

Multilevel Data and Decision Fusion Using Heterogeneous Sensory Data for Autonomous Vehicles

Abstract
:1. Introduction
- We propose a versatile fusion architecture that performs an early and late fusion of heterogeneous sensory data.
- We provide intelligent, context-sensitive gating tactics that boost resilience by dynamically deciding which fusion mechanism to use based on the situation at hand.
- We show that our methodology trumps existing methods on a demanding real-world dataset with a variety of driving scenarios, including adverse climatic conditions, poor lighting, and different location types.
- We use an industry-standard AV hardware platform to implement our strategy, and we develop applications using Python. This ensures that our strategy can be practically implemented in a real AV with comparable energy consumption, latency, and memory usage to cutting-edge approaches.
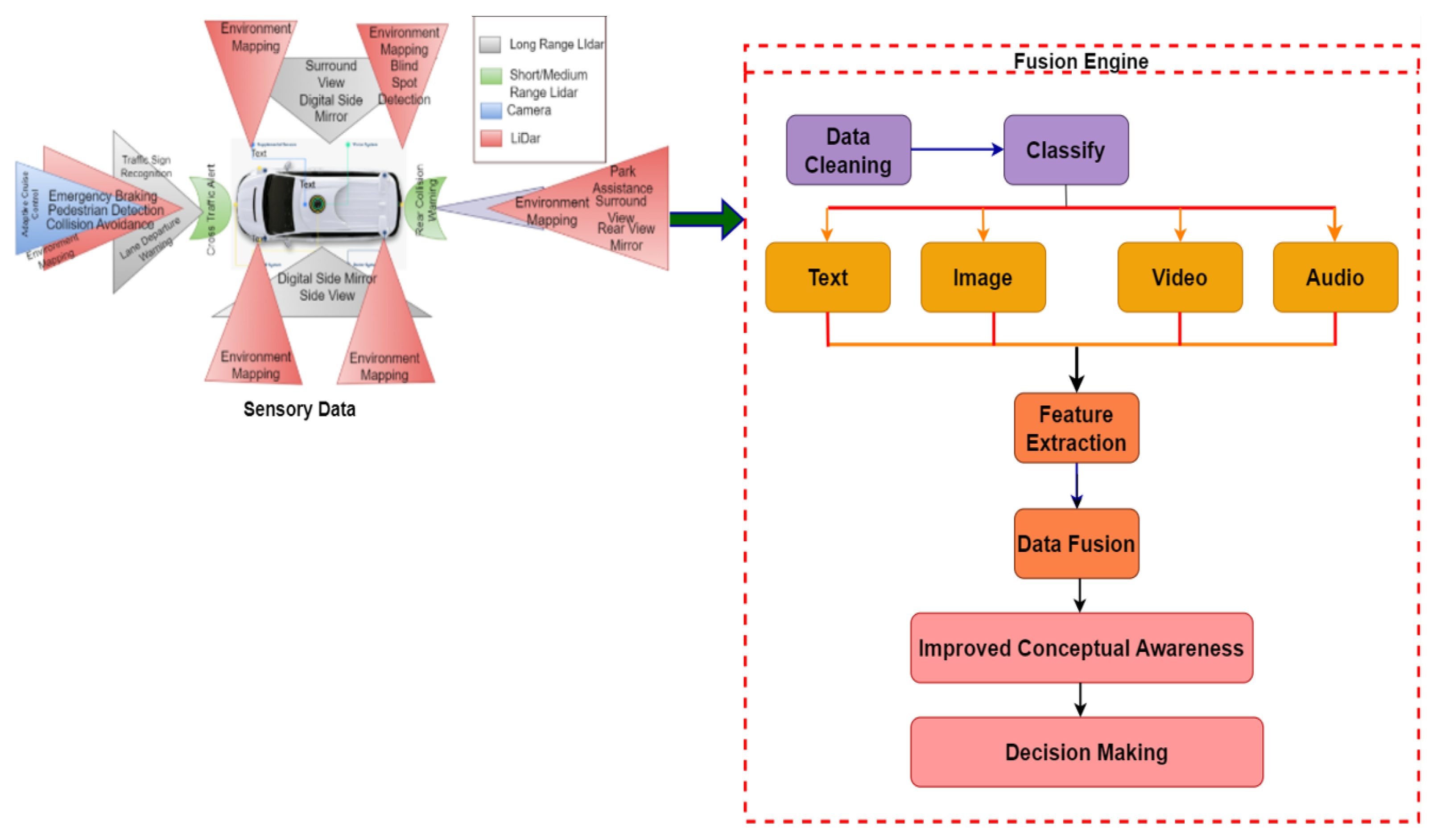
2. Background and Motivation
- Datasets having similar structure (identical columns with similar data types)
- Datasets having different columns
- Datasets that have dissimilar structures (columns having different data types)
Theory behind Data and Decision Level Fusion
3. Related Work
3.1. Sensor Fusion
3.2. Fusion in Object Detection
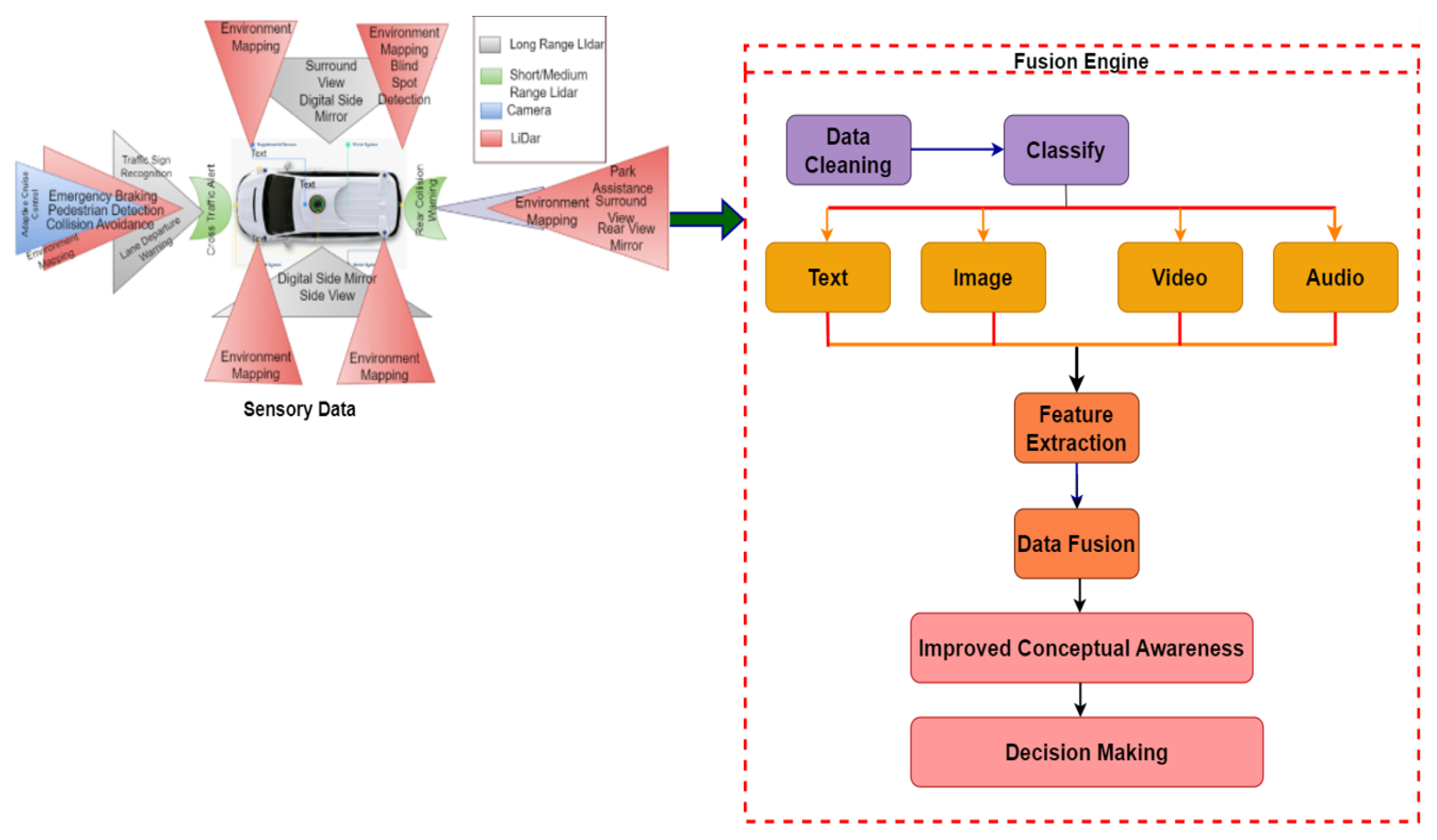
4. Proposed Study
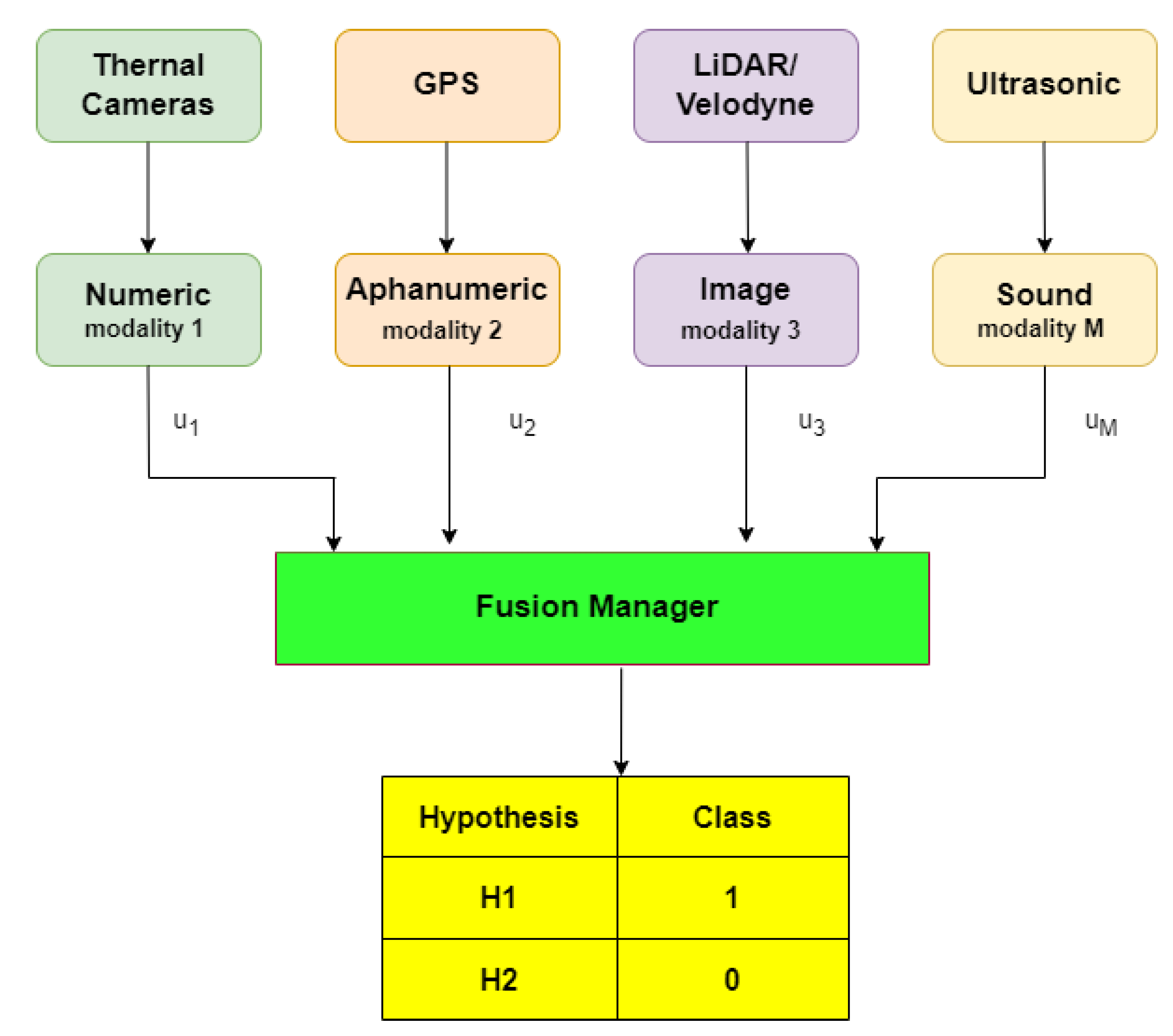
4.1. Problem Formulation
4.2. Proposed Fusion Models
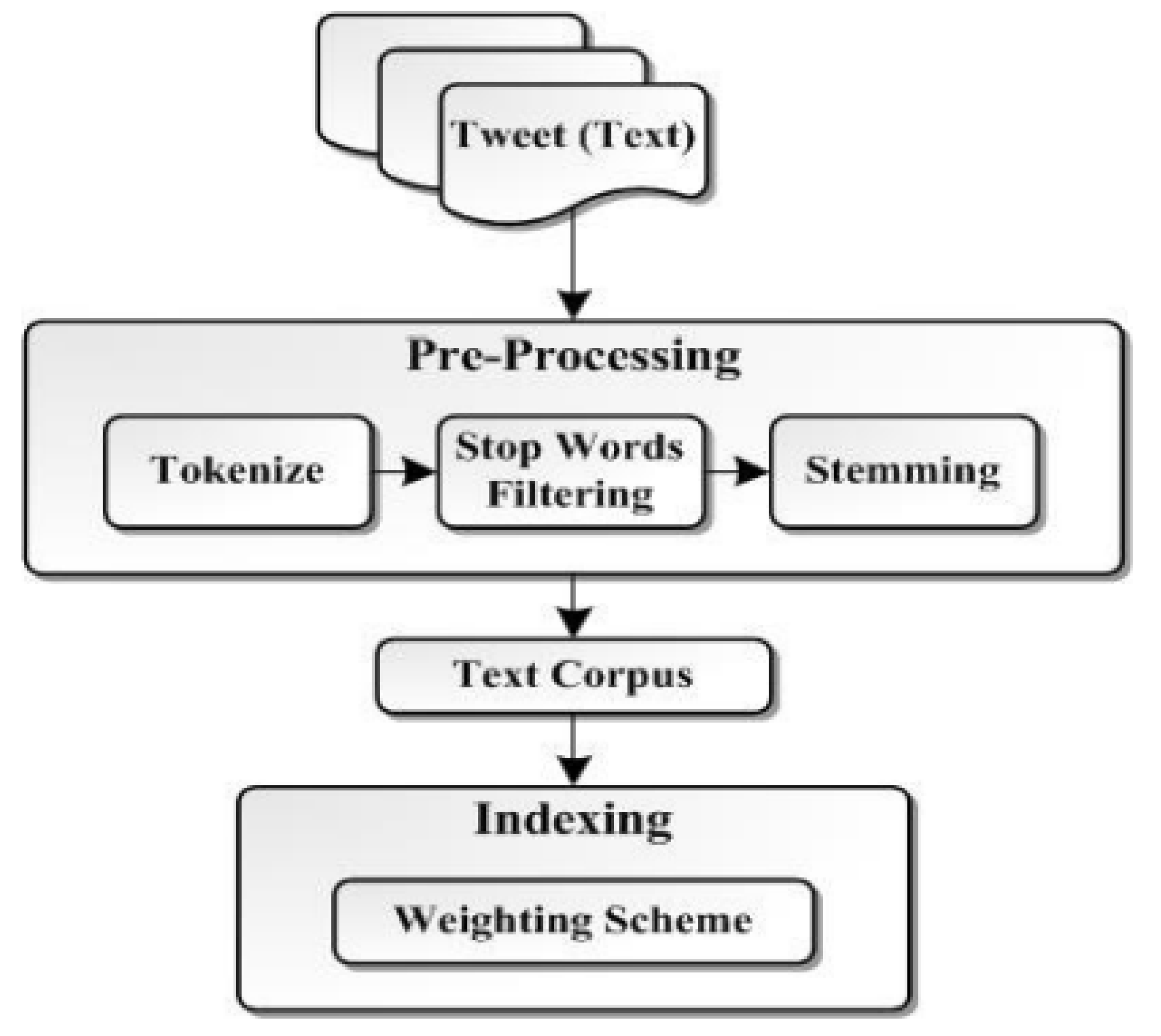
4.2.1. Proposed Data Level Text Fusion Model
| Algorithm 1: Proposed text fusion algorithm |
1 EOL: end of line 2 A: First record 3 B: Alternate record 4 Begin 5 Input 6 The data record from the GPS and move to an Excel file 7 Compare alternate records 8 Count the number of columns of A and B 9 If the column count is the same 10 Repeat while EOL 11 Compare the ASCII value of each column of