

Automated Recognition of Snow-Covered and Icy Road Surfaces Based on T-Net of Mount Tianshan


Abstract
1. Introduction
- A custom dataset covering six types of RSCs was compiled by using highway cameras, mobile lenses, and online resources. Subsequently, illumination correction and standardization processing were implemented to ensure compatibility with deep-learning models. In view of the scarcity of publicly available standardized datasets of road surface meteorological conditions internationally and the relative shortage of picture resources of road surface conditions in extreme weather, this dataset has contributed invaluable resources for improving the accuracy of the RSC recognition models.
- To overcome the limitations of existing RSC recognition methods, a novel model, T-Net, was proposed. It adopts a split-transform-merge paradigm with four distinct branching blocks, multiple attention mechanisms, and three trainable classification heads, allowing it to capture the diversity and complexity of the RSCs. Meanwhile, in order to fill the research gap and answer the question of which structure or architecture of the deep-learning model should be selected for an RSC recognition scenario, the performance differences of deep learning neural networks with different structures and architectures were explored and analyzed.
- The T-Net constructed is particularly beneficial for engineers and policymakers focused on road safety and transportation infrastructure in extreme climates such as those common in the Tianshan region. By exploring various combinations in convolution methods, attention mechanisms, loss functions, and optimizers, this study offers practical solutions for real-time RSC recognition, bridging the gap between theoretical research and practical application.
2. Related Work
2.1. Different Features and Structures of Neural Networks
2.2. RSC Recognition Models
3. Materials and Methods
3.1. Dataset
3.2. Data Preprocessing
- Data Resizing: The images were resized to 224 × 224 pixels, a standard size in deep learning due to its balance between computational efficiency and model performance. This size is widely used in pretrained models, such as those trained on ImageNet, and has proven successful in models such as the VGG and ResNet.
- Dataset split: The dataset was randomly divided into training, validation, and testing sets, comprising 60%, 20%, and 20% of the overall dataset, respectively.
- Adjustment of Brightness: Road surface conditions are often complex and variable, leading to issues such as occlusion between objects and non-uniform lighting. These problems manifest as regions of excessive brightness or darkness in images, which can obscure or blur critical details. Additionally, these factors can cause different types of road surfaces to appear similar, thereby increasing the difficulty of recognition. To address these challenges, an adaptive correction algorithm based on a two-dimensional gamma function was employed to adjust image illumination intensity [45]. The results of this correction are shown in Figure 2.
- Data Augmentation: Data augmentation is a crucial step for addressing dataset imbalance, where some labels have significantly more images than others. This method generates additional data from existing samples by applying transformations such as flipping, rotating, cropping, scaling, and color adjustments. In this study, the OpenCV and NumPy libraries were employed for data augmentation. By applying random flipping, random translation, random rotation, and Gaussian noise addition, the number of images was increased to 9000.
- Data Normalization: Pixel values were normalized to zero mean and unit standard deviation to accelerate model convergence. The mean values of the dataset were [0.550, 0.565, 0.568] and standard deviations were [0.082, 0.082, 0.085] for the red, green, and blue channels, respectively.
