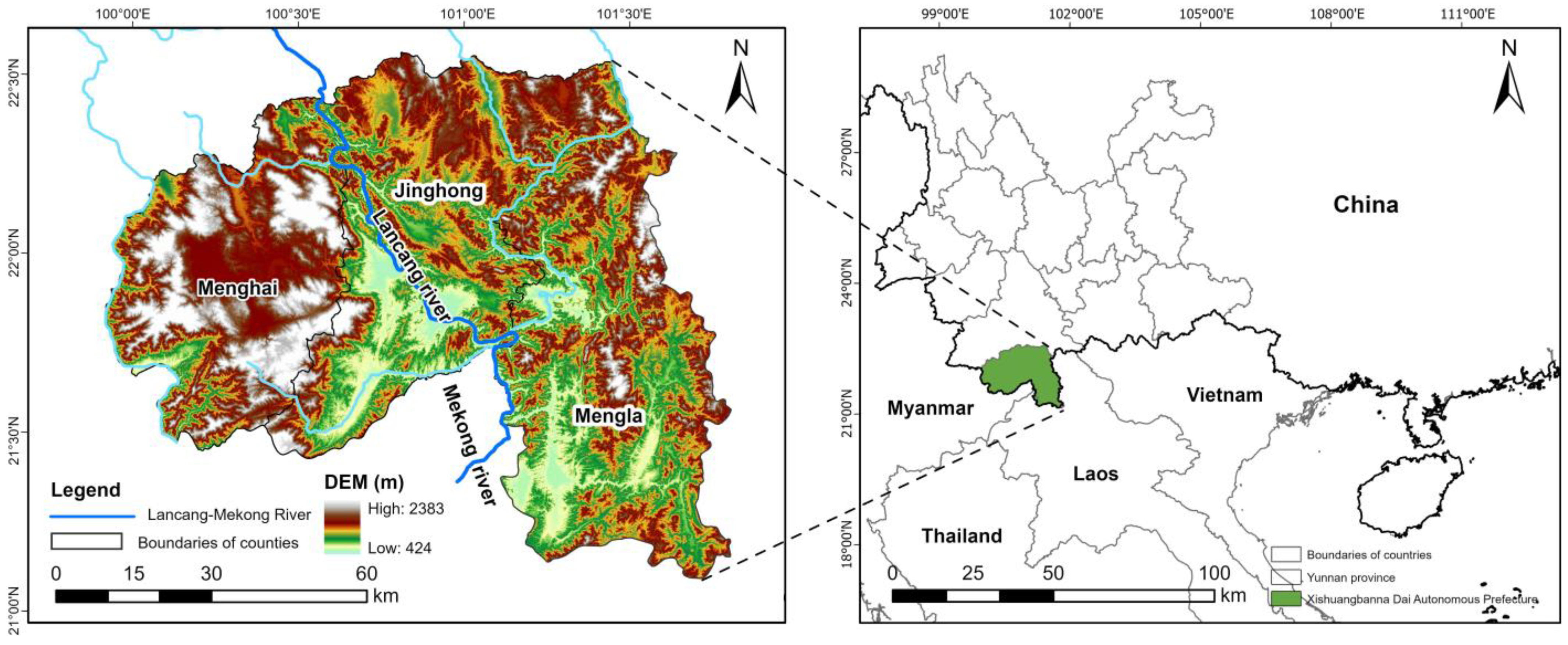
Xishuangbanna Dai Autonomous Prefecture (XSBN) lies in Yunnan Province, southwestern China, 21°08′–22°36′ N, 99°56′–101°50′ E, bordering Laos in the southeast and Myanmar in the southwest, with a national border of 996.3 km long. The Lancang-Mekong River flows through XSBN from north to south, and high mountains and deep valleys characterize the whole territory [
26], forming a landscape tilting from the north to the south [
46]. The highest altitude is 2429 m, the lowest altitude is 477 m and the relative height difference is close to 2000 m (
Figure 1). With the Lancang River as boundary, the landform structure in the eastern region is dominated by middle and low mountains and plateaus, and the remnants of the Nu Mountain Range in the west, mostly basin landforms [
47].
