
TPENAS: A Two-Phase Evolutionary Neural Architecture Search for Remote Sensing Image Classification


Abstract
1. Introduction
- (1)
- We propose a two-phase evolutionary multi-objective neural architecture search (TPENAS) framework for remote sensing image classification. The first search phase explores the optimal the depth of the model, and the second search phase finds the most suitable structure for the model. Our algorithm can automatically design a CNN model suitable for remote sensing image classification, which eases the heavy burden posed by manually designing a CNN model.
- (2)
- We propose the first search phase that determines the depth of the CNN model. A multi-objective optimization problem is established with the depth and classification accuracy of the model as optimization goals. This problem is solved by a heuristic multi-objective optimization algorithm to find the optimal the depth of model.
- (3)
- We propose the second search phase that globally searches the structure of the CNN model. We encode the entire CNN model as a binary string, allowing population evolution to optimize the CNN structure globally. Furthermore, we simultaneously optimize the classification error and complexity of the model so that the final result can provide a set of Pareto solutions, giving users more options in practical applications.
- (4)
- The effectiveness of the proposed TPENAS is verified on three public benchmark datasets. Extensive experiments show that the model searched by the TPENAS outperforms the classic classification CNN model. Compared with other NAS methods, TPENAS not only has higher classification accuracy but also has advantages in the GFLOPs and parameters of the model.
2. Materials and Methods
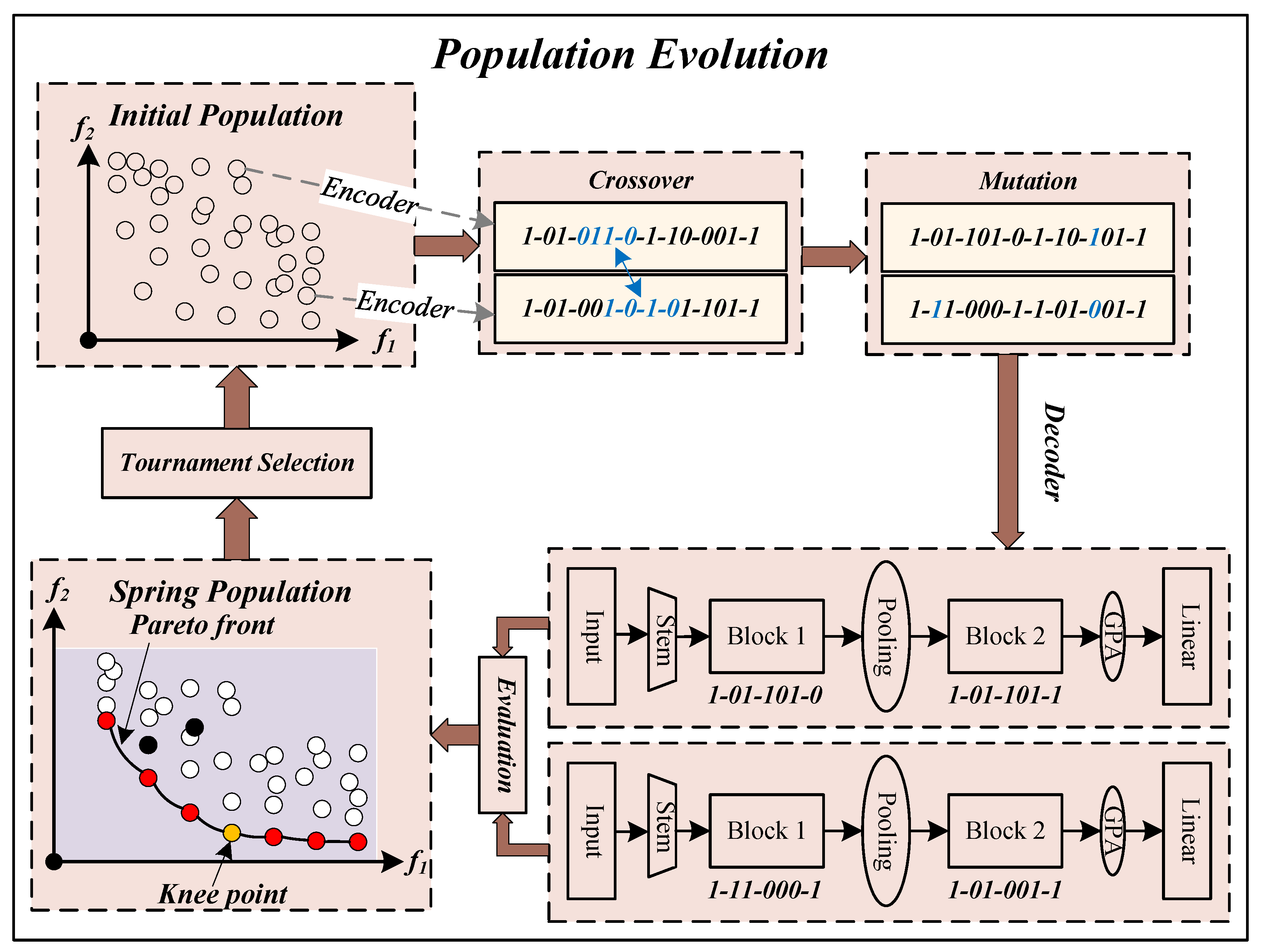
2.1. The Overall Framework
| Algorithm 1 The Pseudocode of TPENAS |
Input: T1: the maximum population iterations during the first search phase; T2: the maximum population iterations during the second search phase; : the population size in the first search phase. : the population size in the second search phase. : remote sensing image classification problem. Output: The best model.
|
2.2. The First Search Phase
2.2.1. Encoding Schedule
- (1)
- A block with n nodes is represented by n groups of binary strings.
- (2)
- The i-th group of codes is represented by i + 1 bit binary. The j-th bit of the i-th group indicates whether the (i+ 1)-th node is connected to the j-th node (i > j and i = n − 1), 1 means connection, 0 means disconnection.
- (3)
- The last group has only one bit, which indicates whether there is a direct connection from the input to the output.
2.2.2. Initialization
2.2.3. Population Evolution
- (1)
- Crossover and MutationCrossover and mutation operations are used to generate better-quality individuals, which are common operations in genetic algorithms. We randomly pick two individuals from the population and perform a crossover on them with probability . The crossover operation involves selecting a continuous binary string of the same length from two individuals and generating two new individuals by exchanging the binary string segments. The two new individuals perform mutation operations respectively to generate new individuals. The mutation operation is practiced by inverting each binary bit with probability in turn. In the experiment, the crossover probability and mutation probability are set to pc and pm , respectively, where l represents the code length of the individual.
