

An Integrated Method for Road Crack Segmentation and Surface Feature Quantification under Complex Backgrounds


Abstract
1. Introduction
- An integrated framework for road crack detection and quantification at the pixel level is proposed. Compared with previous crack detection and segmentation algorithms, the framework enables more accurate detection, segmentation, and quantification of road cracks in complex backgrounds, where various common realistic interferences, such as vehicles, plants, buildings, shadows, or dark light conditions, can be found;
- An attention gate module is embedded in the original Res-UNet to effectively improve the accuracy of road crack segmentation. Compared with YOLACT++ and DeepLabv3+ algorithms, the modified Res-UNet shows higher segmentation accuracy;
- A new surface feature quantification algorithm is developed to accurately detect the length and width of segmented road cracks. Compared with the conventional DTM method, the developed algorithm can effectively prevent problems such as local branching and end discontinuity.
2. Methodology
2.1. YOLOv5 for Road Crack Detection
2.2. Modified Res-UNet for Crack Region Segmentation
2.2.1. Attention Gate
2.2.2. Combined Loss
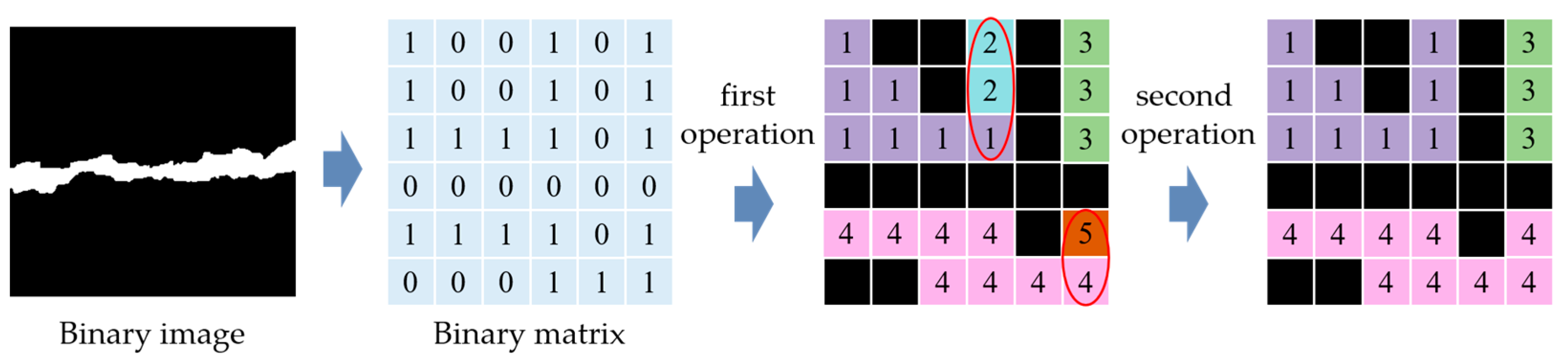
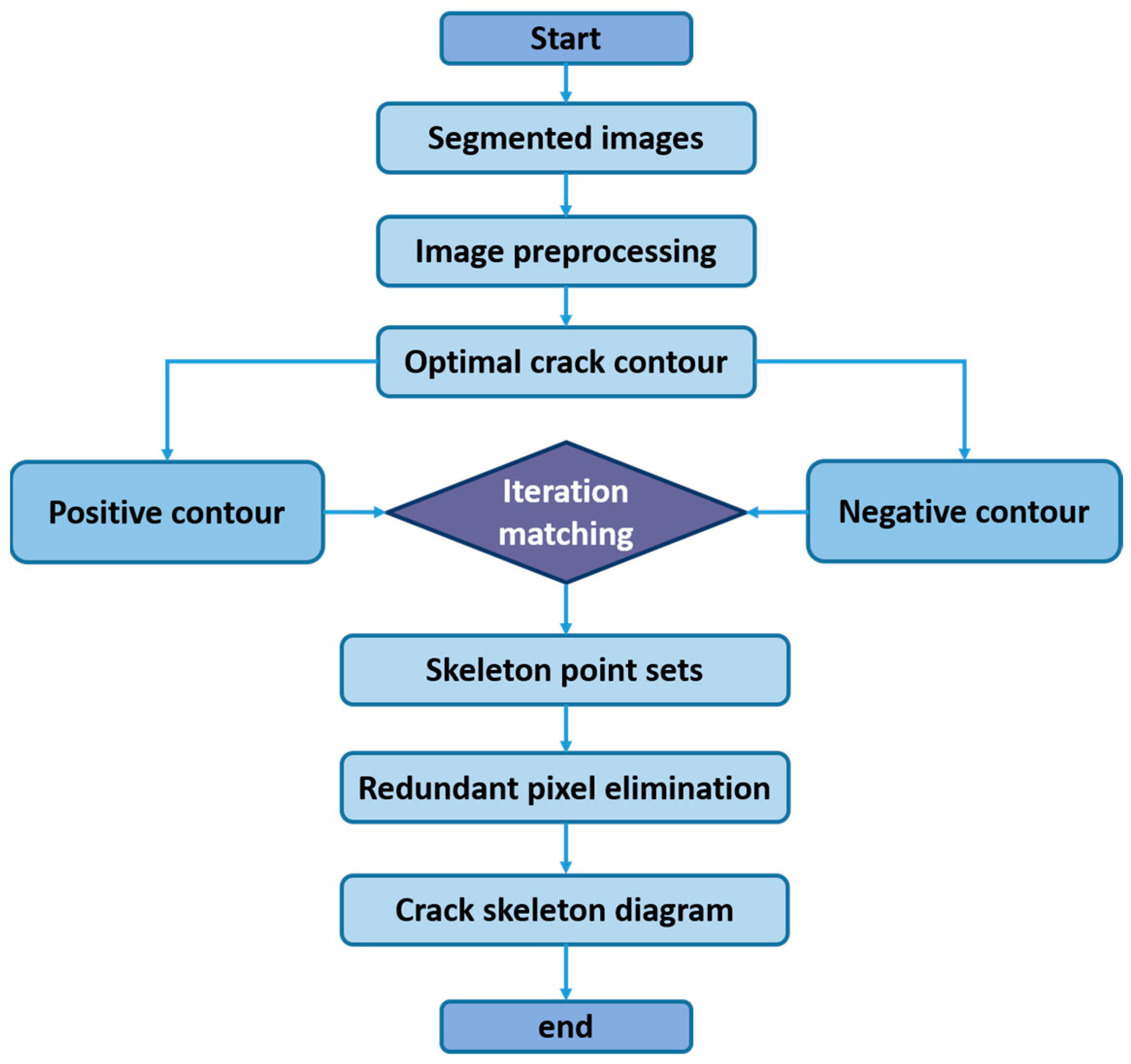
2.3. Novel Algorithm for Crack Quantification
3. Implementation Details
3.1. Datasets
3.2. Training Configuration
