
A Patch-Level Region-Aware Module with a Multi-Label Framework for Remote Sensing Image Captioning

 , , , , and
, , , , and
Abstract
1. Introduction
1.1. Challenges in RSIC Tasks
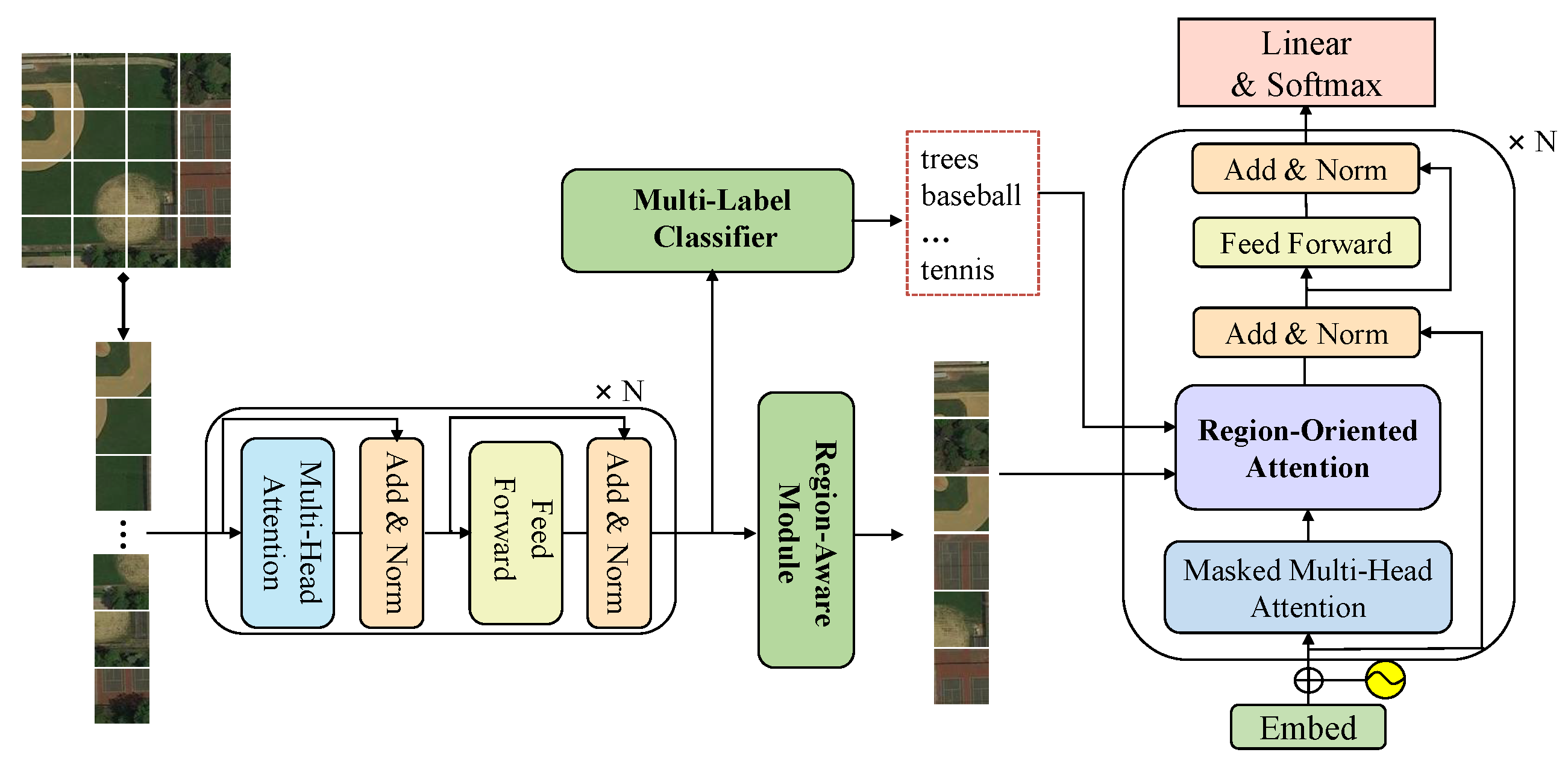
1.2. Possible Solution Based on a Full Transformer
1.3. Novel Contributions
- We propose a novel patch-level region-aware module with a multi-label framework for RSIC by unifying both the detected object’s class and patch-level salient features. Furthermore, the expanded Transformer-based decoder with a region-oriented attention block enhances the cross-modal association learning and affords supplementary hints for query-to-key correlation.