alternate records A and B 12 If the ASCII values are the same then 13 If the data is numeric (or) alphanumeric then 14 Tokenize the data 15 Remove punctuation marks 16 Eliminate commonly occurring words 17 Reduce each word to a stem 18 Index the data 19 Check for similarity 20 If the columns are the same fuse the records by taking union 21 Else 22 Considering the records are dissimilar move to the next record 23 Repeat the same procedure for the rest of the columns 24 End repeat 25 End |
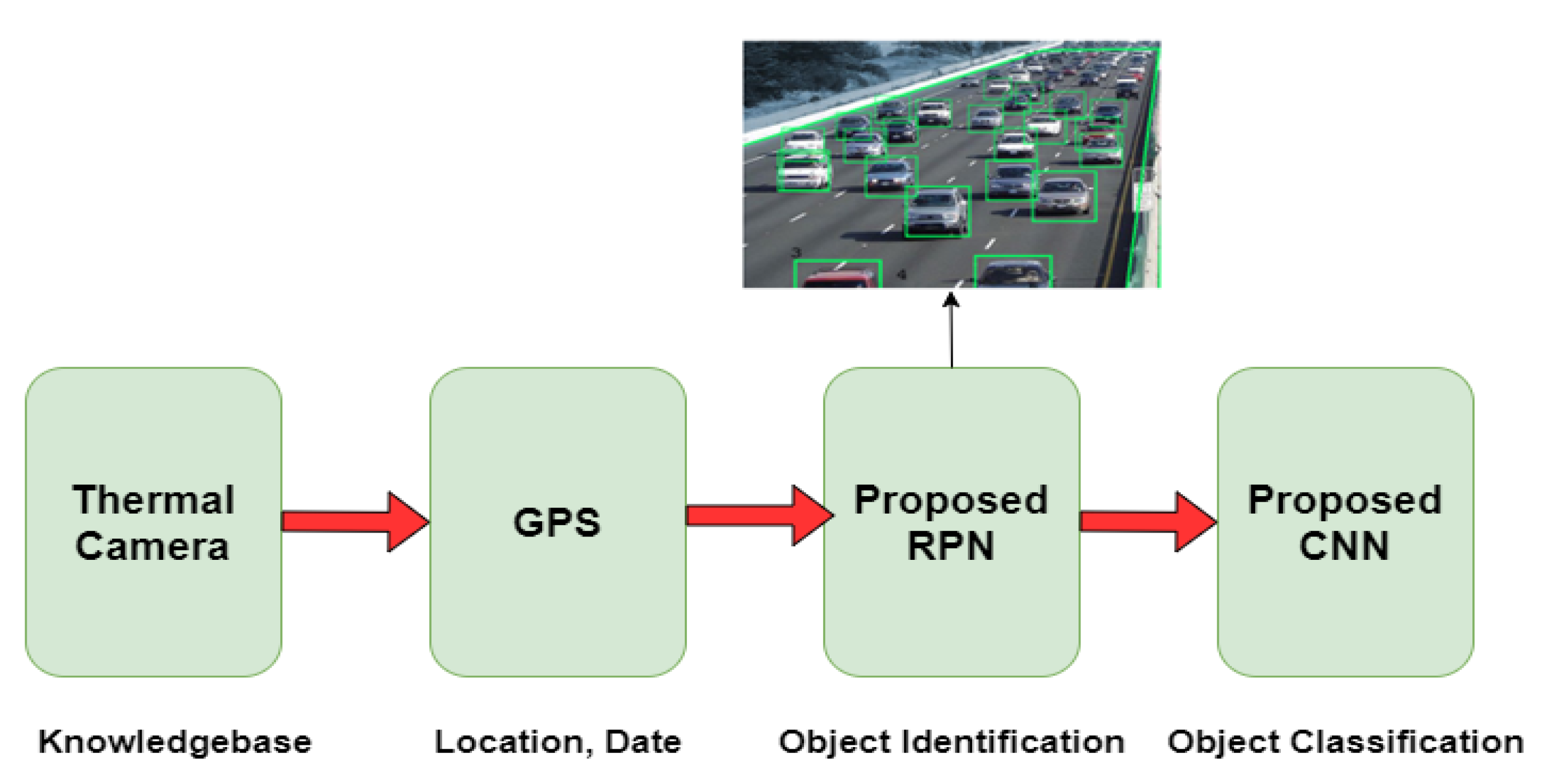
4.2.2. Proposed Object Detection and Classification Models
- function get_image_info(image)
- return (coordinates, image_info)
| Algorithm 2: Proposed object detection algorithm |
1 eol: end of a line 2 eoa: end of the array 3 Begin 4 Input the image frame 5 Do 6 Read pixel information from each line 7 Check whether the pixel is an edge of the image 8 If yes mark the coordinate position of the edge 9 While ≠ eol 10 From the edge_list identify the minimum and maximum coordinate values 11 The information gained forms the boundary of the image () 12 Create a box over the identified coordinates 13 Any information within the box is the identified object 14 Store the identified object in an image array 15 Do 16 Read the image information from the array 17 Pass to a CNN model 18 Obtain the category of the classified object 19 While ≠ eoa |
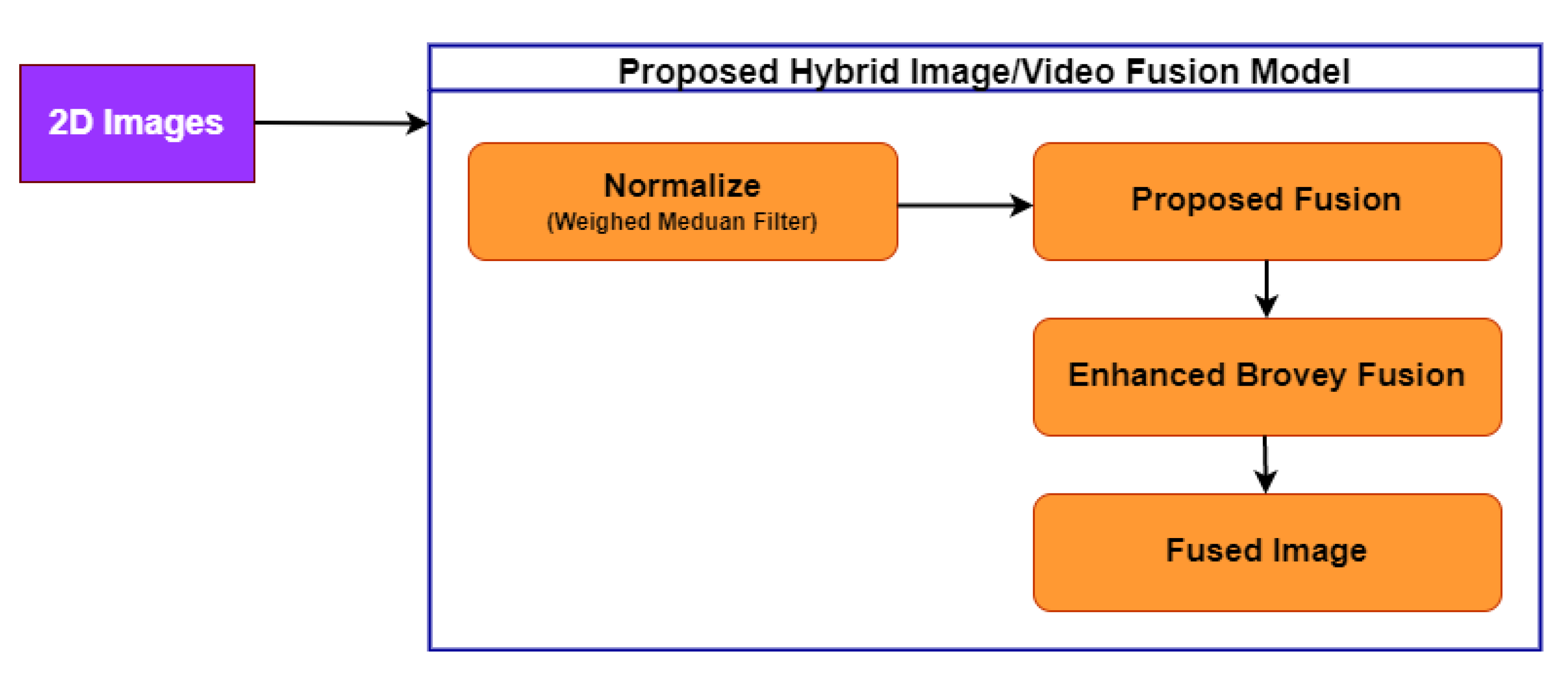
4.2.3. Proposed Hybrid Image Fusion Model
| Algorithm 3: Proposed Hybrid image fusion Algorithm |
1 Input 2D image 2 B:3D GF-3 image 3 Assign Variables 4 A: No of wavelength of 2D image 5 B: No of wavelength of 3D image 6 : No of pixels in 2D image 7 : No of pixels in 3D image 8 : No of pixels in fused 3D image 9 ( - weights, E - normalized pixel values, S - image matrix after transformation) 10 Projection of 2D to 3D 11 for i = 1.. do 12 Compute for 2D image matrix 13 Compute projection of A on B using equation 14 end for 15 Transformation to vector 16 For j = 1.. 