DAMF-Net: Unsupervised Domain-Adaptive Multimodal Feature Fusion Method for Partial Point Cloud Registration


Abstract
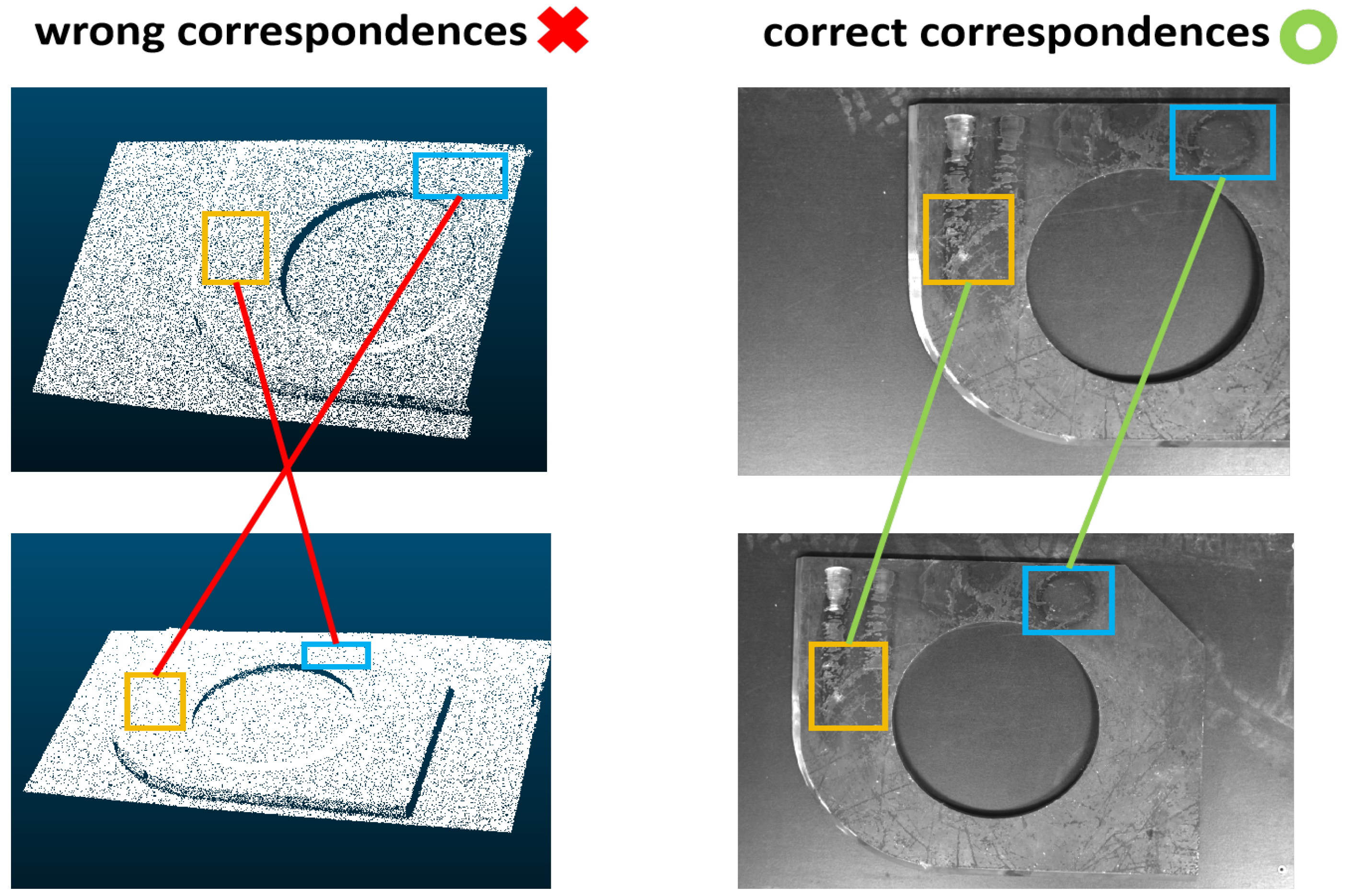
1. Introduction
2. Related Work
2.1. Point Cloud Registration
2.2. Multimodal Feature Fusion
2.3. Domain Adaptation on Point Cloud
3. Methods
3.1. Point-Guided Two-Stage Multimodal Feature Fusion Module
3.1.1. Initial Fusion Stage
3.1.2. Complementary Fusion Stage
3.2. Gradient-Inverse Domain-Aware Module
- Forward propagationDuring forward propagation, the GIL acts as a constant mapping, i.e., the input is directly equal to the output without any transformation. We denote the GIL function and its input vector as f and x, respectively. The forward propagation can be expressed as
- Backward propagationDuring backpropagation, the GIL multiplies the gradient by a negative value (i.e., gradient inverse). We denote the parameter of the GIDA module and its loss function as , respectively. The backward propagation can be expressed aswhere denotes learning rate.
