
An Long Short-Term Memory Model with Multi-Scale Context Fusion and Attention for Radar Echo Extrapolation

 ,
,
Abstract
1. Introduction
- We propose a multi-scale contextual information fusion module for efficient multi-scale feature extraction, as well as for the improvement in the correlation between contexts. It effectively improves the blurring problem of predicted images and enhances the details.
- We propose an attention module that effectively improves the forgetting problem of the prediction unit during information transmission. A better establishment of long-term time dependence improves the prediction of high echo regions.
- Combining the above two methods, CAST-LSTM is constructed. Experiments show that CAST-LSTM achieves state-of-the-art results on long-term prediction tasks.
2. Data
2.1. Moving MNIST Dataset
2.2. Radar Dataset
3. Algorithm Description
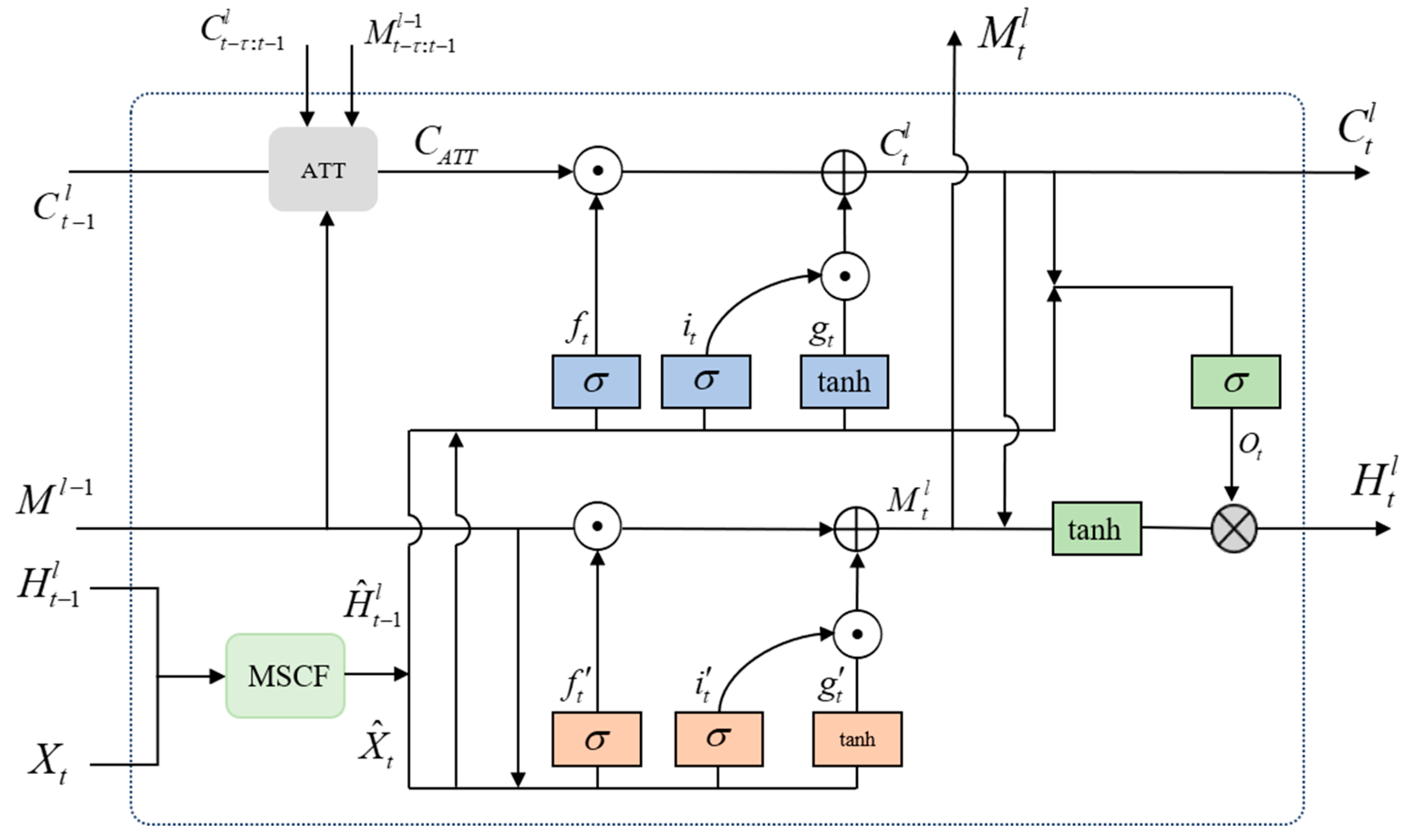
3.1. Context Fusion Module
3.2. Attention Module
3.3. MCA-LSTM Cell
3.4. MCA-LSTM Network Structure
3.5. Evaluation Metrics
4. Experiments and Analysis
4.1. Moving MNIST Experiments
Results and Analysis
4.2. Radar Dataset Experiments
Results and Analysis
5. Conclusions
- The proposed multi-scale context information fusion module effectively enhances the contextual relevance of network units and improves the detail of the predicted images by extracting multi-scale feature information.