17 Compute E using equation 18 Compute using equation 19 Compute S using and with 20 for i = 1.. do 21 Compute using Equation (19) 22 end for 23 for k = 1.. 24 Compute RGB intensities for the fused panchromatic 25 image projected on a 3D image using Brovey fusion Equation (20) 26 Output 27 B = Fused Image |
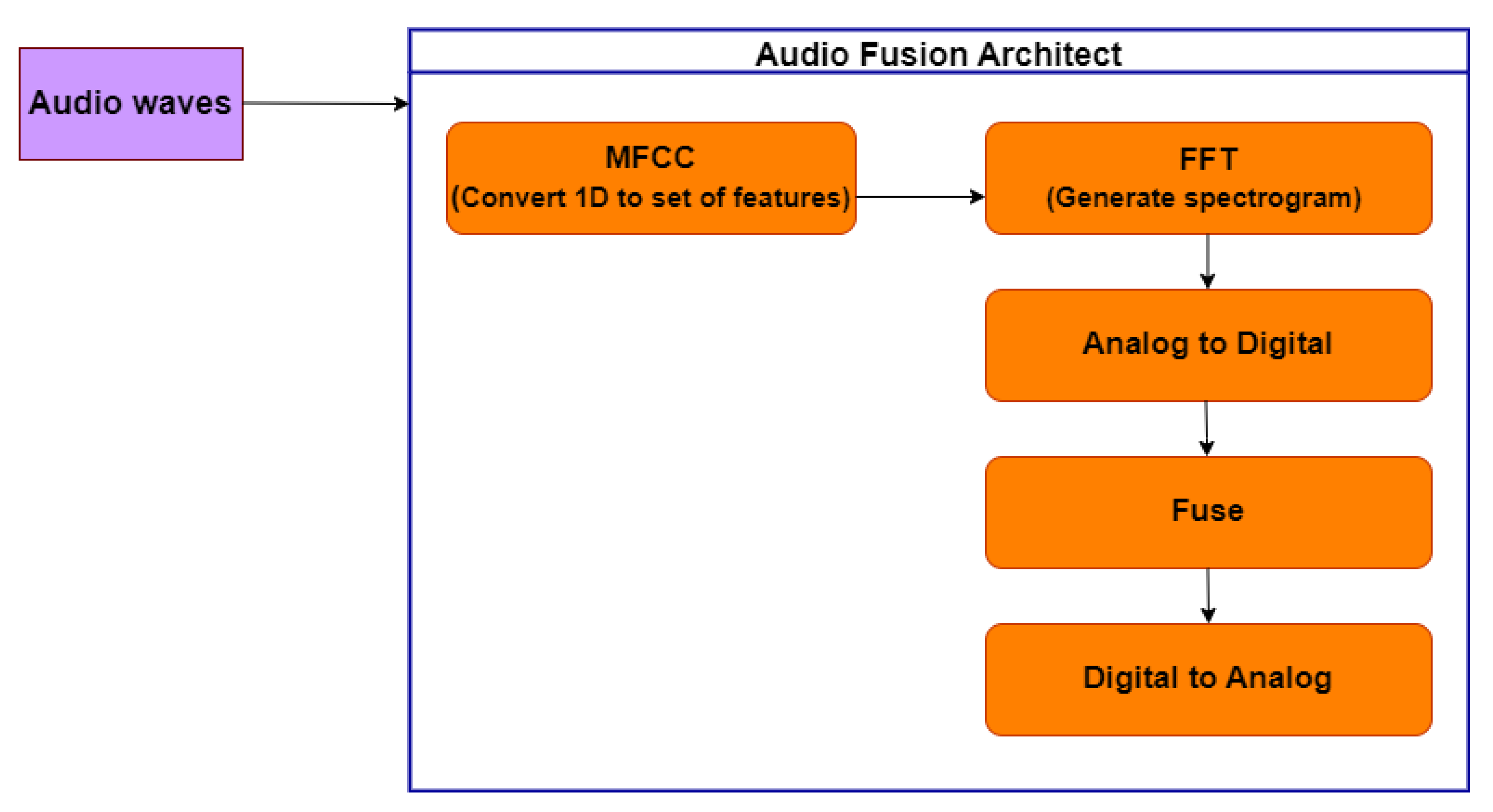
4.2.4. Proposed Audio Fusion Model
4.2.5. Decision Level Fusion
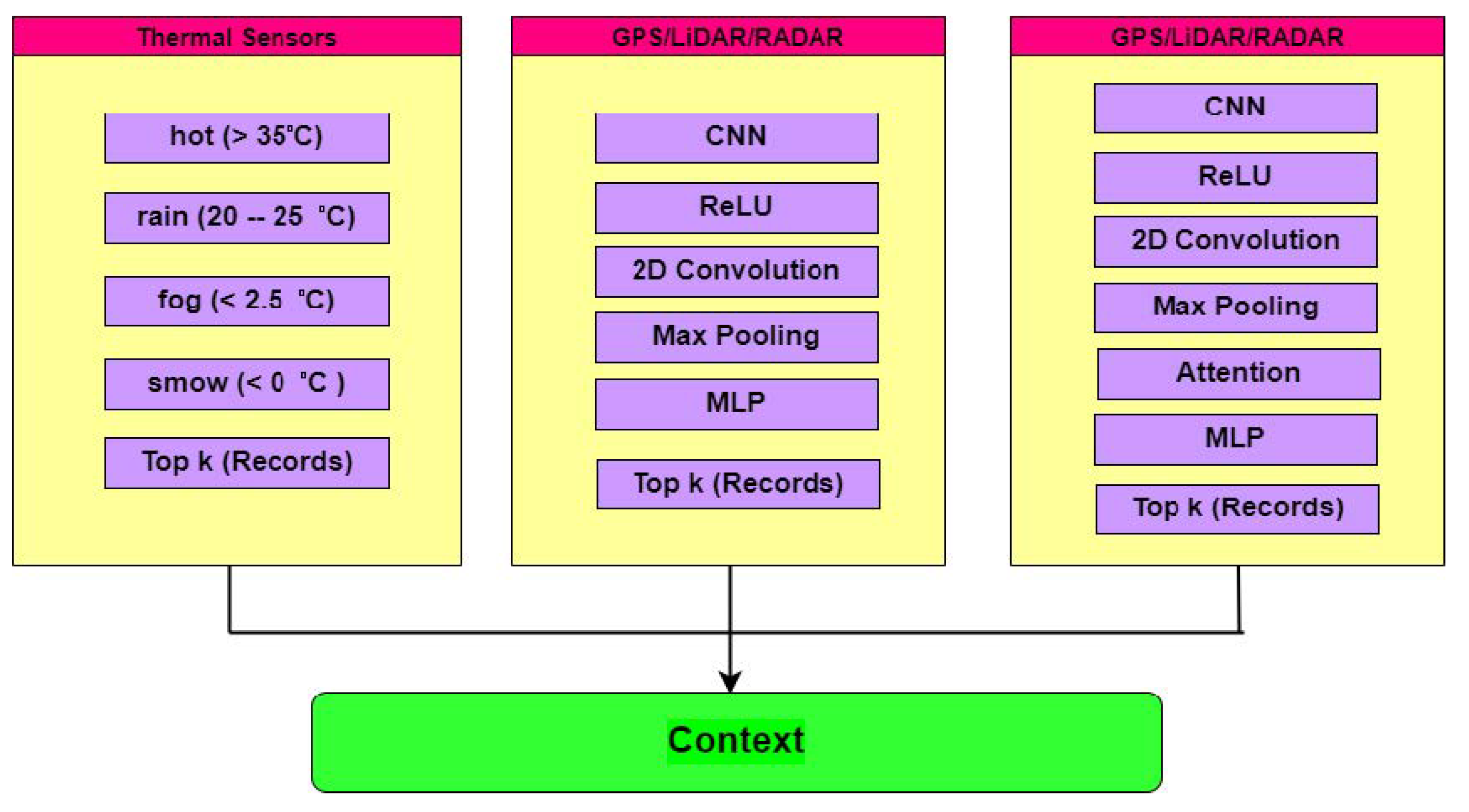
4.2.6. Proposed Context Creation Mechanism
- Data from thermal cameras:
- Data from GPS:
- Data from PCN (Objects Identified):
- Classified data from CNN:
5. Experimental Analysis
5.1. Dataset Details
5.2. Model Implementation
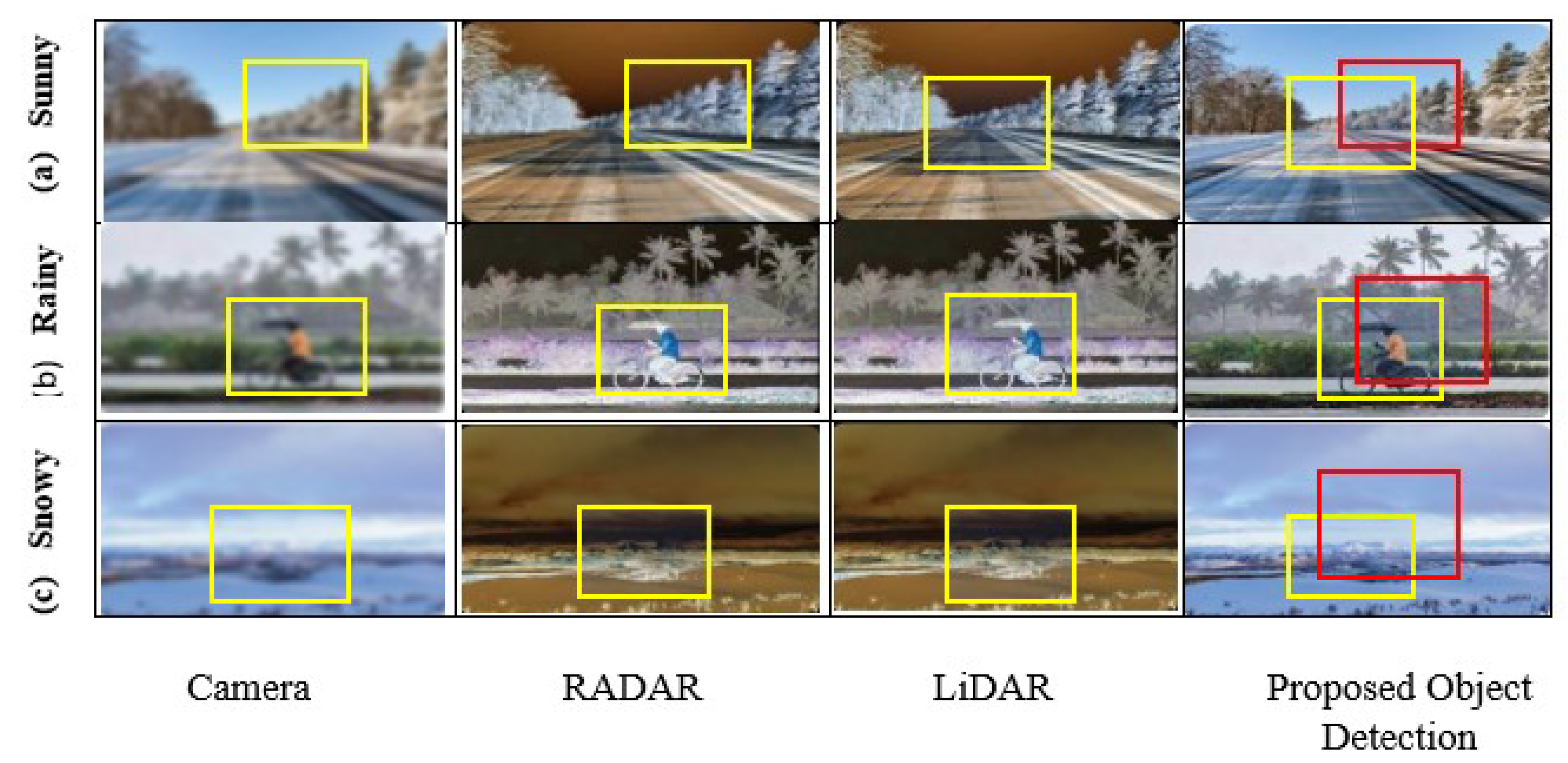
5.3. Overall Analysis
5.3.1. Comparison with Other Related Studies
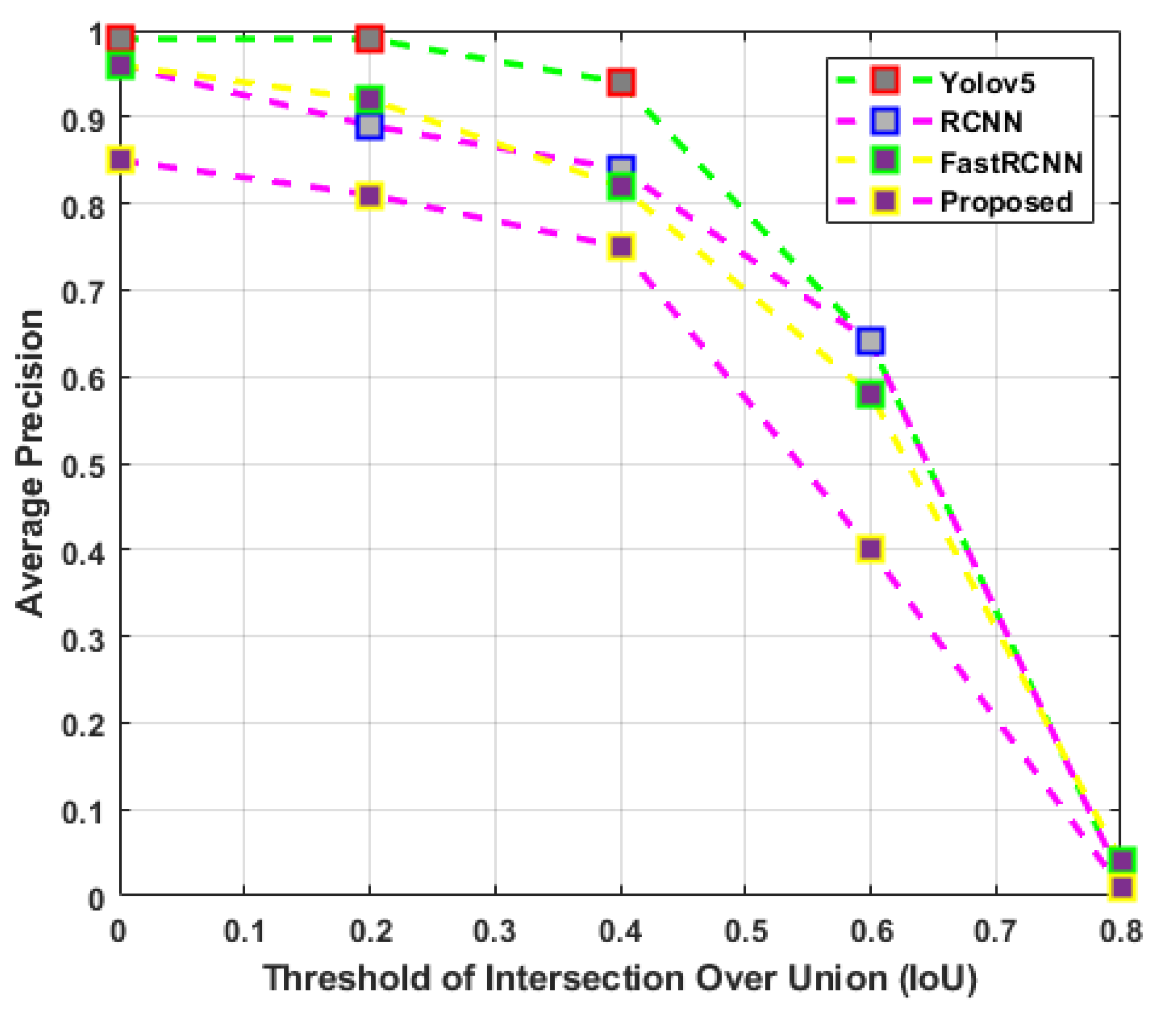
5.3.2. Performance of Hybrid Image Fusion Model
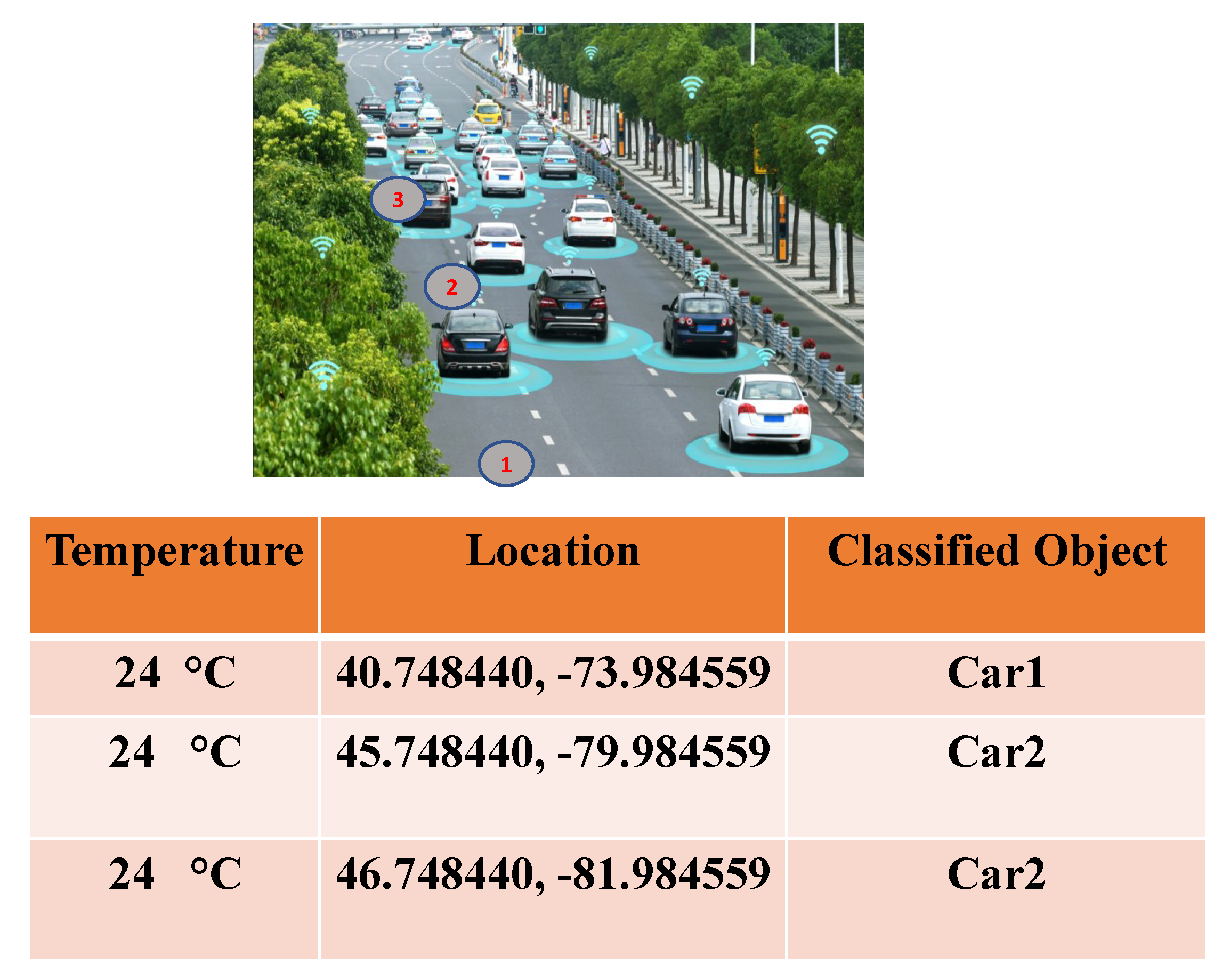
5.3.3. Sample Rule Framing Mechanism
- Rule 1: If the location of object1 > the estimated threshold value of the lane
- Rule 2: If the location of object1 = location of object2
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rosique, F.; Navarro, P.J.; Fernández, C.; Padilla, A. A systematic review of perception system and simulators for autonomous vehicles research. Sensors 2019, 19, 648. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pendleton, S.D.; Andersen, H.; Du, X.; Shen, X.; Meghjani, M.; Eng, Y.H.; Rus, D.; Ang Jr, M.H. Perception, planning, control, and coordination for autonomous vehicles. Machines 2017, 5, 6. [Google Scholar] [CrossRef] [Green Version]
- Feng, D.; Harakeh, A.; Waslander, S.L.; Dietmayer, K. A review and comparative study on probabilistic object detection in autonomous driving. IEEE Trans. Intell. Transp. Syst. 2021, 23, 9961–9980. [Google Scholar] [CrossRef]
