

Inter-Domain Invariant Cross-Domain Object Detection Using Style and Content Disentanglement for In-Vehicle Images
 , , ,
, , ,
Abstract
:
1. Introduction
- (1)
- Due to the negative relationship between the size of the domain gap and the performance of the detector, as well as the neglect of the content gap within the domain gap, we decouple the domain gap into the style and content gap to reduce the domain gap and generate the corresponding synthetic intermediate domain datasets.
- (2)
- To ensure the effective learning in the inter-domain invariance, we employ alternating learning to separately handle the style and content gap. Additionally, we utilize style-invariant loss and the mean teacher self-training framework to address the style and content gap, respectively.
- (3)
- We introduce a multiscale fusion strategy to enhance the detection performance of extreme-scale (very large or very small) objects, thereby improving the quality of pseudo-labels.
- (4)
- Through comprehensive experiments conducted on various adaptation benchmarks in the context of autonomous driving scenarios, we have demonstrated that our proposed method outperforms the majority of existing methods.
2. Related Work
2.1. Object Detection
2.2. Unsupervised Domain Adaptive Object Detection (UDA-OD)
2.3. Pseudo-Label Optimization
3. Method
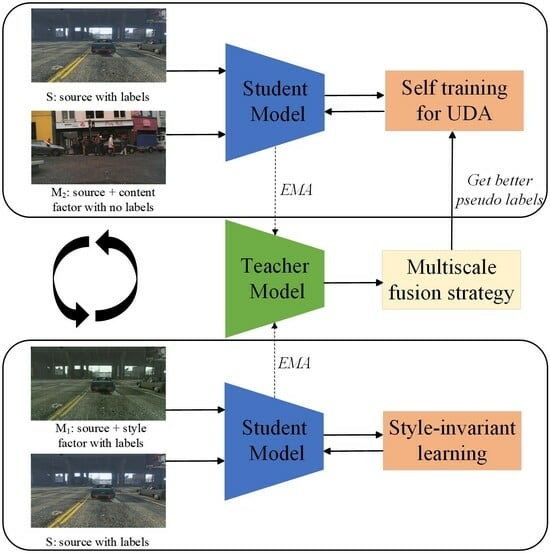
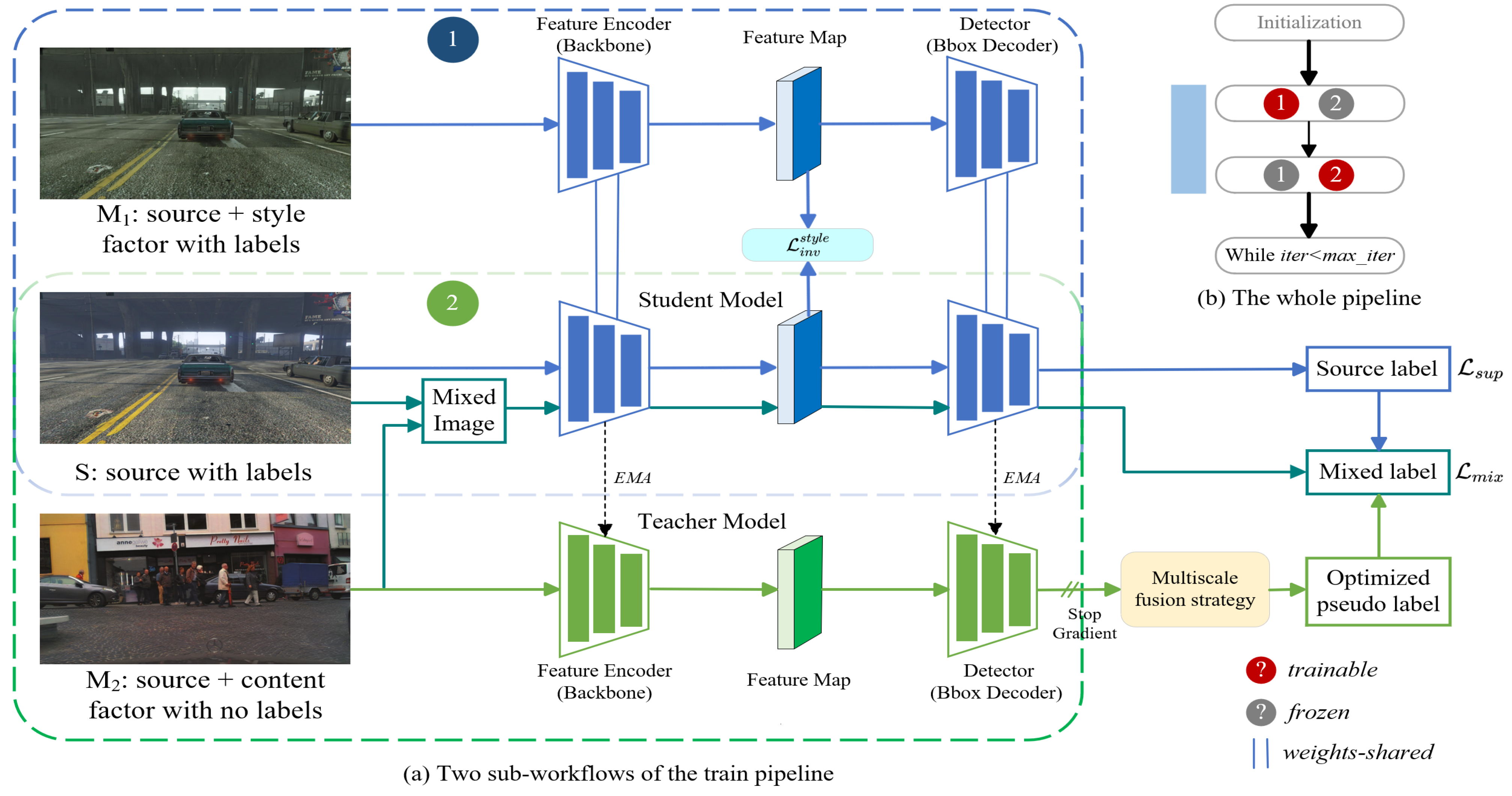
3.1. Overview
3.2. Supervised Training in the Source Domain
3.3. Style Invariant Loss
3.4. Self Training in the Target Domain
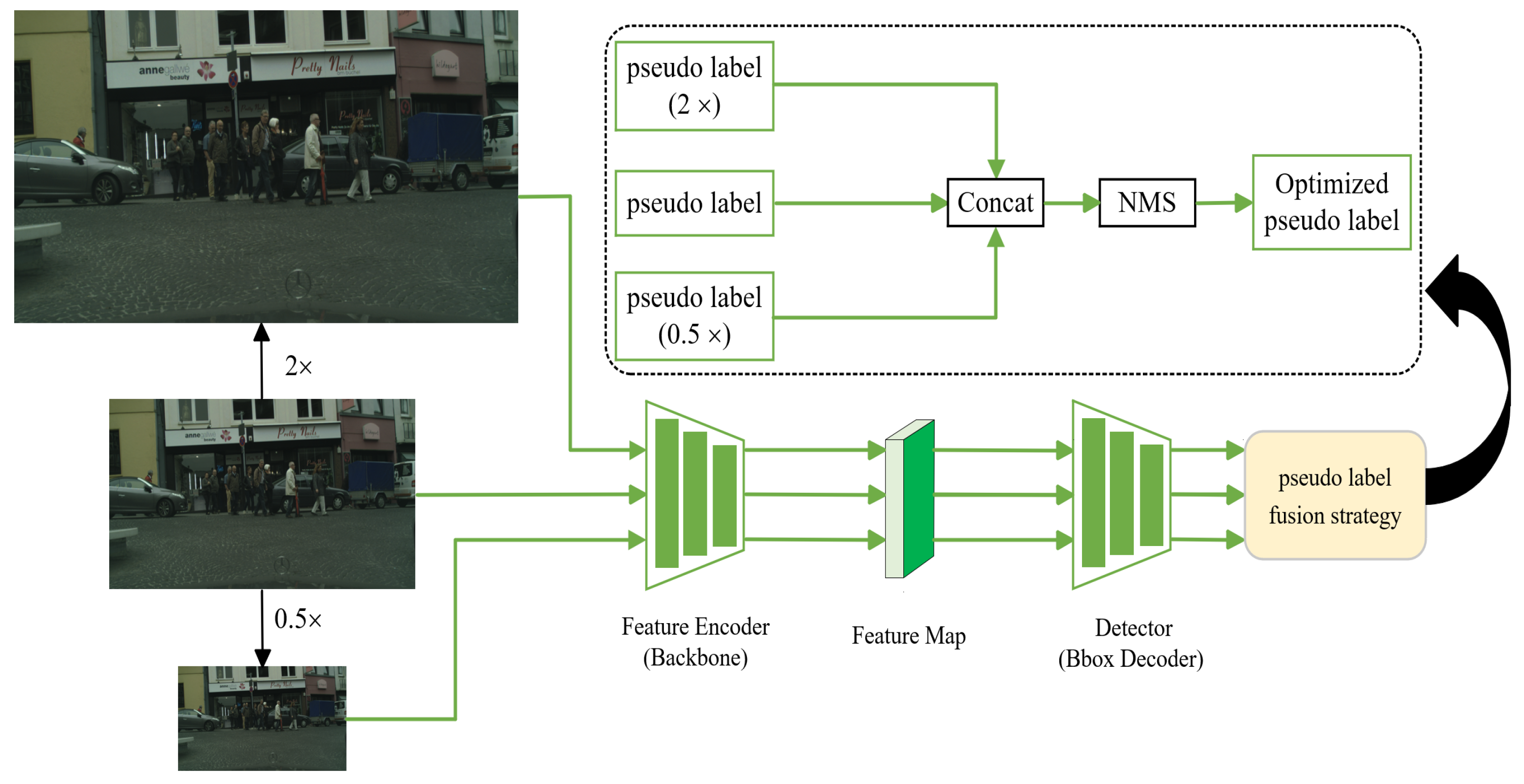
3.5. Pseudo-Label Optimization Based on Multi-Resolution
3.6. Total Loss
4. Experimental Result
4.1. Datasets
4.2. Implementation Details
4.3. Performance Comparison
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhu, H.; Yuen, K.V.; Mihaylova, L.; Leung, H. Overview of environment perception for intelligent vehicles. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2584–2601. [Google Scholar] [CrossRef]
- Gopalan, R.; Li, R.; Chellappa, R. Domain adaptation for object recognition: An unsupervised approach. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 999–1006. [Google Scholar]
- Chen, Y.; Li, W.; Chen, X.; Gool, L.V. Learning semantic segmentation from synthetic data: A geometrically guided input-output adaptation approach. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1841–1850. [Google Scholar]
- Chen, Y.; Li, W.; Sakaridis, C.; Dai, D.; Van Gool, L. Domain adaptive faster r-cnn for object detection in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3339–3348. [Google Scholar]
