1. Introduction
The Tianshan Expressway is a critical transportation artery in Xinjiang, which plays a crucial role in the economic development of the region. Furthermore, the perennial snow accumulation in the Tianshan region, accounting for one-third of China’s snow resources, significantly exacerbates snow and ice hazards on the roadways. From October to March, extreme weather phenomena such as snowfall, snow accumulation, and blowing snow, as well as ice formation in mountainous areas, pose severe risks to transportation, human lives, and property. These conditions represent a significant meteorological hazard, disrupting the normal operation of expressways in Northern Xinjiang during the cold season and significantly impacting local economic development. Therefore, it is imperative to develop an effective method for the real-time surveillance of road surface conditions (RSCs) on the Tianshan Expressway.
In recent years, various methods for RSC recognition have been proposed, which can be categorized into contact and non-contact approaches [
1]. Contact approaches primarily rely on embedded sensors, including capacitive sensors [
2,
3,
4,
5], fiber optic sensors [
6,
7], and resonant sensors [
8]. Although these detection devices typically achieve high accuracy on clean surfaces, the presence of various types of impurities on road surfaces can significantly affect measurement accuracy. Additionally, the installation and maintenance of contact sensors require cutting the road surface, potentially disrupting traffic flow and reducing the lifespan of the road. As a result, capacitive, optical, and resonant methods have been applied within a restricted scope of RSC recognition. Non-contact approaches primarily rely on light sources and photoelectric detectors, including polarization detection [
9,
10,
11], infrared detection [
12,
13], and multi-wavelength detection [
14]. These optical detection technologies position the light source device at a certain height near the road and fix the light receiving device on the opposite side, using a wired transmission method. The high costs of installation, communication, and maintenance, coupled with substantial power consumption, make dense installation of these systems along road sections challenging, thereby also limiting their applicability in certain scenarios.
Recent advancements in deep learning have led to the emergence of camera-based approaches [
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25]. This non-contact method, relying on camera images for RSC recognition, has achieved higher accuracy compared to traditional methods. Pan et al. conducted a comparative study on the performance of four convolutional neural network (CNN) models (VGG16, ResNet50, Inception-v3, and Xception) in addressing RSC recognition problems, identifying ResNet50 as the optimal model for recognizing winter RSCs [
15]. Dewangan et al., proposed a CNN-based network for complex scene road recognition called RCNet [
18]. Huang et al., developed a transfer-learning model based on Inception-v3 for RSC recognition and used a residual neural network to segment flooded road areas [
20]. Yang et al., tackled the challenges of complex and variable road scenes, low recognition rates of traditional machine-learning methods, and poor generalization capability by proposing an RSC-recognition algorithm based on residual neural networks [
22]. Chen et al. addressed the issues of high cost and limited detection range in conventional hardware-based RSC-detection technologies by proposing a high-speed RSC detection method based on a U-Net fusion model [
25].
Despite the fact that deep-learning models for RSC recognition have shown promise, most rely on pre-trained architectures with only superficial adjustments, such as the integration of attention mechanisms. However, the selection of these models is often not well justified, lacking rigorous comparisons with alternative structures or architectures. Most of them are trained on public datasets such as ImageNet and CIFAR. Therefore, it is crucial to compare their performances on specific RSC datasets, as they may not be suitable for RSC recognition. Current research has largely overlooked a comprehensive evaluation of various neural network designs for RSC recognition, which is a critical gap in the field. Addressing this gap is essential for advancing the development of more robust and effective RSC recognition systems. Given this situation, this study aims to develop a more effective method for recognizing RSCs on the Tianshan Expressway, which is crucial for enhancing road safety. The main contributions of the research are summarized as follows.
A custom dataset covering six types of RSCs was compiled by using highway cameras, mobile lenses, and online resources. Subsequently, illumination correction and standardization processing were implemented to ensure compatibility with deep-learning models. In view of the scarcity of publicly available standardized datasets of road surface meteorological conditions internationally and the relative shortage of picture resources of road surface conditions in extreme weather, this dataset has contributed invaluable resources for improving the accuracy of the RSC recognition models.