- Nakrani, N.M.; Joshi, M.M. A human-like decision intelligence for obstacle avoidance in autonomous vehicle parking. Appl. Intell. 2022, 52, 3728–3747. [Google Scholar] [CrossRef]
- Gupta, S.; Snigdh, I. Multi-sensor fusion in autonomous heavy vehicles. In Autonomous and Connected Heavy Vehicle Technology; Elsevier: Amsterdam, The Netherlands, 2022; pp. 375–389. [Google Scholar]
- Bar-Shalom, Y.; Li, X.R.; Kirubarajan, T. Estimation with Applications to Tracking and Navigation: Theory Algorithms and Software; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Chen, C.; Rosa, S.; Miao, Y.; Lu, C.X.; Wu, W.; Markham, A.; Trigoni, N. Selective sensor fusion for neural visual-inertial odometry. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10542–10551. [Google Scholar]
- Chen, C.; Rosa, S.; Xiaoxuan Lu, C.; Trigoni, N.; Markham, A. Selectfusion: A generic framework to selectively learn multisensory fusion. arXiv 2019, arXiv:1912.13077. [Google Scholar]
- Lee, S.; Lee, D.; Choi, P.; Park, D. Accuracy–power controllable LiDAR sensor system with 3D object recognition for autonomous vehicle. Sensors 2020, 20, 5706. [Google Scholar] [CrossRef]
- Gokhale, V.; Barrera, G.M.; Prasad, R.V. FEEL: Fast, energy-efficient localization for autonomous indoor vehicles. In Proceedings of the ICC 2021-IEEE International Conference on Communications, Virtual Event, 14–23 June 2021; pp. 1–6. [Google Scholar]
- Snidaro, L.; García, J.; Llinas, J. Context-based information fusion: A survey and discussion. Inf. Fusion 2015, 25, 16–31. [Google Scholar] [CrossRef] [Green Version]
- Saeedi, S.; Moussa, A.; El-Sheimy, N. Context-aware personal navigation using embedded sensor fusion in smartphones. Sensors 2014, 14, 5742–5767. [Google Scholar] [CrossRef]