- (2)
- EvaluationIn the first search phase, we need to evaluate the overall classification accuracy and the length of the individual. To meet the minimum optimization problem, we use the overall classification error rate of the model on the testing dataset to evaluate the individual’s overall classification accuracy. We use the number of blocks to evaluate an individual’s length. Before evaluating an individual, we need to decode the binary string representing the individual into the corresponding CNN model. The model is trained on the training dataset and then tested on the testing dataset to obtain the overall classification error rate of the model. It is worth noting that in the whole optimization process, we save the binary code of the individual, the overall classification error rate, and the number of blocks of the model into the external population E, and, before evaluating each individual, we first query the individual in the set E. If it exists, the overall classification error rate of the individual and the number of blocks of the model are directly copied without retraining the model, which saves time in the first search phase.
- (3)
- Environmental SelectionWe select the offspring population by binary tournament selection. Specifically, two individuals are selected firstly from the parent population, and then the most suitable one from the two individuals is chosen and added to the offspring population. Repeat N times to select N individuals as the offspring population.
2.2.4. Solution Selection
2.3. The Second Search Phase
- (1)
- In the first search phase, we determine the optimal number of blocks of individuals. In the second search phase, we optimize the classification error rate and GFLOPs of the model and no longer optimize the block number of the model. Therefore, when initializing the population as in Section 2.2.2, M individuals with the same number of blocks are randomly initialized.
- (2)
- In the second search phase, the two optimization objectives are the classification error rate and GFLOPs of the model. Therefore, when evaluating individuals as in Section 2.2.3, we evaluate the individual’s classification error rate and calculate the individual’s GFLOPs.
- (3)
- We do not select the optimal individual from the final population as in Section 2.2.4. This is because we use the binary tournament selection method when choosing the offspring population, which may overlook some Pareto solutions. As a result, we aggregate all of the individuals from each generation into an external population and then select the Pareto front from .
3. Results
3.1. Datasets
3.2. Experimental Settings
3.2.1. Parameter Setting
3.2.2. Evaluation Metrics
3.3. Comparison of the Proposed TPENAS with Other Methods
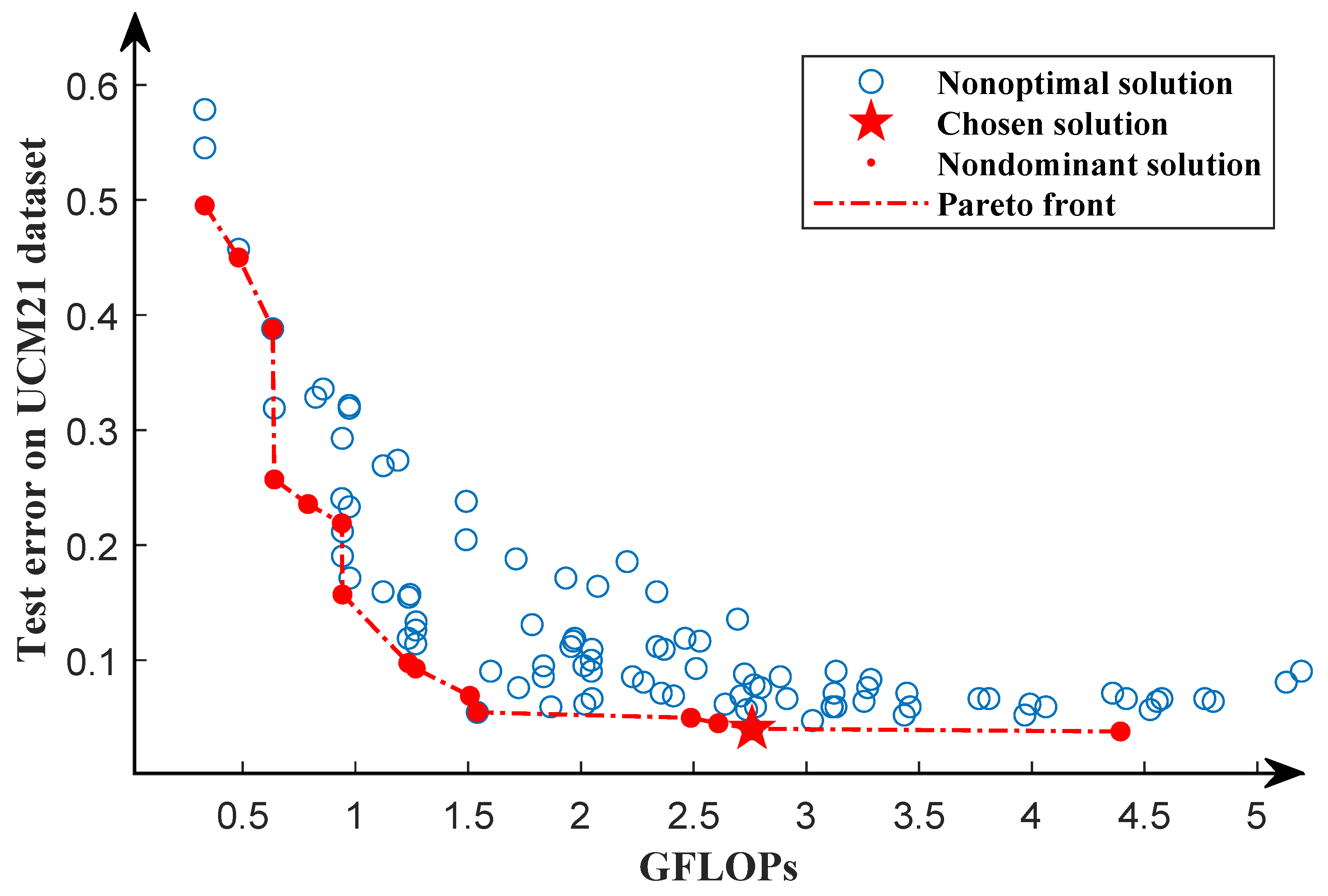
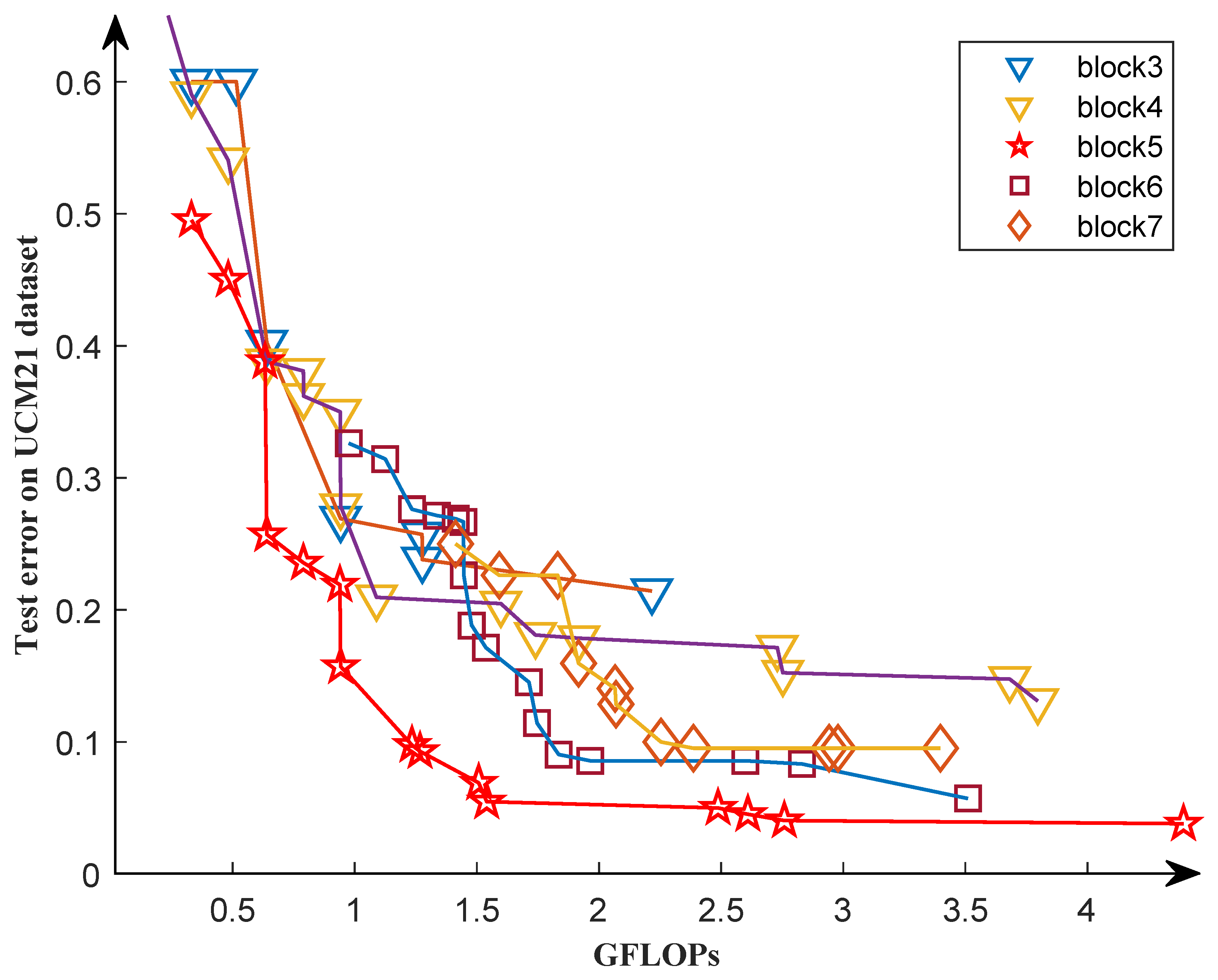
3.3.1. Results on UCM21 Dataset
3.3.2. Result on PatternNet Dataset
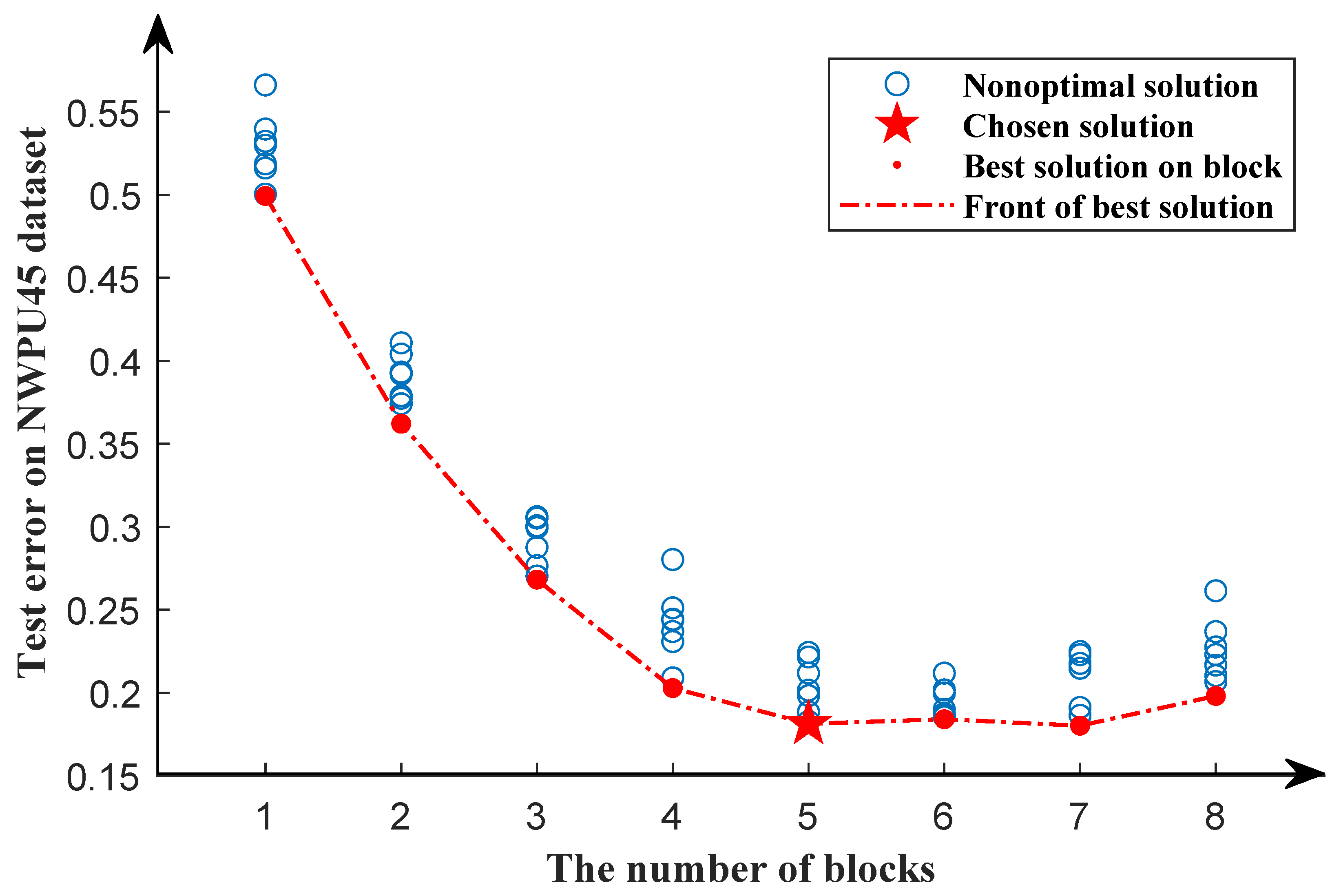
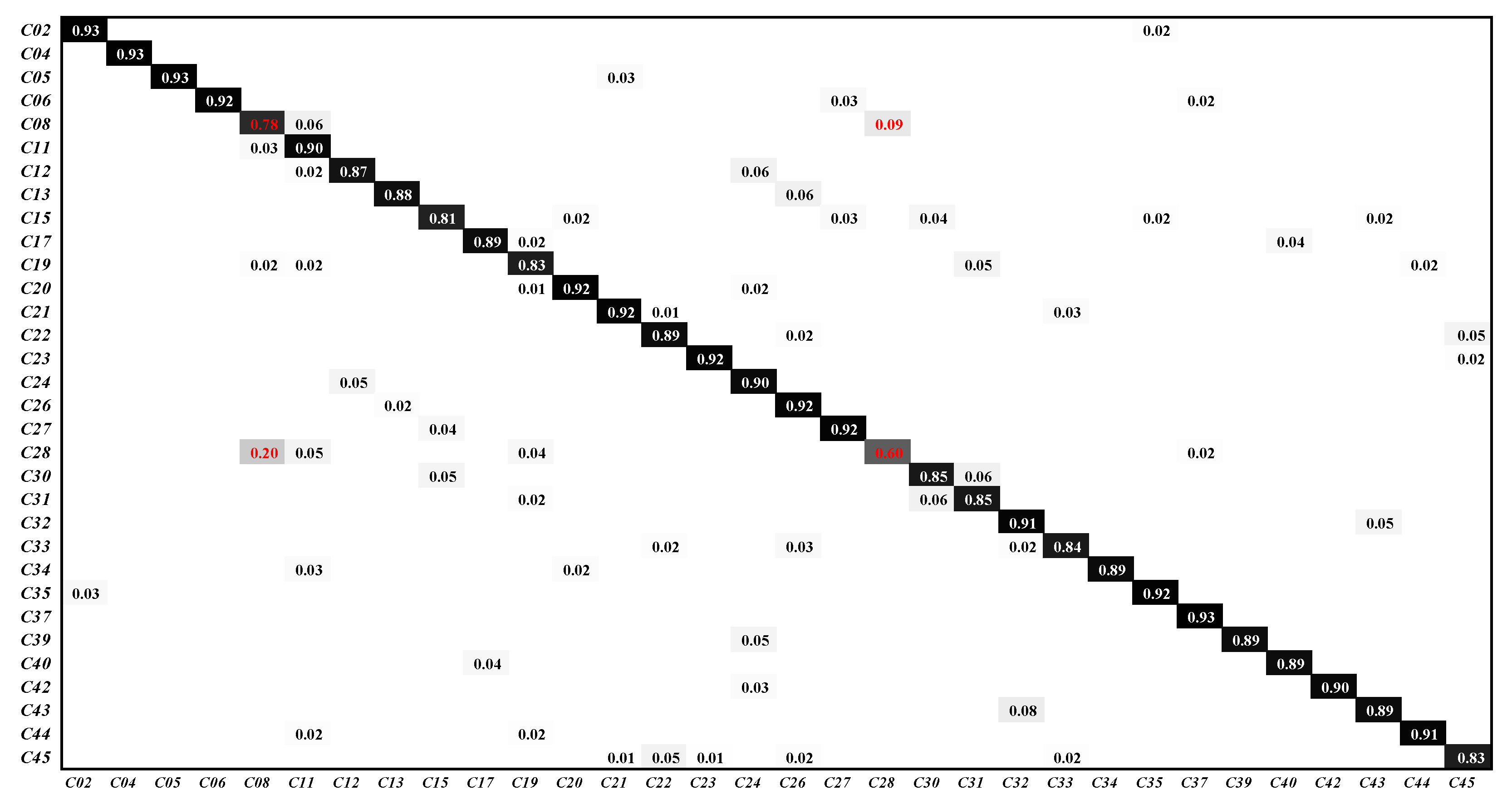
3.3.3. Result on NWPU45 Dataset
3.3.4. Compared to Other CNN-Based Methods
3.3.5. Compared to Other ENAS Methods
4. Discussion
4.1. Analysis of the Number of Evaluated Models
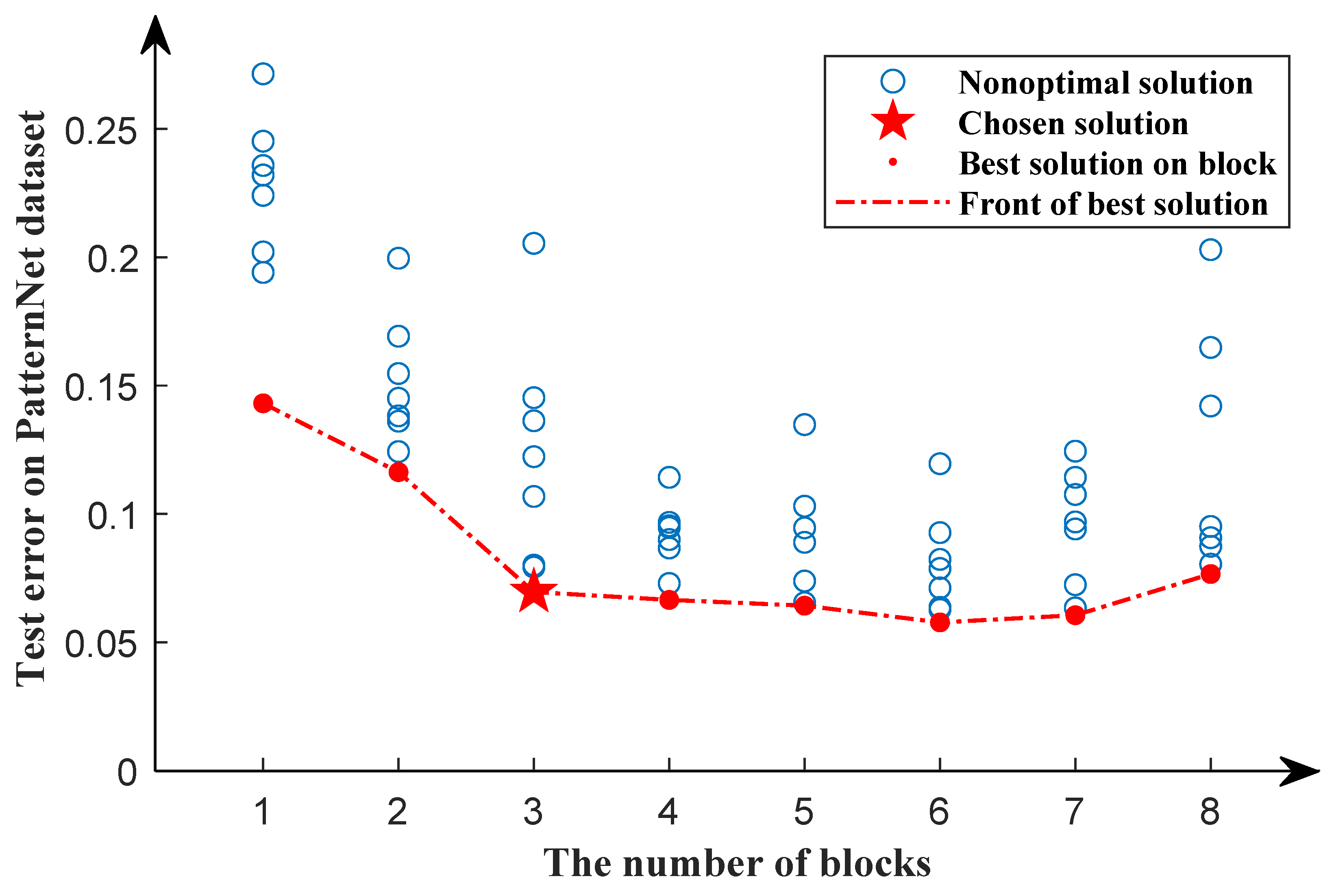
4.2. Analysis of the Depth of the Model in the Second Search Phase
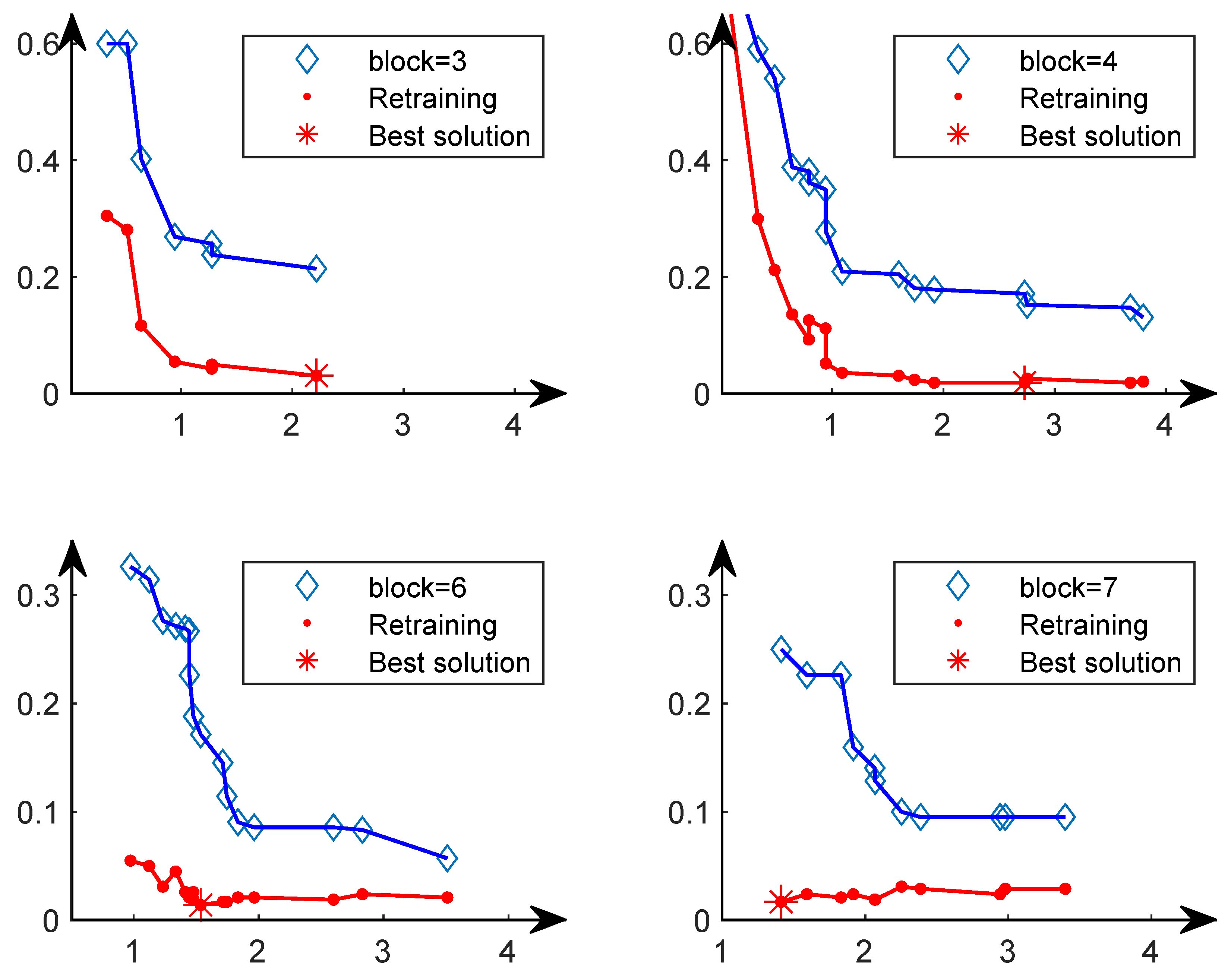
4.3. Analysis of Fully Trained Models and Non-Fully Trained Models
