Abstract
Forest stock volume (FSV) is a major indicator of forest ecosystem health and it also plays an important part in understanding the worldwide carbon cycle. A precise comprehension of the distribution patterns and variations of FSV is crucial in the assessment of the sequestration potential of forest carbon and optimization of the management programs of the forest carbon sink. In this study, a novel vegetation index based on Sentinel-2 data for modeling FSV with the random forest (RF) algorithm in Helan Mountains, China has been developed. Among all the other variables and with a correlation coefficient of r = 0.778, the novel vegetation index (NDVIRE) developed based on the red-edge bands of the Sentinel-2 data was the most significant. Meanwhile, the model that combined bands and vegetation indices (bands + VIs-based model, BVBM) performed best in the training phase (R2 = 0.93, RMSE = 10.82 m3ha−1) and testing phase (R2 = 0.60, RMSE = 27.05 m3ha−1). Using the best training model, the FSV of the Helan Mountains was first mapped and an accuracy of 80.46% was obtained. The novel vegetation index developed based on the red-edge bands of the Sentinel-2 data and RF algorithm is thus the most effective method to assess the FSV. In addition, this method can provide a new method to estimate the FSV in other areas, especially in the management of forest carbon sequestration.
1. Introduction
Forest stock volume (FSV) refers to the total volume of tree trunks growing within a certain area of a forest, and it is thus an important indicator for measuring the total forest resources within that area [1]. It is also an important parameter to measure forest quality, forest carbon sequestration potentials, and an evaluation of the effectiveness of forest management [2]. Around the globe and ever since the Chinese government formally proposed a strategic plan for carbon peaking and carbon neutrality in 2020, global warming has drawn widespread attention [3,4,5]. This is because the carbon sink capacity of forests is an effective measure to mitigate global warming. Through the change in FSV [6], the dynamic change in carbon storage can be understood and the carbon sink capacity of the forest ecosystem can be obtained. Therefore, FSV studies are not only paramount in the global carbon cycle, but also practically significant in the realization of China’s dual-carbon objectives.
The traditional FSV estimation method is mainly based on the manual measurement of the diameter at breast height (DBH) and tree height on the ground [7]. For fine-scale FSV estimation, it is indeed possible to obtain higher-precision estimation results [8]. However, if extended to a large-scale forest area, the small size and small number of sample plots will make it hard to obtain results close to the actual level [9]. Furthermore, forest ecosystems generally exhibit high spatial heterogeneity and inaccessibility [10,11]. Therefore, at this stage, it is not recommended to estimate FSV purely by manual field surveys. The advent of remote sensing has provided a solution to the challenge of large-scale FSV estimation [1,8,12]. By utilizing satellite images, it is now possible to obtain information about forest structures and compositions across vast areas, without the need for extensive ground measurements [13]. This technology has revolutionized the field of forest inventory, allowing for a more efficient and accurate estimation of FSV at a large-scale. Remote sensing images can be used in combination with a small number of ground samples to obtain highly accurate estimates of FSV or biomass [10]. By calibrating remote sensing data with ground-based measurements, it is possible to create statistical models that can accurately predict FSV at a much larger scale [14]. This combined approach has significant advantages over traditional manual field surveys, as it allows for a more efficient and cost-effective estimation of FSV across large areas. Furthermore, the use of remote sensing data can provide a more comprehensive understanding of forest ecosystems, allowing for more informed management decisions.
However, as more and more optical remote sensing images are applied to FSV studies, researchers have focused on the light saturation phenomenon that affects FSV estimation results [15,16,17]. Using the band reflectance of optical remote sensing images, all kinds of vegetation indices can be calculated. These traditional indices are usually used to estimate the corresponding FSV or biomass [18,19,20,21,22]. However, as the forest ages, the traditional vegetation indices will no longer respond accordingly to the decrease or increase in tree age [15,16]. This is the phenomenon of overestimation of low values and underestimation of high values that often occurs in FSV estimation studies. This is a result of the insensitivity of spectral variables to changes in FSV, especially in forest areas with high vegetation coverage. Previous studies have explored a variety of methods to decrease the influence of light saturation phenomena on remote sensing estimation. These studies include the utilization of spatial regression models and multi-source remote sensing image fusion [15,17]. Unfortunately, being an FSV study solely on a specific region, it has generalized limitations and it does not apply to other regions.
The present study proposes a novel vegetation index aimed at improving the ability to estimate FSV from remote sensing images. According to the literature, it is known that the Sentinel-2 imagery covers 13 spectral bands [23,24,25,26], from visible light to short-wave infrared, and each band has different spatial resolutions. Among all optical satellites, Sentinel-2 is the only satellite that includes three spectral bands in the red-edge range [24,26]. These bands are very effective in monitoring vegetation change information. Such as to estimate the FSV of the Helan Mountains, the vegetation reflectance of these three red-edge bands was used to calculate the novel vegetation index [27]. Similarly, by setting the step size, the optimal weighting coefficient of each red-edge band was determined. As this study was carried out the a typical semi-arid montane forest ecosystem of the Helan Mountains, this study may serve as a knowledge base for related research in similar areas across the globe.
Furthermore, the present study aims at developing a novel vegetation index based on Sentinel-2 multiple red-edge bands. It also combines the original band information and traditional vegetation indices to estimate the FSV of the Helan Mountains under the machine learning algorithm. The study will accomplish the following three goals: (1) to explore the potentials of the novel vegetation index developed based on Sentinel-2 data to estimate the FSV; (2) to compare the ability of the different variable combinations to estimate FSV and determine the best model among the three models developed in this study; (3) to map the FSV distribution of the study area by the best variable combination obtained in objective (2).
2. Materials and Methods
2.1. Study Area
This study focused on the forest resources in the Helan Mountains National Nature Reserve (38°19′–39°22′ N, 105°49′–106°41′ E) in Ningxia Province (Figure 1). The Helan Mountains belongs to the temperate arid climate zone with typical continental monsoon climate characteristics. The lack of rain and snow all year round leads to a dry climate. Although the average annual temperature is −0.7 °C, there is a wide seasonal variation in precipitation. For instance, the average precipitation from June to September, which accounts for over 62% of the annual precipitation, reaches 260.2 mm. Due to the steep mountain and complex terrain, the Helan Mountains are an important dividing line between climate and vegetation in western China. To the east is the grassland climate and grassland vegetation, and to the west is the desert climate and desert vegetation. It is located at the junction of the Qinghai-Tibetan Plateau, the Mongolian Plateau, and the North China Plain. The special geographical environment has shaped the unique biological groups of the Helan Mountains, making it the only biodiversity hotspot in northern China. Furthermore, the Helan Mountains National Nature Reserve in Ningxia Province has played a major role in studies on the virtuous cycle of vegetation development, succession, and restoration of ecosystems in semi-arid areas.