- Board, N. Collision between a sport utility vehicle operating with partial driving automation and a crash attenuator mountain view, california. Accessed Oct. 2020, 30. [Google Scholar]
- Gong, Y.; Xiao, Z.; Tan, X.; Sui, H.; Xu, C.; Duan, H.; Li, D. Context-aware convolutional neural network for object detection in VHR remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 58, 34–44. [Google Scholar] [CrossRef]
- Taylor, E. Autonomous vehicle decision-making algorithms and data-driven mobilities in networked transport systems. Contemp. Readings Law Soc. Justice 2021, 13, 9–19. [Google Scholar]
- Alexander, H.; El-Sayed, H.; Khan, M.A.; Kulkarni, P. Analyzing Factors Influencing Situation Awareness in Autonomous Vehicles—A Survey. Sensors, 2023; Accepted for publication. [Google Scholar]
- Kovacova, M.; Oláh, J.; Popp, J.; Nica, E. The Algorithmic Governance of Autonomous Driving Behaviors: Multi-Sensor Data Fusion, Spatial Computing Technologies, and Movement Tracking Tools. Contemp. Readings Law Soc. Justice 2022, 14, 27–45. [Google Scholar]
- Choi, J.D.; Kim, M.Y. A sensor fusion system with thermal infrared camera and LiDAR for autonomous vehicles and deep learning based object detection. ICT Express 2022. [Google Scholar] [CrossRef]
- Yi, C.; Zhang, K.; Peng, N. A multi-sensor fusion and object tracking algorithm for self-driving vehicles. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2019, 233, 2293–2300. [Google Scholar] [CrossRef]
- Mei, P.; Karimi, H.R.; Ma, F.; Yang, S.; Huang, C. A Multi-sensor Information Fusion Method for Autonomous Vehicle Perception System. In Proceedings of the Science and Technologies for Smart Cities: 7th EAI International Conference, SmartCity360°, Virtual Event, 2–4 December 2021; pp. 633–646. [Google Scholar]
