

Domain Adaptation for Satellite-Borne Multispectral Cloud Detection


Abstract
1. Introduction
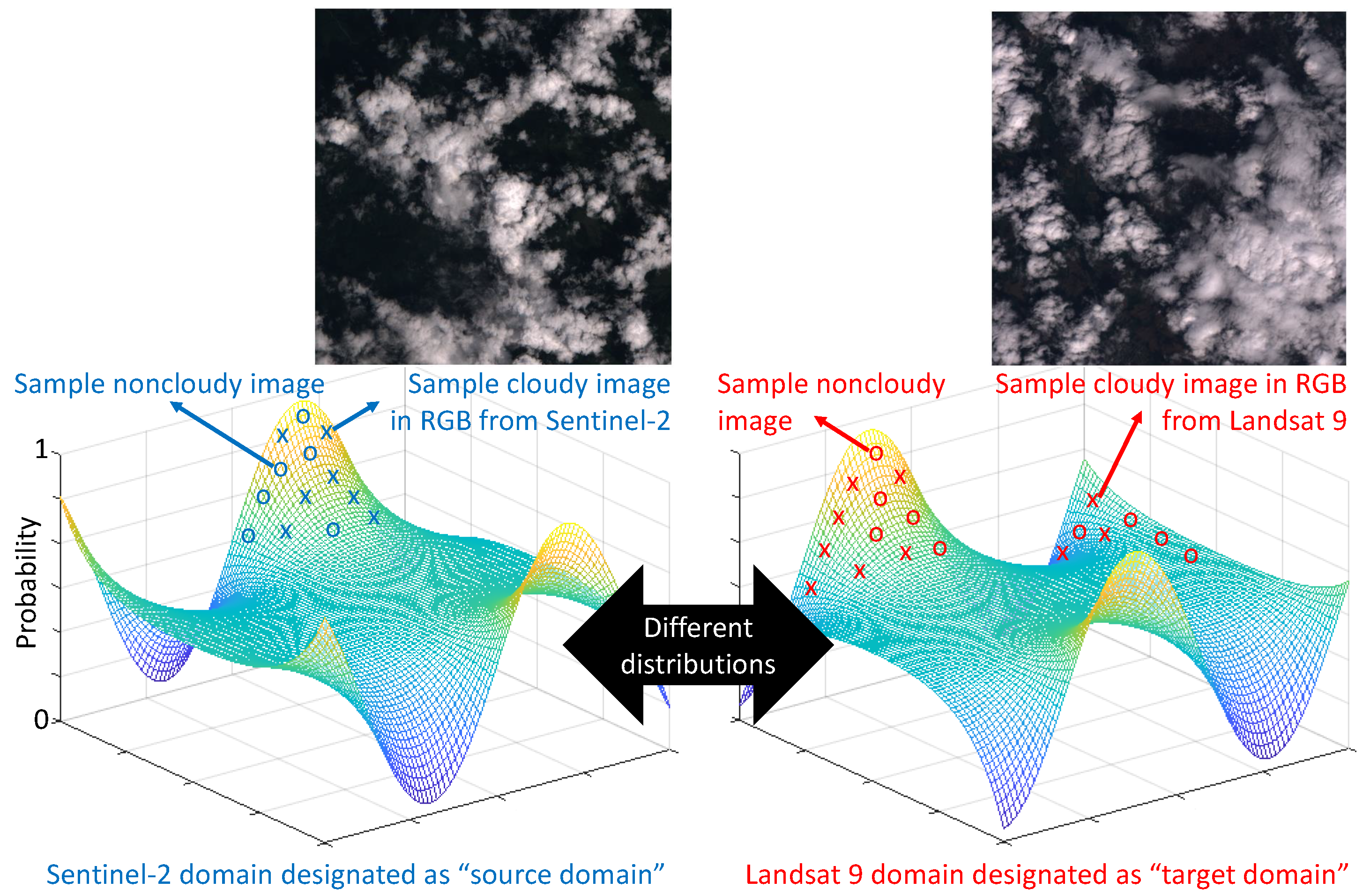
1.1. What Is the Domain Gap Problem?
- deviating from in what is known as the covariate shift,
- or less commonly, deviating from , or deviating from ,
- Sensor variations: Significant variations in sensor characteristics can occur between different models, especially when newer models are typically designed to improve upon older ones. For example, the multispectral instrument for the Sentinel-2 mission was designed to provide continuity of data products from the Landsat and SPOT missions, but it has narrower spectral bands compared to those used in the Landsat and SPOT missions to limit the influence of atmospheric constituents [11]. Even sensors of the same build can exhibit variations in many aspects; these aspects are discussed in detail in Appendix A.
- Environmental variations: Multi/hyperspectral measurements depend significantly on environmental conditions, and the conditions encountered during testing may not have been recorded in the training dataset. For example, plant phenotyping features in hyperspectral data vary with solar zenith angle, solar irradiation, temperature, humidity, wind speed and other environmental conditions [12]; these conditions may differ between the times when a plant feature prediction model is trained and when it is tested.
- Nature of manufacturing: EO sensors including multi/hyperspectral imagers are specialised instruments typically manufactured in low volumes. Nontrivial variations can also occur across different builds of the same sensor model due to manufacturing irregularities.
1.2. Challenges to Domain Adaptation in Satellite-Borne Machine Learning
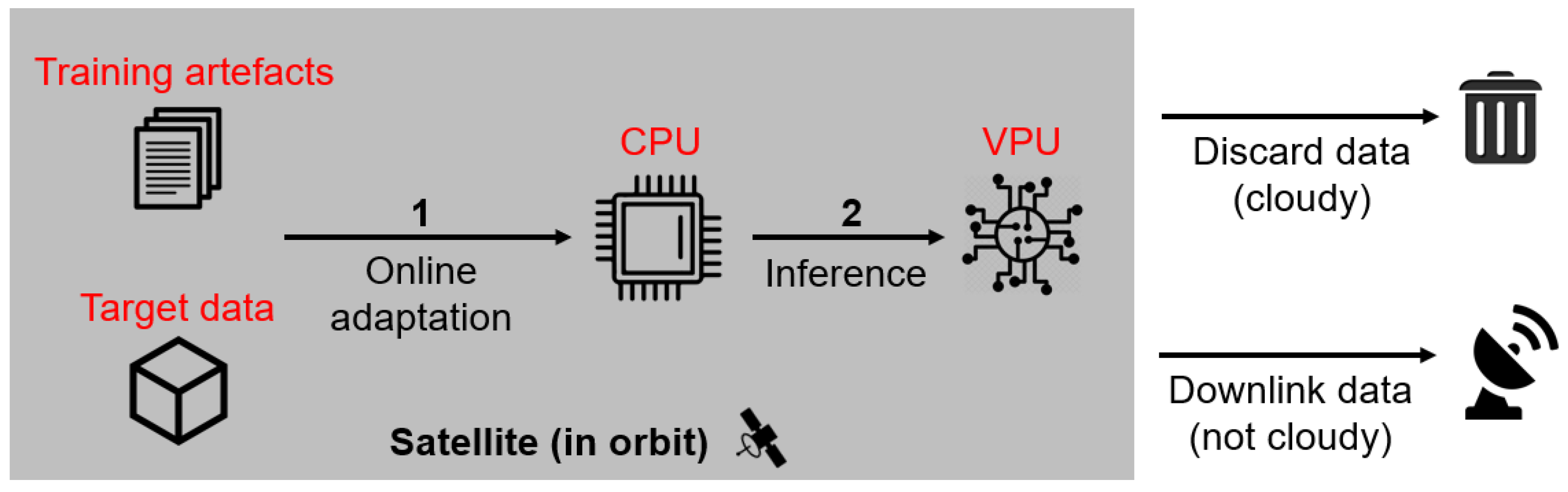
- Edge compute devices for satellite-borne machine learning are still much more limited in terms of compute capability relative to their desktop counterparts. For example, the EoT AI board [4], which features an Intel Myriad 2 vision processing unit (VPU), is targeted for accelerating machine learning inference. Furthermore, the onboard central processing unit (CPU) is typically catered for data acquisition and processing activities [6], not for training machine learning systems or using domain adaptation techniques that are computationally costly to run.
- The operational constraints of a space mission, particularly limited, unreliable and/or asymmetrical downlink/uplink bandwidths, lead to obstacles in data communication that affects domain adaptation, e.g., difficulties in procuring labelled target-domain data and remote updating of the model deployed in space.
