1. Introduction
Ground-moving-target indication (GMTI) in a synthetic aperture radar (SAR) system has attracted much interest from wide-area traffic monitoring, as well as military surveillance activities due to its long-range, all-day, and all-weather imaging capability [
1,
2,
3,
4]. However, the SAR system is typically designed for imaging stationary scenes, so when a target is in motion, it can cause the defocusing and misplacement of the target in the SAR image. This is because the target moves during the synthetic aperture time, causing a phase shift in the received signal [
5,
6,
7]. Especially for adjacent multiple targets with overlapping images, it brings additional difficulties to the imaging task in the SAR-GMTI system. Furthermore, the moving-target signal may be corrupted by undesirable clutter and noise, which is not conducive to target imaging.
An efficient method to solve this problem is time–frequency-representation (TFR)-based methods, such as the Wigner–Ville distribution (WVD) [
8,
9], Chirplet decomposition [
10,
11], the fractional Fourier transform [
12,
13], and Lv’s distribution (LVD) [
14,
15], where the signal of the moving target during the coherent processing interval (CPI) can be represented as a linear frequency modulation (LFM) form. The refocused image can be generated through parameter estimation, as well as azimuth filtering. However, owing to the corrupted moving-target signal due to the strong clutter and the cross-term induced by the multiple LFM signal components, the imaging performance of TFR-based methods is limited.
With the development of deep learning technology, deep neural networks have been widely utilized in the SAR moving-target-imaging task [
16,
17,
18,
19,
20,
21,
22]. In [
19], a deep CNN-based method was first explored and applied for multi-moving-target imaging in a SAR-GMTI system. A SAR moving-target-imaging method based on the improved U-net network was presented in [
20]. An approach based on long short-term memory networks was proposed for tracking moving targets with consecutive SAR images. Then, the refocusing process could be optimized by utilizing the predicted trajectories [
22]. However, the above imaging networks may be sensitive to radar system parameters given that they are trained on synthetic datasets under a specific SAR system, limiting the applicability of deep-learning-based methods in practical systems. The imaging performance of the previously trained networks might be compromised when handling new datasets with different system parameters. Besides, in the ship-target-imaging application, a complex-valued channel fusion U-shaped network was designed for ship target refocusing [
23], and a complex-valued convolutional autoencoder based on the attention mechanism was proposed to improve the imaging of ship targets in the GEO SA-Bi SAR system [
24]. A novel Omega-KA-net based on sparse optimization was proposed to realize moving-target imaging [
21]. The high-quality imaging results can be obtained under down-sampling and a low signal-to-noise ratio (SNR). However, these methods mainly focus on ship target imaging and do not take into account the interference of ground clutter in complex ground scenes.
The signal separation and the residual clutter removal are crucial for accurate parameter estimation and high-quality imaging of multiple moving targets. Recently, deep learning has achieved superior performance for audio separation and chirp-signal-parameter-estimation tasks [
25,
26,
27,
28,
29]. Considering the multicomponent LFM signal characteristics of the radar echo for the SAR-GMTI system, one might wonder whether this deep-learning-based technique can be applied to multicomponent LFM signal separation and can bring huge advancements for target imaging in both accuracy and efficiency. A complex-valued deep neural network was designed for the parameter estimation of chirp signals [
28]. Moreover, a framework combining the fractional Fourier transform and the alternating direction method of multipliers network was reported to achieve the parameter estimation of chirp signals under sub-Nyquist sampling [
29]. However, these methods are based on the assumption that the component number is a priori known. Thus, they may not perform optimally for practical imaging applications.
To solve the difficulties of the obvious residual clutter and cross-term interferences, the high sensitivity to the system parameters, as well as the unknown target number in existing multi-moving-target-imaging methods, a deep CNN-assisted method is proposed for multi-moving-target imaging in the SAR-GMTI system. The multi-moving-target-signal model was first analyzed and formulated by a multicomponent LFM signal form with additive perturbation after the basic SAR imaging processing and clutter suppression. The SAR system parameters and target motion information are implicitly embedded within the multicomponent LFM signal parameters, which means that the signal model is capable of comprehensively representing multi-moving-target signals under different SAR systems. Given the unknown target number, an iterative signal-separation framework based on a deep CNN is proposed. In this framework, a network named MLFMSS-Net was designed to extract the most-energetic LFM signal component from the multicomponent LFM signal and iteratively applied multiple times until all the LFM signal component separation and residual clutter suppression were achieved. The network MLFMSS-Net was designed based on a convolutional encoder–decoder architecture and trained on the dataset with various SAR system parameters, target information, and clutter types, which was generated by the multicomponent LFM-signal model. This allows the network to exhibit strong robustness and makes it a suitable solution for practical imaging applications. Consequently, a well-focused multi-moving-target image can be obtained by parameter estimation and secondary azimuth compression for each separated LFM signal component. The signal separation performance of MLFMSS-Net was explored by a simulated multicomponent LFM signal. Simulations and experiments on both airborne and spaceborne SAR data were further performed to verify the effectiveness of the MLFMSS-Net-assisted imaging method. The experimental results showed that, compared with traditional imaging methods, the proposed method achieved high-quality and high-efficiency imaging without prior knowledge of the target number in different SAR systems.
Overall, the main contributions of this paper are presented as follows:
- (1)
We designed the MLFMSS-Net based on a convolutional encoder–decoder architecture to separate the most-energetic LFM signal component from the multicomponent LFM signal with additive perturbation. The network exhibited strong robustness and low dependence on the system parameters, making it more suitable for practical imaging tasks;
- (2)
We propose a MLFMSS-Net-assisted multi-moving-target-imaging method for the SAR-GMTI system. Given the unknown target number, an iterative signal-separation framework based on the trained MLFMSS-Net is presented to separate the multi-moving-target signal into multiple LFM signal components while eliminating the residual clutter. Both the imaging quality and efficiency of the proposed method were greatly improved.
The remainder of this paper is organized as follows. The multi-moving-target-signal model for the SAR-GMTI system is first established in
Section 2. On this basis,
Section 3 proposes the MLFMSS-Net-assisted multi-moving-target-imaging method. The iterative signal-separation framework based on MLFMSS-Net and the corresponding network details are provided in this section.
Section 4 discusses the experimental results and performance analysis, including the results on the simulated multicomponent LFM signal and simulations and experiments on both airborne and spaceborne SAR data. Finally, the discussion and conclusion are given in
Section 5 and
Section 6, respectively.
3. MLFMSS-Net-Assisted Multi-Moving-Target Imaging
To realize the simultaneous refocusing of multiple moving targets, a MLFMSS-Net-assisted multi-moving-target-imaging method is proposed in this section. In the following, the overall scheme is presented in
Section 3.1. In
Section 3.2,
Section 3.3 and
Section 3.4, the dataset, the architecture, and the training procedure of the designed network named MLFMSS-Net will be discussed in detail, respectively.
