
Multi-Scale and Context-Aware Framework for Flood Segmentation in Post-Disaster High Resolution Aerial Images



Abstract
1. Introduction
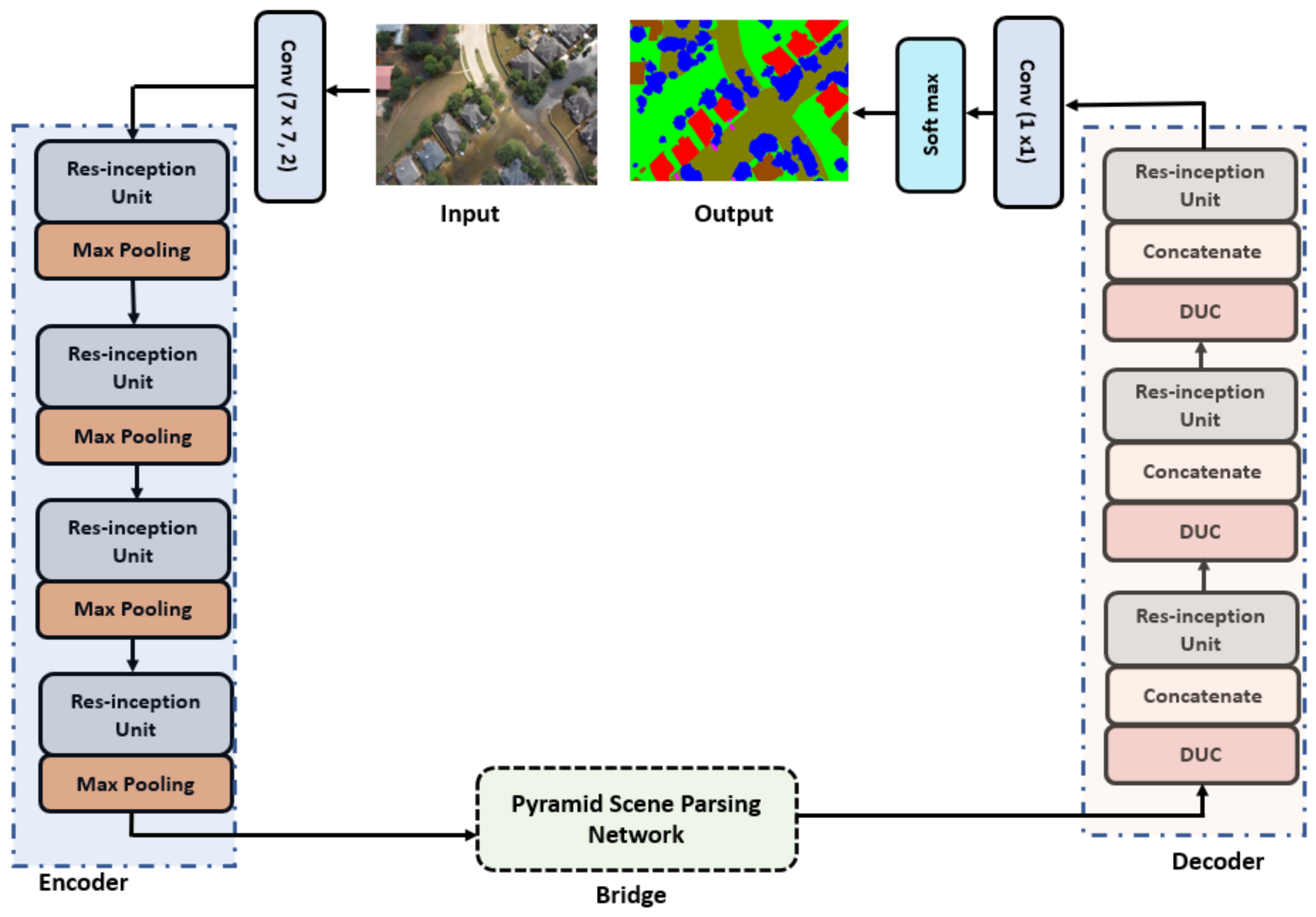
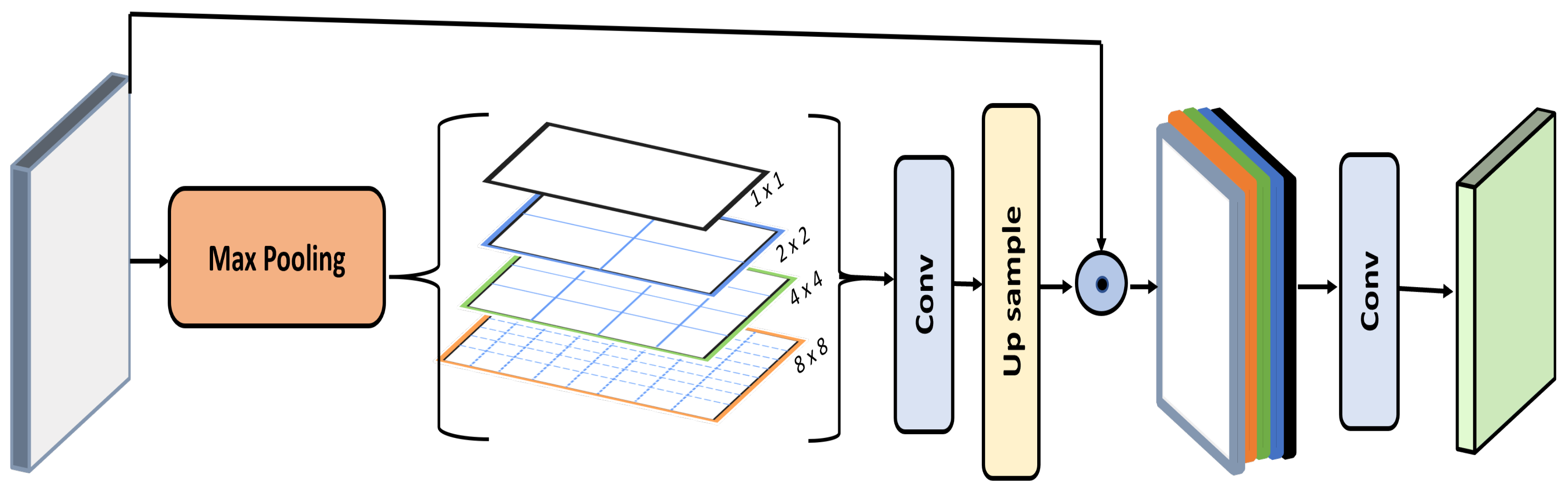
- For flood segmentation in satellite images, it is crucial to extract multi-scale features. For this purpose, the proposed framework introduces Res-inception units that extract multi-scale features from multiple layers of the network.
- The framework integrates a pyramid scene parsing network as bridge between the encoder and decoder modules to capture global contextual information.
- The effectiveness of proposed framework is gauged on the challenging publicly available FloodNet dataset. From quantitative and qualitative comparisons, it is demonstrated that the framework achieves the best performance and is better than the other reference methods.
