
SIM-MultiDepth: Self-Supervised Indoor Monocular Multi-Frame Depth Estimation Based on Texture-Aware Masking

Abstract
1. Introduction
- We propose a novel self-supervised indoor monocular multi-frame depth estimation framework called SIM-MultiDepth. To solve the overfitting problem and achieve a better performance in low-textured areas, a single-frame depth estimation network is introduced to compute camera poses and serve as supervision.
- Considering the patch-based photometric loss, a texture-aware masking supervision strategy is well-designed. The corresponding depth consistency loss guarantees that the points with discriminative features are only involved in geometric reasoning, instead of being forced to be consistent with the single-frame depth.
- The experiments on the NYU Depth V2 dataset illustrate the effectiveness of our proposed SIM-MultiDepth and the texture-aware masking strategy. All evaluation metrics improved compared with the single-frame method. The generalization experiments on the 7-Scenes and Campus Indoor datasets also reveal the characteristics of the multi-frame and single-frame methods.
2. Related Work
2.1. Indoor Monocular Single-Frame Depth Estimation
2.2. Monocular Multi-Frame Depth Estimation
3. Methods
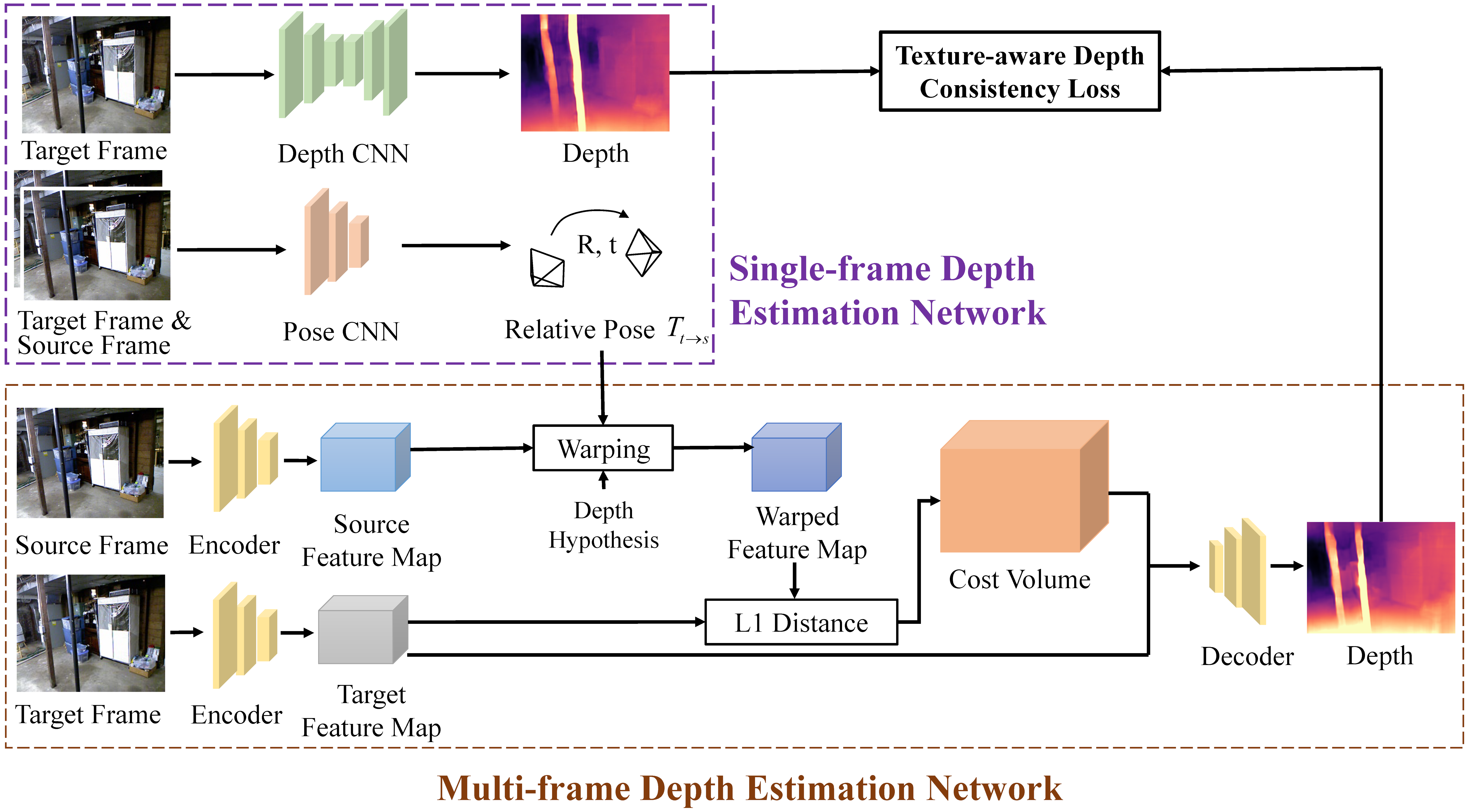
3.1. Overview of SIM-MultiDepth
3.2. Texture-Aware Depth Consistency Loss
3.3. Overall Loss Functions
4. Experiments
4.1. Implementation Details
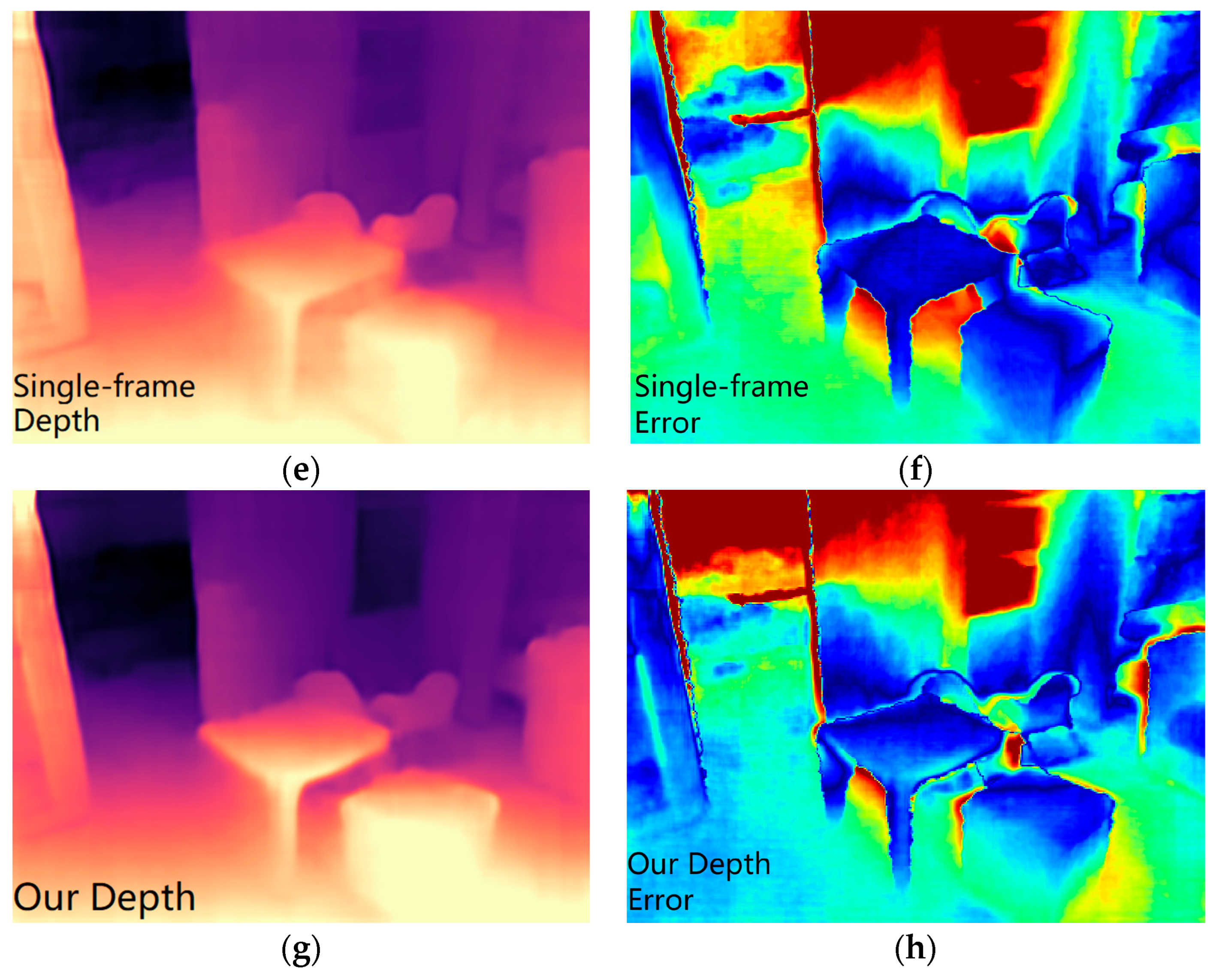
4.2. Results
4.2.1. Evaluation Results on NYU Depth V2
4.2.2. Zero-Shot Generalization Results on 7-Scenes
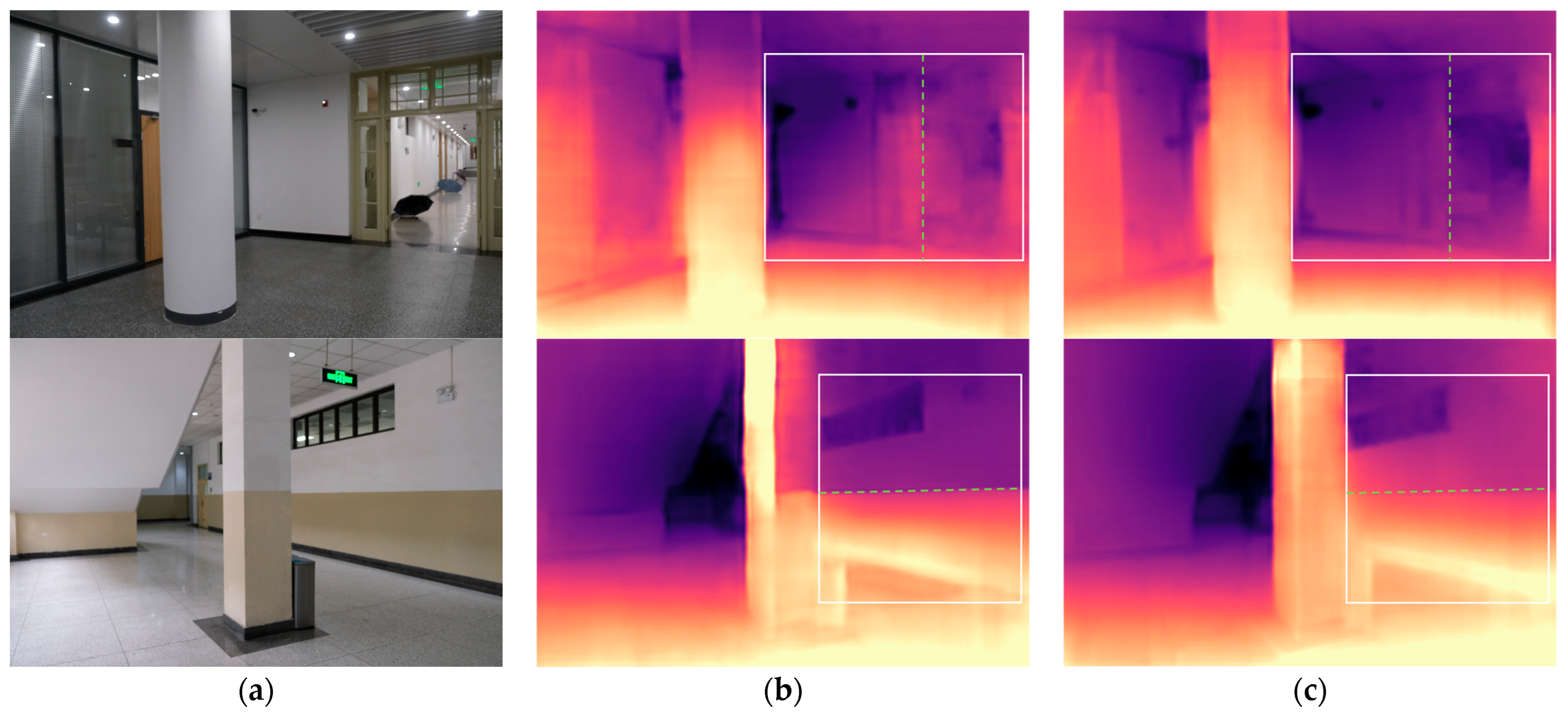
4.2.3. Zero-Shot Generalization Results on Campus Indoor
4.2.4. Ablation Studies on NYU Depth V2
5. Conclusions and Discussions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1851–1858. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G.J. Digging into self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3828–3838. [Google Scholar]
- Yu, Z.; Jin, L.; Gao, S. P2Net: Patch-match and plane-regularization for unsupervised indoor depth estimation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXIV. pp. 206–222. [Google Scholar]
- Watson, J.; Mac Aodha, O.; Prisacariu, V.; Brostow, G.; Firman, M. The temporal opportunist: Self-supervised multi-frame monocular depth. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 1164–1174. [Google Scholar]
- Feng, Z.; Yang, L.; Jing, L.; Wang, H.; Tian, Y.; Li, B. Disentangling object motion and occlusion for unsupervised multi-frame monocular depth. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 228–244. [Google Scholar]
- Feng, C.; Chen, Z.; Zhang, C.; Hu, W.; Li, B.; Lu, F. IterDepth: Iterative residual refinement for outdoor self-supervised multi-frame monocular depth estimation. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 329–341. [Google Scholar] [CrossRef]