- Bhattacharya, P.; Shukla, A.; Tanwar, S.; Kumar, N.; Sharma, R. 6Blocks: 6G-enabled trust management scheme for decentralized autonomous vehicles. Comput. Commun. 2022, 191, 53–68. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Arnold, E.; Al-Jarrah, O.Y.; Dianati, M.; Fallah, S.; Oxtoby, D.; Mouzakitis, A. A survey on 3d object detection methods for autonomous driving applications. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3782–3795. [Google Scholar] [CrossRef] [Green Version]
- Nobis, F.; Geisslinger, M.; Weber, M.; Betz, J.; Lienkamp, M. A deep learning-based radar and camera sensor fusion architecture for object detection. In Proceedings of the 2019 Sensor Data Fusion: Trends, Solutions, Applications (SDF), Solutions, Bonn, Germany, 15–17 October 2019; pp. 1–7. [Google Scholar]
- Shahian Jahromi, B.; Tulabandhula, T.; Cetin, S. Real-time hybrid multi-sensor fusion framework for perception in autonomous vehicles. Sensors 2019, 19, 4357. [Google Scholar] [CrossRef] [Green Version]
- Xu, D.; Anguelov, D.; Jain, A. Pointfusion: Deep sensor fusion for 3d bounding box estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 244–253. [Google Scholar]
- Aljundi, R.; Chakravarty, P.; Tuytelaars, T. Expert gate: Lifelong learning with a network of experts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3366–3375. [Google Scholar]
- Mullapudi, R.T.; Mark, W.R.; Shazeer, N.; Fatahalian, K. Hydranets: Specialized dynamic architectures for efficient inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8080–8089. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-aware trident networks for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6054–6063. [Google Scholar]
- Wei, Z.; Zhang, F.; Chang, S.; Liu, Y.; Wu, H.; Feng, Z. MmWave Radar and Vision Fusion for Object Detection in Autonomous Driving: A Review. Sensors 2022, 22, 2542. [Google Scholar] [CrossRef]
