1. Introduction
As a penetrating active sensor, synthetic aperture radar (SAR) is not limited by time or weather conditions and plays an important role in remote sensing [
1]. With the development of sensor technology, SAR imaging mode has been expanded from single-polarization to full-polarization with more available scattering information, and the previous study [
2] has proven that the utilization of polarimetric information can significantly improve the performance of polarimetric SAR (PolSAR) target interpretation. Ship detection has been a hot topic of research in SAR/PolSAR applications for many years. It helps to strengthen the management of maritime traffic and has a good application prospect in both civilian and military fields, such as safeguarding maritime rights and interests and improving maritime early warning capabilities.
SAR/PolSAR ship detection approaches can be classified into statistical characteristic-based, polarimetric feature-based, and spatial feature-based methods. The statistical characteristic-based method is based on the assumption that the sea background is relatively dark to ship targets, therefore, ships can be detected by modeling the sea clutter through statistical analysis and searching for outliers. The constant false alarm rate (CFAR) and its variants [
3] belong to this kind of method. Gao et al. [
4,
5,
6] studied the statistical modeling and parameter estimation of clutter for ship detection. Tao et al. [
7] proposed an adaptive truncation method to estimate the parameter of the statistical model, and Liu et al. [
8] extended it to PolSAR images. The polarimetric feature-based method distinguishes the ship from the sea clutter with the help of polarimetric features. Ringrose et al. [
9] applied the polarimetric features obtained by Cameron decomposition for ship detection in the ocean. Touzi et al. [
10] used the polarization entropy, eigenvalue and average of scattering angles decomposed from the polarimetric covariance matrix to detect ships. Chen et al. [
11] proposed polarization cross-entropy and proved the effectiveness of this feature in ship detection on AIRSAR data. Sugimoto et al. [
12] utilized the decomposition of the four-component model proposed by Yamaguchi for ship detection. Yang et al. [
13,
14] proposed the generalized optimization of polarimetric contrast enhancement (GOPCE) to detect ships. Gao et al. [
15] combined polarization entropy and backscattered energy to detect ships in PolSAR images, showing the advantages of feature fusion in the energy domain and the polarization domain. Xu et al. [
16] proposed a new parameter, surface scanning randomness (SSR), to enhance the contrast between wake and sea. The potential ship wakes can be extracted through the digital axoids transform of SSR, and the ships are detected indirectly by detecting ship wakes. The spatial feature-based method uses artificially designed or automatically learned features extracted in the spatial domain for discriminating ships from sea clutter. Early traditional methods rely on features and detectors designed by experts. Kaplan et al. [
17] proposed an extended fractal feature that is sensitive to the target scale and can achieve fast detection. Grandi et al. [
18] used the wavelet features for detecting targets in PolSAR images, which explained the dependence of texture measurement on the polarization state. In addition, deep learning is also a method based on spatial features.
At present, deep learning has become the mainstream method in ship detection for its excellent spatial feature extraction ability. Li et al. [
19] used the Faster R-CNN architecture, and Lin et al. [
20] improved the performance of SAR ship detection by using the squeeze and excitation mechanisms. Wang et al. [
21] applied a single-shot multi-box detector (SSD) to target detection in SAR images and boosted the detection precision with data augmentation and transfer learning. Zhang et al. [
22] proposed a high-speed SAR ship detection approach by improving you only look once version 3 (YOLOv3) and realized fast detection on a public SAR ship detection dataset (SSDD) by simplifying the network structure. Zhu et al. [
23] took fully convolutional one-stage object detection (FCOS) as the baseline and re-designed its feature extraction, classification and regression to detect dim and small ships in large-scale SAR images with higher accuracy. Similarly, they introduced the adaptive training sample selection (ATSS) version of FCOS (FCOS and ATSS) as the baseline and improved it for ship detection in SAR images [
24]. Most of the current deep learning-based SAR ship detection research focuses on single-polarization SAR images, which mainly extract the spatial features of SAR ships. However, the studies with regard to deep learning-based ship detection in PolSAR images are few, and the polarimetric features are also not well utilized in these studies. In summary, it is meaningful to explore a PolSAR ship detection method utilizing neural networks to process the polarimetric feature, and which kind of polarimetric feature is more suitable for the network is also worth investigating. How to better extract polarimetric and spatial features in the process of PolSAR ship detection based on deep learning is an urgent problem to be solved, and so this paper aims to put forward a PolSAR ship detection method by better making use of the polarimetric and spatial information.
