
Multi-Stage Frequency Attention Network for Progressive Optical Remote Sensing Cloud Removal

 , , and
, , and
Abstract
1. Introduction
2. Related Work
2.1. Cloud Removal
2.1.1. Single-Stage Approach
2.1.2. Multi-Stage Approach
2.2. Attention Mechanisms
2.3. Learning in Frequency Domain
3. Materials and Methods
3.1. Overview
3.2. Multi-Stage Progressive Architecture
3.3. Frequency Attention Block
3.4. Non-Local Attention Block
3.5. Collaborative Optimization Loss
4. Experiments
4.1. Dataset
4.1.1. RICE Dataset
4.1.2. T-Cloud Dataset
4.2. Evaluation Metrics
4.3. Experimental Setup
4.4. Comparison with Other Methods
4.4.1. Results on RICE1 Dataset
4.4.2. Results on RICE2 Dataset
4.4.3. Results on T-Cloud Dataset
4.5. Effects of Different Stage Numbers
4.6. Effects of Critical Module
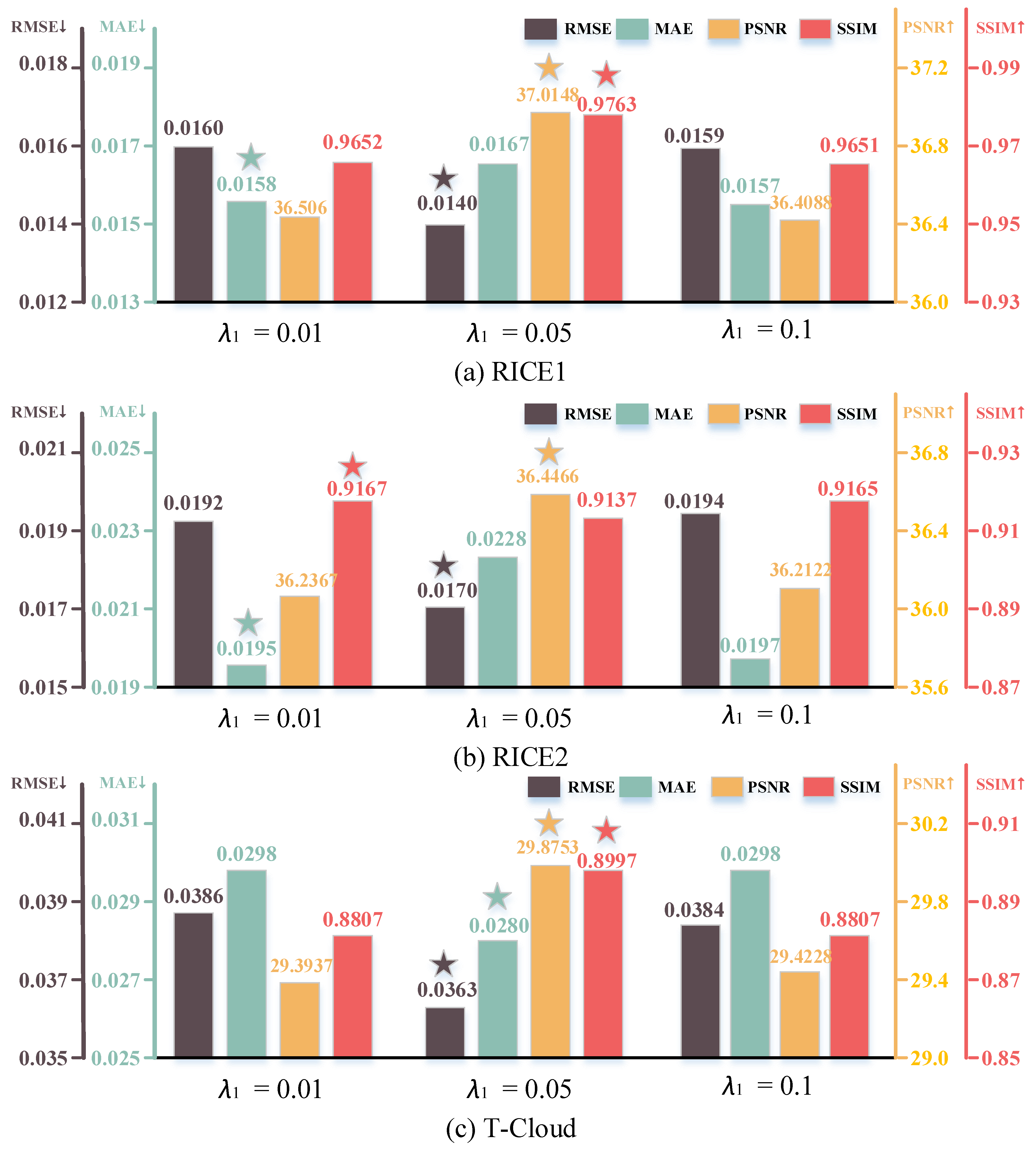
4.7. Effects of Different Loss Functions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, J.; Wang, X.; Chen, M.; Liu, S.; Zhou, X.; Shao, Z.; Liu, P. Thin cloud removal from single satellite images. Opt. Express 2014, 22, 618–632. [Google Scholar] [CrossRef]
- Cao, R.; Chen, Y.; Chen, J.; Zhu, X.; Shen, M. Thick cloud removal in Landsat images based on autoregression of Landsat time-series data. Remote Sens. Environ. 2020, 249, 112001. [Google Scholar] [CrossRef]
- King, M.D.; Platnick, S.; Menzel, W.P.; Ackerman, S.A.; Hubanks, P.A. Spatial and temporal distribution of clouds observed by MODIS onboard the Terra and Aqua satellites. IEEE Trans. Geosci. Remote Sens. 2013, 51, 3826–3852. [Google Scholar] [CrossRef]
- Zheng, J.; Liu, X.Y.; Wang, X. Single image cloud removal using U-Net and generative adversarial networks. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6371–6385. [Google Scholar] [CrossRef]
- Guillemot, C.; Le Meur, O. Image inpainting: Overview and recent advances. IEEE Signal Process. Mag. 2013, 31, 127–144. [Google Scholar] [CrossRef]
- Zhang, C.; Li, W.; Travis, D. Gaps-fill of SLC-off Landsat ETM+ satellite image using a geostatistical approach. Int. J. Remote Sens. 2007, 28, 5103–5122. [Google Scholar] [CrossRef]
- Shen, H.; Wu, J.; Cheng, Q.; Aihemaiti, M.; Zhang, C.; Li, Z. A spatiotemporal fusion based cloud removal method for remote sensing images with land cover changes. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 862–874. [Google Scholar] [CrossRef]
- Criminisi, A.; Pérez, P.; Toyama, K. Region filling and object removal by exemplar-based image inpainting. IEEE Trans. Image Process. 2004, 13, 1200–1212. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Gao, F.; Liu, D.; Chen, J. A modified neighborhood similar pixel interpolator approach for removing thick clouds in Landsat images. IEEE Geosci. Remote Sens. Lett. 2011, 9, 521–525. [Google Scholar] [CrossRef]
