

Multi-Scale Classification and Contrastive Regularization: Weakly Supervised Large-Scale 3D Point Cloud Semantic Segmentation


Abstract
1. Introduction
- We propose MCCR, an end-to-end weakly supervised point cloud semantic segmentation network that combines multiple strategies to obtain better results with only 0.1% annotation.
- We introduce multi-scale classification to comprehensively capture the complex features in large-scale point clouds, thereby improving classification accuracy.
- We incorporate contrastive regularization to extract more stable local features, thereby enhancing 3D semantic scene understanding tasks.
- Our proposed MCCR shows a significant improvement over baselines on our benchmark and reaches state-of-the-art performance.
2. Related Work
2.1. Fully Supervised Point Cloud Semantic Segmentation
2.2. Weakly Supervised Point Cloud Semantic Segmentation
2.2.1. Two-Dimensional Label-Based Methods
2.2.2. Pseudo 3D Label-Based Methods
2.2.3. Limited 3D Label-Based Methods
2.3. Unsupervised Point Cloud Semantic Segmentation
3. Method
3.1. Overview
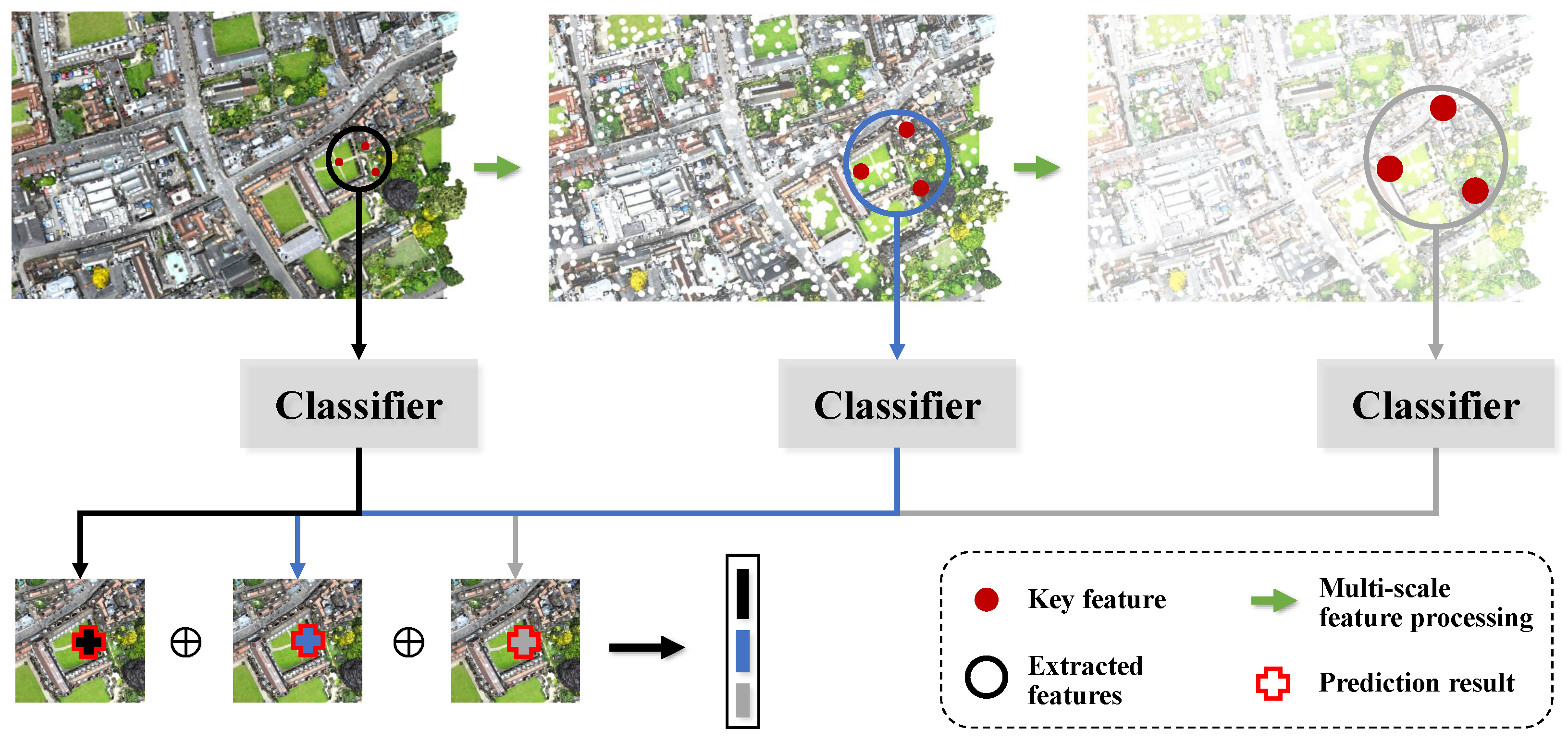
3.2. Multi-Scale Classification
3.3. Contrastive Regularization
3.3.1. Point-Level Contrastive Regularization
3.3.2. Local Contrastive Regularization
3.3.3. Decoupling Layer
3.4. Loss Functions
4. Experimental Results
4.1. Implementation Details
4.2. Evaluation Metrics
4.3. Comparison with SOTA Methods on Large-Scale Datasets
4.3.1. Evaluation on SemanticKITTI
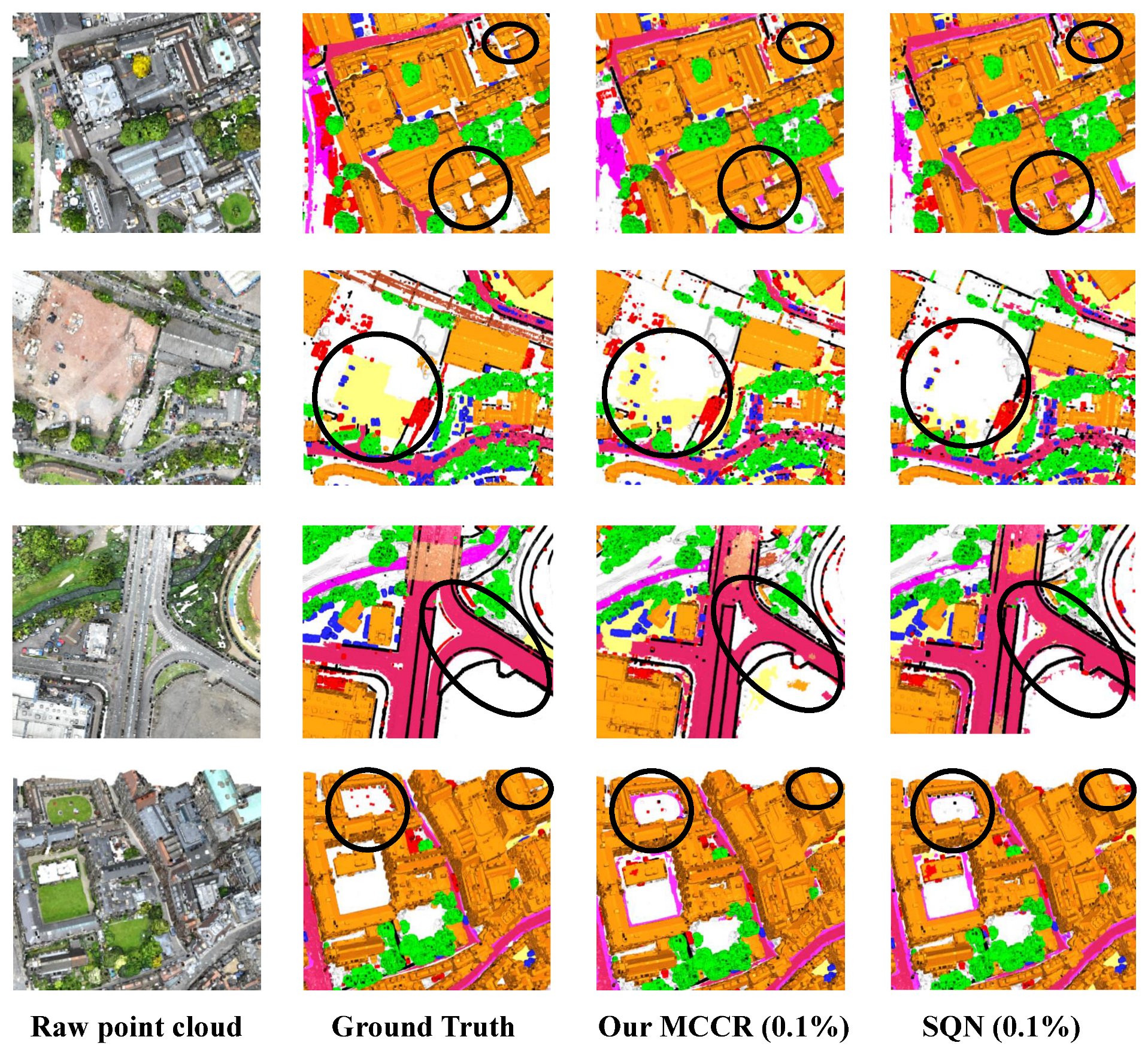
4.3.2. Evaluation on SensatUrban
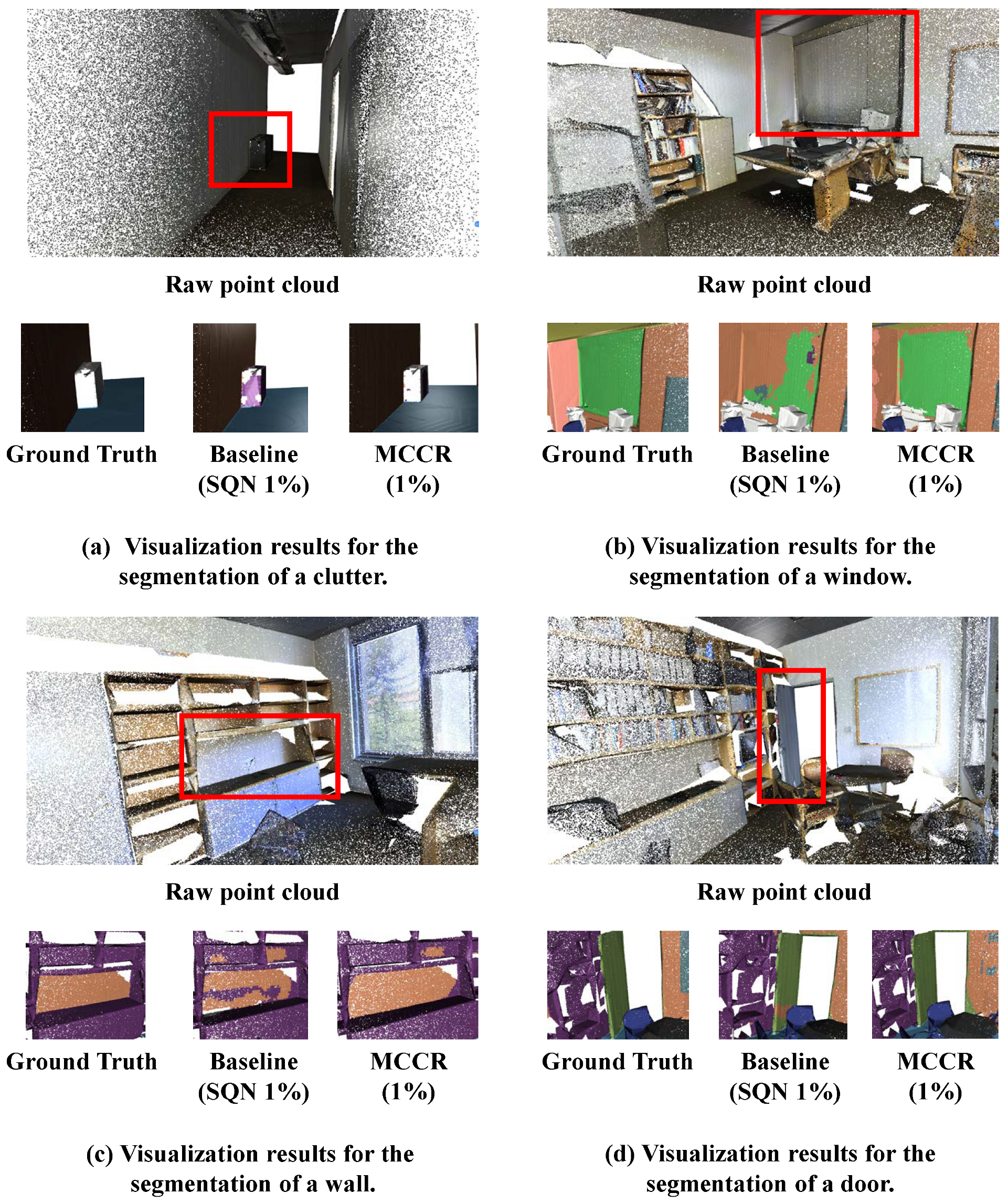
4.3.3. Evaluation on Large Indoor Dataset S3DIS
5. Discussion
5.1. Visualization Study of the Results on Indoor Dataset
5.2. Ablation Study
5.2.1. Effectiveness of the Designed Trilinear Interpolation Weights
5.2.2. Effectiveness of Contrastive Regularization
5.2.3. Effectiveness of Multi-Scale Classification
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| MCCR | Multi-scale Classification and Contrastive Regularization |
| MLPs | Multilayer perceptrons |
| SOTA | State of the art |
| BN | Batch normalization |
| LFA | Local feature aggregation |