1.3. Our Contributions
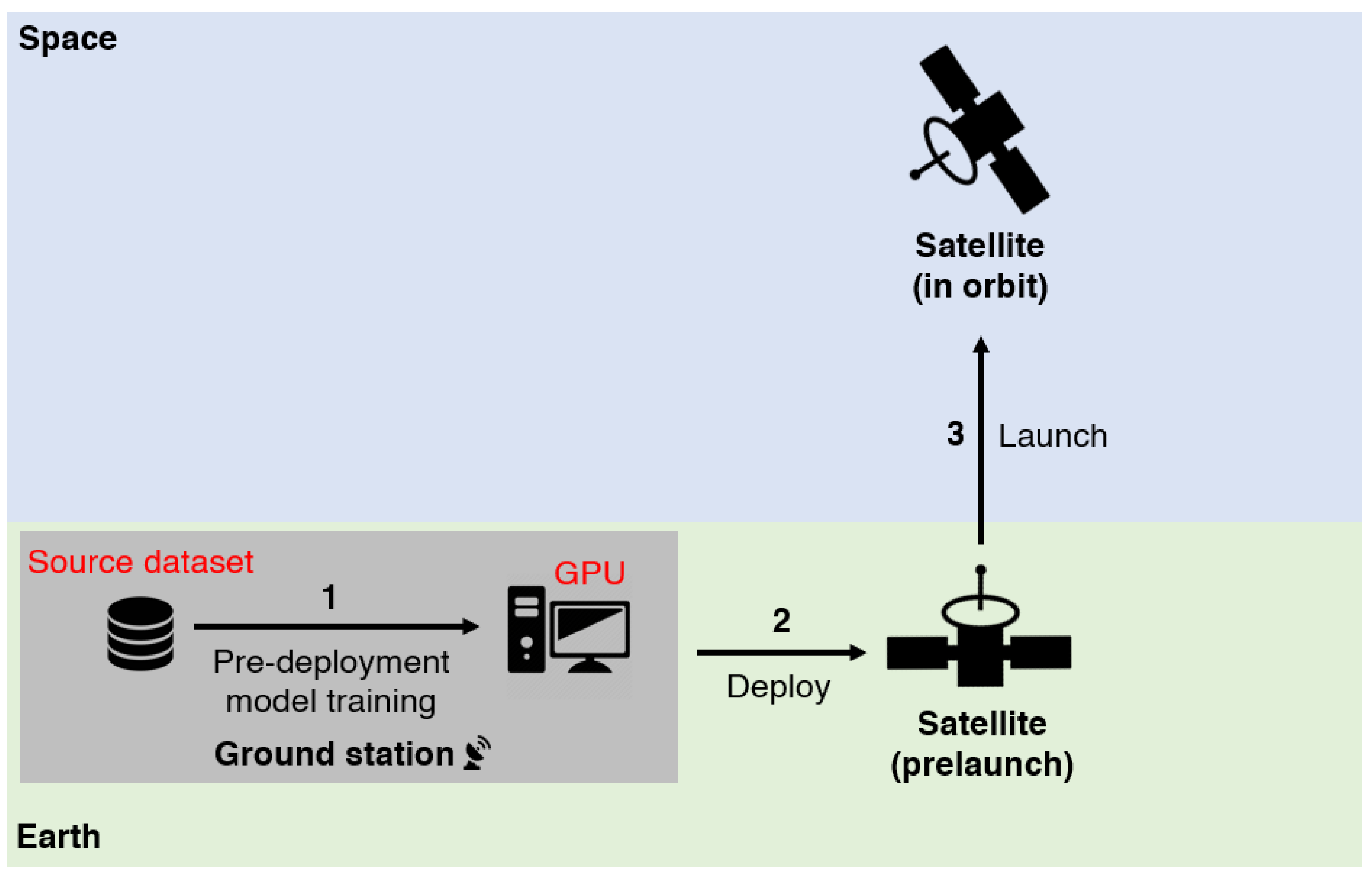
- We propose novel task definitions for domain adaptation, which we named offline adaptation and online adaptation, that are framed in the setting of an EO mission that conducts onboard machine learning inference.
- For offline adaptation, we propose a supervised domain adaptation (SDA) technique that allows a satellite-borne CNN to be remotely updated while consuming only a tiny fraction of the uplink bandwidth.
- For online adaptation, we demonstrate test-time adaptation (TTA) on a satellite-borne CNN hardware accelerator, specifically, the Ubotica CogniSAT-XE1 [13]. This shows that CNNs can be updated on realistic space hardware to account for the multispectral domain gap.
2. Related Work
2.1. Cloud Detection in EO Data
- Cloud detection, where typically the location and extent cloud coverage in a data cube are estimated;

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cloud Detector | Satellite | DNN Characteristics |
|---|---|---|
| CloudScout [5] | PhiSat-1 [2] | Classifies cloudiness per image using a six-layer CNN. |
| CloudScout segmentation network [6] | PhiSat-1 [2] | Classifies cloudiness per pixel using a variation of U-Net. |
| RaVAEn [38,39] | D-Orbit’s ION SCV004 [40] | Classifies cloudiness per tile of an image using a variational auto-encoder [41] in a few-shot learning manner. |
2.2. Domain Adaptation in Remote Sensing Applications
| Ref. | Source Dom. | Target Dom. | Characteristics | |
|---|---|---|---|---|
| SDA | [54] | PlanetScope | Sentinel-2 | An ensemble of three CNN models is pre-trained on the source data and fine-tuned on the target data. |
| [55] * | Landsat 8 | Proba-V | A U-Net-based CNN is trained on the source data and three images from the target domain. | |
| [42] | Sentinel-2 | D-Sense images | A CNN is trained on the source data and four images from the target domain. Model retraining happens on the ground and the entire updated model is uplinked to the satellite. | |
| UDA | [56] * | WorldView-2 | Sentinel-2 | A DeepLab-like [57] CNN is trained on the source data and adapted to the target domain through a Domain-Adversarial Neural Network [58]. |
| [59] * | Landsat 8 | Proba-V | A five-layer fully connected neural network is trained on an upscaled version of the source data, and adapted to the target domain through generative domain mapping [45], where a cycle-consistent generative adversarial network [60] maps target data to the upscaled source domain. | |
| [61] * | WorldView-2 Google Earth | Google Earth WorldView-2 | Image level: Pseudo-target-domain data generator fuses source-domain foreground information with target-domain background information. Feature level: (i) Global feature alignment based on domain discrimination reduces global domain shift. (ii) Decision optimisation based on self-ensembling consistency [62] reduces local domain shift. | |
| TTA | [63] | Dioni | HyRANK, Pavia | A 3D-CNN [64] is trained on the source data and adapted to the target domain through contrastive prototype generation and adaptation (CGPA) [65]. |
| [66] | Google Earth (rural) | Google Earth (urban) | Attention-guided prompt tuning: Uses the encoder of a vision foundation model as the backbone network (with embedded target prompts) and the decoder of UperNet [67] as the segmentation head. Loss function is the cosine similarity between the source prototypes and target features filtered by the pseudo-labels (generated by the source-trained model) with high prediction confidence. Optimising the loss function trains source and target attention matrices to select layers that are relevant to the current task and target prompts to bring target features close to source features. |
- When source data are available for adapting the model to the target domain, this type of UDA is so-called conventional.
- When the source data are unavailable but a source model is available to be adapted to the target domain, this type of UDA is called source-free (unsupervised) domain adaptation (SFDA), or equivalently TTA. In theory, source-free supervised domain adaptation is feasible but practically meaningless. TTA is further discussed in Section TTA.
- Discrepancy-based methods perform statistical divergence alignment [45], i.e., match marginal or/and conditional distributions between domains by integrating into a DNN adaptation layer designed to minimise domain discrepancy in a latent feature space. See [46] for a survey of applications of discrepancy-based UDA to EO image classification.
- Adversarial-learning methods learn transferable and domain-invariant features through adversarial learning. A well-known method is using a domain-adversarial neural network (DANN) [58], which comprises a feature extractor network connected to a label predictor and a domain classifier. Training the network parameters to (i) minimise the loss of the label predictor but (ii) maximise the loss of the domain classifier promotes the emergence of domain-invariant features. See [46] for a survey of applications of adversarial-learning UDA to EO image classification.
TTA
- Test-time Entropy Minimization (Tent) [69]: This method adapts a probabilistic and differentiable model by minimising the Shannon entropy of its predictions. For each batch normalisation (BN) [70] layer in a DNN, Tent updates (i) the normalisation statistics in the forward pass, and (ii) the affine transformation parameters in the backward pass. See Section 6.2.2 for more details.
- Dynamic Unsupervised Adaptation (DUA) [71]: This method modulates the “momentum” of BN layers with a decay parameter, which helps stabilise the adaptation process. See Section 6.2.1 for more details. DUA shows similar adaptation performance to Tent [71].