Another issue that needs to be addressed for PolSAR ship detection based on deep learning is the few-shot problem because of the scarce data. The acquisition of labeled PolSAR ship is not as simple as that of natural images, and the following characteristics of PolSAR targets exacerbate the issue. The scattering characteristic of a PolSAR target is sensitive to the relative geometric relation between target orientation and radar line of sight [
25,
26]. For the same target, when its orientation relative to the radar line of sight is different, its polarimetric features could be significantly different. For different targets, they may also exhibit very similar polarimetric scattering features under specific orientations. The same issue occurs for the spatial features. To sum up, the scattering diversity of PolSAR targets presents a great challenge for target detection in PolSAR images, especially when there are only a few training samples, since it is extremely hard to learn the effective discriminating features with quite limited samples for the data-driven method. What is more, azimuth ambiguity, reef influence, and high sea conditions also increase the difficulty of PolSAR ship detection with only a few labeled training samples, since the model is prone to overfit the training data and thus lacks generalization ability to the un-seen data. Under the few-shot case, interference objects such as offshore drilling platforms, reefs, lighthouses, buoys, etc. are probably wrongly recognized as ships, and some ships could go un-detected due to the complex background. Few-shot learning in SAR target interpretation has attracted lots of attention. Rostami et al. [
27,
28] borrowed the knowledge from the panchromatic remote sensing image classification task to the SAR image classification task through transfer learning to mitigate the few-shot issue of SAR data, and the distribution difference of features in the panchromatic domain and the SAR domain is minimized through domain adaptation. Wang et al. [
29] used a hybrid inference network combining inductive inference and transductive inference to predict the class of the feature space mapped by the embedded network, and completed the classification of few-shot SAR images by enhancing the interclass separability in the embedding space with a novel loss function named enhanced hybrid loss. Fu et al. [
30] proposed a meta-learning framework consisting of a meta-learner and a basic learner that can learn a good initialization as well as a proper update strategy and implement fast adaptation with a few training images on new tasks after training. Each of the aforementioned few-shot learning methods presents certain limitations. Transfer learning typically involves a more intricate design process, necessitating the meticulous selection of transfer schemes that are specifically tailored to the particular problem at hand [
31]. The transductive inference method is challenging to integrate into various target detection frameworks, and the meta-learning approach relies on a sequence of similar tasks. Therefore, it is imperative to explore alternative approaches to mitigate these shortcomings. Recently, contrastive self-supervised learning (CSSL) has achieved impressive results for few-shot learning in the field of computer vision, which learns general representations from massive un-labeled data, and can be used in downstream tasks with only a few samples to finetune the pre-trained model. The basic principle of CSSL is to learn the underlying image representations by grouping similar samples (positive pairs) together and pushing diverse samples (negative pairs) away from each other. The representative methods include MOCO [
32] and SimCLR [
33]. There are other kinds of CSSL methods that only make use of positive pairs, such as BYOL [
34] and SimSiam [
35]. The reason for taking out negative pairs is that the samples in a negative pair could be very similar, making the training model hard to converge. Another advantage of the CSSL method without negative pairs is its training efficiency. By only processing the positive pairs, many resource consumptions can be saved. The research on the application of CSSL in remote sensing is at an elementary stage [