| RS | Random sampling |
| DC | Decoupling Layer |
| CE | Cross-entropy |
References
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30, 5105–5114. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Randla-net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11108–11117. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6411–6420. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Wang, Y.; Zhang, J.; Kan, M.; Shan, S.; Chen, X. Self-supervised equivariant attention mechanism for weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12275–12284. [Google Scholar]
- Wang, J.; Liu, Y.; Tan, H.; Zhang, M. A survey on weakly supervised 3D point cloud semantic segmentation. IET Comput. Vis. 2024, 18, 329–342. [Google Scholar] [CrossRef]
- Wang, H.; Rong, X.; Yang, L.; Wang, S.; Tian, Y. Towards Weakly Supervised Semantic Segmentation in 3D Graph-Structured Point Clouds of Wild Scenes. In Proceedings of the BMVC, Cardiff, UK, 9–12 September 2019; p. 284. [Google Scholar]
- Wang, B.H.; Chao, W.L.; Wang, Y.; Hariharan, B.; Weinberger, K.Q.; Campbell, M. LDLS: 3-D object segmentation through label diffusion from 2-D images. IEEE Robot. Autom. Lett. 2019, 4, 2902–2909. [Google Scholar] [CrossRef]
- Wang, H.; Rong, X.; Yang, L.; Feng, J.; Xiao, J.; Tian, Y. Weakly supervised semantic segmentation in 3d graph-structured point clouds of wild scenes. arXiv 2020, arXiv:2004.12498. [Google Scholar]
- Wei, J.; Lin, G.; Yap, K.H.; Hung, T.Y.; Xie, L. Multi-path region mining for weakly supervised 3D semantic segmentation on point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4384–4393. [Google Scholar]
- Cheng, M.; Hui, L.; Xie, J.; Yang, J. Sspc-net: Semi-supervised semantic 3d point cloud segmentation network. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 9–21 May 2021; Volume 35, pp. 1140–1147. [Google Scholar]
- Liu, Z.; Qi, X.; Fu, C.W. One thing one click: A self-training approach for weakly supervised 3d semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1726–1736. [Google Scholar]
- Wang, P.; Yao, W. A new weakly supervised approach for ALS point cloud semantic segmentation. ISPRS J. Photogramm. Remote Sens. 2022, 188, 237–254. [Google Scholar]