- Xu, H.; Zhou, Z.; Qiao, Y.; Kang, W.; Wu, Q. Self-supervised multi-view stereo via effective co-segmentation and data-augmentation. Proc. AAAI Conf. Artif. Intell. 2021, 35, 3030–3038. [Google Scholar] [CrossRef]
- Shi, B.; Wu, Z.; Mo, Z.; Duan, D.; Yeung, S.-K.; Tan, P. A benchmark dataset and evaluation for non-lambertian and uncalibrated photometric stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3707–3716. [Google Scholar]
- Ju, Y.; Lam, K.-M.; Xie, W.; Zhou, H.; Dong, J.; Shi, B. Deep Learning Methods for Calibrated Photometric Stereo and Beyond. IEEE Trans. Pattern Anal. Mach. Intell. 2024; early access. [Google Scholar] [CrossRef]
- Chen, G.; Han, K.; Shi, B.; Matsushita, Y.; Wong, K.-Y.K. Deep photometric stereo for non-lambertian surfaces. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 129–142. [Google Scholar] [CrossRef]
- Xiang, J.; Wang, Y.; An, L.; Liu, H.; Liu, J. Exploring the mutual influence between self-supervised single-frame and multi-frame depth estimation. IEEE Robot. Autom. Lett. 2023, 8, 6547–6554. [Google Scholar] [CrossRef]
- Wang, X.; Zhu, Z.; Huang, G.; Chi, X.; Ye, Y.; Chen, Z.; Wang, X. Crafting monocular cues and velocity guidance for self-supervised multi-frame depth learning. Proc. AAAI Conf. Artif. Intell. 2023, 37, 2689–2697. [Google Scholar] [CrossRef]
- Long, Y.; Yu, H.; Liu, B. Two-stream based multi-stage hybrid decoder for self-supervised multi-frame monocular depth. IEEE Robot. Autom. Lett. 2022, 7, 12291–12298. [Google Scholar] [CrossRef]
- Uhrig, J.; Schneider, N.; Schneider, L.; Franke, U.; Brox, T.; Geiger, A. Sparsity invariant cnns. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 11–20. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from rgbd images. In Proceedings of Computer Vision–ECCV 2012: 12th European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 746–760. [Google Scholar]
- Shotton, J.; Glocker, B.; Zach, C.; Izadi, S.; Criminisi, A.; Fitzgibbon, A. Scene coordinate regression forests for camera relocalization in RGB-D images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2930–2937. [Google Scholar]
- Guo, X.; Zhao, H.; Shao, S.; Li, X.; Zhang, B. F2Depth: Self-supervised indoor monocular depth estimation via optical flow consistency and feature map synthesis. Eng. Appl. Artif. Intell. 2024, 133, 108391. [Google Scholar] [CrossRef]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep ordinal regression network for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2002–2011. [Google Scholar]