XSBN is located on the northern border of the tropics, south of the Tropic of Cancer, and has a humid monsoon climate typical of the northern tropics. Due to the staggered influence of terrain and monsoons, the climate is divided into two distinct dry and wet seasons, but no clear four seasons. The wet season extends from late May to late October, and the dry season last from late October to late May of the following year [
48,
49,
50]. The average annual rainfall ranges from 1138.6 to 2431.5 mm, with more than 80% of rainfall occurring during the rainy season [
51], and the average annual temperature is between 18.9–23.5 °C.
The study area is rich in biodiversity; as one of the few tropical regions in China, XSBN comprises only 0.2% of China’s land area, but harbors nearly 16% of plant species, 36.2% of birds, 22% of mammals and 15% of amphibian and reptiles found in the country [
52]. Distributed with the largest coverage area and the most abundant types of tropical seasonal rainforests and tropical mountainous rainforests, XSBN is also the region with the most complete preservation of tropical ecosystems in China [
53]. With a total administrative area of 19,124.5 km
2, the state consists of one metropolis, two counties and three districts. There are 13 ethnic minorities that make up 77.9% of the state’s total population, totaling 792,800 inhabitants [
46].
XSBN’s unique climate and geographical environment provide favorable circumstances for the development of rubber plantations. As the economic value of rubber has increased over the past decade, its cultivation area has expanded, and rubber has become the predominant land use and land cover (LULC) type and economic pillar industry in the region [
26].
2.2. Data Sources and Preprocessing
The GEE platform was applied to acquire and pre-process the remote sensing data that were used in the study. Due to the low availability of images caused by cloudy and rainy conditions in the highland mountains, two data sources, multispectral (MSI) and synthetic aperture radar (SAR), were used to combine the advantages of various sensors in terms of temporal and spatial resolution to obtain complete time-series data. MSI data products include Landsat-7/ETM+ surface reflectance (L7_SR), Landsat-8/OLI surface reflectance (L8_SR) and Sentinel-2 MSI surface reflectance (S2_SR).
L7_SR and L8_SR are 2A-level data products obtained by LEDAPS (Landsat Ecosystem Disturbance Adaptive Processing System) and LaSRC (Landsat Surface Reflectance Code) algorithms after atmospheric correction. With a resolution of 30 m, a revisit time of 16 d, and an amplitude of 185 km, the SR data products include the whole visible (VIS), near infrared (NIR) and shortwave infrared (SWIR) spectrum. Both sets of data extend from 1999 to the present, making it possible to conduct large-scale, long-term studies for LULC classification and vegetation phenology monitoring.
S2_SR is a 2A-level SR data product obtained after atmospheric and orthographic correction, including 13 spectral bands from VIS, NIR to SWIR, and the wavelength range is from 442.3 nm to 2202.4 nm. The spatial resolution is 10 m, 20 m and 60 m, the revisit period of one satellite is 10 d, the two satellites are complementary and the revisit period is 5 d. Because of its superiority in time, spatial and spectral resolution, Sentinel-2 imagery has been broadly applied for LULC classification and other vegetation identification [
23].
Benefiting from the calculation and data management mechanism of the GEE platform, the resolution matching between different data sources too much can be achieved [
40]. In this study, the spatial resolution of the Landsat data is 30 m, and the GEE platform can automatically sample to 10 m to match this resolution. At the same time, the coordinate system is unified through the embedded algorithm, so that each pixel can accurately represent the same range on the ground.