2. Related Work
2.1. Handcrafted Feature-Based Models
2.2. Deep Learning Models
3. Methodology
4. Experiment Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Memon, A.A.; Muhammad, S.; Rahman, S.; Haq, M. Flood monitoring and damage assessment using water indices: A case study of Pakistan flood-2012. Egypt. J. Remote Sens. Space Sci. 2015, 18, 99–106. [Google Scholar] [CrossRef]
- Schumann, G.J.; Brakenridge, G.R.; Kettner, A.J.; Kashif, R.; Niebuhr, E. Assisting flood disaster response with earth observation data and products: A critical assessment. Remote Sens. 2018, 10, 1230. [Google Scholar] [CrossRef]
- Abid, S.K.; Sulaiman, N.; Chan, S.W.; Nazir, U.; Abid, M.; Han, H.; Ariza-Montes, A.; Vega-Muñoz, A. Toward an integrated disaster management approach: How artificial intelligence can boost disaster management. Sustainability 2021, 13, 12560. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Lal, S.; Nalini, J.; Reddy, C.S.; Dell’Acqua, F. DIResUNet: Architecture for multiclass semantic segmentation of high resolution remote sensing imagery data. Appl. Intell. 2022, 52, 15462–15482. [Google Scholar]
- Rahnemoonfar, M.; Chowdhury, T.; Sarkar, A.; Varshney, D.; Yari, M.; Murphy, R.R. Floodnet: A high resolution aerial imagery dataset for post flood scene understanding. IEEE Access 2021, 9, 89644–89654. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Jégou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The one hundred layers tiramisu: Fully convolutional densenets for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 11–19. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Li, M.; Staunton, R.C. Optimum Gabor filter design and local binary patterns for texture segmentation. Pattern Recognit. Lett. 2008, 29, 664–672. [Google Scholar] [CrossRef]
- Suresh, A.; Shunmuganathan, K. Image texture classification using gray level co-occurrence matrix based statistical features. Eur. J. Sci. Res. 2012, 75, 591–597. [Google Scholar]
- Shotton, J.; Johnson, M.; Cipolla, R. Semantic texton forests for image categorization and segmentation. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, Alaska, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Sturgess, P.; Alahari, K.; Ladicky, L.; Torr, P.H. Combining appearance and structure from motion features for road scene understanding. In Proceedings of the BMVC-British Machine Vision Conference, BMVA, London, UK, 7–10 September 2009. [Google Scholar]
- Zhang, C.; Wang, L.; Yang, R. Semantic segmentation of urban scenes using dense depth maps. In Proceedings of the European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2011; Springer: Berlin/Heidelberg, Germany, 2010; pp. 708–721. [Google Scholar]
- Ghiasi, M.; Amirfattahi, R. Fast semantic segmentation of aerial images based on color and texture. In Proceedings of the 2013 8th Iranian Conference on Machine Vision and Image Processing (MVIP), Zanjan, Iran, 10–12 September 2013; pp. 324–327. [Google Scholar]
- Wang, X.Y.; Wang, T.; Bu, J. Color image segmentation using pixel wise support vector machine classification. Pattern Recognit. 2011, 44, 777–787. [Google Scholar] [CrossRef]
- Wang, A.; Wang, S.; Lucieer, A. Segmentation of multispectral high-resolution satellite imagery based on integrated feature distributions. Int. J. Remote Sens. 2010, 31, 1471–1483. [Google Scholar] [CrossRef]
- Barbieri, A.L.; De Arruda, G.; Rodrigues, F.A.; Bruno, O.M.; da Fontoura Costa, L. An entropy-based approach to automatic image segmentation of satellite images. Phys. A Stat. Mech. Its Appl. 2011, 390, 512–518. [Google Scholar] [CrossRef]
- Awad, M.; Chehdi, K.; Nasri, A. Multicomponent image segmentation using a genetic algorithm and artificial neural network. IEEE Geosci. Remote Sens. Lett. 2007, 4, 571–575. [Google Scholar] [CrossRef]