- Wilson, G.; Cook, D.J. A survey of unsupervised deep domain adaptation. ACM Trans. Intell. Syst. Technol. 2020, 11, 1–46. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, X.; Yuan, L.; Feng, J. Few-shot adaptive faster r-cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7173–7182. [Google Scholar]
- Zhuang, C.; Han, X.; Huang, W.; Scott, M. ifan: Image-instance full alignment networks for adaptive object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13122–13129. [Google Scholar]
- Rezaeianaran, F.; Shetty, R.; Aljundi, R.; Reino, D.O.; Zhang, S.; Schiele, B. Seeking similarities over differences: Similarity-based domain alignment for adaptive object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9204–9213. [Google Scholar]
- Saito, K.; Ushiku, Y.; Harada, T.; Saenko, K. Strong-weak distribution alignment for adaptive object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6956–6965. [Google Scholar]
- Xie, R.; Yu, F.; Wang, J.; Wang, Y.; Zhang, L. Multi-level domain adaptive learning for cross-domain detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Zhang, H.; Tian, Y.; Wang, K.; He, H.; Wang, F.Y. Synthetic-to-real domain adaptation for object instance segmentation. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–7. [Google Scholar]
- Chen, C.; Zheng, Z.; Ding, X.; Huang, Y.; Dou, Q. Harmonizing transferability and discriminability for adapting object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8869–8878. [Google Scholar]
- Zhu, X.; Pang, J.; Yang, C.; Shi, J.; Lin, D. Adapting object detectors via selective cross-domain alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 687–696. [Google Scholar]
- Wang, W.; Cao, Y.; Zhang, J.; He, F.; Zha, Z.J.; Wen, Y.; Tao, D. Exploring sequence feature alignment for domain adaptive detection transformers. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 1730–1738. [Google Scholar]
- Wang, K.; Pu, L.; Dong, W. Cross-domain Adaptive Object Detection Based on Refined Knowledge Transfer and Mined Guidance in Autonomous Vehicles. IEEE Trans. Intell. Veh. 2023, 7, 603–615. [Google Scholar] [CrossRef]
- Cai, Q.; Pan, Y.; Ngo, C.W.; Tian, X.; Duan, L.; Yao, T. Exploring object relation in mean teacher for cross-domain detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11457–11466. [Google Scholar]
- Deng, J.; Li, W.; Chen, Y.; Duan, L. Unbiased mean teacher for cross-domain object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 11–17 October 2021; pp. 4091–4101. [Google Scholar]