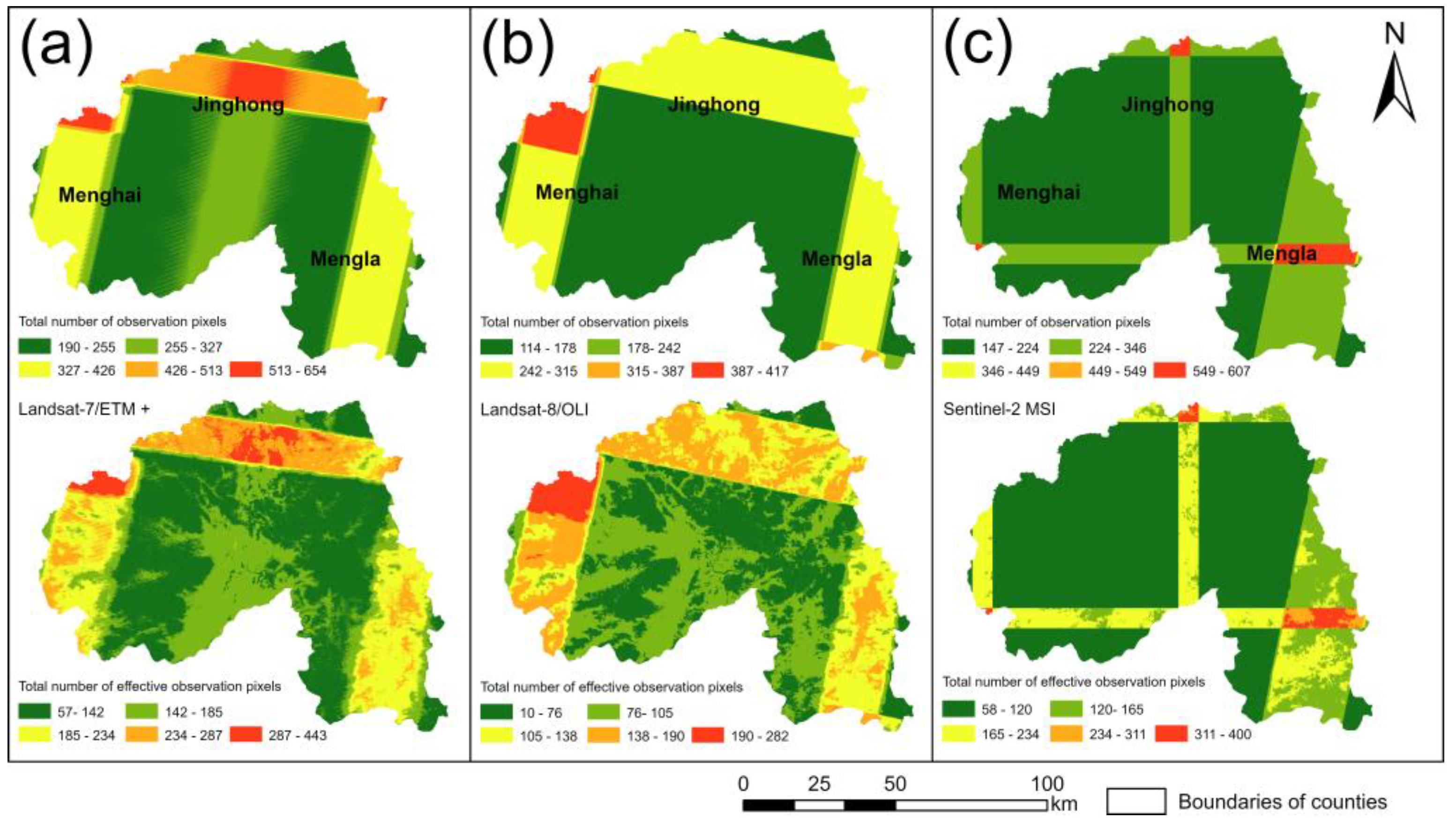
In order to obtain images that can cover the entire study area, the quantity and availability of pixels in three multispectral datasets were evaluated. Specifically, (i) spatial filtering: a 10 km buffer was generated first, and all images intersecting the buffer were filtered; (ii) temporal filtering: the image availability of Landsat-7/ETM+, Landsat-8/OLI and Sentinel-2, was considered and the time period was set from 2014 to 2020; (iii) attribute filtering: based on cloudy pixels percentage and the QA60 de-clouding band, the cloud mask function was used to eliminate cloud-influenced pixels from each image, and those with acceptable quality were used in the subsequent surface parameter computation. For the three data products, the final number of accessible images (
Table 1), the total number of observed pixels and the number of valid pixels (
Figure 2) were determined.
The SAR data employed are the Sentinel-1 SAR Ground Range Detected (S1_GRD) product, which is a first-level image dataset after Doppler Centroid Estimation, Single-Looking Composite (SLC) focusing and post-processing. There are four bands in each image, corresponding to four polarization combinations: horizontal transmit/horizontal receive (HH), horizontal transmit/vertical receive (HV), vertical transmit/vertical receive (VV) and vertical transmit/horizontal receive (VH), with a resolution of 10 m. Although SAR data were unaffected by rain and cloud cover, noise has a significant influence on data quality. We utilized the Sentinel-1 toolkit to further pre-process each scene image for speckle filtering, thermal noise removal, terrain correction and radiometric calibration [
54], with ALOS 12.5 m DEM data used for the terrain correction step. The rectified images were used to generate year-by-year time series data from 2014 to 2020, with the details of each data product listed in
Table 2.