- Mei, J.; Gao, B.; Xu, D.; Yao, W.; Zhao, X.; Zhao, H. Semantic segmentation of 3d lidar data in dynamic scene using semi-supervised learning. IEEE Trans. Intell. Transp. Syst. 2019, 21, 2496–2509. [Google Scholar] [CrossRef]
- Wei, J.; Lin, G.; Yap, K.H.; Liu, F.; Hung, T.Y. Dense supervision propagation for weakly supervised semantic segmentation on 3d point clouds. arXiv 2021, arXiv:2107.11267. [Google Scholar] [CrossRef]
- Xu, X.; Lee, G.H. Weakly supervised semantic point cloud segmentation: Towards 10x fewer labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13706–13715. [Google Scholar]
- Li, M.; Xie, Y.; Shen, Y.; Ke, B.; Qiao, R.; Ren, B.; Lin, S.; Ma, L. Hybridcr: Weakly-supervised 3d point cloud semantic segmentation via hybrid contrastive regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14930–14939. [Google Scholar]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. Semantickitti: A dataset for semantic scene understanding of lidar sequences. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9297–9307. [Google Scholar]
- Hu, Q.; Yang, B.; Khalid, S.; Xiao, W.; Trigoni, N.; Markham, A. Sensaturban: Learning semantics from urban-scale photogrammetric point clouds. Int. J. Comput. Vis. 2022, 130, 316–343. [Google Scholar] [CrossRef]
- Armeni, I.; Sener, O.; Zamir, A.R.; Jiang, H.; Brilakis, I.; Fischer, M.; Savarese, S. 3d semantic parsing of large-scale indoor spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1534–1543. [Google Scholar]
- Kundu, A.; Yin, X.; Fathi, A.; Ross, D.; Brewington, B.; Funkhouser, T.; Pantofaru, C. Virtual multi-view fusion for 3d semantic segmentation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXIV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 518–535. [Google Scholar]
- Dai, A.; Nießner, M. 3dmv: Joint 3d-multi-view prediction for 3d semantic scene segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 452–468. [Google Scholar]
- Choy, C.; Gwak, J.; Savarese, S. 4d spatio-temporal convnets: Minkowski convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3075–3084. [Google Scholar]