4.4. Analysis of TPENAS Algorithm with Fewer Training Samples
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gong, M.; Jiang, F.; Qin, A.K.; Liu, T.; Zhan, T.; Lu, D.; Zheng, H.; Zhang, M. A spectral and spatial attention network for change detection in hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5521614. [Google Scholar] [CrossRef]
- Gong, M.; Zhou, Z.; Ma, J. Change detection in synthetic aperture radar images based on image fusion and fuzzy clustering. IEEE Trans. Image Process. 2012, 21, 2141–2151. [Google Scholar] [CrossRef] [PubMed]
- Gong, M.; Zhao, J.; Liu, J.; Miao, Q.; Jiao, L. Change detection in synthetic aperture radar images based on deep neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 125–138. [Google Scholar] [CrossRef]
- Liu, T.; Gong, M.; Lu, D.; Zhang, Q.; Zheng, H.; Jiang, F.; Zhang, M. Building change detection for VHR remote sensing images via local–global pyramid network and cross-task transfer learning strategy. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4704817. [Google Scholar] [CrossRef]
- Gong, M.; Su, L.; Jia, M.; Chen, W. Fuzzy clustering with a modified MRF energy function for change detection in synthetic aperture radar images. IEEE Trans. Fuzzy Syst. 2014, 22, 98–109. [Google Scholar] [CrossRef]
- Wu, Y.; Li, J.; Yuan, Y.; Qin, A.; Miao, Q.G.; Gong, M.G. Commonality autoencoder: Learning common features for change detection from heterogeneous images. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 4257–4270. [Google Scholar] [CrossRef] [PubMed]
- Castelluccio, M.; Poggi, G.; Sansone, C.; Verdoliva, L. Land use classification in remote sensing images by convolutional neural networks. arXiv 2015, arXiv:1508.00092. [Google Scholar]
- Zhu, Q.; Sun, Y.; Guan, Q.; Wang, L.; Lin, W. A weakly pseudo-supervised decorrelated subdomain adaptation framework for cross-domain land-use classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5623913. [Google Scholar] [CrossRef]
- Pires de Lima, R.; Marfurt, K. Convolutional neural network for remote-sensing scene classification: Transfer learning analysis. Remote Sens. 2019, 12, 86. [Google Scholar] [CrossRef]
- Gong, M.; Li, J.; Zhang, Y.; Wu, Y.; Zhang, M. Two-path aggregation attention network with quad-patch data augmentation for few-shot scene classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4511616. [Google Scholar] [CrossRef]
- Wang, Z.; Li, J.; Liu, Y.; Xie, F.; Li, P. An adaptive surrogate-assisted endmember extraction framework based on intelligent optimization algorithms for hyperspectral remote sensing images. Remote Sens. 2022, 14, 892. [Google Scholar] [CrossRef]
- Huang, X.; Wen, D.; Li, J.; Qin, R. Multi-level monitoring of subtle urban changes for the megacities of China using high-resolution multi-view satellite imagery. Remote Sens. Environ. 2017, 196, 56–75. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Huang, X.; Yuille, A.L. Deep networks under scene-level supervision for multi-class geospatial object detection from remote sensing images. ISPRS J. Photogramm. Remote Sens. 2018, 146, 182–196. [Google Scholar] [CrossRef]
- Longbotham, N.; Chaapel, C.; Bleiler, L.; Padwick, C.; Emery, W.J.; Pacifici, F. Very high resolution multiangle urban classification analysis. IEEE Trans. Geosci. Remote Sens. 2012, 50, 1155–1170. [Google Scholar] [CrossRef]