ALOS 12.5 m DEM data (
https://search.earthdata.nasa.gov/search (accessed on 1 June 2022)) are collected from the ALOS (Advanced Land Observing Satellite) satellite equipped with PALSAR sensors and a horizontal/vertical accuracy of 12.5 m that may be used for all-weather, all-day land observation. The data were uploaded to the GEE platform as one of the key features for the acquisition of information on the spatial distribution of rubber plantations in our study.
Three non-homologous LULC products were prepared including: (1) ESA_2020_10m data product jointly produced by European Space Agency produced in collaboration with a number of global research institutions, (2) ESRI_Land_Cover_2020_10m data product produced using deep learning methods by Environmental Systems Research Institute and (3) Google’s near real-time 10 m resolution global LULC dataset Dynamic World generated from Tensorflow deep learning framework using GEE and AI platform, based on Sentinel-2 MSI image. The above three sets of products are used to determine the input sample type of the Random Forest classification algorithm, and the detailed information of each product is shown in
Table 3.
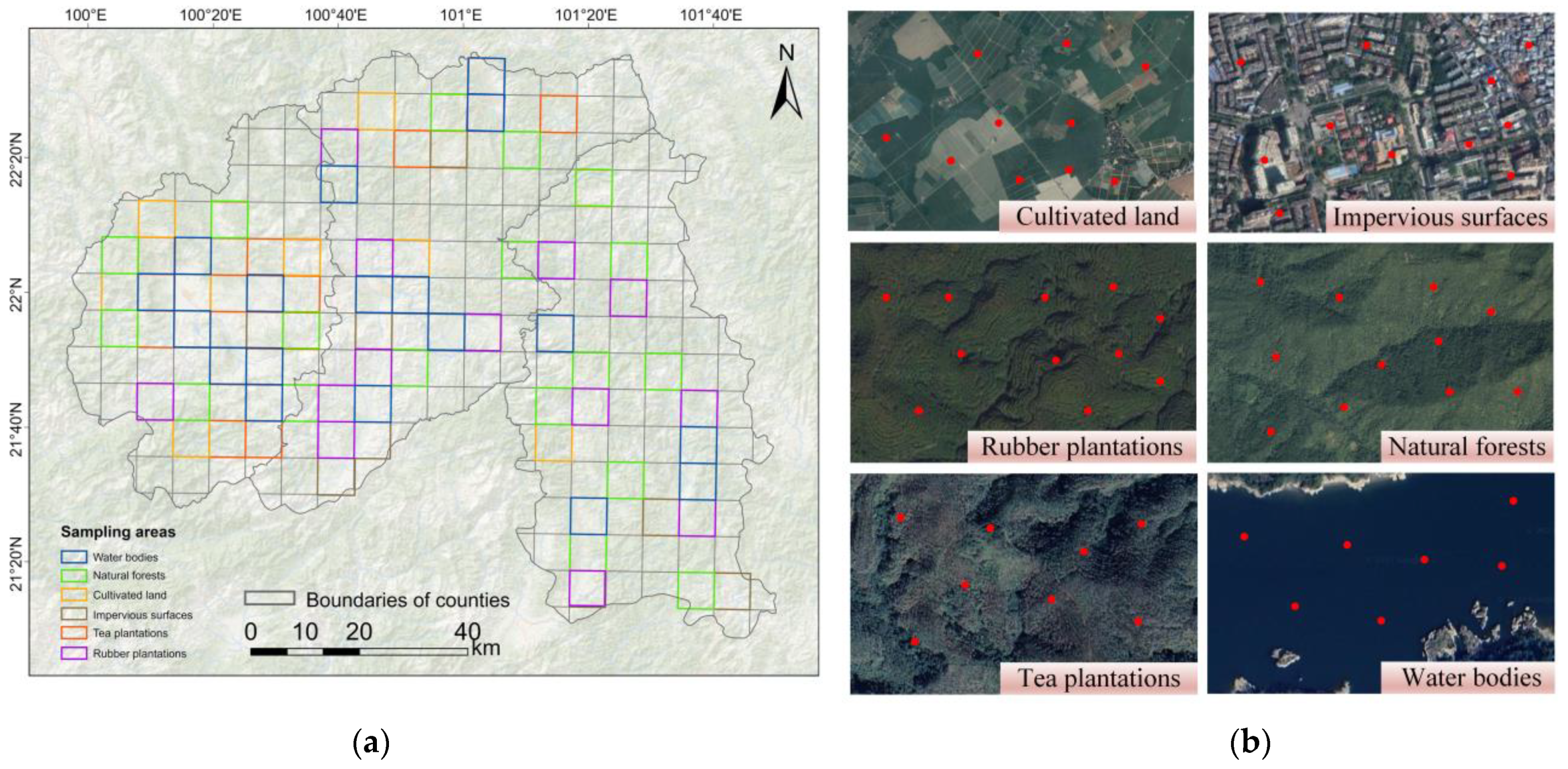
The sample data for training and validation was selected based on field investigation, Google Earth high-resolution remote sensing images, as well as the mentioned three LULC datasets. By using an integrated method of “stratified sampling + non-homogenous data voting” with visual interpretation, 6569 sample points were finally obtained, including 1051 natural forests, 843 cultivated land, 1000 tea plantations, 216 water bodies (rivers, lakes, reservoirs, etc.), 459 impervious surfaces (building lands, highways, etc.) and 3000 rubber plantations samples (
Figure 3 shows a part of the sample data). All the sample points that satisfied the requirements were randomly divided into 70% training sample data and 30% validation sample data for the Random Forest classification algorithm.
