
MBT-UNet: Multi-Branch Transform Combined with UNet for Semantic Segmentation of Remote Sensing Images



Abstract
1. Introduction
- MBT-UNet builds a multi-branch encoder based on a Pyramid Vision Transformer (PVT). Using Transformer’s self-attention mechanism, the dependence between pixels can be modelled globally. By applying PVT to multiple branches, feature information at different scales is fully extracted.
- A feature fusion module (FFM) is proposed, specifically used to achieve effective integration of feature information at different scales. This module includes pooling, attention mechanism and other parts to ensure that features from multiple branches can effectively integrate complementary feature information while retaining the original information. This feature fusion mechanism can effectively improve the ability to capture image details and edges.
- A multi-scale upsampling module (MSUM) is proposed in the decoder stage. Different from single-path upsampling, the MSUM uses convolution kernels of different sizes in parallel, allowing the model to restore the image more precisely during the upsampling process, thereby improving the accuracy and robustness of segmentation.
- Experiments are carried out on the ISPRS Vaihingen dataset, Potsdam dataset, LoveDA dataset and UAVid dataset. The results show that the proposed method achieves excellent performance.
2. Related Works
2.1. Semantic Segmentation of RS Images Based on CNN
2.2. Semantic Segmentation of RS Images Based on Transformer
2.3. Semantic Segmentation of RS Images Based on the Combination of CNN and Transformer
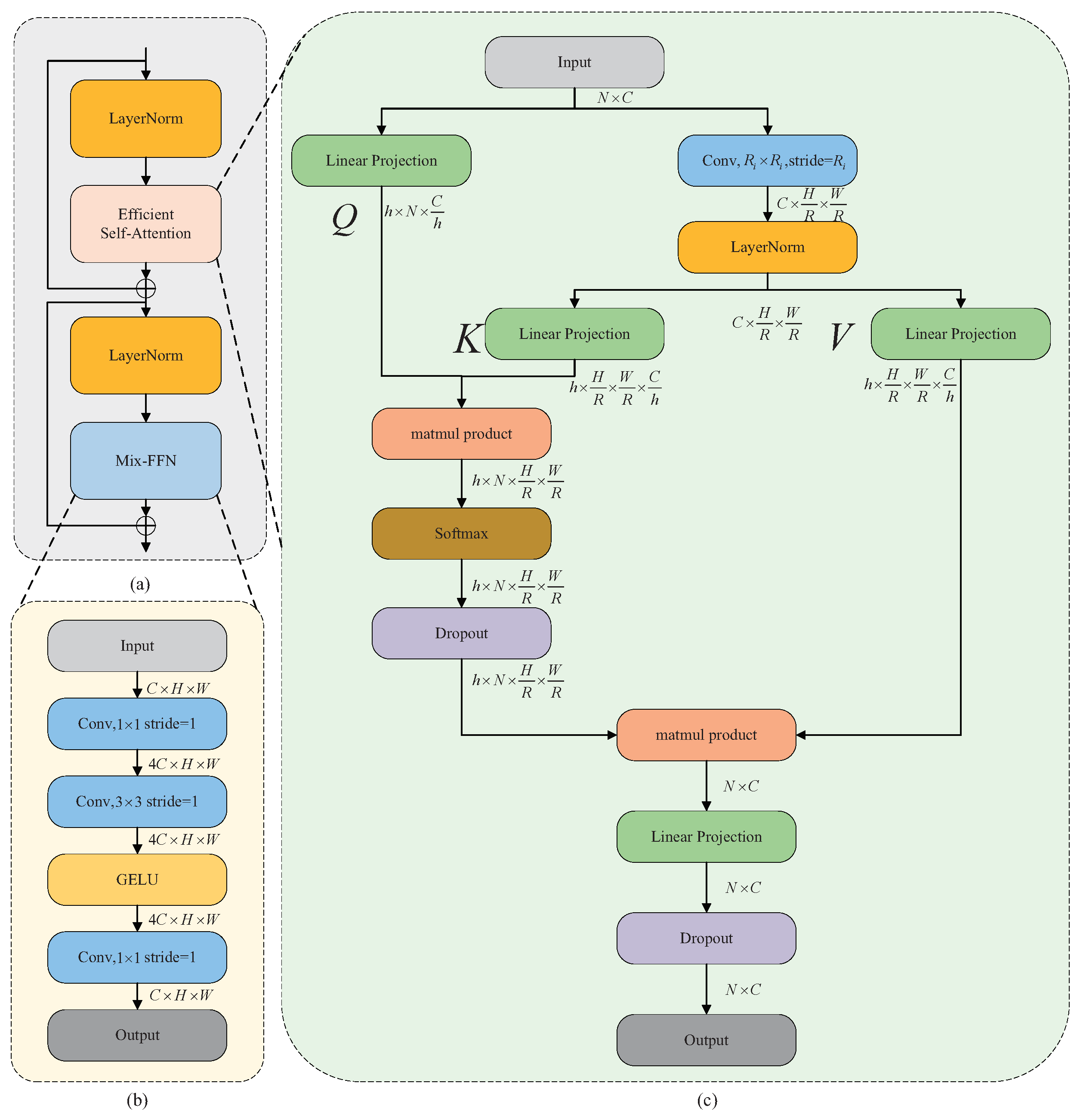
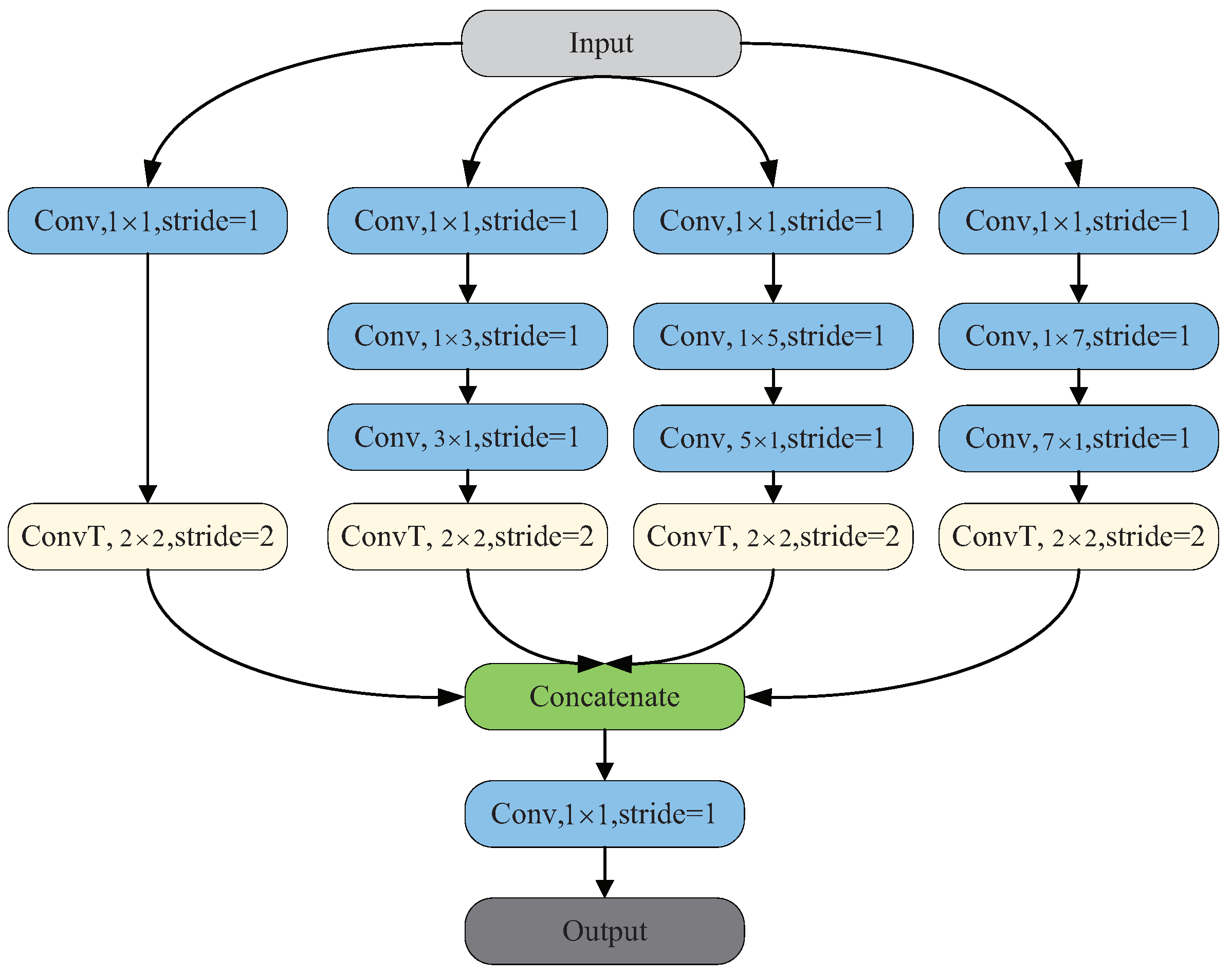
3. Method
3.1. Overall Architecture of MBT-UNet
3.2. PVT-Based Encoder
3.3. Feature Fusion Module
3.4. Multi-Scale Upsampling Module
4. Experiment
4.1. Datasets
4.1.1. Potsdam Dataset
4.1.2. Vaihingen Dataset
4.1.3. LoveDA Dataset
4.1.4. UAVid Dataset
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. Ablation Study
4.4.1. Effect of Multi-Branch PVT
4.4.2. Effect of FFM
4.4.3. Effect of MSUM
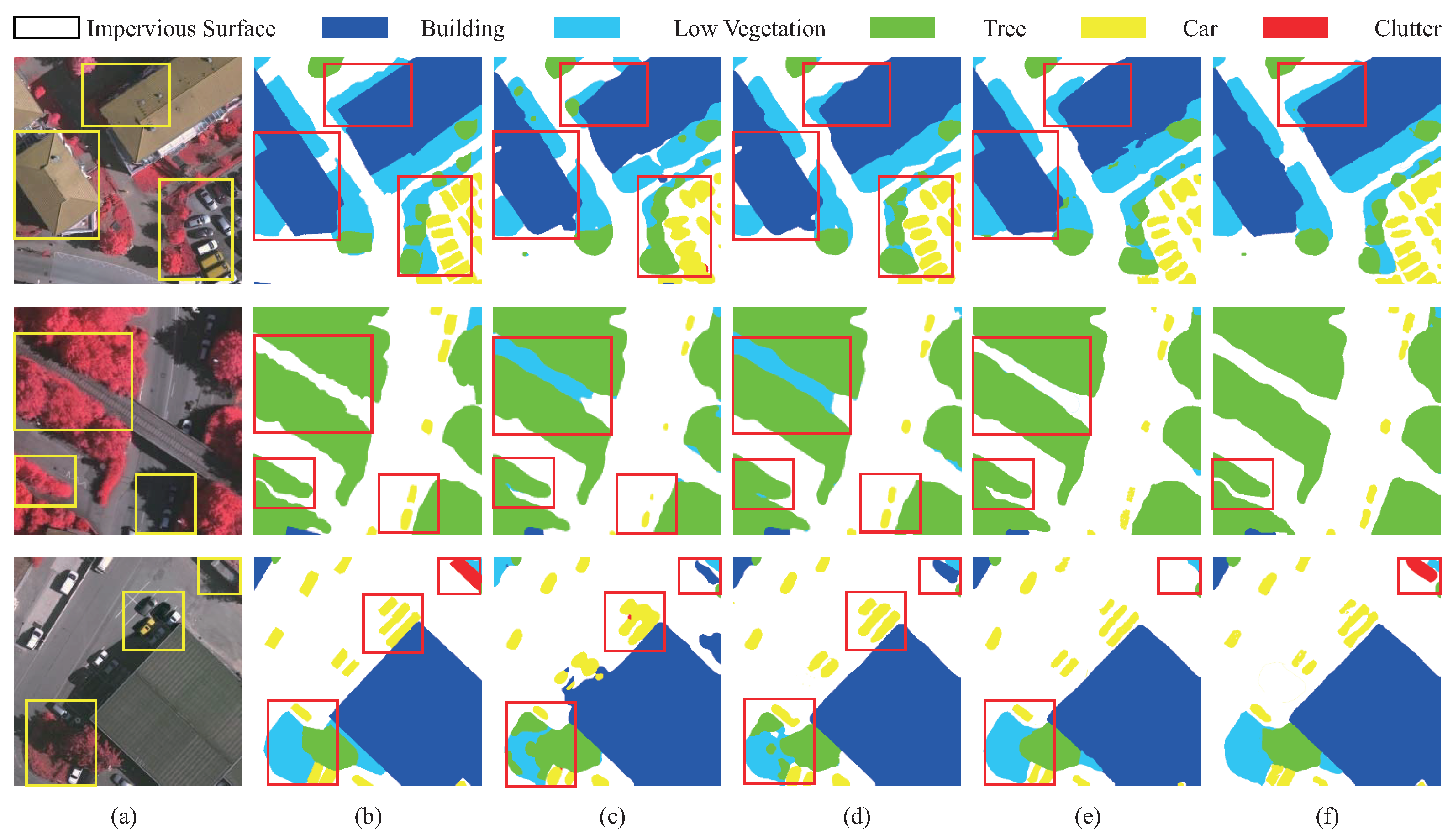
4.5. Comparison with State-of-the-Art Methods
4.5.1. Results on the Vaihingen Dataset
4.5.2. Results on the Potsdam Dataset
4.5.3. Results on the LoveDA Dataset
4.5.4. Results on the UAVid Dataset
4.5.5. Efficiency Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Amani, M.; Mahdavi, S.; Kakooei, M.; Ghorbanian, A.; Brisco, B.; DeLancey, E.R.; Toure, S.; Reyes, E.L. Wetland Change Analysis in Alberta, Canada Using Four Decades of Landsat Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10314–10335. [Google Scholar] [CrossRef]
- Xu, C.; Wang, J.; Sang, Y.; Li, K.; Liu, J.; Yang, G. An Effective Deep Learning Model for Monitoring Mangroves: A Case Study of the Indus Delta. Remote Sens. 2023, 15, 2220. [Google Scholar] [CrossRef]