- Gong, M.; Liang, Y.; Shi, J.; Ma, W.; Ma, J. Fuzzy c-means clustering with local information and kernel metric for image segmentation. IEEE Trans. Image Process. 2012, 22, 573–584. [Google Scholar] [CrossRef]
- Wu, Y.; Ma, W.; Gong, M.; Su, L.; Jiao, L. A novel point-matching algorithm based on fast sample consensus for image registration. IEEE Geosci. Remote Sens. Lett. 2014, 12, 43–47. [Google Scholar] [CrossRef]
- Zhang, Y.; Gong, M.; Li, J.; Zhang, M.; Jiang, F.; Zhao, H. Self-supervised monocular depth estimation with multiscale perception. IEEE Trans. Image Process. 2022, 31, 3251–3266. [Google Scholar] [CrossRef]
- Li, H.; Li, J.; Zhao, Y.; Gong, M.; Zhang, Y.; Liu, T. Cost-sensitive self-paced learning with adaptive regularization for classification of image time series. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 11713–11727. [Google Scholar] [CrossRef]
- Li, J.; Gong, M.; Liu, H.; Zhang, Y.; Zhang, M.; Wu, Y. Multiform ensemble self-supervised learning for few-shot remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4500416. [Google Scholar] [CrossRef]
- Perronnin, F.; Sánchez, J.; Mensink, T. Improving the fisher kernel for large-scale image classification. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 143–156. [Google Scholar]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; pp. 2169–2178. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Zhang, F.; Du, B.; Zhang, L. Saliency-guided unsupervised feature learning for scene classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2175–2184. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Guo, L.; Liu, T. Learning coarse-to-fine sparselets for efficient object detection and scene classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1173–1181. [Google Scholar]
- Han, X.; Zhong, Y.; Zhao, B.; Zhang, L. Scene classification based on a hierarchical convolutional sparse auto-encoder for high spatial resolution imagery. Int. J. Remote Sens. 2017, 38, 514–536. [Google Scholar] [CrossRef]
- Shi, C.; Zhang, X.; Sun, J.; Wang, L. Remote sensing scene image classification based on self-compensating convolution neural network. Remote Sens. 2022, 14, 545. [Google Scholar] [CrossRef]
- Zhu, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Generative adversarial networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5046–5063. [Google Scholar] [CrossRef]
- Gu, S.; Zhang, R.; Luo, H.; Li, M.; Feng, H.; Tang, X. Improved singan integrated with an attentional mechanism for remote sensing image classification. Remote Sens. 2021, 13, 1713. [Google Scholar] [CrossRef]
- Miao, W.; Geng, J.; Jiang, W. Semi-supervised remote-sensing image scene classification using representation consistency siamese network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5616614. [Google Scholar] [CrossRef]
- Penatti, O.A.; Nogueira, K.; Dos Santos, J.A. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 44–51. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25; Curran Associates, Inc.: Red Hook, NY, USA, 2012. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Amsterdam, The Netherlands, 8–16 October 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Zhang, B.; Zhang, Y.; Wang, S. A lightweight and discriminative model for remote sensing scene classification with multidilation pooling module. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2636–2653. [Google Scholar] [CrossRef]