3.3. Correspondence Estimation and Geometric Fitting
3.4. Loss Function
3.4.1. Registration Loss
3.4.2. Domain Adaptation Loss
4. Experiments
4.1. Datasets and Implementation Details
4.2. Compared Methods and Evaluation Metrics
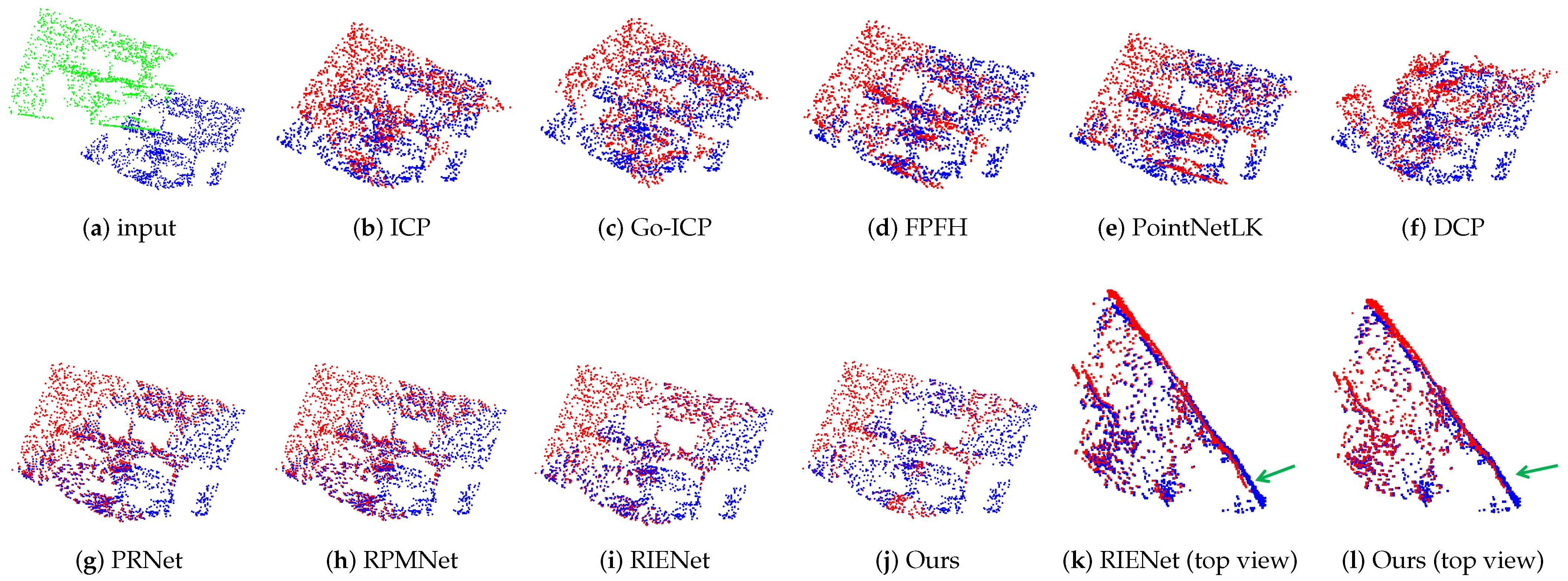
4.3. Comparative Evaluation
4.4. Ablation Experiments
4.4.1. The Effectiveness of Key Components
4.4.2. Combination of Different Point Cloud and Image Backbones
4.4.3. The Effectiveness of Fusion Style in Two-Stage Feature Fusion
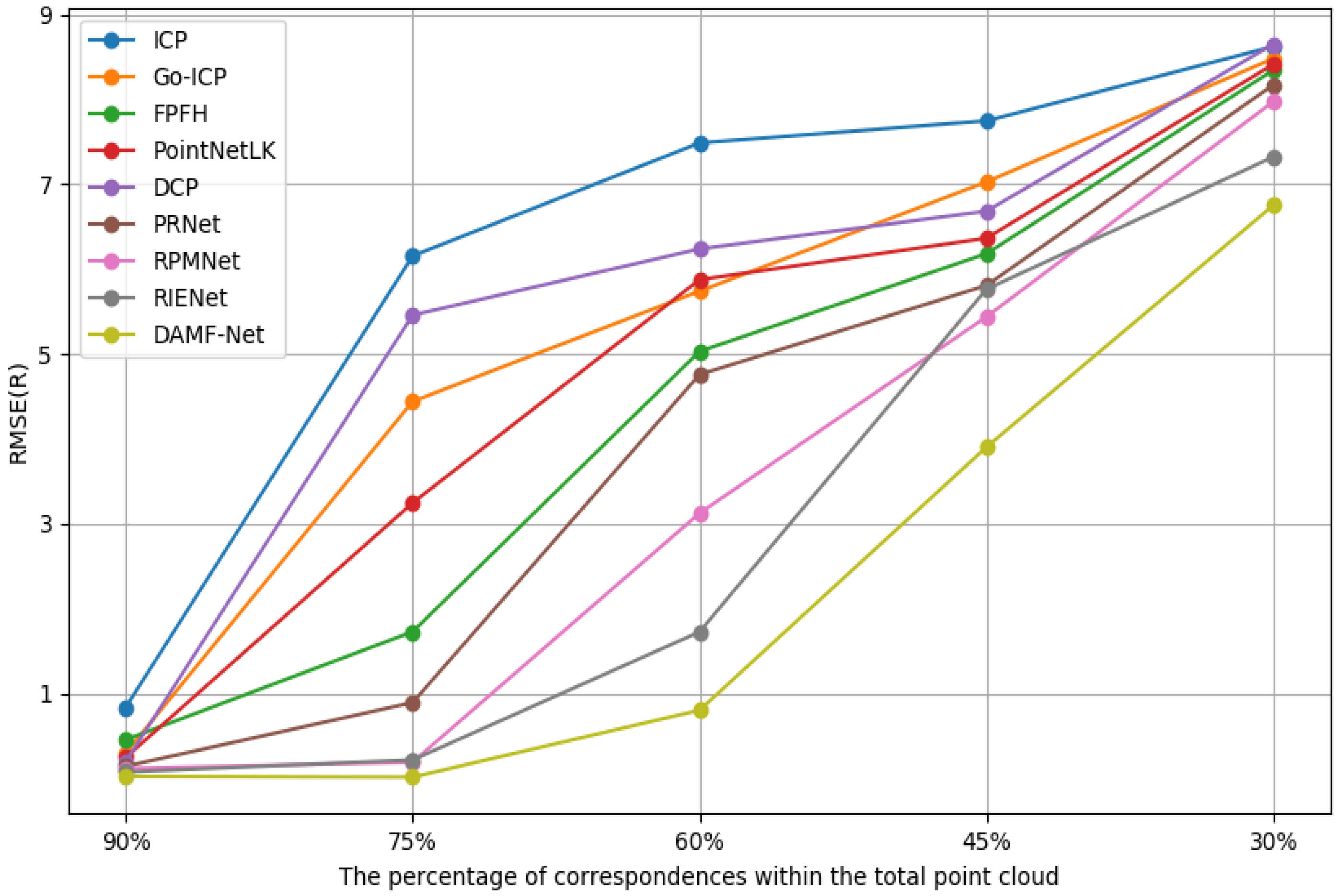
4.4.4. Ablation Study on the Number of Correspondences
4.4.5. Ablation Study on the Robustness to Noise
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| 3D | Three dimensional |
| RGB-D | Red green blue-depth |
| RMSE | Root mean square error |
| PFH | Point feature histogram |
| FPFH | Fast point feature histogram |
| SVD | Singular value decomposition |
| CNN | Convolutional neural network |
| 2D | Two dimensional |
| BEV | Bird’s eye view |
| MLP | Multilayer perceptron |
| ADAM | Adaptive moment estimation |
References
- Tulbure, A.; Dulf, E. A review on modern defect detection models using DCNNs—Deep convolutional neural networks. J. Adv. Res. 2022, 35, 33–48. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Dai, Y.; Sun, J. Deep learning based point cloud registration: An overview. Virtual Real. Intell. Hardw. 2020, 2, 222–246. [Google Scholar] [CrossRef]
- Aoki, Y.; Goforth, H.; Srivatsan, R.A.; Lucey, S. Pointnetlk: Robust & efficient point cloud registration using pointnet. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7163–7172. [Google Scholar]
- Li, X.; Wang, L.; Fang, Y. Unsupervised category-specific partial point set registration via joint shape completion and registration. IEEE Trans. Vis. Comput. Graph. 2023, 29, 3251–3265. [Google Scholar] [CrossRef]
- Afham, M.; Dissanayake, I.; Dissanayake, D.; Dharmasiri, A.; Thilakarathna, K.; Rodrigo, R. Crosspoint: Self-supervised cross-modal contrastive learning for 3d point cloud understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 9902–9912. [Google Scholar]