- Jung, H.; Choi, H.S.; Kang, M. Boundary Enhancement Semantic Segmentation for Building Extraction From Remote Sensed Image. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Wang, L.; Fang, S.; Meng, X.; Li, R. Building Extraction With Vision Transformer. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Huan, H.; Liu, Y.; Xie, Y.; Wang, C.; Xu, D.; Zhang, Y. MAENet: Multiple Attention Encoder–Decoder Network for Farmland Segmentation of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Zhang, R.; Chen, J.; Feng, L.; Li, S.; Yang, W.; Guo, D. A Refined Pyramid Scene Parsing Network for Polarimetric SAR Image Semantic Segmentation in Agricultural Areas. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Yu, Z.; Wang, J.; Yang, X.; Ma, J. Superpixel-Based Style Transfer Method for Single-Temporal Remote Sensing Image Identification in Forest Type Groups. Remote Sens. 2023, 15, 3875. [Google Scholar] [CrossRef]
- Liu, T.; Yao, L.; Qin, J.; Lu, J.; Lu, N.; Zhou, C. A Deep Neural Network for the Estimation of Tree Density Based on High-Spatial Resolution Image. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Han, W.; Li, J.; Wang, S.; Zhang, X.; Dong, Y.; Fan, R.; Zhang, X.; Wang, L. Geological Remote Sensing Interpretation Using Deep Learning Feature and an Adaptive Multisource Data Fusion Network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Chen, X.; Yao, X.; Zhou, Z.; Liu, Y.; Yao, C.; Ren, K. DRs-UNet: A Deep Semantic Segmentation Network for the Recognition of Active Landslides from InSAR Imagery in the Three Rivers Region of the Qinghai–Tibet Plateau. Remote Sens. 2022, 14, 1848. [Google Scholar] [CrossRef]
- Zhong, H.F.; Sun, Q.; Sun, H.M.; Jia, R.S. NT-Net: A Semantic Segmentation Network for Extracting Lake Water Bodies From Optical Remote Sensing Images Based on Transformer. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Liu, S.; Li, M.; Xu, M.; Zeng, Z. An Improved Lightweight U-Net for Sea Ice Lead Extraction From Multipolarization SAR Images. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Cui, L.; Jing, X.; Wang, Y.; Huan, Y.; Xu, Y.; Zhang, Q. Improved Swin Transformer-Based Semantic Segmentation of Postearthquake Dense Buildings in Urban Areas Using Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 369–385. [Google Scholar] [CrossRef]
- Liu, X.; Peng, Y.; Lu, Z.; Li, W.; Yu, J.; Ge, D.; Xiang, W. Feature-Fusion Segmentation Network for Landslide Detection Using High-Resolution Remote Sensing Images and Digital Elevation Model Data. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]
- Pal, S.K.; Ghosh, A.; Shankar, B.U. Segmentation of Remotely Sensed Images with Fuzzy Thresholding, and Quantitative Evaluation. Int. J. Remote Sens. 2000, 21, 2269–2300. [Google Scholar] [CrossRef]
- Yu, Q.; Clausi, D.A. SAR Sea-Ice Image Analysis Based on Iterative Region Growing Using Semantics. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3919–3931. [Google Scholar] [CrossRef]