- The proposed attention module captures more historical temporal dynamics from a broader perception field, reducing information loss and enhancing the prediction capability for strong echo regions.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Singh, S.; Sarkar, S.; Mitra, P. A deep learning based approach with adversarial regularization for Doppler weather radar ECHO prediction. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Fort Worth, TX, USA, 23–28 July 2017; pp. 5205–5208. [Google Scholar]
- Marshall, J. The distribution of raindrops with size. J. Meteor. 1948, 5, 165–166. [Google Scholar] [CrossRef]
- Rinehart, R.; Garvey, E. Three-dimensional storm motion detection by conventional weather radar. Nature 1978, 273, 287–289. [Google Scholar] [CrossRef]
- Zou, H.; Wu, S.; Shan, J. A method of radar echo extrapolation based on TREC and Barnes filter. J. Atmos. Ocean. Technol. 2019, 36, 1713–1727. [Google Scholar] [CrossRef]
- Lakshmanan, V.; Hondl, K.; Rabin, R. An efficient, general-purpose technique for identifying storm cells in geospatial images. J. Atmos. Ocean. Technol. 2009, 26, 523–537. [Google Scholar] [CrossRef]
- Chung, K.; Yao, I. Improving radar echo Lagrangian extrapolation nowcasting by blending numerical model wind information: Statistical performance of 16 typhoon cases. Mon. Weather. Rev. 2020, 148, 1099–1120. [Google Scholar] [CrossRef]
- Woo, W.; Wong, W. Operational application of optical flow techniques to radar-based rainfall nowcasting. Atmosphere 2017, 8, 48. [Google Scholar] [CrossRef]
- Ayzel, G.; Heistermann, M.; Winterrath, T. Optical flow models as an open benchmark for radar-based precipitation nowcasting (rainymotion v0.1). Geosci. Model Dev. 2019, 12, 1387–1402. [Google Scholar] [CrossRef]
- Chang, Z.; Zhang, Y.; Wang, S. A Motion-Aware Unit for Video Prediction and Beyond. Adv. Neural Inf. Process. Syst. 2021, 34, 26950–26962. [Google Scholar]
- Tamaru, R.; Siritanawan, P.; Kotani, K. Interaction Aware Relational Representations for Video Prediction. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Melbourne, Australia, 17–20 October 2021; pp. 2089–2094. [Google Scholar]
- Bei, X.; Yang, Y.; Soatto, S. Learning semantic-aware dynamics for video prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 902–912. [Google Scholar]
- Tian, C.; Chan, W. Spatial-temporal attention wavenet: A deep learning framework for traffic prediction considering spatial-temporal dependencies. IET Intell. Transp. Syst. 2021, 15, 549–561. [Google Scholar] [CrossRef]
- Yin, X.; Wu, G.; Wei, J.; Shen, Y.; Qi, H.; Yin, B. Deep learning on traffic prediction: Methods, analysis and future directions. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4927–4943. [Google Scholar] [CrossRef]
- Zhao, J.; Liu, Z.; Sun, Q.; Li, Q.; Jia, X.; Zhang, R. Attention-based dynamic spatial-temporal graph convolutional networks for traffic speed forecasting. Expert Syst. Appl. 2022, 204, 117511. [Google Scholar] [CrossRef]
- Guo, S.; Xiao, D.; Yuan, X. Short-term rainfall prediction method based on neural network and model ensemble. Adv. Meteor. Sci. Technol. 2017, 7, 107–113. [Google Scholar]
- Huang, J.; Cao, R.; Yao, R. Application of deep learning network in precipitation phase identification and prediction. Meteor. Mon. 2021, 47, 317–326. [Google Scholar]