3.3. Network Architecture
3.3.1. Conv Layer
3.3.2. Pooling Layer
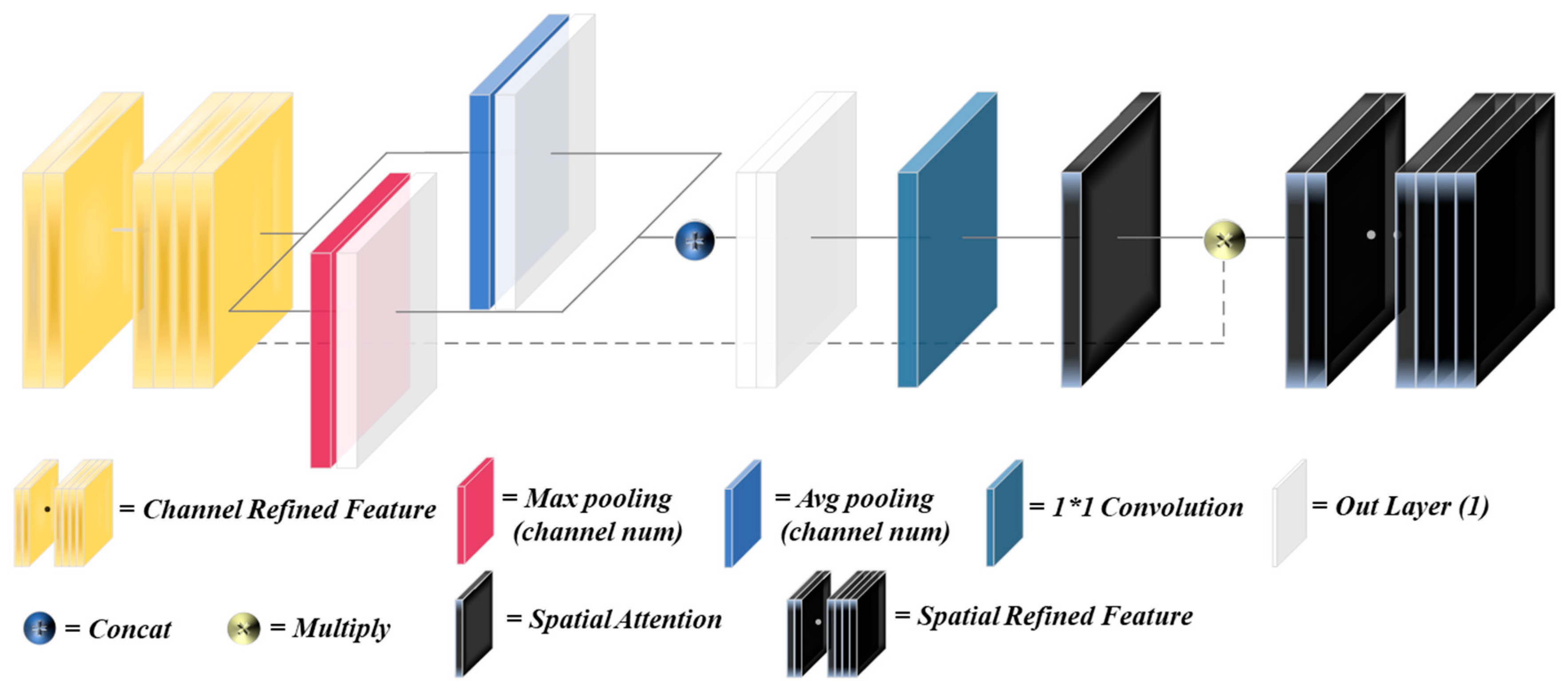
3.3.3. Channel and Spatial Attention
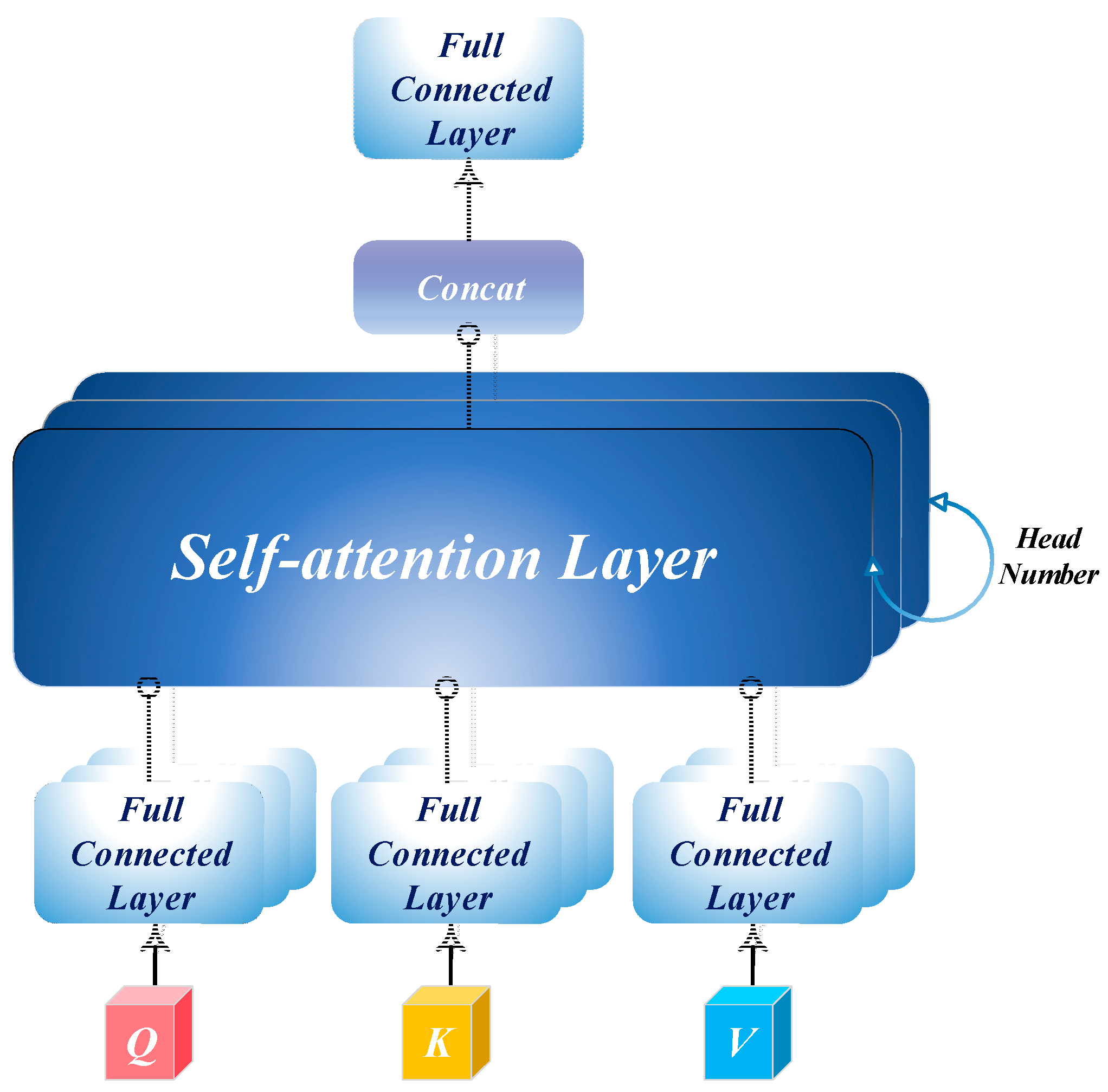
3.3.4. Multi-Head Self-Attention
4. Results
4.1. Performance Testing of Different Network Architectures for RSC Recognition
4.2. Comparsion with Specilized RSC Recognition Networks
4.3. Ablation Experiment
4.4. Confusion Matrix and Model Evaluation
5. Discussion
5.1. Comparison and Analysis of Different Neural Networks for RSC Recognition
5.2. Key Modules in T-Net
5.3. Advantage and Limitation of T-Net
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ou, Y.; Pu, X.; Zhou, X.C.; Lu, Y.; Ren, Y.; Sun, D.Q. Research progress of road icing monitoring technology. Highway 2013, 4, 191–196. [Google Scholar]
- Shao, J. Fuzzy categorization of weather conditions for thermal mapping. J. Appl. Meteorol. Climatol. 2000, 39, 1784–1790. [Google Scholar] [CrossRef]
- Troiano, A.; Pasero, E.; Mesin, L. New system for detecting road ice formation. Trans. Instrum. Meas. 2010, 60, 1091–1101. [Google Scholar] [CrossRef]
- Flatscher, M.; Neumayer, M.; Bretterklieber, T.; Schweighofer, B. Measurement of complex dielectric material properties of ice using electrical impedance spectroscopy. In Proceedings of the 2016 IEEE Sensors, Orlando, FL, USA, 30 October–3 November 2016; pp. 1–3. [Google Scholar]
- Troiano, A.; Naddeo, F.; Sosso, E.; Camarota, G.; Merletti, R.; Mesin, L. Assessment of force and fatigue in isometric contractions of the upper trapezius muscle by surface EMG signal and perceived exertion scale. Gait Posture 2008, 28, 179–186. [Google Scholar] [CrossRef]
- Amoiropoulos, K.; Kioselaki, G.; Kourkoumelis, N.; Ikiades, A. Shaping beam profiles using plastic optical fiber tapers with application to ice sensors. Sensors 2020, 20, 2503. [Google Scholar] [CrossRef]
- Siegl, A.; Neumayer, M.; Bretterklieber, T. Fibre optical ice sensing: Sensor model and icing experiments for different ice types. In Proceedings of the 2020 IEEE International Instrumentation and Measurement Technology Conference, Dubrovnik, Croatia, 25–28 May 2020; pp. 1–6. [Google Scholar]
- Li, X.; Shih, W.Y.; Vartuli, J.; Milius, D.L.; Prud’homme, R.; Aksay, I.A.; Shih, W.-H. Detection of water-ice transition using a lead zirconate titanate/brass transducer. J. Appl. Phys. 2002, 92, 106–111. [Google Scholar] [CrossRef]