- Ferraioli, G. Multichannel InSAR Building Edge Detection. IEEE Trans. Geosci. Remote Sens. 2010, 48, 1224–1231. [Google Scholar] [CrossRef]
- Wang, Y.; Yu, W.; Fang, Z. Multiple Kernel-Based SVM Classification of Hyperspectral Images by Combining Spectral, Spatial, and Semantic Information. Remote Sens. 2020, 12, 120. [Google Scholar] [CrossRef]
- Zheng, C.; Wang, L. Semantic Segmentation of Remote Sensing Imagery Using Object-Based Markov Random Field Model With Regional Penalties. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 1924–1935. [Google Scholar] [CrossRef]
- Zheng, C.; Zhang, Y.; Wang, L. Semantic Segmentation of Remote Sensing Imagery Using an Object-Based Markov Random Field Model With Auxiliary Label Fields. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3015–3028. [Google Scholar] [CrossRef]
- Zhang, P.; Li, M.; Wu, Y.; Li, H. Hierarchical Conditional Random Fields Model for Semisupervised SAR Image Segmentation. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4933–4951. [Google Scholar] [CrossRef]
- Du, S.; Zhang, F.; Zhang, X. Semantic Classification of Urban Buildings Combining VHR Image and GIS Data: An Improved Random Forest Approach. ISPRS J. Photogramm. Remote Sens. 2015, 105, 107–119. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. Proc. AAAI Conf. Artif. Intell. 2017, 31. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar] [CrossRef]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified Perceptual Parsing for Scene Understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 418–434. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the Computer Vision–ECCV 2020, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Zhang, Q.; Yang, Y.B. ResT: An Efficient Transformer for Visual Recognition. Proc. Adv. Neural Inf. Process. Syst. 2021, 34, 15475–15485. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. Proc. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef]
- Yi, Y.; Zhang, Z.; Zhang, W.; Zhang, C.; Li, W.; Zhao, T. Semantic Segmentation of Urban Buildings from VHR Remote Sensing Imagery Using a Deep Convolutional Neural Network. Remote Sens. 2019, 11, 1774. [Google Scholar] [CrossRef]
- Ding, L.; Tang, H.; Bruzzone, L. LANet: Local Attention Embedding to Improve the Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 426–435. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, W.; Zhang, T.; Li, J. HRCNet: High-Resolution Context Extraction Network for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2021, 13, 71. [Google Scholar] [CrossRef]
- Yang, X.; Li, S.; Chen, Z.; Chanussot, J.; Jia, X.; Zhang, B.; Li, B.; Chen, P. An Attention-Fused Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Imagery. ISPRS J. Photogramm. Remote Sens. 2021, 177, 238–262. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Wang, L.; Atkinson, P.M. ABCNet: Attentive Bilateral Contextual Network for Efficient Semantic Segmentation of Fine-Resolution Remotely Sensed Imagery. ISPRS J. Photogramm. Remote Sens. 2021, 181, 84–98. [Google Scholar] [CrossRef]
