
SSGAM-Net: A Hybrid Semi-Supervised and Supervised Network for Robust Semantic Segmentation Based on Drone LiDAR Data



Abstract
:1. Introduction
- This study proposes a plug-and-play module, named GAM, which utilizes few samples to generate the pseudo-labels for guiding the network to learn complex global contextual relationships within noisy point clouds, so as to improve the anti-noise performance of our method.
- Based on the GAM module, we construct a novel loss function that augments the network’s ability to perceive global contextual relationships in noisy true-color point clouds, thus solving the issue of distorted geometric structure and color information shift.
- We build an airborne true-color point cloud dataset with precise annotations for 3D semantic learning.
- We present a novel hybrid learning-based network for semantic segmentation of noisy true-color point clouds, which integrates the GAM module and Encoder–Decoder Module to improve the segmentation performance.
2. Related Work
2.1. Accuracy Assessment
2.2. Point Cloud Semantic Segmentation
2.2.1. Projection-Based Methods
2.2.2. Voxel-Based Methods
2.2.3. Point-Wise MLP Methods
2.2.4. Point Convolution Methods
2.3. Point Cloud Datasets
3. Methodology
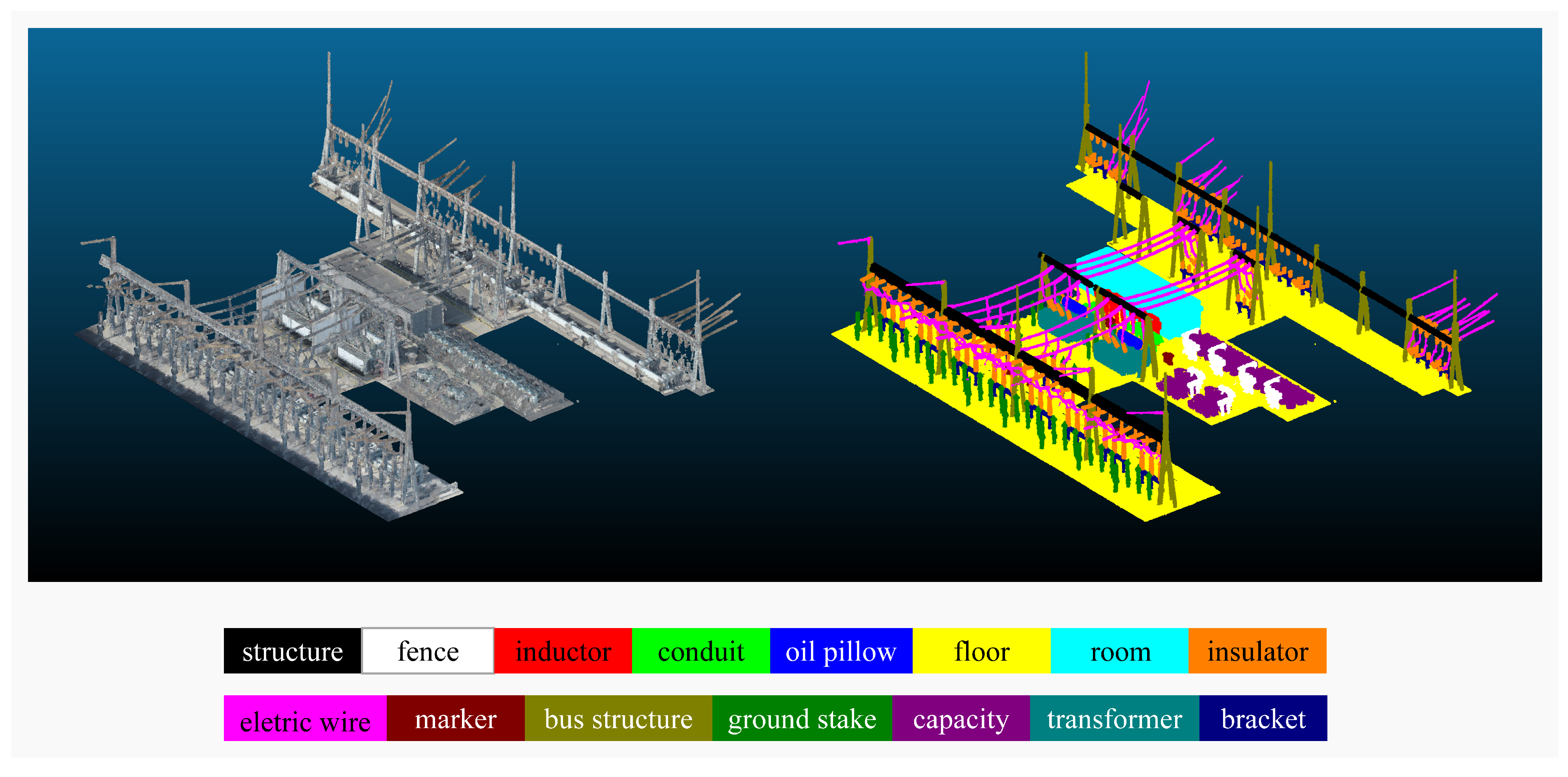
3.1. Building an Airborne True-Color Point Cloud Dataset
3.1.1. Data Collection and Processing
3.1.2. Data Annotation
- Spatial Decomposition: we partition each scene into subregions to eliminate irrelevant surrounding objects near the substations, thereby improving processing efficiency.