- Gu, H.; Li, B.; Zhang, X.; Chen, Q.; He, J. Detection of road surface water and ice based on polarization measurement. Electron. Meas. Technol. 2011, 34, 99–102. [Google Scholar]
- Horita, Y.; Shibata, K.; Maeda, K.; Hayashi, Y. Omni-directional polarization image sensor based on an omni-directional camera and a polarization filter. In Proceedings of the 2009 6th IEEE International Conference on Advanced Video and Signal Based Surveillance, Genova, Italy, 2–4 September 2009; pp. 280–285. [Google Scholar]
- Casselgren, J.; Sjödahl, M. Polarization resolved classification of winter road condition in the near-infrared region. Appl. Opt. 2012, 51, 3036–3045. [Google Scholar] [CrossRef]
- Sun, Z.Q.; Zhang, J.Q.; Zhao, Y.S. Laboratory studies of polarized light reflection from sea ice and lake ice in visible and near infrared. Geosci. Remote Sens. Lett. 2012, 10, 170–173. [Google Scholar] [CrossRef]
- Jonsson, P.; Casselgren, J.; Thörnberg, B. Road surface status classification using spectral analysis of NIR camera images. Sensors 2014, 15, 1641–1656. [Google Scholar] [CrossRef]
- Jonsson, P. Remote sensor for winter road surface status detection. In Proceedings of the 2011 IEEE Sensors, Limerick, Ireland, 28–31 October 2011; pp. 1285–1288. [Google Scholar]
- Pan, G.Y.; Fu, L.P.; Yu, R.F.; Muresan, M. Evaluation of alternative pre-trained convolutional neural networks for winter road surface condition monitoring. In Proceedings of the 2019 5th International Conference on Transportation Information and Safety, Liverpool, UK, 14–17 July 2019; pp. 614–620. [Google Scholar]
- Yang, W.; Zhou, K.X.; Liu, J.J.; Zhang, Z.Z.; Wang, T. Road surface wet and dry state recognition method based on transfer learning and Inception-v3 model. Electronics 2019, 14, 912–916. [Google Scholar]
- Lee, H.; Kang, M.; Song, J.; Hwang, K. The detection of black ice accidents for preventative automated vehicles using convolutional neural networks. Electronics 2020, 9, 2178. [Google Scholar] [CrossRef]
- Dewangan, D.K.; Sahu, S.P. RCNet: Road classification convolutional neural networks for intelligent vehicle system. Intell. Serv. Robot. 2021, 14, 199–214. [Google Scholar] [CrossRef]
- Wang, J.; Huang, D.Q.; Guo, X. Urban traffic road surface condition recognition algorithm based on improved Inception-ResNet-v2. Sci. Technol. Eng. 2019, 22, 2524–2530. [Google Scholar]