- Sun, L.; Cheng, S.; Zheng, Y.; Wu, Z.; Zhang, J. SPANet: Successive Pooling Attention Network for Semantic Segmentation of Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4045–4057. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Duan, C.; Su, J.; Zhang, C. Multistage Attention ResU-Net for Semantic Segmentation of Fine-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Su, J.; Wang, L.; Atkinson, P.M. Multiattention Network for Semantic Segmentation of Fine-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, Y.; Xiong, S.; Lu, X.; Zhu, X.X.; Mou, L. Integrating Detailed Features and Global Contexts for Semantic Segmentation in Ultrahigh-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–14. [Google Scholar] [CrossRef]
- Hu, L.; Zhou, X.; Ruan, J.; Li, S. ASPP+-LANet: A Multi-Scale Context Extraction Network for Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sens. 2024, 16, 1036. [Google Scholar] [CrossRef]
- Wang, Q.; Chen, W.; Huang, Z.; Tang, H.; Yang, L. MultiSenseSeg: A Cost-Effective Unified Multimodal Semantic Segmentation Model for Remote Sensing. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–24. [Google Scholar] [CrossRef]
- Xie, J.; Pan, B.; Xu, X.; Shi, Z. MiSSNet: Memory-Inspired Semantic Segmentation Augmentation Network for Class-Incremental Learning in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–13. [Google Scholar] [CrossRef]
- Li, J.; Zhang, S.; Sun, Y.; Han, Q.; Sun, Y.; Wang, Y. Frequency-Driven Edge Guidance Network for Semantic Segmentation of Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 9677–9693. [Google Scholar] [CrossRef]
- Liu, J.; Hua, W.; Zhang, W.; Liu, F.; Xiao, L. Stair Fusion Network With Context-Refined Attention for Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–17. [Google Scholar] [CrossRef]
- Bai, Q.; Luo, X.; Wang, Y.; Wei, T. DHRNet: A Dual-Branch Hybrid Reinforcement Network for Semantic Segmentation of Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 4176–4193. [Google Scholar] [CrossRef]
- Ni, Y.; Liu, J.; Chi, W.; Wang, X.; Li, D. CGGLNet: Semantic Segmentation Network for Remote Sensing Images Based on Category-Guided Global–Local Feature Interaction. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–17. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Xu, Z.; Zhang, W.; Zhang, T.; Yang, Z.; Li, J. Efficient Transformer for Remote Sensing Image Segmentation. Remote Sens. 2021, 13, 3585. [Google Scholar] [CrossRef]
- Hao, S.; Wu, B.; Zhao, K.; Ye, Y.; Wang, W. Two-Stream Swin Transformer with Differentiable Sobel Operator for Remote Sensing Image Classification. Remote Sens. 2022, 14, 1507. [Google Scholar] [CrossRef]
- Zhou, Y.; Chen, S.; Zhao, J.; Yao, R.; Xue, Y.; Saddik, A.E. CLT-Det: Correlation Learning Based on Transformer for Detecting Dense Objects in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Xu, Z.; Geng, J.; Jiang, W. MMT: Mixed-Mask Transformer for Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–15. [Google Scholar] [CrossRef]