3. Domain Adaptation Tasks for EO Mission
3.1. Cloud Detection on PhiSat-1
3.2. Pre-Deployment Model Training
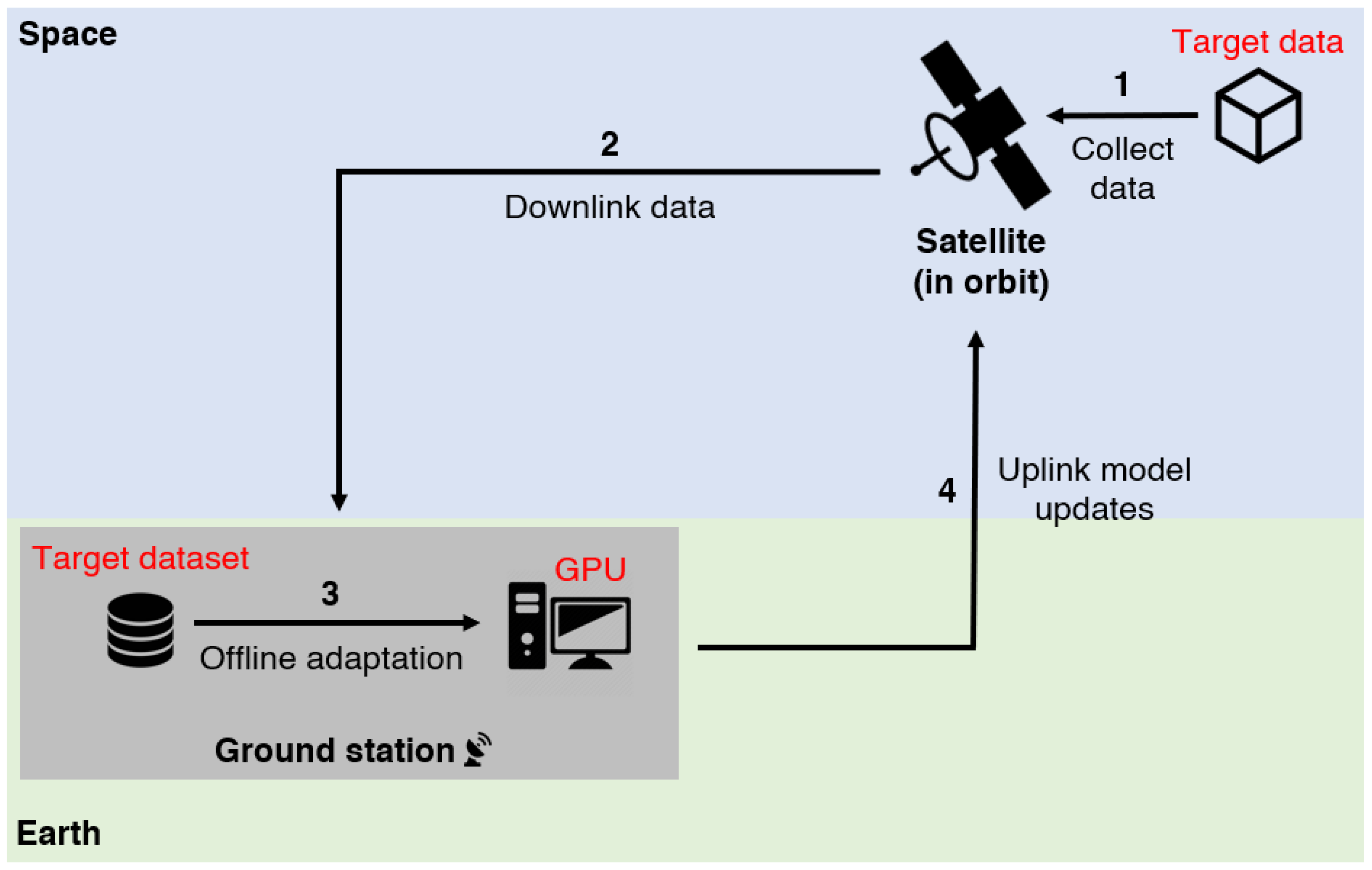
3.3. Post-Deployment Domain Adaptation
3.3.1. Offline Adaptation
| Problem 1: Bandwidth-efficient SDA |
| Given labelled target dataset and source cloud detector , update using by making as few changes to the source weights as possible. |
3.3.2. Online Adaptation
| Problem 2: TTA on satellite hardware |
| Given unlabelled target dataset and source cloud detector , update using in a runtime environment suitable for satellite-borne edge compute hardware. |
4. Constructing the Multispectral Datasets
4.1. Sentinel-2
4.2. Landsat 9
4.3. Ground-Truth Labels and Their Usage
5. Building the Cloud Detector
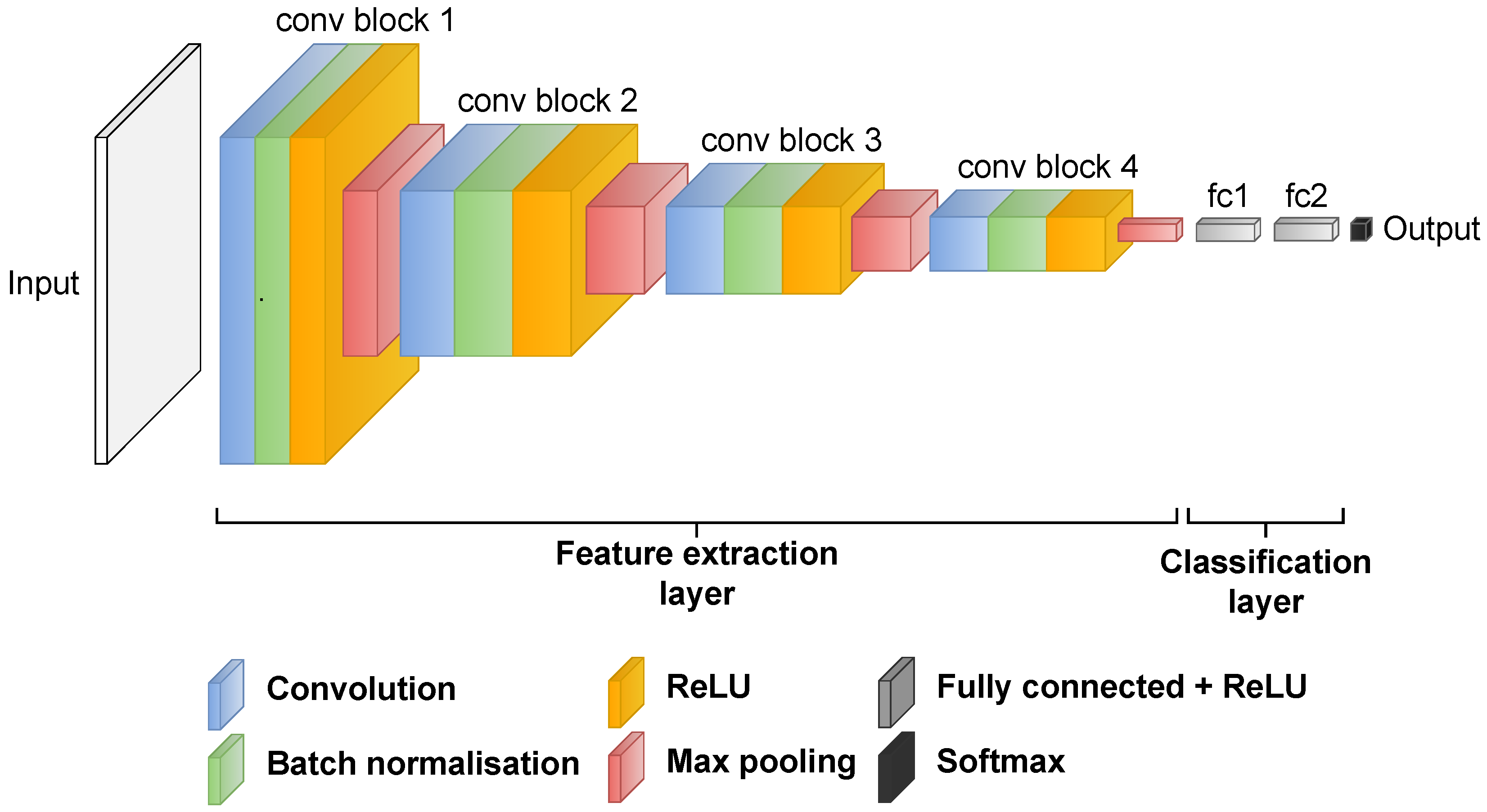
5.1. CNN Architectures for Cloud Detection
5.2. Training Cloud Detectors
6. Adapting the Cloud Detector to the Target Domain
6.1. Bandwidth-Efficient SDA
| Algorithm 1 Bandwidth-efficient SDA using FISH Mask |
for to do ▹ are parameters of ▹ Initialise ith element of empirical Fisher information vector for to do Get sample and associated ground-truth label end for end for parameters corresponding to the l largest elements of ▹l is mask sparsity level solution of Equation (6) ▹ gets uplinked to update |
6.2. TTA on Satellite Hardware
- The XE1 is a low-power edge processing device designed for SmallSat and CubeSat missions. It features the Intel Myriad 2 VPU and its main purpose is to accelerate machine learning inference.
- ORT was selected since it only requires ≈ 18.1 MB (version 1.15) of disk space and supports a wide range of operating systems and programming languages.

| Algorithm 2 TTA algorithm |
▹ Copy source weights to target weights ▹ Initialise current batch for to do if then end if end for |
6.2.1. DUA
6.2.2. Tent
7. Evaluation Platforms and Metrics
- Export the model to the ONNX format.
- Convert the generated ONNX files to the OpenVINO Intermediate Representation format.
- Convert the OpenVINO Intermediate Representation to the Ubotica Neural Network (UNN) format.
- Accuracy (ACC) of ,where is the indicator function, and . The higher the test accuracy means the higher predicts the correct class label. This helps in increasing the quality of each prediction, especially in challenging situations, e.g., clouds on ice or clouds on salt-lake.
- False positive (FP) rate of ,The lower the FP rate means the less incorrectly predicts non-cloudy data cubes as cloudy, which helps avoid discarding clear-sky data cubes.
8. Results
8.1. Domain Gap in Multispectral Data
- ARCH is the architecture of either CloudScout or ResNet50,
- NUMBANDS is either 3 or 8,
- SOURCE is either S2 for Sentinel-2 or L9 for Landsat 9.
- SAT is either S2 for Sentinel-2 or L9 for Landsat 9,
- SET is either TRAIN for training set or TEST for testing set.
- The domain gap is more prominent in cloud detectors trained on eight bands compared to their three-band counterparts; observe the difference in performance between CloudScout-3-S2 (ACC/FP of 66.40%/0.80%) and CloudScout-8-S2 (ACC/FP of 52.00%/ 48.00%) evaluated on the L9-TEST.
- The domain gap appears to be smaller in ResNet50 than CloudScout; observe the difference in performance between CloudScout-3-S2 (ACC/FP of 66.40%/0.80%) and ResNet50-3-S2 (ACC/FP of 90.80%/1.60%) evaluated on L9-TEST.
- Overall, the effects of the domain gap are significant, since it prevents machine learning models from performing as required by EO mission standards, e.g., CloudScout [5] requires a minimum ACC of 85% and maximum FP of 1.2%.