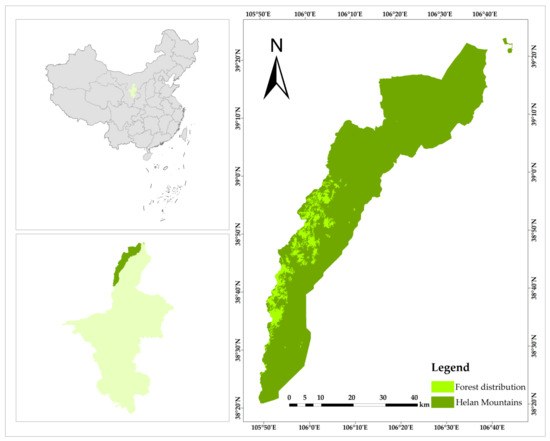
Figure 1.
The geographical location of the Helan Mountains.
2.2. Field Data Collection
The field data were obtained from the 2020 forest resources management “one map” annual update data released by the Ningxia Forestry Survey and Planning Institute. Using these data reduces the workload of field surveys, and it provides access to a large amount of information on ground sample plots. Due to the wide distribution of national surface survey plots, not all sample plots can be surveyed on the spot, and there is a certain degree of uncertainty in these data. Therefore, based on previous studies, the NDVI obtained from Sentinel-2 data was used to screen plots and remove outlier data (NDVI < 0.2) [28,29]. In the end, 881 small class data were extracted for the modeling analysis, and took the hectare stock volume of living trees as the unit area FSV of each sample plot.
Random grouping was used to divide the training data and the testing data. Among the 881 sample plots, 530 (about 60%) were used as the training data and 351 (about 40%) were used as the testing data. Table 1 counts the characteristics of the field FSV training data and testing data, respectively.

Table 1.
Descriptive statistics of the FSV training and testing data.
2.3. The Acquiring and Processing of Sentinel-2 Data
Sentinel-2 covers spectral information in 13 bands, including visible light, near-infrared, red-edge, and short-wave infrared. The Sentinel-2 images are directly extracted from the processed surface reflectance product (COPERNICUS/S2_SR) through the Google Earth Engine (GEE) platform. To match the date of field data and consider the influence of cloud coverage of remote sensing images in the study area, the product date is selected from 1 July 2020 to 31 August 2020. The declouding process uses the method officially announced by the GEE to directly mask out the pixels whose pixel_QA band pixel attributes are 3 and 5. Following cloud removal, the overlaid images were medianized using the median function, followed by coordinate system matching and resampling to 30 m resolution.
2.3.1. Original Band Information
Then, the band information was extracted from the processed images using the vector file of the ground sample. Eight bands (Table 2) of the Sentinel-2 data were selected for this study [30,31,32], excluding bands 1, 9, 10, 11, and 12 because these bands are mainly associated with the atmosphere or water vapor.
Table 2.
Selected band information of Sentinel-2.
2.3.2. Traditional Vegetation Indices
The potential of six traditional vegetation indices for estimating FSV, calculated from the band reflectance extracted from the Sentinel-2 data (Table 3) were initially tested. Normalized Difference Vegetation Index (NDVI) reflects the background influence of plant canopy and is concerned with vegetation coverage. It is a vegetation index frequently utilized for detecting the growth status of plants. The difference vegetation index (DVI) can also reflect changes in vegetation coverage very well, and within a certain range of vegetation coverage, the DVI rises with the growth of biomass. The ratio vegetation Index (RVI) is a highly sensitive indicator parameter for monitoring green plants, which can be used to detect vegetation status and estimate the FSV. This index is the ratio of light scattered in the near-infrared to light absorbed in the red band, which lessens the effect of the atmosphere and terrain. The perpendicular vegetation index (PVI) represents the vertical distance from the vegetation pixel to the soil brightness line in the two-dimensional coordinate system of R—NIR and is less sensitive to the atmosphere than other vegetation indices. The transformed vegetation index (TVI) is based on the NDVI and introduces a constant of 0.5 to convert the negative value that the NDVI may take into a positive value. The EVI not only inherits the advantages of the NDVI, but also improves the saturation of high vegetation areas, incomplete correction of atmospheric effects, and soil background. The enhanced vegetation index (EVI) can improve the sensitivity of vegetation in high biomass areas and reduce the influence of soil background and atmosphere.
Table 3.
Several traditional vegetation indices calculated based on Sentinel-2 data.
2.3.3. Novel Vegetation Index Based on Red-Edge Bands
The accuracy of traditional vegetation indices to estimate FSV is severely affected by the light saturation phenomenon. While the three red-edge bands in the Sentinel-2 data have been proven to be an effective way to improve the estimation of the forest parameters, unfortunately only one or two of the red-edge bands were used in existing indices. Therefore, to maximize the ability to estimate FSV using the three red-edge bands in the Sentinel-2 data, a novel vegetation index based on existing NDVI construction principles, the 4-band red-edge NDVI (NDVIRE), such as Formula (1) was developed. According to the novel index construction rules, as elaborated in previous studies, in the NDVIRE formula, instead of using the NIR band, the reflectance values of RE3 and RE2 are averaged using weights and are substituted. Similarly, the Red band is replaced with a weighted average of the reflectance values of RE1 and RE2 [27]. The weighting coefficients “α” and “β” are designed to define the optimal proportion of each band in the construction of the novel index.
where , , , and are the reflectance of B5, B6, B7, and B4, respectively. “α” and “β” represent weighting coefficients. The value range of “α” and “β” is (0,1), and the step size is 0.1.
2.4. Acquisition of the Forest Distribution Pattern in the Helan Mountains
The Global PALSAR-2/PALSAR Forest/Non-Forest Map product utilizes synthetic aperture radar (SAR) images obtained from the phased array type L-band synthetic aperture radar (PALSAR) on the ALOS-2 satellite to generate a global map of forest and non-forest areas. The classification accuracy of this map, in terms of forest and non-forest information, can reach 90%. This product is widely used for monitoring forest changes, assessing forest carbon storage, and providing information for forest management decisions. We downloaded this product using the GEE and extracted the pixels defined as forest areas within the Helan Mountains region, ultimately obtaining the forest distribution pattern of the Helan Mountains.