- Zheng, C.; Jiang, Y.; Lv, X.; Nie, J.; Liang, X.; Wei, Z. SSDT: Scale-Separation Semantic Decoupled Transformer for Semantic Segmentation of Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 9037–9052. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Wang, D.; Duan, C.; Wang, T.; Meng, X. Transformer Meets Convolution: A Bilateral Awareness Network for Semantic Segmentation of Very Fine Resolution Urban Scene Images. Remote Sens. 2021, 13, 3065. [Google Scholar] [CrossRef]
- Gao, L.; Liu, H.; Yang, M.; Chen, L.; Wan, Y.; Xiao, Z.; Qian, Y. STransFuse: Fusing Swin Transformer and Convolutional Neural Network for Remote Sensing Image Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10990–11003. [Google Scholar] [CrossRef]
- Zhang, C.; Jiang, W.; Zhang, Y.; Wang, W.; Zhao, Q.; Wang, C. Transformer and CNN Hybrid Deep Neural Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–20. [Google Scholar] [CrossRef]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin Transformer Embedding UNet for Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Zhou, X.; Zhou, L.; Gong, S.; Zhong, S.; Yan, W.; Huang, Y. Swin Transformer Embedding Dual-Stream for Semantic Segmentation of Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 175–189. [Google Scholar] [CrossRef]
- Ren, D.; Li, F.; Sun, H.; Liu, L.; Ren, S.; Yu, M. Local-Enhanced Multi-Scale Aggregation Swin Transformer for Semantic Segmentation of High-Resolution Remote Sensing Images. Int. J. Remote Sens. 2024, 45, 101–120. [Google Scholar] [CrossRef]
- Dimitrovski, I.; Spasev, V.; Loshkovska, S.; Kitanovski, I. U-Net Ensemble for Enhanced Semantic Segmentation in Remote Sensing Imagery. Remote Sens. 2024, 16, 2077. [Google Scholar] [CrossRef]
- Yao, M.; Zhang, Y.; Liu, G.; Pang, D. SSNet: A Novel Transformer and CNN Hybrid Network for Remote Sensing Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 3023–3037. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, T.; Zhao, L.; Hu, L.; Wang, Z.; Niu, Z.; Cheng, P.; Chen, K.; Zeng, X.; Wang, Z.; et al. RingMo-Lite: A Remote Sensing Lightweight Network With CNN-Transformer Hybrid Framework. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–20. [Google Scholar] [CrossRef]
- Zhang, R.; Zhang, Q.; Zhang, G. LSRFormer: Efficient Transformer Supply Convolutional Neural Networks With Global Information for Aerial Image Segmentation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–13. [Google Scholar] [CrossRef]
- Yu, X.; Li, S.; Zhang, Y. Incorporating Convolutional and Transformer Architectures to Enhance Semantic Segmentation of Fine-Resolution Urban Images. Eur. J. Remote Sens. 2024, 57, 2361768. [Google Scholar] [CrossRef]
- Chen, Y.; Dong, Q.; Wang, X.; Zhang, Q.; Kang, M.; Jiang, W.; Wang, M.; Xu, L.; Zhang, C. Hybrid Attention Fusion Embedded in Transformer for Remote Sensing Image Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 4421–4435. [Google Scholar] [CrossRef]