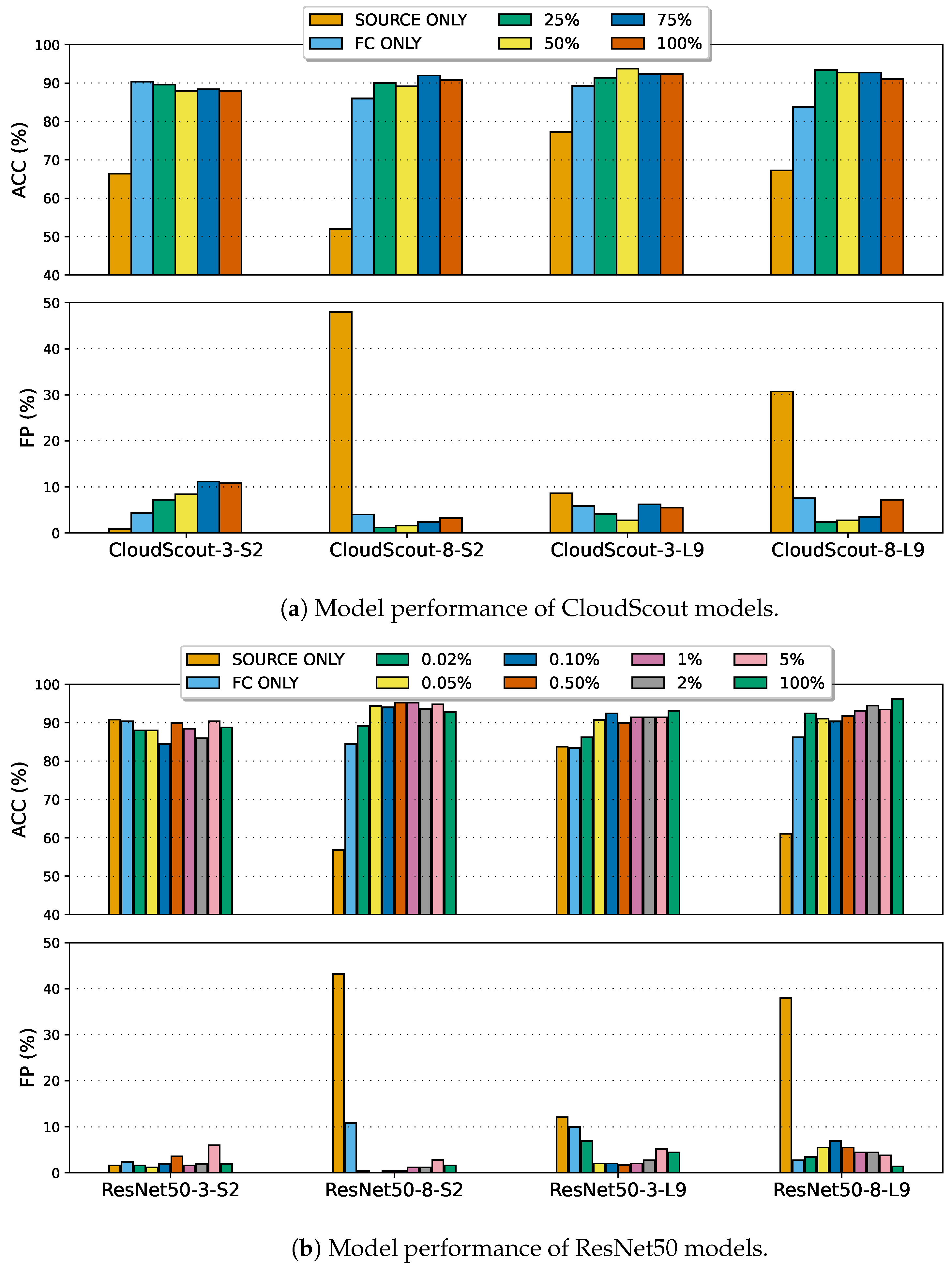
| (a) Cloud detectors trained on Sentinel-2 and evaluated on Landsat 9. | ||||||||
| S2-TRAIN | S2-TEST | L9-TEST | GAP | |||||
| Model Settings | ACC (%) | FP (%) | ACC (%) | FP (%) | ACC (%) | FP (%) | ACC (%) | FP (%) |
| CloudScout-3-S2 | 92.85 | 0.96 | 92.07 | 1.72 | 66.40 | 0.80 | 25.67 | 0.92 |
| CloudScout-8-S2 | 93.36 | 3.69 | 92.41 | 4.48 | 52.00 | 48.00 | 40.41 | 43.52 |
| ResNet50-3-S2 | 97.86 | 1.11 | 93.10 | 4.14 | 90.80 | 1.60 | 2.30 | 2.54 |
| ResNet50-8-S2 | 93.73 | 2.51 | 93.79 | 2.41 | 56.80 | 43.20 | 36.99 | 40.79 |
| (b) Cloud detectors trained on Landsat 9 and evaluated on Sentinel-2. | ||||||||
| L9-TRAIN | L9-TEST | S2-TEST | GAP | |||||
| Model settings | ACC (%) | FP (%) | ACC (%) | FP (%) | ACC (%) | FP (%) | ACC (%) | FP (%) |
| CloudScout-3-L9 | 88.49 | 0.52 | 85.60 | 2.00 | 77.24 | 8.62 | 8.36 | 6.62 |
| CloudScout-8-L9 | 92.61 | 3.78 | 88.80 | 4.40 | 67.24 | 30.69 | 21.56 | 26.29 |
| ResNet50-3-L9 | 95.10 | 2.66 | 90.80 | 4.40 | 83.79 | 12.07 | 7.01 | 7.67 |
| ResNet50-8-L9 | 98.20 | 1.80 | 93.60 | 4.80 | 61.03 | 37.93 | 32.57 | 33.13 |
8.2. Ablation Studies
8.2.1. Bandwidth-Efficient SDA
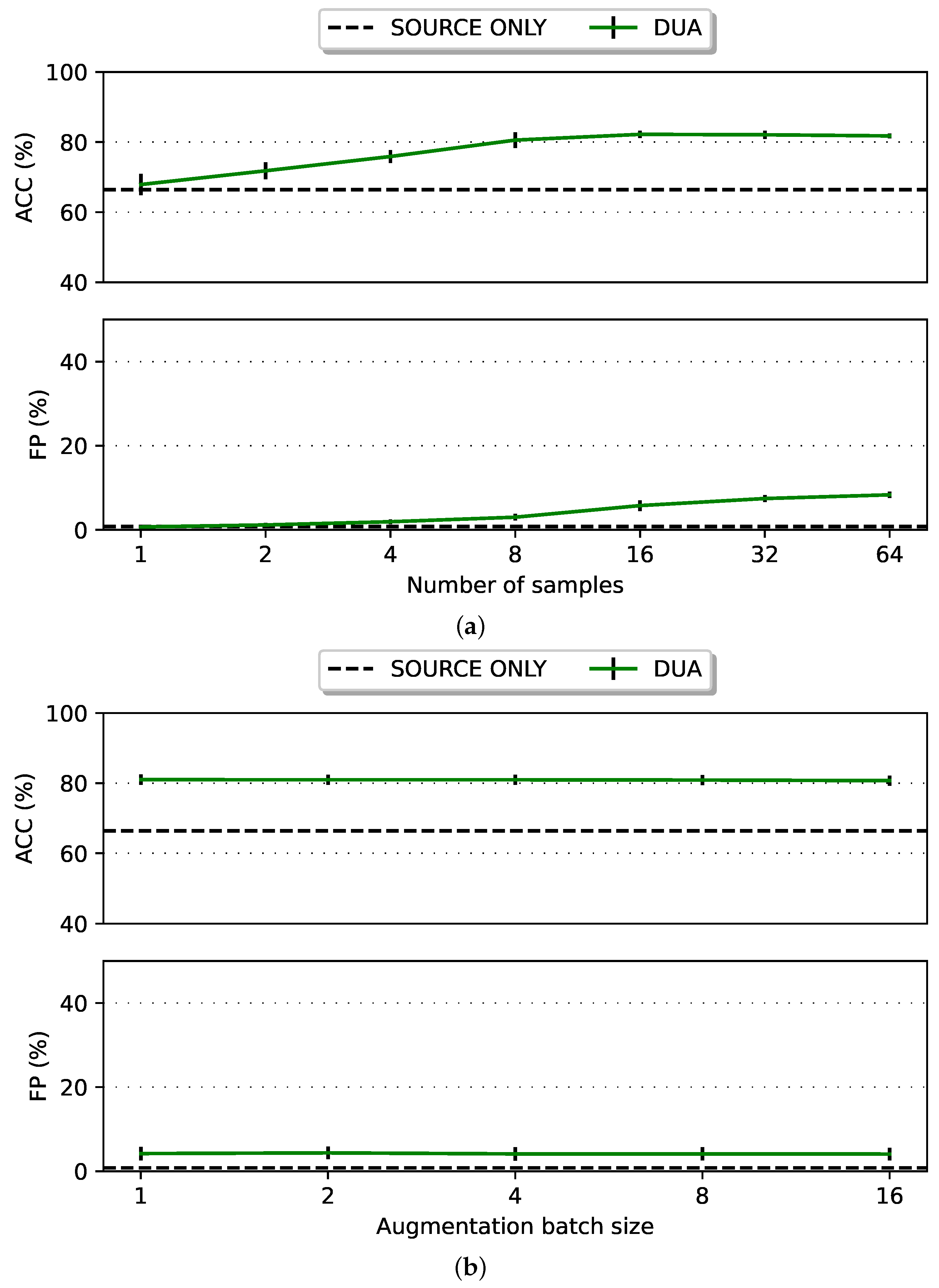
8.2.2. TTA on Satellite Hardware: DUA
- DUA utilises models pretrained on source-domain data. This pre-training helps a model learn general features that are often shared across different domains. As a result, the model requires only minor adjustments to adapt to the target domain, avoiding the need for a large amount of new data.
- The statistics of the source and target domain, such as the mean and variance, may exhibit a high degree of similarity. When these statistics are closely aligned, a model is efficiently transferable across domains, i.e., the model parameters can be adapted to a new domain using few new samples.
8.2.3. TTA on Satellite Hardware: Tent
- Small batches provide noisier gradient estimates because each batch is less representative of the overall data distribution. This noise in the gradient estimates can lead to more erratic updates to the model weights, causing oscillations in the loss curve, where the loss may fluctuate rather than decrease smoothly. Consequently, this instability in the training process can be observed to have produced spread in the ACC and FP.
- Larger batches provide more stable and accurate gradient estimates, which can lead to a smoother path to convergence and fewer FPs. However, as the results show, increasing the batch size too much can degrade the ACC on data aligned with the source distribution; this performance degradation is known as error accumulation and catastrophic forgetting in the literature [43].