- Volpi, M.; Ferrari, V. Semantic segmentation of urban scenes by learning local class interactions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Banerjee, B.; Varma, S.; Buddhiraju, K.M. Satellite image segmentation: A novel adaptive mean-shift clustering based approach. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 4319–4322. [Google Scholar]
- Volpi, M.; Ferrari, V. Structured prediction for urban scene semantic segmentation with geographic context. In Proceedings of the 2015 Joint Urban Remote Sensing Event (JURSE), Lausanne, Switzerland, 30 March–1 April 2015; pp. 1–4. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ren, Y.; Yu, Y.; Guan, H. DA-CapsUNet: A dual-attention capsule U-Net for road extraction from remote sensing imagery. Remote Sens. 2020, 12, 2866. [Google Scholar] [CrossRef]
- Khan, S.D.; Alarabi, L.; Basalamah, S. DSMSA-Net: Deep Spatial and Multi-scale Attention Network for Road Extraction in High Spatial Resolution Satellite Images. Arab. J. Sci. Eng. 2023, 48, 1907–1920. [Google Scholar] [CrossRef]
- Wulamu, A.; Shi, Z.; Zhang, D.; He, Z. Multiscale road extraction in remote sensing images. Comput. Intell. Neurosci. 2019, 2019, 2373798. [Google Scholar] [CrossRef]
- Lian, R.; Huang, L. DeepWindow: Sliding window based on deep learning for road extraction from remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1905–1916. [Google Scholar] [CrossRef]
- Xu, Y.; Xie, Z.; Feng, Y.; Chen, Z. Road extraction from high-resolution remote sensing imagery using deep learning. Remote Sens. 2018, 10, 1461. [Google Scholar] [CrossRef]
- Li, P.; He, X.; Qiao, M.; Cheng, X.; Li, Z.; Luo, H.; Song, D.; Li, D.; Hu, S.; Li, R.; et al. Robust deep neural networks for road extraction from remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6182–6197. [Google Scholar] [CrossRef]
- Chen, Z.; Deng, L.; Luo, Y.; Li, D.; Junior, J.M.; Gonçalves, W.N.; Nurunnabi, A.A.M.; Li, J.; Wang, C.; Li, D. Road extraction in remote sensing data: A survey. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102833. [Google Scholar] [CrossRef]
- Hu, Q.; Zhen, L.; Mao, Y.; Zhou, X.; Zhou, G. Automated building extraction using satellite remote sensing imagery. Autom. Constr. 2021, 123, 103509. [Google Scholar] [CrossRef]
- Rudner, T.G.; Rußwurm, M.; Fil, J.; Pelich, R.; Bischke, B.; Kopačková, V.; Biliński, P. Multi3Net: Segmenting flooded buildings via fusion of multiresolution, multisensor, and multitemporal satellite imagery. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 702–709. [Google Scholar]
- Li, S.; Tang, H.; Huang, X.; Mao, T.; Niu, X. Automated detection of buildings from heterogeneous VHR satellite images for rapid response to natural disasters. Remote Sens. 2017, 9, 1177. [Google Scholar] [CrossRef]
- Wu, S.S.; Qiu, X.; Wang, L. Population estimation methods in GIS and remote sensing: A review. GISci. Remote Sens. 2005, 42, 80–96. [Google Scholar] [CrossRef]
- Na, Y.; Kim, J.H.; Lee, K.; Park, J.; Hwang, J.Y.; Choi, J.P. Domain adaptive transfer attack-based segmentation networks for building extraction from aerial images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5171–5182. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, J.; Fan, Y.; Gao, H.; Shao, Y. An efficient building extraction method from high spatial resolution remote sensing images based on improved mask R-CNN. Sensors 2020, 20, 1465. [Google Scholar] [CrossRef]
- Liu, H.; Luo, J.; Huang, B.; Hu, X.; Sun, Y.; Yang, Y.; Xu, N.; Zhou, N. DE-Net: Deep encoding network for building extraction from high-resolution remote sensing imagery. Remote Sens. 2019, 11, 2380. [Google Scholar] [CrossRef]
- Zhang, Z.; Guo, W.; Li, M.; Yu, W. GIS-supervised building extraction with label noise-adaptive fully convolutional neural network. IEEE Geosci. Remote Sens. Lett. 2020, 17, 2135–2139. [Google Scholar] [CrossRef]