- To extract visual features for multi-scale RSIs, RSI patches are encoded by a Transformer-based encoder for patch-level features and class tokens. Meanwhile, a patch-level region-aware module is designed to seek the core object features guided by the relationships between patch-level features and class tokens, which decides to replace the image’s global or redundant representation.
- Rejecting pre-trained algorithm migration for multi-label classification, we directly apply a multi-label classifier on the class token features from the Transformer-based encoder. It can alleviate the negative effects of the potentially noisy labels during the whole model training phase compared with pre-trained algorithms.
- The integration of regional features and semantic features into a novel region-oriented attention block aims to capture more cross-modal interactional information, which is crucial for accurately characterizing the complex content of RSIs and thus for achieving accurate sentence predictions.
2. Related Work
2.1. LSTM-Based RSIC Methods
2.2. Transformer-Based RSIC Methods
3. Proposed Method
3.1. Pure Transformer Framework
3.2. Patch-Level Region-Aware Extractor
3.3. Co-Training Multi-Label Classifier
3.4. Region-Oriented Attention
4. Experiments
4.1. Datasets
4.2. Model Implementations
4.3. Evaluation Metrics
4.4. Evaluation Results and Analysis
- (1)
- Quantitative Comparison
- (2)
- Qualitative Comparison
4.5. Ablation Experiments
- (1)
- Quantitative Comparison
- (2)
- Qualitative Comparison
4.6. Parameter Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| RSIC | Remote sensing image captioning. |
| CNN | Convolutional neural networks. |
| LSTM | Long short-term memory. |
| VGG | Visual geometry group. |
| ResNet | Residual network. |
| LAM | Label attention mechanism. |
| BLEU | Biingual evaluation understudy. |
| ROUGE-L | Recall-oriented understudy for gisting evaluation—Longest. |
| METEOR | Metric for Evaluation of translation with explicit ordering. |
| CIDEr | Consensus-based image description evaluation. |
| GLCM | Global–local captioning model. |
| VRTMM | Variational autoencoder and reinforcement learning |
| based two-stage multitask learning model. | |
| MGT | Mask-guided Transformer. |
| MHA | Multi-head attention. |
| FFN | Feed-forward network. |
| I | The input remote sensing image. |
| The visual features from Vit encoder. | |
| S | The similarity of queries and keys . |
| The similarity score in . | |
| The similarity score of in . | |
| The averaged similarity scores of for all heads. | |
| The salient regional map. | |
| The label probability distribution over ground-truth labels. | |
| The attended features from label mlti-head attention. | |
| The attended features from region mlti-head attention. | |
| The fused cross-modal features. | |
| The resultant vectors from . | |
| The probability of generating specific word. | |
| T | The max length in ground-truth sentence. |
| The generated word at t time. |
References
- Farooq, A.; Jia, X.; Hu, J.; Zhou, J. Transferable Convolutional Neural Network for Weed Mapping with Multisensor Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Li, X.; An, J.; Gao, L.; Hou, B.; Li, C. Natural language description of remote sensing images based on deep learning. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 4798–4801. [Google Scholar]