- Huang, L.H.; Chang, H.D.; Cui, K.J.; Gao, J.Y.; Li, J. A Detection System for Road Surface Slippery Condition Based on Convolutional Neural Networks. Automob. Appl. Technol. 2022, 47, 18–21. [Google Scholar]
- Xie, Q.; Kwon, T.J. Development of a highly transferable urban winter road surface classification model: A deep learning approach. Transp. Res. Rec. 2022, 2676, 445–459. [Google Scholar] [CrossRef]
- Yang, L.M.; Huang, D.Q.; Wei, X.; Wang, J. Deep learning-based identification of slippery state of road surface. Automob. Appl. Technol. 2022, 12, 137–142. [Google Scholar]
- Lee, S.Y.; Jeon, J.S.; Le, T.H.M. Feasibility of Automated Black Ice Segmentation in Various Climate Conditions Using Deep Learning. Buildings 2023, 13, 767. [Google Scholar] [CrossRef]
- Kou, F.R.; Hu, K.L.; Chen, R.C.; He, H.Y. Model predictive control of Active Suspension based on Road surface condition recognition by ResNeSt. Control. Decis. 2023, 39, 1849–1858. [Google Scholar]
- Chen, S.J.; Liu, P.Y.; Bai, Y.B.; Wang, T.; Yuan, J. Computer vision based High-speed pavement condition detection method. Automob. Appl. Technol. 2023, 42, 44–51. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25 (NIPS 2012), Lake Tahoe, NA, USA, 3–6 December 2012; p. 25. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.N.; Girshick, R.; Dollár, P.; Tu, Z.W.; He, K.M. Aggregated residual transformations for deep neural networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.Q.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the 2016 AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the 2017 AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2010, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.T.; Cao, Y.; Hu, H.; Wei, Y.X.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4700–4708. [Google Scholar]
- Liu, Z.; Mao, H.Z.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Zhang, X.Y.; Zhou, X.Y.; Lin, M.X.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.N.; Zhang, X.Y.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the 2018 European Conference on Computer Vision, Heidelberg, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.L.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Tan, M.X.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Mehta, S.; Rastegari, M. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Liu, X.Y.; Peng, H.W.; Zheng, N.X.; Yang, Y.; Hu, H.; Yuan, Y. EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 14420–14430. [Google Scholar]