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper depth prediction with fully convolutional residual networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 239–248. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Li, J.; Klein, R.; Yao, A. A two-streamed network for estimating fine-scaled depth maps from single rgb images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3372–3380. [Google Scholar]
- Zhang, S.; Yang, L.; Mi, M.B.; Zheng, X.; Yao, A. Improving deep regression with ordinal entropy. arXiv 2023, arXiv:2301.08915. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. Adv. Neural Inf. Process. Syst. 2014, 27, 2366–2374. [Google Scholar]
- Liu, F.; Shen, C.; Lin, G.; Reid, I. Learning depth from single monocular images using deep convolutional neural fields. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 2024–2039. [Google Scholar] [CrossRef]
- Shao, S.; Pei, Z.; Wu, X.; Liu, Z.; Chen, W.; Li, Z. IEBins: Iterative elastic bins for monocular depth estimation. Adv. Neural Inf. Process. Syst. 2024, 36, 53025–53037. [Google Scholar]
- Agarwal, A.; Arora, C. Attention attention everywhere: Monocular depth prediction with skip attention. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 5861–5870. [Google Scholar]
- Agarwal, A.; Arora, C. Depthformer: Multiscale vision transformer for monocular depth estimation with global local information fusion. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 3873–3877. [Google Scholar]
- Bhat, S.F.; Alhashim, I.; Wonka, P. LocalBins: Improving depth estimation by learning local distributions. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part I. pp. 480–496. [Google Scholar]
- Bhat, S.F.; Alhashim, I.; Wonka, P. Adabins: Depth estimation using adaptive bins. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4009–4018. [Google Scholar]
- Jun, J.; Lee, J.-H.; Lee, C.; Kim, C.-S. Depth map decomposition for monocular depth estimation. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part II. pp. 18–34. [Google Scholar]
- Ning, J.; Li, C.; Zhang, Z.; Wang, C.; Geng, Z.; Dai, Q.; He, K.; Hu, H. All in tokens: Unifying output space of visual tasks via soft token. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 19900–19910. [Google Scholar]
- Shao, S.; Pei, Z.; Chen, W.; Li, R.; Liu, Z.; Li, Z. URCDC-Depth: Uncertainty rectified cross-distillation with cutflip for monocular depth estimation. IEEE Trans. Multimed. 2023, 26, 3341–3353. [Google Scholar] [CrossRef]
- Piccinelli, L.; Sakaridis, C.; Yu, F. iDisc: Internal discretization for monocular depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 21477–21487. [Google Scholar]