- Siravenha, A.C.; Sousa, D.; Bispo, A.; Pelaes, E. The use of high-pass filters and the inpainting method to clouds removal and their impact on satellite images classification. In Proceedings of the Image Analysis and Processing—ICIAP 2011: 16th International Conference, Ravenna, Italy, 14–16 September 2011; Proceedings, Part II 16. pp. 333–342. [Google Scholar]
- He, K.; Sun, J. Image completion approaches using the statistics of similar patches. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2423–2435. [Google Scholar] [CrossRef]
- Yuan, Q.; Shen, H.; Li, H. Single remote sensing image haze removal based on spatial and spectral self-adaptive model. In Proceedings of the Image and Graphics: 8th International Conference, ICIG 2015, Tianjin, China, 13–16 August 2015; Proceedings, Part III. pp. 382–392. [Google Scholar]
- Li, X.; Jing, Y.; Shen, H.; Zhang, L. The recent developments in cloud removal approaches of MODIS snow cover product. Hydrol. Earth Syst. Sci. 2019, 23, 2401–2416. [Google Scholar] [CrossRef]
- Xu, L.; Fang, S.; Niu, R.; Li, J. Cloud detection based on decision tree over tibetan plateau with modis data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, 39, 535–538. [Google Scholar] [CrossRef]
- Hu, G.; Sun, X.; Liang, D.; Sun, Y. Cloud removal of remote sensing image based on multi-output support vector regression. J. Syst. Eng. Electron. 2014, 25, 1082–1088. [Google Scholar] [CrossRef]
- Wang, L.; Wang, Q. Fast spatial-spectral random forests for thick cloud removal of hyperspectral images. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102916. [Google Scholar] [CrossRef]
- Lee, Y.; Wahba, G.; Ackerman, S.A. Cloud classification of satellite radiance data by multicategory support vector machines. J. Atmos. Ocean. Technol. 2004, 21, 159–169. [Google Scholar] [CrossRef]
- Hu, G.; Li, X.; Liang, D. Thin cloud removal from remote sensing images using multidirectional dual tree complex wavelet transform and transfer least square support vector regression. J. Appl. Remote Sens. 2015, 9, 095053. [Google Scholar] [CrossRef]
- Tahsin, S.; Medeiros, S.C.; Hooshyar, M.; Singh, A. Optical cloud pixel recovery via machine learning. Remote Sens. 2017, 9, 527. [Google Scholar] [CrossRef]
- Zhang, X.; Qiu, Z.; Peng, C.; Ye, P. Removing cloud cover interference from Sentinel-2 imagery in Google Earth Engine by fusing Sentinel-1 SAR data with a CNN model. Int. J. Remote Sens. 2022, 43, 132–147. [Google Scholar] [CrossRef]