- Graham, B.; Engelcke, M.; Van Der Maaten, L. 3d semantic segmentation with submanifold sparse convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9224–9232. [Google Scholar]
- Jiang, M.; Wu, Y.; Zhao, T.; Zhao, Z.; Lu, C. Pointsift: A sift-like network module for 3d point cloud semantic segmentation. arXiv 2018, arXiv:1807.00652. [Google Scholar]
- Chen, L.Z.; Li, X.Y.; Fan, D.P.; Wang, K.; Lu, S.P.; Cheng, M.M. LSANet: Feature learning on point sets by local spatial aware layer. arXiv 2019, arXiv:1905.05442. [Google Scholar]
- Phan, A.V.; Le Nguyen, M.; Nguyen, Y.L.H.; Bui, L.T. Dgcnn: A convolutional neural network over large-scale labeled graphs. Neural Netw. 2018, 108, 533–543. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. Pointcnn: Convolution on x-transformed points. Adv. Neural Inf. Process. Syst. 2018, 31, 828–838. [Google Scholar]
- Wu, W.; Qi, Z.; Fuxin, L. Pointconv: Deep convolutional networks on 3d point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9621–9630. [Google Scholar]
- Lai, X.; Liu, J.; Jiang, L.; Wang, L.; Zhao, H.; Liu, S.; Qi, X.; Jia, J. Stratified transformer for 3d point cloud segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8500–8509. [Google Scholar]
- Landrieu, L.; Simonovsky, M. Large-scale point cloud semantic segmentation with superpoint graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4558–4567. [Google Scholar]
- Ma, Y.; Guo, Y.; Liu, H.; Lei, Y.; Wen, G. Global context reasoning for semantic segmentation of 3D point clouds. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 2931–2940. [Google Scholar]
- Zhiheng, K.; Ning, L. PyramNet: Point cloud pyramid attention network and graph embedding module for classification and segmentation. arXiv 2019, arXiv:1906.03299. [Google Scholar]
- Tao, A.; Duan, Y.; Wei, Y.; Lu, J.; Zhou, J. Seggroup: Seg-level supervision for 3d instance and semantic segmentation. IEEE Trans. Image Process. 2022, 31, 4952–4965. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Zhang, Y.; Li, Z.; Xie, Y.; Qu, Y.; Li, C.; Mei, T. Weakly supervised semantic segmentation for large-scale point cloud. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 3421–3429. [Google Scholar]