3.1. Overall Scheme
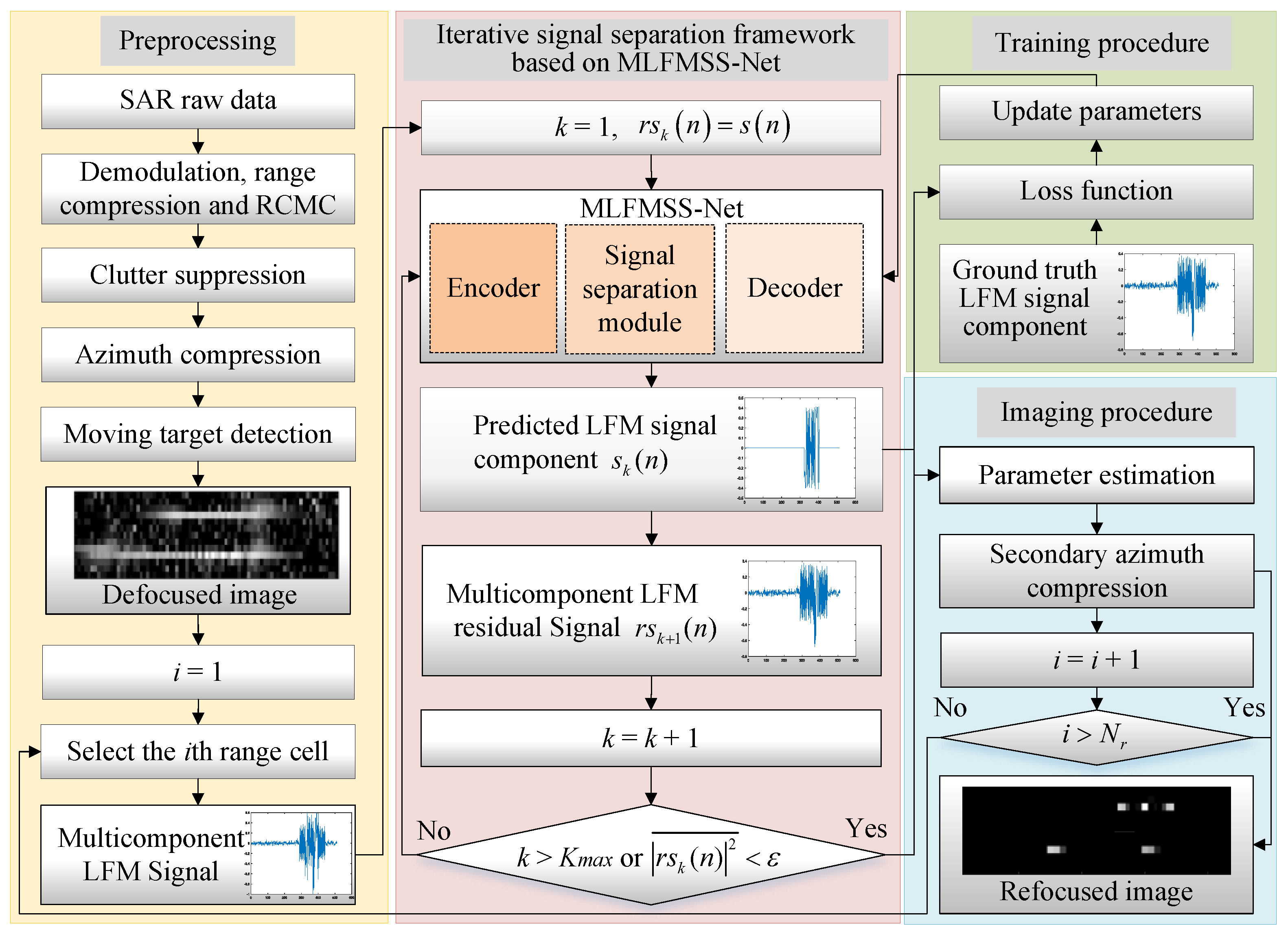
The flowchart of the proposed MLFMSS-Net-assisted multi-moving-target-imaging method is illustrated in
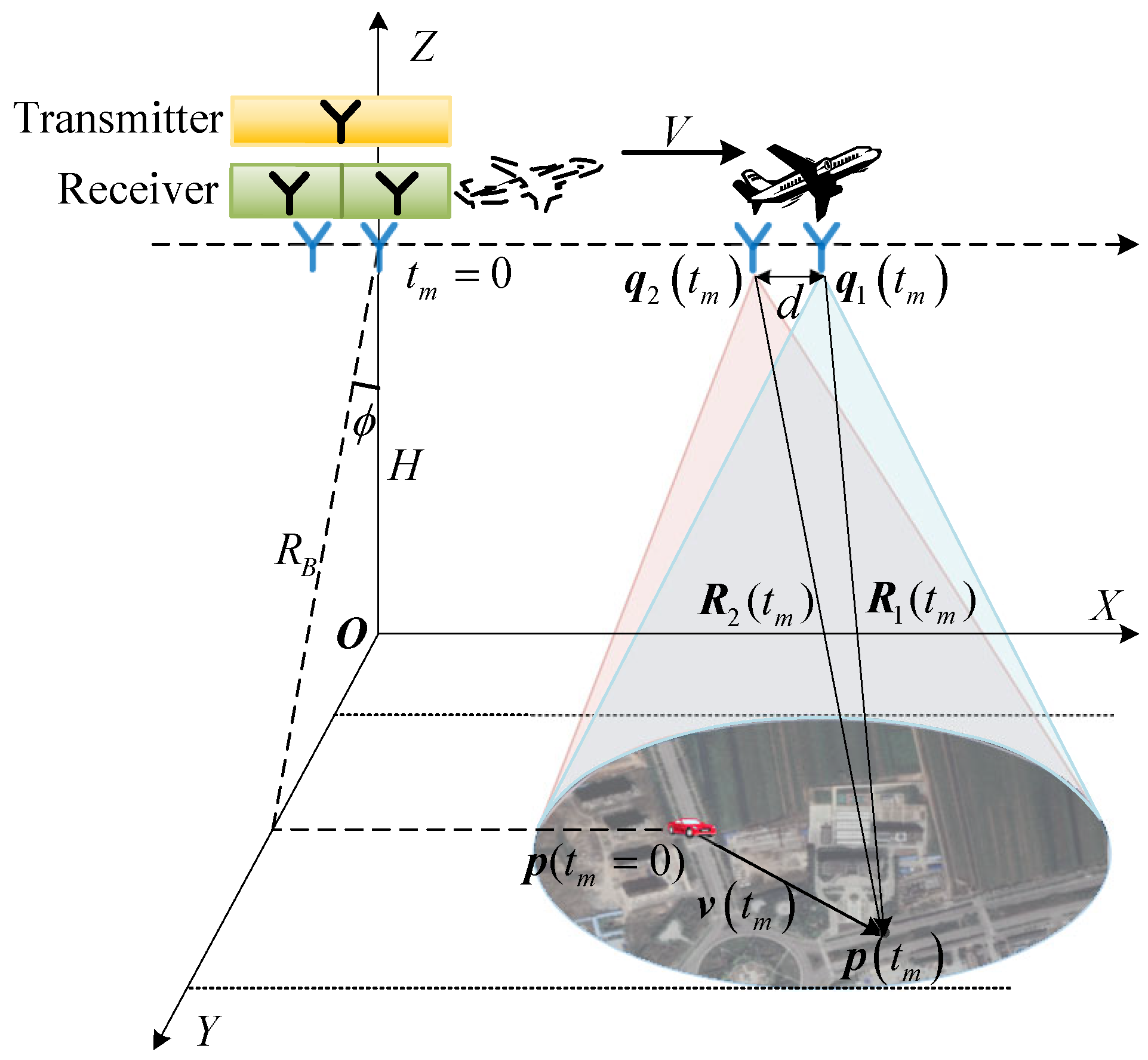
Figure 2. In the preprocessing procedure, basic SAR imaging processing (including demodulation, range compression, RCMC, and azimuth compression) and clutter suppression are performed on the SAR raw data. Then, a constant false alarm rate (CFAR) detector is utilized to detect and extract the defocused moving-target image, each range cell of which can be modeled as a multicomponent LFM signal form given by Equation (
13). Considering that different motion parameters of targets lead to different values of
in Equation (
13), it is difficult to directly perform the parameter estimation and the azimuth compression matched to each target parameter on
. Therefore, the multicomponent LFM signal separation during the residual clutter elimination, i.e.,
separation into
and
elimination from
, is a critical step for the multi-moving-target imaging before the parameter estimation and secondary azimuth compression. However, the unknown target numbers pose significant challenges for the signal-separation task. To address this problem, an iterative signal-separation framework based on a deep CNN is proposed. In this framework, a network named MLFMSS-Net is designed to extract the most-energetic LFM signal component from the multicomponent LFM signal, iteratively applied multiple times until all LFM signal components are successfully separated.