- Ma, X.; Huang, Y.; Zhang, X.; Pun, M.O.; Huang, B. Cloud-EGAN: Rethinking CycleGAN from a feature enhancement perspective for cloud removal by combining CNN and transformer. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 4999–5012. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Li, L.; Xu, N.; Liu, F.; Yuan, C.; Chen, Z.; Lyu, X. AAFormer: Attention-Attended Transformer for Semantic Segmentation of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Chen, Y.; Cai, Z.; Yuan, J.; Wu, L. A Novel Dense-Attention Network for Thick Cloud Removal by Reconstructing Semantic Information. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 2339–2351. [Google Scholar] [CrossRef]
- Xu, M.; Deng, F.; Jia, S.; Jia, X.; Plaza, A.J. Attention mechanism-based generative adversarial networks for cloud removal in Landsat images. Remote Sens. Environ. 2022, 271, 112902. [Google Scholar] [CrossRef]
- Wu, P.; Pan, Z.; Tang, H.; Hu, Y. Cloudformer: A Cloud-Removal Network Combining Self-Attention Mechanism and Convolution. Remote Sens. 2022, 14, 6132. [Google Scholar] [CrossRef]
- Zhang, Q.; Yuan, Q.; Shen, H.; Zhang, L. A unified spatial-temporal-spectral learning framework for reconstructing missing data in remote sensing images. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 4981–4984. [Google Scholar]
- Zi, Y.; Xie, F.; Zhang, N.; Jiang, Z.; Zhu, W.; Zhang, H. Thin cloud removal for multispectral remote sensing images using convolutional neural networks combined with an imaging model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3811–3823. [Google Scholar] [CrossRef]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Dai, P.; Ji, S.; Zhang, Y. Gated convolutional networks for cloud removal from bi-temporal remote sensing images. Remote Sens. 2020, 12, 3427. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Liu, F.; Tong, Y.; Lyu, X.; Zhou, J. Semantic segmentation of remote sensing images by interactive representation refinement and geometric prior-guided inference. IEEE Trans. Geosci. Remote Sens. 2023, 62, 1–18. [Google Scholar] [CrossRef]
- Lin, D.; Xu, G.; Wang, X.; Wang, Y.; Sun, X.; Fu, K. A remote sensing image dataset for cloud removal. arXiv 2019, arXiv:1901.00600. [Google Scholar]
- Ding, H.; Zi, Y.; Xie, F. Uncertainty-based thin cloud removal network via conditional variational autoencoders. In Proceedings of the Asian Conference on Computer Vision, Macao, China, 4–8 December 2022; pp. 469–485. [Google Scholar]
- Bermudez, J.; Happ, P.; Oliveira, D.; Feitosa, R. SAR to optical image synthesis for cloud removal with generative adversarial networks. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 4, 5–11. [Google Scholar] [CrossRef]
- Meraner, A.; Ebel, P.; Zhu, X.X.; Schmitt, M. Cloud removal in Sentinel-2 imagery using a deep residual neural network and SAR-optical data fusion. ISPRS J. Photogramm. Remote Sens. 2020, 166, 333–346. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Luo, X.; Rong, W.; Xu, H. Cloud removal for optical remote sensing imagery using distortion coding network combined with compound loss functions. Remote Sens. 2022, 14, 3452. [Google Scholar] [CrossRef]