36], and most current studies are conducted for classification tasks. Similarly, Zhang et al. [
37] proposed a PolSAR-tailored contrastive learning network (PCLNet), which learns useful representations from un-labeled PolSAR data through an un-supervised pre-training phase. The acquired representations are transferred to the downstream task to achieve few-shot PolSAR classification. Yang et al. [
38] proposed a coarse-to-fine CSSL framework, which made the global and local features learned respectively through the pre-training of two stages and realized the land-cover classification in SAR images with limited labeled data. How to apply CSSL on the PolSAR ship detection task for coping with the few-shot issue needs to be investigated, and this is another purpose of this study.
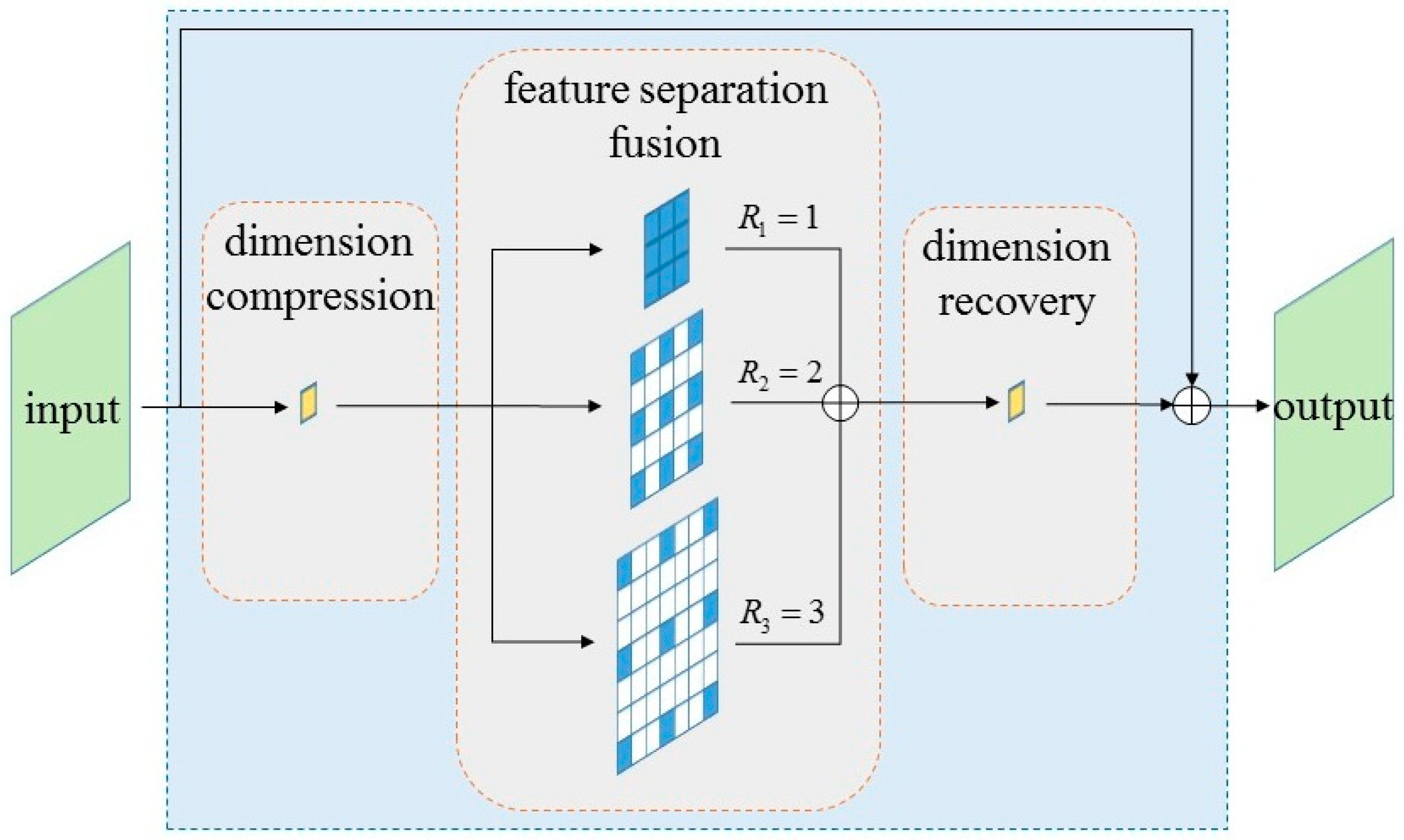
In this paper, we propose a few-shot PolSAR ship detection method based on polarimetric feature selection and improved contrastive self-supervised learning. Firstly, eight polarimetric features obtained via various polarization decompositions, polarimetric coherence, and speckle filtering are taken into consideration to serve as the input of the network. Then, taking SimSiam as the baseline, an improved CSSL method with a multi-scale feature fusion module (MFFM) and mix-up auxiliary pathway (MUAP) is proposed to learn the effective representation of PolSAR data. Specifically speaking, MFFM is proposed to replace the common convolution layer in the residual block. The input feature map of MFFM is divided into several groups along the channel dimension. These groups are individually passed through dilated convolution layers with various dilation rates, so multi-scale feature maps can be obtained by the above-mentioned process. The multi-scale feature maps are merged through the concatenation operation along the channel dimension to get the output feature map of MFFM. MFFM can enhance the representation ability of the network by merging multi-scale features and enlarging the receptive field through a dilated convolution operation. MUAP takes the linear combination of the two inputs of the vanilla CSSL as its input and encourages the model to behave linearly in-between training samples. MUAP enriches the diversity of the input and promotes the robustness of the representations learned by CSSL. Finally, the model pre-trained from the improved CSSL is taken as the feature extractor of the Faster R-CNN detector and finetuned with a few PolSAR ships. The main contributions of this paper are summarized as follows:
- (1)
To our best knowledge, this is the first study introducing self-supervised learning into PolSAR ship detection. An obvious performance gain is achieved by CSSL, especially when the training samples are few.
- (2)
We propose an improved CSSL method with two new modules. The multi-scale feature fusion module enhances the representation capability via multi-scale feature fusion, and the mix-up auxiliary pathway improves the robustness of the features through a mix-up regularization strategy.
- (3)
Eight various polarimetric features are extracted by different polarization decomposition, polarimetric coherence, and speckle filtering, and the effect of them with the proposed improved CSSL method is compared to explore which polarimetric feature is more suitable to our contrastive learning framework.
- (4)
Comprehensive experiments are conducted to validate the effectiveness of the proposed method, and the results indicate that our method achieves state-of-the-art PolSAR ship detection performance in comparison with recent studies, especially under the few-shot situation. In addition, our method also mitigates the shortcomings of other few-shot learning methods.
The remainder of this paper is organized as follows: The proposed method is detailed in
Section 2, followed by experimental results in
Section 3. Some discussions are presented in
Section 4, and
Section 5 concludes the paper.