The most-energetic LFM signal-component-extraction task can be formulated as a regression problem, i.e.,
, which can be solved by MLFMSS-Net.
is the network with parameters
. Utilizing a set of training data, MLFMSS-Net is trained through the minimization of the loss function. This training process enables the determination of optimal network parameters
, leading to improved performance of the model. The network details will be discussed in subsequent subsections. Then, the well-trained MLFMSS-Net is applied in the iterative signal-separation framework. Specifically, the number of iterations and the residual are first initialized by
and
, respectively. At each iterative step, the well-trained MLFMSS-Net is employed to
for the most-energetic LFM signal component
extraction. Then, the new signal component
is eliminated from
to obtain the updated residual as follows:
The number of iterations is updated by . The aforementioned steps are repeated to extract a new LFM signal component from the residual until k either exceeds the maximum number of moving targets or the average power of the residual is less than an empirical threshold value . Given that is feasible for a new LFM signal component declaration, it is advisable to set the value of equal to the average power of the background clutter surrounding the moving targets for the residual clutter suppression. Then, let the target number . As a consequence, all LFM signal components’, , separation and residual clutter suppression from have been achieved based on the proposed framework.
To realize
K-moving-target imaging, in the imaging procedure, WVD is applied for the quadratic coefficient
estimation of
. Secondary azimuth compression matched to
is further performed on the corresponding signal component
to generate the well-focused
kth moving-target image as follows:
where
and
denote the Fourier transform and the inverse Fourier transform, respectively. The azimuth matching function is expressed as
. The azimuth multi-moving-target image of each range cell can be generated by the linear superposition of each target image as follows:
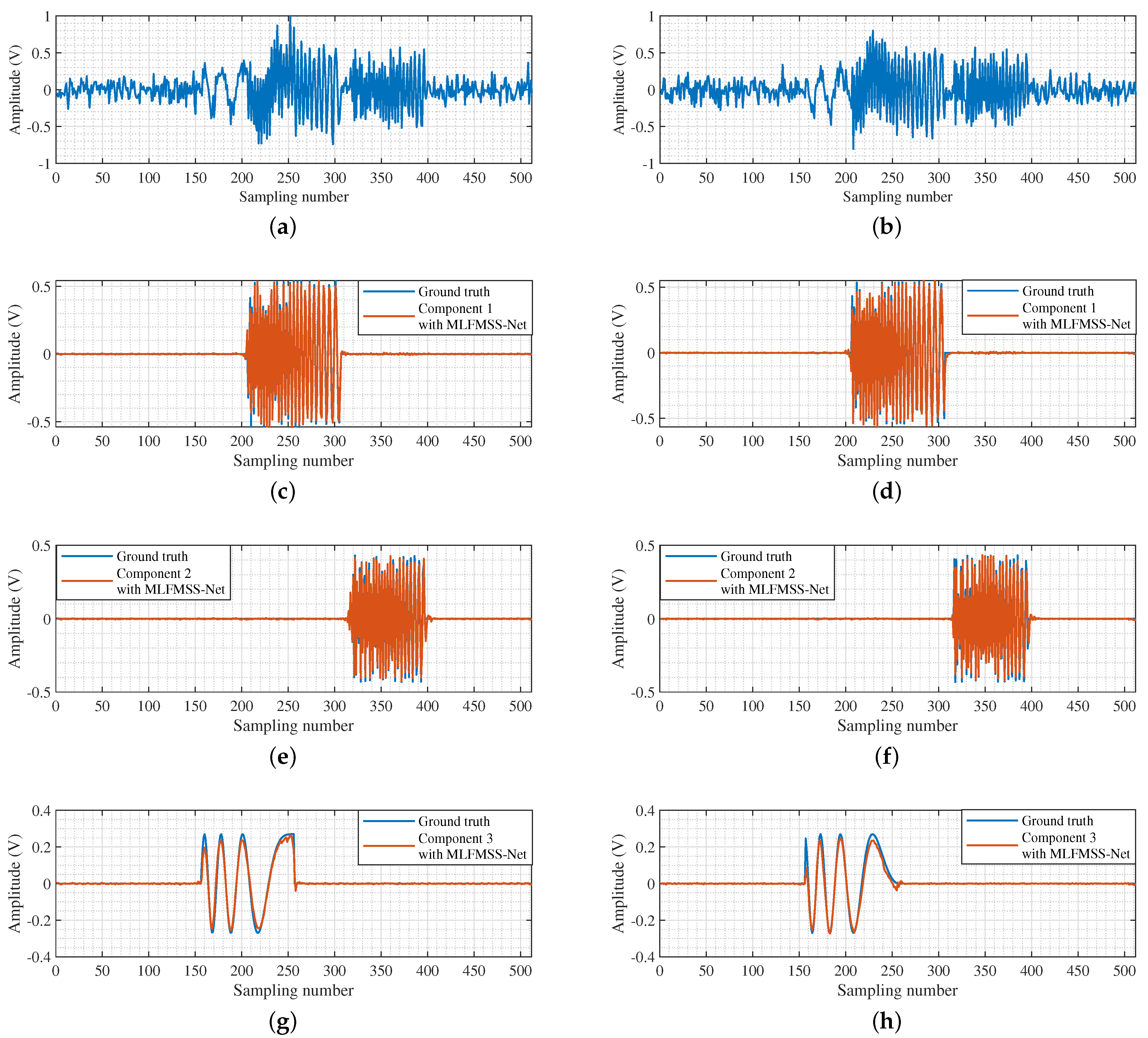
Therefore, the iterative signal-separation framework based on MLFMSS-Net, as well as the imaging procedure are implemented on each of the range cell data containing multiple targets to obtain the whole well-refocused moving-target image. The specific implementation procedures of the proposed method can be summarized in Algorithm 1.
| Algorithm 1: The MLFMSS-Net-assisted multi-moving-target-imaging method |
- 1
Preprocessing: Implement the basic SAR imaging processing and clutter suppression to obtain the defocused image of multiple moving targets - 2
Input: Defocused multi-moving-target image - 3
Output: Refocused multi-moving-target image - 4
for to do - 5
select the signal from the ith range cell; - 6
initialize and ; - 7
while or do - 8
by the well-trained MLFMSS-Net; /* design MLFMSS-Net , where the network parameters are optimized by minimizing the loss function through the training data */ - 9
; - 10
; - 11
end - 12
; - 13
for to K do - 14
estimate of by WVD; - 15
; - 16
end - 17
; - 18
end
|
3.2. Dataset Description
Data pairs consisting of the multicomponent LFM signal and the corresponding most-energetic LFM signal component are required for the training of MLFMSS-Net. The multicomponent LFM signal from different SAR systems can be simulated according to Equation (
13). It is worth mentioning that this network primarily focuses on refocusing the moving targets, rather than imaging the SAR observation scene. If all the large-sized SAR data are directly utilized as the network input, it would require a large amount of memory and computation time for training. Moreover, many clutter areas without moving targets are not useless for training. Instead of all the SAR data, therefore, numerous small-sized data patches with the length
containing moving targets should be extracted from the SAR data and processed by the proposed MLFMSS-Net-assisted imaging method. The number of LFM signal components is a random integer from 0 to 5 for each signal sample. The signal parameters, respectively, obey the following uniform distributions:
,
,
,
. Given that the SAR system parameters are implicitly embedded within the
of
,
follows a uniform distribution over the reasonable range
. This ensures that the dataset contains multicomponent LFM signals from various SAR systems.