- Lu, X.; Wang, B.; Zheng, X.; Li, X. Exploring models and data for remote sensing image caption generation. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2183–2195. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, X.; Tang, X.; Zhou, H.; Li, C. Description generation for remote sensing images using attribute attention mechanism. Remote Sens. 2019, 11, 612. [Google Scholar] [CrossRef]
- Li, Y.; Fang, S.; Jiao, L.; Liu, R.; Shang, R. A multi-level attention model for remote sensing image captions. Remote Sens. 2020, 12, 939. [Google Scholar] [CrossRef]
- Wang, Q.; Gao, J.; Li, X. Weakly supervised adversarial domain adaptation for semantic segmentation in urban scenes. IEEE Trans. Image Process. 2019, 28, 4376–4386. [Google Scholar] [CrossRef]
- Chen, W.; Ouyang, S.; Tong, W.; Li, X.; Zheng, X.; Wang, L. GCSANet: A global context spatial attention deep learning network for remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1150–1162. [Google Scholar] [CrossRef]
- Wang, W.; Chen, Y.; Ghamisi, P. Transferring CNN With Adaptive Learning for Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin transformer embedding UNet for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Wang, H.; Tao, C.; Qi, J.; Xiao, R.; Li, H. Avoiding Negative Transfer for Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Zhang, X.; Jiao, L.; Liu, F.; Bo, L.; Gong, M. Spectral Clustering Ensemble Applied to SAR Image Segmentation. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2126–2136. [Google Scholar] [CrossRef]
- Ma, W.; Li, N.; Zhu, H.; Jiao, L.; Tang, X.; Guo, Y.; Hou, B. Feature split-merge-enhancement network for remote sensing object detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Zhou, X.; Shen, K.; Weng, L.; Cong, R.; Zheng, B.; Zhang, J.; Yan, C. Edge-guided recurrent positioning network for salient object detection in optical remote sensing images. IEEE Trans. Cybern. 2022, 53, 539–552. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Wang, L.; Cheng, S.; Li, Y. SwinSUNet: Pure transformer network for remote sensing image change detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Lv, Z.; Wang, F.; Cui, G.; Benediktsson, J.A.; Lei, T.; Sun, W. Spatial–spectral attention network guided with change magnitude image for land cover change detection using remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Shi, Z.; Zou, Z. Can a machine generate humanlike language descriptions for a remote sensing image? IEEE Trans. Geosci. Remote Sens. 2017, 55, 3623–3634. [Google Scholar] [CrossRef]
- Yuan, Z.; Li, X.; Wang, Q. Exploring multi-level attention and semantic relationship for remote sensing image captioning. IEEE Access 2019, 8, 2608–2620. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Shen, X.; Liu, B.; Zhou, Y.; Zhao, J.; Liu, M. Remote sensing image captioning via Variational Autoencoder and Reinforcement Learning. Knowl.-Based Syst. 2020, 203, 105920. [Google Scholar] [CrossRef]
- Huang, W.; Wang, Q.; Li, X. Denoising-based multiscale feature fusion for remote sensing image captioning. IEEE Geosci. Remote Sens. Lett. 2020, 18, 436–440. [Google Scholar] [CrossRef]