- Yuan, W.; Gu, X.; Dai, Z.; Zhu, S.; Tan, P. Neural window fully-connected CRFs for monocular depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3916–3925. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Zhao, W.; Rao, Y.; Liu, Z.; Liu, B.; Zhou, J.; Lu, J. Unleashing text-to-image diffusion models for visual perception. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 5729–5739. [Google Scholar]
- Ji, Y.; Chen, Z.; Xie, E.; Hong, L.; Liu, X.; Liu, Z.; Lu, T.; Li, Z.; Luo, P. DDP: Diffusion model for dense visual prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 21741–21752. [Google Scholar]
- Hu, J.; Ozay, M.; Zhang, Y.; Okatani, T. Revisiting single image depth estimation: Toward higher resolution maps with accurate object boundaries. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; pp. 1043–1051. [Google Scholar]
- Yin, W.; Liu, Y.; Shen, C.; Yan, Y. Enforcing geometric constraints of virtual normal for depth prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5684–5693. [Google Scholar]
- Liu, C.; Yang, J.; Ceylan, D.; Yumer, E.; Furukawa, Y. PlaneNet: Piece-wise planar reconstruction from a single rgb image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2579–2588. [Google Scholar]
- Yu, Z.; Zheng, J.; Lian, D.; Zhou, Z.; Gao, S. Single-image piece-wise planar 3d reconstruction via associative embedding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1029–1037. [Google Scholar]
- Patil, V.; Sakaridis, C.; Liniger, A.; Van Gool, L. P3Depth: Monocular depth estimation with a piecewise planarity prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1610–1621. [Google Scholar]
- Shao, S.; Pei, Z.; Chen, W.; Wu, X.; Li, Z. NDDepth: Normal-distance assisted monocular depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 7931–7940. [Google Scholar]
- Li, B.; Huang, Y.; Liu, Z.; Zou, D.; Yu, W. StructDepth: Leveraging the structural regularities for self-supervised indoor depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 12663–12673. [Google Scholar]
- Bian, J.; Li, Z.; Wang, N.; Zhan, H.; Shen, C.; Cheng, M.-M.; Reid, I. Unsupervised scale-consistent depth and ego-motion learning from monocular video. Adv. Neural Inf. Process. Syst. 2019, 32, 1–11. [Google Scholar]
- Bian, J.-W.; Zhan, H.; Wang, N.; Chin, T.-J.; Shen, C.; Reid, I. Auto-rectify network for unsupervised indoor depth estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 9802–9813. [Google Scholar] [CrossRef]
- Ji, P.; Li, R.; Bhanu, B.; Xu, Y. MonoIndoor: Towards good practice of self-supervised monocular depth estimation for indoor environments. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 12787–12796. [Google Scholar]
- Li, R.; Ji, P.; Xu, Y.; Bhanu, B. MonoIndoor++: Towards better practice of self-supervised monocular depth estimation for indoor environments. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 830–846. [Google Scholar] [CrossRef]