2.5. Machine Learning Algorithm of Modeling FSV
The random forest (RF) is a machine learning algorithm that uses multiple decision tree classifiers for classification and prediction. In recent years, studies on RF algorithms have rapidly developed accompanied by large numbers of applied research carried out in many fields. The RF algorithm is an efficient bagging-based integrated learning algorithm, and numerous prior studies have shown that the RF algorithm performs well in regression prediction [35,36,37,38]. Therefore, this study chooses the RF algorithm for modeling and analysis. The RF algorithm operates by utilizing the bootstrap method, that involves randomly sampling from the original population to create multiple samples. These samples are then used to generate a set of decision trees (ntree). The RF algorithm achieves higher accuracy and robustness by increasing the number of decision trees. At each splitting node, the RF algorithm randomly selects a subset of predictors (mtry) to build each tree. Additionally, there is no need to prune each tree. The RF algorithm employs the “out-of-bag” (OOB) error procedure to independently build each tree based on the training data. This procedure allows for the calculation of variable importance (VI) and OOB error for each tree grown by the RF algorithm. An estimation of the OOB error can be obtained using the following formula:
where is the measured FSV, is the predicted FSV, and n is the total number of OOB samples.
In this study, three RF-based models composed of bands and vegetation indices (VIs) to estimate FSV, namely the bands-based model (BBM), VIs-based model (VBM), and bands + VIs-based model (BVBM) have been used.
2.6. Selecting Variables Using the VSURF Package
The VSURF package is a powerful tool for variable selection in regression problems using the RF algorithm. It is a three-step process that involves eliminating irrelevant variables, selecting relevant variables for interpretation, and improving prediction accuracy by removing redundant variables. To begin, the first step of the process involves identifying and eliminating irrelevant variables from the dataset. In the second step, all variables that are associated with the response variable are selected for interpretation. Finally, in the third step, redundant variables are removed to enhance the model’s prediction performance. Once the relevant variables have been selected, the minimum mean square error (MSE) is used to determine the optimal number of decision trees (ntree) and the number of variables (mtry) to be used in the RF model. Initially, the ntree parameter is set to 500 and mtry parameter is set to the total number of variables. Once the optimal parameters are calculated, the RF regression model is established and tested.
2.7. Assessment of the Modeling Performance
This study utilized two metrics to assess the effectiveness of the RF model. The first metric was the coefficient of determination (R2, Formula (3)), that indicates the extent to which the independent variable can account for the variability in the dependent variable. The second metric was the root mean square error (RMSE, Formula (4)), that represents the standard deviation of the difference between the observed data and the fitted model. A higher R2 and a lower RMSE are indicative of a well-fitting model. The model is trained on 60% of the total samples, and the remaining 40% are used for testing. This approach allows for accurate predictions while reducing the risk of over-fitting.
where is the measured FSV, is the predicted FSV, is the mean measured FSV, i is the same index, and n is the number of sample plots.
3. Results
3.1. Determination of the Optimal Novel Vegetation Index
According to the calculation formula of the novel vegetation index (NDVIRE), the value range of the weighting coefficients “α” and “β” is (0,1), and the step size is 0.1, so 121 NDVIRE can be obtained. Python 3.10 software was used to calculate each NDVIRE value of all small class data, and the Pearson correlation coefficient of each NDVIRE with the FSV per unit area was also calculated. Results of the analysis are shown in Figure 2 (correlation is significant at the 0.01 level (two-tailed). In addition, the Pearson correlation coefficient was also put between the traditional NDVI and unit area FSV in the figure for comparison. Results showed the 47th NDVIRE to have the highest correlation coefficient (r = 0.778), which is better than the traditional NDVI (r = 0.767), and its corresponding values of “α” and “β” were 0.4 and 0.2, respectively. Therefore, the optimal NDVIRE was determined and used for the subsequent modeling analysis.
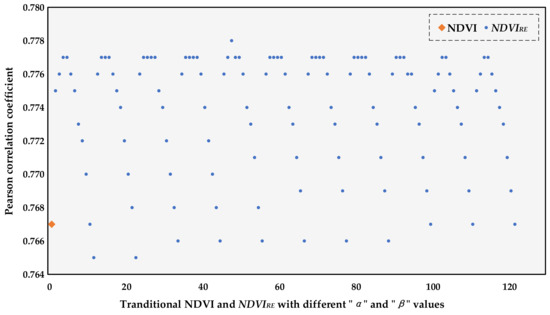
Figure 2.
Pearson correlation coefficients of the NDVI and NDVIRE with FSV per unit area.
3.2. Major Variables Selection and the Importance Related to the FSV Data
Two types of variables, the band (B2, B3, B4, B5, B6, B7, B8, and B8A) and vegetation index (NDVI, DVI, RVI, PVI, TVI, EVI, and NDVIRE) were selected to participate in the modeling. Figure 3, Figure 4 and Figure 5, represent the variable selection process of the three models (BBM, VBM, and BVBM). Meanwhile, Table 4 shows the final variable selection results of each model.
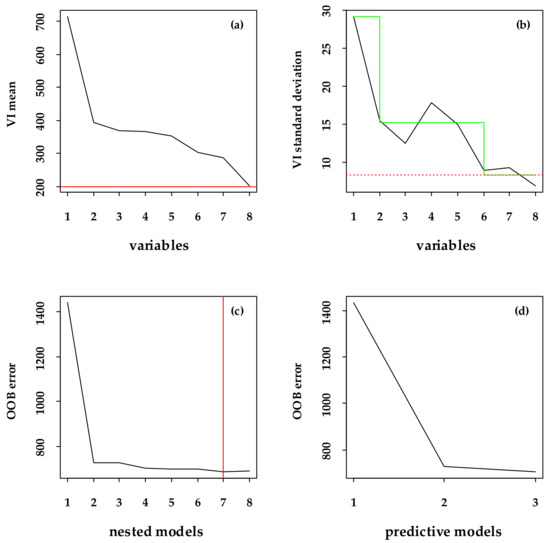
Figure 3.