To overcome the limitations of existing RSC recognition methods, a novel model, T-Net, was proposed. It adopts a split-transform-merge paradigm with four distinct branching blocks, multiple attention mechanisms, and three trainable classification heads, allowing it to capture the diversity and complexity of the RSCs. Meanwhile, in order to fill the research gap and answer the question of which structure or architecture of the deep-learning model should be selected for an RSC recognition scenario, the performance differences of deep learning neural networks with different structures and architectures were explored and analyzed.
The T-Net constructed is particularly beneficial for engineers and policymakers focused on road safety and transportation infrastructure in extreme climates such as those common in the Tianshan region. By exploring various combinations in convolution methods, attention mechanisms, loss functions, and optimizers, this study offers practical solutions for real-time RSC recognition, bridging the gap between theoretical research and practical application.
The remainder of this paper is organized as follows:
Section 2 outlines the development of classical image recognition neural networks and RSC recognition models,
Section 3 describes the preparation of the dataset and the architecture of the T-Net model,
Section 4 provides the experimental settings and results,
Section 5 presents a comprehensive discussion based on experimental outcomes, and
Section 6 gives a summary of the paper.
2. Related Work
From our perspective, the latest networks are not always superior to older ones. Although new network architectures typically introduce more advanced algorithms and technologies, they do not consistently achieve superior performance in certain scenarios. Performance depends on various factors, including the complexity of the task, characteristics of the dataset, and the adaptability of the model. Therefore, a review of existing neural network architectures and RSC recognition models was conducted in preparation for the subsequent experiments in this section.
2.1. Different Features and Structures of Neural Networks
The rapid advancement of neural networks began in 2012 with the advent of deep-learning techniques and advancements in computational resources, which led to significant breakthroughs in computer vision. In the field of image recognition, neural networks can be categorized as follows:
From a design philosophy and core mechanism perspective, neural networks can be classified into two primary types: CNN-based and transformer-based. In CNN-based neural networks, two main design structures are prevalent. The first is the sequential (or chain) structure, typically formed by sequentially stacking a series of convolutional and pooling layers to create a linear network flow. Examples include AlexNet [
26], VGG [
27], ResNet [
28], and others. The simplicity and intuitiveness of this structure render it facile to understand and implement. Notably, ResNet introduced residual connections, laying the foundation for deeper convolutional neural networks. The second type is the multi-branch structure, also known as the Inception structure. Xie et al. described this as a split-transform-merge model paradigm [
29]. This structure uses multiple branches at the same level with different convolutional kernels or pooling operations, concatenating the output of each branch, as seen in GoogLeNet [
30] and the Inception series [
31,
32]. The advantage of the multi-branch structure lies in its ability to simultaneously capture features at different scales and levels, enhancing the network’s expressive power. In transformer-based neural networks, although their design principles and mechanisms differ from CNN-based models, most still adopt a sequential connection structure. Examples include the Vision Transformer (ViT) [
33], the Swin Transformer [
34], and others. It is worth noting that the ViT represents a pioneering milestone by effectively integrating the self-attention mechanism from the transformer architecture into computer vision. Despite the fact that transformer-based models have demonstrated remarkable performance on benchmarks such as ImageNet, surpassing traditional CNNs and advancing the field of neural network research, they still encounter challenges, including a high number of parameters, demanding computational requirements, a lack of spatial inductive bias, limited adaptability to diverse tasks, and training complexities.