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision transformers for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 12179–12188. [Google Scholar]
- Ranftl, R.; Lasinger, K.; Hafner, D.; Schindler, K.; Koltun, V. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1623–1637. [Google Scholar] [CrossRef]
- Wu, C.-Y.; Wang, J.; Hall, M.; Neumann, U.; Su, S. Toward practical monocular indoor depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3814–3824. [Google Scholar]
- Zhao, C.; Poggi, M.; Tosi, F.; Zhou, L.; Sun, Q.; Tang, Y.; Mattoccia, S. GasMono: Geometry-aided self-supervised monocular depth estimation for indoor scenes. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 16209–16220. [Google Scholar]
- Schonberger, J.L.; Frahm, J.-M. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Luo, X.; Huang, J.-B.; Szeliski, R.; Matzen, K.; Kopf, J. Consistent video depth estimation. ACM Trans. Graph. (ToG) 2020, 39, 71. [Google Scholar] [CrossRef]
- Patil, V.; Van Gansbeke, W.; Dai, D.; Van Gool, L. Don’t forget the past: Recurrent depth estimation from monocular video. IEEE Robot. Autom. Lett. 2020, 5, 6813–6820. [Google Scholar] [CrossRef]
- Yasarla, R.; Cai, H.; Jeong, J.; Shi, Y.; Garrepalli, R.; Porikli, F. MAMo: Leveraging memory and attention for monocular video depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 8754–8764. [Google Scholar]
- Yang, J.; Alvarez, J.M.; Liu, M. Self-supervised learning of depth inference for multi-view stereo. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7526–7534. [Google Scholar]
- Ding, Y.; Zhu, Q.; Liu, X.; Yuan, W.; Zhang, H.; Zhang, C. KD-MVS: Knowledge distillation based self-supervised learning for multi-view stereo. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 630–646. [Google Scholar]
- Liu, C.; Gu, J.; Kim, K.; Narasimhan, S.G.; Kautz, J. Neural rgb→d sensing: Depth and uncertainty from a video camera. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10986–10995. [Google Scholar]
- Hou, Y.; Kannala, J.; Solin, A. Multi-view stereo by temporal nonparametric fusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2651–2660. [Google Scholar]
- Wu, Z.; Wu, X.; Zhang, X.; Wang, S.; Ju, L. Spatial correspondence with generative adversarial network: Learning depth from monocular videos. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7494–7504. [Google Scholar]
- Wimbauer, F.; Yang, N.; Von Stumberg, L.; Zeller, N.; Cremers, D. MonoRec: Semi-supervised dense reconstruction in dynamic environments from a single moving camera. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6112–6122. [Google Scholar]
- Li, R.; Gong, D.; Yin, W.; Chen, H.; Zhu, Y.; Wang, K.; Chen, X.; Sun, J.; Zhang, Y. Learning to fuse monocular and multi-view cues for multi-frame depth estimation in dynamic scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 21539–21548. [Google Scholar]