3. Experimental Results
In this section, comprehensive experiments are conducted to validate the effectiveness of the proposed method. Specifically speaking, (1) the effect of input data with polarimetric features constructed by different type of polarimetric feature extraction algorithms are explored, (2) the soundness of the proposed improved CSSL method will be validated by comparing the detection performance of the network with the pre-trained backbone and the network trained from scratch, and (3) the impact of the structure of backbone on the detection accuracy is also discussed.
3.1. Data Description
We use 26 fully PolSAR images from Chinese GF-3 satellite at different locations for experiments, of which 8 PolSAR images are used for the backbone pre-training and 18 PolSAR images are used for the ship detection network training and detection. GF-3 satellite is one of the civilian space-borne SAR systems with 12 imaging modes, such as stripmap, spotlight, scanSAR and so on, and the resolution can reach up to 1 m [
54]. The used 26 fully PolSAR images are obtained by the imaging mode of QPSI, and has the spatial resolution of 8 m and the observation swath of 30 km. The product level is L1A, which provides the complex data of images with HH, HV, VH and VV polarizations.
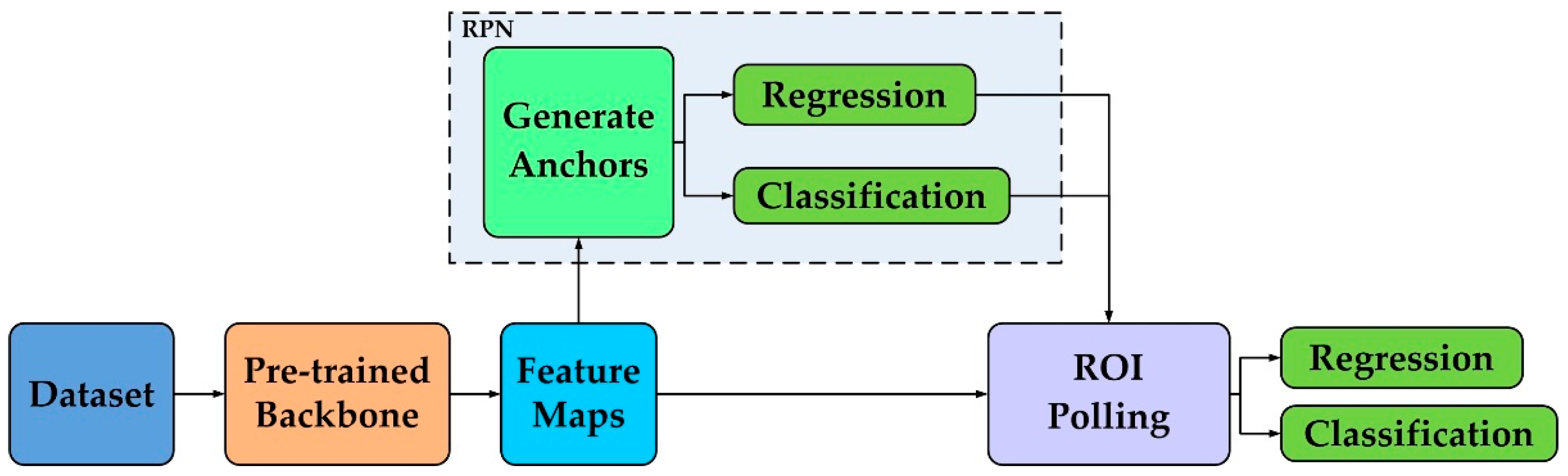
The experiment includes backbone pre-training based on the improved CSSL mthod and fine-tuning based on Faster R-CNN target detection network.
In the improved CSSL pre-training stage, eight GF-3 PolSAR images containing multiple scenes (ocean, port, hill, city, etc.) are selected for making self-supervised PolSAR datasets to train the feature extraction backbone network. These 8 GF-3 PolSAR images range from 3891 pixels to 7834 pixels in width and 5938 pixels to 8072 pixels in height. In order to make full use of the input images with various polarimetric features, according to the 8 polarimetric feature extraction methods, the channel superposition method is used to fuse the images extracted by each method, and a total of 8 × 8 fused images are obtained where 8 is the number of original PolSAR images. Then we cut the 8 original images into small images which are 40 pixels by 40 pixels. After the cutting operation, a total of 225,313 un-labeled PolSAR small size images are obtained by each polarimetric feature extraction method. These images form the un-supervised PolSAR dataset and are used to pre-train the feature extraction backbone network by the improved CSSL method.
In the Faster R-CNN network training stage, 18 PolSAR images with ships in open sea, nearshore and in harbor scenario near the area of Shanghai and Hong Kong are taken to construct the training and the test datasets for ship detection. The datasets also adopts the channel superposition method to obtain 8 × 18 fused images with 8 polarimetric feature extraction methods on the 18 original PolSAR images, and the fused images are cut into multiple 512 pixels × 512 pixels small size images. Furthermore, in order to reduce the useless information in the dataset and improve the learning effect, small size images are filtered based on whether they contain complete ship targets. Then, each polarimetric feature extraction method obtained 283 labeled small size images containing ship targets. Among them, 198 images (70% of the total number of images) are set as the training set and 89 images (30% of the total number of images) are set as the test set. The open source annotation tool Labelme is used for labeling the ships in the COCO format.