- Object extraction: substation experts used the advanced point cloud processing software, CloudCompare, to manually extract individual objects within each subregion according to their functional attributes. Subsequently, these segmented objects were stored as distinct files.
- Data quality check: The annotation results are checked by human experts to ensure the high quality and consistency of the annotation of the point cloud data.
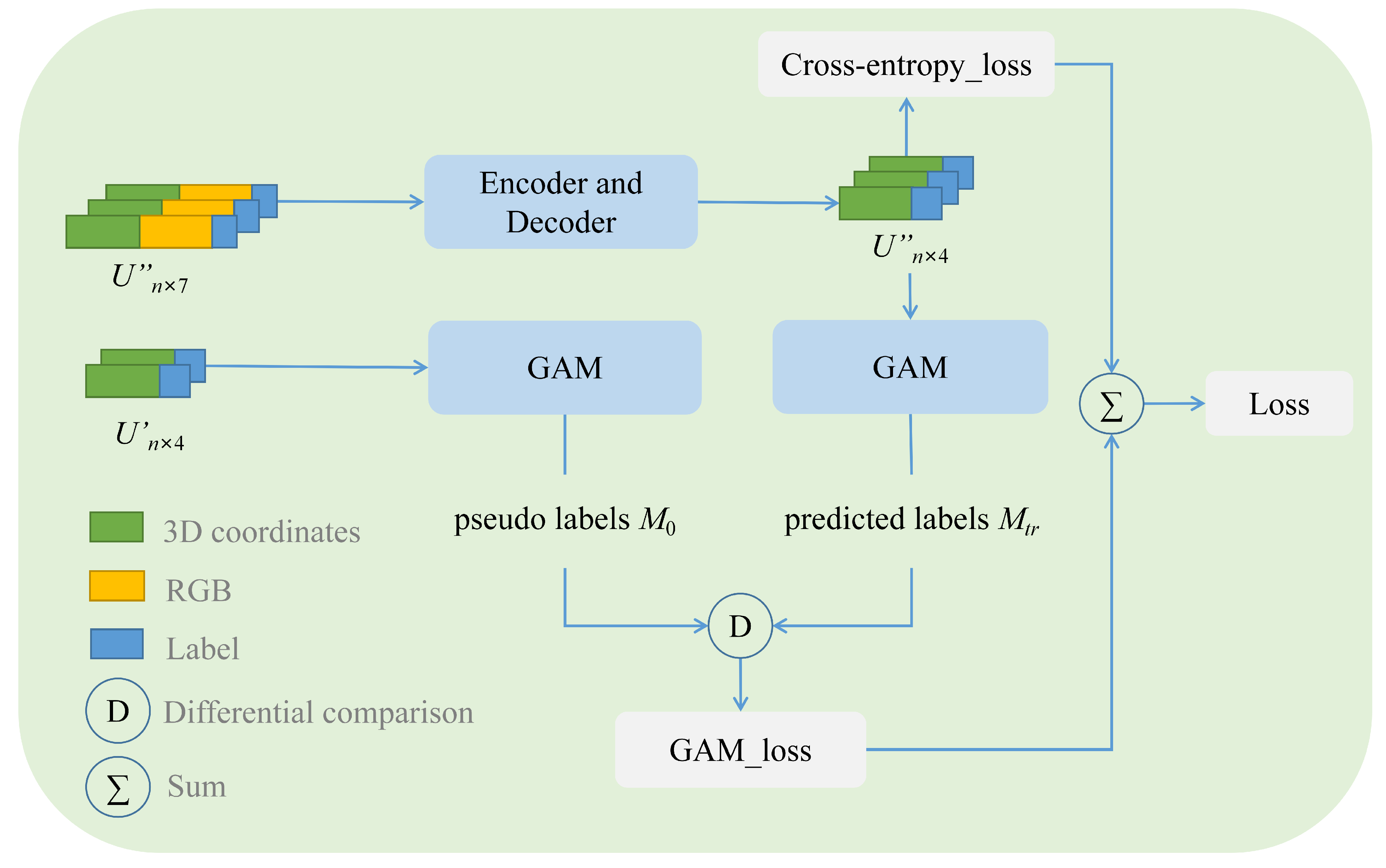
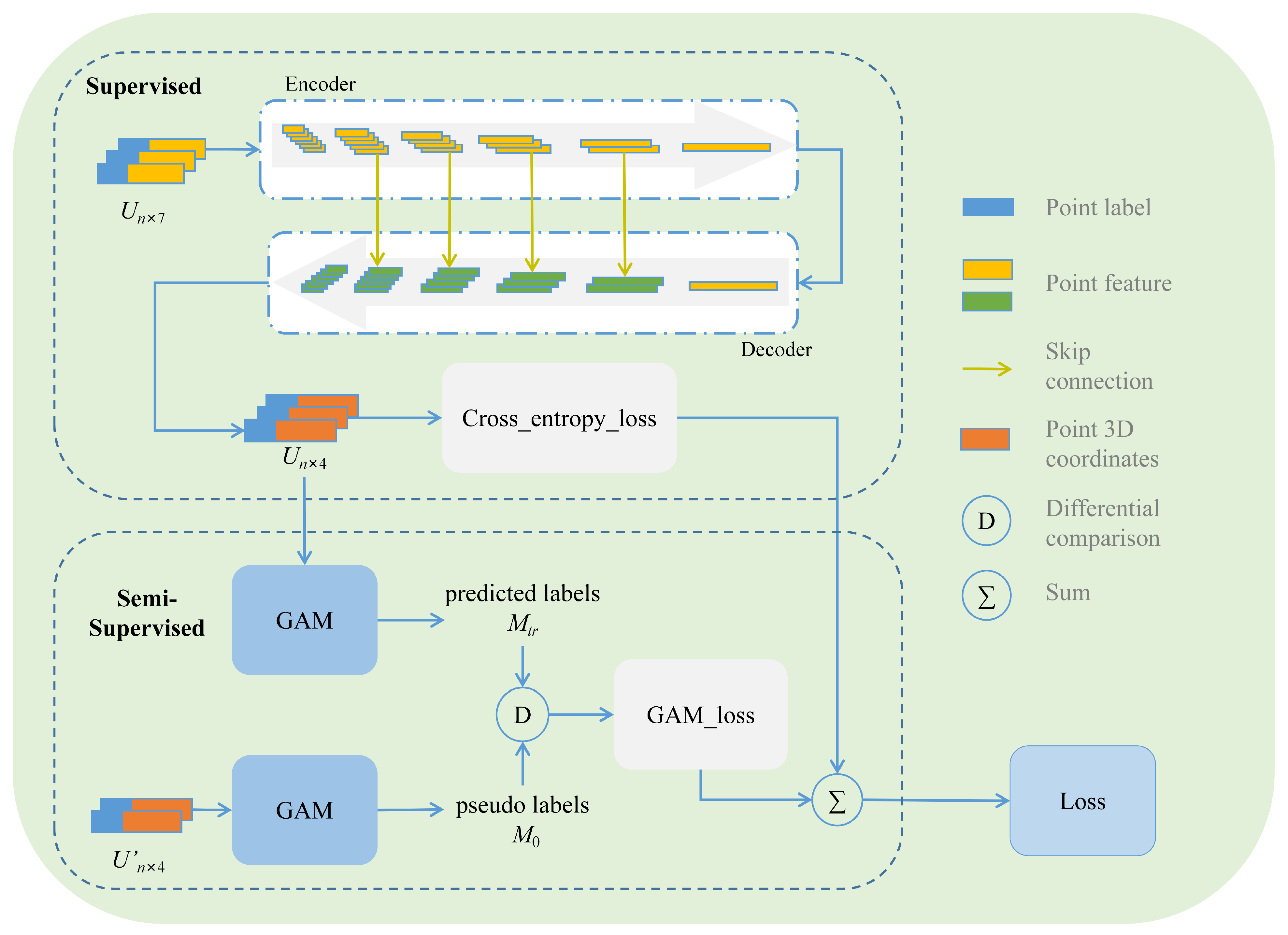
3.2. Proposed Novel SSGAM-Net
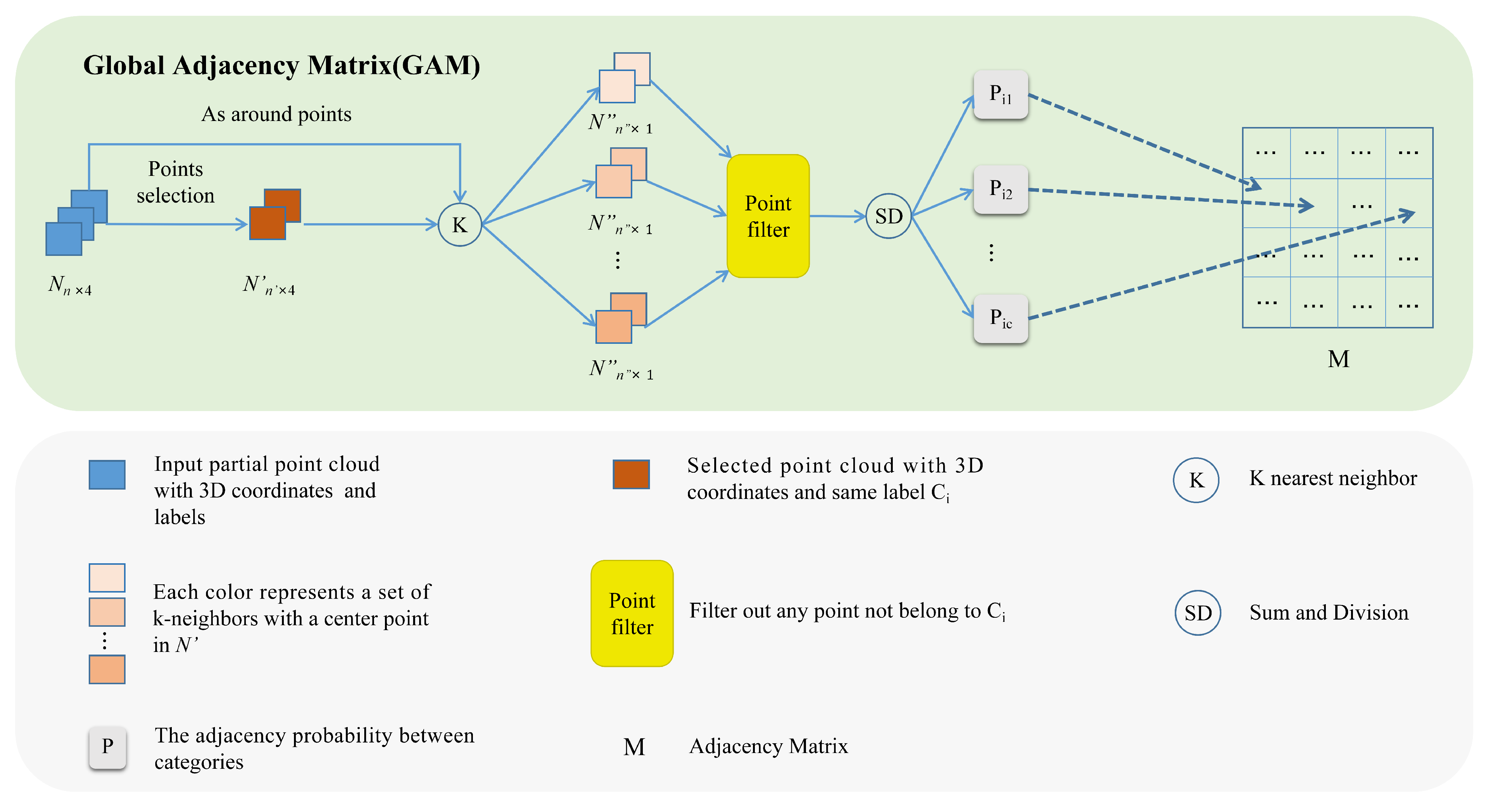
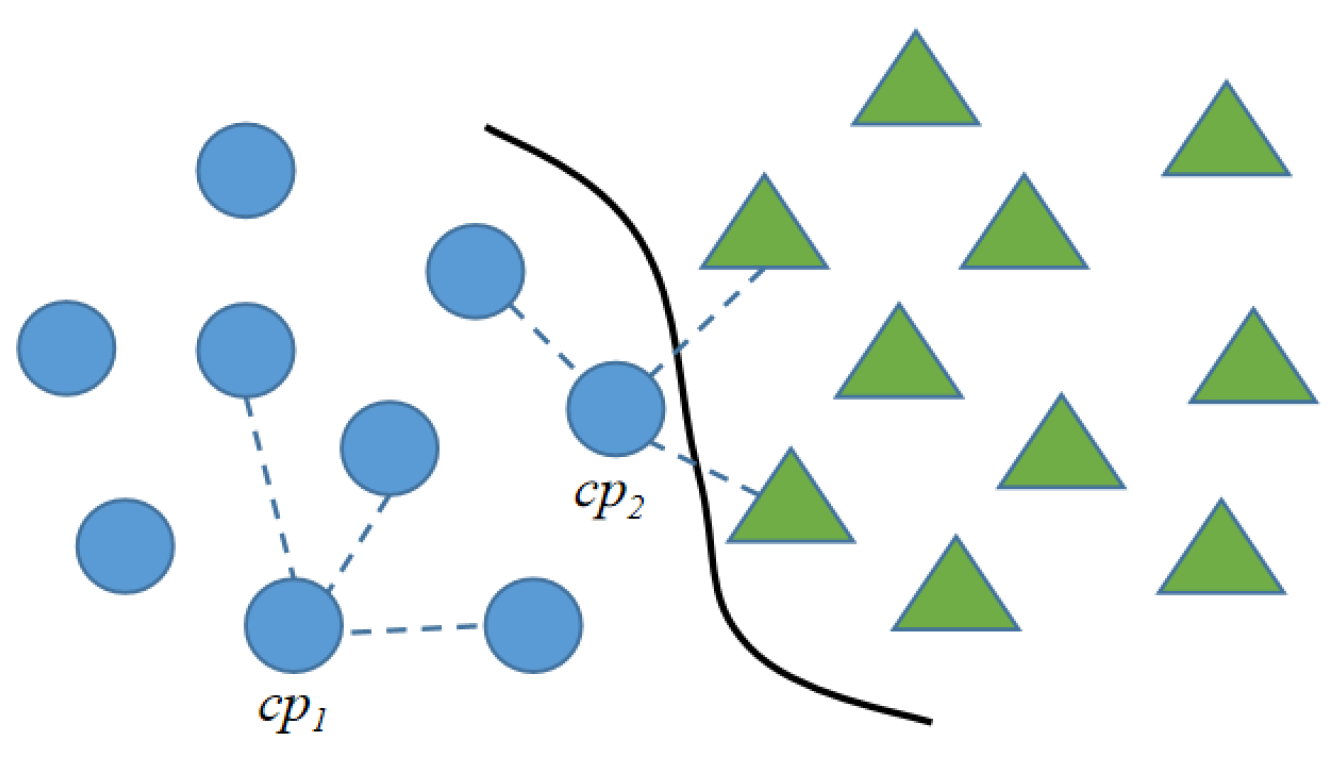
3.2.1. Semi-Supervised GAM Module
3.2.2. Network Architecture
4. Experiments
4.1. Evaluation Metrics and Experimental Settings
4.2. Experimental Settings and Environment
4.3. Experimental Results
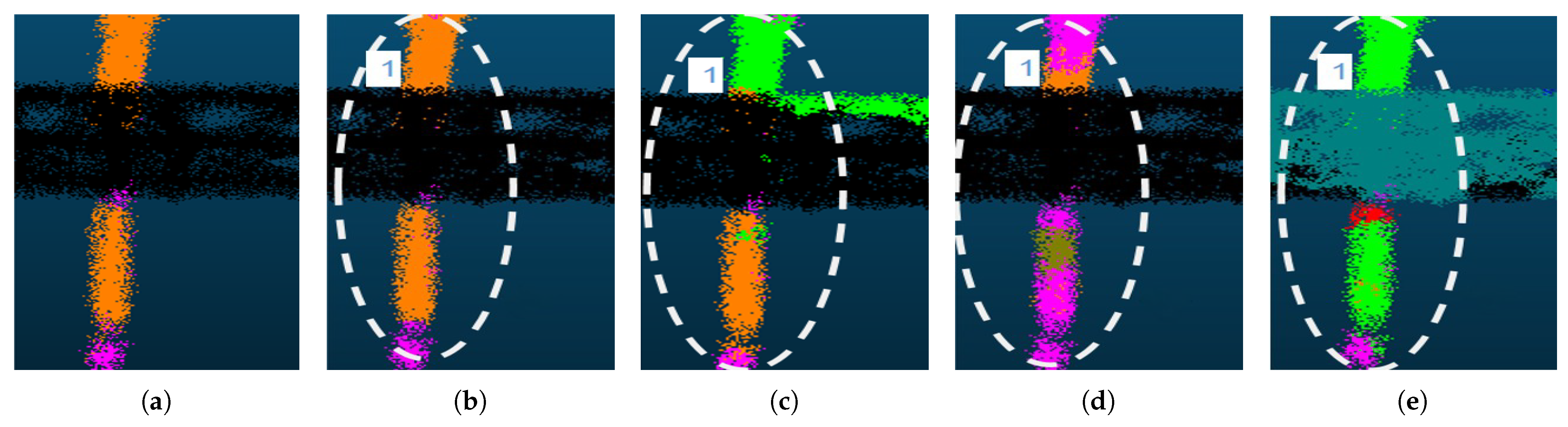
4.3.1. Comparison with Other Methods
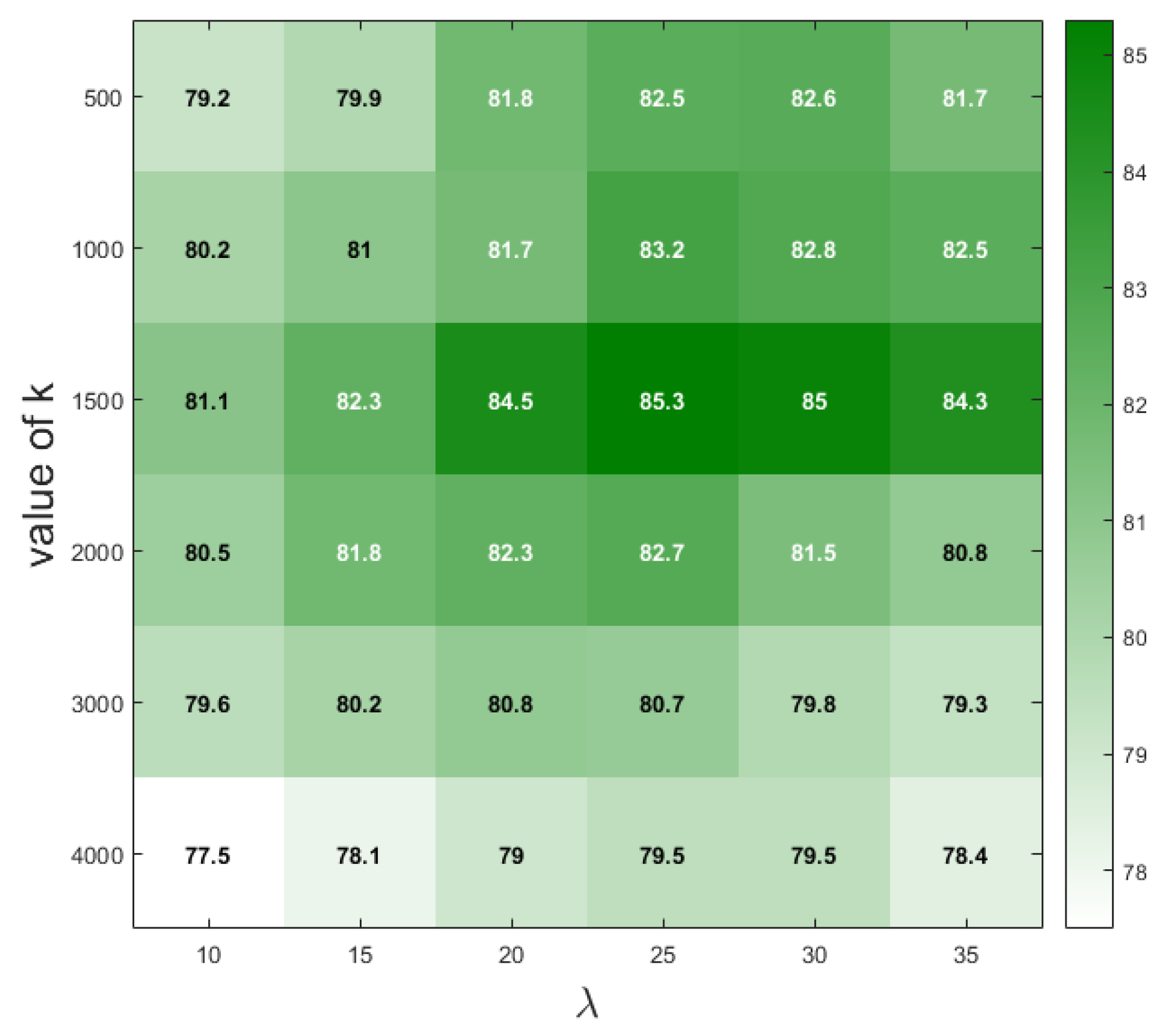
4.3.2. Hyperparameter Selection
4.3.3. Computational Cost Comparison
5. Conclusions and Outlook
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, J.; Sun, Z.; Sun, J. 3-DFineRec: Fine-Grained Recognition for Small-Scale Objects in 3-D Point Cloud Scenes. IEEE Trans. Instrum. Meas. 2021, 71, 5000312. [Google Scholar] [CrossRef]
- Qi, C.; Yin, J. Multigranularity Semantic Labeling of Point Clouds for the Measurement of the Rail Tanker Component with Structure Modeling. IEEE Trans. Instrum. Meas. 2020, 70, 5000312. [Google Scholar] [CrossRef]
- Yuan, Q.; Luo, Y.; Wang, H. 3D point cloud recognition of substation equipment based on plane detection. Results Eng. 2022, 15, 100545. [Google Scholar] [CrossRef]
- Shen, X.; Xu, Z.; Wang, M. An Intelligent Point Cloud Recognition Method for Substation Equipment Based on Multiscale Self-Attention. IEEE Trans. Instrum. Meas. 2023, 72, 2528912. [Google Scholar] [CrossRef]
- Arastounia, M.; Lichti, D.D. Automatic Object Extraction from Electrical Substation Point Clouds. Remote Sens. 2015, 7, 15605–15629. [Google Scholar] [CrossRef]