- Yu, D.; Guo, H.; Xu, Q.; Lu, J.; Zhao, C.; Lin, Y. Hierarchical attention and bilinear fusion for remote sensing image scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 6372–6383. [Google Scholar] [CrossRef]
- Tong, W.; Chen, W.; Han, W.; Li, X.; Wang, L. Channel-attention-based densenet network for remote sensing image scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4121–4132. [Google Scholar] [CrossRef]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When deep learning meets metric learning: Remote sensing image scene classification via learning discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Wang, C.; Tang, X.; Li, L.; Tian, B.; Zhou, Y.; Shi, J. IDN: Inner-class dense neighbours for semi-supervised learning-based remote sensing scene classification. Remote Sens. Lett. 2023, 14, 80–90. [Google Scholar] [CrossRef]
- Zoph, B.; Le, Q.V. Neural architecture search with reinforcement learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Baker, B.; Gupta, O.; Naik, N.; Raskar, R. Designing neural network architectures using reinforcement learning. arXiv 2016, arXiv:1611.02167. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar]
- Real, E.; Moore, S.; Selle, A.; Saxena, S.; Suematsu, Y.L.; Tan, J.; Le, Q.V.; Kurakin, A. Large-scale evolution of image classifiers. In Proceedings of the International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 2902–2911. [Google Scholar]
- Xie, L.; Yuille, A. Genetic cnn. In Proceedings of the the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1379–1388. [Google Scholar]
- Sun, Y.; Xue, B.; Zhang, M.; Yen, G.G. Evolving deep convolutional neural networks for image classification. IEEE Trans. Evol. Comput. 2020, 24, 394–407. [Google Scholar] [CrossRef]
- Liu, H.; Simonyan, K.; Yang, Y. Darts: Differentiable architecture search. arXiv 2018, arXiv:1806.09055. [Google Scholar]
- Xie, S.; Zheng, H.; Liu, C.; Lin, L. SNAS: Stochastic neural architecture search. arXiv 2018, arXiv:1812.09926. [Google Scholar]
- Tanveer, M.S.; Khan, M.U.K.; Kyung, C.M. Fine-tuning darts for image classification. In Proceedings of the IEEE International Conference on Pattern Recognition, Los Alamitos, CA, USA, 11–17 October 2021; pp. 4789–4796. [Google Scholar]
- Wu, Y.; Ding, H.; Gong, M.; Qin, A.; Ma, W.; Miao, Q.; Tan, K.C. Evolutionary multiform optimization with two-stage bidirectional knowledge transfer strategy for point cloud registration. IEEE Trans. Evol. Comput. 2022. [CrossRef]
- Li, J.; Li, H.; Liu, Y.; Gong, M. Multi-fidelity evolutionary multitasking optimization for hyperspectral endmember extraction. Appl. Soft Comput. 2021, 111, 107713. [Google Scholar] [CrossRef]
- Elsken, T.; Metzen, J.H.; Hutter, F. Simple and efficient architecture search for convolutional neural networks. arXiv 2017, arXiv:1711.04528. [Google Scholar]
- Chen, T.; Goodfellow, I.; Shlens, J. Net2net: Accelerating learning via knowledge transfer. arXiv 2015, arXiv:1511.05641. [Google Scholar]
- Zhu, H.; An, Z.; Yang, C.; Xu, K.; Zhao, E.; Xu, Y. EENA: Efficient evolution of neural architecture. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Los Alamitos, CA, USA, 27–28 October 2019; pp. 1891–1899. [Google Scholar]