3.3. Evaluation Metrics
4. Experiment Results and Discussion
4.1. Road Crack Detection
4.2. Region Crack Segmentation
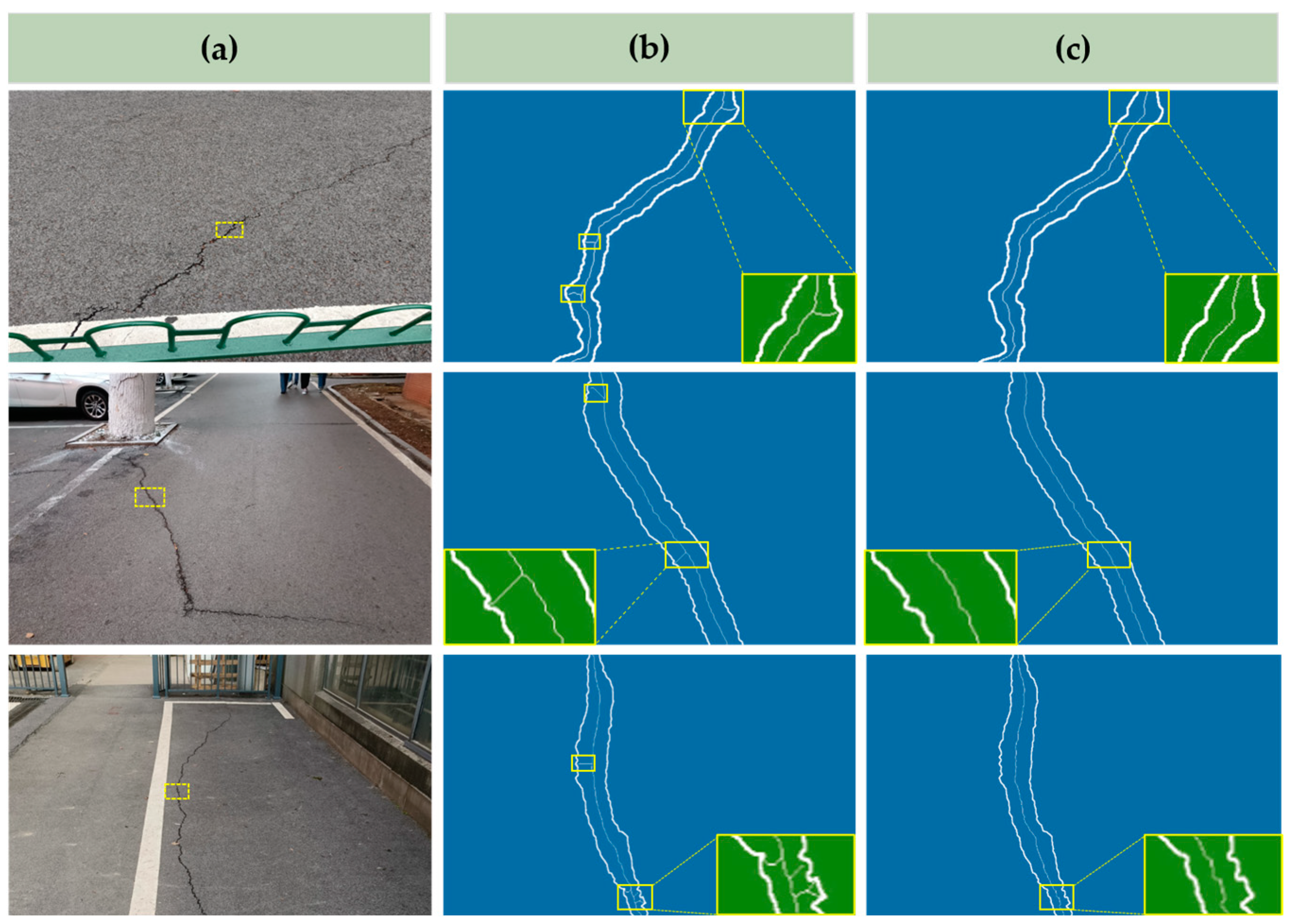
4.3. Quantification of Crack Surface Feature
4.4. Limitations and Future Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- National Bureau of Statistics. National Data. Available online: https://data.stats.gov.cn/ (accessed on 1 January 2022).
- The State Council. Policy Analyzing. Available online: http://www.gov.cn/zhengce/2022-05/11/content_5689580.htm (accessed on 11 May 2022).
- Ministry of Transport and Logistic Services. Road Maintenance. Available online: https://mot.gov.sa/en/Roads/Pages/RoadsMaintenance.aspx (accessed on 15 September 2022).
