
Learning SAR-Optical Cross Modal Features for Land Cover Classification


Abstract
1. Introduction
2. Overview
2.1. Image-Level Fusion
2.2. Feature-Level Fusion
3. Experimental Setup
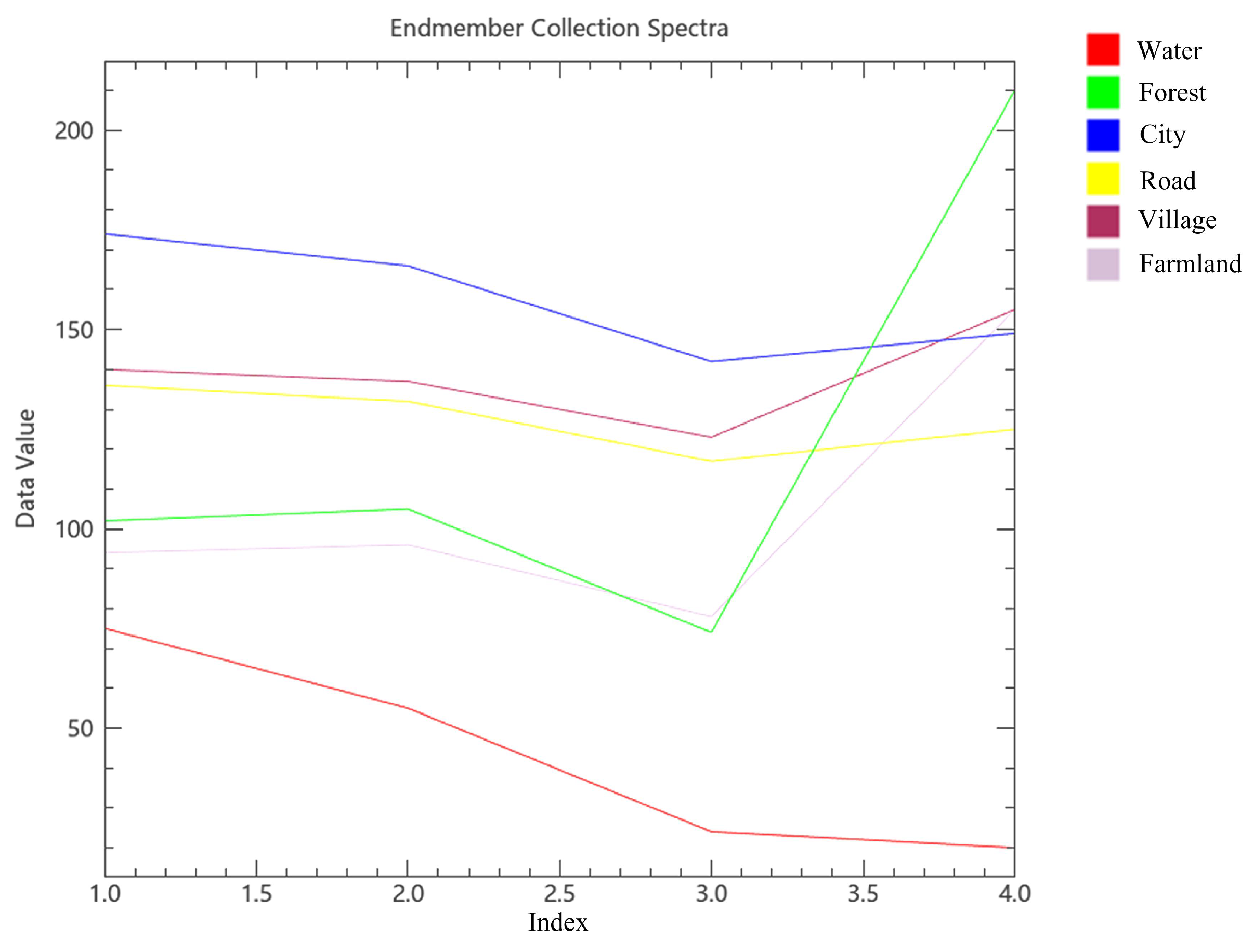
3.1. Datasets
3.2. Implementation Details
3.3. Experiment and Discussion
4. Conclusions and Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xia, J.; Yokoya, N.; Baier, G. DML: Differ-Modality Learning for Building Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Peng, B.; Zhang, W.; Hu, Y.; Chu, Q.; Li, Q. LRFFNet: Large Receptive Field Feature Fusion Network for Semantic Segmentation of SAR Images in Building Areas. Remote Sens. 2022, 14, 6291. [Google Scholar] [CrossRef]
- Wu, W.; Guo, S.; Shao, Z.; Li, D. CroFuseNet: A Semantic Segmentation Network for Urban Impervious Surface Extraction Based on Cross Fusion of Optical and SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 2573–2588. [Google Scholar] [CrossRef]
- Kang, W.; Xiang, Y.; Wang, F.; You, H. CFNet: A Cross Fusion Network for Joint Land Cover Classification Using Optical and SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1562–1574. [Google Scholar] [CrossRef]
- Xu, H.; He, M.; Rao, Z.; Li, W. Him-Net: A New Neural Network Approach for SAR and Optical Image Template Matching1. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 3827–3831. [Google Scholar] [CrossRef]
- Kulkarni, S.; Rege, P.P. Pixel level fusion techniques for SAR and optical images: A review. Inf. Fusion 2020, 59, 13–29. [Google Scholar] [CrossRef]
- Zhu, B.; Zhou, L.; Pu, S.; Fan, J.; Ye, Y. Advances and Challenges in Multimodal Remote Sensing Image Registration. IEEE J. Miniaturization Air Space Syst. 2023, 4, 165–174. [Google Scholar] [CrossRef]
- Gao, C.; Li, W. Multi-Scale PIIFD for Registration of Multi-Source Remote Sensing Images. J. Beijing Inst. Technol. 2021, 30, 113–124. [Google Scholar]
- Ye, Y.; Zhu, B.; Tang, T.; Yang, C.; Xu, Q.; Zhang, G. A Robust Multimodal Remote Sensing Image Registration Method and System Using Steerable Filters with First- and Second-order Gradients. arXiv 2022, arXiv:2202.13347. [Google Scholar] [CrossRef]
- Shakya, A.; Biswas, M.; Pal, M. Fusion and Classification of SAR and Optical Data Using Multi-Image Color Components with Differential Gradients. Remote Sens. 2023, 15, 274. [Google Scholar] [CrossRef]
- Lewis, J.J.; O’Callaghan, R.J.; Nikolov, S.G.; Bull, D.R.; Canagarajah, N. Pixel- and region-based image fusion with complex wavelets. Inf. Fusion 2007, 8, 119–130. [Google Scholar] [CrossRef]
- Gaetano, R.; Cozzolino, D.; D’Amiano, L.; Verdoliva, L.; Poggi, G. Fusion of sar-optical data for land cover monitoring. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 5470–5473. [Google Scholar] [CrossRef]
- Zhang, R.; Tang, X.; You, S.; Duan, K.; Xiang, H.; Luo, H. A Novel Feature-Level Fusion Framework Using Optical and SAR Remote Sensing Images for Land Use/Land Cover (LULC) Classification in Cloudy Mountainous Area. Appl. Sci. 2020, 10, 2928. [Google Scholar] [CrossRef]