- Shen, Y.; Hui, L.; Jiang, H.; Xie, J.; Yang, J. Reliable inlier evaluation for unsupervised point cloud registration. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; pp. 2198–2206. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Zeng, A.; Song, S.; Nießner, M.; Fisher, M.; Xiao, J.; Funkhouser, T. 3DMatch: Learning local geometric descriptors from RGB-D reconstructions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1802–1811. [Google Scholar]
- Besl, P.J.; McKay, N.D. Method for registration of 3-D shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Yang, J.; Li, H.; Campbell, D.; Jia, Y. Go-ICP: A globally optimal solution to 3D ICP point-set registration. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2241–2254. [Google Scholar] [CrossRef] [PubMed]
- Rusu, R.B.; Blodow, N.; Marton, Z.C.; Beetz, M. Aligning point cloud views using persistent feature histograms. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008; pp. 3384–3391. [Google Scholar]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast point feature histograms (FPFH) for 3D registration. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 3212–3217. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Lucas, B.D.; Kanade, T. An iterative image registration technique with an application to stereo vision. In Proceedings of the 7th International Joint Conference on Artificial Intelligence, Vancouver, BC, Canada, 24–28 August 1981; pp. 674–679. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Wang, Y.; Solomon, J.M. Deep closest point: Learning representations for point cloud registration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3523–3532. [Google Scholar]
- Eckart, C.; Young, G. Approximation by superpositions of a given matrix and its transpose. Math. Control. Signals Syst. 1989, 2, 303–314. [Google Scholar]
- Zhang, Z.; Lyu, E.; Min, Z.; Zhang, A.; Yu, Y.; Meng, M.Q.-H. Robust Semi-Supervised Point Cloud Registration via Latent GMM-Based Correspondence. Remote Sens. 2023, 15, 4493. [Google Scholar] [CrossRef]
- Wang, Y.; Solomon, J.M. PRNet: Self-supervised learning for partial-to-partial registration. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Yew, Z.J.; Lee, G.H. RPM-Net: Robust point matching using learned features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 11824–11833. [Google Scholar]
- Sinkhorn, R. Diagonal equivalence to matrices with prescribed row and column sums. Am. Math. Mon. 1967, 74, 402–405. [Google Scholar] [CrossRef]
