1. Introduction
Rice is one of the most important food crops worldwide, especially in Asian countries, where it plays a crucial role in diets. According to statistics, more than 3 billion people rely on rice as their primary source of food, and rice production accounts for nearly 20% of the world’s total grain output. Additionally, rice is a major export commodity for many countries and regions and has significant impacts on local economies and trade [
1]. Rice disease is one of the main factors affecting the high quality, efficiency, and yield of rice, so the recognition of rice diseases is an important method to protect food security.
The traditional method of rice disease recognition relies on visual observation and monitoring by plant protection specialists. However, this method requires experienced rice specialists, and long periods of monitoring are costly on large farms. The shortage of rice specialists, especially in developing countries, prevents effective and timely rice disease control.
With the development of artificial intelligence technology, researchers at home and abroad have successfully applied machine learning methods to the automatic recognition and identification of crop diseases. For example, image processing-based techniques have been used for rice disease detection and recognition with high recognition accuracy [
2,
3] involving support vectors [
4,
5],
k-Nearest Neighbor [
6], and decision trees [
7]. Nevertheless, these methods have disadvantages, such as difficulties in implementation for large-scale training samples and solving multiple classification issues and sensitivity to the selection of parameters, which hinder the further improvement of the recognition effect. Significant breakthroughs in deep learning have been achieved with better results in recent years, which include convolutional neural (CNNs) networks [
8,
9] and migration learning [
4,
10] for image recognition.
Recently, deep learning has become a key technology for big data intelligence [
11] and has been successfully applied to tasks of plant disease identification and classification. Compared with classical machine learning methods, deep learning has a more complex model structure with more powerful feature extraction capabilities. In [
12], depthwise separable convolution was proposed for crop disease detection. Experimentally tested on a subset of the PlantVillage dataset, Reduced MobileNet achieved a classification accuracy of 98.34%, with a lower number of parameters than VGG and MobileNet. In [
13], aiming at low power consumption and low performance of small devices, a depth-wise separable convolution (DSC)-based PLD (DSCPLD) recognition framework was proposed, which was tested on rice disease datasets, and the accuracy of using S-modified MobileNet and F-modified MobilNet reached 98.53% and 95.53%, respectively. In [
4], the model for the classification of rice leaf disease images by ResNet-50 combined with the SVM method achieved an F1 score of 98.38%. In [
14], to improve the accuracy of existing rice disease diagnosis, VGG-16 and GooLeNet models were used to train on a dataset of three painless species of diseases, and the experimental results showed that the average classification accuracies of VGG-16 and GoogLeNet were 92.24% and 91.28%, respectively. In [
15], the authors constructed a novel rice blast recognition method based on CNN to identify 90% of diseased leaves and 86% of healthy leaves, respectively. Although the above methods achieve accurate recognition of rice diseases, deep learning techniques need to include large datasets that satisfy various criteria to obtain better recognition results. Note that using limited image datasets for training can lead to the overfitting of model training [
16]. That is to say, training dataset size has a large impact on deep learning-based disease recognition methods, and their performance will be severely degraded in the case of small samples, uneven data distribution, etc. [
17,
18].
A strategy to solve the data shortage is to convert the original data to generate artificial data, which is usually called data augmentation. Data augmentation is achieved by executing geometric transformations, noise addition, interpolation, color transformation, and other operations on the original data. Common structures in convolutional neural networks include pooling layers, strided convolutions, and downsampling layers. When the position of the input image changes, the output tensor may change drastically. Therefore, convolutional neural networks may misclassify images that have undergone image processing transformations. This type of transformation can be used to enhance small sample image datasets. However, this data augmentation method does not increase the diversity of image features in the original dataset but only exploits the design flaw of convolutional neural networks [
19]. Methods based on deep learning provide an effective and powerful way to learn the implicit representation of data distribution. Inspired by the zero-sum game in game theory, the Generative Adversarial Networks (GAN) model has been proposed in [
20], which can learn how to approach the true distribution of data and has powerful capabilities in image generation. The original GAN suffers from the problems of difficult convergence, training, and control of the model. To deal with these problems, the Wasserstein Generative Adversarial Network (WGAN) has been proposed in [
21] to solve the difficulty of training the original GAN. WGAN training is more stable and theoretically solves the pattern collapse and the gradient disappearance. Whereas WGAN causes issues such as gradient explosion when generating data due to direct weight cropping, which makes the model training unstable. Wasserstein Generative Adversarial Network with Gradient Penalized (WGAN-GP) was developed in [
22], a generative adversarial network that controls the gradient by gradient penalty to settle the matters of gradient explosion and pattern collapse.