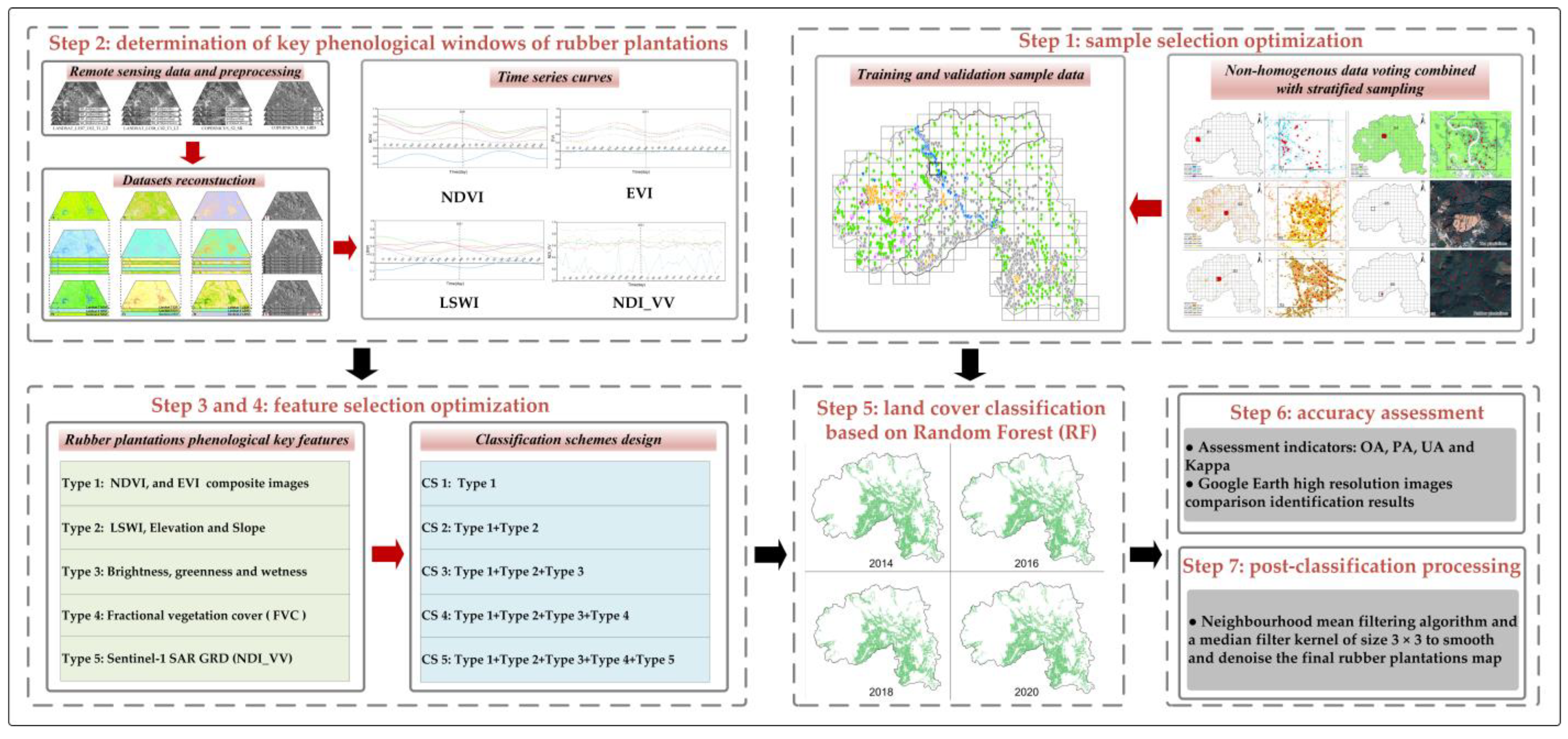
The overall workflow used for rubber plantations distribution identification in XSBN is presented in
Figure 4, and it consists of the following steps: (1) sample selection optimization; (2) determination of key phenology windows of rubber plantations; (3) input feature optimization; (4) classification schemes design; (5) Random Forest classification and validation; (6) accuracy assessment; (7) classification post-processing.
2.3. Sample Selection Optimization
In order to accurately identify the spatial distribution information of rubber plantations in XSBN, we optimized the method for selecting input samples. According to the actual situation of the study area, land use and land cover types were divided into six classes: natural forests, cultivated land, tea plantations, water bodies (river, lake, reservoir, etc.), impervious surfaces (construction land, road, etc.) and rubber plantations.
Non-rubber plantations sample points (with exception of tea plantations) were selected using a combination of “stratified sampling + non-homogeneous data voting” (
Figure 5), with pure image pixels of natural forests, cultivated land, tea plantations, water bodies, impervious surfaces and rubber plantations classification consistent across the three data products as the selection range (that is, all three non-homologous data products considered which as the same type). We randomly generated sample points within the range.
To avoid localized clustering of sample points, the study area was gridded in blocks of 10 km × 10 km based on the GEE platform’s online editing code. A fixed number of sample points were then randomly generated within each grid to ensure that the sample points were evenly distributed in the study area, and ineligible sample points within the grid were removed through visual interpretation.
As none of the above-mentioned three sets of products partitioned the tea plantations, the sample points of the tea plantations and rubber plantations were selected point-by-point in combination with Google Earth high-resolution, long time series remote sensing images as an auxiliary.