- Guizilini, V.; Ambruș, R.; Chen, D.; Zakharov, S.; Gaidon, A. Multi-frame self-supervised depth with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 160–170. [Google Scholar]
- Zhang, S.; Zhao, C. Dyna-DepthFormer: Multi-frame transformer for self-supervised depth estimation in dynamic scenes. arXiv 2023, arXiv:2301.05871. [Google Scholar]
- Zhou, J.; Wang, Y.; Qin, K.; Zeng, W. Moving Indoor: Unsupervised video depth learning in challenging environments. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8618–8627. [Google Scholar]
- Liu, M.; Salzmann, M.; He, X. Discrete-continuous depth estimation from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 716–723. [Google Scholar]
- Li, B.; Shen, C.; Dai, Y.; Van Den Hengel, A.; He, M. Depth and surface normal estimation from monocular images using regression on deep features and hierarchical crfs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1119–1127. [Google Scholar]
- Zhao, W.; Liu, S.; Shu, Y.; Liu, Y.-J. Towards better generalization: Joint depth-pose learning without posenet. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9151–9161. [Google Scholar]
- Zhang, Y.; Gong, M.; Li, J.; Zhang, M.; Jiang, F.; Zhao, H. Self-supervised monocular depth estimation with multiscale perception. IEEE Trans. Image Process. 2022, 31, 3251–3266. [Google Scholar] [CrossRef]
- Song, X.; Hu, H.; Liang, L.; Shi, W.; Xie, G.; Lu, X.; Hei, X. Unsupervised monocular estimation of depth and visual odometry using attention and depth-pose consistency loss. IEEE Trans. Multimed. 2023, 26, 3517–3529. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Supervision | REL ↓ | RMS ↓ | Log10 ↓ | δ < 1.25 ↑ | δ < 1.252 ↑ | δ < 1.253 ↑ |
|---|---|---|---|---|---|---|---|
| Liu [68] | ✓ | 0.335 | 1.060 | 0.127 | - | - | - |
| Li [69] | ✓ | 0.232 | 0.821 | 0.094 | 0.621 | 0.886 | 0.968 |
| Liu [25] | ✓ | 0.213 | 0.759 | 0.087 | 0.650 | 0.906 | 0.976 |
| Eigen [21] | ✓ | 0.158 | 0.641 | - | 0.769 | 0.950 | 0.988 |
| Li [22] | ✓ | 0.143 | 0.635 | 0.063 | 0.788 | 0.958 | 0.991 |
| PlaneNet [41] | ✓ | 0.142 | 0.514 | 0.060 | 0.827 | 0.963 | 0.990 |
| PlaneReg [42] | ✓ | 0.134 | 0.503 | 0.057 | 0.827 | 0.963 | 0.990 |
| Laina [20] | ✓ | 0.127 | 0.573 | 0.055 | 0.811 | 0.953 | 0.988 |
| DORN [19] | ✓ | 0.115 | 0.509 | 0.051 | 0.828 | 0.965 | 0.992 |
| VNL [40] | ✓ | 0.108 | 0.416 | 0.048 | 0.875 | 0.976 | 0.994 |
| P3Depth [43] | ✓ | 0.104 | 0.356 | 0.043 | 0.898 | 0.981 | 0.996 |
| Jun [31] | ✓ | 0.100 | 0.362 | 0.043 | 0.907 | 0.986 | 0.997 |
| DDP [38] | ✓ | 0.094 | 0.329 | 0.040 | 0.921 | 0.990 | 0.998 |
| Moving Indoor [67] | × | 0.208 | 0.712 | 0.086 | 0.674 | 0.900 | 0.968 |