The variables selection of BBM. (a,b) Removes the negatively important variables based on the variable importance (VI) mean and standard deviation, respectively ((a), the threshold position is represented by a solid red line that runs horizontally, and (b), the green segmented line represents the predicted value given by the CART model, and the red line with dashes running horizontally represents the minimum predicted value). (c) Gradually builds a random forest from only the most important variables to all variables selected in the first step, and selects the corresponding variables according to the average OOB error (the vertical solid red line indicates the minimum error position). (d) Gives the number of variables meeting the requirements.
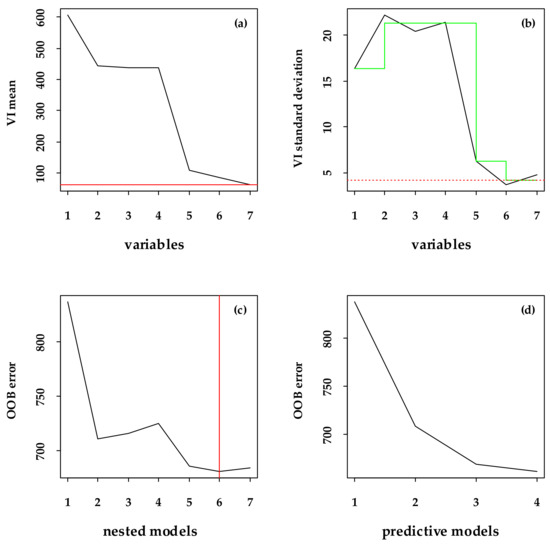
Figure 4.
The variables selection of VBM. (a,b) Removes the negatively important variables based on the VI mean and standard deviation, respectively ((a), the threshold position is represented by a solid red line that runs horizontally, and (b), the green segmented line represents the predicted value given by the CART model, and the red line with dashes running horizontally represents the minimum predicted value). (c) Gradually builds a random forest from only the most important variables to all variables selected in the first step, and selects the corresponding variables according to the average OOB error (the vertical solid red line indicates the minimum error position). (d) Gives the number of variables meeting the requirements.
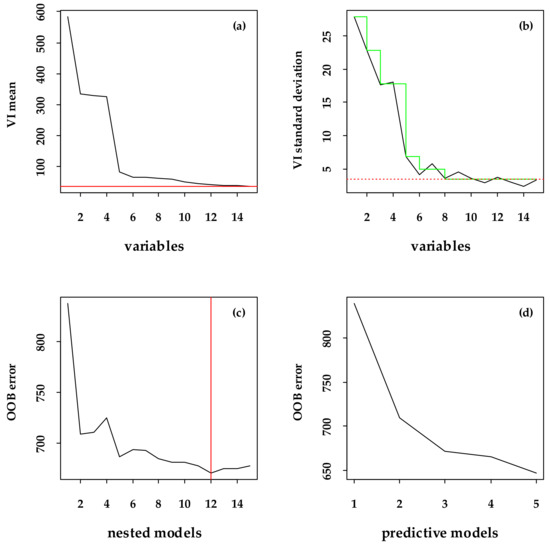
Figure 5.
The variables selection of BVBM. (a,b) Removes the negatively important variables based on the VI mean and standard deviation, respectively ((a), the threshold position is represented by a solid red line that runs horizontally, and (b), the green segmented line represents the predicted value given by the CART model, and the red line with dashes running horizontally represents the minimum predicted value). (c) Gradually builds a random forest from only the most important variables to all variables selected in the first step, and selects the corresponding variables according to the average OOB error (the vertical solid red line indicates the minimum error position). (d) Gives the number of variables meeting the requirements.
Table 4.
The variables selection results using the VSURF package.
Furthermore, all predictor variables were ranked based on their ability to estimate FSV using PercentIncMSE and IncNodePurity estimated from the OOB data. The greater the value, the greater the significance of the variable (Figure 6). It is worth noting that the novel vegetation index NDVIRE ranks first in importance under the two evaluation criteria.
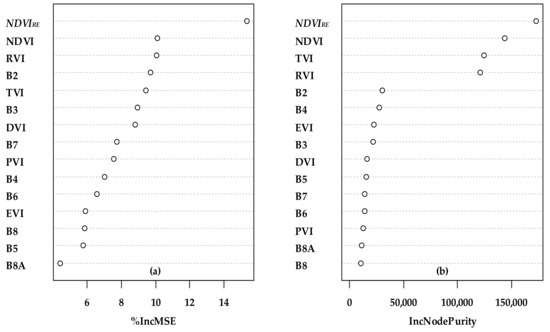
Figure 6.
Importance ranking plot of all variables. Left, %IncMSE (percentage increase in the mean square error, (a)), and right, IncNodePurity (increase in NodePurity, (b)).
3.3. Optimal Regression Model for the Three Models
To optimize the RF regression model, we need to find the optimal values for two key parameters: “mtry”, which determines the number of variables randomly selected as candidates for each split in the decision tree, and “ntree”, which determines the total number of trees in the forest that have grown. To calculate the minimum error rate, an iterative algorithm was used, known as an “error rate loop”, according to the number of variables participating in the modeling in the three models. Figure 7 shows the determination process of the optimal mtry and ntree of the three models. The values of mtry, ntree, and other performances of each model are summarized in Table 5.
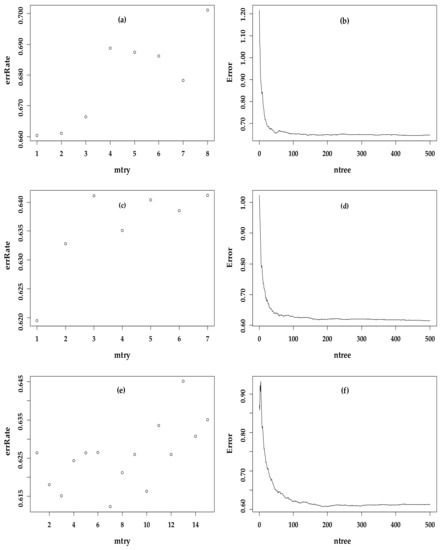
Figure 7.
(a,c,e) are the distribution of error rate versus mtry; (b,d,f) are the distribution of the error versus ntree; (a,b) are related to the BBM; (c,d) are related to the VBM; and (e,f) are related to the BVBM.
Table 5.
The best mtry, ntree, and performance of the three models.