Because of the terrain’s heterogeneity, according to the analysis in [
34], the additive perturbation
was simulated under the assumption of a compound clutter model. This model accounts for heterogeneity in the data by assuming that each sampling cell is the product of a speckle random variable (RV)
and a statistically independent texture RV
, i.e.,
.
is characterized by a complex Gaussian distribution
, where
is the correlation coefficient between two channels.
and
are the clutter and noise powers, respectively. It is convenient to normalize
to its expectation, i.e.,
.
can be physically interpreted as the fluctuating variance (power) of the speckle. It is independent of the radar position and depends on the spatial distribution, orientation, and type of clutter under measurement.
obeys the following distribution [
34]:
where
represents the texture parameter indicating the level of clutter heterogeneity in the imaging scene. A higher value of
suggests a more-homogeneous scene, while a lower value indicates a more-heterogeneous scene. The density function of
can be calculated by Bayes rule as follows [
35]:
According to the aforementioned distribution, can be simulated with a given . To obtain the dataset containing the clutter with various heterogeneity levels, should follow the uniform distribution . Consequently, the multicomponent LFM signal can be obtained by summing the LFM signal components and the additive perturbation with different input SCNRs obeying the uniform distribution in the dataset. The real and imaginary parts of the multicomponent LFM signal are divided into two independent channels as the network input .
In addition, the most-energetic LFM signal component in the multicomponent LFM signal will be adopted as the output of MLFMSS-Net. Similarly, the real and imaginary parts of the signal component are treated as two independent channels, i.e., .
Therefore, thousands of data pairs with diverse SAR system parameters, target motion characteristics, and clutter types have been generated for training and testing. It is worth noting that the minimax normalization strategy is utilized to normalize the dataset into the range [0, 1] for better network training and performance optimization.
3.3. Architecture of Multicomponent Linear Frequency Modulation Signal-Separation-Net
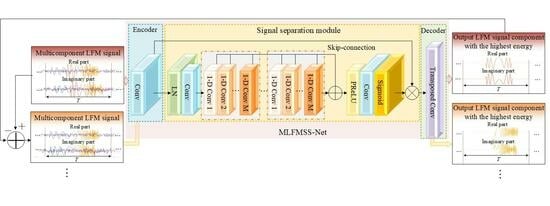
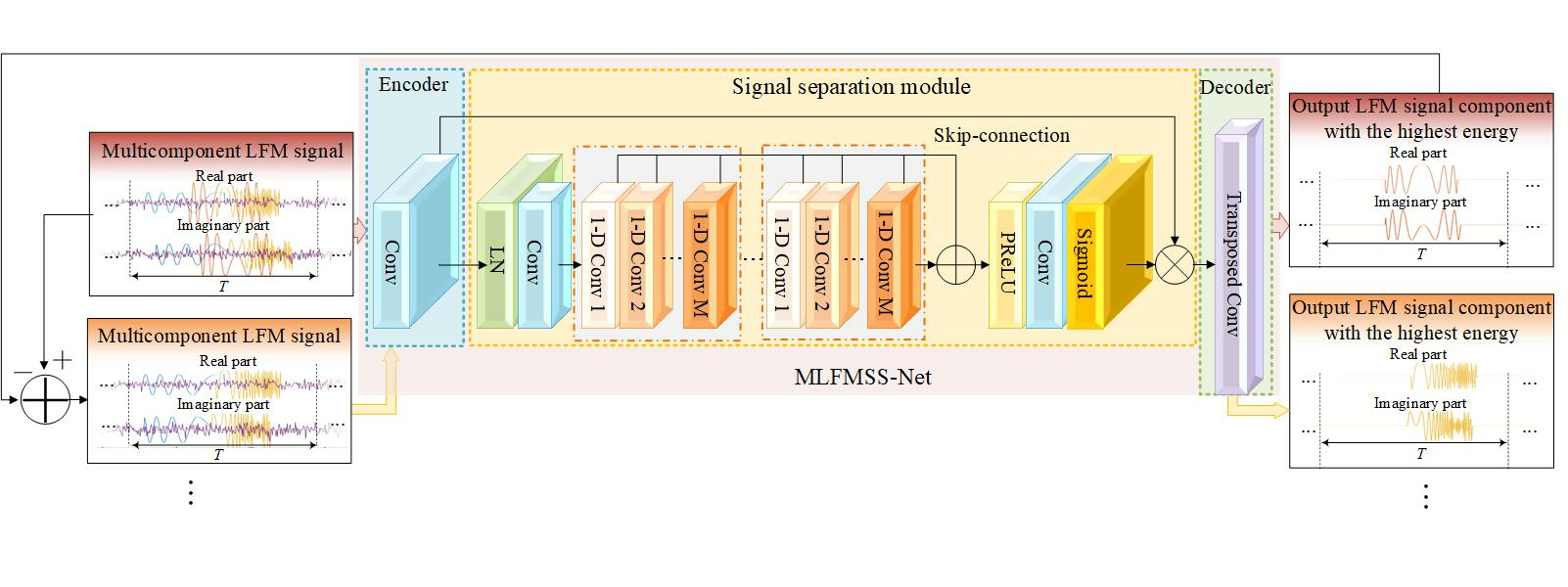
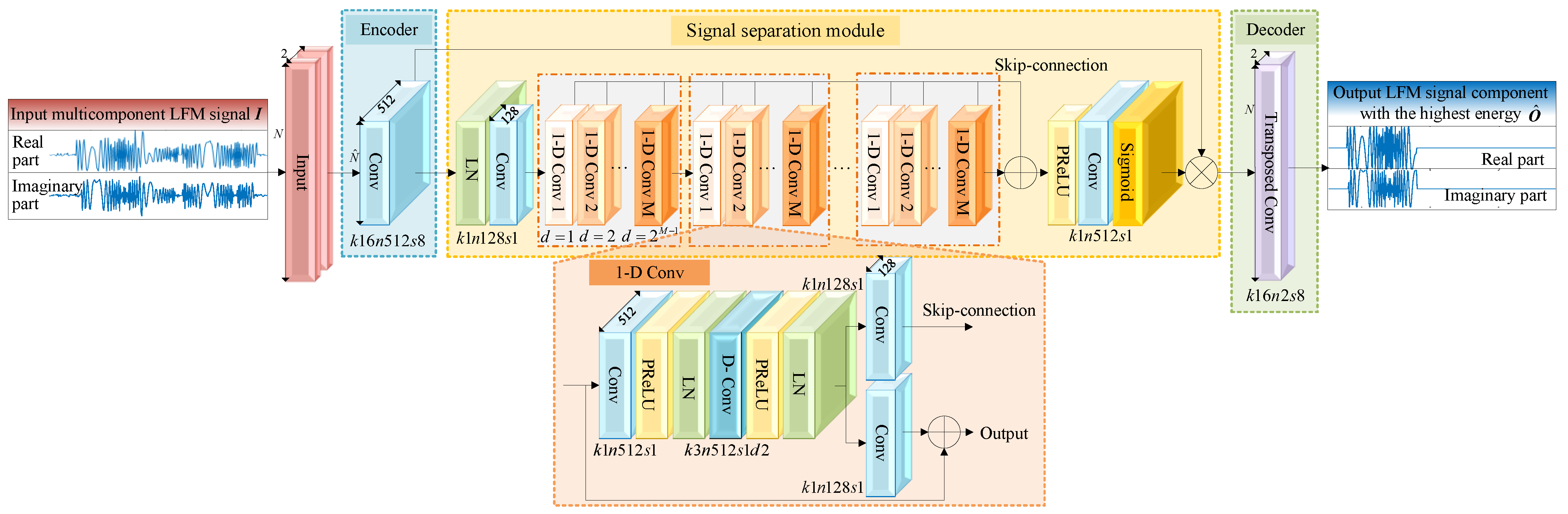
As shown in
Figure 3, MLFMSS-Net consists of the encoder, the signal-separation module, and the decoder. The notation
represents a 1D convolutional layer with a kernel size of 16, a filter number of 32, and a stride of 8. A convolutional layer without zero padding is utilized as the encoder to transform short segments of the network input
into their corresponding representations
in an intermediate feature space. The signal-separation module is then implemented by estimating a weighting function (mask)
, which is elementwise multiplied with the encoder output, i.e.,
, where ⊙ denotes the elementwise multiplication. Finally, a transposed convolutional layer as the decoder is exploited to transform the masked encoder feature into the LFM signal component with the highest energy
. We describe the details of the signal-separation module in the following.