8.3. Performance on Ubotica CogniSAT-XE1
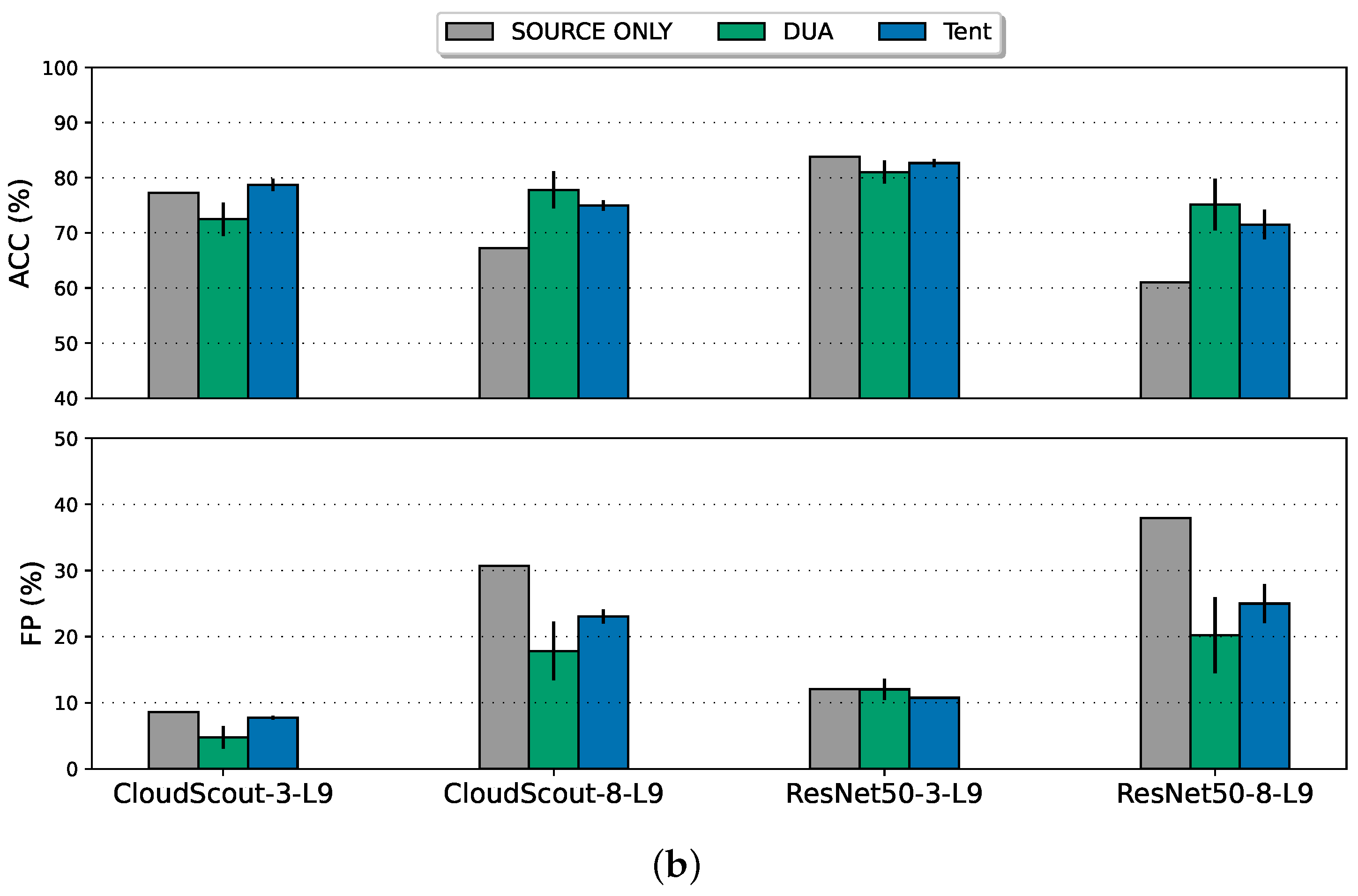
- For offline adaptation, we can solve Problem 1 in Section 3.3.1 by employing the FISH Mask and, thereby, enabling more sophisticated models to be deployed and updated remotely through the thin uplink channel. As expected, we found that this adaptation approach outperforms the TTA approaches by a large margin. Note that CloudScout and ResNet50 models with a mask sparsity level of 25% and 1%, respectively, were only evaluated here.
- For online adaptation, while Tent has a slight performance advantage in ACC over DUA, the advantage does not extend to FP rate, and furthermore, Tent is 60–100% more computationally expensive than DUA. Nevertheless, both TTA methods are evidently viable on satellite-borne edge compute hardware.
- Quantising the weights from FP32 to FP16 had negligible effects on model performance, as well as the added benefit of reducing the memory footprint by two-fold.
- ResNet50 models had a faster inference time (per sample) than CloudScout models, which is surprising since they are ≈18× larger in size.
9. Discussion
9.1. Preprocessing
9.2. Experimentation
- A Linux desktop: In an EO mission, this is limited to model training, but since there were minute differences in ACC and FP rate between a desktop-hosted version and an XE1-hosted version of the same model, the experimental results on ACC and FP rate in Figure 7, Figure 8, Figure 9, Figure 10 and Figure 11 were obtained on a Linux desktop. Realism was compromised in this setting, but the domain adaptation methods were evaluated and compared on an equal footing.
9.3. Performance of TTA
9.4. Extension to Hyperspectral Applications
9.5. Adapting to Constraints
- Energy constraint: Onboard machine learning can be computationally intensive and thus power-hungry, but EO satellites typically rely on photovoltaics and battery storage for energy supply. To avoid the risk of unrecoverable energy depletion, it is crucial to monitor the state of charge (SoC) of the battery and only perform power-hungry computation such as onboard updating of machine learning models when the SoC is at a sustainable level.
- Downlink bandwidth constraint: The time during which a satellite and a ground station are within communication range of each other, allowing the satellite to downlink its data to the ground station, is known as the communication window. The size of the communication window, the capacity of the communication channel (e.g., RF, optical) and environmental effects (e.g., multipath, atmospheric turbulence, space weather) determine the amount of data that can be downlinked; if this amount is less than how much the satellite needs to downlink, then the satellite should selectively downlink the data that improve domain adaptation the most. The detail of the selection strategy is a topic of our ongoing research.
- Uplink bandwidth constraint: The fact that uplink bandwidth is more limited than downlink bandwidth, as mentioned in Section 3.3.1, incentivises further conservation of uplink bandwidth by the bandwidth-efficient SDA method proposed in Section 6.1. A naive application of the proposed SDA method could see the ground station (i) executing the FISH Mask algorithm on the labelled target dataset to update the model weights and (ii) uploading the updated model weights defined by Equation (6) to the EO satellite during every communication window. However, valuable uplink bandwidth can be conserved if the FISH Mask algorithm is only executed on whenever the sum of losses exceeds a certain threshold. How this threshold can be set for a desired trade-off between domain gap and bandwidth usage is another topic of our ongoing research.
10. Conclusions and Future Study
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Acronyms
| ACC | accuracy |
| BN | batch normalisation |
| CNN | convolutional neural network |
| CPGA | contrastive prototype generation and adaptation |
| CPU | central processing unit |
| DANN | domain-adversarial neural network |
| DNN | deep neural network |
| DUA | dynamic unsupervised adaptation |
| EO | Earth observation |
| FISH | Fisher-Induced Sparse uncHanging |
| Fmask | Function of mask |
| FP | false positive |
| GPU | graphics processing unit |
| NDCI | normalised difference cloud index |
| ReLU | rectified linear unit |
| SDA | supervised domain adaptation |
| SNR | signal-to-noise ratio |
| SoC | state of charge |
| SSDA | semi-supervised domain adaptation |
| Tent | test-time entropy minimisation |
| TOA | top-of-atmosphere |
| TTA | test-time adaptation |
| UDA | unsupervised domain adaptation |
| UNN | Ubotica neural network |
| VPU | vision processing unit |
Appendix A. Additional Details on Sensor Variations
- Spectral band and spectral response: A spectral band is defined by (i) its wavelength range and (ii) the spectral response over this range. Spectral response is photocurrent level per incident light level, measured in ampere per watt, as a function of wavelength [88]. Wavelength ranges are typically selected to maximise object-to-background contrast; for example, Sentinel-2 uses a narrow band at 865 nm because iron-oxide soil exhibits an absorption band in the 850–900 nm region [11,89]. However, imagers configured to observe the same wavelength ranges can exhibit different spectral responses.
- Spatial resolution: This is a measure of the smallest angular or linear separation between two objects that can be resolved by the imager [89]. Equivalently, the spatial resolution is the area on the ground each pixel occupies. Spatial resolution can vary from one spectral band to another. Furthermore, imagers with the same spectral bands can provide different spatial resolutions.
- SNR: For a spectral band, the SNR is the mean of the measured radiances divided by their standard deviation [90]. Among the factors that determine the SNR are the sources of shot noise and thermal noise in the photodetector–preamplifier circuit [88]. SNR can vary from one spectral band to another. Imagers with the same spectral bands can have different SNRs.
- Calibration error and instrument drift: Imagers with the same spectral bands can be subject to different calibration errors and instrument drift characteristics. For example, brightness temperature data obtained from different geostationary meteorological satellites have been observed to vary for the same/similar scenes not only due to differences in the spectral characteristics but also due to calibration errors and sensor drift among these satellites [91].
Appendix B. Additional Results on Ubotica CogniSAT-XE1
- precision ,
- recall (note false negative rate = 1 − recall),
- F1-score .