One labeled image is shown in
Figure 5a, and
Figure 5b–d gives the three local close-ups.
Figure 5b shows a patch containing a labeled ship.
Figure 5c,d illustrates two patches containing an island and an azimuth ambiguity respectively, which are similar with ships and thus are prone to form false alarms, indicating the challenge of the task.
3.2. Experimental Setup and Evaluation Index
We implement the proposed algorithm through python 3.6 and the open-source deep learning library PyTorch 1.9.0, and execute it on a 64-bit Ubuntu 20.04 workstation with 12 GB memory GeForce RTX3060 GPU. In the improved CSSL pre-training stage, the SGD method is used to train 20 epochs for the proposed network. The batch size is set as 32, the initial learning rate is set as 0.002, and the momentum and weight decay are set as 0.9 and 0.0005, respectively. The argument for the mixed coefficient resulting from the beta distribution is set as 1.0, in the final loss is set as 0.5. In the Faster R-CNN network training stage, the SGD method is used to train 20 epochs for the Faster R-CNN network. The batch size is set as 8, the initial learning rate is set as 0.005, and the momentum and weight decay are set as 0.9 and 0.0005, respectively. In the first five epochs of training, we freeze the feature extraction network weights, then train the RPN network and the detection network. In the subsequent 15 epochs of training, we un-freeze the feature extraction network weights, and train all network parameters at the same time.
The evaluation indicator is the standard to measure the training effect of the model. In the process of our model’s training and testing, accuracy, precision, recall, and mean average precision (mAP) are mainly selected as the evaluation indicators. The combination of sample real class and model prediction class is divided into four cases: true positive, false positive, true negative and false negative. We denote them by , , and respectively. Obviously, + + + = total number of samples.
means the ratio of correct prediction made by the model, which is defined as:
means the ratio of actually positive examples in the examples divided into positive examples. In the case of un-balanced positive and negative samples, the
will have problems in measuring the prediction effect of the model, and the
makes up for this defect.
is defined as:
means the ratio of positive samples predicted as positive samples in the total positive samples, reflecting the comprehensiveness of the model’s prediction of positive samples, which is defined as:
Mean Average Precision (mAP) means the mean value of all classifications’ AP. Since there is only one classification (ship), mAP = AP. AP defined as the area under the precision-recall curve.
3.3. PolSAR Ship Detection Experiments
3.3.1. Ablation Experiments
In the experiments, we extracted the polarimetric features of the original PolSAR images and constructed multi-channel input data through Pauli, Cloude, Freeman, Yamaguchi, Cui, Coherence, Refined Lee and Adaptive methods. The constructed input image is shown in
Figure 6. The number of channels of the input image obtained by different polarimetric feature extraction methods is different, methods Cloude and Yamaguchi obtaine 4-channel images, and other methods obtaine 3-channel images. As shown in
Figure 6a–c, the three images obtained by Pauli decomposition respectively represent: odd-bounce scattering energy, corresponding to channel B; volume scattering energy, corresponding to channel G; and double-bounce scattering energy, corresponding to channel R.
Figure 6d is the pseudo-color image of above, that is, the multi-channel input data. Similarly,
Figure 6e–h show the polarization entropy, average of scattering angles, polarization anti-entropy, and scattering power SPAN obtained by Cloude decomposition.
Figure 6i–k show the surface, volume, and double-bounce scattering obtained by Cui decomposition.
Figure 6m–o show the images obtained by Pauli decomposition after Adaptive filtering. The images obtained by Freeman and Yamaguchi are similar in appearance to those obtained by Cui, the images obtained by Refined Lee are similar in appearance to those obtained by Adaptive, and the images obtained by Coherence are very dark because of the value is within [0,1). Therefore, the images of the remaining four methods will not be shown. Input data containing multiple polarimetric features are used in subsequent experiments to study the effect of various factors on the detection results.
Firstly, we explored the effect of the input data constructed by eight polarimetric feature extraction methods on the detection results. Quantitative results comparison is summarized in
Table 1. As seen from the detection results, after the pre-training of our method under the input of all data which contains 198 labeled samples, the Adaptive method achieves the best detection result of 0.935 (AP). The detection results of the Refined Lee method, which is also a speckle filtering method as same as the Adaptive method, and the Pauli method, which is the basis of the two speckle filtering methods, both exceeding 0.93 together. The Cui method is one of the three polarization decomposition methods based on scattering model, and its detection result exceeding 0.9, reaching 0.921. The above four methods also obtain better detection results than other methods in the case of other input sample numbers and train from scratch [
55]. In addition, the detection result of the Coherence method is the worst, which is less than 0.325. The huge difference of the detection results obtained by different polarimetric feature inputs proves that selecting the appropriate polarimetric feature extraction method is helpful to improve the effect of ship detection.