- Hallyburton, R.S.; Liu, Y.; Cao, Y.; Mao, Z.M.; Pajic, M. Security analysis of camera-lidar fusion against black-box attacks on autonomous vehicles. In Proceedings of the 31st USENIX Security Symposium (USENIX SECURITY), Boston, MA, USA, 10–12 August 2022. [Google Scholar]
- Ahmed, K.; Baig, M.H.; Torresani, L. Network of experts for large-scale image categorization. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 516–532. [Google Scholar]
- Ye, E.; Spiegel, P.; Althoff, M. Cooperative raw sensor data fusion for ground truth generation in autonomous driving. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–7. [Google Scholar]
- Ren, M.; He, P.; Zhou, J. Improved Shape-Based Distance Method for Correlation Analysis of Multi-Radar Data Fusion in Self-Driving Vehicle. IEEE Sensors J. 2021, 21, 24771–24781. [Google Scholar] [CrossRef]
- Liu, W.; Liu, Y.; Bucknall, R. Filtering based multi-sensor data fusion algorithm for a reliable unmanned surface vehicle navigation. J. Mar. Eng. Technol. 2022, 1–17. [Google Scholar] [CrossRef]
- Alexander, H.; El-Sayed, H.; Khan, M.A.; Kulkarni, P. A versatile hybrid image fusion model to fuse multispectral image data. Big Data, 2023; Currently under review. [Google Scholar]
- El-Sayed, H.; Alexander, H.; Khan, M.A.; Kulkarni, P.; Bouktif, S. DyReT: A Dynamic Rule Framing Engine Equipped With Trust Management for Vehicular Networks. IEEE Access 2020, 8, 72757–72767. [Google Scholar] [CrossRef]
- Butt, F.A.; Chattha, J.N.; Ahmad, J.; Zia, M.U.; Rizwan, M.; Naqvi, I.H. On the Integration of Enabling Wireless Technologies and Sensor Fusion for Next-Generation Connected and Autonomous Vehicles. IEEE Access 2022, 10, 14643–14668. [Google Scholar] [CrossRef]
- nuScenes. 2019. Available online: https://www.nuscenes.org/nuscenes (accessed on 19 July 2019).
- KITTI. 2019. Available online: https://paperswithcode.com/dataset/kitti (accessed on 19 July 2019).