- Wu, Q.; Yang, H.; Wei, M.; Remil, O.; Wang, B.; Wang, J. Automatic 3D reconstruction of electrical substation scene from LiDAR point cloud. ISPRS J. Photogramm. Remote Sens. 2018, 143, 57–71. [Google Scholar] [CrossRef]
- Jeong, S.; Kim, D.; Kim, S.; Ham, J.W.; Lee, J.K.; Oh, K.Y. Real-Time Environmental Cognition and Sag Estimation of Transmission Lines Using UAV Equipped With 3-D Lidar System. IEEE Trans. Power Deliv. 2020, 36, 2658–2667. [Google Scholar] [CrossRef]
- Chakravarthy, A.S.; Sinha, S.; Narang, P.; Mandal, M.; Chamola, V.; Yu, F.R. DroneSegNet: Robust Aerial Semantic Segmentation for UAV-Based IoT Applications. IEEE Trans. Veh. Technol. 2022, 71, 4277–4286. [Google Scholar] [CrossRef]
- Pepe, M.; Alfio, V.S.; Costantino, D.; Scaringi, D. Data for 3D reconstruction and point cloud classification using machine learning in cultural heritage environment. Data Brief 2022, 42, 108250. [Google Scholar] [CrossRef]
- Romero-Jarén, R.; Arranz, J. Automatic segmentation and classification of BIM elements from point clouds. Autom. Constr. 2021, 124, 103576. [Google Scholar] [CrossRef]
- Ma, J.W.; Czerniawski, T.; Leite, F. Semantic segmentation of point clouds of building interiors with deep learning: Augmenting training datasets with synthetic BIM-based point clouds. Autom. Constr. 2020, 113, 103144. [Google Scholar] [CrossRef]
- Gao, H.; Koch, C.; Wu, Y. Building information modelling based building energy modelling: A review. Appl. Energy 2019, 238, 320–343. [Google Scholar] [CrossRef]
- Štroner, M.; Urban, R.; Línková, L. A New Method for UAV Lidar Precision Testing Used for the Evaluation of an Affordable DJI ZENMUSE L1 Scanner. Remote Sens. 2021, 13, 4811. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep Learning for 3D Point Clouds: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4338–4364. [Google Scholar] [CrossRef]