In terms of application scenarios, networks are mainly categorized as either standard or lightweight. Standard networks typically include models that excel on large-scale tasks, characterized by larger parameters and higher computational complexity. Examples include ResNet, ResNeXt, GoogLeNet, Inception, Inception-ResNet, ViT, ResViT, Swin Transformer, DenseNet [
35], ConvNeXt [
36], and others. Notably, ConvNeXt, proposed in 2022, demonstrates performance comparable to transformer-based networks when the convolutional architecture is well designed. In contrast, due to the increasing demand for neural networks in resource-constrained environments, studies [
37,
38,
39,
40,
41,
42,
43,
44] have increasingly focused on the development of lightweight neural networks. Recent examples specifically designed for mobile devices and embedded systems include MobileNet [
40], EfficientNet [
41], MobileViT [
42], EfficientViT [
43], and others. The core designs of MobileNet consist of depthwise separable convolution and width multipliers, which significantly reduce the computational cost and parameter count. EfficientNet achieves optimal performance through a compound scaling method. MobileViT adopts a hybrid CNN and transformer architecture, enhancing network convergence and inference speed through a CNN while incorporating spatial information through a transformer to improve network transferability. EfficientViT, the latest lightweight deep-learning model, incorporates a sandwich layout and cascaded group attention as fundamental components, surpassing existing efficient models and achieving an optimal balance between inference speed and accuracy.
Based on design approaches, neural networks can be divided into two major types: manually designed networks and neural architecture search (NAS) networks. Manual design of neural network architecture excels in flexibility and interpretability. Examples include GoogLeNet, DenseNet, ConvNeXt, and others. However, manual design is limited by the challenge of fully exploring potential data features, as effective neural network structure design requires significant expertise and experimentation. NAS methods aim to automate this process, providing more efficient discovery and optimization of neural network architectures. High-performance networks derived from NAS include MobileNet, EfficientNet, RegNet [
44] and others. Although NAS methods have achieved good results, they also face several challenges, including high demands on computational resources, complexities in defining effective search spaces, uncertainties in performance evaluation, and limitations in generalization and applicability. Addressing these challenges is crucial for advancing NAS methods to enhance their efficiency and reliability in practical applications.
As discussed above, a wide range of neural network structures and architectures are used in image recognition, with key features and design methods outlined in
Table 1. However, many networks are optimized on datasets such as ImageNet and CIFAR, which do not necessarily guarantee good performance on other datasets. In practical applications, a suitable network architecture should be chosen based on a comprehensive consideration of task scenarios, data resources, computational resources, and other factors.
2.2. RSC Recognition Models
In recent years, deep learning neural networks for RSC recognition have gained widespread attention. In 2019, Pan et al., compared the performance of four CNN models (VGG16, ResNet50, Inception-v3, and Xception) to solve road condition classification problems. The results indicated that ResNet50 is the optimal model for classifying winter road surface conditions [
15]. Yang et al. proposed an Inception-v3 model based on transfer learning to address the low accuracy of conventional methods for recognizing wet and dry RSC [
16]. In 2020, Lee et al., introduced a convolutional network to identify black ice on roads to prevent traffic accidents of automated vehicles [
17]. In 2021, Dewangan et al., developed the RCNet to tackle the challenges of complex scenes, varied road structures, and inappropriate lighting conditions on RSC recognition tasks [
18]. In 2022, Wang et al., addressed the issue of low accuracy on RSC recognition tasks using an improved Inception-ResNet-v2 algorithm [
19]. Huang et al., employed a transfer-learning model based on Inception-v3 for road surface slippery condition recognition and used a full-resolution residual network to segment waterlogged areas on roads [
20]. Xie et al., developed a city RSC model using a pretrained CNN model to fill gaps in city highway condition recognition [
21]. Yang et al., addressed the challenges of complex and variable road surface slippery condition recognition, low recognition rates of conventional machine-learning methods, and poor generalization capabilities by proposing a road surface slippery condition recognition algorithm based on high/low attention residual neural networks [
22]. In 2023, Lee et al. constructed a deep-learning architecture for detecting black ice on roads using a pretrained ResNet-v2 and compared the performance of different models. The results showed that R101-FPN is the best model [
23]. Kou et al., used a ResNeSt network for RSC recognition and proposed an active suspension control algorithm based on RSC recognition, improving performance of the suspension system effectively [
24]. Chen et al., tackled the issues of high cost and limited detection range of conventional hardware-based RSC recognition technologies by proposing a high-speed RSC recognition method based on a U-Net fusion model [
25].