| TrianFlow [70] | × | 0.189 | 0.686 | 0.079 | 0.701 | 0.912 | 0.978 |
| Zhang [71] | × | 0.177 | 0.634 | - | 0.733 | 0.936 | - |
| Monodepth2 [2] | × | 0.170 | 0.617 | 0.072 | 0.748 | 0.942 | 0.986 |
| ADPDepth [72] | × | 0.165 | 0.592 | 0.071 | 0.753 | 0.934 | 0.981 |
| SC-Depth [46] | × | 0.159 | 0.608 | 0.068 | 0.772 | 0.939 | 0.982 |
| P2Net [3] | × | 0.159 | 0.599 | 0.068 | 0.772 | 0.942 | 0.984 |
| F2Depth [18] | × | 0.158 | 0.583 | 0.067 | 0.779 | 0.947 | 0.987 |
| Ours | × | 0.152 | 0.567 | 0.065 | 0.792 | 0.950 | 0.988 |
| b | REL ↓ | RMS ↓ | Log10 ↓ | δ < 1.25 ↑ | δ < 1.252 ↑ | δ < 1.253 ↑ |
|---|---|---|---|---|---|---|
| 0.5 | 0.156 | 0.578 | 0.066 | 0.783 | 0.946 | 0.987 |
| 0.8 | 0.152 | 0.567 | 0.065 | 0.792 | 0.950 | 0.988 |
| 1 | 0.152 | 0.567 | 0.065 | 0.792 | 0.950 | 0.988 |
| 1.2 | 0.152 | 0.568 | 0.065 | 0.791 | 0.949 | 0.988 |
| 1.5 | 0.153 | 0.571 | 0.065 | 0.788 | 0.948 | 0.988 |
| 2 | 0.157 | 0.581 | 0.067 | 0.780 | 0.946 | 0.987 |
| Methods | Our SIM-MultiDepth | F2Depth [18] | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Scene | REL ↓ | RMS ↓ | Log10 ↓ | δ < 1.25 ↑ | δ < 1.252 ↑ | δ < 1.253 ↑ | REL ↓ | RMS ↓ | Log10 ↓ | δ < 1.25 ↑ | δ < 1.252 ↑ | δ < 1.253 ↑ |
| Chess | 0.186 | 0.411 | 0.081 | 0.668 | 0.940 | 0.992 | 0.186 | 0.409 | 0.081 | 0.671 | 0.936 | 0.993 |
| Fire | 0.180 | 0.332 | 0.078 | 0.690 | 0.950 | 0.991 | 0.176 | 0.322 | 0.076 | 0.701 | 0.951 | 0.991 |
| Heads | 0.196 | 0.204 | 0.082 | 0.674 | 0.924 | 0.985 | 0.185 | 0.195 | 0.078 | 0.718 | 0.930 | 0.983 |
| Office | 0.159 | 0.363 | 0.066 | 0.766 | 0.970 | 0.996 | 0.162 | 0.370 | 0.067 | 0.762 | 0.963 | 0.996 |
| Pumpkin | 0.136 | 0.372 | 0.059 | 0.813 | 0.978 | 0.996 | 0.127 | 0.350 | 0.056 | 0.846 | 0.980 | 0.995 |
| RedKitchen | 0.171 | 0.414 | 0.073 | 0.724 | 0.950 | 0.994 | 0.173 | 0.416 | 0.074 | 0.722 | 0.946 | 0.992 |
| Stairs | 0.147 | 0.437 | 0.064 | 0.784 | 0.922 | 0.974 | 0.159 | 0.455 | 0.068 | 0.766 | 0.912 | 0.972 |
| Average | 0.167 | 0.376 | 0.071 | 0.734 | 0.954 | 0.992 | 0.167 | 0.375 | 0.071 | 0.740 | 0.950 | 0.992 |
| Methods | Our SIM-MultiDepth | F2Depth [18] | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Scene No. | REL ↓ | RMS ↓ | Log10 ↓ | δ < 1.25 ↑ | δ < 1.252 ↑ | δ < 1.253 ↑ | REL ↓ | RMS ↓ | Log10 ↓ | δ < 1.25 ↑ | δ < 1.252 ↑ | δ < 1.253 ↑ |
| 1 | 0.156 | 0.590 | 0.063 | 0.750 | 0.977 | 1 | 0.164 | 0.592 | 0.064 | 0.766 | 0.947 | 1 |
| 2 | 0.144 | 1.083 | 0.066 | 0.752 | 1 | 1 | 0.135 | 0.949 | 0.060 | 0.798 | 0.981 | 1 |
| 3 | 0.218 | 0.887 | 0.083 | 0.685 | 0.946 | 1 | 0.215 | 0.889 | 0.084 | 0.644 | 0.973 | 1 |
| 4 | 0.142 | 0.559 | 0.060 | 0.818 | 1 | 1 | 0.134 | 0.588 | 0.058 | 0.777 | 1 | 1 |
| 5 | 0.183 | 1.224 | 0.078 | 0.667 | 0.973 | 1 | 0.159 | 1.091 | 0.067 | 0.746 | 0.946 | 1 |