- Shi, H.; Wei, J.; Li, R.; Liu, F.; Lin, G. Weakly supervised segmentation on outdoor 4D point clouds with temporal matching and spatial graph propagation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11840–11849. [Google Scholar]
- Liu, G.; van Kaick, O.; Huang, H.; Hu, R. Active self-training for weakly supervised 3D scene semantic segmentation. Comput. Vis. Media 2024, 10, 425–438. [Google Scholar] [CrossRef]
- Li, R.; Cao, A.Q.; de Charette, R. COARSE3D: Class-Prototypes for Contrastive Learning in Weakly-Supervised 3D Point Cloud Segmentation. arXiv 2022, arXiv:2210.01784. [Google Scholar]
- Wu, Z.; Wu, Y.; Lin, G.; Cai, J. Reliability-Adaptive Consistency Regularization for Weakly-Supervised Point Cloud Segmentation. Int. J. Comput. Vis. 2024, 132, 2276–2289. [Google Scholar] [CrossRef]
- Zhang, Y.; Qu, Y.; Xie, Y.; Li, Z.; Zheng, S.; Li, C. Perturbed self-distillation: Weakly supervised large-scale point cloud semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15520–15528. [Google Scholar]
- Hu, Q.; Yang, B.; Fang, G.; Guo, Y.; Leonardis, A.; Trigoni, N.; Markham, A. Sqn: Weakly-supervised semantic segmentation of large-scale 3d point clouds. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XXVII. Springer: Berlin/Heidelberg, Germany, 2022; pp. 600–619. [Google Scholar]
- Yang, C.K.; Wu, J.J.; Chen, K.S.; Chuang, Y.Y.; Lin, Y.Y. An mil-derived transformer for weakly supervised point cloud segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11830–11839. [Google Scholar]
- Han, X.F.; Cheng, H.; Jiang, H.; He, D.; Xiao, G. Pcb-randnet: Rethinking random sampling for lidar semantic segmentation in autonomous driving scene. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 4435–4441. [Google Scholar]
- Lee, M.S.; Yang, S.W.; Han, S.W. Gaia: Graphical information gain based attention network for weakly supervised point cloud semantic segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 582–591. [Google Scholar]
- Su, Y.; Xu, X.; Jia, K. Weakly supervised 3d point cloud segmentation via multi-prototype learning. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 7723–7736. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, J.; Ni, B.; Wang, H.; Yang, J.; Liu, N.; Li, T.; Tian, Q. Shape self-correction for unsupervised point cloud understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 8382–8391. [Google Scholar]