- Zhang, H.; Lin, H.; Li, Y. Impacts of Feature Normalization on Optical and SAR Data Fusion for Land Use/Land Cover Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1061–1065. [Google Scholar] [CrossRef]
- Maggiolo, L.; Solarna, D.; Moser, G.; Serpico, S.B. Optical-SAR Decision Fusion with Markov Random Fields for High-Resolution Large-Scale Land Cover Mapping. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 5508–5511. [Google Scholar] [CrossRef]
- Li, X.; Lei, L.; Sun, Y.; Li, M.; Kuang, G. Multimodal Bilinear Fusion Network With Second-Order Attention-Based Channel Selection for Land Cover Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1011–1026. [Google Scholar] [CrossRef]
- Zhang, D.; Gade, M.; Zhang, J. SOF-UNet: SAR and Optical Fusion Unet for Land Cover Classification. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 907–910. [Google Scholar] [CrossRef]
- Li, X.; Lei, L.; Sun, Y.; Li, M.; Kuang, G. Collaborative Attention-Based Heterogeneous Gated Fusion Network for Land Cover Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 3829–3845. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, Y.; Zhang, Y.; Zhong, L.; Wang, J.; Chen, J. DKDFN: Domain Knowledge-Guided deep collaborative fusion network for multimodal unitemporal remote sensing land cover classification. ISPRS J. Photogramm. Remote Sens. 2022, 186, 170–189. [Google Scholar] [CrossRef]
- Lin Sen, Z.Y. Reiview on key technologies of target exploration in underwater optical images. Laster Optoelectron. Prog. 2020, 57, 060002. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, H.; Sun, H.; Ying, W. Multireceiver SAS Imagery Based on Monostatic Conversion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10835–10853. [Google Scholar] [CrossRef]
- Yang, P. An imaging algorithm for high-resolution imaging sonar system. Multimed. Tools Appl. 2023. [Google Scholar] [CrossRef]
- Luo, D.; Li, L.; Mu, F.; Gao, L. Fusion of high spatial resolution optical and polarimetric SAR images for urban land cover classification. In Proceedings of the 2014 Third International Workshop on Earth Observation and Remote Sensing Applications (EORSA), Changsha, China, 1–14 June 2014; pp. 362–365. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. arXiv 2018, arXiv:1807.10165. [Google Scholar]
- Quan, Y.; Yu, A.; Cao, X.; Qiu, C.; Zhang, X.; Liu, B.; He, P. Building Extraction From Remote Sensing Images With DoG as Prior Constraint. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 6559–6570. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Makar, R.; Shahin, S.; El-Nazer, M.; Wheida, A. Development of a PCA-based land use/land cover classification utilizing Sentinel-2 time series. Middle East J. Agric. Res. 2022, 11, 630–637. [Google Scholar]