- Han, T.; Zhang, R.; Kan, J.; Dong, R.; Zhao, X.; Yao, S. A Point Cloud Registration Framework with Color Information Integration. Remote Sens. 2024, 16, 743. [Google Scholar] [CrossRef]
- Wang, C.; Xu, D.; Zhu, Y.; Martin, R.; Lu, C.; Fei-Fei, L.; Savarese, S. DenseFusion: 6D object pose estimation by iterative dense fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3343–3352. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Xu, D.; Anguelov, D.; Jain, A. PointFusion: Deep sensor fusion for 3D bounding box estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 244–253. [Google Scholar]
- Sindagi, V.A.; Zhou, Y.; Tuzel, O. MVX-Net: Multimodal voxelNet for 3D object detection. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 7276–7282. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-end learning for point cloud based 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar]
- Xu, X.; Dong, S.; Xu, T.; Ding, L.; Wang, J.; Jiang, P.; Song, L.; Li, J. FusionRCNN: LiDAR-camera fusion for two-stage 3D object detection. Remote Sens. 2023, 15, 1839. [Google Scholar] [CrossRef]
- Luo, Z.; Zhou, C.; Pan, L.; Zhang, G.; Liu, T.; Luo, Y.; Zhao, H.; Liu, Z.; Lu, S. Exploring point-BEV fusion for 3D point cloud object tracking with transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 1, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Bińkowski, M.; Sutherland, D.J.; Arbel, M.; Gretton, A. Demystifying mmd gans. arXiv 2018, arXiv:1801.01401. [Google Scholar]
- Sun, B.; Saenko, K. Deep coral: Correlation alignment for deep domain adaptation. In Proceedings of the Computer Vision—ECCV 2016Workshops, Amsterdam, The Netherlands, October 8–10 and 15–16, 2016, Proceedings, Part III 14; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 443–450. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; March, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Zhou, X.; Karpur, A.; Gan, C.; Luo, L.; Huang, Q. Unsupervised domain adaptation for 3D keypoint estimation via view consistency. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 137–153. [Google Scholar]