- Kee, S.-H.; Zhu, J. Using Piezoelectric Sensors for Ultrasonic Pulse Velocity Measurements in Concrete. Smart Mater. Struct. 2013, 22, 115016. [Google Scholar] [CrossRef]
- Zoidis, N.; Tatsis, E.; Vlachopoulos, C.; Gotzamanis, A.; Clausen, J.S.; Aggelis, D.G.; Matikas, T.E. Inspection, Evaluation and Repair Monitoring of Cracked Concrete Floor Using NDT Methods. Constr. Build. Mater. 2013, 48, 1302–1308. [Google Scholar] [CrossRef]
- Li, J.; Deng, J.; Xie, W. Damage Detection with Streamlined Structural Health Monitoring Data. Sensors 2015, 15, 8832–8851. [Google Scholar] [CrossRef] [PubMed]
- Dery, L.; Jelnov, A. Privacy–Accuracy Consideration in Devices that Collect Sensor-Based Information. Sensors 2021, 21, 4684. [Google Scholar] [CrossRef] [PubMed]
- Jiang, S.; Zhang, J.; Wang, W.; Wang, Y. Automatic Inspection of Bridge Bolts Using Unmanned Aerial Vision and Adaptive Scale Unification-Based Deep Learning. Remote Sens. 2023, 15, 328. [Google Scholar] [CrossRef]
- Fiorentini, N.; Maboudi, M.; Leandri, P.; Losa, M.; Gerke, M. Surface Motion Prediction and Mapping for Road Infrastructures Management by PS-Insar Measurements and Machine Learning Algorithms. Remote Sens. 2020, 12, 3976. [Google Scholar] [CrossRef]
- Zhu, Y.; Tang, H. Automatic Damage Detection and Diagnosis for Hydraulic Structures Using Drones and Artificial Intelligence Techniques. Remote Sens. 2023, 15, 615. [Google Scholar] [CrossRef]
- Chen, M.; Tang, Y.; Zou, X.; Huang, K.; Li, L.; He, Y. High-Accuracy Multi-Camera Reconstruction Enhanced by Adaptive Point Cloud Correction Algorithm. Opt. Lasers Eng. 2019, 122, 170–183. [Google Scholar] [CrossRef]
- Al Duhayyim, M.; Malibari, A.A.; Alharbi, A.; Afef, K.; Yafoz, A.; Alsini, R.; Alghushairy, O.; Mohsen, H. Road Damage Detection Using the Hunger Games Search with Elman Neural Network on High-Resolution Remote Sensing Images. Remote Sens. 2022, 14, 6222. [Google Scholar] [CrossRef]
- Lee, T.; Yoon, Y.; Chun, C.; Ryu, S. CNN-Based Road-Surface Crack Detection Model that Responds to Brightness Changes. Electronics 2021, 10, 1402. [Google Scholar] [CrossRef]
- Zhong, J.; Zhu, J.; Huyan, J.; Ma, T.; Zhang, W. Multi-Scale Feature Fusion Network for Pixel-Level Pavement Distress Detection. Autom. Constr. 2022, 141, 104436. [Google Scholar] [CrossRef]
- Hacıefendioğlu, K.; Başağa, H.B. Concrete Road Crack Detection Using Deep Learning-Based Faster R-Cnn Method. Iran. J. Sci. Technol. Trans. Civ. Eng. 2022, 46, 1621–1633. [Google Scholar] [CrossRef]
- Que, Y.; Dai, Y.; Ji, X.; Leung, A.K.; Chen, Z.; Tang, Y.; Jiang, Z. Automatic Classification of Asphalt Pavement Cracks Using A Novel Integrated Generative Adversarial Networks and Improved Vgg Model. Eng. Struct. 2023, 277, 115406. [Google Scholar] [CrossRef]
- Du, Y.; Pan, N.; Xu, Z.; Deng, F.; Shen, Y.; Kang, H. Pavement Distress Detection and Classification Based on YOLO Network. Int. J. Pavement Eng. 2021, 22, 1659–1672. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. Yolov6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Ultralytics. Yolov8. Available online: https://github.com/ultralytics/ultralytics (accessed on 12 January 2023).