- Radosavovic, I.; Kosaraju, R.R.; Girshick, R.; He, K.M.; Dollár, P. Designing network design spaces. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10428–10436. [Google Scholar]
- Lee, S.; Kwon, H.; Han, H.; Lee, G.; Kang, B. A space-variant luminance map based color image enhancement. Trans. Consum. Electron. 2010, 56, 2636–2643. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the 2018 European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; p. 30. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Peng, B.; Li, Y.X.; He, L.; Fan, K.L.; Tong, L. Road segmentation of UAV RS image using adversarial network with multi-scale context aggregation. In Proceedings of the 2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 6935–6938. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 2015 International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classes | Model and Version | Key Feature or Design Method |
|---|---|---|
| Normal network | AlexNet [26] | sequential structure |
| VGG [27] | sequential structure | |
| GoogLeNet [30] | multi-branch structure | |
| Inception [31] | multi-branch structure | |
| ResNet [28] | sequential structure with residual connection | |
| Inception-ResNet [32] | multi-branch structure with residual connection | |
| ResNeXt [29] | multi-branch structure with residual connection | |
| DenseNet [35] | sequential structure with dense connection | |
| ViT [33] | sequential structure with self-attention | |
| ResViT [33] | sequential structure with residual connection and self-attention | |
| Swin Transformer [34] | sequential structure with self-attention in shifted window | |
| ConvNeXt [36] | ResNet based on Swin Transformer design idea | |
| Lightweight network | ShuffleNet [37,38] | hand-designed CNN architecture |
| MobileNet [39,40] | NAS CNN architecture | |
| EfficientNet [41] | NAS CNN architecture | |
| RegNet [44] | NAS CNN architecture | |
| MobileViT [42] | hand-designed CNN-Transformer hybrid architecture | |
| EfficientViT [43] | NAS CNN-Transformer hybrid architecture |
| Road Categories | Dry | Fully Snowy | Icy | Snow-Blowing | Snow-Melting | Wet |
|---|---|---|---|---|---|---|
| Original | 898 | 499 | 275 | 92 | 336 | 402 |
| Augmentation | 1500 | 1500 | 1500 | 1500 | 1500 | 1500 |
| Sample size (MB) | 28.6 | 17.2 | 36.0 | 19.8 | 38.1 | 27.6 |
| Seq | Layers | Patch Size/Stride/Padding | Output Size | |
|---|---|---|---|---|