- Qin, C.; You, H.; Wang, L.; Kuo, C.-C.J.; Fu, Y. PointDAN: A multi-scale 3D domain adaption network for point cloud representation. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph CNN for learning on point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6418–6427. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K. Focal loss for dense object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2980–2988. [Google Scholar]
- Huang, X.; Qu, W.; Zuo, Y.; Fang, Y.; Zhao, X. IMFNet: Interpretable multimodal fusion for point cloud registration. IEEE Robot. Autom. Lett. 2022, 7, 12323–12330. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2014. [Google Scholar]
- Yuan, M.; Fu, K.; Li, Z.; Meng, Y.; Wang, M. PointMBF: A multi-scale bidirectional fusion network for unsupervised RGB-D point cloud registration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Vancouver, BC, Canada, 18–22 June 2023; pp. 17694–17705. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet + +: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30, 5105–5114. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | 7Scenes | Industrial Components | ||||
|---|---|---|---|---|---|---|
| RMSE(R) | RMSE(t) | CD | RMSE(R) | RMSE(t) | CD | |
| ICP | 2.7752 | 0.0271 | 19.1795 | 6.1539 | 0.2391 | 39.0656 |
| Go-ICP | 5.1133 | 0.3823 | 38.4563 | 4.4389 | 0.0718 | 26.6444 |
| FPFH + RANSAC | 2.1404 | 0.0382 | 13.4047 | 1.7253 | 0.0227 | 12.9046 |
| PointNetLK | 1.1554 | 0.0269 | 10.9058 | 3.2435 | 0.0311 | 21.4798 |
| DCP | 6.0744 | 0.2183 | 41.7216 | 5.4562 | 0.1811 | 35.4356 |
| PRNet | 0.1568 | 0.0021 | 8.7981 | 0.8901 | 0.0157 | 9.0159 |
| RPMNet | 0.0781 | 0.0019 | 6.5086 | 0.1878 | 0.0014 | 4.6819 |
| RIENet | 0.0247 | 0.0001 | 2.7058 | 0.2137 | 0.0006 | 3.4755 |
| Ours | 0.0109 | 0.0001 | 0.5674 | 0.0116 | 0.0001 | 0.0497 |
| Model | 7Scenes | Industrial Components | ||||
|---|---|---|---|---|---|---|
| RMSE(R) | RMSE(t) | CD | RMSE(R) | RMSE(t) | CD | |
| BS | 0.0254 | 0.0002 | 3.6972 | 0.2507 | 0.0009 | 4.2145 |
| BS + P2MF | 0.0142 | 0.0001 | 0.8473 | 0.0735 | 0.0003 | 1.8095 |
| BS + P2MF + GIDA | 0.0109 | 0.0001 | 0.5674 | 0.0116 | 0.0001 | 0.0497 |
| Point Backbone | Image Backbone | 7Scenes | Industrial Components | ||
|---|---|---|---|---|---|
| RMSE(R) | RMSE(t) | RMSE(R) | RMSE(t) | ||
| PointNet | VGG | 0.8873 | 0.0024 | 0.9795 | 0.0006 |