| 6 | 0.136 | 1.487 | 0.066 | 0.774 | 0.933 | 0.972 | 0.154 | 1.625 | 0.073 | 0.757 | 0.919 | 0.932 |
| 7 | 0.244 | 2.224 | 0.109 | 0.514 | 0.830 | 0.973 | 0.266 | 2.321 | 0.122 | 0.436 | 0.802 | 0.960 |
| 8 | 0.172 | 0.791 | 0.071 | 0.745 | 0.915 | 1 | 0.149 | 0.699 | 0.063 | 0.772 | 0.929 | 1 |
| 9 | 0.099 | 0.418 | 0.041 | 0.907 | 1 | 1 | 0.088 | 0.372 | 0.037 | 0.946 | 1 | 1 |
| 10 | 0.232 | 0.761 | 0.091 | 0.583 | 0.933 | 1 | 0.193 | 0.686 | 0.076 | 0.717 | 0.917 | 1 |
| 11 | 0.183 | 0.674 | 0.076 | 0.733 | 0.973 | 0.987 | 0.168 | 0.667 | 0.072 | 0.787 | 0.973 | 1 |
| 12 | 0.124 | 0.512 | 0.058 | 0.763 | 1 | 1 | 0.143 | 0.536 | 0.066 | 0.736 | 1 | 1 |
| 13 | 0.144 | 0.594 | 0.067 | 0.790 | 0.974 | 1 | 0.147 | 0.594 | 0.067 | 0.803 | 0.974 | 1 |
| 14 | 0.141 | 0.443 | 0.062 | 0.827 | 0.987 | 1 | 0.135 | 0.422 | 0.060 | 0.880 | 1 | 1 |
| 15 | 0.256 | 0.433 | 0.087 | 0.747 | 0.813 | 0.947 | 0.236 | 0.409 | 0.084 | 0.720 | 0.867 | 0.946 |
| 16 | 0.163 | 0.527 | 0.067 | 0.787 | 0.960 | 1 | 0.202 | 0.647 | 0.079 | 0.707 | 0.920 | 1 |
| 17 | 0.127 | 0.270 | 0.050 | 0.907 | 0.947 | 0.987 | 0.114 | 0.244 | 0.047 | 0.893 | 0.960 | 1 |
| 18 | 0.144 | 0.227 | 0.063 | 0.800 | 0.987 | 1 | 0.144 | 0.230 | 0.061 | 0.787 | 0.987 | 1 |
| Average | 0.165 | 0.769 | 0.069 | 0.754 | 0.956 | 0.993 | 0.164 | 0.753 | 0.069 | 0.760 | 0.950 | 0.991 |
| Final Mask | REL ↓ | RMS ↓ | Log10 ↓ | δ < 1.25 ↑ | δ < 1.252 ↑ | δ < 1.253 ↑ |
|---|---|---|---|---|---|---|
| No consistency loss | 0.158 | 0.591 | 0.067 | 0.779 | 0.943 | 0.985 |
| 0.153 | 0.570 | 0.065 | 0.791 | 0.949 | 0.987 | |
| 0.152 | 0.570 | 0.065 | 0.790 | 0.949 | 0.987 | |
| 0.152 | 0.567 | 0.065 | 0.792 | 0.950 | 0.988 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, X.; Zhao, H.; Shao, S.; Li, X.; Zhang, B.; Li, N. SIM-MultiDepth: Self-Supervised Indoor Monocular Multi-Frame Depth Estimation Based on Texture-Aware Masking. Remote Sens. 2024, 16, 2221. https://doi.org/10.3390/rs16122221
Guo X, Zhao H, Shao S, Li X, Zhang B, Li N. SIM-MultiDepth: Self-Supervised Indoor Monocular Multi-Frame Depth Estimation Based on Texture-Aware Masking. Remote Sensing. 2024; 16(12):2221. https://doi.org/10.3390/rs16122221
Chicago/Turabian StyleGuo, Xiaotong, Huijie Zhao, Shuwei Shao, Xudong Li, Baochang Zhang, and Na Li. 2024. "SIM-MultiDepth: Self-Supervised Indoor Monocular Multi-Frame Depth Estimation Based on Texture-Aware Masking" Remote Sensing 16, no. 12: 2221. https://doi.org/10.3390/rs16122221
APA StyleGuo, X., Zhao, H., Shao, S., Li, X., Zhang, B., & Li, N. (2024). SIM-MultiDepth: Self-Supervised Indoor Monocular Multi-Frame Depth Estimation Based on Texture-Aware Masking. Remote Sensing, 16(12), 2221. https://doi.org/10.3390/rs16122221