At present, GAN has been employed effectively in the field of data enhancement. A method has been put forward in [
23] based on deep learning for tomato disease diagnostics that uses the conditional generative adversarial network (CGAN) to produce synthetic images of tomato plant leaves. The recognition accuracy of this method in the classification of tomato leaf images into 5, 7, and 10 categories is 99.51%, 98.65%, and 97.11%, respectively. An infrared image-generation approach was designed in [
24] depending on CGAN. This method can generate high-quality and reliable infrared image data. In [
25], a model combining CycleGAN and U-net has been constructed and applied to a small dataset of tomato plant disease images. The results show that the model is better than the original CycleGAN. A fault recognition mechanism was presented in [
26] for bearing small samples based on InfoGAN and CNN. The extracted time-frequency image features are input into InfoGAN for training to expand the data. Tested on the CWRU dataset, the results show that this method is better than other algorithms and models. In [
27] a strategy was raised relying on a WGAN combined with a DNN. The cancer image is expanded by GAN to improve the classification accuracy and generalization of DNN. The results show that the classification accuracy of DNN using WGAN is the highest in comparison with other methods. CycleGAN has been put to use in [
28] to retreat the CT segmentation task domain dataset for enhancement. The results display that the Dice score on the kidney increases from 0.09 to 0.66, and the effect is significant, while the improvement is small on the liver and spleen. However, WGAN-GP is still not effective at generating high-resolution images. Therefore, Tero Karras proposed Progressive GAN (ProGAN) in [
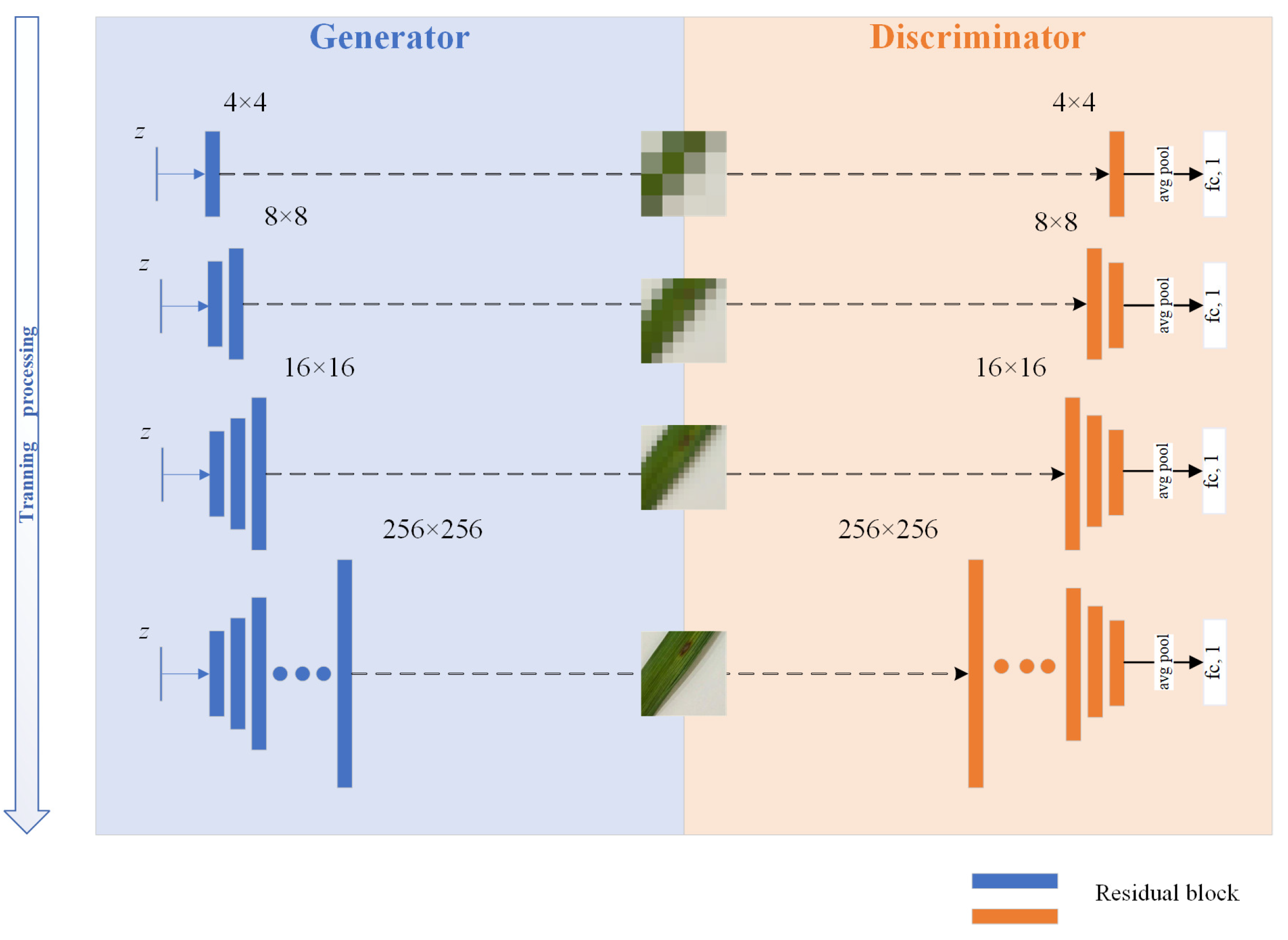
29], a growing GAN-derived model, which generates very low-resolution images first, and then gradually increases the generated resolution during training to generate high-resolution images stably. In [
30], a Dual GAN was proposed for generating high-resolution images of rice disease, which is used in the field of data enhancement. Dual GAN uses WGAN-GP to generate rice disease images, and Optimized-Real-ESRGAN is used to improve image resolution. The experimental results show that the accuracy of ResNet-18 and VGG-11 is improved by 4.57% and 4.1%, respectively. In [
31], a novel neural network-based hybrid model (GCL) is proposed. CGL includes GAN for data enhancement, CNN for feature extraction, and LSTM for rice disease image classification. The experimental results show that the proposed method can achieve 97% accuracy for disease classification. In [
32], a new convolutional neural network was proposed for the identification of three rice leaf diseases, using a GAN-based technique to augment the dataset. The experimental results showed that the proposed method achieved an accuracy of 98.23%. The above studies can show that GAN application is effective for data enhancement in small sample datasets, but the resolution and stability of the current generation are yet to be improved.