- Wang, B.; Sun, Y.; Xue, B.; Zhang, M. Evolving deep convolutional neural networks by variable-length particle swarm optimization for image classification. In Proceedings of the IEEE Congress on Evolutionary Computation, Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Xie, X.; Liu, Y.; Sun, Y.; Yen, G.G.; Xue, B.; Zhang, M. BenchENAS: A benchmarking platform for evolutionary neural architecture search. IEEE Trans. Evol. Comput. 2022, 26, 1473–1485. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, S.; Zhang, Y.; Chen, W. RS-DARTS: A convolutional neural architecture search for remote sensing image scene classification. Remote Sens. 2021, 14, 141. [Google Scholar] [CrossRef]
- Peng, C.; Li, Y.; Jiao, L.; Shang, R. Efficient convolutional neural architecture search for remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6092–6105. [Google Scholar] [CrossRef]
- Chen, J.; Huang, H.; Peng, J.; Zhu, J.; Chen, L.; Tao, C.; Li, H. Contextual information-preserved architecture learning for remote-sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5602614. [Google Scholar] [CrossRef]
- Ma, A.; Wan, Y.; Zhong, Y.; Wang, J.; Zhang, L. SceneNet: Remote sensing scene classification deep learning network using multi-objective neural evolution architecture search. ISPRS J. Photogramm. Remote Sens. 2021, 172, 171–188. [Google Scholar] [CrossRef]
- Wan, Y.; Zhong, Y.; Ma, A.; Wang, J.; Zhang, L. E2SCNet: Efficient multiobjective evolutionary automatic search for remote sensing image scene classification network architecture. IEEE Trans. Neural Netw. Learn. Syst. 2022; Early Access. [Google Scholar]
- Gudzius, P.; Kurasova, O.; Darulis, V.; Filatovas, E. AutoML-based neural architecture search for object recognition in satellite imagery. Remote Sens. 2022, 15, 91. [Google Scholar] [CrossRef]
- Zhang, X.; Tian, Y.; Jin, Y. A knee point-driven evolutionary algorithm for many-objective optimization. IEEE Trans. Evol. Comput. 2015, 19, 761–776. [Google Scholar] [CrossRef]
- Zhou, W.; Newsam, S.; Li, C.; Shao, Z. PatternNet: A benchmark dataset for performance evaluation of remote sensing image retrieval. ISPRS J. Photogramm. Remote Sens. 2018, 145, 197–209. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 11976–11986. [Google Scholar]
- Li, G.; Qian, G.; Delgadillo, I.C.; Muller, M.; Thabet, A.; Ghanem, B. Sgas: Sequential greedy architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Los Alamitos, CA, USA, 25 June 2020; pp. 1620–1630. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. Mnasnet: Platform-aware neural architecture search for mobile. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2820–2828. [Google Scholar]
- Li, J.; Weinmann, M.; Sun, X.; Diao, W.; Feng, Y.; Fu, K. Random topology and random multiscale mapping: An automated design of multiscale and lightweight neural network for remote-sensing image recognition. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5610917. [Google Scholar] [CrossRef]
- Chen, X.; Xie, L.; Wu, J.; Tian, Q. Progressive differentiable architecture search: Bridging the depth gap between search and evaluation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 1294–1303. [Google Scholar]
- Wang, J.; Zhong, Y.; Zheng, Z.; Ma, A.; Zhang, L. RSNet: The search for remote sensing deep neural networks in recognition tasks. IEEE Trans. Geosci. Remote Sens. 2020, 59, 2520–2534. [Google Scholar] [CrossRef]