- Guo, H.; Chen, M.; Han, L.; Zhang, W.; Qing, R.; Song, L. Correlation analysis between vegetation coverage and climate drought conditions in North China during 2001–2013. J. Geogr. Sci. 2017, 27, 143–160. [Google Scholar]
- Chen, J.; Feng, Y.; Meng, W. Research on hourly precipitation forecast correction method based on convolutional neural network. Meteor. Mon. 2021, 47, 60–70. [Google Scholar]
- Li, Y.; Li, Q.; Wei, J. Meteorological radar echo extrapolation based on ConvLSTM. J. Qinghai Univ. 2021, 39, 93–100. [Google Scholar]
- Yin, Q.; Gan, J.; Qi, H.; Hu, W.; Zhang, Y.; Li, R.; Tang, W. An improved recurrent neural network radar image extrapolation algorithm. Meteor. Sci. Technol. 2021, 49, 18–24. [Google Scholar]
- Huang, X.; Ma, Y.; Hu, S. Extrapolation and effect analysis of weather radar echo sequence based on deep learning. Acta Meteor. Sin. 2021, 27, 817–827. [Google Scholar]
- Luo, C.; Li, X.; Ye, Y. A spatiotemporal LSTM model with pseudo flow prediction for precipitation nowcasting. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 843–857. [Google Scholar] [CrossRef]
- Ravuri, S.; Lenc, K.; Willson, M.; Kangin, D.; Lam, R.; Mirowski, P.; Fitzsimons, M.; Athanassiadou, M.; Kashem, S.; Madge, S.; et al. Skilful precipitation nowcasting using deep generative models of radar. Nature 2021, 597, 672–677. [Google Scholar] [CrossRef]
- Pathak, J.; Subramanian, S.; Harrington, P.; Raja, S.; Chattopadhyay, A.; Mardani, M.; Kurth, T.; Hall, D.; Li, Z.; Azizzadenesheli, K.; et al. Fourcastnet: A global data-driven high-resolution weather model using adaptive fourier neural operators. arXiv 2022, arXiv:2202.11214. [Google Scholar]
- Lam, R.; Sanchez-Gonzalez, A.; Willson, M.; Wirnsberger, P.; Fortunato, M.; Alet, F. GraphCast: Learning skillful medium-range global weather forecasting. arXiv 2022, arXiv:2212.12794. [Google Scholar]
- Bi, K.; Xie, L.; Zhang, H.; Chen, X.; Gu, X.; Tian, Q. Pangu-weather: A 3d high-resolution model for fast and accurate global weather forecast. arXiv 2022, arXiv:2211.02556. [Google Scholar]
- Andrychowicz, M.; Espeholt, L.; Li, D.; Merchant, S.; Merose, A.; Zyda, F.; Agrawal, S.; Kalchbrenner, N. Deep Learning for Day Forecasts from Sparse Observations. arXiv 2023, arXiv:2306.06079. [Google Scholar]
- Chen, L.; Du, F.; Hu, Y.; Wang, Z.; Wang, F. SwinRDM: Integrate SwinRNN with diffusion model towards high-resolution and high-quality weather forecasting. Proc. AAAI Conf. Artif. Intell. 2023, 37, 322–330. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.; Wong, W.; Woo, W. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 28–39. [Google Scholar]
- Wang, Y.; Long, M.; Wang, J.; Gao, Z.; Yu, P. Predrnn: A Recurrent Neural Network for Spatiotemporal Predictive Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 45, 2208–2225. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Gao, Z.; Long, M. Predrnn++: Towards a resolution of thedeep-in-time dilemma in spatiotemporal predictive learning. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5123–5132. [Google Scholar]
- Wang, Y.; Jiang, L.; Yang, M. Eidetic 3D LSTM: A model for video prediction and beyond. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Wang, Y.; Zhang, J.; Zhu, H. Memory in memory: A predictive neural network for learning higher-order non-stationarity from spatiotemporal dynamics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9154–9162. [Google Scholar]
