1. Introduction
Hyperspectral images (HSIs) are a type of remote sensing data that provide enriched information of the spectral characteristics of a scene. HSIs can be utilized for diverse visual tasks including object detection [
1] and classification [
2,
3,
4,
5,
6,
7,
8]. However, during the generation and transmission process, the vast amount of HSIs are often corrupted by severe noise, making denoising techniques crucial for effectively analyzing and interpreting the images. Therefore, HSI denoising is vital and has inspired extensive research.
Conventional techniques for HSI denoising, which are often called model-based methods, can be categorized into two groups: filter-based methods and low-rank-based methods. For filter-based methods, 3D model-based methods [
9,
10] first attempted to take advantage of spatial–spectial information. Then, a variety of methods that utilized penalties to exploit spatial and spectral information [
11,
12,
13,
14] were proposed. For low-rank-based methods, they have been found to be more efficient for HSI denoising, and various methods were developed based on low-rank matrix recovery [
15,
16,
17,
18,
19]. Considering HSI data as a three-order tensor, many low-rank approaches based on tensor decomposition [
20,
21,
22,
23] have achieved good effects.
Recently, deep learning has made great progress in a variety of fields. Deep-learning-based denoising methods are regarded as state-of-the-art and many network architectures were proposed for HSI denoising work [
24,
25,
26,
27,
28]. In refs. [
25,
27], convolutional-neural-network (CNN)-based architectures were suggested. Generative adversarial networks (GANs) were also examined in [
28]. These supervised deep-learning-based methods have a shortcoming that they need a large training set to obtain good effects while HSIs data are limited. To address this issue, a variety of unsupervised methods were developed [
29,
30,
31]. These methods can denoise a single observed HSI without external data.
Among these unsupervised methods, ref. [
29] uses deep image prior (DIP) [
32] for HSI inverse problems (denoising, inpainting, super-resolution). In ref. [
29], 2D convolution was extended to a 3D one, but the 3D one has a poorer performance. However, neither of them is as advanced as most state-of-the-art methods. A popular research trend is to combine DIP with other data priors. For example, reference [
30] inserts spatial–spectral total variation (SSTV) into DIP and achieves state-of-the-art results. Despite their good performance, most of the DIP-based methods assume HSIs are corrupted by Gaussian noise or Laplace noise (a.k.a., sparse noise). It is well-known that HSI noise is very complicated, including Gaussian, impulse, stripe and deadline noise. By no means can HSI noise be simply modeled by Gaussian or Laplace noise. How to design a proper noise model for real HSIs plays an important role in HSI denoising and deepens the understanding on the HSI noise pattern. Hence, there is still room to enhance the performance for DIP if it is equipped with more suitable and reasonable noise assumptions.
Our previous work [
19] has revealed that synthetic and real-world HSI noise are both heavy-tailed and asymmetric. Taking the Urban dataset as an example,
Figure 1 analyzes the statistical distribution of the real-world HSI noise. Band 87, which is degraded by deadline and horizon stripe noise, is shown in
Figure 1a. An approximately clean band is generated by averaging bands 85, 86, 87, 88 and 89, as shown in
Figure 1b. Finally, the noise of band 87 can be roughly estimated by the observation band minus the corresponding clean one, as displayed in
Figure 1c. We thereafter discuss the noise distribution.
Firstly, traditional DIP’s loss function is mean squared error (MSE, or
-norm), which hypothesizes that noise obeys a Gaussian distribution, while
Figure 1d demonstrates that the Laplace distribution better fits real-world HSI noise than the Gaussian distribution. This fact suggests that HSI noise is heavy-tailed, so mean absolute error (MAE, or
-norm) is the better choice.
Secondly, HSI noise is also asymmetric. For example, the noise frequencies are highly distinct for
and
. Neither Gaussian nor Laplace distribution can characterize this property. We propose to utilize an asymmetric Laplace (AL) distribution for modeling real-world HSI noise, and
Figure 1e illustrates that the AL distribution is more suitable to characterize the noise, which is both heavy-tailed and asymmetric.