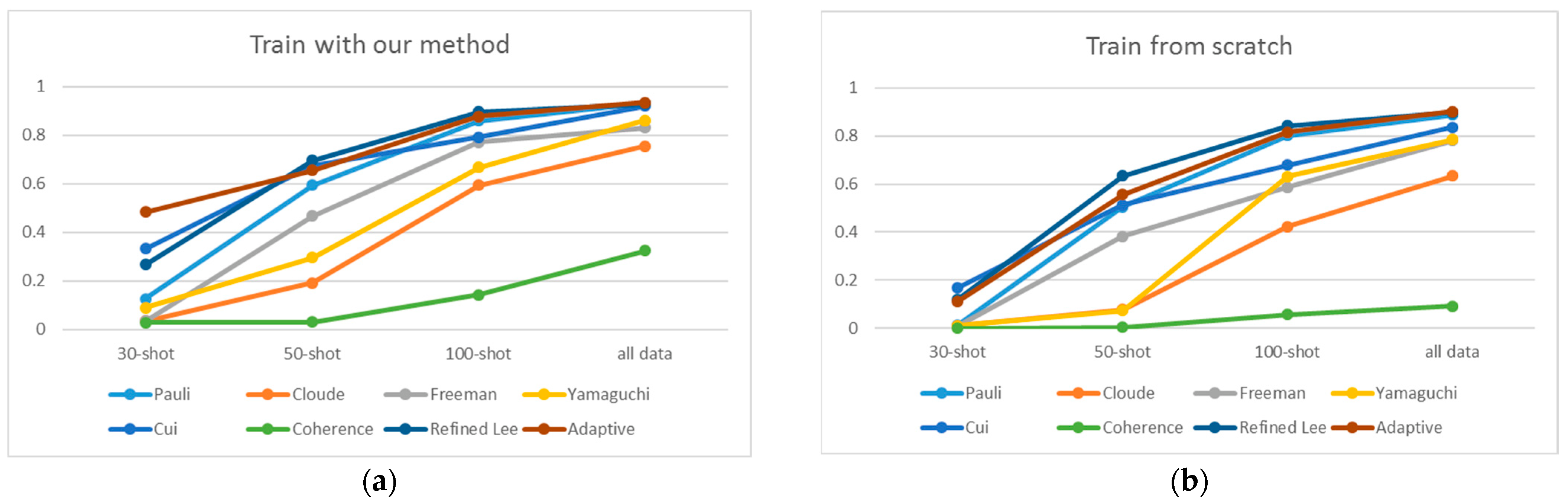
Secondly, we compared the ship detection results with and without pre-training under different training sample numbers. As shown in
Table 1, under the factors of 8 polarimetric feature inputs and four kinds of input sample numbers, the detection results have been improved after the pre-training of the proposed method. The visualization of detection results is shown in
Figure 7. Specifically,
Figure 7a–c show that after pre-training, the false detection caused by near-shore has been avoided, and one of the two near-shore ships has been successfully detected;
Figure 7d–f show that the missed detection caused by sidelobe is successfully detected after pre-training;
Figure 7g–i show that after pre training, two of the three missed detections caused by dense targets have been successfully detected;
Figure 7j–l show that, the missed detection caused by defocusing is successfully detected after pre training;
Figure 7m–o show that the missed detection caused by small targets is successfully detected after pre-training. As seen from
Figure 8, under some polarimetric feature input factors, when the number of input samples decreases, the detection result will decrease rapidly. For example, when the number of input samples of Cloude method decreases from 100-shot to 50-shot, and when the number of input samples of Pauli, Freeman, and Refined Lee method decreases from 50-shot to 30-shot, the detection results decreases by more than 0.4 (AP). This shows that although pre-training can improve the detection effect on few-shot PolSAR ship detection task, when the number of input samples is reduced to a certain threshold, the generalization ability of the model will be insufficient.
Finally, we compared the original contrastive learning method with the proposed improved CSSL method and presented ablation experiments on each module of the proposed method to understand their effectiveness. The results are shown in
Table 2. The polarimetric feature extraction method of the input data adopts the Adaptive method. After the original SimSiam method is optimized by the MFFM module and the MUAP module, respectively, the ship detection results are improved, which shows that both modules contribute to improving the performance of the pre-training network. We also conducted experiments on the effect of different structures of backbone on the detection results, including ResNet-18, ResNet-34, ResNet-50 and ResNet-101. The polarimetric feature extraction method of the input data is the Adaptive method, and the results are shown in
Table 3. When the backbone is ResNet-34, the best detection result is obtained, which is 0.942, followed by ResNet-18, which is reduced by 0.007. Considering the efficiency of pre-training, we chose ResNet-18 as the backbone of our method.