- Protopapadakis, E.; Doulamis, A.; Doulamis, N.; Maltezos, E. Stacked autoencoders driven by semi-supervised learning for building extraction from near infrared remote sensing imagery. Remote Sens. 2021, 13, 371. [Google Scholar] [CrossRef]
- Bi, Q.; Qin, K.; Zhang, H.; Zhang, Y.; Li, Z.; Xu, K. A multi-scale filtering building index for building extraction in very high-resolution satellite imagery. Remote Sens. 2019, 11, 482. [Google Scholar] [CrossRef]
- Li, K.; Hu, X.; Jiang, H.; Shu, Z.; Zhang, M. Attention-guided multi-scale segmentation neural network for interactive extraction of region objects from high-resolution satellite imagery. Remote Sens. 2020, 12, 789. [Google Scholar] [CrossRef]
- Ma, J.; Wu, L.; Tang, X.; Liu, F.; Zhang, X.; Jiao, L. Building extraction of aerial images by a global and multi-scale encoder-decoder network. Remote Sens. 2020, 12, 2350. [Google Scholar] [CrossRef]
- Stow, D.A.; Hope, A.; McGuire, D.; Verbyla, D.; Gamon, J.; Huemmrich, F.; Houston, S.; Racine, C.; Sturm, M.; Tape, K.; et al. Remote sensing of vegetation and land-cover change in Arctic Tundra Ecosystems. Remote Sens. Environ. 2004, 89, 281–308. [Google Scholar] [CrossRef]
- Anand, T.; Sinha, S.; Mandal, M.; Chamola, V.; Yu, F.R. AgriSegNet: Deep aerial semantic segmentation framework for IoT-assisted precision agriculture. IEEE Sens. J. 2021, 21, 17581–17590. [Google Scholar] [CrossRef]
- Perumal, B.; Kalaiyarasi, M.; Deny, J.; Muneeswaran, V. Forestry land cover segmentation of SAR image using unsupervised ILKFCM. Mater. Today Proc. 2021. [Google Scholar] [CrossRef]
- Bengana, N.; Heikkilä, J. Improving land cover segmentation across satellites using domain adaptation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 1399–1410. [Google Scholar] [CrossRef]
- Khan, S.D.; Alarabi, L.; Basalamah, S. Deep Hybrid Network for Land Cover Semantic Segmentation in High-Spatial Resolution Satellite Images. Information 2021, 12, 230. [Google Scholar] [CrossRef]
- Atik, S.O.; Ipbuker, C. Integrating convolutional neural network and multiresolution segmentation for land cover and land use mapping using satellite imagery. Appl. Sci. 2021, 11, 5551. [Google Scholar] [CrossRef]
- Sravya, N.; Lal, S.; Nalini, J.; Reddy, C.S.; Dell’Acqua, F. DPPNet: An Efficient and Robust Deep Learning Network for Land Cover Segmentation From High-Resolution Satellite Images. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 7, 128–139. [Google Scholar]
- Rehman, M.F.U.; Aftab, I.; Sultani, W.; Ali, M. Mapping Temporary Slums From Satellite Imagery Using a Semi-Supervised Approach. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Xu, L.; Ming, D.; Zhou, W.; Bao, H.; Chen, Y.; Ling, X. Farmland extraction from high spatial resolution remote sensing images based on stratified scale pre-estimation. Remote Sens. 2019, 11, 108. [Google Scholar] [CrossRef]
- Gao, X.; Liu, L.; Gong, H. MMUU-Net: A Robust and Effective Network for Farmland Segmentation of Satellite Imagery. J. Phys. Conf. Ser. 2020, 1651, 012189. [Google Scholar] [CrossRef]
- Zhuang, L.; Zhang, Z.; Wang, L. The automatic segmentation of residential solar panels based on satellite images: A cross learning driven U-Net method. Appl. Soft Comput. 2020, 92, 106283. [Google Scholar] [CrossRef]
- Li, P.; Zhang, H.; Guo, Z.; Lyu, S.; Chen, J.; Li, W.; Song, X.; Shibasaki, R.; Yan, J. Understanding rooftop PV panel semantic segmentation of satellite and aerial images for better using machine learning. Adv. Appl. Energy 2021, 4, 100057. [Google Scholar] [CrossRef]
- Wurm, M.; Stark, T.; Zhu, X.X.; Weigand, M.; Taubenböck, H. Semantic segmentation of slums in satellite images using transfer learning on fully convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2019, 150, 59–69. [Google Scholar] [CrossRef]