- Luo, C.; Zhao, X.; Sun, Y.; Li, X.; Ye, Y. Predrann: The spatiotemporal attention convolution recurrent neural network for precipitation nowcasting. Knowl.-Based Syst. 2022, 239, 107900. [Google Scholar] [CrossRef]
- Yang, Z.; Wu, H.; Liu, Q.; Liu, X.; Zhang, Y.; Cao, X. A self-attention integrated spatiotemporal LSTM approach to edge-radar echo extrapolation in the Internet of Radars. ISA Trans. 2023, 132, 155–166. [Google Scholar] [CrossRef]
- Ma, Z.; Zhang, H.; Liu, J. Preciplstm: A meteorological spatiotemporal lstm for precipitation nowcasting. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4109108. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Forecast | Forecast | |
|---|---|---|
| True | TN (True negative) | FP (False positive) |
| True | FN (False negative) | TP (True positive) |
| Method | MSE/Frame↓ | SSIM/Frame↑ |
|---|---|---|
| ConvGRU | 103.4 | 0.713 |
| ConvLSTM | 102.3 | 0.725 |
| PredRNN | 55.8 | 0.866 |
| PredRNN++ | 45.6 | 0.895 |
| MIM | 44.1 | 0.905 |
| IDA-LSTM | 38.4 | 0.916 |
| MCA-LSTM | 29.7 | 0.938 |
| Method | 20 dBZ | 35 dBZ | 45 dBZ | Avg |
|---|---|---|---|---|
| ConvGRU | 0.5805 | 0.4461 | 0.1605 | 0.3957 |
| ConvLSTM | 0.5829 | 0.4588 | 0.1647 | 0.4021 |
| PredRNN | 0.5894 | 0.4323 | 0.1660 | 0.3959 |
| PredRNN++ | 0.5753 | 0.4606 | 0.1491 | 0.3950 |
| MIM | 0.5808 | 0.4488 | 0.1636 | 0.3977 |
| IDA-LSTM | 0.5721 | 0.4267 | 0.1334 | 0.3774 |
| MCA-LSTM | 0.5803 | 0.4631 | 0.1852 | 0.4095 |
| Method | 20 dBZ | 35 dBZ | 45 dBZ | Avg |
|---|---|---|---|---|
| ConvGRU | 0.6541 | 0.5497 | 0.2396 | 0.4811 |
| ConvLSTM | 0.6558 | 0.5629 | 0.2445 | 0.4877 |
| PredRNN | 0.6609 | 0.5646 | 0.2449 | 0.4901 |
| PredRNN++ | 0.6491 | 0.5435 | 0.2216 | 0.4714 |
| MIM | 0.6529 | 0.5521 | 0.2413 | 0.4821 |
| IDA-LSTM | 0.6446 | 0.5294 | 0.2019 | 0.4586 |
| MCA-LSTM | 0.6511 | 0.5673 | 0.2725 | 0.4970 |
| Method | 20 dBZ | 35 dBZ | 45 dBZ | Avg |
|---|---|---|---|---|
| ConvGRU | 0.6585 | 0.5177 | 0.1886 | 0.4549 |
| ConvLSTM | 0.6651 | 0.5408 | 0.1937 | 0.4665 |
| PredRNN | 0.6791 | 0.5425 | 0.1951 | 0.4722 |
| PredRNN++ | 0.6448 | 0.5078 | 0.1741 | 0.4422 |
| MIM | 0.6642 | 0.5209 | 0.1908 | 0.4586 |
| IDA-LSTM | 0.6551 | 0.4921 | 0.1516 | 0.4329 |
| MCA-LSTM | 0.6755 | 0.5561 | 0.2239 | 0.4852 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, G.; Qu, H.; Luo, J.; Cheng, Y.; Wang, J.; Zhang, P. An Long Short-Term Memory Model with Multi-Scale Context Fusion and Attention for Radar Echo Extrapolation. Remote Sens. 2024, 16, 376. https://doi.org/10.3390/rs16020376
He G, Qu H, Luo J, Cheng Y, Wang J, Zhang P. An Long Short-Term Memory Model with Multi-Scale Context Fusion and Attention for Radar Echo Extrapolation. Remote Sensing. 2024; 16(2):376. https://doi.org/10.3390/rs16020376
Chicago/Turabian StyleHe, Guangxin, Haifeng Qu, Jingjia Luo, Yong Cheng, Jun Wang, and Ping Zhang. 2024. "An Long Short-Term Memory Model with Multi-Scale Context Fusion and Attention for Radar Echo Extrapolation" Remote Sensing 16, no. 2: 376. https://doi.org/10.3390/rs16020376
APA StyleHe, G., Qu, H., Luo, J., Cheng, Y., Wang, J., & Zhang, P. (2024). An Long Short-Term Memory Model with Multi-Scale Context Fusion and Attention for Radar Echo Extrapolation. Remote Sensing, 16(2), 376. https://doi.org/10.3390/rs16020376