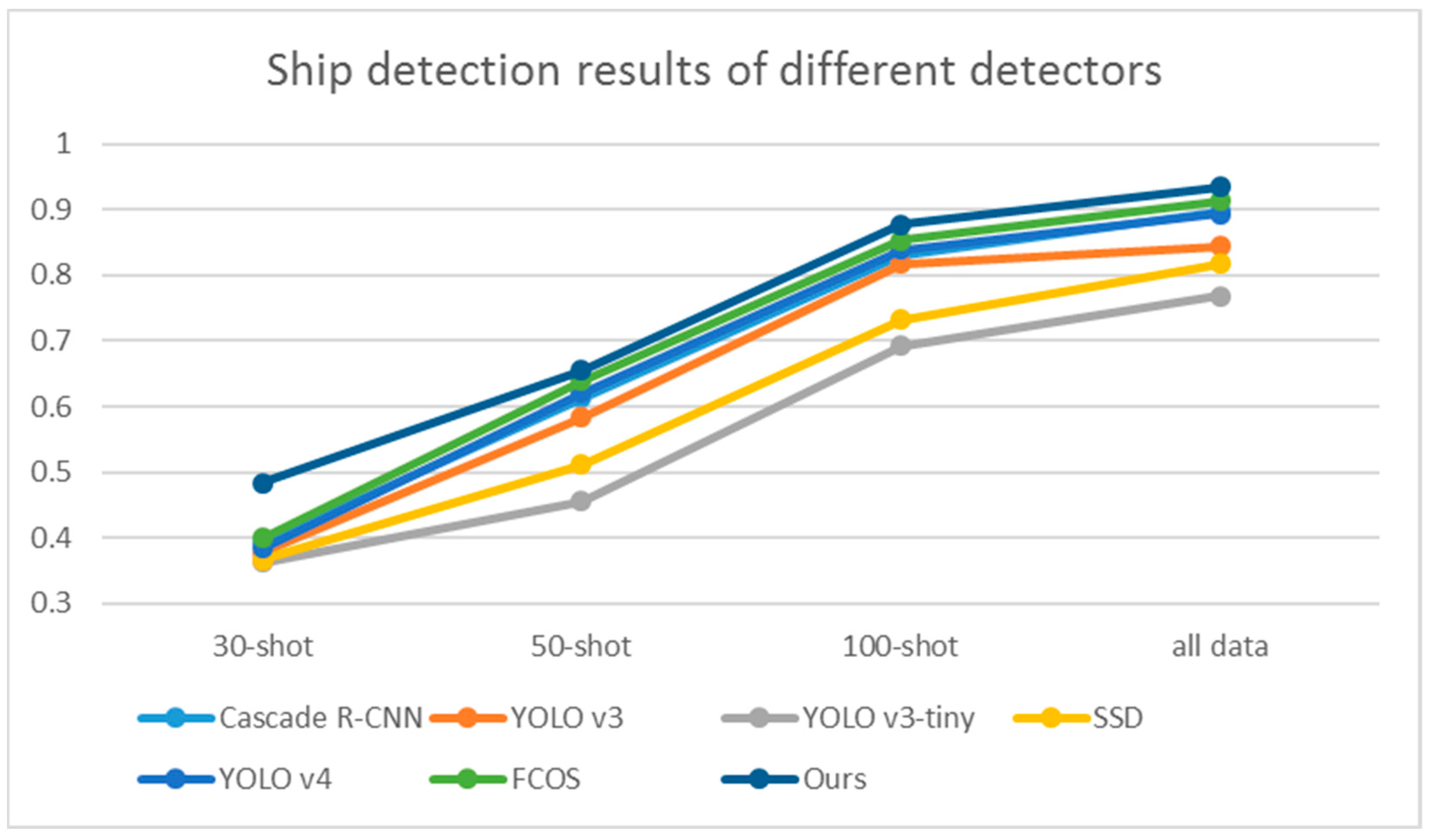
3.3.2. Comparison Experiments
We compared our method with some classic target detectors, including Cascade R-CNN [
56], YOLO v3 [
57], YOLO v3-tiny [
58], SSD [
59], YOLO v4 [
60] and FCOS [
61]. The polarimetric feature extraction method of the input data adopts the Adaptive method, and the backbone adopts ResNet-18. The results are shown in
Table 4. It can be observed that our method has achieved the best detection results under the factors of each input sample number. The test result next to our method is the FCOS method, and the worst detection result is YOLO v3-tiny method. The visualization of detection results is shown in
Figure 9. Specifically,
Figure 9a–c show that the missed detection caused by complex background and small targets that cannot be detected by all classic detectors has been successfully detected by our method;
Figure 9d–f show that the missed detection caused by proximity to edges and small targets that cannot be detected by all classic detectors except SSD has been successfully detected by our method;
Figure 9g–i show that the missed detection caused by defocusing that cannot be detected by only SSD method has been successfully detected by our method;
Figure 9j–l show that the missed detection caused by proximity to edges and small targets that cannot be detected by YOLO v3, YOLO v3-tiny, and FCOS methods has been successfully detected by our method;
Figure 9m–o show that the missed detection caused by small targets that cannot be detected by Cascade R-CNN, SSD, YOLO v3, and YOLO v4 methods has been successfully detected by our method. By comparing the test results with the FCOS method under the factors of different input sample numbers, it can be seen from
Figure 10 that our method has made a great improvement in the case of a few numbers of training samples. The comparison with other detectors also confirmed this point. In conclusion, the results of comparison experiments verify the effectiveness of our method in few-shot PolSAR ship detection task.