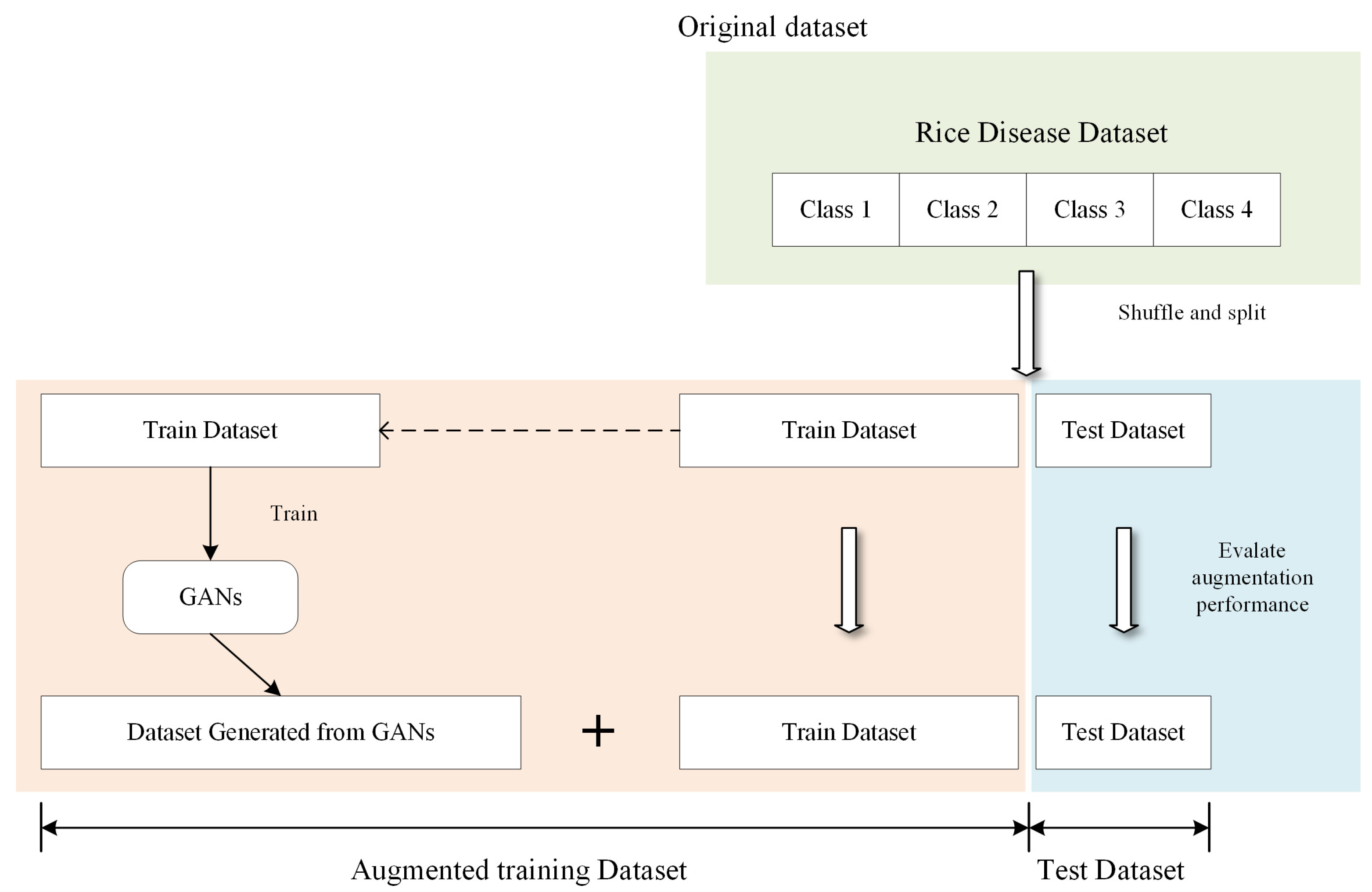
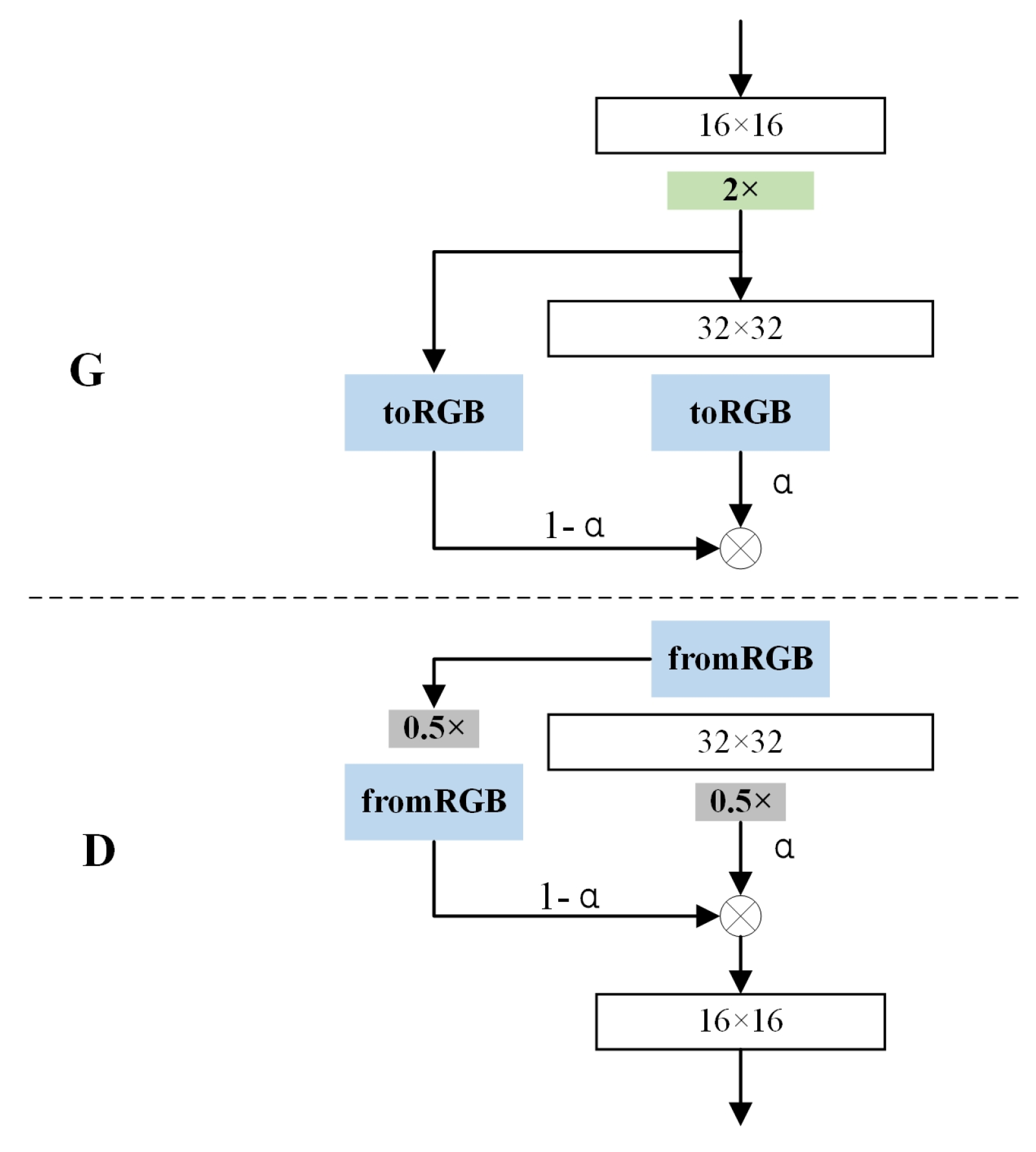
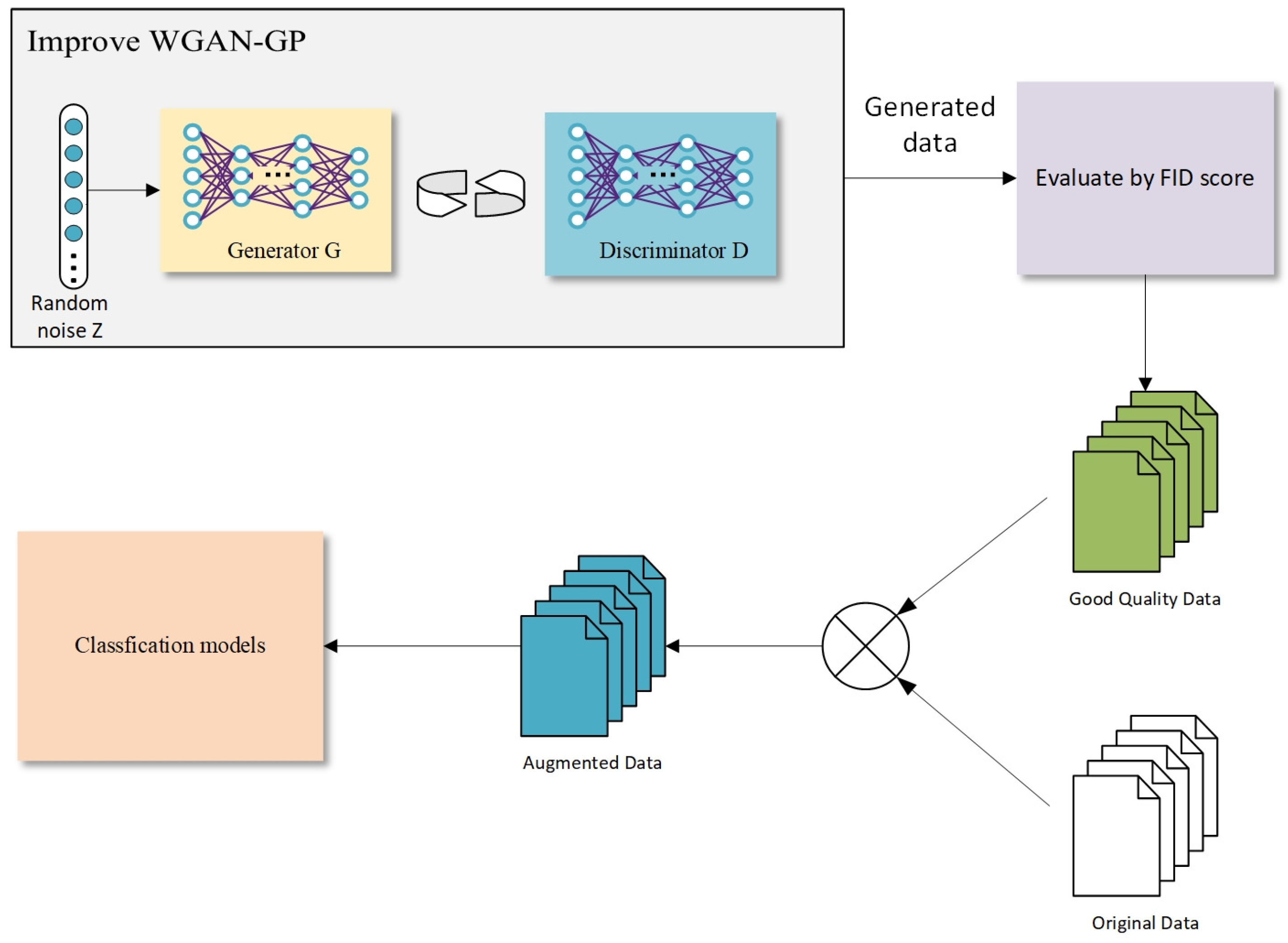
To alleviate the lack of image data on rice diseases, we introduce a Progressive WGAN-GP, which is based on the WGAN-GP model and combines a progressive training method. This model is applied to rice disease image data augmentation to increase the accuracy of the recognition model in small-sample datasets. By analyzing the three diseases in the collected dataset as well as the open-source dataset, the experimental results show that the method has good robustness and generalization ability and has a fine recognition effect under small sample conditions. The main contributions of this paper are twofold. (1) The progressive training method is introduced into the WGAN-GP model. In the field of rice disease image generation, the generation performs better than WGAN-GP, WGAN, and Deep convolutional GAN (DCGAN). (2) The experimental results show that the PWGAN-GP method can not only generate high-quality images of rice diseases but also apply the generated images to the CNNs training by blending the dataset with real images, which can improve the performance of CNNs, and obtain a higher recognition accuracy than other methods.