- Liu, C.; Sui, H.; Wang, J.; Ni, Z.; Ge, L. Real-Time Ground-Level Building Damage Detection Based on Lightweight and Accurate Yolov5 Using Terrestrial Images. Remote Sens. 2022, 14, 2763. [Google Scholar] [CrossRef]
- Shokri, P.; Shahbazi, M.; Nielsen, J. Semantic Segmentation and 3d Reconstruction of Concrete Cracks. Remote Sens. 2022, 14, 5793. [Google Scholar] [CrossRef]
- An, Q.; Chen, X.; Wang, H.; Yang, H.; Yang, Y.; Huang, W.; Wang, L. Segmentation of Concrete Cracks by Using Fractal Dimension and Uhk-Net. Fractal Fract. 2022, 6, 95. [Google Scholar] [CrossRef]
- Zhang, Y.; Fan, J.; Zhang, M.; Shi, Z.; Liu, R.; Guo, B. A Recurrent Adaptive Network: Balanced Learning for Road Crack Segmentation with High-Resolution Images. Remote Sens. 2022, 14, 3275. [Google Scholar] [CrossRef]
- Yong, P.; Wang, N. RIIAnet: A Real-Time Segmentation Network Integrated with Multi-Type Features of Different Depths for Pavement Cracks. Appl. Sci. 2022, 12, 7066. [Google Scholar] [CrossRef]
- Sun, X.; Xie, Y.; Jiang, L.; Cao, Y.; Liu, B. DMA-Net: Deeplab with Multi-Scale Attention for Pavement Crack Segmentation. IEEE Trans. Intell. Transp. Syst. 2022, 23, 18392–18403. [Google Scholar] [CrossRef]
- Shen, Y.; Yu, Z.; Li, C.; Zhao, C.; Sun, Z. Automated Detection for Concrete Surface Cracks Based on Deeplabv3+ BDF. Buildings 2023, 13, 118. [Google Scholar] [CrossRef]
- Ji, A.; Xue, X.; Wang, Y.; Luo, X.; Xue, W. An Integrated Approach to Automatic Pixel-Level Crack Detection and Quantification of Asphalt Pavement. Autom. Constr. 2020, 114, 103176. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Zhu, Z.; German, S.; Brilakis, I. Visual Retrieval of Concrete Crack Properties for Automated Post-Earthquake Structural Safety Evaluation. Autom. Constr. 2011, 20, 874–883. [Google Scholar] [CrossRef]
- Kang, D.; Benipal, S.S.; Gopal, D.L.; Cha, Y.-J. Hybrid Pixel-Level Concrete Crack Segmentation and Quantification Across Complex Backgrounds Using Deep Learning. Autom. Constr. 2020, 118, 103291. [Google Scholar] [CrossRef]
- Tang, Y.; Huang, Z.; Chen, Z.; Chen, M.; Zhou, H.; Zhang, H.; Sun, J. Novel Visual Crack Width Measurement Based on Backbone Double-Scale Features for Improved Detection Automation. Eng. Struct. 2023, 274, 115158. [Google Scholar] [CrossRef]
- Zhang, T.Y.; Suen, C.Y. A Fast Parallel Algorithm for Thinning Digital Patterns. Commun. ACM 1984, 27, 236–239. [Google Scholar] [CrossRef]
- Guizilini, V.; Li, J.; Ambruș, R.; Gaidon, A. Geometric Unsupervised Domain Adaptation for Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 8537–8547. [Google Scholar]
- Toldo, M.; Michieli, U.; Zanuttigh, P. Unsupervised Domain Adaptation in Semantic Segmentation via Orthogonal and Clustered Embeddings. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikola, HI, USA, 3–7 January 2021; pp. 1358–1368. [Google Scholar]
- Stan, S.; Rostami, M. Unsupervised Model Adaptation for Continual Semantic Segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, online, 2–9 February 2021; pp. 2593–2601. [Google Scholar]
- Marsden, R.A.; Wiewel, F.; Döbler, M.; Yang, Y.; Yang, B. Continual Unsupervised Domain Adaptation for Semantic Segmentation Using A Class-Specific Transfer. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar]
- Zhu, J.; Zhong, J.; Ma, T.; Huang, X.; Zhang, W.; Zhou, Y. Pavement Distress Detection Using Convolutional Neural Networks with Images Captured via UAV. Autom. Constr. 2022, 133, 103991. [Google Scholar] [CrossRef]
- Ruiqiang, X. YOLOv5s-GTB: Light-Weighted and Improved Yolov5s for Bridge Crack Detection. arXiv 2022, arXiv:2206.01498. [Google Scholar]
- Jing, Y.; Ren, Y.; Liu, Y.; Wang, D.; Yu, L. Automatic Extraction of Damaged Houses by Earthquake Based on Improved YOLOv5: A case study in Yangbi. Remote Sens. 2022, 14, 382. [Google Scholar] [CrossRef]
- Ultralytics. Yolov5. Available online: https://github.com/ultralytics/yolov5 (accessed on 17 January 2022).