- Malawade, A.V.; Mortlock, T.; Al Faruque, M.A. HydraFusion: Context-aware selective sensor fusion for robust and efficient autonomous vehicle perception. In Proceedings of the 2022 ACM/IEEE 13th International Conference on Cyber-Physical Systems (ICCPS), Virtual, 4–6 May 2022; pp. 68–79. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scene | Camera | Radar | LiDAR | Fusion |
|---|---|---|---|---|
| Urban | × | × | × | ✔ |
| Rainy | × | ✔ | ✔ | ✔ |
| Foggy | × | ✔ | ✔ | ✔ |
| Snowy | × | ✔ | × | ✔ |
| Night | × | ✔ | × | ✔ |
| Hardware | |
|---|---|
| Processor | Processor: 2*Intel Xeon Gold 5218 16 core |
| Memory Storage | Memory: 128 GB DDR4-2999 Storage: 2TB SSD |
| Graphics Card | Nvidia quadro 8 GB |
| Software | |
| Operating System | Microsoft Windows 10 Pro 64 for Workstations |
| Tools | Python (3.10.8), MatLab (2022a (R2022a)) |
| Python Packages | · NumPy · SciPy · Scikit-learn · Theano · TensorFlow · Keras · PyTorch. · Pandas. In-demand Machine Learning Skills |
| Dataset | RADIATE, nuScenes, KITTI |
| Fusion Method | Configuration | Energy (J) | Latency (ms) | Memory (MB) |
|---|---|---|---|---|
| None | Radar or LiDAR Single Cam | 0.935 0.927 | 21.65 21.67 | 754 743 |
| Early Fusion | L/R Cam L/R Cam + LiDAR L/R Cam + LiDAR + RADAR | 1.194 1.356 1.627 | 27.23 30.12 34.25 | 756 743 728 |
| Late Fusion | L/R Cam L/R Cam + LiDAR L/R Cam + LiDAR + RADAR | 1.856 2.726 3.649 | 42.66 61.78 82.25 | 924 1023 1139 |
| Proposed Fusion | 3-Branch (ResNet + RCNN) 5-Branch (ResNet + RCNN) 7-Branch (ResNet + RCNN) | 3.345 5.006 6.476 | 72.15 100.26 120.56 | 1261 1362 1465 |
| Fusion Method | Configuration | mAP (%) |
|---|---|---|
| None | Single Camera Radar LiDAR | 67.21 67.50 67.58 |
| Early Fusion | L/R Cam Radar + LiDAR Camera + LiDAR | 69.23 69.45 69.55 |
| Late Fusion | L/R Cameras Radar + LiDAR L/R Cameras + LiDAR Radar + LiDAR + L/R Cameras | 71.25 71.43 71.23 71.00 |
| Proposed Fusion | 3-Branch (ResNet + RCNN) 5-Branch (ResNet + RCNN) 7-Branch (ResNet + RCNN) | 74.32 79.34 82.31 |
| Fusion Method | Configuration | (Proposed) | (Other Work [31]) | ||||
|---|---|---|---|---|---|---|---|
| Energy (J) | Latency (ms) | Memory (MB) | Energy (J) | Latency (ms) | Memory (MB) | ||
| None | Radar or LiDAR Single Cam | 0.935 0.927 | 21.65 21.67 | 754 743 | 0.954 0.945 | 21.85 21.57 | 769 767 |
| Early Fusion | L/R Cam L/R Cam + LiDAR L/R Cam + LiDAR + RADAR | 1.194 1.356 1.627 | 27.23 30.12 34.25 | 756 643 728 | 1.192 1.379 1.615 | 27.36 31.36 36.86 | 768 694 750 |
| Late Fusion | L/R Cam L/R Cam + LiDAR L/R Cam + LiDAR + RADAR | 1.856 2.726 3.649 | 42.66 61.78 82.25 | 924 1023 1139 | 1.959 2.878 3.769 | 43.99 64.09 84.32 | 923 1087 1239 |
| Proposed Fusion | 3-Branch (ResNet + RCNN) | 3.245 | 72.15 | 1001 | 3.317 | 73.84 | 1080 |
| Fusion Method | Configuration | Proposed Fusion | (Other Work [31]) |
|---|---|---|---|
| mAP (%) | mAP (%) | ||
| None | Single Camera Radar LiDAR | 67.41 67.21 67.58 | 65.33 69.42 61.86 |
| Early Fusion | L/R Cam Radar + LiDAR Camera + LiDAR | 69.25 69.45 69.55 | 65.33 71.63 65.99 |
| Late Fusion | L/R Cameras Radar + LiDAR L/R Cameras + LiDAR Radar + LiDAR + L/R Cameras | 70.25 71.43 71.23 71.00 | 65.71 65.33 66.20 71.16 |
| Proposed Fusion | 3-Branch (ResNet + RCNN) 5-Branch (ResNet + RCNN) 7-Branch (ResNet + RCNN) | 74.32 79.32 82.31 | 74.54 78.51 81.31 |
| Metric Name | Purpose |
|---|---|
| Accuracy (Acc) | To compare accuracy |
| Efficiency (Eff) | To evaluate the performance of the models |
| Standard Deviation (SD) | To estimate the contrast |
| Average Gradient (AG) | To express small detail contrast and texture changes, as well as the sharpness of the image |
| Spatial Frequency (SF) | To measure the overall activity level of the image |
| Peak Signal to Noise Ratio (PSNR) | To compute the visual error between the fused image and the reference Image |
| Correlation Coefficient (CC) | To find the similarity between the reference image and the fused image |
| Images | Model | SD | AG | SF | PSNR | CC |
|---|---|---|---|---|---|---|
| 1 | GS | 305.3385 | 9.4444 | 60.0375 | 89.6709 | 0.6908 |
| HIS | 363.5207 | 9.5403 | 133.8691 | 95.5200 | 0.7078 | |
| Subtractive | 375.7824 | 9.4150 | 133.5344 | 94.5325 | 0.7107 | |
| Proposed | 380.298 | 10.2148 | 135.6382 | 96.2867 | 0.9472 | |
| 2 | GS | 289.3498 | 9.6105 | 78.5329 | 90.0781 | 0.6040 |
| HIS | 325.7555 | 9.7290 | 177.7829 | 93.0075 | 0.6077 | |
| Subtractive | 339.9461 | 10.4368 | 178.6462 | 93.0360 | 0.6360 | |
| Proposed | 365.4752 | 11.4976 | 180.5643 | 94.2335 | 0.8235 | |
| 3 | GS | 625.3025 | 10.5363 | 131.9687 | 114.0561 | 0.7434 |
| HIS | 646.8171 | 10.8526 | 132.6416 | 95.5631 | 0.7313 | |
| Subtractive | 657.6024 | 9.9434 | 120.6161 | 95.6224 | 0.7344 | |
| Proposed | 370.2539 | 11.3145 | 123.6213 | 93.25 | 0.6543 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ignatious, H.A.; El-Sayed, H.; Kulkarni, P. Multilevel Data and Decision Fusion Using Heterogeneous Sensory Data for Autonomous Vehicles. Remote Sens. 2023, 15, 2256. https://doi.org/10.3390/rs15092256
Ignatious HA, El-Sayed H, Kulkarni P. Multilevel Data and Decision Fusion Using Heterogeneous Sensory Data for Autonomous Vehicles. Remote Sensing. 2023; 15(9):2256. https://doi.org/10.3390/rs15092256
Chicago/Turabian StyleIgnatious, Henry Alexander, Hesham El-Sayed, and Parag Kulkarni. 2023. "Multilevel Data and Decision Fusion Using Heterogeneous Sensory Data for Autonomous Vehicles" Remote Sensing 15, no. 9: 2256. https://doi.org/10.3390/rs15092256
APA StyleIgnatious, H. A., El-Sayed, H., & Kulkarni, P. (2023). Multilevel Data and Decision Fusion Using Heterogeneous Sensory Data for Autonomous Vehicles. Remote Sensing, 15(9), 2256. https://doi.org/10.3390/rs15092256