- Diara, F.; Roggero, M. Quality Assessment of DJI Zenmuse L1 and P1 LiDAR and Photogrammetric Systems: Metric and Statistics Analysis with the Integration of Trimble SX10 Data. Geomatics 2022, 2, 254–281. [Google Scholar] [CrossRef]
- Zhang, J.; Lin, X.; Ning, X. SVM-Based Classification of Segmented Airborne LiDAR Point Clouds in Urban Areas. Remote Sens. 2013, 5, 3749–3775. [Google Scholar] [CrossRef]
- Grandio, J.; Riveiro, B.; Soilán, M.; Arias, P. Point cloud semantic segmentation of complex railway environments using deep learning. Autom. Constr. 2022, 141, 104425. [Google Scholar] [CrossRef]
- Xia, T.; Yang, J.; Chen, L. Automated semantic segmentation of bridge point cloud based on local descriptor and machine learning. Autom. Constr. 2022, 133, 103992. [Google Scholar] [CrossRef]
- Xia, X.; Meng, Z.; Han, X.; Li, H.; Tsukiji, T.; Xu, R.; Zheng, Z.; Ma, J. An automated driving systems data acquisition and analytics platform. Transp. Res. Part C Emerg. Technol. 2023, 151, 104120. [Google Scholar] [CrossRef]
- Meng, Z.; Xia, X.; Xu, R.; Liu, W.; Ma, J. HYDRO-3D: Hybrid Object Detection and Tracking for Cooperative Perception Using 3D LiDAR. IEEE Trans. Intell. Veh. 2023, 8, 4069–4080. [Google Scholar] [CrossRef]
- Zhou, Y.; Ji, A.; Zhang, L.; Xue, X. Sampling-attention deep learning network with transfer learning for large-scale urban point cloud semantic segmentation. Eng. Appl. Artif. Intell. 2023, 117, 105554. [Google Scholar] [CrossRef]
- Liu, C.; Zeng, D.; Akbar, A.; Wu, H.; Jia, S.; Xu, Z.; Yue, H. Context-aware network for semantic segmentation toward large-scale point clouds in urban environments. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Tatarchenko, M.; Park, J.; Koltun, V.; Zhou, Q.Y. Tangent Convolutions for Dense Prediction in 3D. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 3887–3896. [Google Scholar]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. Squeezesegv2: Improved Model Structure and Unsupervised Domain Adaptation for Road-Object Segmentation from a LiDAR Point Cloud. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4376–4382. [Google Scholar]
