Figure 1.
Illustration of existing PU methods. Such methods utilize clustering algorithms to obtain pseudo-labels and calculate the averaged momentum representations of each cluster to initialize the cluster-level memory bank.
Figure 1.
Illustration of existing PU methods. Such methods utilize clustering algorithms to obtain pseudo-labels and calculate the averaged momentum representations of each cluster to initialize the cluster-level memory bank.
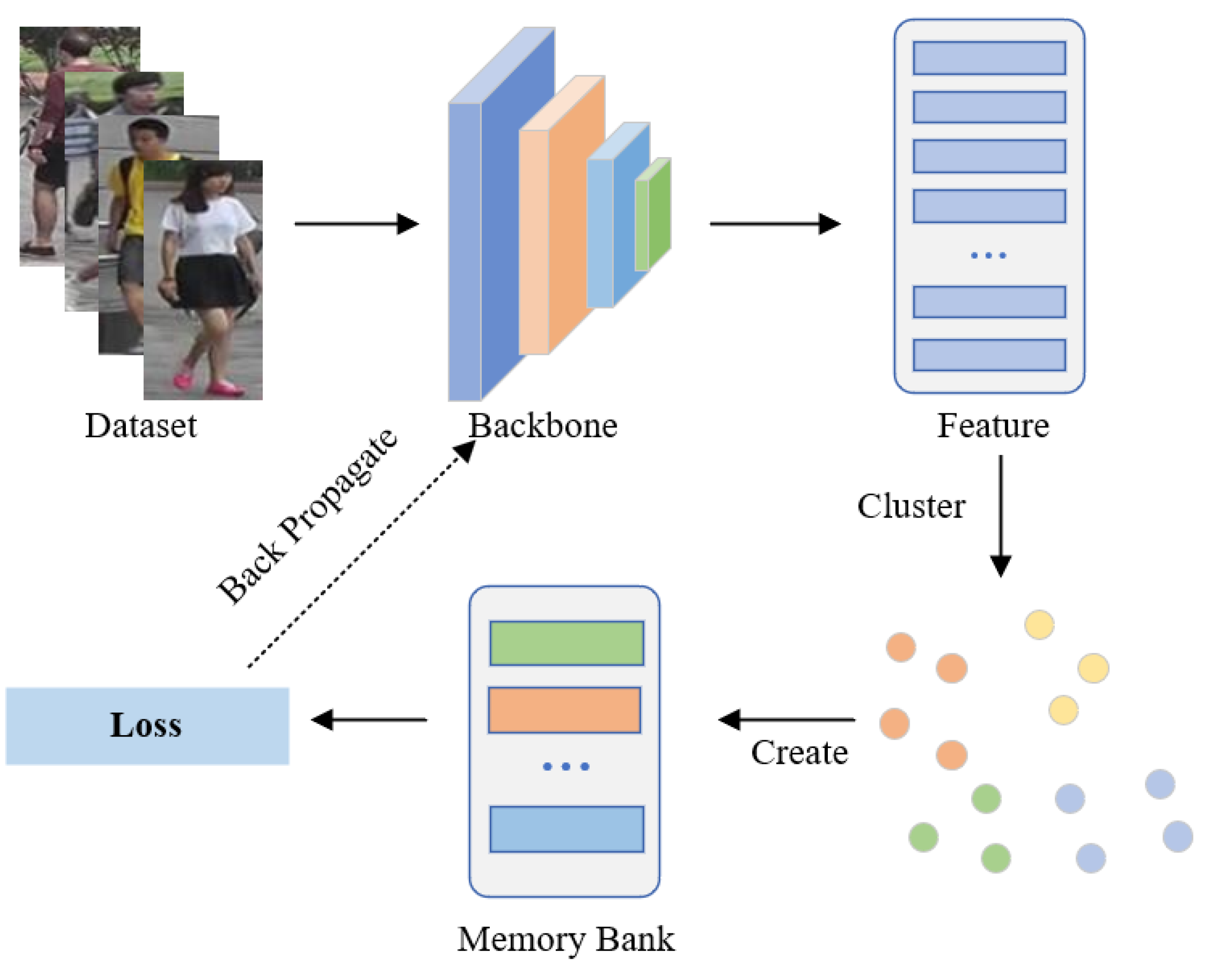
Figure 2.