2.4. Determination of Key Phenological Windows of Rubber Plantations
We chose the Normalized Difference Vegetation Index (NDVI), which can effectively reflect the density and intensity of the vegetation growth process using the calculation between NIR band and Red band [
55]; the Enhanced Vegetation Index (EVI) is an optimized vegetation index that increases the sensitivity to high vegetation cover areas and enhances the ability to monitor vegetation canopy changes at the same time [
55,
56]; the Land Surface Water Index (LSWI) can effectively reflect plant canopy changes, soil moisture and soil surface water content status [
57], whereas the NDI_VV is extremely sensitive to vegetation canopy orientation, structural changes and leaf water content [
58,
59]. NDI_VV, for instance, can successfully distinguish vegetation, bare ground and building land; the particular formula and explanation of each index are provided in
Table 4.
On the basis of three sets of non-homologous LULC classification datasets and high-resolution Google Earth remote sensing images, 74 sampling areas were selected in the study area (
Figure 6), which contains 6 of the above land use and land cover classes. Since XSBN is located in a tropical rainforest with mixed vegetation and easily affected by cloud and rain, resulting in a low number of available images in the area, it is even more difficult to ensure the quality of remote sensing images during the rainy season (the vigorous vegetation growing season) from May to October. In order to solve the problem of incomplete multi-spectral coverage of the perennial time series data in the plateau and mountain areas, the three datasets L7_SR, L8_SR and S2_SR were reconstructed (
Figure 7a) and the time series curves of NDVI, EVI and LSWI were reconstructed by a Harmonic Analysis of Time Series (HANTS) [
60] (
Figure 7b).