- Ma, X.; Zhao, R.; Shi, Z. Multiscale methods for optical remote-sensing image captioning. IEEE Geosci. Remote Sens. Lett. 2020, 18, 2001–2005. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, X.; Gu, J.; Li, C.; Wang, X.; Tang, X.; Jiao, L. Recurrent attention and semantic gate for remote sensing image captioning. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, W.; Yan, M.; Gao, X.; Fu, K.; Sun, X. Global visual feature and linguistic state guided attention for remote sensing image captioning. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Zhao, R.; Shi, Z.; Zou, Z. High-resolution remote sensing image captioning based on structured attention. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Zhang, Z.; Diao, W.; Zhang, W.; Yan, M.; Gao, X.; Sun, X. LAM: Remote sensing image captioning with label-attention mechanism. Remote Sens. 2019, 11, 2349. [Google Scholar] [CrossRef]
- Wang, S.; Ye, X.; Gu, Y.; Wang, J.; Meng, Y.; Tian, J.; Hou, B.; Jiao, L. Multi-label semantic feature fusion for remote sensing image captioning. ISPRS J. Photogramm. Remote Sens. 2022, 184, 1–18. [Google Scholar] [CrossRef]
- Wang, Q.; Huang, W.; Zhang, X.; Li, X. Word–sentence framework for remote sensing image captioning. IEEE Trans. Geosci. Remote Sens. 2020, 59, 10532–10543. [Google Scholar] [CrossRef]
- Gajbhiye, G.O.; Nandedkar, A.V. Generating the captions for remote sensing images: A spatial-channel attention based memory-guided transformer approach. Eng. Appl. Artif. Intell. 2022, 114, 105076. [Google Scholar] [CrossRef]
- Zia, U.; Riaz, M.M.; Ghafoor, A. Transforming remote sensing images to textual descriptions. Int. J. Appl. Earth Obs. Geoinf. 2022, 108, 102741. [Google Scholar] [CrossRef]
- Ren, Z.; Gou, S.; Guo, Z.; Mao, S.; Li, R. A mask-guided transformer network with topic token for remote sensing image captioning. Remote Sens. 2022, 14, 2939. [Google Scholar] [CrossRef]
- Lu, X.; Wang, B.; Zheng, X. Sound active attention framework for remote sensing image captioning. IEEE Trans. Geosci. Remote Sens. 2019, 58, 1985–2000. [Google Scholar] [CrossRef]
- Zhang, M.; Zheng, H.; Gong, M.; Wu, Y.; Li, H.; Jiang, X. Self-structured pyramid network with parallel spatial-channel attention for change detection in VHR remote sensed imagery. Pattern Recognit. 2023, 138, 109354. [Google Scholar] [CrossRef]
- Yang, Z.; Li, Q.; Yuan, Y.; Wang, Q. HCNet: Hierarchical Feature Aggregation and Cross-Modal Feature Alignment for Remote Sensing Image Captioning. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–11. [Google Scholar] [CrossRef]
- Yang, Q.; Ni, Z.; Ren, P. Meta captioning: A meta learning based remote sensing image captioning framework. ISPRS J. Photogramm. Remote Sens. 2022, 186, 190–200. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Wang, J.; Chen, Z.; Ma, A.; Zhong, Y. Capformer: Pure Transformer for Remote Sensing Image Caption. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 7996–7999. [Google Scholar]
- Wang, Q.; Huang, W.; Zhang, X.; Li, X. GLCM: Global–local captioning model for remote sensing image captioning. IEEE Trans. Cybern. 2022, 53, 6910–6922. [Google Scholar] [CrossRef]
- Du, R.; Cao, W.; Zhang, W.; Zhi, G.; Sun, X.; Li, S.; Li, J. From plane to hierarchy: Deformable transformer for remote sensing image captioning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 7704–7717. [Google Scholar] [CrossRef]