Illustration of JCL. Our method alternates between the feature extraction stage, clustering stage, and training stage. In the feature extraction stage, we employ ResNet-50 combined with WAM to capture image features from unlabeled datasets. Subsequently, we divide the extracted features into various clusters as pseudo labels and enhance cluster reliability through the clustering optimization module. Finally, a joint contrastive learning method according to cluster-level and instance-level memory banks serves to enhance the feature recognition capability of the model.
Figure 2.
Illustration of JCL. Our method alternates between the feature extraction stage, clustering stage, and training stage. In the feature extraction stage, we employ ResNet-50 combined with WAM to capture image features from unlabeled datasets. Subsequently, we divide the extracted features into various clusters as pseudo labels and enhance cluster reliability through the clustering optimization module. Finally, a joint contrastive learning method according to cluster-level and instance-level memory banks serves to enhance the feature recognition capability of the model.
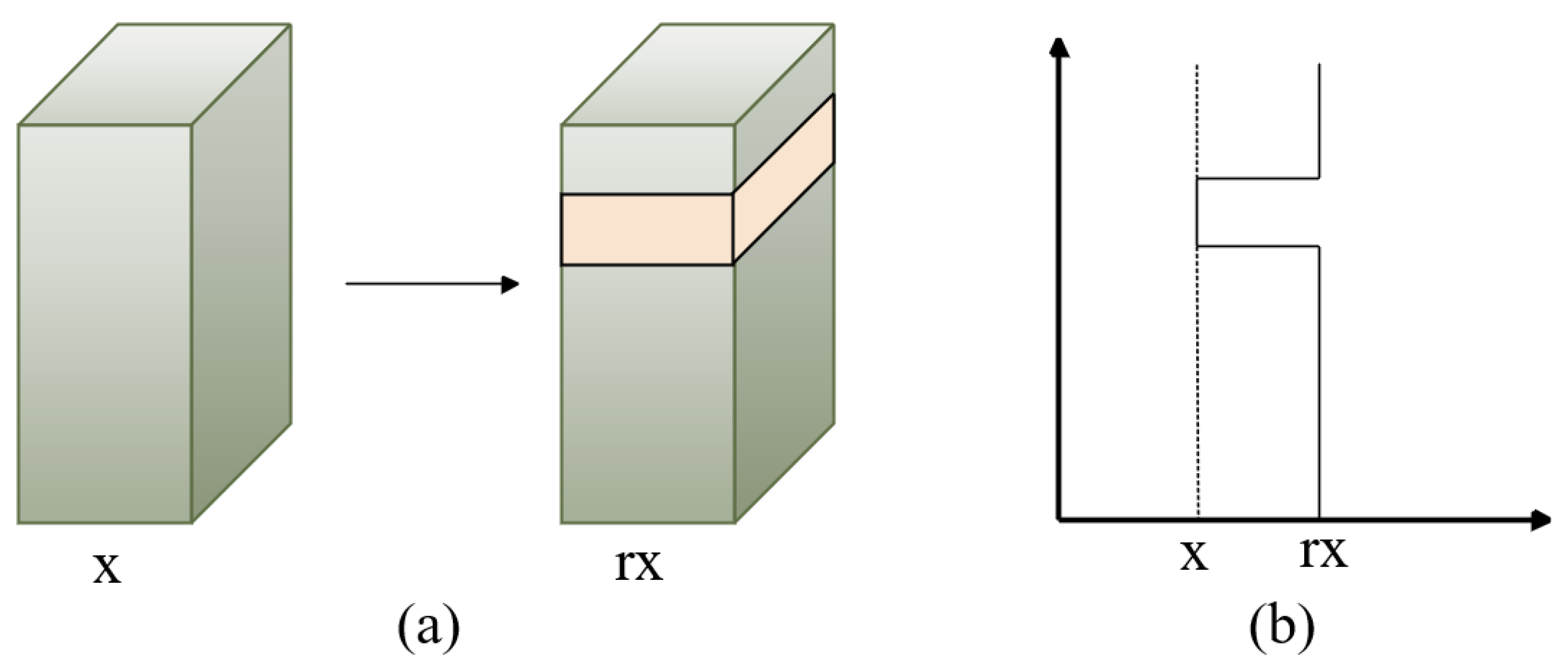
Figure 3.