- Li, Y.J.; Dai, X.; Ma, C.Y.; Liu, Y.C.; Chen, K.; Wu, B.; He, Z.; Kitani, K.; Vajda, P. Cross-domain adaptive teacher for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7581–7590. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Hsu, H.K.; Yao, C.H.; Tsai, Y.H.; Hung, W.C.; Tseng, H.Y.; Singh, M.; Yang, M.H. Progressive domain adaptation for object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 749–757. [Google Scholar]
- Arruda, V.F.; Paixao, T.M.; Berriel, R.F.; De Souza, A.F.; Badue, C.; Sebe, N.; Oliveira-Santos, T. Cross-domain car detection using unsupervised image-to-image translation: From day to night. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Oza, P.; Sindagi, V.A.; Sharmini, V.V.; Patel, V.M. Unsupervised domain adaptation of object detectors: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 1–24. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar]
- Viola, P.; Jones, M.J. Robust real-time face detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Lecture Notes in Computer Science, Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part I 14; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Lecture Notes in Computer Science, Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part I 16; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Lecture Notes in Computer Science, Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Part V 13; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Cao, S.; Joshi, D.; Gui, L.Y.; Wang, Y.X. Contrastive Mean Teacher for Domain Adaptive Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 23839–23848. [Google Scholar]
- Gong, K.; Li, S.; Li, S.; Zhang, R.; Liu, C.H.; Chen, Q. Improving Transferability for Domain Adaptive Detection Transformers. In Proceedings of the 30th ACM International Conference on Multimedia, Lisbon, Portugal, 10–13 October 2022; pp. 1543–1551. [Google Scholar]
- Li, W.; Li, L.; Yang, H. Progressive cross-domain knowledge distillation for efficient unsupervised domain adaptive object detection. Eng. Appl. Artif. Intell. 2023, 119, 105774. [Google Scholar] [CrossRef]
- Yu, F.; Wang, D.; Chen, Y.; Karianakis, N.; Shen, T.; Yu, P.; Lymberopoulos, D.; Lu, S.; Shi, W.; Chen, X. Sc-uda: Style and content gaps aware unsupervised domain adaptation for object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 382–391. [Google Scholar]
- Liu, L.; Zhang, B.; Zhang, J.; Zhang, W.; Gan, Z.; Tian, G.; Zhu, W.; Wang, Y.; Wang, C. MixTeacher: Mining Promising Labels with Mixed Scale Teacher for Semi-Supervised Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7370–7379. [Google Scholar]