- Zhuang, S.; Wang, P.; Wang, G.; Wang, D.; Chen, J.; Gao, F. Improving remote sensing image captioning by combining grid features and transformer. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Fu, K.; Li, Y.; Zhang, W.; Yu, H.; Sun, X. Boosting memory with a persistent memory mechanism for remote sensing image captioning. Remote Sens. 2020, 12, 1874. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Qu, B.; Li, X.; Tao, D.; Lu, X. Deep semantic understanding of high resolution remote sensing image. In Proceedings of the 2016 International Conference on Computer, Information and Telecommunication Systems (Cits), Kunming, China, 6–8 July 2016; pp. 1–5. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 65–72. [Google Scholar]
- Rouge, L.C. ROUGE: A package for automatic evaluation of summaries. In Proceedings of the Workshop on Text Summarization of ACL, Barcelona, Spain, 25 July 2004. [Google Scholar]
- Anderson, P.; Fernando, B.; Johnson, M.; Gould, S. Spice: Semantic propositional image caption evaluation. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part V 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 382–398. [Google Scholar]
- Vedantam, R.; Zitnick, C.L.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | BLEU1 | BLEU2 | BLEU3 | BLEU4 | METEOR | ROUGE-L | SPICE | CIDEr |
|---|---|---|---|---|---|---|---|---|
| SAT | 0.6707 | 0.5438 | 0.4550 | 0.3870 | 0.3203 | 0.5724 | 0.4539 | 2.4686 |
| FC-ATT | 0.6671 | 0.5511 | 0.4691 | 0.4059 | 0.3225 | 0.5781 | 0.4673 | 2.5763 |
| LAM(SAT) | 0.6753 | 0.5537 | 0.4686 | 0.4026 | 0.3254 | 0.5823 | 0.4636 | 2.5850 |
| Sound-a-a | 0.6196 | 0.4819 | 0.3902 | 0.3195 | 0.2733 | 0.5143 | 0.3598 | 1.6386 |
| GA | 0.6779 | 0.5600 | 0.4781 | 0.4165 | 0.3258 | 0.5929 | - | 2.6012 |
| Struc-ATT | 0.7016 | 0.5614 | 0.4648 | 0.3934 | 0.3291 | 0.5706 | - | 1.7031 |
| VRTMM | 0.7813 | 0.6721 | 0.5645 | 0.5123 | 0.3737 | 0.6713 | - | 2.715 |
| WDT | 0.7240 | 0.5861 | 0.4933 | 0.4250 | 0.3197 | 0.6260 | - | 2.0629 |
| SCAMET | 0.7681 | 0.6309 | 0.5352 | 0.4611 | 0.4572 | 0.6979 | - | 2.4681 |
| CNN-T | 0.7980 | 0.6470 | 0.5690 | 0.4890 | 0.2850 | - | - | 2.4040 |
| GLCM | 0.7767 | 0.6492 | 0.5642 | 0.4937 | 0.3627 | 0.6769 | - | 2.5491 |
| HCNet | 0.7863 | 0.6754 | 0.5863 | 0.5122 | 0.3837 | 0.6877 | - | 2.8916 |
| P-to-H | 0.7581 | 0.6416 | 0.5585 | 0.4923 | 0.3550 | 0.6523 | 0.4579 | 2.5814 |
| MGT | 0.7931 | 0.6874 | 0.5960 | 0.5131 | 0.3878 | 0.6900 | - | 2.9231 |
| Ours | 0.8022 | 0.6924 | 0.6018 | 0.5257 | 0.3815 | 0.6919 | 0.4966 | 2.9471 |
| Methods | BLEU1 | BLEU2 | BLEU3 | BLEU4 | METEOR | ROUGE-L | SPICE | CIDEr |
|---|---|---|---|---|---|---|---|---|
| SAT | 0.7995 | 0.7365 | 0.6792 | 0.6244 | 0.4171 | 0.7441 | 0.4951 | 3.1044 |
| FC-ATT | 0.8102 | 0.7330 | 0.6727 | 0.6188 | 0.4280 | 0.7667 | 0.4867 | 3.3700 |
| LAM(SAT) | 0.8195 | 0.7764 | 0.7485 | 0.7161 | 0.4837 | 0.7908 | 0.5024 | 3.6171 |
| Sound-a-a | 0.7093 | 0.6228 | 0.5393 | 0.4602 | 0.3121 | 0.5974 | 0.3837 | 1.7477 |
| GA | 0.8319 | 0.7657 | 0.7103 | 0.6596 | 0.4436 | 0.7845 | 0.4853 | 3.327 |
| Struc-ATT | 0.8538 | 0.8035 | 0.7572 | 0.7149 | 0.4632 | 0.8141 | - | 3.3489 |
| VRTMM | 0.8394 | 0.7785 | 0.7283 | 0.6828 | 0.4527 | 0.8026 | - | 3.4948 |
| WDT | 0.7931 | 0.7237 | 0.6671 | 0.6202 | 0.4395 | 0.7132 | - | 2.7871 |
| SCAMET | 0.8460 | 0.7772 | 0.7262 | 0.6812 | 0.5257 | 0.8166 | - | 3.3773 |