Our method applies the pre-trained backbone to the downstream target detection network. Only a few labeled samples are used for fine-tuning to achieve the few-shot PolSAR ship detection effect. Therefore, our method does not depend on the target detection framework. To better demonstrate the effectiveness of our proposed methodology and its adaptability to different ship detection frameworks, we replaced the Faster-RCNN baseline with YOLO v5 [
62] and FCOS. Specifically, the original backbone networks of YOLO v5 and FCOS will be replaced by our pre-trained ResNet-18 with the FMMF module, while other components, such as the neck module, will be retained. The results are presented in
Table 5. From the table, it is evident that the YOLO v5 and FCOS networks, enhanced through our pre-training methodology, exhibit improved performance compared to their original versions. Therefore, it can be concluded that the effectiveness of our proposed methodology is universally applicable and does not depend on a specific object detection framework.
In order to demonstrate the superiority of our proposed method, we make a comparison with two state-of-the-art few-shot learning methods, including SAMBFS-FSDet [
63] and G-FSDet [
64]. As for the two methods, Faster R-CNN and TFA [
65] are used for the few-shot object detection framework. In the fine-tuning stage, we use the previously labeled ship samples as the novel classes to achieve a few-shot ship detection target. The comparison results are presented in
Table 6. From the table, it can be observed that our proposed method is still competitive compared to the state-of-the-art few-shot learning methods.
4. Discussion
By analyzing the effect of eight polarimetric feature extraction methods in
Table 1 on the detection results, we find that the input data constructed by Pauli decomposition, Refined Lee filtering and Adaptive filtering have achieved good detection results, exceeding 0.93 (AP). Since the Refined Lee filtering and Adaptive filtering are speckle filtering methods based on the Pauli decomposition, this shows that the Pauli decomposition method extracts more effective polarimetric and spatial features. Through speckle filtering, the spatial features are further enhanced at the cost of a certain loss of the polarimetric features. The detection results of the two speckle filtering methods are better than those of the original Pauli decomposition method, indicating that our method is more sensitive to the spatial features of the target. Freeman, Yamaguchi and Cui are polarization decomposition methods based on scattering models. Yamaguchi adds a helix component on the basis of Freeman. Cui exactly accounts for every element of the observed coherency matrix compared with Freeman and Yamaguchi. According to the detection results in
Table 1, the detection effect of these three methods will increase with the increase in the fineness of the model. This means that extracting better polarimetric features as input will help increase the detection effect of our model. The detection effects of Cloude decomposition and polarimetric coherence are poor, which may be due to the insufficient power features extracted by these methods. Cloude decomposition presents power features as a single channel image SPAN, while polarimetric coherence does not contain power features.
Through the comparison of the effect of whether to use CSSL pre-training and different numbers of input samples on the test results, it can be seen from
Table 1 that after pre-training, the detection ability of the model has improved under each case of input samples, with an average improvement of 0.084 in the case of all-data, 0.096 in the case of 100-shot, 0.107 in the case of 50-shot, and 0.12 in the case of 30-shot. It shows that the smaller the number of input samples, the more obvious the improvement in the detection ability.
Figure 8 also shows the situation intuitively.
To further study the effect of the depth of ResNet as the backbone network on ship detection results, several typical ResNets are selected for ablation experiments. As shown in
Table 3, ResNet-34 was used as the feature extraction backbone and achieved the best ship detection results. With the increase in network layers, the detection effect shows a trend of improving first and then decreasing. This indicates that the network can learn features better when the number of network layers increases, but when the number of network layers is too large, the network cannot be well fitted due to a lack of training samples. Finally, we chose ResNet-18 as the backbone network. The ResNet-18 network is chosen as the feature extraction backbone because of its high training efficiency and ability to maintain good detection results.
Compared with several ship detection methods, our proposed method has improved the feature extraction ability of the network, especially under the few-shot conditions, but further work is still needed to improve the detection performance. In addition, when the number of input samples is too small, the test results will drop significantly. This shows that although pre-training can improve the detection effect on a few-shot PolSAR ship detection task, when the number of input samples is reduced to a certain threshold, the generalization ability of the model will be insufficient. Other factors, such as the number of backbone layers, the input data selection with polarimetric features, and the ship detection framework, also have a certain impact. This is the limitation of our method. The core idea of this work is to find the best combination of input data with polarimetric features and increase detection performance by optimizing the backbone network.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}