| SOURCE ONLY | ||
| True | ||
| Predicted | Cloudy | Not Cloudy |
| Cloudy | TP: 17.20% | FP: 0.80% |
| Not cloudy | FN: 32.80% | TN: 49.20% |
| FISH Mask | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 46.80% | FP: 7.20% |
| Not cloudy | FN: 3.20% | TN: 42.80% |
| DUA | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 40.00% | FP: 6.40% |
| Not cloudy | FN: 10.00% | TN: 43.60% |
| Tent | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 36.40% | FP: 5.20% |
| Not cloudy | FN: 13.60% | TN: 44.80% |
| SOURCE ONLY | ||
| True | ||
| Predicted | Cloudy | Not Cloudy |
| Cloudy | TP: 50.00% | FP: 48.00% |
| Not cloudy | FN: 0.00% | TN: 2.00% |
| FISH Mask | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 41.20% | FP: 1.20% |
| Not cloudy | FN: 8.80% | TN: 48.80% |
| DUA | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 49.60% | FP: 40.00% |
| Not cloudy | FN: 0.40% | TN: 10.00% |
| Tent | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 48.40% | FP: 34.40% |
| Not cloudy | FN: 1.60% | TN: 15.60% |
| SOURCE ONLY | ||
| True | ||
| Predicted | Cloudy | Not Cloudy |
| Cloudy | TP: 42.40% | FP: 1.60% |
| Not cloudy | FN: 7.60% | TN: 48.40% |
| FISH Mask | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 40.00% | FP: 1.60% |
| Not cloudy | FN: 10.00% | TN: 48.40% |
| DUA | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 40.80% | FP: 2.00% |
| Not cloudy | FN: 9.20% | TN: 48.00% |
| Tent | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 46.00% | FP: 5.20% |
| Not cloudy | FN: 4.00% | TN: 44.80% |
| SOURCE ONLY | ||
| True | ||
| Predicted | Cloudy | Not Cloudy |
| Cloudy | TP: 50.00% | FP: 43.20% |
| Not cloudy | FN: 0.00% | TN: 6.80% |
| FISH Mask | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 46.40% | FP: 1.20% |
| Not cloudy | FN: 3.60% | TN: 48.80% |
| DUA | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 49.20% | FP: 30.80% |
| Not cloudy | FN: 0.80% | TN: 19.20% |
| Tent | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 48.00% | FP: 27.60% |
| Not cloudy | FN: 2.00% | TN: 22.40% |
| SOURCE ONLY | ||
| True | ||
| Predicted | Cloudy | Not Cloudy |
| Cloudy | TP: 35.86% | FP: 8.62% |
| Not cloudy | FN: 14.14% | TN: 41.38% |
| FISH Mask | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 45.52% | FP: 4.14% |
| Not cloudy | FN: 4.48% | TN: 45.86% |
| DUA | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 31.38% | FP: 6.21% |
| Not cloudy | FN: 18.62% | TN: 43.79% |
| Tent | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 34.14% | FP: 7.59% |
| Not cloudy | FN: 15.86% | TN: 42.41% |
| SOURCE ONLY | ||
| True | ||
| Predicted | Cloudy | Not Cloudy |
| Cloudy | TP: 47.93% | FP: 30.69% |
| Not cloudy | FN: 2.07% | TN: 19.31% |
| FISH Mask | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 45.86% | FP: 2.41% |
| Not cloudy | FN: 4.14% | TN: 47.59% |
| DUA | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 46.90% | FP: 18.62% |
| Not cloudy | FN: 3.10% | TN: 31.38% |
| Tent | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 47.24% | FP: 21.38% |
| Not cloudy | FN: 2.76% | TN: 28.62% |
| SOURCE ONLY | ||
| True | ||
| Predicted | Cloudy | Not Cloudy |
| Cloudy | TP: 45.86% | FP: 12.07% |
| Not cloudy | FN: 4.14% | TN: 37.93% |
| FISH Mask | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 43.45% | FP: 2.07% |
| Not cloudy | FN: 6.55% | TN: 47.93% |
| DUA | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 43.10% | FP: 11.72% |
| Not cloudy | FN: 6.90% | TN: 38.28% |
| Tent | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 43.10% | FP: 10.69% |
| Not cloudy | FN: 6.90% | TN: 39.31% |
| SOURCE ONLY | ||
| True | ||
| Predicted | Cloudy | Not Cloudy |
| Cloudy | TP: 48.97% | FP: 37.93% |
| Not cloudy | FN: 1.03% | TN: 12.07% |
| FISH Mask | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 47.59% | FP: 4.48% |
| Not cloudy | FN: 2.41% | TN: 45.52% |
| DUA | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 46.21% | FP: 19.31% |
| Not cloudy | FN: 3.79% | TN: 30.69% |
| Tent | ||
| True | ||
| Predicted | Cloudy | Not cloudy |
| Cloudy | TP: 46.21% | FP: 20.69% |
| Not cloudy | FN: 3.79% | TN: 29.31% |
References
- Euroconsult. Earth Observation Satellites Set to Triple over the Next Decade. 2024. Available online: https://www.euroconsult-ec.com/press-release/earth-observation-satellites-set-to-triple-over-the-next-decade/ (accessed on 11 September 2024).
- European Space Agency. PhiSat-1 Nanosatellite Mission. In Satellite Missions Catalogue, eoPortal; European Space Agency: Paris, France, 2020. [Google Scholar]
- Esposito, M.; Conticello, S.S.; Pastena, M.; Domínguez, B.C. In-orbit demonstration of artificial intelligence applied to hyperspectral and thermal sensing from space. In Proceedings of the CubeSats and SmallSats for Remote Sensing III, San Diego, CA, USA, 11–12 August 2019; Pagano, T.S., Norton, C.D., Babu, S.R., Eds.; International Society for Optics and Photonics. SPIE: Philadelphia, PA, USA, 2019; Volume 11131, p. 111310C. [Google Scholar] [CrossRef]
- Deniz, O.; Vallez, N.; Espinosa-Aranda, J.L.; Rico-Saavedra, J.M.; Parra-Patino, J.; Bueno, G.; Moloney, D.; Dehghani, A.; Dunne, A.; Pagani, A.; et al. Eyes of Things. Sensors 2017, 17, 1173. [Google Scholar] [CrossRef] [PubMed]
- Giuffrida, G.; Diana, L.; de Gioia, F.; Benelli, G.; Meoni, G.; Donati, M.; Fanucci, L. CloudScout: A Deep Neural Network for On-Board Cloud Detection on Hyperspectral Images. Remote Sens. 2020, 12, 2205. [Google Scholar] [CrossRef]
- Giuffrida, G.; Fanucci, L.; Meoni, G.; Batič, M.; Buckley, L.; Dunne, A.; van Dijk, C.; Esposito, M.; Hefele, J.; Vercruyssen, N.; et al. The Φ-Sat-1 Mission: The First On-Board Deep Neural Network Demonstrator for Satellite Earth Observation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5517414. [Google Scholar] [CrossRef]
- ESA. S2 Mission: Overview of Sentinel-2 Mission. SentiWiki. 2021. Available online: https://sentiwiki.copernicus.eu/web/s2-mission (accessed on 27 August 2024).
- Kouw, W.M.; Loog, M. An introduction to domain adaptation and transfer learning. arXiv 2019, arXiv:1812.11806. [Google Scholar] [CrossRef]
- ISO 24585-1:2023; Graphic Technology—Multispectral Imaging Measurement and Colorimetric Computation for Graphic Arts and Industrial Application—Part 1: Parameters and Measurement Methods. ISO: Geneva, Switzerland, 2023.
- Hagen, N.A.; Kudenov, M.W. Review of snapshot spectral imaging technologies. Opt. Eng. 2013, 52, 090901. [Google Scholar] [CrossRef]
- European Space Agency. Sentinel-2 User Handbook; Issue 1 Rev 2; European Space Agency: Paris, France, 2015. [Google Scholar]
- Ma, D.; Rehman, T.U.; Zhang, L.; Maki, H.; Tuinstra, M.R.; Jin, J. Modeling of Environmental Impacts on Aerial Hyperspectral Images for Corn Plant Phenotyping. Remote Sens. 2021, 13, 2520. [Google Scholar] [CrossRef]
- Ubotica. CogniSAT-XE1: AI and Computer Vision Edge Computing Platform Overview. 2023. Available online: https://ubotica.com/ubotica-cognisat-xe1/ (accessed on 7 February 2023).
- Jeppesen, J.H.; Jacobsen, R.H.; Inceoglu, F.; Toftegaard, T.S. A cloud detection algorithm for satellite imagery based on deep learning. Remote Sens. Environ. 2019, 229, 247–259. [Google Scholar] [CrossRef]
- Li, H.; Zheng, H.; Han, C.; Wang, H.; Miao, M. Onboard Spectral and Spatial Cloud Detection for Hyperspectral Remote Sensing Images. Remote Sens. 2018, 10, 152. [Google Scholar] [CrossRef]
- Li, X.; Wang, L.; Cheng, Q.; Wu, P.; Gan, W.; Fang, L. Cloud removal in remote sensing images using nonnegative matrix factorization and error correction. ISPRS J. Photogramm. Remote Sens. 2019, 148, 103–113. [Google Scholar] [CrossRef]
- Meraner, A.; Ebel, P.; Zhu, X.X.; Schmitt, M. Cloud removal in Sentinel-2 imagery using a deep residual neural network and SAR-optical data fusion. ISPRS J. Photogramm. Remote Sens. 2020, 166, 333–346. [Google Scholar] [CrossRef]
- Zi, Y.; Xie, F.; Zhang, N.; Jiang, Z.; Zhu, W.; Zhang, H. Thin Cloud Removal for Multispectral Remote Sensing Images Using Convolutional Neural Networks Combined with an Imaging Model. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2021, 14, 3811–3823. [Google Scholar] [CrossRef]
- Sinergise Laboratory. Cloud Masks. In Sentinel Hub User Guide; Sinergise Laboratory: Ljubljana, Slovenia, 2021. [Google Scholar]
- Marshak, A.; Knyazikhin, Y.; Davis, A.B.; Wiscombe, W.J.; Pilewskie, P. Cloud-vegetation interaction: Use of normalized difference cloud index for estimation of cloud optical thickness. Geophys. Res. Lett. 2000, 27, 1695–1698. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud shadow detection in Landsat imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Tang, B.H.; Shrestha, B.; Li, Z.L.; Liu, G.; Ouyang, H.; Gurung, D.R.; Giriraj, A.; Aung, K.S. Determination of snow cover from MODIS data for the Tibetan Plateau region. Int. J. Appl. Earth Obs. Geoinf. 2013, 21, 356–365. [Google Scholar] [CrossRef]
- Li, Z.; Shen, H.; Weng, Q.; Zhang, Y.; Dou, P.; Zhang, L. Cloud and cloud shadow detection for optical satellite imagery: Features, algorithms, validation, and prospects. ISPRS J. Photogramm. Remote Sens. 2022, 188, 89–108. [Google Scholar] [CrossRef]
- Mahajan, S.; Fataniya, B. Cloud detection methodologies: Variants and development—A review. Complex Intell. Syst. 2020, 6, 251–261. [Google Scholar] [CrossRef]
- López-Puigdollers, D.; Mateo-García, G.; Gómez-Chova, L. Benchmarking Deep Learning Models for Cloud Detection in Landsat-8 and Sentinel-2 Images. Remote Sens. 2021, 13, 992. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, W.; Li, Q.; Min, M.; Yao, Z. DCNet: A Deformable Convolutional Cloud Detection Network for Remote Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8013305. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Li, Z.; Shen, H.; Cheng, Q.; Liu, Y.; You, S.; He, Z. Deep learning based cloud detection for medium and high resolution remote sensing images of different sensors. ISPRS J. Photogramm. Remote Sens. 2019, 150, 197–212. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Mohajerani, S.; Krammer, T.A.; Saeedi, P. A Cloud Detection Algorithm for Remote Sensing Images Using Fully Convolutional Neural Networks. In Proceedings of the 2018 IEEE 20th International Workshop on Multimedia Signal Processing (MMSP), Vancouver, BC, Canada, 29–31 August 2018. [Google Scholar] [CrossRef]
- Yang, J.; Guo, J.; Yue, H.; Liu, Z.; Hu, H.; Li, K. CDnet: CNN-Based Cloud Detection for Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6195–6211. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, Y.; Wang, H.; Wu, J.; Li, Y. CNN Cloud Detection Algorithm Based on Channel and Spatial Attention and Probabilistic Upsampling for Remote Sensing Image. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5404613. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Griffin, M.; Burke, H.; Mandl, D.; Miller, J. Cloud cover detection algorithm for EO-1 Hyperion imagery. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Toulouse, France, 21–25 July 2003; Volume 1, pp. 86–89. [Google Scholar] [CrossRef]
- Du, A.; Law, Y.W.; Sasdelli, M.; Chen, B.; Clarke, K.; Brown, M.; Chin, T.J. Adversarial Attacks against a Satellite-borne Multispectral Cloud Detector. In Proceedings of the 2022 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Sydney, Australia, 30 November–2 December 2022. [Google Scholar] [CrossRef]
- Růžička, V.; Mateo-García, G.; Bridges, C.; Brunskill, C.; Purcell, C.; Longépé, N.; Markham, A. Fast model inference and training on-board of Satellites. In Proceedings of the International Geoscience and Remote Sensing Symposium, Pasadena, CA, USA, 16–21 July 2023. [Google Scholar]
- Růžička, V.; Vaughan, A.; De Martini, D.; Fulton, J.; Salvatelli, V.; Bridges, C.; Mateo-Garcia, G.; Zantedeschi, V. RaVÆn: Unsupervised change detection of extreme events using ML on-board satellites. Sci. Rep. 2022, 12, 16939. [Google Scholar] [CrossRef]
- D-Orbit. Dashing through the Stars Mission Booklet. 2023. Available online: https://www.dorbit.space/media/3/97.pdf (accessed on 25 April 2023).