- Fu, Y.; Zhang, X.; Wang, M. DSHNet: A Semantic Segmentation Model of Remote Sensing Images Based on Dual Stream Hybrid Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 4164–4175. [Google Scholar] [CrossRef]
- Wu, H.; Zhang, M.; Huang, P.; Tang, W. CMLFormer: CNN and Multiscale Local-Context Transformer Network for Remote Sensing Images Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 7233–7241. [Google Scholar] [CrossRef]
- Lu, W.; Zhang, Z.; Nguyen, M. A Lightweight CNN–Transformer Network With Laplacian Loss for Low-Altitude UAV Imagery Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–20. [Google Scholar] [CrossRef]
- Wang, X.; Wang, H.; Jing, Y.; Yang, X.; Chu, J. A Bio-Inspired Visual Perception Transformer for Cross-Domain Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sens. 2024, 16, 1514. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction Without Convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian Error Linear Units (GELUs). arXiv 2023, arXiv:1606.08415. [Google Scholar]
- Stergiou, A.; Poppe, R.; Kalliatakis, G. Refining Activation Downsampling With SoftPool. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10357–10366. [Google Scholar]
- ISPRS. 2D Semantic Labeling Contest. Available online: https://www.isprs.org/education/benchmarks/UrbanSemLab/semantic-labeling.aspx (accessed on 8 February 2023).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the Computer Vision–ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar] [CrossRef]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. BiSeNet V2: Bilateral Network with Guided Aggregation for Real-Time Semantic Segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Name | Modules | IoU (%) | Evaluation Index | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MBT | FFM | MSUM | Impervious Surface | Building | Low Vegetation | Tree | Car | MIoU (%) | mF1 (%) | |
| P_UNet | 80.9 | 84.98 | 69.28 | 78.29 | 55.02 | 73.69 | 84.56 | |||
| ✓ | 81.75 | 85.6 | 69.32 | 78.44 | 61.17 | 75.26 | 85.58 | |||
| ✓ | ✓ | 82.69 | 87.42 | 69.38 | 78.76 | 63.75 | 76.4 | 86.23 | ||
| ✓ | ✓ | ✓ | 84.25 | 88.14 | 69.62 | 79 | 64.34 | 77.07 | 86.76 | |
| Method Name | Modules | Evaluation Index | |||
|---|---|---|---|---|---|
| MBT | FFM | MSUM | MIoU (%) | mF1 (%) | |
| P_UNet | 43.47 | 59.7 | |||
| ✓ | 44.32 | 60.78 | |||
| ✓ | ✓ | 45.12 | 61.5 | ||
| ✓ | ✓ | ✓ | 45.97 | 62.33 | |
| Method | Backbone | IoU (%) | Evaluation Index | |||||
|---|---|---|---|---|---|---|---|---|
| Impervious Surface | Building | Low Vegetation | Tree | Car | MIoU (%) | mF1 (%) | ||
| UNet | - | 79.58 | 84.54 | 66.68 | 77.91 | 49.92 | 71.73 | 82.89 |
| FCN | ResNet-50 | 78.71 | 81.75 | 65.98 | 77.41 | 54.05 | 71.58 | 83 |
| DANet | ResNet-50 | 81.31 | 85.36 | 68.2 | 78.5 | 53.06 | 73.29 | 84.03 |