- Mattolin, G.; Zanella, L.; Ricci, E.; Wang, Y. ConfMix: Unsupervised Domain Adaptation for Object Detection via Confidence-based Mixing. In Proceedings of theIEEE/CVF Winter Conference on Applications of Computer Vision, Vancouver, BC, Canada, 18–22 June 2023; pp. 423–433. [Google Scholar]
- Johnson-Roberson, M.; Barto, C.; Mehta, R.; Sridhar, S.N.; Rosaen, K.; Vasudevan, R. Driving in the matrix: Can virtual worlds replace human-generated annotations for real world tasks? arXiv 2016, arXiv:1610.01983. [Google Scholar]
- Yu, F.; Xian, W.; Chen, Y.; Liu, F.; Liao, M.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving video database with scalable annotation tooling. arXiv 2018, arXiv:1805.04687. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3213–3223. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Bottou, L. Stochastic gradient descent tricks. In Neural Networks: Tricks of the Trade, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 421–436. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Yoo, J.; Chung, I.; Kwak, N. Unsupervised domain adaptation for one-stage object detector using offsets to bounding box. In Proceedings of the European Conference on Computer Vision, ECCV 2022: Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 691–708. [Google Scholar]
- Xu, C.D.; Zhao, X.R.; Jin, X.; Wei, X.S. Exploring categorical regularization for domain adaptive object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11724–11733. [Google Scholar]
- Zhou, Q.; Gu, Q.; Pang, J.; Lu, X.; Ma, L. Self-adversarial disentangling for specific domain adaptation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 8954–8968. [Google Scholar] [CrossRef] [PubMed]
- Jiang, J.; Chen, B.; Wang, J.; Long, M. Decoupled adaptation for cross-domain object detection. arXiv 2021, arXiv:2110.02578. [Google Scholar]
- Hsu, C.C.; Tsai, Y.H.; Lin, Y.Y.; Yang, M.H. Every pixel matters: Center-aware feature alignment for domain adaptive object detector. In Lecture Notes in Computer Science, Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part IX 16; Springer: Cham, Switzerland, 2020; pp. 733–748. [Google Scholar]
- Li, W.; Liu, X.; Yuan, Y. Sigma: Semantic-complete graph matching for domain adaptive object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5291–5300. [Google Scholar]
- Zhang, L.; Zhou, W.; Fan, H.; Luo, T.; Ling, H. Robust Domain Adaptive Object Detection with Unified Multi-Granularity Alignment. arXiv 2023, arXiv:2301.00371. [Google Scholar]