- Chen, J.; Huang, H.; Peng, J.; Zhu, J.; Chen, L.; Li, W.; Sun, B.; Li, H. Convolution neural network architecture learning for remote sensing scene classification. arXiv 2020, arXiv:2001.09614. [Google Scholar]
- Chu, X.; Zhou, T.; Zhang, B.; Li, J. Fair darts: Eliminating unfair advantages in differentiable architecture search. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 465–480. [Google Scholar]
- Lin, D.; Fu, K.; Wang, Y.; Xu, G.; Sun, X. MARTA GANs: Unsupervised representation learning for remote sensing image classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2092–2096. [Google Scholar] [CrossRef]
- Yu, Y.; Li, X.; Liu, F. Attention GANs: Unsupervised deep feature learning for aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2019, 58, 519–531. [Google Scholar] [CrossRef]
- Zhang, W.; Tang, P.; Zhao, L. Remote sensing image scene classification using CNN-CapsNet. Remote Sens. 2019, 11, 494. [Google Scholar] [CrossRef]
- Sun, H.; Li, S.; Zheng, X.; Lu, X. Remote sensing scene classification by gated bidirectional network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 82–96. [Google Scholar] [CrossRef]
- He, N.; Fang, L.; Li, S.; Plaza, A.; Plaza, J. Remote sensing scene cassification using multilayer stacked covariance pooling. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6899–6910. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Scene Classes | Total Image | Image per Class | Spatial Resolution (m) | Image Size |
|---|---|---|---|---|---|
| UCM21 | 21 | 2100 | 100 | 0.3 | 256 × 256 |
| PatternNet | 38 | 30,400 | 800 | 0.06∼4.69 | 256 × 256 |
| NWPU45 | 45 | 31,500 | 700 | 0.2∼30 | 256 × 256 |
| Versions | |
|---|---|
| CPU | Inter(R) Core(TM) i7-10700 |
| GPU | NVIDIA GeForce 3090 |
| Pytorch | 1.11.0 |
| Python | 3.10.4 |
| Phase | Hyperparameter Name | Hyperparameter Value |
|---|---|---|
| Population size | 64 | |
| Number of blocks | from 1 to 8 | |
| Number of nodes | 6 | |
| Crossover probability | 0.5 | |
| Mutation probability | ||
| Batch size | 16 | |
| Optimizer | SGD | |
| First search phase | Momentum | 0.9 |
| Weight decay | ||
| Learning strategy | Cosine | |
| Learning rate | 0.03 | |
| Epoch_UCM21 | 50 | |
| Epoch_PatternNet | 20 | |
| Epoch_NWPU45 | 50 | |
| Population size | 40 | |
| Number of nodes | 6 | |
| Crossover probability | 0.5 | |
| Mutation probability | ||
| Batch size | 16 | |
| Optimizer | SGD | |
| Second search phase | Momentum | 0.9 |
| Weight decay | ||
| Learning strategy | Cosine | |
| Learning rate | 0.03 | |
| Epoch_UCM21 | 50 | |
| Epoch_PatternNet | 15 | |
| Epoch_NWPU45 | 20 | |
| Eopch | 1000 | |
| Batch size | 16 | |
| Optimizer | SGD | |
| Retraining phase | Momentum | 0.9 |
| Weight decay | ||
| Learning strategy | Cosine | |
| Learning rate | 0.03 | |
| Loss function | Cross Entropy Loss |
| Method | OA (%) ↑ | GFLOPs ↓ | Params (M) ↓ | Search Strategy |
|---|---|---|---|---|
| AlexNet [66] | 81.19 | 0.92 | 57.09 | manual |
| VGG16 [32] | 78.57 | 20.18 | 134.35 | manual |
| ResNet50 [33] | 85.24 | 5.37 | 23.56 | manual |
| ConvNeXt [67] | 84.29 | 20.07 | 88.57 | manual |
| DenseNet161 [35] | 86.19 | 10.17 | 26.52 | manual |
| Fine-tuned AlexNet [66] | 92.14 | 0.92 | 57.09 | manual |
| Fine-tuned VGG16 [32] | 95.48 | 20.18 | 134.35 | manual |
| Fine-tuned ResNet50 [33] | 98.57 | 5.37 | 23.56 | manual |
| Fine-tuned ConvNeXt [67] | 97.86 | 20.07 | 88.57 | manual |