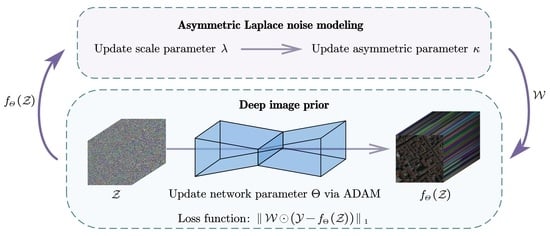
Based on the analysis above, incorporating DIP with the AL distribution assumption may enhance the denoising performance for HSI data. ThereforeInspired by this discovery, an asymmetric Laplace noise modeling deep image prior (ALDIP) method is formulated to boost performance in HSI mixed-noise removal, where the key idea is to assume that the HSI noise of each band obeys an AL distribution. Additionally, to fully utilize spatial–spectral information, we incorporate a spatial–spectral total variation (SSTV) [
33] term to preserve the spatial–spectral local smoothness. To validate ALDIP and ALDIP-SSTV’s performance, DIP2D-
(2D convolution DIP with
loss), DIP2D-
(2D convolution DIP with
loss), ALDIP, ALDIP-SSTV are applied to the real-world HSI dataset Shanghai. The result is displayed in
Figure 2.
According to
Figure 2, it is evident that ALDIP and ALDIP-SSTV preserve more details than DIP2D-
and DIP2D-
. This confirms our analysis of HSI noise and shows that modeling HSI noise as an asymmetric Laplace distribution provides superior results for HSI mixed noise removal. Furthermore, we compare ALDIP and ALDIP-SSTV with other state-of-the-art methods on two synthetic and three real-world HSI datasets. The result shows that ALDIP and ALDIP-SSTV outperform other methods. The main contributions of this paper can be formulated as follows:
We propose ALDIP for HSI mixed noise removal. More specifically, we combine a more suitable and reasonable noise model with DIP. Our model hypothesizes real-world HSI noise obeys asymmetric Laplace (AL) distribution.
ALDIP-SSTV is presented by incorporating the SSTV term to fully utilize spatial–spectral information for performance improvement.
A variety of experiments are conducted that rigorously validate the effectiveness of our methods. The result shows that our methods outperform many state-of-the-art methods.
The rest of this paper is structured as follows:
Section 2 contains a brief overview of the related work.
Section 3 introduces the methods we propose.
Section 4 introduces the experiments we conduct. Finally,
Section 5 concludes the paper.
4. Experiments
To validate the effectiveness and performance of ALDIP and ALDIP-SSTV, we conduct experiments on both synthetic and real-world HSI data. To further demonstrate the superiority of our methods, following eight state-of-the-art methods are selected for comparison:
Low-rank methods: fast hyperspectral denoising (FastHyDe) [
56], which is based on low-rank and sparse representations.
TV regularized low-rank methods: TV regularized low-rank matrix factorization (LRTV) [
39] and TV regularized low-rank tensor decomposition (LRTDTV) [
22], and three-dimensional correlated total variation regularized RPCA (CTV) [
57].
Noise modeling methods: non-i.i.d. mixture of Gaussians modeling low-rank matrix factorization (NMoG) [
50] and a bandwise-AL-noise-based matrix factorization (BALMF) [
19].
DIP-based methods: 2D convolution DIP with
loss (DIP2D-
) [
29], 2D convolution DIP with
loss (DIP2D-
) [
29] and spatial–spectral constrained unsupervised deep image prior (S2DIP) [
30].
In this paper, we use a four-layer hourglass architecture with skip connections, which is shown in
Figure 3. We use the Adam optimizer with a learning rate of 0.01 for the network in the following experiments.
4.1. Synthetic Data Experiment
Two HSI datasets are selected to conduct the simulated denoising experiment:
Indian Pines: ground truth of the scene gathered by AVIRIS sensor over the Indian Pines test site in north-western Indiana with pixels and 224 bands.