| CNN-T | 0.8390 | 0.7690 | 0.7150 | 0.6750 | 0.4460 | - | - | 3.2310 |
| GLCM | 0.8182 | 0.7540 | 0.6986 | 0.6468 | 0.4619 | 0.7524 | - | 3.0279 |
| HCNet | 0.7686 | 0.7109 | 0.6573 | 0.6102 | 0.3980 | 0.7172 | - | 2.4714 |
| P-to-H | 0.8230 | 0.7700 | 0.7228 | 0.6792 | 0.4439 | 0.7839 | 0.4852 | 3.4629 |
| MGT | 0.8839 | 0.8359 | 0.7909 | 0.7482 | 0.4872 | 0.8369 | - | 3.6566 |
| Ours | 0.8557 | 0.8013 | 0.7567 | 0.7163 | 0.4754 | 0.8153 | 0.5134 | 3.6965 |
| Methods | BLEU1 | BLEU2 | BLEU3 | BLEU4 | METEOR | ROUGE-L | SPICE | CIDEr |
|---|---|---|---|---|---|---|---|---|
| SAT | 0.7391 | 0.6402 | 0.5623 | 0.5248 | 0.3493 | 0.6721 | 0.3945 | 2.2015 |
| FC-ATT | 0.7383 | 0.6440 | 0.5701 | 0.5085 | 0.3638 | 0.6689 | 0.3951 | 2.2415 |
| LAM(SAT) | 0.7405 | 0.6550 | 0.5904 | 0.5304 | 0.3689 | 0.6814 | 0.4038 | 2.3519 |
| Sound-a-a | 0.7484 | 0.6837 | 0.6310 | 0.5896 | 0.3623 | 0.6579 | 0.3907 | 2.7281 |
| GA | 0.7681 | 0.6846 | 0.6145 | 0.5504 | 0.3866 | 0.7030 | 0.4532 | 2.4522 |
| Struc-ATT | 0.7795 | 0.7019 | 0.6392 | 0.5861 | 0.3954 | 0.7299 | - | 2.3791 |
| VRTMM | 0.7443 | 0.6723 | 0.6172 | 0.5699 | 0.3748 | 0.6698 | - | 2.5285 |
| WDT | 0.7891 | 0.7094 | 0.6317 | 0.5625 | 0.4181 | 0.6922 | - | 2.0411 |
| SCAMET | 0.8072 | 0.7136 | 0.6431 | 0.5846 | 0.4614 | 0.7258 | - | 2.3570 |
| CNN-T | 0.8220 | 0.7410 | 0.6620 | 0.5940 | 0.3970 | - | - | 2.7050 |
| GLCM | 0.8041 | 0.7305 | 0.6745 | 0.6259 | 0.4421 | 0.6965 | - | 2.4337 |
| HCNet | 0.8826 | 0.8335 | 0.7885 | 0.7449 | 0.4865 | 0.8391 | - | 3.5183 |
| P-to-H | 0.8373 | 0.7771 | 0.7198 | 0.6659 | 0.4548 | 0.7860 | 0.4839 | 3.0369 |
| MGT | 0.8155 | 0.7315 | 0.6517 | 0.5796 | 0.4195 | 0.7442 | - | 2.6160 |
| Ours | 0.7816 | 0.6980 | 0.6268 | 0.5628 | 0.4044 | 0.7231 | 0.4637 | 2.5920 |
| Methods | BLEU1 | BLEU2 | BLEU3 | BLEU4 | METEOR | ROUGE-L | SPICE | CIDEr |
|---|---|---|---|---|---|---|---|---|
| T1 | 0.7913 | 0.6786 | 0.5882 | 0.5126 | 0.3832 | 0.6872 | 0.4963 | 2.8826 |
| T2 | 0.797 | 0.6869 | 0.5963 | 0.5213 | 0.3822 | 0.6866 | 0.4943 | 2.9197 |
| T3 | 0.7931 | 0.6835 | 0.5952 | 0.5218 | 0.3853 | 0.6909 | 0.4970 | 2.9399 |
| T4 | 0.8022 | 0.6924 | 0.6018 | 0.5257 | 0.3815 | 0.6919 | 0.4966 | 2.9471 |
| Methods | Training Time (min) | Inference Speed (Images/s) |
|---|---|---|
| T1 | 24.3 min | 2.58 |
| T4 | 20.5 min | 2.72 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Zhang, X.; Zhang, T.; Wang, G.; Wang, X.; Li, S. A Patch-Level Region-Aware Module with a Multi-Label Framework for Remote Sensing Image Captioning. Remote Sens. 2024, 16, 3987. https://doi.org/10.3390/rs16213987
Li Y, Zhang X, Zhang T, Wang G, Wang X, Li S. A Patch-Level Region-Aware Module with a Multi-Label Framework for Remote Sensing Image Captioning. Remote Sensing. 2024; 16(21):3987. https://doi.org/10.3390/rs16213987
Chicago/Turabian StyleLi, Yunpeng, Xiangrong Zhang, Tianyang Zhang, Guanchun Wang, Xinlin Wang, and Shuo Li. 2024. "A Patch-Level Region-Aware Module with a Multi-Label Framework for Remote Sensing Image Captioning" Remote Sensing 16, no. 21: 3987. https://doi.org/10.3390/rs16213987
APA StyleLi, Y., Zhang, X., Zhang, T., Wang, G., Wang, X., & Li, S. (2024). A Patch-Level Region-Aware Module with a Multi-Label Framework for Remote Sensing Image Captioning. Remote Sensing, 16(21), 3987. https://doi.org/10.3390/rs16213987