

Multi-Window Fusion Spatial-Frequency Joint Self-Attention for Remote-Sensing Image Super-Resolution


Abstract
:1. Introduction
- We start from the global characteristics of the frequency domain and explore and design a spatial-frequency joint self-attention mechanism. The spatial and frequency-domain information complement each other, greatly expanding the model’s ability to extract and utilize information. As a result, our model achieves higher pixel-level evaluation metrics and better visual quality in the reconstruction results.
- By merging and updating highly similar windows, we effectively integrate information from multiple windows, enabling self-attention to capture long-range dependencies. This expands the scope of information utilization during feature extraction, further improving image reconstruction quality.
- We validated our approach through experiments on multiple datasets, demonstrating that our method significantly outperforms other state-of-the-art techniques in both image super-resolution metrics and visual quality.
2. Materials and Methods
2.1. Methods
2.1.1. Spatial-Frequency Joint Self-Attention
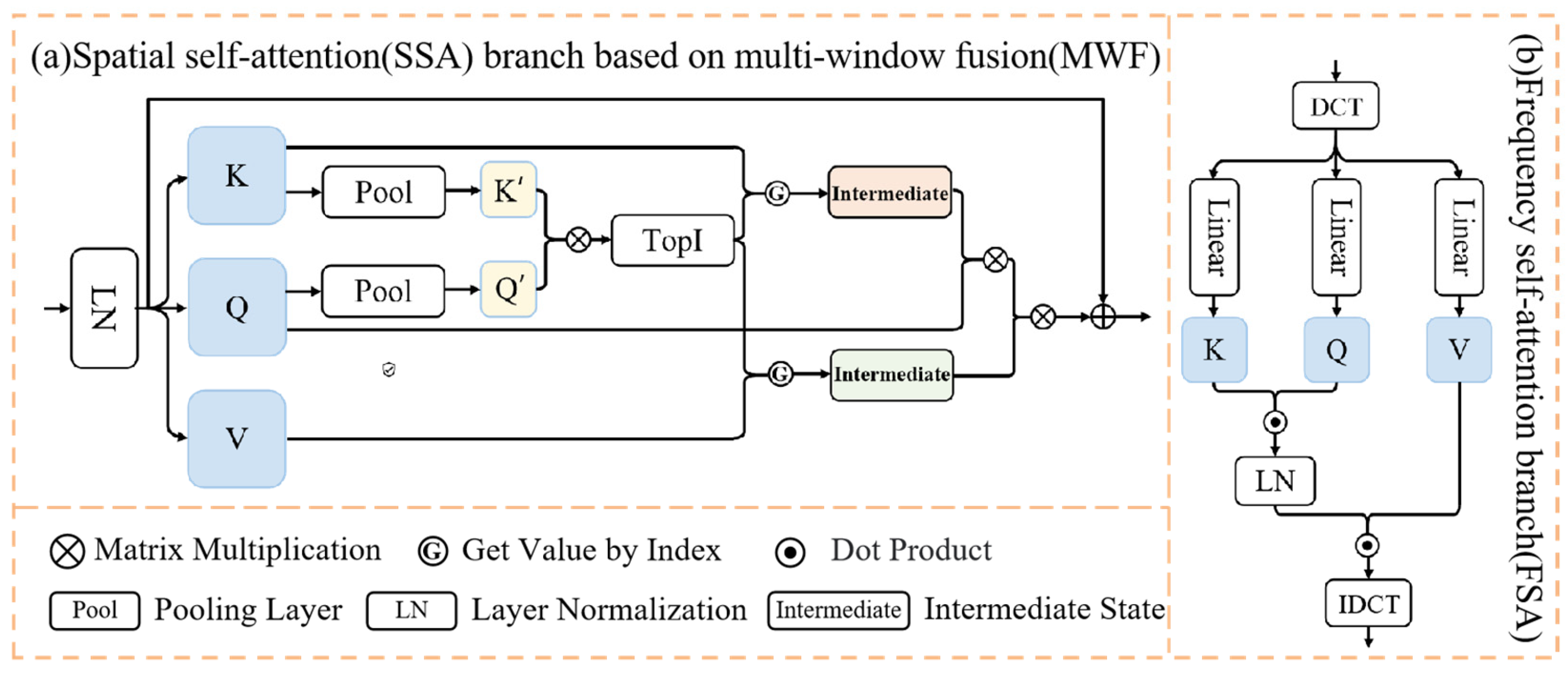
2.1.2. The Spatial Self-Attention Branch Based on Multi-Window Fusion
2.1.3. The Frequency-Domain Branch of the Spatial-Frequency Self-Attention Module
2.1.4. Loss Function
2.2. Dataset and Implementation Details
2.2.1. Dataset
2.2.2. Implementation Details and Metrics
3. Results
3.1. Comparisons with State-of-the-Art Methods
3.2. Model Analysis
3.2.1. The Effect of Spatial Domain Branching
3.2.2. The Effect of Multi-Window Fusion Strategies
3.2.3. The Effect of Frequency-Domain Branching
4. Discussion
4.1. Method of Application
4.2. Limitation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, Z.; Chen, J.; Hoi, S.C.H. Deep Learning for Image Super-Resolution: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3365–3387. [Google Scholar] [CrossRef] [PubMed]
- Wu, Z.; Chen, X.; Gao, Y.; Li, Y. Rapid Target Detection in High-Resolution Remote Sensing Images Using YOLO Model. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2018, 42, 1915–1920. [Google Scholar] [CrossRef]
- Gupta, M.; Almomani, O.; Khasawneh, A.M.; Darabkh, K.A. Smart Remote Sensing Network for Early Warning of Disaster Risks. In Nanotechnology-Based Smart Remote Sensing Networks for Disaster Prevention, 2nd ed.; Elsevier: Amsterdam, The Netherlands, 2022; pp. 303–324. [Google Scholar]
- Wang, Z.; Kang, Q.; Xun, Y.; Shen, Z.; Cui, C. Military Reconnaissance Application of High-Resolution Optical Satellite Remote Sensing. Proc. SPIE 2014, 9299, 301–305. [Google Scholar]
- Wang, Z.; Jiang, K.; Yi, P.; Han, Z.; He, Z. Ultra-Dense GAN for Satellite Imagery Super-Resolution. Neurocomputing 2020, 398, 328–337. [Google Scholar] [CrossRef]
- Lim, S.B.; Seo, C.W.; Yun, H.C. Digital Map Updates with UAV Photogrammetric Methods. J. Korean Soc. Surv. Geod. Photogramm. Cartogr. 2015, 33, 397–405. [Google Scholar] [CrossRef]
- Guo, M.; Liu, H.; Xu, Y.; Huang, Y. Building Extraction Based on U-Net with an Attention Block and Multiple Losses. Remote Sens. 2020, 12, 1400. [Google Scholar] [CrossRef]