Pavia Centre: a cropped HSI with 200 × 200 pixels and 80 bands acquired by the ROSIS sensor during a flight campaign over Pavia, northern Italy.
To simulate real-world HSI noise, we firstly set up eight different noise cases that synthesize various types of noise ranging from simple to complex. Furthermore, four more cases are set up to simulate the scenario where the signal is more severely corrupted by mixed noise. On the basis of case 8, these four cases simulate more severe mixture noise either by adding more severe noise (case 9, case 10) or by having more bands corrupted (case 11, case 12).
Table 1 shows the details of the synthetic noise setting. Cases 3 to 12 are more consistent with real-world HSI noise.
For fair comparison, the hyper-parameters for all methods are fine-tuned to achieve their best performance and metrics for evaluation include: PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity), SAM (Spectral Angle Mapper) and ERGAS (Erreur Relative Global Adimensionnelle de Synthèse).
Table 2 and
Table 3 present the evaluation results for the twelve cases on the Indian Pines and Pavia Centre datasets. We will analyze the experiment results to gain a deeper understanding of the performance of our model.
Firstly, we will compare our methods with non-DIP-based methods. Although our methods are not specifically designed for Gaussian noise, ALDIP and ALDIP-SSTV perform well in case 1 and case 2, and even outperform other methods in some metrics. It should be attributed to DIP and SSTV terms. However, the effect of AL noise modeling is not obvious in these cases. As we further add various types of noise and increase the intensities, the superior performance of our methods becomes more apparent. In cases 3 to 12, our methods rank first or second in most metrics. In some cases of the Pavia Centre dataset (case 3, 5, 7, 8), NMoG takes the first place on the PSNR metric, but the structural and spectral similarity is not as good as our methods.
Secondly, we compare our methods with other DIP-based methods. In case 1 and case 2, DIP2D-
performs well. However, in other cases, it performs much worse than other DIP-based methods. Therefore, the assumption of Gaussian distribution performs poorly for mixed HSI noise. S2DIP has the best performance in case 1 and case 2. In other cases, our methods outperform S2DIP. Next, we focus on the comparison between DIP2D-
and ALDIP. When updating the parameters of the network, DIP2D-
uses
as the loss function while ALDIP uses
. ALDIP multiplies an additional
, which guides the network to learn the skewness of noise. To assess the effect of this operation, we further show the difference between the above two methods in the metrics.
Table 4 shows the improvement of AL noise modeling, where positive numbers represent positive effects and negative numbers represent negative effects.
According to
Table 4, we find that AL noise modeling can always achieve good improvements on the Indian Pines dataset. However, on the Pavia Centre dataset, AL modeling leads to a decrease in PSNR and ERGAS, but an improvement in SSIM and SAM in cases 1–5. For other cases with more intensive noise, the effect of AL modeling becomes more and more obvious. In other words, the more complex the noise, the more asymmetric it becomes.
Figure 4 and
Figure 5 display the denoising result on Indian Pines and Pavia Centre.
Figure 4a and
Figure 5a show the noisy HSI, which is seriously degraded by the mixture of Gaussian noise, impulse noise, deadlines and stripes. Some local areas are amplified to display detailed information. It is shown that DIP-based methods outperform other methods. For DIP-based methods, our methods retain some important details.
Pixel (67,7) on the Indian Pines dataset for case 9 is chosen to visualize the spectral curves in
Figure 6. For the Indian Pines dataset, DIP2D-
, S2DIP, ALDIP and ALDIP-SSTV’s spectral curves almost perfectly fit the curves of the ground truth. However, a local area of curves is zoomed in to show that ALDIP and ALDIP-SSTV preserve details that other methods fail to.
Pixel (52,59) on the Pavia Centre dataset for case 12 is also selected. In
Figure 7, it is clear that ALDIP and ALDIP-SSTV finely recover the truth spectrum. Therefore, our proposed ALDIP and ALDIP-SSTV are able to achieve a restoration closest to the truth.