3.3.1. Signal-Separation Module
For the separation mask
estimation, the global layer normalization (gLN) is first exploited to normalize the feature over both the channel and time dimensions [
36]. A convolutional layer of kernel size 1 is added as a bottleneck layer to adaptively fuse the effective features and stabilize the training of the deeper network. Inspired by the network for audio separation, the mask can be generated by a temporal convolutional network (TCN) [
26,
37]. This TCN is composed of multiple 1D dilated convolutional blocks (1D Convs), which enable the network to capture long-term dependencies within the input signal while maintaining a compact model size. The 1D Conv with an exponentially increasing dilation factor ensures a sufficiently large temporal context window to take advantage of the long-range dependencies of the signal. In the signal-separation module, eight 1D Convs with dilation factors
are repeated 3 times. A residual path and a skip-connection path of each 1D Conv are applied: the residual path of the current 1D Conv is directly fed into the next block, while the skip-connection paths for all blocks are summed up and utilized as the output of the TCN, which is passed to a parametric rectified linear unit (PReLU) activation function [
38]. Finally, a convolutional layer with a Sigmoid function is applied to estimate the mask.
3.3.2. One-Dimensional Dilated Convolutional Block
In each 1D Conv, as shown in
Figure 3, a convolutional layer with a kernel size of 1 is first added to increase the complexity and richness of the features. The PReLU activation function is utilized to introduce nonlinearity and is followed by a gLN. Subsequently, to further reduce the number of parameters while maintaining a certain level of feature representation capability, the depthwise separable convolution can be employed as a substitute for the standard convolutional operation [