Overview of the WaveBlock module, where x represents the value of extracting the person-image feature blocks and r is the wave rate. A block is chosen randomly and remains unchanged, while feature values of the remaining blocks are multiplied by r times. (a) represents the selected feature block, while (b) describes the way in which the feature values are changed.
Figure 3.
Overview of the WaveBlock module, where x represents the value of extracting the person-image feature blocks and r is the wave rate. A block is chosen randomly and remains unchanged, while feature values of the remaining blocks are multiplied by r times. (a) represents the selected feature block, while (b) describes the way in which the feature values are changed.
Figure 4.
Visual representation of the feature space (a) prior to and (b) subsequent to the cluster optimization module. Distinct shapes indicate various cameras, while varying colors represent belonging to different clusters. Black means outlier instances.
Figure 4.
Visual representation of the feature space (a) prior to and (b) subsequent to the cluster optimization module. Distinct shapes indicate various cameras, while varying colors represent belonging to different clusters. Black means outlier instances.
Figure 5.
Visual representation of feature space for ILL. Each point represents the features of the image, and different colors are used to represent various identities, where q is a query instance. The ILL we formulated effectively improves the similarity between the query instance and positive sample by minimizing the distance between them while pushing away negative samples.
Figure 5.
Visual representation of feature space for ILL. Each point represents the features of the image, and different colors are used to represent various identities, where q is a query instance. The ILL we formulated effectively improves the similarity between the query instance and positive sample by minimizing the distance between them while pushing away negative samples.
Figure 6.
The examples are sourced from the Xiongan New Area dataset, which includes 19 land cover types, and among them, agricultural and forestry vegetation are the main research objects.
Figure 6.
The examples are sourced from the Xiongan New Area dataset, which includes 19 land cover types, and among them, agricultural and forestry vegetation are the main research objects.
Figure 7.
Comparing the top-5 ranking lists between baseline and our method on Market-1501. Images with green borders indicate correct matches, while those with red borders signify incorrect matches.
Figure 7.
Comparing the top-5 ranking lists between baseline and our method on Market-1501. Images with green borders indicate correct matches, while those with red borders signify incorrect matches.
Figure 8.
Ablation study with different settings of (a) batch size and (b) hyperparameter on Market-1501. The batch size refers to the amount of data selected by the model for processing during the training process, while the hyperparameter is used to control the impact of the loss function.
Figure 8.
Ablation study with different settings of (a) batch size and (b) hyperparameter on Market-1501. The batch size refers to the amount of data selected by the model for processing during the training process, while the hyperparameter is used to control the impact of the loss function.
Figure 9.
Example images in the Market-1501 and PRAI-1581 datasets. Compared to the Market-1501 dataset, the PRAI-1581 dataset contains rich scale diversity, including low resolution, partial occlusion, different perspectives, person posture, and UAVs flying at different altitudes.
Figure 9.
Example images in the Market-1501 and PRAI-1581 datasets. Compared to the Market-1501 dataset, the PRAI-1581 dataset contains rich scale diversity, including low resolution, partial occlusion, different perspectives, person posture, and UAVs flying at different altitudes.
Figure 10.