- Zhang, Y.; Zhou, Z.; David, P.; Yue, X.; Xi, Z.; Gong, B.; Foroosh, H. PolarNet: An Improved Grid Representation for Online LiDAR Point Clouds Semantic Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 9601–9610. [Google Scholar]
- Razani, R.; Cheng, R.; Taghavi, E.; Bingbing, L. Lite-HDSeg: LiDAR Semantic Segmentation Using Lite Harmonic Dense Convolutions. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, SX, China, 30 May–5 June 2021; pp. 9550–9556. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. RangeNet++: Fast and Accurate LiDAR Semantic Segmentation. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4213–4220. [Google Scholar]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar]
- Riegler, G.; Osman Ulusoy, A.; Geiger, A. OctNet: Learning Deep 3D Representations at High Resolutions. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3577–3586. [Google Scholar]
- Meng, H.Y.; Gao, L.; Lai, Y.K.; Manocha, D. VV-Net: Voxel VAE Net With Group Convolutions for Point Cloud Segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8500–8508. [Google Scholar]
- Liu, Z.; Tang, H.; Lin, Y.; Han, S. Point-Voxel CNN for Efficient 3D Deep Learning. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Zhao, H.; Jiang, L.; Fu, C.W.; Jia, J. PointWeb: Enhancing Local Neighborhood Features for Point Cloud Processing. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5565–5573. [Google Scholar]
- Zhang, Z.; Hua, B.S.; Yeung, S.K. ShellNet: Efficient Point Cloud Convolutional Neural Networks Using Concentric Shells Statistics. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1607–1616. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 11105–11114. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution On X-Transformed Points. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Komarichev, A.; Zhong, Z.; Hua, J. A-CNN: Annularly Convolutional Neural Networks on Point Clouds. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 7421–7430. [Google Scholar]