| DeepLabv3+ | ResNet-50 | 82.09 | 86.88 | 65.69 | 75.83 | 55.82 | 73.26 | 84.07 |
| PSPNet | ResNet-50 | 81.55 | 83.92 | 66.3 | 74.83 | 54.4 | 72.2 | 83.38 |
| SegFormer | MIT-B5 | 83.09 | 88.01 | 69.45 | 78.49 | 53.4 | 74.49 | 85.04 |
| BiSeNet V2 | - | 81.68 | 86.81 | 69.5 | 78.04 | 56.55 | 74.52 | 84.95 |
| ST-UNet | ResNet-50+Swin-B | 83.38 | 88.12 | 67.69 | 78.08 | 57.81 | 75.02 | 85.26 |
| SSNet | MIT-B5+SegNext | 84.19 | 87.18 | 70.17 | 78.94 | 58.72 | 75.84 | 85.76 |
| STDSNet | Swin-B | 84.19 | 87.3 | 70.4 | 78.16 | 60.39 | 76.09 | 85.94 |
| DSHNet | ViT-Base | 82.48 | 87.64 | 69.33 | 78.94 | 57.8 | 75.24 | 85.44 |
| MBT-UNet | MBT | 84.25 | 88.14 | 69.62 | 79 | 64.34 | 77.07 | 86.76 |
| Method | Backbone | IoU (%) | Evaluation Index | |||||
|---|---|---|---|---|---|---|---|---|
| Impervious Surface | Building | Low Vegetation | Tree | Car | MIoU (%) | mF1 (%) | ||
| UNet | - | 79.61 | 82.85 | 69.66 | 69.86 | 84.06 | 77.21 | 87.23 |
| FCN | ResNet-50 | 79.73 | 84.94 | 69.44 | 67.5 | 83.14 | 76.95 | 86.79 |
| DANet | ResNet-50 | 81.4 | 87.4 | 70.84 | 68.99 | 83.14 | 78.35 | 87.8 |
| DeepLabv3+ | ResNet-50 | 79.63 | 87.02 | 69.98 | 69.96 | 85.07 | 78.33 | 88.06 |
| PSPNet | ResNet-50 | 80.6 | 84.39 | 68.87 | 69.28 | 84.06 | 77.44 | 87.11 |
| SegFormer | MIT-B5 | 80.07 | 84.64 | 71.03 | 68.24 | 83.74 | 77.54 | 87.18 |
| BiSeNet V2 | - | 79.35 | 84.47 | 67.03 | 65.84 | 82.68 | 75.87 | 86.04 |
| ST-UNet | ResNet-50+Swin-B | 81.47 | 86.82 | 70.12 | 69.78 | 84.9 | 78.62 | 87.84 |
| SSNet | MIT-B5+SegNext | 81.32 | 85.26 | 71.94 | 70.07 | 84.18 | 78.55 | 87.88 |
| STDSNet | Swin-B | 81.25 | 87.84 | 71.99 | 70.06 | 82.84 | 78.80 | 87.97 |
| DSHNet | ViT-Base | 81.31 | 86.56 | 70.15 | 71.46 | 84.94 | 78.88 | 88.05 |
| MBT-UNet | MBT | 81.88 | 88.24 | 72.19 | 70.38 | 85.14 | 79.57 | 88.44 |
| Method | Backbone | IoU (%) | Evaluation Index | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Background | Building | Road | Water | Barren | Forest | Agricultural | MIoU (%) | mF1 (%) | ||
| UNet | - | 48.45 | 48.72 | 43.07 | 42.65 | 21.77 | 37.85 | 42.84 | 40.76 | 57.35 |
| FCN | ResNet-50 | 46.74 | 46.25 | 45.45 | 40.05 | 24.98 | 40.44 | 39.12 | 40.43 | 57.2 |
| DaNet | ResNet-50 | 48.97 | 53.36 | 48.66 | 45.43 | 16.04 | 38.67 | 40.57 | 41.67 | 57.7 |
| Deeplabv3+ | ResNet-50 | 50.34 | 47.29 | 49.07 | 52.06 | 22.67 | 37.14 | 47.47 | 43.72 | 60.14 |
| PSPNet | ResNet-50 | 45.53 | 42.04 | 52.82 | 56.08 | 12.36 | 37.94 | 43.53 | 41.47 | 57.2 |
| Segformer | MIT-B5 | 51.02 | 53.74 | 53.78 | 46.82 | 17.53 | 37.75 | 47.37 | 44.00 | 60.02 |
| BiseNetv2 | - | 46.31 | 50.18 | 37.14 | 53.06 | 21.14 | 35.10 | 44.89 | 41.12 | 57.49 |
| ST-UNet | ResNet50+Swin-B | 51.20 | 53.50 | 48.24 | 57.09 | 23.61 | 39.13 | 41.09 | 44.84 | 61.06 |
| SSNet | MIT-B5+SegNext | 50.08 | 54.22 | 49.37 | 56.88 | 25.18 | 33.22 | 45.34 | 44.90 | 61.17 |
| STDSNet | Swin-B | 51.86 | 54.12 | 46.01 | 55.03 | 24.8 | 40.58 | 43.06 | 45.07 | 61.35 |