| 1 | Conv1 | 3 × 3/2/0 | 111 × 111 × 32 | |
| 2 | Conv2 | 3 × 3/1/0 | 109 × 109 × 64 | |
| 3 | Conv3 | 3 × 3/1/1 | 109 × 109 × 64 | |
| 4 | Branch 1-1 | MaxPool | 3 × 3/2/0 | 54 × 54 × 64 |
| 5 | Branch 1-2 | AvgPool | 3 × 3/2/0 | 54 × 54 × 64 |
| 6 | Branch 1-3 | Conv1 | 3 × 3/2/0 | 54 × 54 × 96 |
| 7 | CBAM | 54 × 54 × 224 | ||
| 8 | Branch 2-1 | Conv3 | 1 × 1/1/0 | 54 × 54 × 64 |
| 9 | Conv2 | 3 × 3/1/0 | 52 × 52 × 96 | |
| 10 | Branch 2-2 | Conv3 | 1 × 1/1/0 | 54 × 54 × 64 |
| 11 | Conv4 | 7 × 1/1/3 | 54 × 54 × 64 | |
| 12 | Conv4 | 1 × 7/1/3 | 54 × 54 × 64 | |
| 13 | Conv2 | 3 × 3/1/0 | 52 × 52 × 96 | |
| 14 | CBAM | 52 × 52 × 192 | ||
| 15 | Branch 3-1 | Conv1 | 3 × 3/2/0 | 25 × 25 × 96 |
| 16 | Conv4 | 3 × 1/1/1 | 25 × 25 × 96 | |
| 17 | Conv4 | 1 × 3/1/1 | 25 × 25 × 96 | |
| 18 | Branch 3-2 | Conv3 | 1 × 1/1/0 | 52 × 52 × 96 |
| 19 | MaxPool | 3 × 3/2/0 | 25 × 25 × 96 | |
| 20 | Branch 3-3 | Conv3 | 1 × 1/1/0 | 52 × 52 × 96 |
| 21 | AvgPool | 3 × 3/2/0 | 25 × 25 × 96 | |
| 22 | Branch 3-4 | Conv1 | 3 × 3/2/0 | 25 × 25 × 96 |
| 23 | CBAM | 25 × 25 × 384 | ||
| 24 | Conv1 | 3 × 3/2/0 | 12 × 12 × 512 | |
| 25 | Branch 4-1 | Transformer | 1 × 1 × 512 | |
| 26 | Linear | 1 × 1 × 6 | ||
| 27 | Branch 4-2 | CBAM | 12 × 12 × 512 | |
| 28 | MaxPool | 12 × 12/1/0 | 1 × 1 × 512 | |
| 29 | Linear | 1 × 1 × 6 | ||
| 30 | Branch 4-3 | MaxPool | 12 × 12/1/0 | 1 × 1 × 512 |
| 31 | Linear | 1 × 1 × 6 | ||
| Model and Version | #param. (M) | FLOPs (G) | Accuracy | Loss |
|---|---|---|---|---|
| VGG-16 | 134.29 | 15.48 | 90.50% | 66.47% |
| Inception-v4 | 48.35 | 12.73 | 96.11% | 19.74% |
| ResNet-18 | 11.18 | 1.81 | 94.50% | 21.79% |
| ResNet-50 | 23.52 | 4.09 | 93.78% | 22.40% |
| Inception-ResNet-v2 | 30.37 | 9.27 | 97.05% | 11.12% |
| ResNeXt-50 | 22.99 | 4.23 | 96.39% | 15.26% |
| DenseNet-121 | 6.96 | 2.83 | 96.89% | 12.87% |
| ViT-base | 85.80 | 0.20 | 90.44% | 59.00% |
| Swin Transformer-base | 86.75 | 0.18 | 87.67% | 55.32% |
| ConvNeXt-base | 87.57 | 0.65 | 93.00% | 69.20% |
| T-Net | 6.03 | 1.69 | 97.44% | 9.79% |
| ShuffleNet-v2-x2 | 5.36 | 0.58 | 95.27% | 15.18% |
| EfficientNet-b0 | 4.02 | 0.38 | 92.83% | 29.50% |
| EfficientViT-m2 | 3.96 | 0.20 | 88.17% | 36.99% |
| MobileNet-v3-large | 4.21 | 0.22 | 93.39% | 23.78% |
| MobileViT-small | 4.94 | 0.85 | 94.17% | 27.11% |
| Model and Version | #param. (M) | FLOPs (G) | Accuracy | Loss |
|---|---|---|---|---|