Comparing the top-5 ranking lists between baseline and our method on PRAI-1581. Images with green borders indicate correct matches, while those with red borders signify incorrect matches.
Figure 10.
Comparing the top-5 ranking lists between baseline and our method on PRAI-1581. Images with green borders indicate correct matches, while those with red borders signify incorrect matches.
Figure 11.
Grad-CAM visualization of feature maps extracted by our model in the Xiongan New Area dataset. The red box represents the original image, and the green box represents the heatmap.
Figure 11.
Grad-CAM visualization of feature maps extracted by our model in the Xiongan New Area dataset. The red box represents the original image, and the green box represents the heatmap.
Figure 12.
Our model obtains the top-3 ranking lists for Xiongan New Area dataset. Images with green borders indicate correct matching, while images with red borders indicate incorrect matching.
Figure 12.
Our model obtains the top-3 ranking lists for Xiongan New Area dataset. Images with green borders indicate correct matching, while images with red borders indicate incorrect matching.
Table 1.
Number of object samples in the Xiongan New Area dataset.
Table 1.
Number of object samples in the Xiongan New Area dataset.
|
Category
|
Sample Size
|
Category
|
Sample Size
|
|---|
|
Rice
|
26,138
|
Peach
|
67,210
|
|
Rice stubble
|
187,425
|
Vegetable field
|
29,763
|
|
Water
|
124,862
|
Corn
|
85,547
|
|
Grass
|
91,518
|
Poplar
|
68,885
|
|
Willow
|
197,218
|
Pear
|
986,139
|
|
Elm
|
19,663
|
Soybean
|
7456
|
|
Acer palmatum
|
296,538
|
Lotus leaf
|
27,178
|
|
White wax
|
276,755
|
Robinia
|
6506
|
|
Locust
|
44,232
|
Residential
|
26,140
|
|
Sophora japonica
|
372,708
| | |
Table 2.
Comparison with the state-of-the-art unsupervised Re-ID methods on Market-1501 and DukeMTMC-reID, employing ResNet-50 as the backbone model. Bold indicates the best performance.
Table 2.
Comparison with the state-of-the-art unsupervised Re-ID methods on Market-1501 and DukeMTMC-reID, employing ResNet-50 as the backbone model. Bold indicates the best performance.
| Method | Market-1501 | DukeMTMC-reID |
|---|
| Rank-1 | Rank-5 | Rank-10 | mAP | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|
| Domain Adaptation Methods |
| MMT [12] | ICLR20 | 87.7 | 94.9 | 96.9 | 71.2 | 78.0 | 88.8 | 92.5 | 65.1 |
| MMCL [11] | CVPR20 | 84.4 | 92.8 | 95.0 | 60.4 | 72.4 | 82.9 | 85.0 | 51.4 |
| JVTC [45] | ECCV20 | 83.8 | 93.0 | 95.2 | 61.1 | 75.0 | 85.1 | 88.2 | 56.2 |
| SpCL [6] | NeurIPS20 | 89.7 | 96.1 | 97.6 | 77.5 | 82.9 | 90.1 | 92.5 | 68.8 |
| JGCL [15] | CVPR21 | 90.5 | 96.2 | 97.1 | 75.4 | 81.9 | 88.9 | 90.6 | 67.6 |
| JNTL [10] | CVPR21 | 90.1 | - | - | 76.5 | 79.5 | - | - | 65.0 |