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 1, pp. 2117–2125. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid Attention Network for Semantic Segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999 2018. [Google Scholar]
- Hou, H.; Lan, C.; Xu, Q.; Lv, L.; Xiong, X.; Yao, F.; Wang, L. Attention-Based Matching Approach for Heterogeneous Remote Sensing Images. Remote Sens. 2023, 15, 163. [Google Scholar] [CrossRef]
- Lee, T.C.; Kashyap, R.L.; Chu, C.N. Building Skeleton Models via 3-D Medial Surface Axis Thinning Algorithms. Graph. Models Image Process. 1994, 56, 462–478. [Google Scholar] [CrossRef]
- Home—OpenCV. Available online: https://opencv.org (accessed on 1 November 2021).
- Pytorch. Available online: https://pytorch.org/ (accessed on 15 June 2021).
- Arya, D.; Maeda, H.; Ghosh, S.K.; Toshniwal, D.; Sekimoto, Y. RDD2020: An Annotated Image Dataset for Automatic Road Damage Detection Using Deep Learning. Data Brief 2021, 36, 107133. [Google Scholar] [CrossRef] [PubMed]
- Road-Crack-Images-Test. Available online: https://www.kaggle.com/datasets/andada/road-crack-imagestest (accessed on 25 January 2023).
- Eisenbach, M.; Stricker, R.; Seichter, D.; Amende, K.; Debes, K.; Sesselmann, M.; Ebersbach, D.; Stoeckert, U.; Gross, H.-M. How to Get Pavement Distress Detection Ready for Deep Learning? A Systematic Approach. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 2039–2047. [Google Scholar] [CrossRef]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic Road Crack Detection Using Random Structured Forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Zou, Q.; Cao, Y.; Li, Q.; Mao, Q.; Wang, S. Cracktree: Automatic Crack Detection from Pavement Images. Pattern Recognit. Lett. 2012, 33, 227–238. [Google Scholar] [CrossRef]
- Feiyu. Vimble 3. Available online: https://www.feiyu-tech.cn/vimble-3/ (accessed on 23 March 2022).
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. YOLACT++: Better Real-Time Instance Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 1108–1121. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Zhu, Y.; Papandreou, G. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Zhang, L.; Shen, J.; Zhu, B. A Research on An Improved Unet-Based Concrete Crack Detection Algorithm. Struct. Health Monit. 2021, 20, 1864–1879. [Google Scholar] [CrossRef]
- Liu, F.; Wang, L. Unet-Based Model for Crack Detection Integrating Visual Explanations. Constr. Build. Mater. 2022, 322, 126265. [Google Scholar] [CrossRef]
- Radopoulou, S.C.; Brilakis, I. Automated Detection of Multiple Pavement Defects. J. Comput. Civ. Eng. 2017, 31, 04016057. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training | Validation | Test | |
|---|---|---|---|
| (a) YOLOv5 | |||
| Number of images | 2200 | 240 | 120 |
| Resolution | 1280 × 1280 | 1280 × 1280 | 1920 × 1080, 4032 × 3024 |
| (b) Modified Res-UNet | |||
| Number of images | 3800 | 360 | 120 |