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. version 11. arXiv 2022, arXiv:1312.6114. [Google Scholar]
- Mateo-Garcia, G.; Veitch-Michaelis, J.; Purcell, C.; Longepe, N.; Reid, S.; Anlind, A.; Bruhn, F.; Parr, J.; Mathieu, P.P. In-orbit demonstration of a re-trainable machine learning payload for processing optical imagery. Sci. Rep. 2023, 13, 10391. [Google Scholar] [CrossRef]
- Liang, J.; He, R.; Tan, T. A Comprehensive Survey on Test-Time Adaptation Under Distribution Shifts. In International Journal of Computer Vision; Springer: Berlin/Heidelberg, Germany, 2024. [Google Scholar] [CrossRef]
- Farahani, A.; Voghoei, S.; Rasheed, K.; Arabnia, H.R. A Brief Review of Domain Adaptation. In Proceedings of the Advances in Data Science and Information Engineering; Stahlbock, R., Weiss, G.M., Abou-Nasr, M., Yang, C.Y., Arabnia, H.R., Deligiannidis, L., Eds.; Springer: Cham, Switzerland, 2021; pp. 877–894. [Google Scholar]
- Liu, X.; Yoo, C.; Xing, F.; Oh, H.; Fakhri, G.E.; Kang, J.W.; Woo, J. Deep Unsupervised Domain Adaptation: A Review of Recent Advances and Perspectives. Apsipa Trans. Signal Inf. Process. 2022, 11, e25. [Google Scholar] [CrossRef]
- Peng, J.; Huang, Y.; Sun, W.; Chen, N.; Ning, Y.; Du, Q. Domain Adaptation in Remote Sensing Image Classification: A Survey. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2022, 15, 9842–9859. [Google Scholar] [CrossRef]
- Zhang, L.; Gao, X. Transfer Adaptation Learning: A Decade Survey. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 23–44. [Google Scholar] [CrossRef]
- Fang, Y.; Yap, P.T.; Lin, W.; Zhu, H.; Liu, M. Source-free unsupervised domain adaptation: A survey. Neural Netw. 2024, 174, 106230. [Google Scholar] [CrossRef] [PubMed]
- Singhal, P.; Walambe, R.; Ramanna, S.; Kotecha, K. Domain Adaptation: Challenges, Methods, Datasets, and Applications. IEEE Access 2023, 11, 6973–7020. [Google Scholar] [CrossRef]
- Li, J.; Yu, Z.; Du, Z.; Zhu, L.; Shen, H.T. A Comprehensive Survey on Source-Free Domain Adaptation. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 5743–5762. [Google Scholar] [CrossRef] [PubMed]
- Kellenberger, B.; Tasar, O.; Bhushan Damodaran, B.; Courty, N.; Tuia, D. Deep Domain Adaptation in Earth Observation. In Deep Learning for the Earth Sciences; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2021; Chapter 7; pp. 90–104. [Google Scholar] [CrossRef]
- Zhou, K.; Liu, Z.; Qiao, Y.; Xiang, T.; Loy, C.C. Domain Generalization: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 4396–4415. [Google Scholar] [CrossRef] [PubMed]
- Lucas, B.; Pelletier, C.; Schmidt, D.; Webb, G.I.; Petitjean, F. A Bayesian-inspired, deep learning-based, semi-supervised domain adaptation technique for land cover mapping. Mach. Learn. 2023, 112, 1941–1973. [Google Scholar] [CrossRef]
- Shendryk, Y.; Rist, Y.; Ticehurst, C.; Thorburn, P. Deep learning for multi-modal classification of cloud, shadow and land cover scenes in PlanetScope and Sentinel-2 imagery. ISPRS J. Photogramm. Remote Sens. 2019, 157, 124–136. [Google Scholar] [CrossRef]
- Mateo-García, G.; Laparra, V.; López-Puigdollers, D.; Gómez-Chova, L. Transferring deep learning models for cloud detection between Landsat-8 and Proba-V. ISPRS J. Photogramm. Remote Sens. 2020, 160, 1–17. [Google Scholar] [CrossRef]
- Segal-Rozenhaimer, M.; Li, A.; Das, K.; Chirayath, V. Cloud detection algorithm for multi-modal satellite imagery using convolutional neural-networks (CNN). Remote Sens. Environ. 2020, 237, 111446. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; March, M.; Lempitsky, V. Domain-Adversarial Training of Neural Networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Mateo-García, G.; Laparra, V.; López-Puigdollers, D.; Gómez-Chova, L. Cross-sensor adversarial domain adaptation of Landsat-8 and Proba-V images for cloud detection. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2021, 14, 747–761. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Gao, X.; Zhang, G.; Yang, Y.; Kuang, J.; Han, K.; Jiang, M.; Yang, J.; Tan, M.; Liu, B. Two-Stage Domain Adaptation Based on Image and Feature Levels for Cloud Detection in Cross-Spatiotemporal Domain. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5610517. [Google Scholar] [CrossRef]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Nice, France, 2017; Volume 30. [Google Scholar]
- Xu, Z.; Wei, W.; Zhang, L.; Nie, J. Source-free domain adaptation for cross-scene hyperspectral image classification. In Proceedings of the IGARSS 2022–2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 3576–3579. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, H.; Shen, Q. Spectral–Spatial Classification of Hyperspectral Imagery with 3D Convolutional Neural Network. Remote Sens. 2017, 9, 67. [Google Scholar] [CrossRef]
- Qiu, Z.; Zhang, Y.; Lin, H.; Niu, S.; Liu, Y.; Du, Q.; Tan, M. Source-free Domain Adaptation via Avatar Prototype Generation and Adaptation. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, Montreal, QC, Canada, 19–27 August 2021; pp. 2921–2927. [Google Scholar] [CrossRef]
- Gao, K.; You, X.; Li, K.; Chen, L.; Lei, J.; Zuo, X. Attention Prompt-Driven Source-Free Adaptation for Remote Sensing Images Semantic Segmentation. IEEE Geosci. Remote. Sens. Lett. 2024, 21, 6012105. [Google Scholar] [CrossRef]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified Perceptual Parsing for Scene Understanding. In Proceedings of the Computer Vision—ECCV 2018: 15th European Conference, Munich, Germany, 8–14 September 2018; Proceedings, Part V. Springer: Berlin/Heidelberg, Germany, 2018; pp. 432–448. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Wang, D.; Shelhamer, E.; Liu, S.; Olshausen, B.; Darrell, T. Tent: Fully test-time adaptation by entropy minimization. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Mirza, M.J.; Micorek, J.; Possegger, H.; Bischof, H. The norm must go on: Dynamic unsupervised domain adaptation by normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14765–14775. [Google Scholar]
- Furano, G.; Meoni, G.; Dunne, A.; Moloney, D.; Ferlet-Cavrois, V.; Tavoularis, A.; Byrne, J.; Buckley, L.; Psarakis, M.; Voss, K.O.; et al. Towards the use of artificial intelligence on the edge in space systems: Challenges and opportunities. IEEE Aerosp. Electron. Syst. Mag. 2020, 35, 44–56. [Google Scholar] [CrossRef]
- Papadimitriou, P.; Tsaoussidis, V. On TCP performance over asymmetric satellite links with real-time constraints. Comput. Commun. 2007, 30, 1451–1465. [Google Scholar] [CrossRef]
- PyTorch Foundation. PyTorch. 2023. Available online: https://pytorch.org (accessed on 25 April 2023).
- Francis, A.; Mrziglod, J.; Sidiropoulos, P.; Muller, J.P. Sentinel-2 Cloud Mask Catalogue (Version 1). Dataset under CC BY 4.0 license at 2020. Available online: https://zenodo.org/records/4172871 (accessed on 3 April 2023).