3.4. Comparison of the Three Models Predicting FSV
In the training phase, BBM (Figure 8a) with an R2 = 0.92 is slightly better than VBM (Figure 8c) with an R2 = 0.91. However, the RMSE = 11.90 m3ha−1 of the VBM is lower than the RMSE = 12.23 m3ha−1 of the BBM. The BVBM (Figure 8e) has the highest R2 = 0.93 and the smallest RMSE = 10.82 m3ha−1. In the testing phase, the BBM (Figure 8b) with an R2 = 0.59 and RMSE = 27.72 m3ha−1 performed almost the same as VBM (Figure 8d) with an R2 = 0.59 and RMSE = 27.32 m3ha−1. Similarly, the BVBM (Figure 8f) had the best performance with an R2 = 0.60 and RMSE = 27.05 m3ha−1. Obviously, the BVBM is the optimal model in this study, and its predicted FSV is used as the final estimation result to map the FSV. A summary of the data characteristics of FSV as predicted by the three models is presented in Table 6.
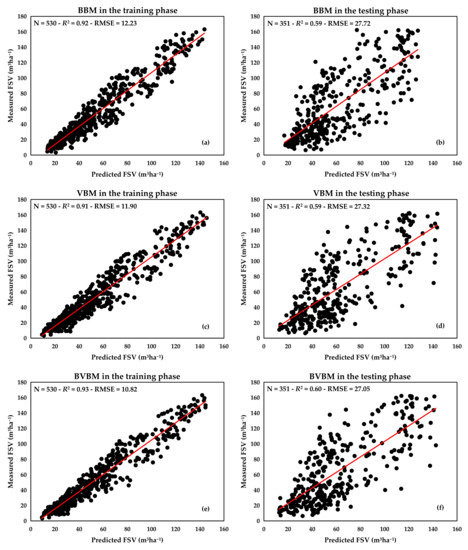
Figure 8.
Comparison of the measured FSV and predicted FSV by the three models. (a), BBM in the training phase. (b), BBM in the testing phase. (c), VBM in the training phase. (d), VBM in the testing phase. (e), BVBM in the training phase. (f), BVBM in the testing phase.
Table 6.
Characterization of FSV predicted by the three models.
3.5. Mapping FSV Distribution of Helan Mountains
Based on the results shown in Figure 8, we have concluded that the BVBM is the best-performing model in this study, and we calculated the FSV of the Helan Mountains by the BVBM combined with the forest distribution pattern. Figure 9 is the final FSV map, the minimum value of the unit area FSV of the Helan Mountains is 9.63 m3ha−1 and the maximum value is 143.96 m3ha−1. The total amount of FSV in the Helan Mountains was estimated to be 1,062,727.25 m3. According to the FSV data released by the Helan Mountains National Nature Reserve in Ningxia Province (http://www.hlsbhq.com/, accessed on 22 January 2023), the total FSV of the Helan Mountains is 1,320,721.7 m3. Therefore, the accuracy of the BVBM to predict the FSV in the Helan Mountains reached 80.46%.
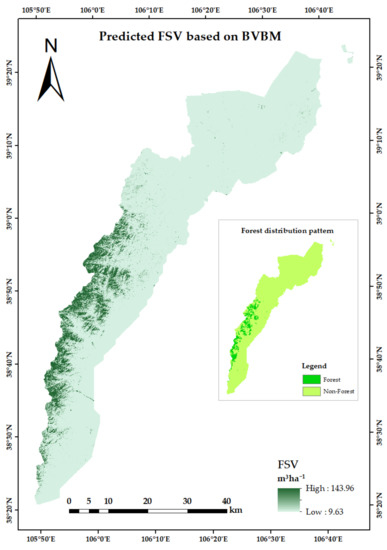
Figure 9.
Spatial distribution of the predicted FSV, and forest distribution of the Helan Mountains.
4. Discussion
The carbon sequestration capacity of montane forest ecosystems is very significant and of prime importance in the global carbon cycle. Due to their geographical location and climatic characteristics, montane forests are an integral part of the entire terrestrial forest ecosystem [35,39]. The Helan Mountains are highly representative of montane forest ecosystems, their FSV estimation has a very high reference value for studies across similar landscapes. However, as a result of the inaccessibility and complex spatial heterogeneity of montane forest ecosystems, it is often a daunting task to obtain a sufficient number and sufficiently representative ground samples to estimate FSV in large-scale areas. Although remote sensing images have made it easier, issues related to low-value overestimation and high-value underestimation still occur [15,17]. However, as more and more red-edge bands in Sentinel-2 data are applied, the accurate estimation of vegetation parameters has been greatly improved [1,2]. For example, based on the red-edge band of Sentinel-2, Liu et al. [27] developed several new vegetation indices to estimate the photosynthetic and non-photosynthetic fractional vegetation cover of alpine grasslands on the Qinghai-Tibetan Plateau. Despite exhibiting a more sensitive response at low vegetation coverage, their study found that compared with traditional vegetation indices, the novel vegetation indices can effectively alleviate the high vegetation saturation problem at low vegetation coverage. In a related study in Zhejiang Province, China, Fang et al. [2] used the optimal variable selection method of different dominant tree species to estimate FSV. Their selected variables included a variety of vegetation indices, such as SRre, MSRre, CIre, and NDI45 developed based on the Sentinel-2 red-edge bands. Almost all of these variables appear in the final variable selection results, which also prove the potential of the red-edge band in estimating forest parameters.
In exploring the potential of NDVIRE to estimate FSV based on the Sentinel-2 red-edge bands, in the variable importance results of the VBM and BVBM, the NDVIRE ranks first. It is worth mentioning that the introduction of weighting coefficients “α” and “β” played a key role in the successful construction of the NDVIRE. The results of this study also indicate that the model’s estimation accuracy of FSV is significantly improved due to the addition of the NDVIRE. First of all, an estimation accuracy of 80.46% is impressive in the research on FSV estimation. Moreover, according to Table 6, we found that the minimum and maximum values in the estimated results of the VBM and BVBM with the NDVIRE involvement are superior to those in the BBM, indicating that the NDVIRE mitigates the issue of light saturation to some extent. In addition, the mean values of FSV predicted by the BVBM in the training phase (56.88 m3ha−1) and the testing phase (60.79 m3ha−1) are also very close to the mean values of the training data (56.66 m3ha−1) and the testing data (63.84 m3ha−1).