While the aforementioned models have demonstrated significant advantages for RSC recognition, most of them rely on pretrained models and were fine-tuned on their specific datasets, or only minor modifications such as adding attention mechanisms were made to the original architectures. There is no reason why they chose that model. Notably, there is a clear research gap in the current body of work on road surface recognition, as few existing studies on road surface condition recognition have thoroughly investigated or compared the performance of different neural network structures and architectures from previous works.
5. Discussion
5.1. Comparison and Analysis of Different Neural Networks for RSC Recognition
For the sequential structure models, VGG, ResNet18, ResNet50, and DensNet were selected. The choice of the two ResNet versions is due to their differing structures—BasicBlock in ResNet18 and Bottleneck in ResNet50. However, the residual connections in ResNet do not achieve optimal performance under complex and variable road surface conditions. Notably, the deeper ResNet50 model is more prone to overfitting, highlighting that increasing network depth alone does not necessarily improve performance, especially when handling high-dimensional and complex data. Remarkably, DenseNet-121 exhibits outstanding performance levels despite not utilizing the split-transform-merge structure. The dense connectivity in DenseNet enables greater feature reuse and smoother information flow throughout the network, which mitigates the risk of gradient vanishing and enhances its learning capacity, making it particularly well-suited for RSC recognition.
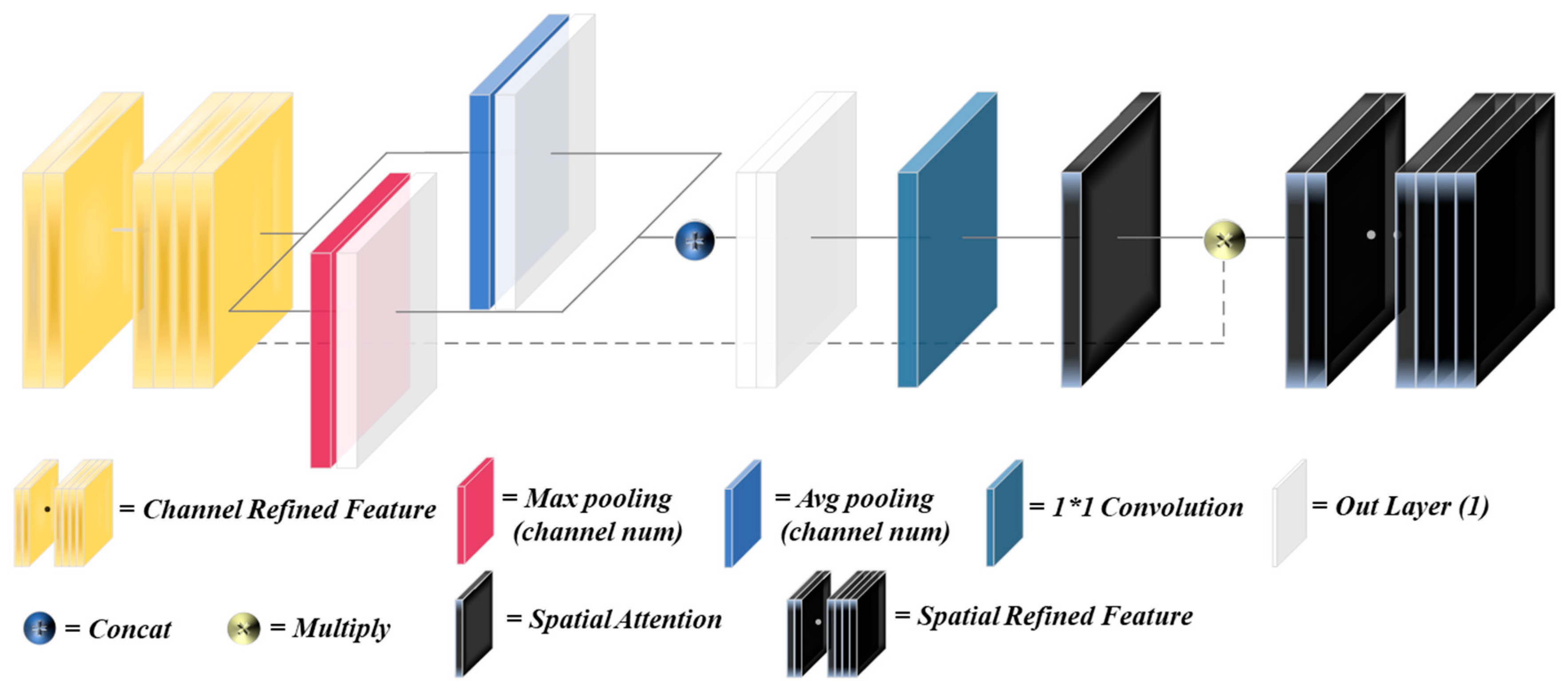