The remainder of this paper is organized as follows. In
Section 2, we describe the source and the pre-processing of the data.
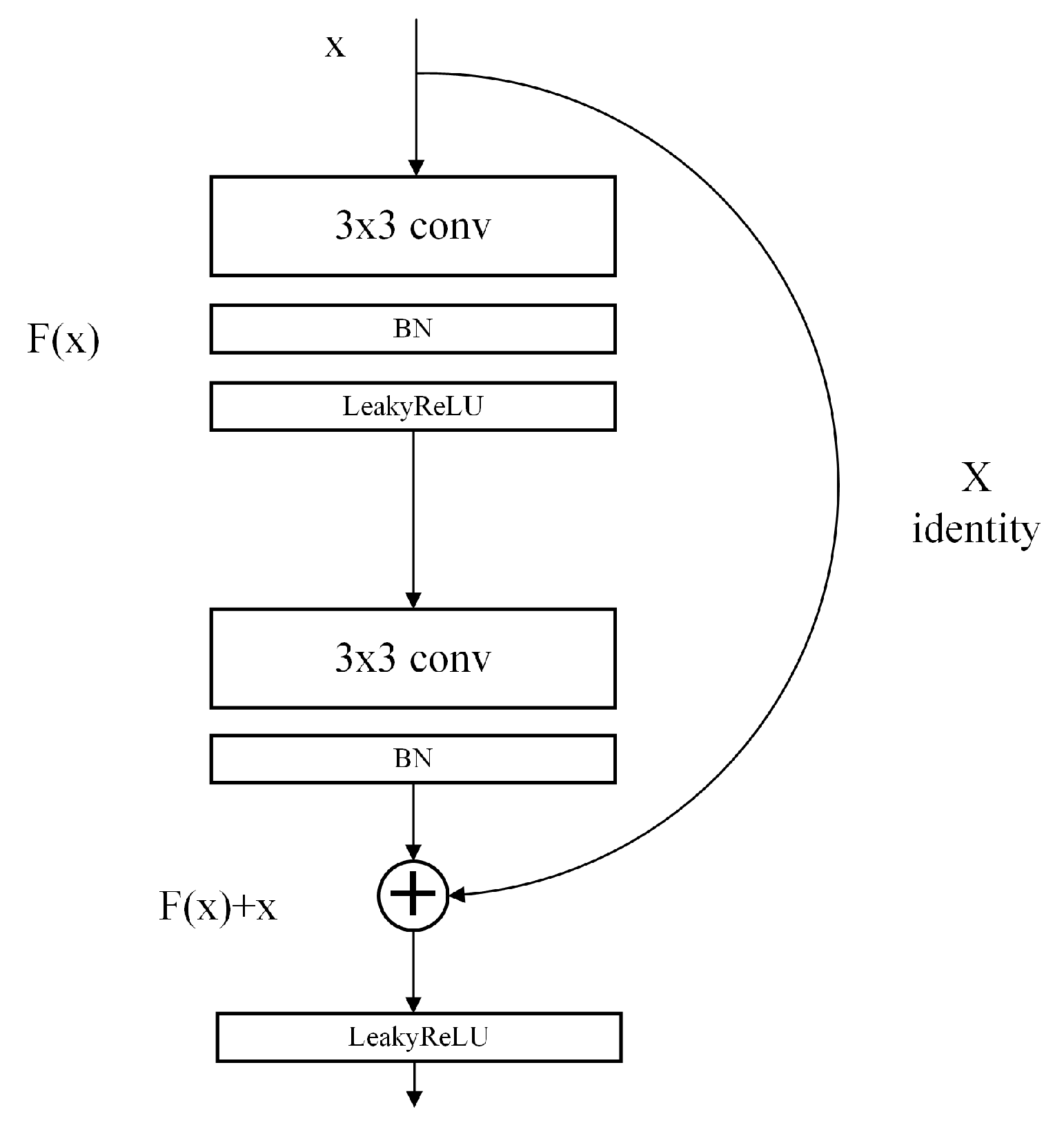
Section 3 presents the theory related to PWGAN-GP.
Section 4 describes the experimental setup of the PWGAN-GP for the application problem of rice disease image generation as well as recognition.
Section 5 analyzes the experimental data of image generation and the comparison with other methods. Conclusions are given in
Section 6.