| ViT-B [44] | 1.7590 | 0.0018 | 1.5140 | 0.0095 | |
| ResNet | 2.2217 | 0.0166 | 3.1183 | 0.0747 | |
| PointNet++ [45] | VGG | 1.6718 | 0.0039 | 2.5271 | 0.0082 |
| ViT-B | 0.2429 | 0.0005 | 0.1090 | 0.0001 | |
| ResNet | 0.5601 | 0.0004 | 0.9678 | 0.0031 | |
| DGCNN | VGG | 0.1864 | 0.0007 | 0.0225 | 0.0001 |
| ViT-B | 0.1834 | 0.0012 | 0.7159 | 0.0034 | |
| ResNet | 0.0109 | 0.0001 | 0.0116 | 0.0001 | |
| Connection Style | 7Scenes | Industrial Components | ||
|---|---|---|---|---|
| RMSE(R) | RMSE(t) | RMSE(R) | RMSE(t) | |
| CA | 0.0167 | 0.0001 | 0.0814 | 0.0001 |
| C | 0.0358 | 0.0002 | 0.1196 | 0.0001 |
| C, MLP | 0.0124 | 0.0001 | 0.0532 | 0.0002 |
| MLP | 0.0248 | 0.0001 | 0.1049 | 0.0002 |
| MLP, ⨁ | 0.0136 | 0.0001 | 0.0788 | 0.0001 |
| C, MLP, ⨁ | 0.0109 | 0.0001 | 0.0116 | 0.0001 |
| Model | Original Dataset | Noisy Dataset | ||
|---|---|---|---|---|
| RMSE(R) | RMSE(t) | RMSE(R) | RMSE(t) | |
| ICP | 6.1539 | 0.2391 | 7.7306 | 0.3674 |
| Go-ICP | 4.4389 | 0.0718 | 4.9596 | 0.0742 |
| FPFH + RANSAC | 1.7253 | 0.0227 | 2.1645 | 0.0293 |
| PointNetLK | 3.2435 | 0.0311 | 3.5038 | 0.0536 |
| DCP | 5.4562 | 0.1811 | 5.9572 | 0.1703 |
| PRNet | 0.8901 | 0.0157 | 1.3392 | 0.0285 |
| RPMNet | 0.1878 | 0.0014 | 0.3142 | 0.0037 |
| RIENet | 0.2137 | 0.0006 | 0.3519 | 0.0008 |
| Ours | 0.0116 | 0.0001 | 0.0920 | 0.0002 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, H.; Sun, J.; Dong, B. DAMF-Net: Unsupervised Domain-Adaptive Multimodal Feature Fusion Method for Partial Point Cloud Registration. Remote Sens. 2024, 16, 1993. https://doi.org/10.3390/rs16111993
Zhao H, Sun J, Dong B. DAMF-Net: Unsupervised Domain-Adaptive Multimodal Feature Fusion Method for Partial Point Cloud Registration. Remote Sensing. 2024; 16(11):1993. https://doi.org/10.3390/rs16111993
Chicago/Turabian StyleZhao, Haixia, Jiaqi Sun, and Bin Dong. 2024. "DAMF-Net: Unsupervised Domain-Adaptive Multimodal Feature Fusion Method for Partial Point Cloud Registration" Remote Sensing 16, no. 11: 1993. https://doi.org/10.3390/rs16111993
APA StyleZhao, H., Sun, J., & Dong, B. (2024). DAMF-Net: Unsupervised Domain-Adaptive Multimodal Feature Fusion Method for Partial Point Cloud Registration. Remote Sensing, 16(11), 1993. https://doi.org/10.3390/rs16111993