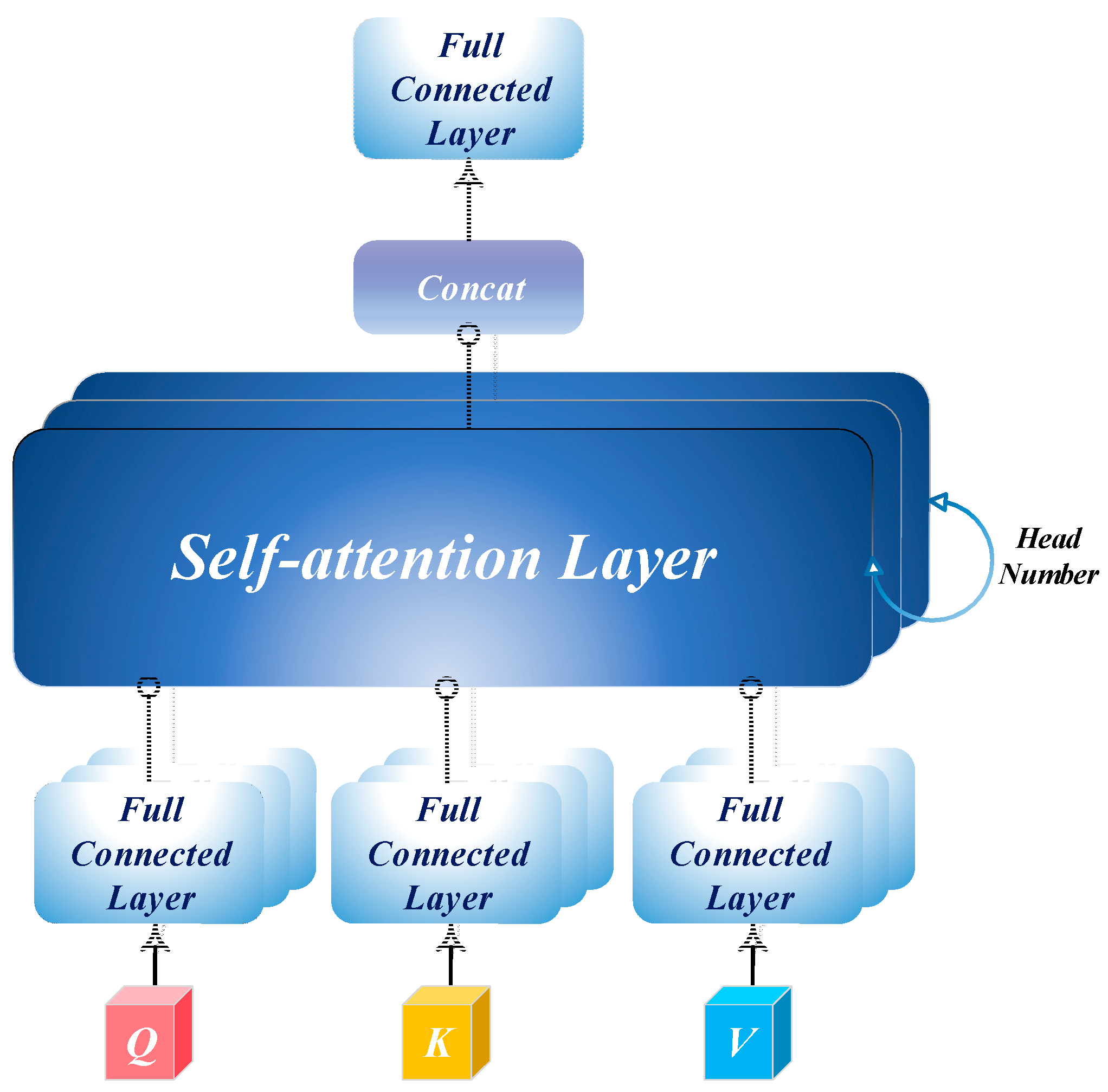
For the multi-branch structure models, Inception-v4, Inception-ResNet-v2, ResNeXt-50, and T-Net were selected. Inception-ResNet-v2 and ResNeXt-50 demonstrate strong performance, primarily due to their split-transform-merge paradigm and effective residual connections. This architectural design enables models to capture features across multiple scales and perspectives, promoting feature reuse and enhancing their recognition capabilities in complex environments. Among the five top-performing models, T-Net stands out for its efficiency, achieving a balanced trade-off between parameter count, computational cost, and accuracy. This success is attributed to the integration of the split-transform-merge structure paradigm, spatial attention, channel attention, and self-attention mechanisms, which heightens the sensitivity of the model to critical features and enables the capture of complex patterns effectively.
For transformer-based models, the ViT and Swin Transformer were assessed. While the ViT achieves higher accuracy, the Swin Transformer proves more effective in reducing loss, suggesting that the sliding window mechanism plays a pivotal role in improving model robustness and generalization. However, a notable overfitting trend is observed in transformer-based models, particularly during the latter stages of training, including ConvNeXt, which is inspired by the design structure of the transformer. Consequently, an early stopping mechanism is recommended to preserve generalization and prevent excessive fitting to training data in these models.