- Cho, J.H.; Mall, U.; Bala, K.; Hariharan, B. Picie: Unsupervised semantic segmentation using invariance and equivariance in clustering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16794–16804. [Google Scholar]
- Hoang, C.M.; Kang, B. Pixel-level clustering network for unsupervised image segmentation. Eng. Appl. Artif. Intell. 2024, 127, 107327. [Google Scholar] [CrossRef]
- Niu, D.; Wang, X.; Han, X.; Lian, L.; Herzig, R.; Darrell, T. Unsupervised universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 22744–22754. [Google Scholar]
- Chen, Z.; Xu, H.; Chen, W.; Zhou, Z.; Xiao, H.; Sun, B.; Xie, X.; Kang, W. PointDC: Unsupervised Semantic Segmentation of 3D Point Clouds via Cross-modal Distillation and Super-Voxel Clustering. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 14290–14299. [Google Scholar]
- Bian, Y.; Xie, J.; Qian, J. Unsupervised domain adaptive point cloud semantic segmentation. In Proceedings of the Asian Conference on Pattern Recognition, Jeju Island, Republic of Korea, 9–12 November 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 285–298. [Google Scholar]
- Zhang, Z.; Yang, B.; Wang, B.; Li, B. Growsp: Unsupervised semantic segmentation of 3d point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Paris, France, 2–3 October 2023; pp. 17619–17629. [Google Scholar]
- Xie, S.; Gu, J.; Guo, D.; Qi, C.R.; Guibas, L.; Litany, O. Pointcontrast: Unsupervised pre-training for 3d point cloud understanding. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part III 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 574–591. [Google Scholar]
- Hou, J.; Graham, B.; Nießner, M.; Xie, S. Exploring data-efficient 3d scene understanding with contrastive scene contexts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15587–15597. [Google Scholar]
- Luo, H.; Jiang, W.; Gu, Y.; Liu, F.; Liao, X.; Lai, S.; Gu, J. A strong baseline and batch normalization neck for deep person re-identification. IEEE Trans. Multimed. 2019, 22, 2597–2609. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mIoU (%) | |