- Sun, H.; Sun, X.; Wang, H.; Li, Y.; Li, X. Automatic Target Detection in High-Resolution Remote Sensing Images Using Spatial Sparse Coding Bag-of-Words Model. IEEE Geosci. Remote Sens. Lett. 2011, 9, 109–113. [Google Scholar] [CrossRef]
- Liang, X.; Gan, Z. Improved Non-Local Iterative Back-Projection Method for Image Super-Resolution. In Proceedings of the 2011 Sixth International Conference on Image and Graphics, Hefei, China, 12–15 August 2011; pp. 176–181. [Google Scholar]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image Super-Resolution Via Sparse Representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Gu, S.; Zuo, W.; Xie, Q.; Meng, D.; Feng, X.; Zhang, L. Convolutional Sparse Coding for Image Super-Resolution. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1823–1831. [Google Scholar]
- Peng, C.; Gao, X.; Wang, N.; Li, J. Graphical Representation for Heterogeneous Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 301–312. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-Recursive Convolutional Network for Image Super-Resolution. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual Dense Network for Image Super-Resolution. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.P.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep Back-Projection Networks for Super-Resolution. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1664–1673. [Google Scholar]
- Shocher, A.; Cohen, N.; Irani, M. “Zero-Shot” Super-Resolution Using Deep Internal Learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3118–3126. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image Super-Resolution Using Very Deep Residual Channel Attention Networks. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 2–14 September 2018; pp. 286–301. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Yang, F.; Yang, H.; Fu, J.; Lu, H.; Guo, B. Learning Texture Transformer Network for Image Super-Resolution. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5791–5800. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H. Restormer: Efficient Transformer for High-Resolution Image Restoration. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. SwinIR: Image Restoration Using Swin Transformer. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Part III, 18. Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Choi, H.; Lee, J.; Yang, J. N-Gram in Swin Transformers for Efficient Lightweight Image Super-Resolution. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 2071–2081. [Google Scholar]
- Chen, X.; Wang, X.; Zhou, J.; Qiao, Y.; Chao, D. Activating More Pixels in Image Super-Resolution Transformer. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 22367–22377. [Google Scholar]
- Avdan, U.; Jovanovska, G. Algorithm for Automated Mapping of Land Surface Temperature Using LANDSAT 8 Satellite Data. J. Sensors 2016, 2016, 1480307. [Google Scholar] [CrossRef]
- Gu, J.; Dong, C. Interpreting Super-Resolution Networks with Local Attribution Maps. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 9199–9208. [Google Scholar]
- Deng, X.; Yang, R.; Xu, M.; Dragotti, P.L. Wavelet Domain Style Transfer for an Effective Perception-Distortion Tradeoff in Single Image Super-Resolution. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3076–3085. [Google Scholar]