| RCNet | 3.78 | 5.48 | 89.33% | 33.32% |
| Inception-ResNet-v2 with SE module | 31.87 | 8.62 | 97.39% | 10.32% |
| Inception-ResNet-v2 | 30.37 | 9.27 | 97.05% | 11.12% |
| ResNet18 with high/low attention | 11.88 | 2.02 | 94.94% | 17.84% |
| ResNet-18 | 11.18 | 1.81 | 94.50% | 21.79% |
| T-Net | 6.03 | 1.69 | 97.44% | 9.79% |
| #param. (M) | FLOPs (G) | Accuracy | Loss | |
|---|---|---|---|---|
| Baseline | 6.03 | 1.69 | 97.44% | 9.79% |
 CBAM CBAM | 5.97 | 1.69 | 95.94% | 14.77% |
| MHSA | 2.54 | 1.65 | 96.89% | 12.73% |
| Normal Conv. 🞇 Asym. Conv. | 6.48 | 2.76 | 96.78% | 10.34% |
| Group Conv. 🞇 All Conv. | 3.56 | 0.97 | 93.17% | 33.75% |
| Hswish 🞇 ReLU | 6.03 | 1.69 | 97.12% | 13.97% |
” means remove certain module. “🞇” means using A substitute for B. Asym. is the abbreviation for asymmetric.| Evaluation Metrics | Expression |
|---|---|
| Accuracy | |
| Recall | |
| Specificity | |
| Precision | |
| F1-score | |
| AUC | |
| FDR |
| Categories | Accuracy | Recall | Specificity | Precision | F1-Score | AUC | FPR |
|---|---|---|---|---|---|---|---|
| dry road | 0.988 | 0.943 | 0.997 | 0.986 | 0.964 | 0.970 | 0.003 |
| fully snowy road | 0.996 | 0.980 | 0.999 | 0.997 | 0.988 | 0.990 | 0.001 |
| icy road | 0.993 | 0.990 | 0.993 | 0.967 | 0.979 | 0.992 | 0.007 |
| snow-blowing road | 0.996 | 0.990 | 0.995 | 0.977 | 0.988 | 0.998 | 0.005 |
| snow-melting road | 0.983 | 0.940 | 0.992 | 0.959 | 0.949 | 0.966 | 0.008 |
| wet road | 0.971 | 0.930 | 0.979 | 0.900 | 0.915 | 0.955 | 0.021 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Zhang, Y.; Liu, J.; Wang, Z.; Zhang, Z. Automated Recognition of Snow-Covered and Icy Road Surfaces Based on T-Net of Mount Tianshan. Remote Sens. 2024, 16, 3727. https://doi.org/10.3390/rs16193727
Liu J, Zhang Y, Liu J, Wang Z, Zhang Z. Automated Recognition of Snow-Covered and Icy Road Surfaces Based on T-Net of Mount Tianshan. Remote Sensing. 2024; 16(19):3727. https://doi.org/10.3390/rs16193727
Chicago/Turabian StyleLiu, Jingqi, Yaonan Zhang, Jie Liu, Zhaobin Wang, and Zhixing Zhang. 2024. "Automated Recognition of Snow-Covered and Icy Road Surfaces Based on T-Net of Mount Tianshan" Remote Sensing 16, no. 19: 3727. https://doi.org/10.3390/rs16193727
APA StyleLiu, J., Zhang, Y., Liu, J., Wang, Z., & Zhang, Z. (2024). Automated Recognition of Snow-Covered and Icy Road Surfaces Based on T-Net of Mount Tianshan. Remote Sensing, 16(19), 3727. https://doi.org/10.3390/rs16193727