39]. The depthwise separable convolution operator decouples the standard convolution operation into a depthwise convolution (D-Conv) with dilation factor
d and a pointwise convolution. Besides, a PReLU activation function together with a normalization operation is added after the D-Conv. Each 1D Conv consists of a residual path and a skip-connection path, which improve the flow of information and gradient throughout the network.
3.4. Training Procedure
To achieve the desired signal separation performance of MLFMSS-Net, the network is required to be trained by minimizing a signal separation loss, denoted as
. Here,
represents the predicted output of the network
and
is the ground truth LFM signal component with the highest energy. The signal-separation task can be formulated as a regression problem, where the goal is to minimize the difference between the predicted and ground truth signals. This is typically achieved by applying the pixelwise squared Euclidean distance as the loss function:
An NVIDIA GeForce GTX3090 GPU was utilized to train the MLFMSS-Net model. The model was trained with 500,000 training samples and 150,000 validation samples. Then, 150,000 samples were used for testing. The batch size was configured to 32 during the training process. Furthermore, Adam [
40] was exploited as the optimization algorithm to update
at each step. The learning rate of the network was initially set to
and decayed by 0.5 for every 5 epochs. This allowed the network to gradually adjust its parameters towards the optimal values that minimize the loss function.
During training, MLFMSS-Net underwent 125,000 backpropagation iterations within 1.46 h, resulting in a good fitting performance. The well-trained network is capable of achieving accurate predictions of outputs for unseen inputs. It has learned and captured the mapping relationship between its input and output, allowing it to generate the LFM signal component by simply calculating .
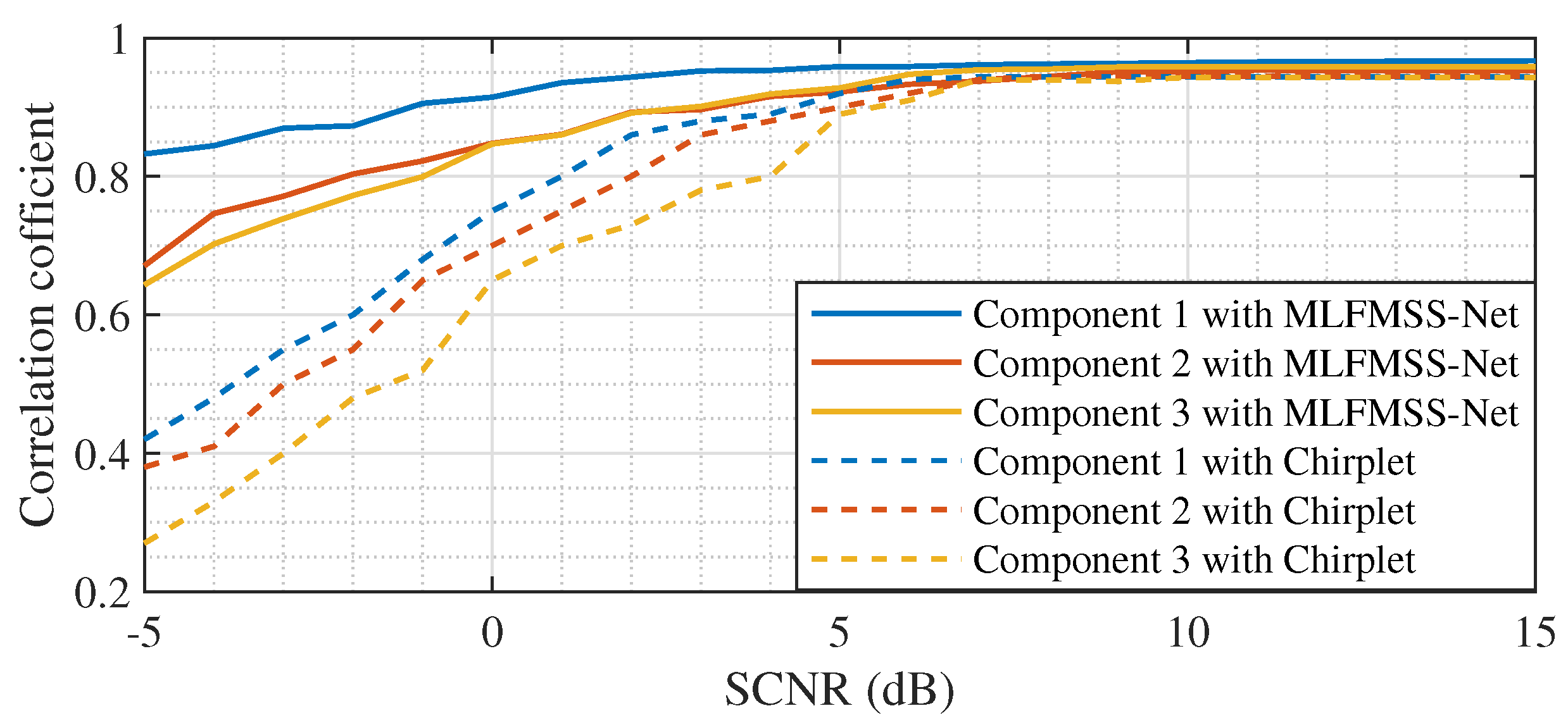
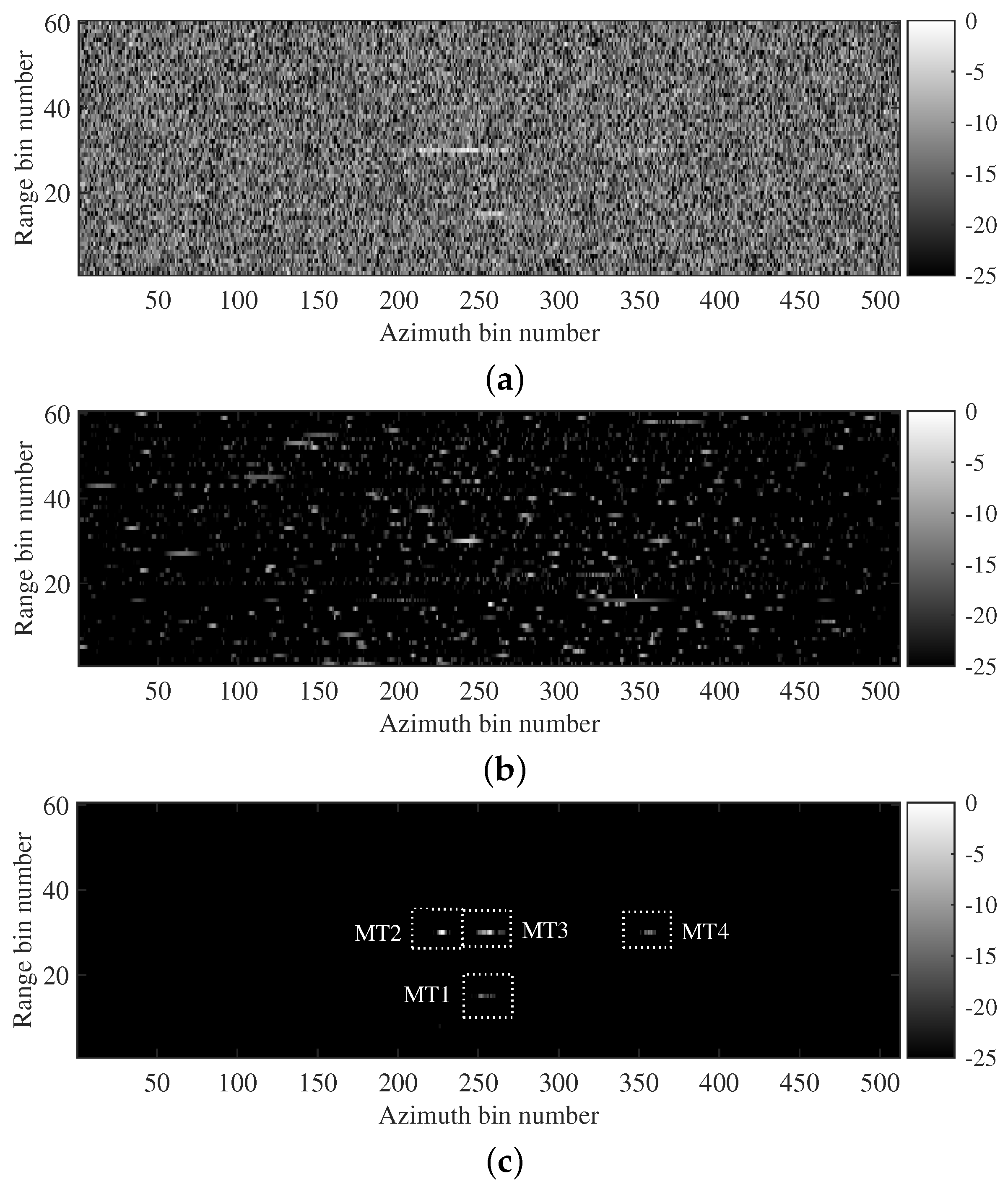
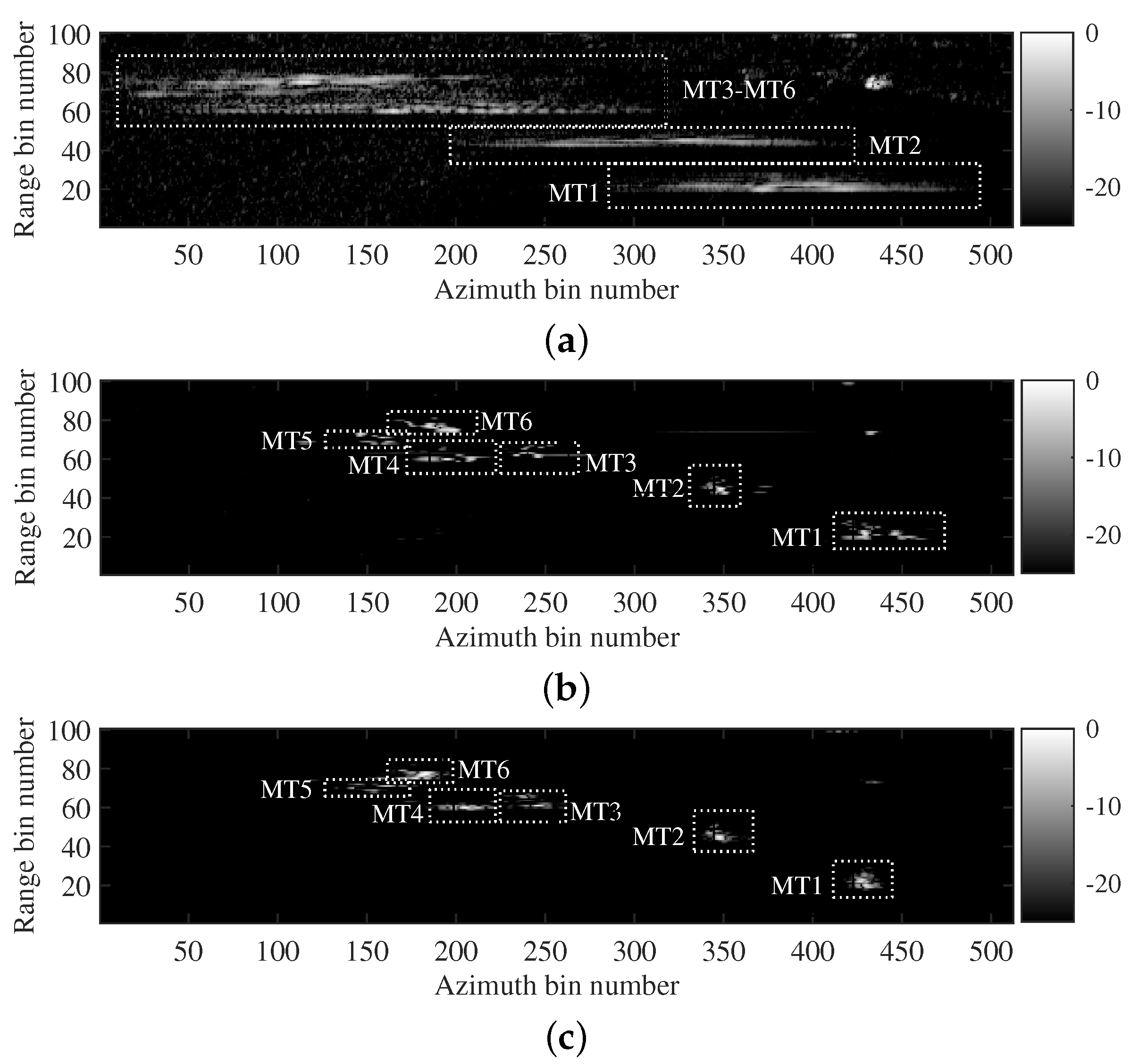
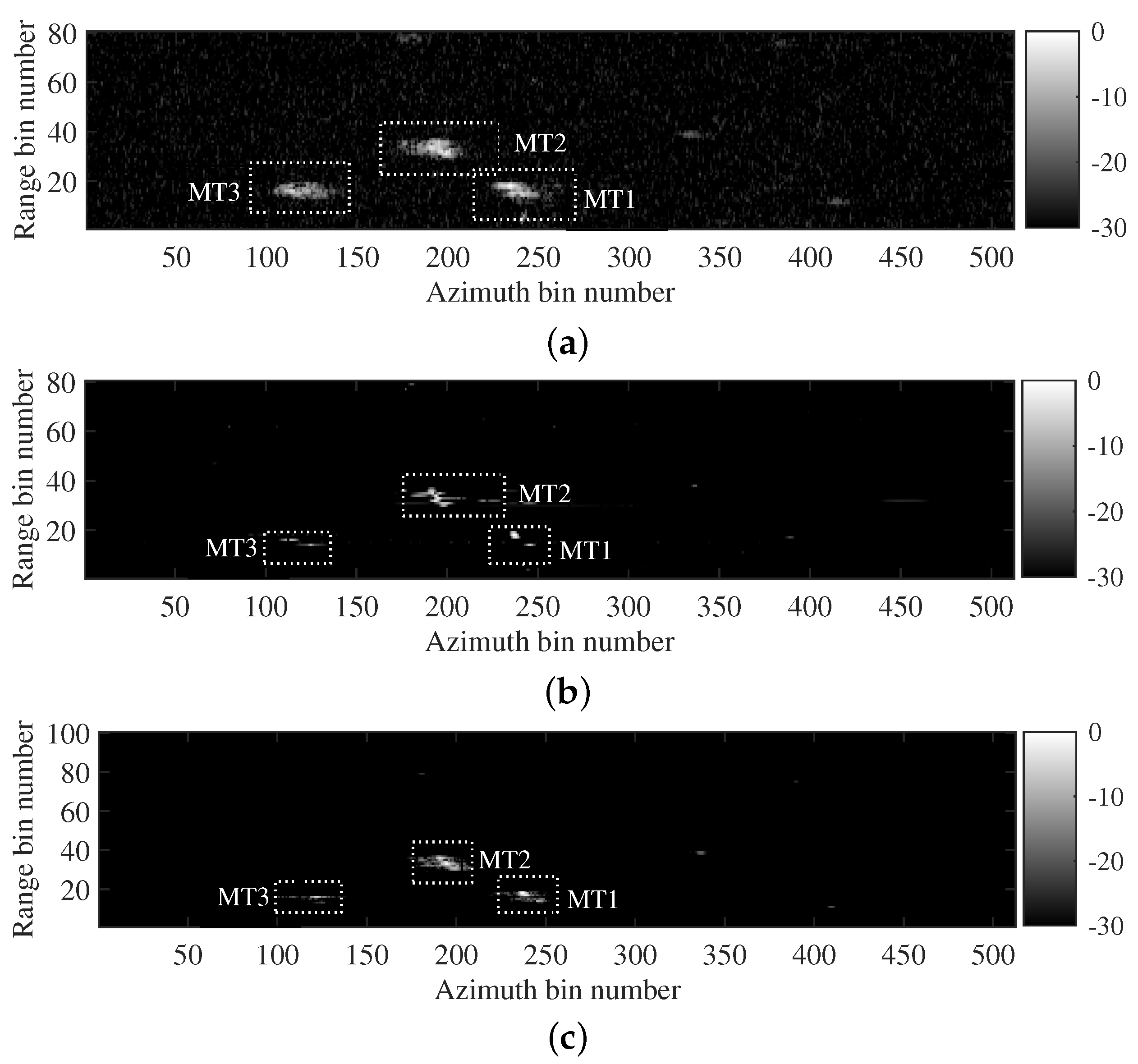
5. Discussion
In
Section 4.2, two simulated data acquired by the airborne and spaceborne SAR systems were both utilized to verify the applicability of the proposed imaging method. The results showed that the trained MLFMSS-Net realizes the separation of multicomponent LFM signals from different SAR systems. With the assistance of MLFMSS-Net, the proposed imaging method achieves high-quality and high-efficiency imaging without prior knowledge of the system parameters. The reason behind this success lies in the fact that the training dataset was generated based on a multicomponent LFM signal model, the parameters of which implicitly embed the radar system parameter information. By training MLFMSS-Net on this abundant dataset containing different signal parameters, the network becomes adaptable to various radar systems. In
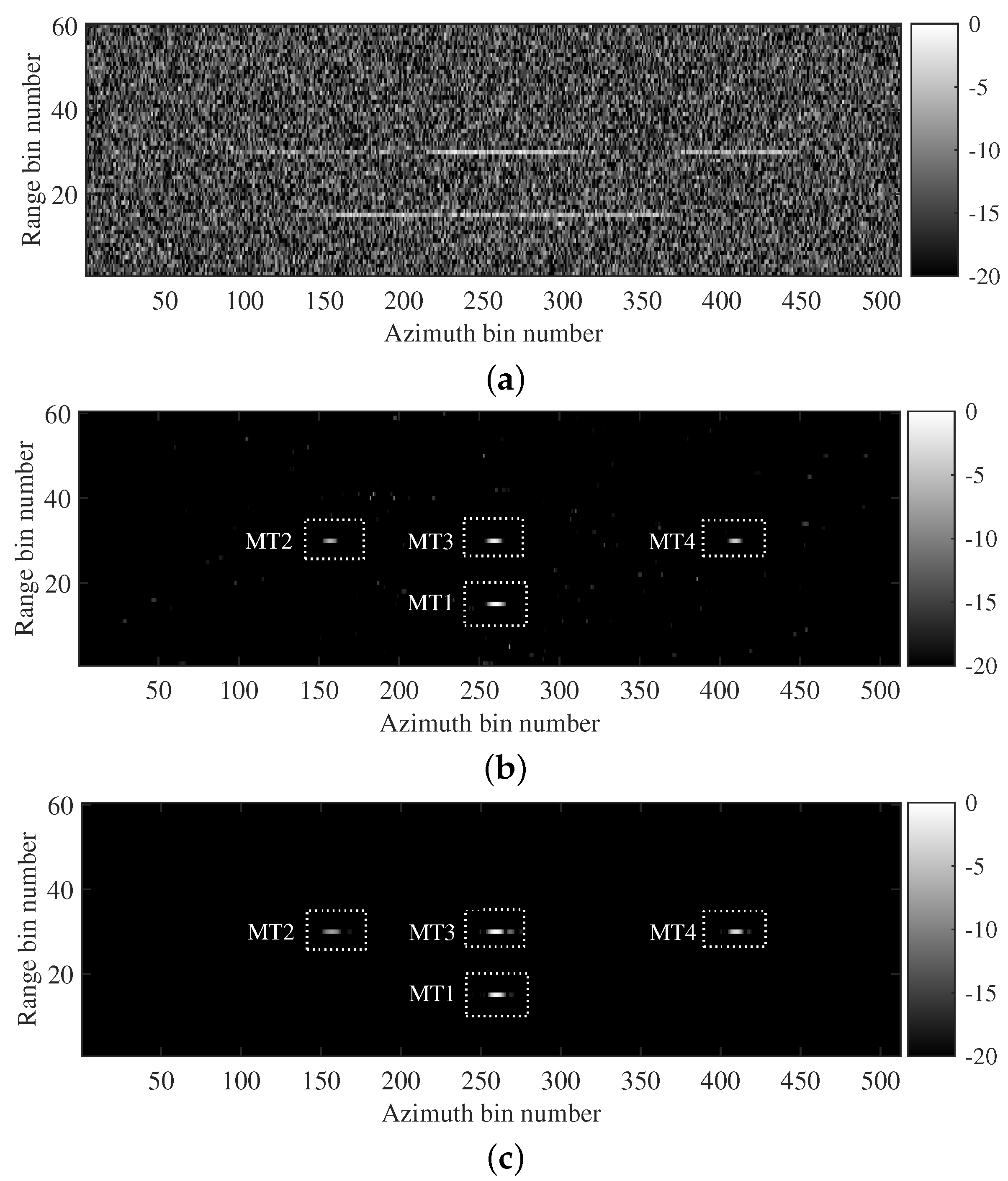
Section 4.3, experiments on two sets of real data acquired from airborne SAR systems and the TerraSAR-X satellite further confirmed the ability of the proposed method to improve the robustness of moving-target imaging, while reducing sensitivity to the system parameters. This is of great significance for the application of the proposed method in real-world scenarios.