- Hnewa, M.; Radha, H. Integrated Multiscale Domain Adaptive YOLO. IEEE Trans. Image Process. 2023, 32, 1857–1867. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Ji, Z.; Qu, X.; Zhou, R.; Cao, D. Cross-domain object detection for autonomous driving: A stepwise domain adaptative YOLO approach. IEEE Trans. Intell. Veh. 2022, 7, 603–615. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cross Domain Scenarios | Trainig Set | Validation Set | |
|---|---|---|---|
| Source Domain | Target Domain | Target Domain | |
| KITTI | Cityscapes | Cityscapes | |
| 10,000 | 2975 | 500 | |
| Sim10k | Cityscapes | Cityscapes | |
| 7481 | 7481 | 500 | |
| Cityscapes | BDD100k | BDD100k | |
| 2975 | 36728 | 5258 | |
| Method | Detector | Backbone | Car AP |
|---|---|---|---|
| Source | RetinaNet | Swin-T | 41.5 |
| DAF [4] | Faster R-CNN | VGG-16 | 41.9 |
| SWDA [9] | Faster R-CNN | ResNet-101 | 44.6 |
| SCDA [13] | Faster R-CNN | VGG-16 | 45.1 |
| MTOR [16] | Faster R-CNN | ResNet-50 | 46.6 |
| CR-DA [59] | Faster R-CNN | VGG-16 | 43.1 |
| CR-SW [59] | Faster R-CNN | VGG-16 | 46.2 |
| SAD [60] | Faster R-CNN | ResNet-50 | 49.2 |
| ViSGA [8] | Faster R-CNN | ResNet-50 | 49.3 |
| D-adapt [61] | Faster R-CNN | ResNet-101 | 53.2 |
| EPM [62] | FCOS | ResNet-101 | 47.3 |
| SIGMA [63] | FCOS | ResNet-50 | 53.7 |
| MGA [64] | FCOS | ResNet-101 | 55.4 |
| OADA [58] | FCOS | VGG-16 | 56.6 |
| SFA [14] | D-DETR | ResNet-50 | 52.6 |
| net [46] | D-DETR | ResNet-50 | 54.1 |
| Our (IDI-SCD) | RetinaNet | Swin-T | 57.7 |
| Method | Detector | Backbone | Car AP |
|---|---|---|---|
| Source | RetinaNet | Swin-T | 42.3 |
| DAF [4] | Faster R-CNN | VGG-16 | 41.8 |
| SWDA [9] | Faster R-CNN | ResNet-101 | 43.2 |
| RKTMG [15] | Faster R-CNN | ResNet-50 | 43.5 |
| SCDA [13] | Faster R-CNN | VGG-16 | 43.6 |
| ViSGA [8] | Faster R-CNN | ResNet-50 | 47.6 |
| EPM [62] | FCOS | ResNet-101 | 45.0 |
| SIGMA [63] | FCOS | ResNet-50 | 45.8 |
| OADA [58] | FCOS | VGG-16 | 46.3 |
| MGA [64] | FCOS | ResNet-101 | 47.6 |
| MS-DAYOLO [65] | YOLOv5 | CSP-Darknet53 | 47.6 |
| DAYOLO [66] | YOLOv5 | CSP-Darknet53 | 48.7 |
| S-DAYOLO [66] | YOLOv5 | CSP-Darknet53 | 49.3 |
| Our (IDI-SCD) | RetinaNet | Swin-T | 49.9 |
| Method | Detector | Backbone | Person | Rider | Car | Truck | Bus | Mcycle | Bicycle | mAP |
|---|---|---|---|---|---|---|---|---|---|---|
| Source | RetinaNet | Swin-T | 35.0 | 27.4 | 54.7 | 17.3 | 11.2 | 15.1 | 22.8 | 26.2 |
| DAF [4] | Faster R-CNN | VGG-16 | 28.9 | 27.4 | 44.2 | 19.1 | 18.0 | 14.2 | 22.4 | 24.9 |