- Wang, S.; Suo, S.; Ma, W.C.; Pokrovsky, A.; Urtasun, R. Deep Parametric Continuous Convolutional Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2589–2597. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L. KPConv: Flexible and Deformable Convolution for Point Clouds. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6410–6419. [Google Scholar]
- Zeng, T.; Luo, F.; Guo, T.; Gong, X.; Xue, J.; Li, H. Recurrent Residual Dual Attention Network for Airborne Laser Scanning Point Cloud Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5702614. [Google Scholar] [CrossRef]
- Lin, Y.; Vosselman, G.; Cao, Y.; Yang, M.Y. Local and global encoder network for semantic segmentation of Airborne laser scanning point clouds. ISPRS J. Photogramm. Remote Sens. 2021, 176, 151–168. [Google Scholar] [CrossRef]
- Liu, W.; Quijano, K.; Crawford, M.M. YOLOv5-Tassel: Detecting Tassels in RGB UAV Imagery With Improved YOLOv5 Based on Transfer Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8085–8094. [Google Scholar] [CrossRef]
- Dharmadasa, V.; Kinnard, C.; Baraër, M. An Accuracy Assessment of Snow Depth Measurements in Agro-forested Environments by UAV Lidar. Remote Sens. 2022, 14, 1649. [Google Scholar] [CrossRef]
- Kim, M.; Stoker, J.; Irwin, J.; Danielson, J.; Park, S. Absolute Accuracy Assessment of Lidar Point Cloud Using Amorphous Objects. Remote Sens. 2022, 14, 4767. [Google Scholar] [CrossRef]
- Qiu, S.; Anwar, S.; Barnes, N. Semantic Segmentation for Real Point Cloud Scenes via Bilateral Augmentation and Adaptive Fusion. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 1757–1767. [Google Scholar]
- Wu, W.; Qi, Z.; Fuxin, L. PointConv: Deep Convolutional Networks on 3D Point Clouds. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 9613–9622. [Google Scholar]