- Cooley, J.W.; Tukey, J.W. An Algorithm for the Machine Calculation of Complex Fourier Series. Math. Comput. 1965, 19, 297–301. [Google Scholar] [CrossRef]
- Simonyan, K. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Guo, M.; Zhang, Z.; Liu, H.; Huang, Y. NDSRGAN: A Novel Dense Generative Adversarial Network for Real Aerial Imagery Super-Resolution Reconstruction. Remote Sens. 2022, 14, 1574. [Google Scholar] [CrossRef]
- Liang, J.; Zeng, H.; Zhang, L. Details or Artifacts: A Locally Discriminative Learning Approach to Realistic Image Super-Resolution. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5657–5666. [Google Scholar]
- Diederik, P.K. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Haut, J.M.; Fernandez-Beltran, R.; Paoletti, M.E.; Plaza, J.; Plaza, A. Remote Sensing Image Super Resolution Using Deep Residual Channel Attention. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9277–9289. [Google Scholar] [CrossRef]
- Dong, X.; Sun, X.; Jia, X.; Xi, Z.; Gao, L.; Zhang, B. Remote Sensing Image Super-Resolution Using Novel Dense-Sampling Networks. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1618–1633. [Google Scholar] [CrossRef]
- Huan, H.; Zou, N.; Zhang, Y.; Xie, Y.; Wang, C. Remote Sensing Image Reconstruction Using an Asymmetric Multi-Scale Super-Resolution Network. J. Supercomput. 2022, 78, 18524–18550. [Google Scholar] [CrossRef]
- Meng, F.; Wu, S.; Li, Y.; Zhang, Z.; Feng, T.; Liu, R.; Du, Z. Single Remote Sensing Image Super-Resolution Via a Generative Adversarial Network with Stratified Dense Sampling and Chain Training. IEEE Trans. Geosci. Remote Sens. 2023, 62, 1–22. [Google Scholar] [CrossRef]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Loy, C.C. ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks. In Proceedings of the 15th European Conference on Computer Vision, ECCV 2018, Munich, Germany, 8–14 September 2018. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Batch Size | Ratio | ||||
|---|---|---|---|---|---|---|
| PSNR | SSIM | LPIPS | Params | FLOPs | ||
| Bicubic | / | 29.098 | 0.85326 | 0.22807 | / | / |
| EDSR [20] | 16 | 31.540 | 0.90802 | 0.13445 | 40.730 M | 166.840 G |
| SRGAN [16] | 16 | 31.166 | 0.90005 | 0.12019 | 1.402 M | 5.935 G |
| DRCAN [36] | 16 | 31.561 | 0.91009 | 0.13156 | 15.445 M | 62.751 G |
| DSSR [37] | 16 | 31.563 | 0.90886 | 0.14000 | 9.134 M | 39.151 G |
| AMSSRN [38] | 16 | 31.592 | 0.90923 | 0.13556 | 11.863 M | 47.193 G |
| HAT [27] | 4 | 31.678 | 0.91055 | 0.13256 | 25.821 M | 133.597 G |
| SRADSGAN [39] | 8 | 31.723 | 0.91044 | 0.13353 | 11.069 M | 45.261 G |
| MWSFA | 8 | 32.021 | 0.91238 | 0.10786 | 29.124 M | 152.324 G |
| Method | Batch Size | Ratio | ||||
| PSNR | SSIM | LPIPS | Params | FLOPs | ||
| Bicubic | / | 26.549 | 0.75513 | 0.37250 | / | / |
| EDSR [20] | 16 | 28.793 | 0.83139 | 0.21365 | 43.680 M | 179.061 G |
| SRGAN [16] | 16 | 28.372 | 0.81628 | 0.14219 | 1.588 M | 7.012 G |
| DRCAN [36] | 16 | 28.873 | 0.83410 | 0.20992 | 15.629 M | 63.541 G |
| DSSR [37] | 16 | 28.820 | 0.83226 | 0.21440 | 9.319 M | 42.206 G |
| AMSSRN [38] | 16 | 28.845 | 0.83382 | 0.21784 | 12.047 M | 47.984 G |