Despite the proven efficiency and robustness of the RF algorithm through numerous studies [8,21,35,36,37,38], there is still a limitation observed in its ability to predict the minimum and maximum values of FSV in both the training and testing phases when compared to the actual training and testing data. This limitation results in overestimation of low values and underestimation of high values. Therefore, it would be necessary for future studies to incorporate more machine learning algorithms and innovative machine learning algorithms. From another perspective, deep learning, as a kind of non-parametric machine learning algorithm, is widely applied in forest monitoring. Numerous prior studies have demonstrated the outstanding capability of deep learning algorithms when it comes to target detection and vegetation classification [40,41,42,43,44].
Another paramount limitation of this study is the source of sample plot data which were the most recent. Although “one map” contains a large amount of necessary forest information, using these data to carry out research can no longer meet the current requirements for real-time forest monitoring. In order to resolve this problem in future studies, it is necessary to use unmanned aerial vehicles (UAVs) to obtain enough measured sample plots. Similarly, many studies have proposed UAVs equipped with hyper-spectral and LiDAR sensors to obtain the horizontal and vertical structure information of forests [45,46,47,48,49,50,51]. Its efficiency in obtaining forest parameters is unmatched by manual investigation. The accuracy of tree height, DBH, and spectral information extracted using UAVs is very close to manual surveys. Therefore, as an innovative research method, it is recommended to use UAVs to replace manual field survey work to improve research efficiency where high-precision forest estimation results can be obtained.
5. Conclusions
This study has effectively estimated and mapped the distribution of FSV in the Helan Mountains, with a resolution of 30 m. Utilizing the RF algorithm in conjunction with data from Sentinel-2, the study has affirmed the potential of NDVIRE in FSV estimation. Among all modeled variables, the novel vegetation index NDVIRE, constructed based on the three red-edge bands of Sentinel-2, contributed the most to predicting FSV. Furthermore, the BVBM performed the best among the three models based on the two variables of the band and vegetation index. Finally, this study would assist policymakers in designing forest conservation and management paradigms that could potentially support the sustainability and carbon sequestration dynamics in the Helan Mountains and other montane forest ecosystems.
Author Contributions
Study design: Y.H. and J.W.; Data curation: T.M.; Investigation, D.P., L.C. and X.N.; Methodology: Y.H. and X.L.; Software, T.M.; Supervision, Y.H.; Writing: T.M.; Writing: review & editing: Y.H. and M.B. All authors have read and agreed to the published version of the manuscript.
Funding
This study was supported by the Key Project of Research and Development of Ningxia, China (2021BEB04061, 2022BEG03050), the National Natural Science Foundation of China (32101524), and the National Natural Science Foundation of Ningxia, China (2021AAC03017).
Data Availability Statement
The data presented in this study are available upon request from the corresponding author. The data are not publicly available due to funder regulations.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Hu, Y.; Xu, X.; Wu, F.; Sun, Z.; Xia, H.; Meng, Q.; Huang, W.; Zhou, H.; Gao, J.; Li, W.; et al. Estimating Forest Stock Volume in Hunan Province, China, by Integrating In Situ Plot Data, Sentinel-2 Images, and Linear and Machine Learning Regression Models. Remote Sens. 2020, 12, 186. [Google Scholar] [CrossRef]
- Fang, G.; Fang, L.; Yang, L.; Wu, D. Comparison of Variable Selection Methods among Dominant Tree Species in Different Regions on Forest Stock Volume Estimation. Forests 2022, 13, 787. [Google Scholar] [CrossRef]
- Yao, W.; Chi-Hui, G.; Xi-Jie, C.; Li-Qiong, J.; Xiao-Na, G.; Rui-Shan, C.; Mao-Sheng, Z.; Ze-Yu, C.; Hao-Dong, W. Carbon peak and carbon neutrality in China: Goals, implementation path and prospects. China Geol. 2021, 4, 720–746. [Google Scholar]
- Sun, Y.; Liu, S.; Li, L. Grey Correlation Analysis of Transportation Carbon Emissions under the Background of Carbon Peak and Carbon Neutrality. Energies 2022, 15, 3064. [Google Scholar] [CrossRef]
- Sun, L.; Cui, H.; Ge, Q. Will China achieve its 2060 carbon neutral commitment from the provincial perspective? Adv. Clim. Change Res. 2022, 13, 169–178. [Google Scholar] [CrossRef]
- Pugh, T.A.M.; Lindeskog, M.; Smith, B.; Poulter, B.; Arneth, A.; Haverd, V.; Calle, L. Role of forest regrowth in global carbon sink dynamics. Proc. Natl. Acad. Sci. USA 2019, 116, 4382–4387. [Google Scholar] [CrossRef] [PubMed]
- Astola, H.; Häme, T.; Sirro, L.; Molinier, M.; Kilpi, J. Comparison of Sentinel-2 and Landsat 8 imagery for forest variable prediction in boreal region. Remote Sens. Environ. 2019, 223, 257–273. [Google Scholar] [CrossRef]
- Li, C.; Zhou, L.; Xu, W. Estimating Aboveground Biomass Using Sentinel-2 MSI Data and Ensemble Algorithms for Grassland in the Shengjin Lake Wetland, China. Remote Sens. 2021, 13, 1595. [Google Scholar] [CrossRef]