For the lightweight models, ShuffleNet-v2-x2 is distinguished by its use of a channel shuffle mechanism, achieving superior accuracy and low loss despite its higher parameter count. This demonstrates the effectiveness of its carefully designed architecture in balancing complexity and performance. In contrast, the lower accuracy of the EfficientViT-m2 suggests limitations associated with its self-attention mechanisms, which may require more extensive training or larger datasets to fully achieve its potential.
In conclusion, the success of top-performing models such as the Inception-ResNet-v2, ResNeXt-50, and DenseNet-121 for RSC recognition can be attributed to their multi-branch, residual, and dense connection architectures, which enable these models to capture intricate features from diverse perspectives. Moreover, these outcomes underscore the importance of integrating advanced modules, such as CBAM, MHSA, SE, high/low attention, and channel shuffle. Incorporating these elements can further bolster the robustness and performance of models in practical applications, ensuring they are better equipped to handle the challenges posed by RSC recognition.
5.2. Key Modules in T-Net
The ablation experimental results underscore the importance of several key modules in enhancing the performance of T-Net, particularly CBAM and asymmetric convolutions. CBAM introduces spatial and channel attention mechanisms that effectively prioritize important information within feature maps, significantly enhancing the ability to capture essential details. In contrast, the MHSA module has a limited impact on the improvement of accuracy. The increase in parameters does not lead to a significant improvement in performance, indicating that the MHSA plays an auxiliary rather than a key role in the overall architecture.