- Xu, F.; Shi, Y.; Ebel, P.; Yu, L.; Xia, G.S.; Yang, W.; Zhu, X.X. GLF-CR: SAR-enhanced cloud removal with global–local fusion. ISPRS J. Photogramm. Remote Sens. 2022, 192, 268–278. [Google Scholar] [CrossRef]
- Jiang, B.; Li, X.; Chong, H.; Wu, Y.; Li, Y.; Jia, J.; Wang, S.; Wang, J.; Chen, X. A deep-learning reconstruction method for remote sensing images with large thick cloud cover. Int. J. Appl. Earth Obs. Geoinf. 2022, 115, 103079. [Google Scholar] [CrossRef]
- Darbaghshahi, F.N.; Mohammadi, M.R.; Soryani, M. Cloud removal in remote sensing images using generative adversarial networks and SAR-to-optical image translation. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–9. [Google Scholar] [CrossRef]
- Tao, C.; Fu, S.; Qi, J.; Li, H. Thick cloud removal in optical remote sensing images using a texture complexity guided self-paced learning method. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part I 13. pp. 818–833. [Google Scholar]
- Li, X.; Xu, F.; Lyu, X.; Gao, H.; Tong, Y.; Cai, S.; Li, S.; Liu, D. Dual attention deep fusion semantic segmentation networks of large-scale satellite remote-sensing images. Int. J. Remote Sens. 2021, 42, 3583–3610. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Yong, X.; Chen, D.; Xia, R.; Ye, B.; Gao, H.; Chen, Z.; Lyu, X. SSCNet: A spectrum-space collaborative network for semantic segmentation of remote sensing images. Remote Sens. 2023, 15, 5610. [Google Scholar] [CrossRef]
- Li, Y.; Wei, F.; Zhang, Y.; Chen, W.; Ma, J. HS2P: Hierarchical spectral and structure-preserving fusion network for multimodal remote sensing image cloud and shadow removal. Inf. Fusion 2023, 94, 215–228. [Google Scholar] [CrossRef]
- Jin, M.; Wang, P.; Li, Y. HyA-GAN: Remote sensing image cloud removal based on hybrid attention generation adversarial network. Int. J. Remote Sens. 2024, 45, 1755–1773. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, B.; Zhang, W.; Hong, D.; Zhao, B.; Li, Z. Cloud Removal with SAR-Optical Data Fusion Using a Unified Spatial-Spectral Residual Network. IEEE Trans. Geosci. Remote Sens. 2023, 62, 1–20. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Gao, H.; Liu, F.; Lyu, X. A Frequency Domain Feature-Guided Network for Semantic Segmentation of Remote Sensing Images. IEEE Signal Process. Lett. 2024, 31, 1369–1373. [Google Scholar] [CrossRef]
- Rao, Y.; Zhao, W.; Zhu, Z.; Lu, J.; Zhou, J. Global filter networks for image classification. Adv. Neural Inf. Process. Syst. 2021, 34, 980–993. [Google Scholar]
- Yang, Y.; Soatto, S. Fda: Fourier domain adaptation for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4085–4095. [Google Scholar]