|---|---|---|
| Full supervision | PointNet [1] | 14.6 |
| PointNet++ [2] | 20.1 | |
| SPG [32] | 17.4 | |
| KPConv [4] | 58.1 | |
| RandLA-Net [3] | 53.9 | |
| 1% | HybridCR [18] | 52.3 |
| 0.1% | SQN* | 51.5 |
| SQN [43] | 50.8 | |
| MCCR (Ours) | 52.9 |
| Method | OA (%) | mIoU (%) | |
|---|---|---|---|
| Full supervision | PointNet [1] | 80.8 | 23.7 |
| PointNet++ [2] | 84.3 | 32.9 | |
| SPGraph [32] | 85.3 | 37.3 | |
| SparseConv [25] | 88.7 | 42.7 | |
| KPConv [4] | 93.2 | 57.6 | |
| RandLA-Net [3] | 89.8 | 52.7 | |
| 0.1% | SQN* | 91.3 | 55.0 |
| SQN [43] | 91.0 | 54.0 | |
| MCCR (Ours) | 92.8 | 59.6 |
| Method | mIoU (%) | Ceiling | Floor | Wall | Beam | Column | Window | Door | Table | Chair | Sofa | Bookcase | Board | Clutter | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Full supervision | PointNet [1] | 41.1 | 88.8 | 97.3 | 69.8 | 0.1 | 3.9 | 46.3 | 10.8 | 58.9 | 52.6 | 5.9 | 40.3 | 26.4 | 33.2 |
| SPG [32] | 54.7 | 91.5 | 97.9 | 75.9 | 0.0 | 14.3 | 51.3 | 52.3 | 77.4 | 86.4 | 40.4 | 65.5 | 7.2 | 50.7 | |
| KPConv [4] | 67.1 | 92.8 | 97.3 | 82.4 | 0.0 | 23.9 | 58.0 | 69.0 | 91.0 | 81.5 | 75.3 | 75.4 | 66.7 | 58.9 | |
| RandLA-Net [3] | 63.0 | 92.4 | 96.7 | 80.6 | 0.0 | 18.3 | 61.3 | 43.3 | 77.2 | 85.2 | 71.5 | 71.0 | 69.2 | 52.3 | |
| 10% | Xu and Lee [17] | 48.0 | 90.9 | 97.3 | 74.8 | 0.0 | 8.4 | 49.3 | 27.3 | 71.7 | 69.0 | 53.2 | 16.5 | 23.3 | 42.8 |
| 1% | Zhang et al. [37] | 61.8 | 91.5 | 96.9 | 80.6 | 0.0 | 18.2 | 58.1 | 47.2 | 75.8 | 85.7 | 65.2 | 68.9 | 65.0 | 50.2 |
| PSD [42] | 63.5 | 92.3 | 97.7 | 80.7 | 0.0 | 27.8 | 56.2 | 62.5 | 78.7 | 84.1 | 63.1 | 70.4 | 58.9 | 53.2 | |
| SQN* [43] | 64.9 | 93.5 | 97.2 | 82.2 | 0.0 | 24.1 | 56.7 | 67.0 | 78.0 | 87.5 | 69.1 | 70.7 | 63.3 | 54.5 | |
| MCCR (Ours) | 65.7 | 93.2 | 97.7 | 83.5 | 0.0 | 30.4 | 60.2 | 72.7 | 79.8 | 86.6 | 57.4 | 73.8 | 63.3 | 56.2 | |
| 0.2% | Xu and Lee [17] | 44.5 | 90.1 | 97.1 | 71.9 | 0.0 | 1.9 | 47.2 | 29.3 | 64.0 | 62.9 | 42.2 | 15.9 | 18.9 | 37.5 |
| 0.1% | SQN* | 59.47 | 90.36 | 96.71 | 78.75 | 0.00 | 12.09 | 54.92 | 64.14 | 70.78 | 81.72 | 50.39 | 68.53 | 55.80 | 48.93 |