On the other hand, asymmetric convolutions demonstrate relatively larger benefits than normal convolutions in feature extraction, significantly impacting both accuracy and loss. By utilizing varying kernel sizes, asymmetric convolutions effectively capture multi-scale features, leading to improved model performance for RSC recognition. Additionally, the use of group convolutions, which reduce computational demands by dividing channels, results in marked performance declines. This suggests a trade-off between model complexity and accuracy, highlighting the importance of balancing these factors during network design.
In summary, the integration of CBAM and asymmetric convolutions emerges as a pivotal strategy for enhancing the performance of T-Net. Future research should aim to further optimize these attention mechanisms and convolutional structures to achieve better outcomes while maintaining computational efficiency. This exploration will likely provide valuable insights for refining T-Net and improving its capabilities in various applications.
5.3. Advantage and Limitation of T-Net
T-Net shows outstanding performance in various road surface categories, with particularly high accuracy in fully snowy roads and snow- blowing roads. The results reveal the strong ability of the model to distinguish these critical road surface conditions, which is essential for applications that require precise identification of hazardous situations. The high recall for fully snowy roads further indicates its effectiveness in identifying dangerous conditions, significantly reducing the risk of undetected hazards. Additionally, the high specificity scores for fully snowy roads and dry roads highlight the reliability of the model in minimizing false positives and ensuring accurate classification of non-hazardous conditions. However, it should be noted that the high recognition rate for blowing snow might be due to the limited sample size, enabling the model to fully grasp the characteristics of the available data.
Despite its advantages in accurately identifying snowy and dry road surface conditions, the model has significant limitations, especially for wet roads. The recall for this category implies a potential risk of insufficient detection of hazardous wet conditions, which is crucial for road safety. Similarly, the precision for wet roads suggests a relatively higher FPR, indicating frequent misclassification of other road categories as wet. This problem could result in inappropriate responses, such as unnecessary warnings or inefficient resource allocation. The F1-score for wet roads further reflects the constraints in this case. The cause of this phenomenon lies in the fact that the wet road surface inherently possesses a relatively high reflectivity, which is highly similar to that of the icy road, the melting-snow road, and the darker dry road. This is a challenging issue for RSC recognition.
6. Conclusions
Conventional methods have fallen short of meeting the real-time RSC monitoring requirements of the Tianshan Highway network, failing to align effectively with practical needs. Against this backdrop, this study introduces T-Net, an innovative neural network designed under a split-transform-merge paradigm. T-Net is purposefully built to monitor road conditions in real time and accurately detect ice and snow hazards, providing robust support for road safety assurance.
T-Net achieves an impressive balance between inference speed and accuracy, showcasing significant advantages. It surpasses 14 previous SOTA models and 3 networks specifically tailored for RSC tasks. Notably, models with multi-branch architectures, residual connections, and dense connections—such as Inception-ResNet-v2, ResNeXt-50, DenseNet-121, and T-Net—demonstrated superior performance for RSC recognition. The T-Net, in particular, delivered remarkable results, achieving a classification accuracy of 98.7%, a recall of 96.2%, a specificity of 99.3%, a precision of 96.4%, an F1-score of 96.4%, an AUC of 97.9%, and an FDR of 0.8%.
While these outcomes are promising, it is essential to acknowledge certain limitations of the T-Net. For instance, it has a greater probability of misclassifying the wet roads as other roads, and its performance in the complex environment of the Tianshan Highway network still awaits further validation. Future research will aim to address these shortcomings by continuously optimizing the architecture of T-Net and integrating it into a comprehensive road monitoring system to establish robust RSC data engineering. Additionally, a semantic segmentation variant of T-Net will be developed. Future experiments will also investigate how the performance of model evolves as dataset sizes increase, aiming to enhance its applicability for RSC recognition.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 CBAM
CBAM