- Mao, J.; Wang, X.; Li, H. Interpolated Convolutional Networks for 3D Point Cloud Understanding. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1578–1587. [Google Scholar]
- Armeni, I.; Sax, S.; Zamir, A.R.; Savarese, S. Joint 2D-3D-Semantic Data for Indoor Scene Understanding. arXiv 2017, arXiv:1702.01105. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. ScanNet: Richly-Annotated 3D Reconstructions of Indoor Scenes. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2432–2443. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D ShapeNets: A Deep Representation for Volumetric Shapes. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9296–9306. [Google Scholar]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. Semantic3D.net: A new Large-scale Point Cloud Classification Benchmark. arXiv 2017, arXiv:1704.03847. [Google Scholar] [CrossRef]
- Wang, Q.; Kim, M.K. Applications of 3D point cloud data in the construction industry: A fifteen-year review from 2004 to 2018. Adv. Eng. Inform. 2019, 39, 306–319. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Structure | Fence | Inductor | Conduit | Oil Pillow | Floor | Room | Insulator | Electric Wire | Marker | Bus Structure | Ground Stake | Capacitor | Transformer | Bracket | Total | Total* |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 24.0 M | 5.2 M | 25.1 M | 14.6 M | 0.5 M | 142.5 M | 11.9 M | 13.9 M | 15.0 M | 1.1 M | 26.1 M | 8.0 M | 2.9 M | 21.6 M | 24.7 M | 337.1 M | 900.0 M |
| Methods | OA (%) | mIoU (%) | Structure | Fence | Inductor | Conduit | Oil Pillow | Floor | Room | Insulator | Electric Wire | Marker | Bus Structure | Ground Stake | Capacitor | Transformer | Bracket |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointNet [32] | 73.1 | 27.3 | 71.7 | 0.0 | 0.0 | 5.1 | 60.6 | 92.2 | 34.2 | 10.1 | 29.2 | 0.1 | 67.6 | 19.6 | 0.0 | 18.5 | 0.1 |
| PointNet++ [33] | 77.3 | 30.9 | 60.4 | 5.8 | 0.0 | 0.0 | 27.8 | 93.4 | 58.4 | 22.2 | 45.9 | 0.2 | 37.9 | 29.2 | 31.5 | 33.0 | 17.3 |