- Hazirbas, C.; Ma, L.; Domokos, C.; Cremers, D. FuseNet: Incorporating Depth into Semantic Segmentation via Fusion-Based CNN Architecture. In Computer Vision—ACCV 2016: 13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016, Revised Selected Papers, Part I 13; Lai, S.H., Lepetit, V., Nishino, K., Sato, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 213–228. [Google Scholar]
- Yao, J.; Cao, X.; Hong, D.; Wu, X.; Meng, D.; Chanussot, J.; Xu, Z. Semi-Active Convolutional Neural Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5537915. [Google Scholar] [CrossRef]
- Dong, W.; Zhang, T.; Qu, J.; Xiao, S.; Zhang, T.; Li, Y. Multibranch Feature Fusion Network With Self- and Cross-Guided Attention for Hyperspectral and LiDAR Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5530612. [Google Scholar] [CrossRef]
- Quan, D.; Wei, H.; Wang, S.; Gu, Y.; Hou, B.; Jiao, L. A Novel Coarse-to-Fine Deep Learning Registration Framework for Multimodal Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5108316. [Google Scholar] [CrossRef]
- Müller, R.; Kornblith, S.; Hinton, G.E. When Does Label Smoothing Help? arXiv 2019, arXiv:1906.02629. [Google Scholar]
- Li, X.; Zhang, G.; Cui, H.; Hou, S.; Wang, S.; Li, X.; Chen, Y.; Li, Z.; Zhang, L. MCANet: A joint semantic segmentation framework of optical and SAR images for land use classification. Int. J. Appl. Earth Obs. Geoinf. 2022, 106, 102638. [Google Scholar] [CrossRef]
- Ren, B.; Ma, S.; Hou, B.; Hong, D.; Chanussot, J.; Wang, J.; Jiao, L. A dual-stream high resolution network: Deep fusion of GF-2 and GF-3 data for land cover classification. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102896. [Google Scholar] [CrossRef]
- Sun, Y.; Zhao, Y.; Wang, Z.; Fan, Y. SOLC. 2022. Available online: https://github.com/yisun98/SOLC (accessed on 22 January 2020).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Method | mIoU% | mPA% | Accuracy% |
|---|---|---|---|---|
| WHU-OPT-SAR | Deeplab-v3-O+S [38] | 39.97 | 49.95 | 76.68 |
| SOLC-O+S [38] | 42.80 | 53.21 | 79.11 | |
| U-Net-O [24] | 50.43 | 61.43 | 80.37 | |
| U-Net+Ours | 52.87 | 63.22 | 80.88 | |
| E-UF-O [26] | 51.55 | 65.05 | 80.87 | |
| E-UF+Ours | 53.37 | 64.98 | 81.16 |
| Datasets | Area | Method | mIoU% | mPA% | Accuracy% |
|---|---|---|---|---|---|
| DDHRNet | Korea | Deeplab-v3-O+S [38] | 68.75 | 79.13 | 86.23 |
| SOLC-O+S [38] | 74.38 | 83.05 | 89.31 | ||
| U-Net-O [24] | 83.30 | 90.02 | 93.68 | ||
| U-Net+Ours | 87.04 | 92.05 | 95.35 | ||
| E-UF-O [26] | 89.83 | 93.95 | 96.52 | ||
| E-UF+Ours | 91.42 | 94.91 | 97.07 | ||
| Shandong | SOLC-O+S [38] | 72.88 | 78.33 | 92.73 | |
| Deeplab-v3-O+S [38] | 75.46 | 83.47 | 90.37 | ||
| U-Net-O [24] | 79.38 | 86.90 | 91.20 | ||
| U-Net+Ours | 83.26 | 89.63 | 92.79 | ||
| E-UF-O [26] | 85.62 | 91.15 | 94.23 | ||
| E-UF+Ours | 86.52 | 91.86 | 94.63 | ||
| Xi’an | SOLC-O+SAR [38] | 67.65 | 73.82 | 90.87 | |
| Deeplab-v3-O+S [38] | 69.50 | 76.02 | 91.91 | ||