Meanwhile, experiments with different target numbers in
Section 4 demonstrated that the proposed method is capable of achieving the multi-moving-target imaging without prior knowledge of the target number, exhibiting its suitability for practical imaging scenarios.
However, it is worthwhile to remark that the length of the separated signals in the experiments was fixed owing to the fixed training sample length in the dataset, limiting the flexibility of moving-target imaging processing. Therefore, our future work will focus on how to improve the adaptability of the network model to the separated signals with different lengths, such as more-diverse data sample generation and multi-scale model building.
6. Conclusions
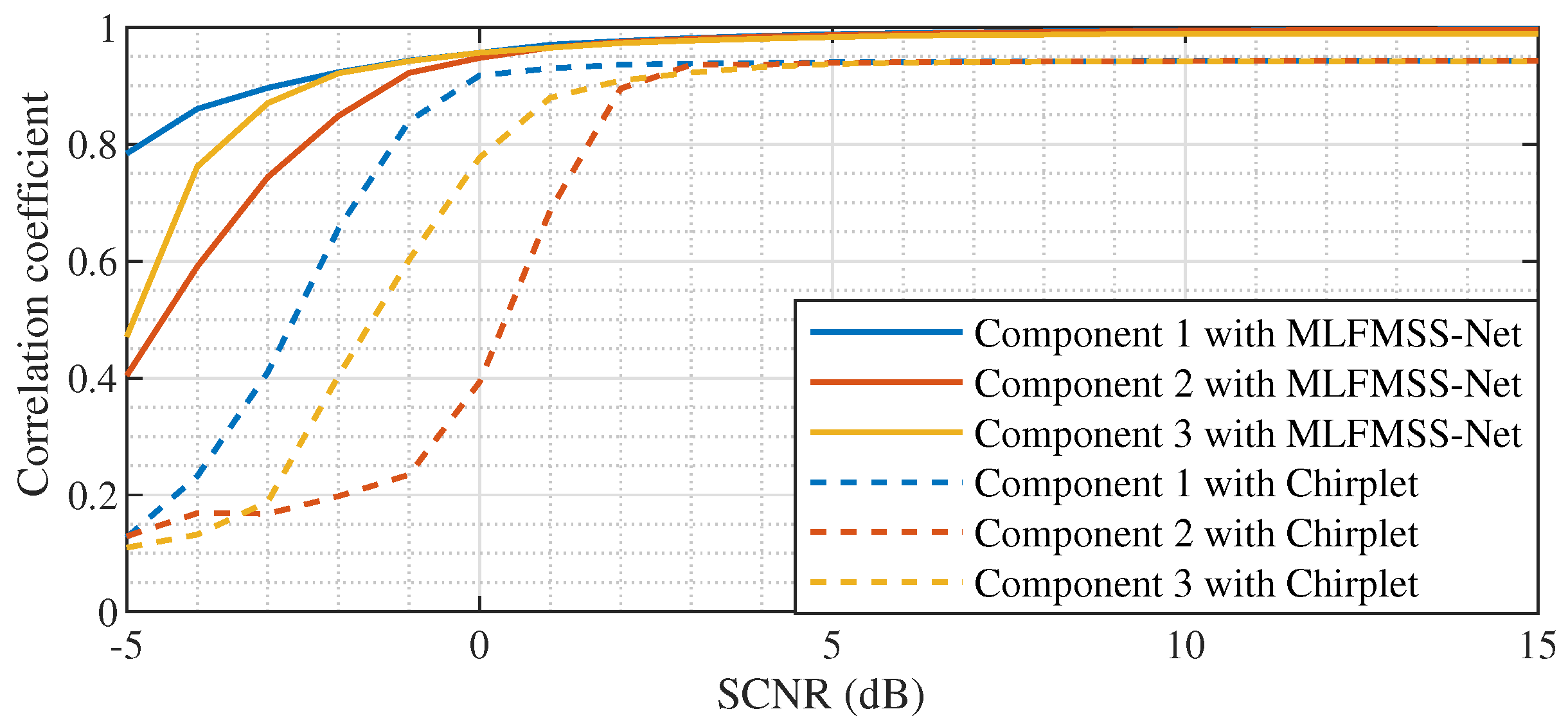
In this paper, we propose a MLFMSS-Net-assisted multi-moving-target-imaging method for the SAR-GMTI system. The network MLFMSS-Net was designed to extract the most-energetic LFM signal component from the multicomponent LFM signal and trained on the dataset with various SAR system parameters, target information, and clutter types, which was generated by the multicomponent LFM signal model. The well-trained MLFMSS-Net was iteratively applied multiple times to realize all LFM signal component separation and residual clutter suppression. Without prior knowledge of the target number, compared with other methods, the target imaging and residual clutter suppression performance were improved with high processing efficiency, especially in low-input SCNR scenarios. It provides further potential to implement the subsequent image interpretation including target classification and recognition. Meanwhile, the proposed method enhances the robustness of moving-target imaging, while reducing sensitivity to the system parameters, preliminarily addressing a significant challenge faced by deep-learning-based imaging methods. This allows the deep-learning-based imaging method to be a suitable solution for practical imaging applications.
In future work, we will further investigate how to incorporate the parameter estimation and pulse compression tasks into the deep network, aiming to overcome the limitations of the inherent resolution on estimation accuracy for traditional TFR-based methods and the signal bandwidth on imaging resolution for matched filtering methods. Additionally, the proposed method focuses on the imaging of ground moving targets with accelerated motions, the radar echoes of which can be characterized as the multicomponent LFM signal model. However, this signal model and the corresponding imaging method are not suitable for maritime targets with complex motions. A multicomponent higher-order phase signal model needs to be established. Subsequent research will explore how to fully utilize the powerful feature extraction and signal separation capabilities of MLFMSS-Net and generalize its applications to complex signal models.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}