| RandLA-Net [36] | 91.9 | 71.7 | 69.8 | 56.1 | 73.7 | 17.8 | 98.8 | 98.1 | 87.9 | 60.7 | 71.0 | 92.0 | 77.3 | 49.3 | 82.7 | 71.7 | 68.9 |
| BAAF-Net [46] | 90.7 | 70.2 | 60.4 | 59.3 | 65.3 | 20.8 | 99.1 | 96.5 | 73.0 | 65.2 | 73.5 | 91.4 | 81.7 | 44.8 | 77.8 | 64.2 | 80.3 |
| KPConv [40] | 95.5 | 81.1 | 95.6 | 90.4 | 70.0 | 62.9 | 99.5 | 98.9 | 91.4 | 69.9 | 76.6 | 86.5 | 84.1 | 46.4 | 90.5 | 81.9 | 71.3 |
| RRDAN [41] | 94.6 | 77.5 | 91.7 | 86.1 | 76.2 | 60.0 | 97.6 | 99.4 | 98.9 | 51.6 | 43.5 | 63.9 | 85.9 | 40.8 | 96.2 | 96.5 | 76.4 |
| SSGAM-Net (Ours) | 96.9 | 85.3 | 96.9 | 92.2 | 74.4 | 75.6 | 99.6 | 99.5 | 93.8 | 74.2 | 72.8 | 90.7 | 86.9 | 54.1 | 97.3 | 86.8 | 84.1 |
| Model | Total Time (s per Epoch) | GPU Memory Cost (MB) |
|---|---|---|
| PointNet [32] | 102 | 5382 |
| PointNet++ [33] | 5182 | 6344 |
| KPConv [40] | 378 | 8663 |
| RandLA-Net [36] | 98 | 23,282 |
| BAAF-Net [46] | 293 | 27,175 |
| RRDAN [41] | 425 | 10,867 |
| SSGAM-Net (Ours) | 641 | 8805 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, H.; Huang, Z.; Zheng, W.; Bai, X.; Sun, L.; Pu, M. SSGAM-Net: A Hybrid Semi-Supervised and Supervised Network for Robust Semantic Segmentation Based on Drone LiDAR Data. Remote Sens. 2024, 16, 92. https://doi.org/10.3390/rs16010092
Wu H, Huang Z, Zheng W, Bai X, Sun L, Pu M. SSGAM-Net: A Hybrid Semi-Supervised and Supervised Network for Robust Semantic Segmentation Based on Drone LiDAR Data. Remote Sensing. 2024; 16(1):92. https://doi.org/10.3390/rs16010092
Chicago/Turabian StyleWu, Hua, Zhe Huang, Wanhao Zheng, Xiaojing Bai, Li Sun, and Mengyang Pu. 2024. "SSGAM-Net: A Hybrid Semi-Supervised and Supervised Network for Robust Semantic Segmentation Based on Drone LiDAR Data" Remote Sensing 16, no. 1: 92. https://doi.org/10.3390/rs16010092
APA StyleWu, H., Huang, Z., Zheng, W., Bai, X., Sun, L., & Pu, M. (2024). SSGAM-Net: A Hybrid Semi-Supervised and Supervised Network for Robust Semantic Segmentation Based on Drone LiDAR Data. Remote Sensing, 16(1), 92. https://doi.org/10.3390/rs16010092