6. Conclusions
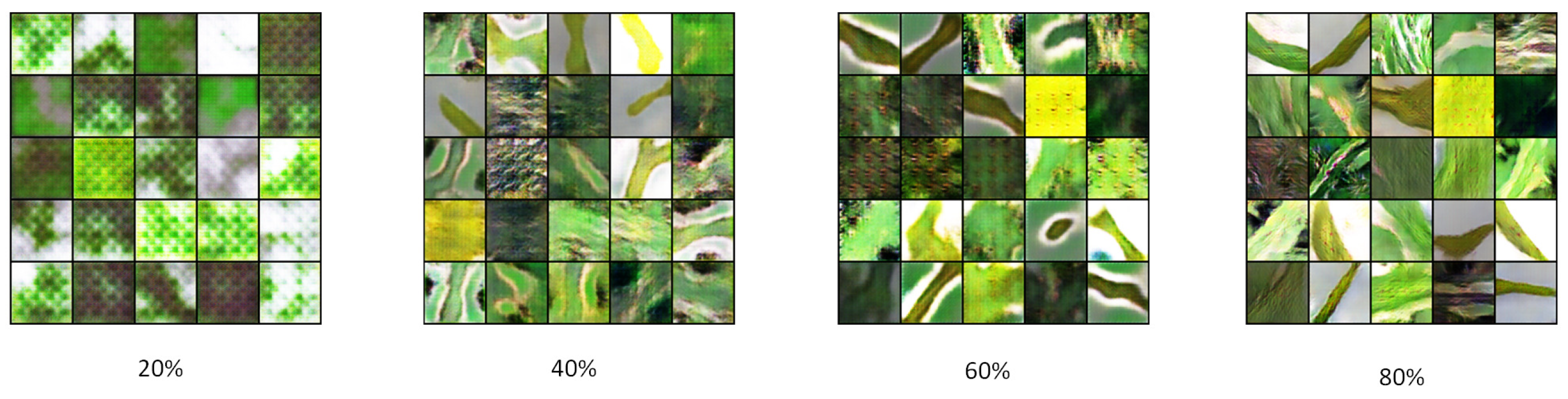
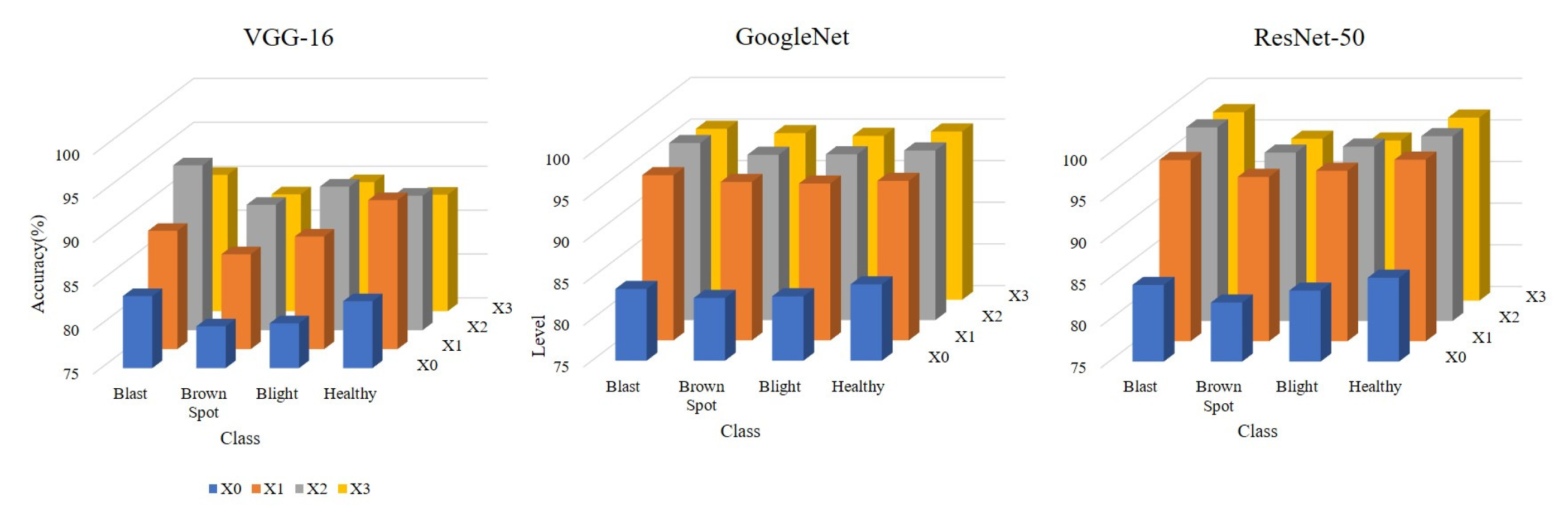
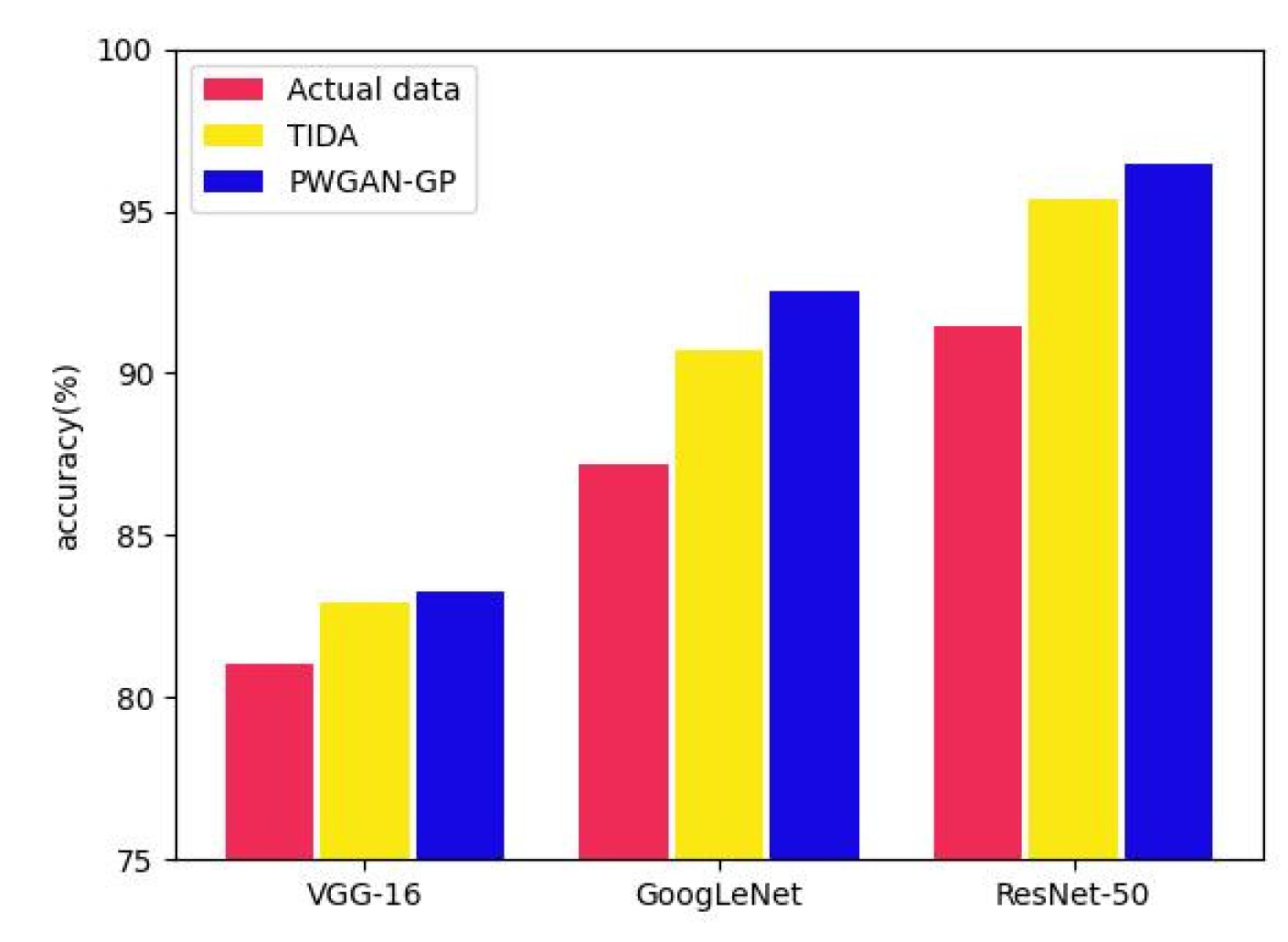
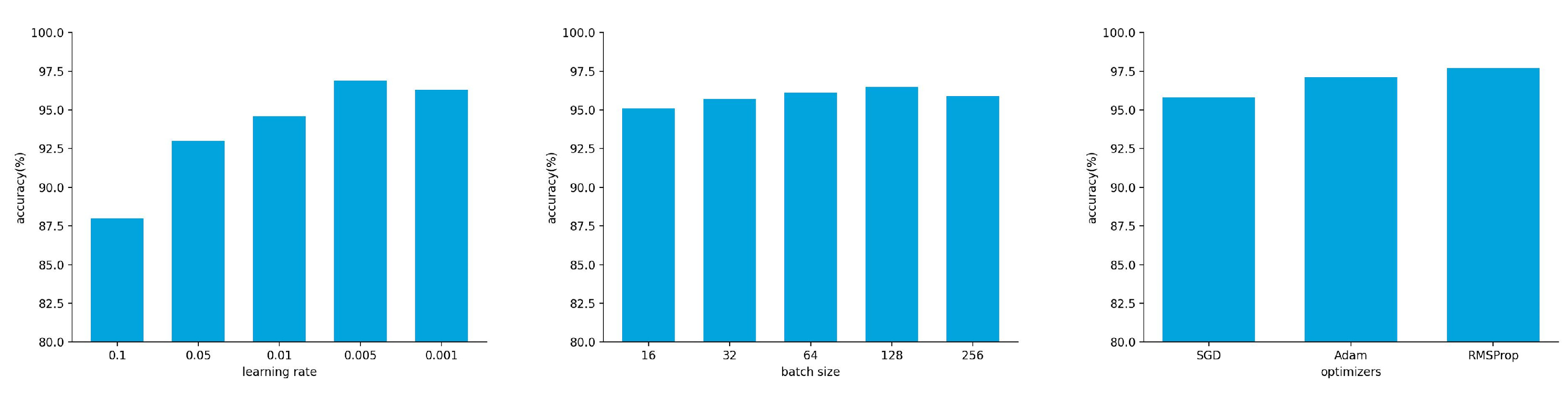
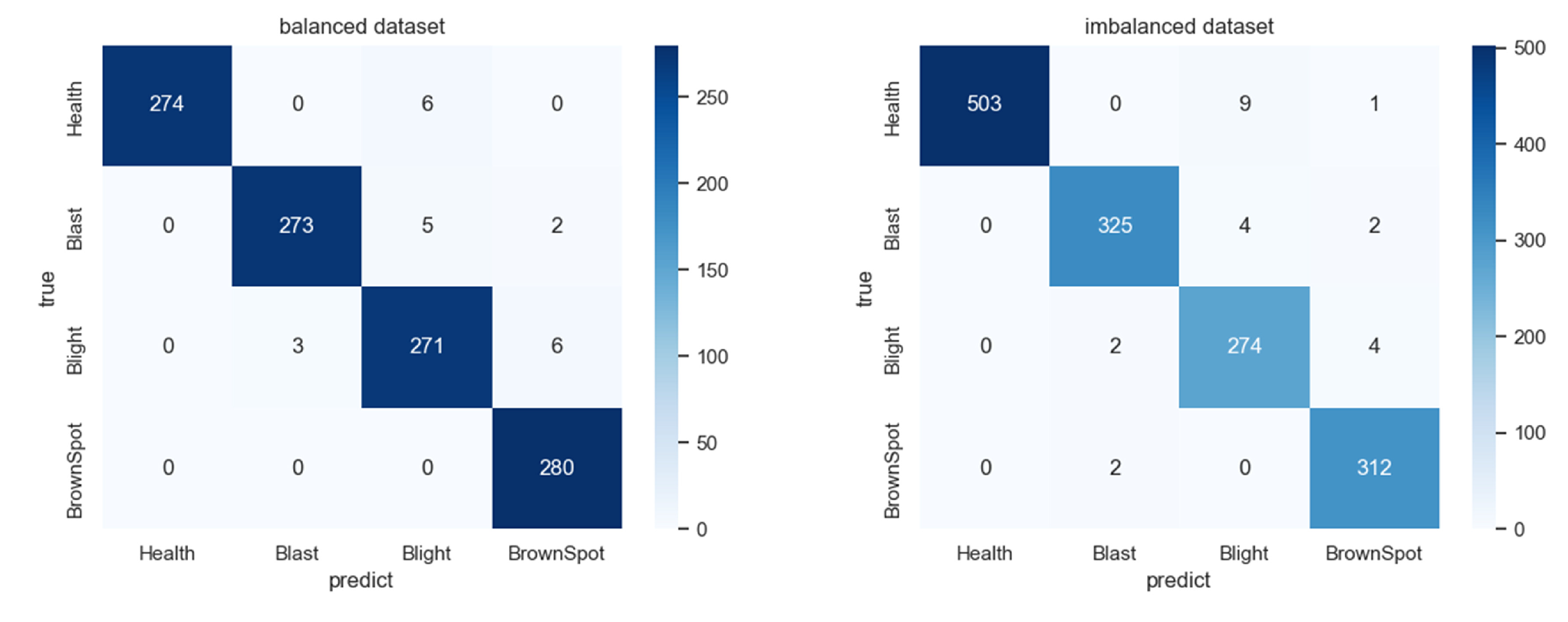
To solve the problem of low accuracy caused by the lack of rice disease image datasets in training CNNs, PWGAN-GP is proposed to generate rice leaf disease images in this paper. First, we use the progressing training method to train the generator model and discriminator model, and a loss function is added to the discriminator model. It has been concluded that the PWGAN-GP network