- Zhong, Z.; Shen, T.; Yang, Y.; Lin, Z.; Zhang, C. Joint sub-bands learning with clique structures for wavelet domain super-resolution. Adv. Neural Inf. Process. Syst. 2018, 31, 1–11. [Google Scholar]
- Chen, Z.; Zhang, P.; Zhang, Y.; Xu, X.; Ji, L.; Tang, H. Thick Cloud Removal in Multi-Temporal Remote Sensing Images via Frequency Spectrum-Modulated Tensor Completion. Remote Sens. 2023, 15, 1230. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 783–792. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Wen, X.; Pan, Z.; Hu, Y.; Liu, J. An effective network integrating residual learning and channel attention mechanism for thin cloud removal. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Pan, H. Cloud removal for remote sensing imagery via spatial attention generative adversarial network. arXiv 2020, arXiv:2009.13015. [Google Scholar]
- Liu, J.; Pan, B.; Shi, Z. Cascaded Memory Network for Optical Remote Sensing Imagery Cloud Removal. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–11. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | ||||
|---|---|---|---|---|
| DCP | 0.1402 | 0.1510 | 17.6752 | 0.8247 |
| Pix2Pix | 0.0679 | 0.0866 | 22.7856 | 0.8401 |
| SpAGAN | 0.0527 | 0.0557 | 27.7522 | 0.9608 |
| RCAN | 0.0279 | 0.0333 | 30.5608 | 0.9528 |
| CVAE | 0.0440 | 0.0520 | 27.2760 | 0.9632 |
| CMNet | 0.0213 | 0.0172 | 35.0473 | 0.9103 |
| our MFCRNet | 0.0140 | 0.0167 | 37.0148 | 0.9763 |
| Method | ||||
|---|---|---|---|---|
| DCP | 0.1455 | 0.1704 | 16.8548 | 0.5865 |
| Pix2Pix | 0.0563 | 0.0812 | 23.3966 | 0.6563 |
| SpAGAN | 0.0851 | 0.0958 | 27.0126 | 0.9030 |
| RCAN | 0.0942 | 0.1133 | 20.1369 | 0.7618 |
| CVAE | 0.0600 | 0.0770 | 25.2760 | 0.8009 |
| CMNet | 0.0248 | 0.0176 | 35.1383 | 0.8875 |
| our MFCRNet | 0.0170 | 0.0228 | 36.4466 | 0.9137 |
| Method | ||||
|---|---|---|---|---|
| DCP | 0.1139 | 0.0971 | 19.8694 | 0.0917 |
| Pix2Pix | 0.0735 | 0.0716 | 26.2355 | 0.6576 |
| SpAGAN | 0.0423 | 0.0419 | 26.6549 | 0.7159 |
| RCAN | 0.0851 | 0.0759 | 24.3434 | 0.6585 |
| CVAE | 0.0746 | 0.0728 | 24.0836 | 0.7941 |
| CMNet | 0.0390 | 0.0297 | 29.0990 | 0.7913 |
| our MFCRNet | 0.0363 | 0.0280 | 29.8753 | 0.8997 |
| Dataset | Stage | Para (M) | ||||
|---|---|---|---|---|---|---|
| 1 | 0.0162 | 0.0191 | 36.0252 | 0.9735 | 4.57 | |
| 2 | 0.0148 | 0.0176 | 36.7629 | 0.9753 | 6.37 | |
| RICE1 | 3 | 0.0144 | 0.0172 | 36.8485 | 0.9758 | 11.20 |
| 4 | 0.0143 | 0.0170 | 36.8870 | 0.9759 | 16.04 | |
| 5 | 0.0140 | 0.0167 | 37.0148 | 0.9763 | 20.87 | |
| 6 | 0.0140 | 0.0168 | 37.0274 | 0.9761 | 25.71 | |
| 1 | 0.0190 | 0.0249 | 35.4552 | 0.9087 | 4.57 | |
| 2 | 0.0183 | 0.0242 | 35.9103 | 0.9117 | 6.37 | |
| RICE2 | 3 | 0.0181 | 0.0241 | 36.1480 | 0.9123 | 11.20 |
| 4 | 0.0171 | 0.0226 | 36.4316 | 0.9134 | 16.04 | |
| 5 | 0.0170 | 0.0228 | 36.4466 | 0.9137 | 20.87 | |
| 6 | 0.0172 | 0.0230 | 36.4018 | 0.9136 | 25.71 | |