2.5. Feature Selection Optimization
Figure 7b shows the annual dynamic changes of rubber plantation and other land use and land cover types in the four indexes of NDVI, EVI, LSWI and NDI_VV. Throughout the year, both natural forests and rubber plantations have high NDVI values, and their intra-annual curve variations are almost similar, showing a process of first a decline, then a rise and then a slow decline. The NDVI of natural forests dropped to the lowest value around July, and rose to the highest value around October. The NDVI values of rubber plantations, however, are second only to natural forests, and have obvious seasonal fluctuation characteristics. During the local rainy season, which lasts from late May to late October, the rubber grows vigorously and has a stable and high NDVI value; during the dry season, from November to May, the rubber enters a slow growth period and the NDVI value decreases gradually; during the dry and hot period, from early January to early February, the rubber experiences concentrated defoliation and the NDVI reaches its lowest value. From early February to mid-March, the rubber entered the new leaf germination stage, and the NDVI value began to rise. The EVI time series curves indicate that rubber has greater EVI values than natural forests throughout the year. From late January to late March, the spectral features of the two time series curves are similar; however, from late March to late December, the spectral features of the two time series curves differ significantly; this time period can be used to distinguish rubber from natural forests. The different intra-annual variability patterns of the LSWI time series curves of rubber plantations and natural forests may be utilized as an essential indication to distinguish between the two. The NDI_VV curves reveal that the natural forests curves basically do not fluctuate throughout the year, whereas the rubber and tea plantations, cultivated land and natural forests curves vary significantly from January to March. This time period can be used to differentiate between tea plantations, cultivated land and rubber plantations. The four time series curves all reflect that the spectral curves of water bodies and impervious surfaces are significantly different from those of other land types. The spectral curves of tea plantations and cultivated land have certain distinguishability with rubber plantations in different time periods.
To sum up, natural forests are the vegetation type that is most easily to be mixed with rubber, but the vegetation index of rubber in the defoliation and foliation period are significantly different from that of natural forests. Composite images of key phenological window periods of rubber were used as input features for the Random Forest classification algorithm to avoid the influence of feature redundancy on the classification results. With the help of GEE platform, the phenological period was further subdivided by median synthesis (
Table 4), while rubber defoliation during dry-hot periods in the dry season accounted for 73.87% of the annual defoliation [
26]. Therefore, FVC [
61] and Tasseled Cap Transformation (TCT) are added to the study to obtain the brightness (TCT-BRI), greenness (TCT-GRE) and wetness (TCT-WET) components [
62,
63,
64] to highlight the leaf fall characteristics during this period.
Table 5 displays the transformation coefficients [
65] used in our study.
2.6. Random Forest (RF) Algorithm
Random Forest algorithm is a machine learning algorithm that can predict hundreds of explanatory variables, and it employs decision trees as units to aggregate numerous decision trees for classification, allowing for the categorization of vast quantities of higher-dimensional data [
66]. Compared with other classification algorithms, Random Forest algorithm has the advantage of efficient training and less prone to overfitting. Furthermore, the algorithm implicitly includes discriminant weights for the classification effect of each metric to highlight features those are advantageous for classification [
40].