| U-Net-O [24] | 78.42 | 83.40 | 95.26 | ||
| U-Net+Ours | 78.99 | 83.66 | 95.50 | ||
| E-UF-O+S [26] | 82.18 | 86.60 | 96.28 | ||
| E-UF+Ours | 83.09 | 87.45 | 96.49 |
| Method | bg | Farmland | City | Village | Water | Forest | Road | Others |
|---|---|---|---|---|---|---|---|---|
| Deeplab-v3-O+S | 10.84 | 62.31 | 52.75 | 38.09 | 58.65 | 75.14 | 11.12 | 10.84 |
| SOLC-O+S | 0.39 | 65.95 | 56.48 | 47.20 | 61.97 | 76.93 | 25.73 | 7.75 |
| U-Net-O | 38.64 | 67.70 | 54.96 | 47.31 | 64.80 | 77.53 | 33.56 | 18.93 |
| U-Net+Ours | 56.42 | 68.52 | 56.04 | 47.68 | 65.32 | 77.95 | 33.67 | 17.34 |
| E-UF-O | 40.35 | 68.88 | 54.12 | 47.76 | 64.83 | 78.20 | 37.35 | 20.88 |
| E-UF+Ours | 48.73 | 68.90 | 55.15 | 48.67 | 66.62 | 77.73 | 38.68 | 22.44 |
| Area | Method | Building | Road | Farmland | Water | Greenery | Others |
|---|---|---|---|---|---|---|---|
| Korea | Deeplab-v3-O+S | 79.61 | 63.03 | 66.83 | 85.51 | 80.70 | 36.83 |
| SOLC-O+S | 85.35 | 54.32 | 82.19 | 97.51 | 77.24 | 49.67 | |
| U-Net-O | 91.61 | 72.83 | 89.17 | 98.34 | 87.18 | 60.69 | |
| U-Net+Ours | 94.04 | 79.50 | 91.81 | 98.42 | 90.86 | 67.61 | |
| E-UF-O | 95.73 | 84.85 | 94.30 | 98.91 | 92.96 | 72.20 | |
| E-UF+Ours | 96.30 | 87.51 | 95.12 | 99.10 | 93.73 | 76.78 | |
| Shandong | SOLC-O+S | 89.92 | 70.73 | 91.74 | 82.96 | 95.95 | 6.00 |
| Deeplab-v3-O+S | 87.13 | 49.41 | 84.27 | 96.38 | 82.51 | 53.05 | |
| U-Net-O | 84.35 | 74.84 | 78.02 | 90.67 | 88.80 | 59.62 | |
| U-Net+Ours | 87.07 | 81.04 | 82.14 | 90.62 | 90.60 | 68.10 | |
| E-UF-O | 90.41 | 83.15 | 85.73 | 93.56 | 90.45 | 70.44 | |
| E-UF+Ours | 91.52 | 84.08 | 86.13 | 93.72 | 92.07 | 71.58 | |
| Xi’an | SOLC-O+S | 86.67 | 57.49 | 90.33 | 81.13 | 91.98 | 0.12 |
| Deeplab-v3-O+S | 88.97 | 60.36 | 91.45 | 82.83 | 93.31 | 0.10 | |
| U-Net-O | 93.45 | 81.37 | 96.09 | 90.01 | 96.19 | 13.39 | |
| U-Net+Ours | 93.38 | 81.58 | 96.13 | 90.64 | 96.29 | 15.91 | |
| E-UF-O | 94.31 | 84.84 | 96.83 | 91.73 | 95.96 | 29.41 | |
| E-UF+Ours | 94.56 | 85.30 | 97.16 | 92.00 | 97.05 | 32.48 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Quan, Y.; Zhang, R.; Li, J.; Ji, S.; Guo, H.; Yu, A. Learning SAR-Optical Cross Modal Features for Land Cover Classification. Remote Sens. 2024, 16, 431. https://doi.org/10.3390/rs16020431
Quan Y, Zhang R, Li J, Ji S, Guo H, Yu A. Learning SAR-Optical Cross Modal Features for Land Cover Classification. Remote Sensing. 2024; 16(2):431. https://doi.org/10.3390/rs16020431
Chicago/Turabian StyleQuan, Yujun, Rongrong Zhang, Jian Li, Song Ji, Hengliang Guo, and Anzhu Yu. 2024. "Learning SAR-Optical Cross Modal Features for Land Cover Classification" Remote Sensing 16, no. 2: 431. https://doi.org/10.3390/rs16020431
APA StyleQuan, Y., Zhang, R., Li, J., Ji, S., Guo, H., & Yu, A. (2024). Learning SAR-Optical Cross Modal Features for Land Cover Classification. Remote Sensing, 16(2), 431. https://doi.org/10.3390/rs16020431