- Kumar, L.; Mutanga, O. Remote Sensing of Above-Ground Biomass. Remote Sens. 2017, 9, 935. [Google Scholar] [CrossRef]
- Lu, L.; Luo, J.; Xin, Y.; Duan, H.; Sun, Z.; Qiu, Y.; Xiao, Q. How can UAV contribute in satellite-based Phragmites australis aboveground biomass estimating? Int. J. Appl. Earth Obs. 2022, 114, 103024. [Google Scholar] [CrossRef]
- Georganos, S.; Grippa, T.; Niang Gadiaga, A.; Linard, C.; Lennert, M.; Vanhuysse, S.; Mboga, N.; Wolff, E.; Kalogirou, S. Geographical random forests: A spatial extension of the random forest algorithm to address spatial heterogeneity in remote sensing and population modelling. Geocarto Int. 2021, 36, 121–136. [Google Scholar] [CrossRef]
- Hu, Y.; Sun, Z. Assessing the Capacities of Different Remote Sensors in Estimating Forest Stock Volume Based on High Precision Sample Plot Positioning and Random Forest Method. Nat. Environ. Pollut. Technol. 2022, 21, 1113–1123. [Google Scholar] [CrossRef]
- Lister, A.J.; Andersen, H.; Frescino, T.; Gatziolis, D.; Healey, S.; Heath, L.S.; Liknes, G.C.; McRoberts, R.; Moisen, G.G.; Nelson, M.; et al. Use of Remote Sensing Data to Improve the Efficiency of National Forest Inventories: A Case Study from the United States National Forest Inventory. Forests 2020, 11, 1364. [Google Scholar] [CrossRef]
- Chave, J.; Davies, S.J.; Phillips, O.L. Ground Data are Essential for Biomass Remote Sensing Missions. Surv. Geophys. 2019, 40, 863–880. [Google Scholar] [CrossRef]
- Ou, G.; Li, C.; Lv, Y.; Wei, A.; Xiong, H.; Xu, H.; Wang, G. Improving Aboveground Biomass Estimation of Pinus densata Forests in Yunnan Using Landsat 8 Imagery by Incorporating Age Dummy Variable and Method Comparison. Remote Sens. 2019, 11, 738. [Google Scholar] [CrossRef]
- Zhao, P.; Lu, D.; Wang, G.; Wu, C.; Huang, Y.; Yu, S. Examining Spectral Reflectance Saturation in Landsat Imagery and Corresponding Solutions to Improve Forest Aboveground Biomass Estimation. Remote Sens. 2016, 8, 469. [Google Scholar] [CrossRef]
- Lu, D.; Chen, Q.; Wang, G.; Moran, E.; Batistella, M.; Zhang, M.; Vaglio Laurin, G.; Saah, D. Aboveground Forest Biomass Estimation with Landsat and LiDAR Data and Uncertainty Analysis of the Estimates. Int. J. For. Res. 2012, 2012, 1–16. [Google Scholar] [CrossRef]
- Tilly, N.; Aasen, H.; Bareth, G. Fusion of Plant Height and Vegetation Indices for the Estimation of Barley Biomass. Remote Sens. 2015, 7, 11449–11480. [Google Scholar] [CrossRef]
- Kross, A.; McNairn, H.; Lapen, D.; Sunohara, M.; Champagne, C. Assessment of RapidEye vegetation indices for estimation of leaf area index and biomass in corn and soybean crops. Int. J. Appl. Earth Obs. 2015, 34, 235–248. [Google Scholar] [CrossRef]
- Li, C.; Chimimba, E.G.; Kambombe, O.; Brown, L.A.; Chibarabada, T.P.; Lu, Y.; Anghileri, D.; Ngongondo, C.; Sheffield, J.; Dash, J. Maize Yield Estimation in Intercropped Smallholder Fields Using Satellite Data in Southern Malawi. Remote Sens. 2022, 14, 2458. [Google Scholar] [CrossRef]
- Luo, W.; Kim, H.S.; Zhao, X.; Ryu, D.; Jung, I.; Cho, H.; Harris, N.; Ghosh, S.; Zhang, C.; Liang, J. New forest biomass carbon stock estimates in Northeast Asia based on multisource data. Glob. Chang. Biol. 2020, 26, 7045–7066. [Google Scholar] [CrossRef]
- Shen, X.; Cao, L.; Yang, B.; Xu, Z.; Wang, G. Estimation of Forest Structural Attributes Using Spectral Indices and Point Clouds from UAS-Based Multispectral and RGB Imageries. Remote Sens. 2019, 11, 800. [Google Scholar] [CrossRef]
- Xiao, C.; Li, P.; Feng, Z.; Liu, Y.; Zhang, X. Sentinel-2 red-edge spectral indices (RESI) suitability for mapping rubber boom in Luang Namtha Province, northern Lao PDR. Int. J. Appl. Earth Obs. 2020, 93, 102176. [Google Scholar] [CrossRef]
- Roy, D.; Li, Z.; Zhang, H. Adjustment of Sentinel-2 Multi-Spectral Instrument (MSI) Red-Edge Band Reflectance to Nadir BRDF Adjusted Reflectance (NBAR) and Quantification of Red-Edge Band BRDF Effects. Remote Sens. 2017, 9, 1325. [Google Scholar] [CrossRef]
- Bramich, J.; Bolch, C.J.S.; Fischer, A. Improved red-edge chlorophyll-a detection for Sentinel 2. Ecol. Indic. 2021, 120, 106876. [Google Scholar] [CrossRef]
- Delegido, J.; Verrelst, J.; Alonso, L.; Moreno, J. Evaluation of Sentinel-2 Red-Edge Bands for Empirical Estimation of Green LAI and Chlorophyll Content. Sensors 2011, 11, 7063–7081. [Google Scholar] [CrossRef]
- Liu, J.; Fan, J.; Yang, C.; Xu, F.; Zhang, X. Novel vegetation indices for estimating photosynthetic and non-photosynthetic fractional vegetation cover from Sentinel data. Int. J. Appl. Earth Obs. 2022, 109, 102793. [Google Scholar] [CrossRef]
- Bilal, M.; Nichol, J.E. Evaluation of the NDVI-Based Pixel Selection Criteria of the MODIS C6 Dark Target and Deep Blue Combined Aerosol Product. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2017, 10, 3448–3453. [Google Scholar] [CrossRef]
- Asgarian, A.; Amiri, B.J.; Sakieh, Y. Assessing the effect of green cover spatial patterns on urban land surface temperature using landscape metrics approach. Urban Ecosyst. 2015, 18, 209–222. [Google Scholar] [CrossRef]
- Ouma, Y.O.; Noor, K.; Herbert, K. Modelling Reservoir Chlorophyll-a, TSS, and Turbidity Using Sentinel-2A MSI and Landsat-8 OLI Satellite Sensors with Empirical Multivariate Regression. J. Sens. 2020, 2020, 1–21. [Google Scholar] [CrossRef]