2.7. Accuracy Assessment
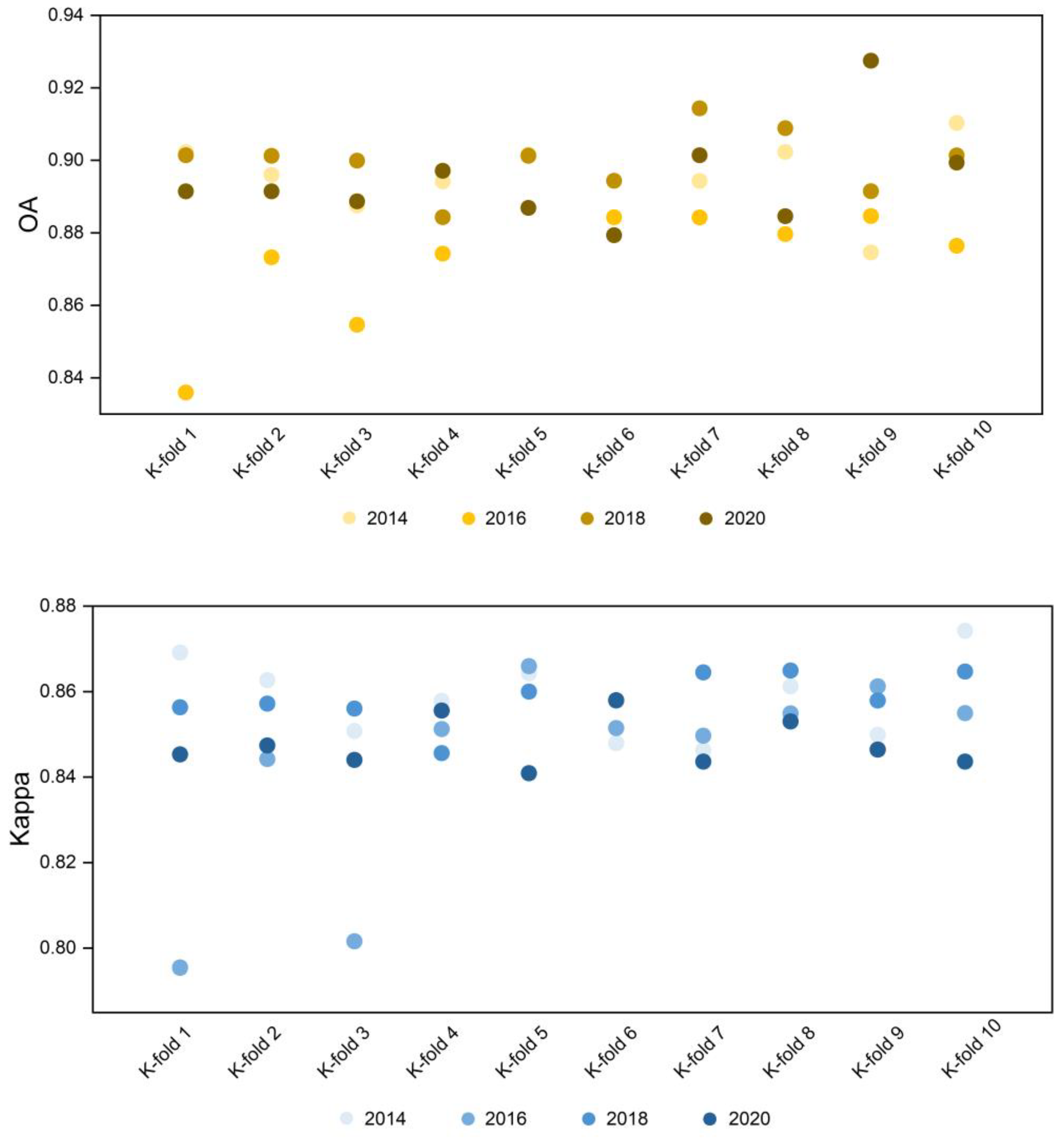
On the basis of validation sample data (
Figure 3), a confusion matrix was utilized to compute OA, PA, UA and Kappa [
67]. The four evaluation indexes were utilized to examine the outcomes of rubber plantations identification. The OA and Kappa indices were used to assess the overall score accuracy, while PA and UA were used to assess the misclassification and omission errors among the LULC types [
68], which were computed as follows:
where
refers to the pixels;
is the total number of pixels;
is the total number of diagonal pixels of the confusion matrix;
is the number of classes in the confusion matrix;
is the sum of row pixels of a class in the confusion matrix;
is the sum of column pixels of a class in the confusion matrix.
2.8. Post-Classification Processing
The Random Forest classification algorithm is based on pixel-by-pixel classification; hence, the ’Salt and Pepper’ phenomenon is difficult to avoid (when the pixels within a single land type are identified as other classes) [
69]. In order to reduce the influence of noise on the classification results, we adopted the neighborhood mean filter algorithm, and sets a 3 × 3 median filter kernel to smooth and denoise the final rubber plantations identification results to eliminate the impact.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}