| SQN [43] | 61.4 | 91.7 | 95.6 | 78.7 | 0.0 | 24.2 | 55.9 | 63.1 | 70.5 | 83.1 | 60.7 | 67.8 | 56.1 | 50.6 | |
| MCCR (Ours) | 61.47 | 92.33 | 96.64 | 79.94 | 0.00 | 24.26 | 55.17 | 61.51 | 71.96 | 84.76 | 57.49 | 69.43 | 53.96 | 51.67 |
| Method | OA (%) | mIoU (%) | |
|---|---|---|---|
| Full supervision | PointNet [1] | 78.6 | 47.6 |
| SPG [32] | 82.9 | 54.1 | |
| PointCNN [29] | 88.1 | 65.4 | |
| DGCNN [28] | \ | 56.1 | |
| KPConv [4] | \ | 70.6 | |
| RandLA-Net [3] | 88.0 | 70.0 | |
| 1% | Zhang et al. [37] | \ | 65.9 |
| PSD [42] | \ | 68.0 | |
| SQN* [43] | 87.4 | 67.3 | |
| MCCR (Ours) | 87.9 | 67.7 | |
| 0.1% | SQN* | 83.8 | 60.1 |
| SQN [43] | 85.3 | 63.7 | |
| MCCR (Ours) | 85.4 | 62.5 |
| Base. | NewWeights. | Contrast. | Multi. | OA (%) | mIoU (%) | |
|---|---|---|---|---|---|---|
| I | ✓ | 86.0 | 59.5 | |||
| II | ✓ | ✓ | 86.5 | 60.3 | ||
| III | ✓ | ✓ | 86.2 | 60.5 | ||
| IV | ✓ | ✓ | 86.7 | 60.7 | ||
| V | ✓ | ✓ | ✓ | 86.8 | 60.0 | |
| VI | ✓ | ✓ | ✓ | 85.8 | 58.5 | |
| VII | ✓ | ✓ | ✓ | 87.0 | 59.8 | |
| VIII | ✓ | ✓ | ✓ | ✓ | 86.9 | 61.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; He, J.; Liu, Y.; Chen, C.; Zhang, M.; Tan, H. Multi-Scale Classification and Contrastive Regularization: Weakly Supervised Large-Scale 3D Point Cloud Semantic Segmentation. Remote Sens. 2024, 16, 3319. https://doi.org/10.3390/rs16173319
Wang J, He J, Liu Y, Chen C, Zhang M, Tan H. Multi-Scale Classification and Contrastive Regularization: Weakly Supervised Large-Scale 3D Point Cloud Semantic Segmentation. Remote Sensing. 2024; 16(17):3319. https://doi.org/10.3390/rs16173319
Chicago/Turabian StyleWang, Jingyi, Jingyang He, Yu Liu, Chen Chen, Maojun Zhang, and Hanlin Tan. 2024. "Multi-Scale Classification and Contrastive Regularization: Weakly Supervised Large-Scale 3D Point Cloud Semantic Segmentation" Remote Sensing 16, no. 17: 3319. https://doi.org/10.3390/rs16173319
APA StyleWang, J., He, J., Liu, Y., Chen, C., Zhang, M., & Tan, H. (2024). Multi-Scale Classification and Contrastive Regularization: Weakly Supervised Large-Scale 3D Point Cloud Semantic Segmentation. Remote Sensing, 16(17), 3319. https://doi.org/10.3390/rs16173319