- Warren, M.A.; Simis, S.G.H.; Martinez-Vicente, V.; Poser, K.; Bresciani, M.; Alikas, K.; Spyrakos, E.; Giardino, C.; Ansper, A. Assessment of atmospheric correction algorithms for the Sentinel-2A MultiSpectral Imager over coastal and inland waters. Remote Sens. Environ. 2019, 225, 267–289. [Google Scholar] [CrossRef]
- Huang, H.; Roy, D.; Boschetti, L.; Zhang, H.; Yan, L.; Kumar, S.; Gomez-Dans, J.; Li, J. Separability Analysis of Sentinel-2A Multi-Spectral Instrument (MSI) Data for Burned Area Discrimination. Remote Sens. 2016, 8, 873. [Google Scholar] [CrossRef]
- Jin, Y.; Yang, X.; Qiu, J.; Li, J.; Gao, T.; Wu, Q.; Zhao, F.; Ma, H.; Yu, H.; Xu, B. Remote Sensing-Based Biomass Estimation and Its Spatio-Temporal Variations in Temperate Grassland, Northern China. Remote Sens. 2014, 6, 1496–1513. [Google Scholar] [CrossRef]
- Xue, J.; Su, B. Significant Remote Sensing Vegetation Indices: A Review of Developments and Applications. J. Sens. 2017, 2017, 1–17. [Google Scholar] [CrossRef]
- Liu, Z.; Ye, Z.; Xu, X.; Lin, H.; Zhang, T.; Long, J. Mapping Forest Stock Volume Based on Growth Characteristics of Crown Using Multi-Temporal Landsat 8 OLI and ZY-3 Stereo Images in Planted Eucalyptus Forest. Remote Sens. 2022, 14, 5082. [Google Scholar] [CrossRef]
- Wang, L.; Zhou, X.; Zhu, X.; Dong, Z.; Guo, W. Estimation of biomass in wheat using random forest regression algorithm and remote sensing data. Crop J. 2016, 4, 212–219. [Google Scholar] [CrossRef]
- Torre-Tojal, L.; Bastarrika, A.; Boyano, A.; Lopez-Guede, J.M.; Graña, M. Above-ground biomass estimation from LiDAR data using random forest algorithms. J. Comput. Sci. 2022, 58, 101517. [Google Scholar] [CrossRef]
- Li, X.; Ye, Z.; Long, J.; Zheng, H.; Lin, H. Inversion of Coniferous Forest Stock Volume Based on Backscatter and InSAR Coherence Factors of Sentinel-1 Hyper-Temporal Images and Spectral Variables of Landsat 8 OLI. Remote Sens. 2022, 14, 2754. [Google Scholar] [CrossRef]
- Glushkova, M.; Zhiyanski, M.; Nedkov, S.; Yaneva, R.; Stoeva, L. Ecosystem services from mountain forest ecosystems: Conceptual framework, approach and challenges. Silva Balc. 2020, 21, 47–68. [Google Scholar] [CrossRef]
- Zhang, L.; Shao, Z.; Liu, J.; Cheng, Q. Deep Learning Based Retrieval of Forest Aboveground Biomass from Combined LiDAR and Landsat 8 Data. Remote Sens. 2019, 11, 1459. [Google Scholar] [CrossRef]
- Ayhan, B.; Kwan, C.; Budavari, B.; Kwan, L.; Lu, Y.; Perez, D.; Li, J.; Skarlatos, D.; Vlachos, M. Vegetation Detection Using Deep Learning and Conventional Methods. Remote Sens. 2020, 12, 2502. [Google Scholar] [CrossRef]
- Bhatnagar, S.; Gill, L.; Ghosh, B. Drone Image Segmentation Using Machine and Deep Learning for Mapping Raised Bog Vegetation Communities. Remote Sens. 2020, 12, 2602. [Google Scholar] [CrossRef]
- Liu, M.; Fu, B.; Xie, S.; He, H.; Lan, F.; Li, Y.; Lou, P.; Fan, D. Comparison of multi-source satellite images for classifying marsh vegetation using DeepLabV3 Plus deep learning algorithm. Ecol. Indic. 2021, 125, 107562. [Google Scholar] [CrossRef]
- Lees, T.; Tseng, G.; Atzberger, C.; Reece, S.; Dadson, S. Deep Learning for Vegetation Health Forecasting: A Case Study in Kenya. Remote Sens. 2022, 14, 698. [Google Scholar] [CrossRef]
- Qin, H.; Zhou, W.; Yao, Y.; Wang, W. Estimating Aboveground Carbon Stock at the Scale of Individual Trees in Subtropical Forests Using UAV LiDAR and Hyperspectral Data. Remote Sens. 2021, 13, 4969. [Google Scholar] [CrossRef]
- Qin, H.; Zhou, W.; Yao, Y.; Wang, W. Individual tree segmentation and tree species classification in subtropical broadleaf forests using UAV-based LiDAR, hyperspectral, and ultrahigh-resolution RGB data. Remote Sens. Environ. 2022, 280, 113143. [Google Scholar] [CrossRef]
- Dashti, H.; Poley, A.; Glenn, N.F.; Ilangakoon, N.; Spaete, L.; Roberts, D.; Enterkine, J.; Flores, A.N.; Ustin, S.L.; Mitchell, J.J. Regional Scale Dryland Vegetation Classification with an Integrated Lidar-Hyperspectral Approach. Remote Sens. 2019, 11, 2141. [Google Scholar] [CrossRef]
- Zhu, W.; Sun, Z.; Peng, J.; Huang, Y.; Li, J.; Zhang, J.; Yang, B.; Liao, X. Estimating Maize Above-Ground Biomass Using 3D Point Clouds of Multi-Source Unmanned Aerial Vehicle Data at Multi-Spatial Scales. Remote Sens. 2019, 11, 2678. [Google Scholar] [CrossRef]
- Picos, J.; Bastos, G.; Míguez, D.; Alonso, L.; Armesto, J. Individual Tree Detection in a Eucalyptus Plantation Using Unmanned Aerial Vehicle (UAV)-LiDAR. Remote Sens. 2020, 12, 885. [Google Scholar] [CrossRef]
- Santos, A.A.D.; Marcato Junior, J.; Araújo, M.S.; Di Martini, D.R.; Tetila, E.C.; Siqueira, H.L.; Aoki, C.; Eltner, A.; Matsubara, E.T.; Pistori, H.; et al. Assessment of CNN-Based Methods for Individual Tree Detection on Images Captured by RGB Cameras Attached to UAVs. Sensors 2019, 19, 3595. [Google Scholar] [CrossRef]
- Sankey, T.T.; McVay, J.; Swetnam, T.L.; McClaran, M.P.; Heilman, P.; Nichols, M.; Pettorelli, N.; Horning, N.; Pettorelli, N.; Horning, N. UAV hyperspectral and lidar data and their fusion for arid and semi-arid land vegetation monitoring. Remote Sens. Ecol. Conserv. 2018, 4, 20–33. [Google Scholar] [CrossRef]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).