| HAT [27] | 8 | 28.942 | 0.83513 | 0.21443 | 26.005 M | 106.292 G |
| SRADSGAN [39] | 16 | 28.909 | 0.83422 | 0.20543 | 11.254 M | 46.052 G |
| MWSFA | 16 | 29.515 | 0.89910 | 0.20924 | 31.018 M | 153.142 G |
| Method | Batch Size | Ratio | ||||
| PSNR | SSIM | LPIPS | Params | FLOPs | ||
| Bicubic | / | 24.694 | 0.65297 | 0.50819 | / | / |
| EDSR [20] | 16 | 26.471 | 0.73930 | 0.31313 | 43.130 M | 205.834 G |
| SRGAN [16] | 16 | 26.235 | 0.72512 | 0.25414 | 1.402 M | 9.128 G |
| DRCAN [36] | 16 | 26.687 | 0.74664 | 0.31583 | 15.592 M | 65.252 G |
| DSSR [37] | 16 | 26.604 | 0.74328 | 0.32480 | 9.134 M | 48.900 G |
| AMSSRN [38] | 16 | 26.648 | 0.74427 | 0.32556 | 12.010 M | 49.694 G |
| HAT [27] | 16 | 26.738 | 0.74841 | 0.31440 | 25.821 M | 136.762 G |
| SRADSGAN [39] | 16 | 26.784 | 0.74898 | 0.31503 | 11.069 M | 47.762 G |
| MWSFA | 16 | 27.236 | 0.77832 | 0.21723 | 29.124 M | 154.894 G |
| Method | Batch Size | Ratio | ||||
| PSNR | SSIM | LPIPS | Params | FLOPs | ||
| Bicubic | / | 21.866 | 0.46479 | 0.73461 | / | / |
| EDSR [20] | 16 | 22.738 | 0.52417 | 0.48182 | 40.730 M | 361.812 G |
| SRGAN [16] | 16 | 22.747 | 0.51051 | 0.42184 | 1.402 M | 21.900 G |
| DRCAN [36] | 16 | 23.039 | 0.53691 | 0.48407 | 15.740 M | 75.386 G |
| DSSR [37] | 16 | 23.035 | 0.53722 | 0.48993 | 9.134 M | 87.894 G |
| AMSSRN [38] | 16 | 23.110 | 0.54018 | 0.49442 | 12.210 M | 52.253 G |
| HAT [27] | 16 | 22.788 | 0.53052 | 0.47275 | 25.821 M | 149.423 G |
| SRADSGAN [39] | 16 | 23.189 | 0.54475 | 0.48342 | 11.069 M | 57.765 G |
| MWSFA | 16 | 24.053 | 0.55592 | 0.43894 | 30.499 M | 159.449 G |
| Method | Scale | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| MWSFA w/o SSA | 17.437 | 0.53878 | 0.49301 | |
| MWSFA w/o FSA | 25.893 | 0.82323 | 0.22345 | |
| MWSFA w/o MWF | 29.327 | 0.87634 | 0.13299 | |
| MWSFA | 32.021 | 0.91238 | 0.10786 | |
| MWSFA w/o SSA | 17.230 | 0.50100 | 0.50221 | |
| MWSFA w/o FSA | 26.983 | 0.77493 | 0.35231 | |
| MWSFA w/o MWF | 27.098 | 0.83721 | 0.24898 | |
| MWSFA | 29.515 | 0.89910 | 0.20924 | |
| MWSFA w/o SSA | 15.902 | 0.41207 | 0.51579 | |
| MWSFA w/o FSA | 25.213 | 0.60752 | 0.33249 | |
| MWSFA w/o MWF | 26.928 | 0.72130 | 0.26598 | |
| MWSFA | 27.236 | 0.77832 | 0.21723 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Lu, W.; Wang, Z.; Hu, J.; Zhang, Z.; He, L. Multi-Window Fusion Spatial-Frequency Joint Self-Attention for Remote-Sensing Image Super-Resolution. Remote Sens. 2024, 16, 3695. https://doi.org/10.3390/rs16193695
Li Z, Lu W, Wang Z, Hu J, Zhang Z, He L. Multi-Window Fusion Spatial-Frequency Joint Self-Attention for Remote-Sensing Image Super-Resolution. Remote Sensing. 2024; 16(19):3695. https://doi.org/10.3390/rs16193695
Chicago/Turabian StyleLi, Ziang, Wen Lu, Zhaoyang Wang, Jian Hu, Zeming Zhang, and Lihuo He. 2024. "Multi-Window Fusion Spatial-Frequency Joint Self-Attention for Remote-Sensing Image Super-Resolution" Remote Sensing 16, no. 19: 3695. https://doi.org/10.3390/rs16193695
APA StyleLi, Z., Lu, W., Wang, Z., Hu, J., Zhang, Z., & He, L. (2024). Multi-Window Fusion Spatial-Frequency Joint Self-Attention for Remote-Sensing Image Super-Resolution. Remote Sensing, 16(19), 3695. https://doi.org/10.3390/rs16193695