- Saunier, S.; Pflug, B.; Lobos, I.M.; Franch, B.; Louis, J.; De Los Reyes, R.; Debaecker, V.; Cadau, E.G.; Boccia, V.; Gascon, F.; et al. Sen2Like: Paving the Way towards Harmonization and Fusion of Optical Data. Remote Sens. 2022, 14, 3855. [Google Scholar] [CrossRef]
- Claverie, M.; Ju, J.; Masek, J.G.; Dungan, J.L.; Vermote, E.F.; Roger, J.C.; Skakun, S.V.; Justice, C. The Harmonized Landsat and Sentinel-2 surface reflectance data set. Remote Sens. Environ. 2018, 219, 145–161. [Google Scholar] [CrossRef]
- NASA. Landsat 9 | Landsat Science. 2023. Available online: https://landsat.gsfc.nasa.gov/satellites/landsat-9/ (accessed on 3 April 2023).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sung, Y.L.; Nair, V.; Raffel, C.A. Training Neural Networks with Fixed Sparse Masks. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–14 December 2021; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: Nice, France, 2021; Volume 34, pp. 24193–24205. [Google Scholar]
- Microsoft. ONNX Runtime: Accelerated GPU Machine Learning. 2023. Available online: https://onnxruntime.ai/ (accessed on 7 June 2023).
- Advantech. ARK-1123L: Intel® Atom E3825 SoC with Dual COM and GPIO Palm-Size Fanless Box PC. 2024. Available online: https://www.advantech.com/en-au/products/1-2jkbyz/ark-1123l/mod_16fa2125-2758-438f-86d2-5763dfa4bc47 (accessed on 20 August 2024).
- Li, Y.; Wang, N.; Shi, J.; Liu, J.; Hou, X. Revisiting Batch Normalization For Practical Domain Adaptation. In Proceedings of the ICLR Workshop, Toulon, France, 24–26 April 2017. [Google Scholar]
- Schneider, S.; Rusak, E.; Eck, L.; Bringmann, O.; Brendel, W.; Bethge, M. Improving robustness against common corruptions by covariate shift adaptation. In Proceedings of the Advances in Neural Information Processing Systems, Omline, 6–12 December 2020; Curran Associates, Inc.: Nice, France, 2020; Volume 33, pp. 11539–11551. [Google Scholar]
- Hughes, G. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 1968, 14, 55–63. [Google Scholar] [CrossRef]
- Rasti, B.; Scheunders, P.; Ghamisi, P.; Licciardi, G.; Chanussot, J. Noise Reduction in Hyperspectral Imagery: Overview and Application. Remote Sens. 2018, 10, 482. [Google Scholar] [CrossRef]
- Gómez, P.; Östman, J.; Shreenath, V.M.; Meoni, G. PAseos Simulates the Environment for Operating multiple Spacecraft. arXiv 2023, arXiv:2302.02659. [Google Scholar] [CrossRef]
- Dakin, J.P.; Brown, R.G. (Eds.) Handbook of Optoelectronics: Concepts, Devices, and Techniques Volume 1, 2nd ed.; Series in Optics and Optoelectronics; CRC Press, Taylor & Francis Group: Boca Raton, FL, USA, 2018. [Google Scholar]
- Jensen, J.R. Remote Sensing of the Environment: An Earth Resource Perspective, 2nd ed.; Pearson Education Limited: Harlow, UK, 2014. [Google Scholar]
- U.S. Geological Survey (USGS). Landsat Project Science Office at the Earth Resources Observation and Science (EROS) Center and the National Aeronautics and Space Administration (NASA) Landsat Project Science Office at NASA’s Goddard Space Flight Center (GSFC). In Landsat 9 Data Users Handbook; LSDS-2082 Version 1.0; U.S. Geological Survey: Menlo Park, CA, USA, 2022. [Google Scholar]
- Janowiak, J.E.; Joyce, R.J.; Yarosh, Y. A Real-Time Global Half-Hourly Pixel-Resolution Infrared Dataset and Its Applications. Bull. Am. Meteorol. Soc. 2001, 82, 205–218. [Google Scholar] [CrossRef]


| Sentinel-2 (13 Bands) | Landsat 9 (11 Bands) | |||||||
|---|---|---|---|---|---|---|---|---|
| Spectral Bands | CW (nm) | BW (nm) | SR (m) | AAA | Spectral Bands | CW (nm) | BW (nm) | SR (m) |
| B01 - Coastal Aerosol | 442.7 | 21 | 60 | B01 - Coastal Aerosol | 443 | 16 | 30 | |
| B02 - Blue | 492.4 | 66 | 10 | B02 - Blue | 482 | 60 | 30 | |
| B03 - Green | 559.8 | 36 | 10 | B03 - Green | 561.5 | 57 | 30 | |
| B08 - Panchromatic | 589.5 | 173 | 15 | |||||
| B04 - Red | 664.6 | 31 | 10 | B04 - Red | 654.5 | 37 | 30 | |
| B05 - Red Edge 1 | 704.1 | 15 | 20 | |||||
| B06 - Red Edge 2 | 740.5 | 15 | 20 | |||||
| B07 - Red Edge 3 | 782.8 | 20 | 20 | |||||
| B08 - NIR | 832.8 | 106 | 10 | |||||
| B08A - Narrow NIR | 864.7 | 21 | 20 | B05 - NIR | 865 | 28 | 30 | |
| B09 - Water Vapour | 945.1 | 20 | 60 | |||||
| B10 - SWIR - Cirrus | 1373.5 | 31 | 60 | B09 - Cirrus | 1373.5 | 21 | 30 | |
| B11 - SWIR 1 | 1613.7 | 91 | 20 | B06 - SWIR 1 | 1608.5 | 85 | 30 | |
| B12 - SWIR 2 | 2202.4 | 175 | 20 | B07 - SWIR 2 | 2200.5 | 187 | 30 | |
| B10 - Thermal | 10895 | 590 | 100 | |||||
| B11 - Thermal | 12005 | 1010 | 100 | |||||
| Cloud Detectors | Memory Footprint | No. of Bands | CONV | BN | FC | Total |
|---|---|---|---|---|---|---|
| CloudScout-3 | 5.20 | 3 | 1,026,560 | 2304 | 263,682 | 1,292,546 |
| CloudScout-8 | 5.20 | 8 | 1,042,560 | 2304 | 263,682 | 1,308,546 |
| ResNet50-3 | 94.00 | 3 | 23,454,912 | 53,120 | 4098 | 23,512,130 |
| ResNet50-8 | 94.00 | 8 | 23,470,592 | 53,120 | 4098 | 23,527,810 |
| (a) Source cloud detectors in Table 5a. | ||||||||||
| SOURCE ONLY | FISH Mask | DUA | Tent | |||||||
| Model Settings | Memory Footprint | Time | ACC (%) | FP (%) | ACC (%) | FP (%) | ACC (%) | FP (%) | ACC (%) | FP (%) |
| CloudScout-3-S2 | 2.60 | 2252 | 66.40 | 0.80 | 89.60 | 7.20 | 83.60 | 6.40 | 81.20 | 5.20 |
| CloudScout-8-S2 | 2.60 | 2015 | 52.00 | 48.00 | 90.00 | 1.20 | 59.60 | 40.00 | 64.00 | 34.40 |
| ResNet50-3-S2 | 47.00 | 1245 | 90.80 | 1.60 | 88.40 | 1.60 | 88.80 | 2.00 | 90.80 | 5.20 |
| ResNet50-8-S2 | 47.00 | 1346 | 56.80 | 43.20 | 95.20 | 1.20 | 68.40 | 30.80 | 70.40 | 27.60 |
| (b) Source cloud detectors in Table 5b. | ||||||||||
| SOURCE ONLY | FISH Mask | DUA | Tent | |||||||
| Model settings | Memory footprint | Time | ACC (%) | FP (%) | ACC (%) | FP (%) | ACC (%) | FP (%) | ACC (%) | FP (%) |
| CloudScout-3-L9 | 2.60 | 2252 | 77.24 | 8.62 | 91.38 | 4.14 | 75.17 | 6.21 | 76.55 | 7.59 |
| CloudScout-8-L9 | 2.60 | 2015 | 67.24 | 30.69 | 93.45 | 2.41 | 78.28 | 18.62 | 75.86 | 21.38 |
| ResNet50-3-L9 | 47.00 | 1245 | 83.79 | 12.07 | 91.38 | 2.07 | 81.38 | 11.72 | 82.41 | 10.69 |
| ResNet50-8-L9 | 47.00 | 1346 | 61.03 | 37.93 | 93.10 | 4.48 | 76.90 | 19.31 | 75.52 | 20.69 |
| Model Settings | DUA #Samples = 16; No Augmentation | Tent Batch Size = 1; #Samples = 250; Epoch = 1 |
|---|---|---|
| CloudScout-3-S2 | 181.25 | 5672.52 |
| CloudScout-8-S2 | 198.27 | 5852.24 |
| ResNet50-3-S2 | 186.32 | 4782.63 |
| ResNet50-8-S2 | 192.16 | 4882.97 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, A.; Doan, A.-D.; Law, Y.W.; Chin, T.-J. Domain Adaptation for Satellite-Borne Multispectral Cloud Detection. Remote Sens. 2024, 16, 3469. https://doi.org/10.3390/rs16183469
Du A, Doan A-D, Law YW, Chin T-J. Domain Adaptation for Satellite-Borne Multispectral Cloud Detection. Remote Sensing. 2024; 16(18):3469. https://doi.org/10.3390/rs16183469
Chicago/Turabian StyleDu, Andrew, Anh-Dzung Doan, Yee Wei Law, and Tat-Jun Chin. 2024. "Domain Adaptation for Satellite-Borne Multispectral Cloud Detection" Remote Sensing 16, no. 18: 3469. https://doi.org/10.3390/rs16183469
APA StyleDu, A., Doan, A.-D., Law, Y. W., & Chin, T.-J. (2024). Domain Adaptation for Satellite-Borne Multispectral Cloud Detection. Remote Sensing, 16(18), 3469. https://doi.org/10.3390/rs16183469