| MET [14] | TIFS22 | 92.7 | 97.5 | 98.6 | 82.3 | 82.4 | 91.2 | 93.7 | 69.8 |
| P2LR [13] | AAAI22 | 92.6 | 97.4 | 98.3 | 81.0 | 82.6 | 90.8 | 93.7 | 70.8 |
| RESL [46] | AAAI22 | 93.2 | 96.8 | 98.0 | 83.1 | 83.9 | 91.7 | 93.6 | 72.3 |
| Purely Unsupervised Methods |
| BUC [18] | AAAI19 | 66.2 | 79.6 | 84.5 | 38.3 | 47.4 | 62.6 | 68.4 | 27.5 |
| MMCL [11] | CVPR20 | 80.3 | 89.4 | 92.3 | 45.5 | 65.2 | 75.9 | 80.0 | 40.2 |
| HCT [47] | CVPR20 | 80.0 | 91.6 | 95.2 | 56.4 | 69.6 | 83.4 | 87.4 | 50.7 |
| SpCL [6] | NeurIPS20 | 88.1 | 95.1 | 97.0 | 73.1 | 81.2 | 90.3 | 92.2 | 65.3 |
| RLCC [48] | CVPR21 | 90.8 | 96.3 | 97.5 | 77.7 | 83.2 | 89.2 | 91.6 | 69.2 |
| CCL [17] | CVPR21 | 92.3 | 96.7 | 97.9 | 82.1 | 84.9 | 91.9 | 93.9 | 72.6 |
| CAP [8] | AAAI21 | 91.4 | 96.0 | 97.7 | 79.2 | 81.1 | 89.3 | 91.8 | 67.3 |
| SECRET [49] | AAAI22 | 93.1 | - | - | 82.9 | 82.0 | - | - | 69.2 |
| HCL [19] | ACPR22 | 92.1 | - | - | 79.6 | 82.5 | - | - | 67.5 |
| GATE [50] | ICME22 | 91.5 | 96.7 | 97.9 | 78.8 | 81.1 | 89.2 | 90.1 | 68.4 |
| CACL [31] | TIP22 | 92.7 | 97.4 | 98.5 | 80.9 | 82.6 | 91.2 | 93.8 | 69.6 |
| O2CAP [9] | TIP22 | 92.5 | 96.9 | 98.0 | 82.7 | 83.9 | 91.3 | 93.4 | 71.2 |
| STS [51] | TIP22 | 93.0 | 97.5 | - | 82.4 | 84.9 | 92.3 | - | 72.2 |
| RPE [52] | TMM23 | 92.6 | 97.1 | 97.9 | 82.4 | 77.8 | 89.3 | 91.7 | 71.5 |
| LESL [53] | TIFS23 | 92.9 | 97.1 | 97.8 | 83.4 | 83.9 | 91.0 | 93.0 | 72.7 |
| JCL | This paper | 93.3 | 97.6 | 98.6 | 83.7 | 85.0 | 92.0 | 93.9 | 73.3 |
Table 3.
Ablation studies on different modules. ILL denotes instance-level contrastive loss; CLL denotes cluster-level contrastive loss; JCL denotes joint contrastive loss; WAM denotes the WaveBlock attention module; COM denotes the cluster optimization module. Bold indicates the best performance.
Table 3.
Ablation studies on different modules. ILL denotes instance-level contrastive loss; CLL denotes cluster-level contrastive loss; JCL denotes joint contrastive loss; WAM denotes the WaveBlock attention module; COM denotes the cluster optimization module. Bold indicates the best performance.
| Variant | Market-1501 | DukeMTMC-ReID |
|---|
| Rank-1 | Rank-5 | Rank-10 | mAP | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|
| (a) Baseline | 88.1 | 95.1 | 97.0 | 73.1 | 81.2 | 90.3 | 92.2 | 65.3 |
|
(b) Baseline + ILL
|
90.7
|
96.2
|
97.2
|
79.7
|
83.7
|
91.3
|
93.1
|
71.2
|
|
(c) Baseline + CLL
|
92.3
|
96.7
|
97.9
|
82.2
|
84.2
|
91.5
|
93.7
|
72.2
|
|
(d) Baseline + JCL
|
92.8
|
97.4
|
98.4
|
82.9
|
84.6
|
91.6
|
93.7
|
72.7
|
| (e) Baseline + JCL + WAM | 93.1 | 97.6 | 98.4 | 83.2 | 84.7 | 92.0 | 93.7 | 72.9 |
| (f) Baseline + JCL + WAM + COM | 93.3 | 97.6 | 98.6 | 83.7 | 85.0 | 92.0 | 93.9 | 73.3 |
Table 4.