| 1 | 0.0392 | 0.0303 | 29.1369 | 0.8749 | 4.57 | |
| 2 | 0.0383 | 0.0297 | 29.4578 | 0.8820 | 6.37 | |
| T-Cloud | 3 | 0.0381 | 0.0293 | 29.7754 | 0.8824 | 11.20 |
| 4 | 0.0378 | 0.0297 | 29.8110 | 0.8904 | 16.04 | |
| 5 | 0.0363 | 0.0280 | 29.8753 | 0.8997 | 20.87 | |
| 6 | 0.0388 | 0.0302 | 29.2848 | 0.8848 | 25.71 |
| Dataset | Module | ||||||
|---|---|---|---|---|---|---|---|
| Baseline | FAB | NAB | |||||
| ✓ | × | × | 0.0155 | 0.0187 | 36.0884 | 0.9746 | |
| RICE1 | ✓ | × | ✓ | 0.0150 | 0.0183 | 36.2673 | 0.9744 |
| ✓ | ✓ | × | 0.0149 | 0.0176 | 36.8983 | 0.9754 | |
| ✓ | ✓ | ✓ | 0.0140 | 0.0167 | 37.0148 | 0.9763 | |
| ✓ | × | × | 0.0173 | 0.0235 | 35.7890 | 0.9091 | |
| RICE2 | ✓ | × | ✓ | 0.0176 | 0.0236 | 35.8661 | 0.9099 |
| ✓ | ✓ | × | 0.0172 | 0.0232 | 36.4391 | 0.9126 | |
| ✓ | ✓ | ✓ | 0.0170 | 0.0228 | 36.4466 | 0.9137 | |
| ✓ | × | × | 0.0373 | 0.0295 | 29.5268 | 0.8036 | |
| T-Cloud | ✓ | × | ✓ | 0.0367 | 0.0291 | 29.5521 | 0.8367 |
| ✓ | ✓ | × | 0.0382 | 0.0295 | 29.4303 | 0.8208 | |
| ✓ | ✓ | ✓ | 0.0363 | 0.0280 | 29.8753 | 0.8997 | |
| Dataset | Module | ||||||
|---|---|---|---|---|---|---|---|
| ✓ | × | × | 0.0153 | 0.0181 | 36.5095 | 0.9749 | |
| RICE1 | ✓ | × | ✓ | 0.0152 | 0.0179 | 36.6615 | 0.9750 |
| ✓ | ✓ | × | 0.0142 | 0.0169 | 36.9770 | 0.9763 | |
| ✓ | ✓ | ✓ | 0.0140 | 0.0167 | 37.0148 | 0.9763 | |
| ✓ | × | × | 0.0173 | 0.0233 | 36.2906 | 0.9188 | |
| RICE2 | ✓ | × | ✓ | 0.0169 | 0.0229 | 36.3693 | 0.9119 |
| ✓ | ✓ | × | 0.0166 | 0.0229 | 36.3726 | 0.9128 | |
| ✓ | ✓ | ✓ | 0.0170 | 0.0228 | 36.4466 | 0.9137 | |
| ✓ | × | × | 0.0412 | 0.0319 | 28.7120 | 0.8658 | |
| T-Cloud | ✓ | × | ✓ | 0.0388 | 0.0299 | 29.1978 | 0.8071 |
| ✓ | ✓ | × | 0.0415 | 0.0321 | 28.6515 | 0.7917 | |
| ✓ | ✓ | ✓ | 0.0363 | 0.0280 | 29.8753 | 0.8997 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, C.; Xu, F.; Li, X.; Wang, X.; Xu, Z.; Fang, Y.; Lyu, X. Multi-Stage Frequency Attention Network for Progressive Optical Remote Sensing Cloud Removal. Remote Sens. 2024, 16, 2867. https://doi.org/10.3390/rs16152867
Wu C, Xu F, Li X, Wang X, Xu Z, Fang Y, Lyu X. Multi-Stage Frequency Attention Network for Progressive Optical Remote Sensing Cloud Removal. Remote Sensing. 2024; 16(15):2867. https://doi.org/10.3390/rs16152867
Chicago/Turabian StyleWu, Caifeng, Feng Xu, Xin Li, Xinyuan Wang, Zhennan Xu, Yiwei Fang, and Xin Lyu. 2024. "Multi-Stage Frequency Attention Network for Progressive Optical Remote Sensing Cloud Removal" Remote Sensing 16, no. 15: 2867. https://doi.org/10.3390/rs16152867
APA StyleWu, C., Xu, F., Li, X., Wang, X., Xu, Z., Fang, Y., & Lyu, X. (2024). Multi-Stage Frequency Attention Network for Progressive Optical Remote Sensing Cloud Removal. Remote Sensing, 16(15), 2867. https://doi.org/10.3390/rs16152867