| DSHNet | ViT-Base | 48.25 | 47.43 | 53.95 | 56.76 | 25.4 | 40.7 | 44.45 | 45.28 | 61.69 |
| MBT-UNet | MBT | 51.92 | 54.33 | 47.15 | 57.68 | 26.16 | 41.06 | 43.50 | 45.97 | 62.33 |
| Method | Backbone | IoU (%) | Evaluation Index | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Clutter | Building | Road | Tree | Low Vegetation | Moving Car | Static Car | Human | MIoU (%) | mF1 (%) | ||
| UNet | - | 92.28 | 82.92 | 76.17 | 65.8 | 59.66 | 54.16 | 39.04 | 13.45 | 60.44 | 79.09 |
| FCN | ResNet-50 | 90.93 | 82.58 | 72.08 | 61.99 | 58.26 | 49.34 | 37.7 | 14.48 | 58.42 | 74.67 |
| DaNet | ResNet-50 | 91.88 | 82.41 | 75.64 | 65.74 | 61.77 | 52.08 | 40.96 | 12.87 | 60.42 | 77.66 |
| Deeplabv3+ | ResNet-50 | 92.78 | 85.28 | 76.98 | 68.33 | 58.99 | 56.52 | 36.69 | 15.89 | 61.43 | 79.58 |
| PSPNet | ResNet-50 | 91.78 | 81.91 | 75.97 | 65.26 | 64.12 | 50.81 | 31.61 | 10.12 | 58.95 | 76.22 |
| Segformer | MIT-B5 | 92.2 | 83.67 | 76.79 | 69.36 | 62.03 | 58.44 | 42.77 | 18.76 | 63.00 | 80.87 |
| BiseNetv2 | - | 93.15 | 85.07 | 77.34 | 69.36 | 60.99 | 56.01 | 38.19 | 16.63 | 62.09 | 79.59 |
| ST-UNet | ResNet50+Swin-B | 93.23 | 85.02 | 77.61 | 69.76 | 62.86 | 57.04 | 37.79 | 19.61 | 62.87 | 80.18 |
| SSNet | MIT-B5+SegNext | 91.93 | 85.19 | 77.67 | 69.61 | 63.11 | 58.26 | 40.96 | 20.87 | 63.45 | 81.08 |
| STDSNet | Swin-B | 92.54 | 84.75 | 76.13 | 70.12 | 63.5 | 59.1 | 43.15 | 19.87 | 63.65 | 81.26 |
| DSHNet | ViT-Base | 91.29 | 84.22 | 76.6 | 69.42 | 63.68 | 59.25 | 41.17 | 18.84 | 63.06 | 80.96 |
| MBT-UNet | MBT | 93.46 | 85.71 | 77.28 | 70.47 | 63.07 | 60.82 | 43.35 | 21.43 | 64.45 | 81.79 |
| Method | Parameters (M) | FLOPs (G) | FPS |
|---|---|---|---|
| UNet | 28.99 | 203 | 72 |
| FCN | 47.13 | 198 | 75 |
| DANet | 47.46 | 211 | 69 |
| DeepLabv3+ | 41.22 | 177 | 70 |
| PSPNet | 46.6 | 179 | 73 |
| SegFormer | 81.98 | 75 | 98 |
| BiSeNet V2 | 3.35 | 12 | 232 |
| ST-UNet | 183.27 | 236 | 48 |
| SSNet | 61.47 | 184 | 64 |
| STDSNet | 138.69 | 331 | 36 |
| DSHNet | 129.34 | 287 | 42 |
| MBT-UNet | 108.22 | 187 | 66 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, B.; Li, B.; Sreeram, V.; Li, S. MBT-UNet: Multi-Branch Transform Combined with UNet for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2024, 16, 2776. https://doi.org/10.3390/rs16152776
Liu B, Li B, Sreeram V, Li S. MBT-UNet: Multi-Branch Transform Combined with UNet for Semantic Segmentation of Remote Sensing Images. Remote Sensing. 2024; 16(15):2776. https://doi.org/10.3390/rs16152776
Chicago/Turabian StyleLiu, Bin, Bing Li, Victor Sreeram, and Shuofeng Li. 2024. "MBT-UNet: Multi-Branch Transform Combined with UNet for Semantic Segmentation of Remote Sensing Images" Remote Sensing 16, no. 15: 2776. https://doi.org/10.3390/rs16152776
APA StyleLiu, B., Li, B., Sreeram, V., & Li, S. (2024). MBT-UNet: Multi-Branch Transform Combined with UNet for Semantic Segmentation of Remote Sensing Images. Remote Sensing, 16(15), 2776. https://doi.org/10.3390/rs16152776