The quantity of pseudo-labels produced at under various clustering thresholds on Market-1501, where the number of pseudo labels represents the number of clusters after clustering.
Table 4.
The quantity of pseudo-labels produced at under various clustering thresholds on Market-1501, where the number of pseudo labels represents the number of clusters after clustering.
| Threshold | 0.4 | 0.45 | 0.5 | 0.55 | 0.6 |
| Number | 708 | 664 | 633 | 590 | 559 |
Table 5.
The influence of various clustering thresholds on Market-1501. Showing the values of rank-r and map (%). The best results are in bold.
Table 5.
The influence of various clustering thresholds on Market-1501. Showing the values of rank-r and map (%). The best results are in bold.
| Threshold | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|
| 0.4 | 92.2 | 97.1 | 98.0 | 82.2 |
| 0.45 | 92.8 | 97.3 | 98.2 | 82.6 |
| 0.5 | 92.9 | 97.6 | 98.4 | 83.2 |
| 0.55 | 93.3 | 97.6 | 98.6 | 83.7 |
| 0.6 | 93.2 | 97.6 | 98.5 | 83.4 |
Table 6.
The influence of various clustering thresholds on DukeMTMC-reID. Showing the values of rank-r and map (%). The best results are in bold.
Table 6.
The influence of various clustering thresholds on DukeMTMC-reID. Showing the values of rank-r and map (%). The best results are in bold.
| Threshold | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|
| 0.4 | 78.8 | 88.0 | 90.4 | 65.5 |
| 0.45 | 82.8 | 90.8 | 93.0 | 69.7 |
| 0.5 | 83.6 | 91.9 | 94.0 | 71.6 |
| 0.55 | 84.6 | 92.0 | 94.3 | 72.3 |
| 0.6 | 85.0 | 92.0 | 93.9 | 73.3 |
Table 7.
The impact of different tricks on our proposed method JCL on two real-world person Re-ID datasets. ’IBN’ indicates the use of IBN-ResNet50. ‘GeM’ indicates the generalized mean pooling layer. The best results are in bold.
Table 7.
The impact of different tricks on our proposed method JCL on two real-world person Re-ID datasets. ’IBN’ indicates the use of IBN-ResNet50. ‘GeM’ indicates the generalized mean pooling layer. The best results are in bold.
| Method | Market-1501 |
|---|
| Rank-1 | Rank-5 | Rank-10 | mAP |
|---|
| ResNet-50 | 93.3 | 97.6 | 98.6 | 83.7 |
| GeM | 94.3 | 97.8 | 98.7 | 85.7 |
| GEM + IBN | 94.7 | 97.8 | 98.7 | 87.4 |
| Method | DukeMTMC-reID |
| Rank-1 | Rank-5 | Rank-10 | mAP |
| ResNet-50 | 85.0 | 92.0 | 93.9 | 73.3 |
| GeM | 86.0 | 93.0 | 94.7 | 75.7 |
| GEM + IBN | 86.5 | 92.6 | 94.5 | 75.9 |
Table 8.
Comparison with the Re-ID methods on PRAI-1581. ID denotes identification loss, TL denotes triplet loss, SP denotes subspace pooling. Bold indicates the best performance.
Table 8.
Comparison with the Re-ID methods on PRAI-1581. ID denotes identification loss, TL denotes triplet loss, SP denotes subspace pooling. Bold indicates the best performance.
| Method | PRAI-1581 |
|---|
| Rank-1 | mAP |
|---|
| ID | 42.6 | 31.4 |
| TL | 47.4 | 36.4 |
| TL + SP [23] | 49.7 | 39.5 |
| OSNET [54] | 54.4 | 42.1 |
| Ours | 55.4 | 43.5 |
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}