- Li, R.; Liu, W.; Yang, L.; Sun, S.; Hu, W.; Zhang, F.; Li, W. DeepUNet: A deep fully convolutional network for pixel-level sea-land segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3954–3962. [Google Scholar] [CrossRef]
- Yue, K.; Yang, L.; Li, R.; Hu, W.; Zhang, F.; Li, W. TreeUNet: Adaptive tree convolutional neural networks for subdecimeter aerial image segmentation. ISPRS J. Photogramm. Remote Sens. 2019, 156, 1–13. [Google Scholar] [CrossRef]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef]
- Luo, H.; Chen, C.; Fang, L.; Zhu, X.; Lu, L. High-resolution aerial images semantic segmentation using deep fully convolutional network with channel attention mechanism. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3492–3507. [Google Scholar] [CrossRef]
- Niu, R.; Sun, X.; Tian, Y.; Diao, W.; Chen, K.; Fu, K. Hybrid multiple attention network for semantic segmentation in aerial images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5603018. [Google Scholar] [CrossRef]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Mehta, S.; Rastegari, M.; Caspi, A.; Shapiro, L.; Hajishirzi, H. Espnet: Efficient spatial pyramid of dilated convolutions for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 552–568. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Instances | Class |
|---|---|
| 3248 | Building—flooded |
| 3427 | Building—non-flooded |
| 495 | Road—flooded |
| 2155 | Road—non-flooded |
| 4535 | Vehicle |
| 1141 | Pool |
| 19,682 | Tree |
| 1374 | Water |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| Building—flooded | 0.75 | 0.71 | 0.73 |
| Building—non-flooded | 0.90 | 0.94 | 0.92 |
| Road—flooded | 0.82 | 0.84 | 0.83 |
| Road—non-flooded | 0.92 | 0.93 | 0.92 |
| Water | 0.94 | 0.93 | 0.94 |
| Tree | 0.92 | 0.94 | 0.93 |
| Vehicle | 0.67 | 0.70 | 0.69 |
| Pool | 0.76 | 0.69 | 0.72 |
| Grass | 0.94 | 0.95 | 0.95 |
| Method | BF | BnF | RF | RnF | W | T | V | P | G | mIoU |
|---|---|---|---|---|---|---|---|---|---|---|
| U-Net | 21.83 | 69.49 | 23.84 | 72.45 | 63.62 | 70.19 | 21.48 | 37.52 | 77.16 | 50.84 |
| DeepLabv3+ | 28.1 | 78.1 | 32 | 81.1 | 73 | 74.5 | 33.6 | 40 | 87.1 | 58.61 |
| FCN | 18.75 | 28.42 | 20.64 | 37.84 | 42.01 | 40.95 | 19.24 | 22.94 | 52.49 | 31.48 |
| U-Net++ | 24.34 | 71.46 | 27.61 | 74.96 | 69.78 | 72.6 | 25.16 | 38.64 | 80.75 | 53.92 |
| ENet | 21.82 | 41.41 | 14.76 | 52.53 | 47.14 | 62.56 | 26.21 | 16.57 | 75.57 | 39.84 |
| SegNet | 17.82 | 38.54 | 10.81 | 48.76 | 34.97 | 55.23 | 19.32 | 21.53 | 68.74 | 35.08 |
| PSPNet | 65.61 | 90.92 | 78.69 | 90.9 | 91.25 | 89.17 | 54.83 | 66.37 | 95.45 | 80.35 |
| Tiramisu | 31.53 | 75.68 | 24.72 | 78.61 | 72.85 | 74.97 | 23.74 | 40.18 | 84.62 | 56.32 |
| Proposed | 72.71 | 91.27 | 84.62 | 92.34 | 93.64 | 93.72 | 67.82 | 71.49 | 94.86 | 84.72 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, S.D.; Basalamah, S. Multi-Scale and Context-Aware Framework for Flood Segmentation in Post-Disaster High Resolution Aerial Images. Remote Sens. 2023, 15, 2208. https://doi.org/10.3390/rs15082208
Khan SD, Basalamah S. Multi-Scale and Context-Aware Framework for Flood Segmentation in Post-Disaster High Resolution Aerial Images. Remote Sensing. 2023; 15(8):2208. https://doi.org/10.3390/rs15082208
Chicago/Turabian StyleKhan, Sultan Daud, and Saleh Basalamah. 2023. "Multi-Scale and Context-Aware Framework for Flood Segmentation in Post-Disaster High Resolution Aerial Images" Remote Sensing 15, no. 8: 2208. https://doi.org/10.3390/rs15082208
APA StyleKhan, S. D., & Basalamah, S. (2023). Multi-Scale and Context-Aware Framework for Flood Segmentation in Post-Disaster High Resolution Aerial Images. Remote Sensing, 15(8), 2208. https://doi.org/10.3390/rs15082208