4.2. Real Data Experiments
Three real-world HSI datasets are used to conduct the real data experiments to validate the effectiveness of our methods. They are:
Shanghai: captured by the GaoFen-5 satellite with 300 × 300 pixels and 155 bands.
Terrain: captured by Hyperspectral Digital Imagery Collection Experiment with 500 × 307 pixels and 210 bands.
Urban: captured by Hyperspectral Digital Imagery Collection Experiment with 307 × 307 pixels and 210 bands.
In the real data experiment, the early stopping trick is applied to all DIP-based methods by manually monitoring to preventing overfitting.
Figure 8 shows that on the Shanghai dataset, FastHyDe, LRTDTV, NMoG and DIP-based methods successfully remove the stripes. Taking a closer observation at these denoising results, FastHyDe, LRTDTV, DIP2D-
and DIP2D-
lose some details in the zoomed local area. Moreover, ALDIP and ALDIP-SSTV preserve more details than DIP2D-
and DIP2D-
, which demonstrates that ALDIP and ALDIP-SSTV obtain a superiority on HSI mixed noise removal.
The denoising result of the Terrain dataset is shown in
Figure 9. Apparently, all non-DIP-based methods cannot completely remove stripes. Among the DIP-based methods, the results of ALDIP and ALDIP-SSTV are less blurring and preserve more details. On the Urban dataset, the effectiveness of our methods is more significant. As shown in
Figure 10, non-DIP-based methods have poor performance. It can be seen visually that ALDIP and ALDIP-SSTV outperform all other methods.
4.3. Sensitivity Analysis
At the first glance, ALDIP needs to initialize parameters
and
. Let us revisit Equation (
22), and it is shown that only
should be initialized, because updating
depends on
rather than the previous
. In practice, we do not know whether the noise is negative skew, positive skew or symmetric. An intuitive strategy is to initialize
, which corresponds to the symmetric case.
As stated before, the loss function of ALDIP can actually be deemed as the weighted
norm, where the weight is determined by
and
. DIP2D-
is hence employed as the baseline.
Figure 11 exhibits the PSNR curve versus a different initial value of
. It is revealed that the PSNR of ALDIP fluctuates within a very small interval and is always higher than that of the baseline. A conclusion is thus drawn that ALDIP is not sensitive to the initial value of
.
Furthermore, as shown in
Figure 12, it is found that ALDIP can always reach the optimal PSNR value with fewer iterations than DIP2D-
, no matter how
is initialized. This indicates that DIP guided by AL noise modeling has a faster learning process.
DIP-based methods require early stopping to avoid the inherited overfitting issue. Therefore, the number of steps is a critical hyperparameter that affects the performance of our methods.
Figure 13 visualized how the number of steps impacts the performance of our methods. As shown in
Figure 13, the PSNR values on both the Indian Pines and Pavia Centre datasets approach their respective peaks at around 800 iterations when the image suffers from i.i.d. Gaussian noise (case 1). There is a similar conclusion for non-i.i.d. Gaussian noise (case 2). For the mixed noise, cases 5, 8 and 10 are selected to be displayed. At about 1500 iterations, ALDIP reaches a high PSNR value on both datasets. Thus, we set the number of steps to 800 for Gaussian noise cases and 1500 for the mixed noise cases.
4.4. Execution Time
Table 5 presents the execution time and corresponding PSNR of DIP-based methods when achieving their optimal PSNR. It is shown that although DIP2D-
has the shortest execution time, its performance is far inferior to other methods. Among DIP2D-
, S2DIP and ALDIP, ALDIP exhibits the shortest execution time and the best performance. Although we need to update the parameters of AL at each iteration, it is not a time-consuming process. Even with the additional time required for updating the parameters of AL, ALDIP still exhibits a shorter execution time due to improvements in learning speed. Under the guidance of AL noise modeling, DIP is accelerated significantly. However, incorporated with the SSTV term, ALDIP-SSTV has the longest execution time. This is because the backpropagation process of the SSTV term is time-consuming.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}