is the best to generate rice leaf disease images compared with WGAN, DCGAN, and WGAN-GP. Second, the experimental results show that the accuracy of VGG-16, GoogLeNet, and ResNet-50 using PWGAN-GP is 10.44%, 12.38%, and 13.19% higher than those without PWGAN-GP. Compared with a traditional image data augmentation method, the accuracy is increased by 3.2%, 3.86%, and 3.11%, respectively. The accuracy of CNNs can be maximized under the condition of X2 (1:20) enhancement intensity. Finally, under hyperparameter optimization, the ResNet-50 with PWGAN-GP achieved 98.14% for identifying three rice diseases. In addition, we also tested the performance of ResNet-50 in some scenarios, and the results were good. Therefore, it has been shown that PWGAN-GP has better image generation ability and improves the classification ability of CNNs.
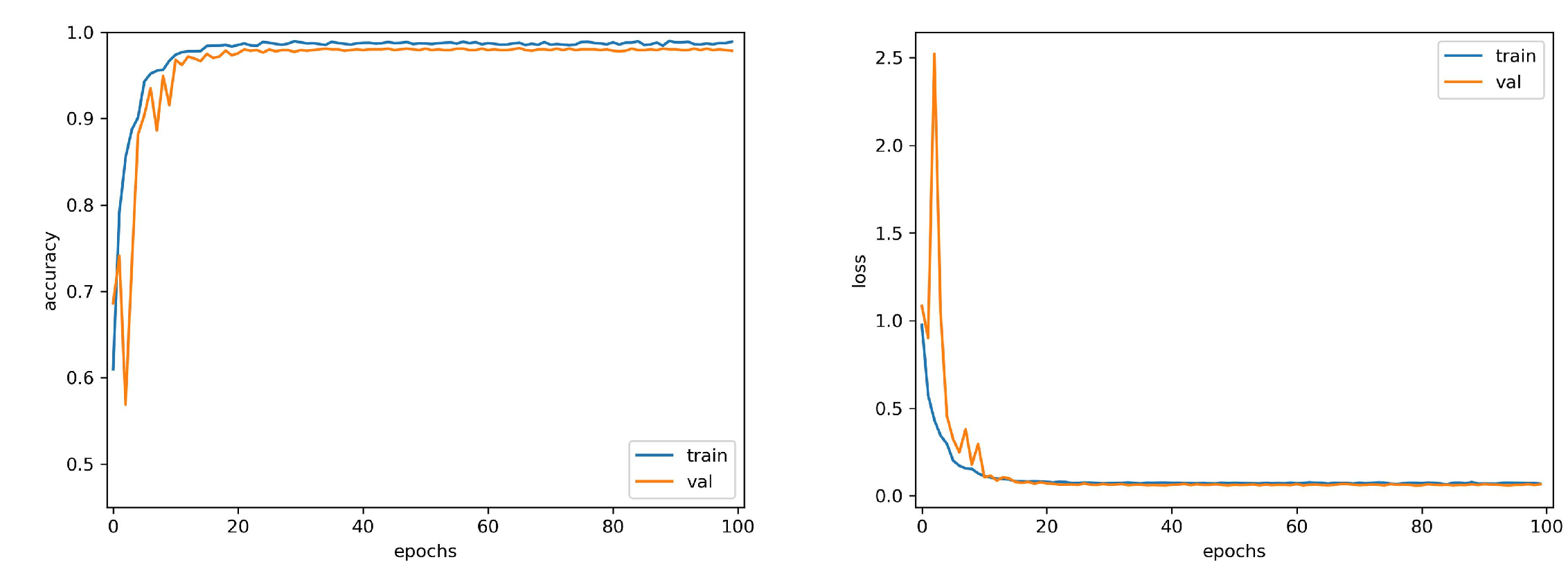
At present, the model proposed in this paper also has the problem of long training time and slow convergence. In future work, we will solve these two problems by optimizing model parameters and combining deep learning with control theory [
48,
49,
50,
51,
52].





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}