| Resolution | 448 × 448 | 448 × 448 | 307 × 706, 908 × 129 et al. |
| Model | Threshold | IoU (%) | PA (%) | DICE (%) |
|---|---|---|---|---|
| UNet | 0.5 | 78.63 | 90.41 | 85.28 |
| Res-UNet | 80.30 | 92.06 | 87.08 | |
| CrackUNet15 | 83.89 | 94.63 | 89.21 | |
| CrackUNet19 | 84.78 | 95.86 | 90.49 | |
| UNet-VGG19 | 84.53 | 95.41 | 90.26 | |
| UNet-InceptionResNetv2 | 83.98 | 94.72 | 89.54 | |
| UNet-EfficientNetb3 | 84.36 | 95.16 | 90.01 | |
| Modified Res-UNet | 87.00 | 98.47 | 93.14 |
| YOLACT++ | DeepLabv3+ | Proposed Approach | |
|---|---|---|---|
| Training data | Public | Public | Public |
| Label type | Pixel mask | Pixel mask | Bounding box + Pixel mask |
| Testing data | self-collected | self-collected | self-collected |
| Test data | 120 | 120 | 120 |
| PA (%) | 63.24 | 72.32 | 98.47 |
| DICE (%) | 57.21 | 64.49 | 93.14 |
| Average IoU (%) | 48.02 | 57.14 | 87.00 |
| Instance | Ground Truth | Predicted Result | Error |
|---|---|---|---|
| Crack-1 | (3, 7, 152) * | (2, 7, 150) | (1, 0, 2) |
| Crack-2 | (4, 11, 224) | (4, 11, 223) | (0, 0, 1) |
| Crack-3 | (3, 17, 267) | (2, 18, 264) | (1, 1, 3) |
| Crack-4 | (4, 26, 110) | (4, 24, 105) | (0, 2, 5) |
| Crack-5 | (2, 20, 145) | (2, 19, 143) | (0, 1, 2) |
| Crack-6 | (2, 11, 201) | (2, 10, 197) | (0, 1, 4) |
| Crack-7 | (3, 134) | (3, 131) | (0, 3) |
| Crack-8 | (8, 17, 297) | (7, 19, 296) | (1, 2, 1) |
| Crack-9 | (14, 21, 129) | (16, 19, 126) | (2, 2, 3) |
| Crack-10 | (9, 33, 276) | (9, 31, 274) | (0, 2, 2) |
| Crack-11 | (7, 8, 277) | (5, 8, 275) | (2, 0, 2) |
| Crack-12 | (4, 13, 56) | (3, 12, 57) | (1, 1, 1) |
| Crack-13 | (3, 9, 298) | (3, 8, 297) | (0, 1, 1) |
| Crack-14 | (9, 17, 335) | (7, 15, 332) | (2, 2, 3) |
| Crack-15 | (4, 7, 227) | (4, 8, 223) | (0, 1, 4) |
| Crack-16 | (8, 3, 124) | (8, 3, 122) | (0, 0, 2) |
| Crack-17 | (4, 7, 378) | (4, 8, 374) | (0, 1, 4) |
| Crack-18 | (12, 9, 194) | (13, 9, 195) | (1, 0, 1) |
| Crack-19 | (5, 6, 325) | (5, 7, 321) | (0, 1, 4) |
| Crack-20 | (3, 4, 102) | (3, 5, 100) | (0, 1, 2) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, L.; Zhang, A.; Guo, J.; Liu, Y. An Integrated Method for Road Crack Segmentation and Surface Feature Quantification under Complex Backgrounds. Remote Sens. 2023, 15, 1530. https://doi.org/10.3390/rs15061530
Deng L, Zhang A, Guo J, Liu Y. An Integrated Method for Road Crack Segmentation and Surface Feature Quantification under Complex Backgrounds. Remote Sensing. 2023; 15(6):1530. https://doi.org/10.3390/rs15061530
Chicago/Turabian StyleDeng, Lu, An Zhang, Jingjing Guo, and Yingkai Liu. 2023. "An Integrated Method for Road Crack Segmentation and Surface Feature Quantification under Complex Backgrounds" Remote Sensing 15, no. 6: 1530. https://doi.org/10.3390/rs15061530
APA StyleDeng, L., Zhang, A., Guo, J., & Liu, Y. (2023). An Integrated Method for Road Crack Segmentation and Surface Feature Quantification under Complex Backgrounds. Remote Sensing, 15(6), 1530. https://doi.org/10.3390/rs15061530