| Fine-tuned DenseNet161 [35] | 98.33 | 10.17 | 26.52 | manual |
| NASNet [43] | 89.62 | 0.77 | 4.26 | NAS |
| SGAS [68] | 92.05 | 0.81 | 4.69 | NAS |
| MNASNet [69] | 94.52 | 0.43 | 3.13 | NAS |
| RTRMM [70] | 96.76 | 0.38 | 0.82 | NAS |
| DARTS [47] | 95.19 | 0.71 | 3.97 | NAS |
| PDARTS [71] | 91.52 | 0.73 | 4.19 | NAS |
| RSNet [72] | 96.78 | 1.19 | 1.22 | NAS |
| CIPAL [59] | 96.58 | - | 1.58 | NAS |
| ALP [73] | 93.43 | - | 2.63 | NAS |
| TPENAS (ours) | 98.81 | 2.76 | 1.80 | NAS |
| Method | OA (%) ↑ | GFLOPs ↓ | Params (M) ↓ | Search Strategy |
|---|---|---|---|---|
| VGG16 [32] | 97.31 | 20.18 | 134.42 | manual |
| GoogLeNet [34] | 96.12 | 1.96 | 56.64 | manual |
| ResNet50 [33] | 96.71 | 5.37 | 235.96 | manual |
| Fine-tuned VGG16 [32] | 98.31 | 20.18 | 134.42 | manual |
| Fine-tuned GoogLeNet [34] | 97.56 | 1.96 | 56.64 | manual |
| Fine-tuned ResNet50 [33] | 98.23 | 5.37 | 23.59 | manual |
| DARTS [47] | 95.58 | 0.71 | 3.98 | NAS |
| PDARTS [71] | 99.10 | 0.73 | 4.21 | NAS |
| Fair DARTS [74] | 98.88 | 0.53 | 3.32 | NAS |
| GPAS [58] | 99.01 | - | 3.72 | NAS |
| TPENAS (ours) | 99.05 | 1.30 | 0.15 | NAS |
| Method | OA (%) ↑ | GFLOPs ↓ | Params (M) ↓ | Search Strategy |
|---|---|---|---|---|
| AlexNet [66] | 79.85 | 0.92 | 57.19 | manual |
| VGGNet16 [32] | 79.79 | 20.18 | 134.44 | manual |
| GoogleNet [34] | 78.48 | 1.97 | 5.65 | manual |
| ResNet50 [33] | 83.00 | 5.37 | 23.60 | manual |
| Fine-tuned AlexNet [66] | 85.16 | 0.92 | 57.19 | manual |
| Fine-tuned VGG16 [32] | 90.36 | 20.18 | 134.44 | manual |
| Fine-tuned GoogLeNet [34] | 86.02 | 1.96 | 5.65 | manual |
| NASNet [43] | 67.48 | 0.77 | 4.28 | NAS |
| SGAS [68] | 75.87 | 0.81 | 4.70 | NAS |
| DARTS [47] | 67.48 | 0.77 | 3.41 | NAS |
| MNASNet [69] | 81.92 | 0.43 | 3.16 | NAS |
| PDARTS [71] | 82.14 | 0.73 | 4.21 | NAS |
| RTRMM [70] | 86.32 | 0.39 | 0.83 | NAS |
| TPENAS (ours) | 90.38 | 1.65 | 1.67 | NAS |
| TPENAS (ours) | 87.79 | 1.27 | 0.41 | NAS |
| Method | UCM21 | NWPU45 |
|---|---|---|
| MARTA GANs [75] | 94.86 | 75.03 |
| Attention GANs [76] | 97.69 | 77.99 |
| VGG-16-CapsNet [77] | 98.81 | 89.18 |
| GBN [78] | 98.57 | - |
| MSCP [79] | 98.36 | 88.93 |
| TPENAS (ours) | 98.81 | 90.38 |
| Method | OA ↑ | Params (M) ↓ | GFLOPs ↓ |
|---|---|---|---|
| SceneNet [60] | 95.22 | 1.02 | 9.47 |
| E2SCNet [61] | 95.23 | 3.88 | 0.60 |
| TPENAS_large (ours) | 95.70 | 1.65 | 1.67 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ao, L.; Feng, K.; Sheng, K.; Zhao, H.; He, X.; Chen, Z. TPENAS: A Two-Phase Evolutionary Neural Architecture Search for Remote Sensing Image Classification. Remote Sens. 2023, 15, 2212. https://doi.org/10.3390/rs15082212
Ao L, Feng K, Sheng K, Zhao H, He X, Chen Z. TPENAS: A Two-Phase Evolutionary Neural Architecture Search for Remote Sensing Image Classification. Remote Sensing. 2023; 15(8):2212. https://doi.org/10.3390/rs15082212
Chicago/Turabian StyleAo, Lei, Kaiyuan Feng, Kai Sheng, Hongyu Zhao, Xin He, and Zigang Chen. 2023. "TPENAS: A Two-Phase Evolutionary Neural Architecture Search for Remote Sensing Image Classification" Remote Sensing 15, no. 8: 2212. https://doi.org/10.3390/rs15082212
APA StyleAo, L., Feng, K., Sheng, K., Zhao, H., He, X., & Chen, Z. (2023). TPENAS: A Two-Phase Evolutionary Neural Architecture Search for Remote Sensing Image Classification. Remote Sensing, 15(8), 2212. https://doi.org/10.3390/rs15082212