| SWDA [9] | Faster R-CNN | ResNet-101 | 29.5 | 29.9 | 44.8 | 20.2 | 20.7 | 15.2 | 23.1 | 26.2 |
| SCDA [13] | Faster R-CNN | VGG-16 | 29.3 | 29.2 | 44.4 | 20.3 | 19.6 | 14.8 | 23.2 | 25.8 |
| CR-DA [59] | Faster R-CNN | VGG-16 | 30.8 | 29.0 | 44.8 | 20.5 | 19.8 | 14.1 | 22.8 | 26.0 |
| CR-SW [59] | Faster R-CNN | VGG-16 | 32.8 | 29.3 | 45.8 | 22.7 | 20.6 | 14.9 | 25.5 | 27.4 |
| EPM [62] | FCOS | ResNet-101 | 39.6 | 26.8 | 55.8 | 18.8 | 19.1 | 14.5 | 20.1 | 27.8 |
| SFA [14] | D-DETR | ResNet-50 | 40.2 | 27.6 | 57.8 | 19.1 | 23.4 | 15.4 | 19.2 | 28.9 |
| net [46] | D-DETR | ResNet-50 | 40.4 | 31.2 | 58.6 | 20.4 | 25.0 | 14.9 | 22.7 | 30.5 |
| Our (IDI-SCD) | RetinaNet | Swin-T | 43.5 | 34.0 | 61.1 | 18.4 | 15.6 | 21.1 | 32.3 | 32.2 |
| Weight | 0.2 | 0.4 | 0.6 | 0.8 | 1.0 | |
|---|---|---|---|---|---|---|
| car AP | 52.1 | 56.3 | 57.0 | 56.7 | 51.2 | 57.7 |
| 1 | 2 | 5 | 10 | 15 | 20 | |
|---|---|---|---|---|---|---|
| car AP | 57.3 | 57.6 | 57.0 | 57.7 | 57.5 | 57.4 |
| Different Combinations of Image Inputs | Car | Car | Car | Car | ||
|---|---|---|---|---|---|---|
| 1.0× | 0.5× | 2× | ||||
| ✓ | 55.2 | 24.2 | 66.2 | 86.0 | ||
| ✓ | ✓ | 55.8 | 25.5 | 66.0 | 87.5 | |
| ✓ | ✓ | 56.3 | 26.4 | 66.9 | 87.3 | |
| ✓ | ✓ | ✓ | 57.7 | 28.0 | 68.8 | 88.5 |
| Combination of Two Sub-Workflows in Train Pipeline | w/AT | mAP | |
|---|---|---|---|
| 48.3 | |||
| 53.9 | |||
| 52.7 | |||
| 55.2 | |||
| ✓ | 57.7 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Z.; Zhang, Y.; Wang, Z.; Yu, Y.; Zhang, Z.; Zhang, M.; Zhang, L.; Cheng, B. Inter-Domain Invariant Cross-Domain Object Detection Using Style and Content Disentanglement for In-Vehicle Images. Remote Sens. 2024, 16, 304. https://doi.org/10.3390/rs16020304
Jiang Z, Zhang Y, Wang Z, Yu Y, Zhang Z, Zhang M, Zhang L, Cheng B. Inter-Domain Invariant Cross-Domain Object Detection Using Style and Content Disentanglement for In-Vehicle Images. Remote Sensing. 2024; 16(2):304. https://doi.org/10.3390/rs16020304
Chicago/Turabian StyleJiang, Zhipeng, Yongsheng Zhang, Ziquan Wang, Ying Yu, Zhenchao Zhang, Mengwei Zhang, Lei Zhang, and Binbin Cheng. 2024. "Inter-Domain Invariant Cross-Domain Object Detection Using Style and Content Disentanglement for In-Vehicle Images" Remote Sensing 16, no. 2: 304. https://doi.org/10.3390/rs16020304
APA StyleJiang, Z., Zhang, Y., Wang, Z., Yu, Y., Zhang, Z., Zhang, M., Zhang, L., & Cheng, B. (2024). Inter-Domain Invariant Cross-Domain Object Detection Using Style and Content Disentanglement for In-Vehicle Images. Remote Sensing, 16(2), 304. https://doi.org/10.3390/rs16020304