
OII: An Orientation Information Integrating Network for Oriented Object Detection in Remote Sensing Images



Abstract
:
1. Introduction
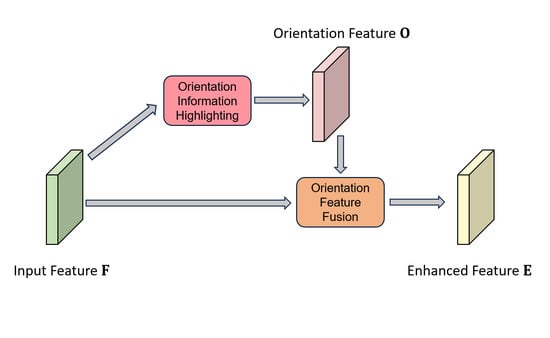
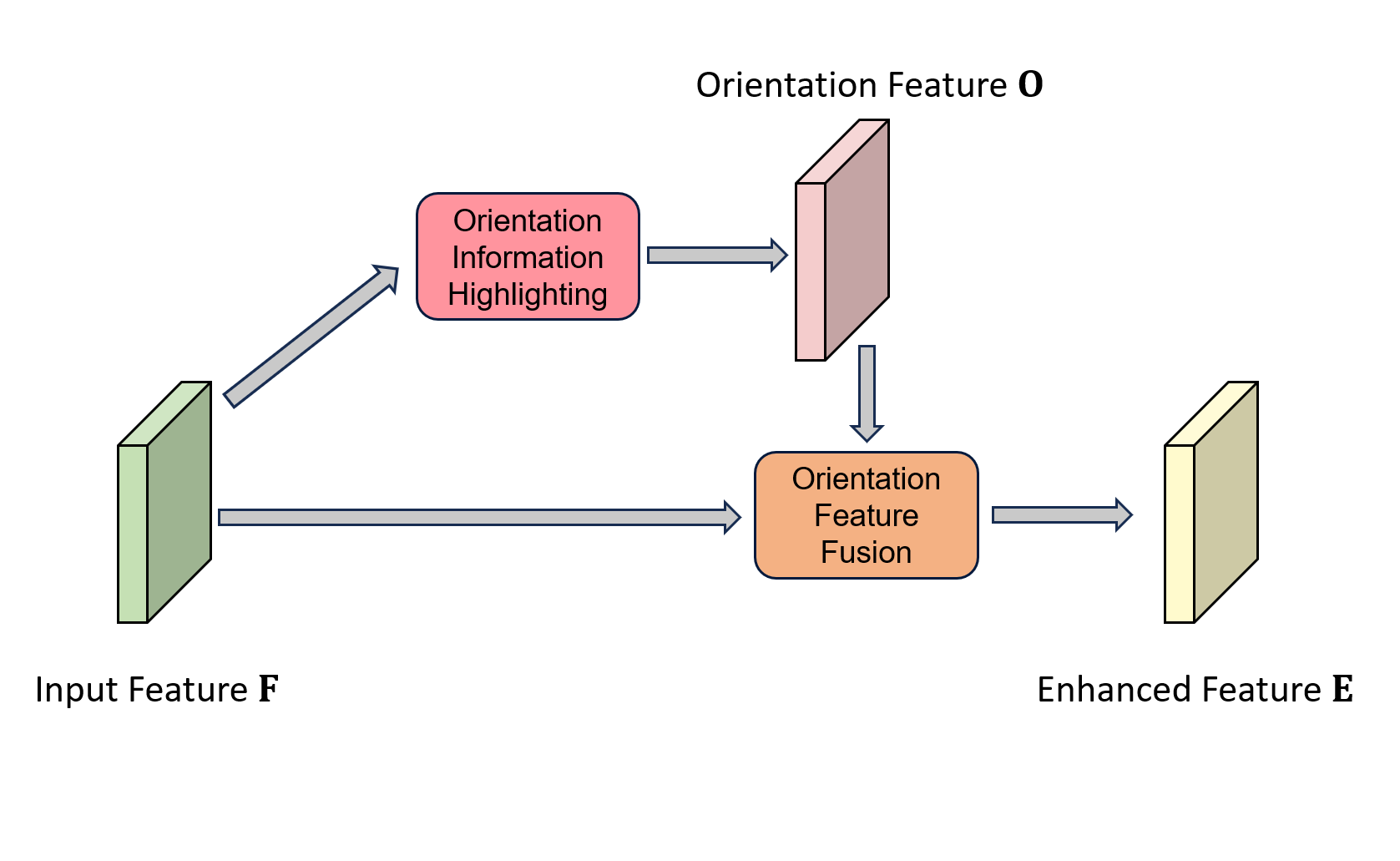
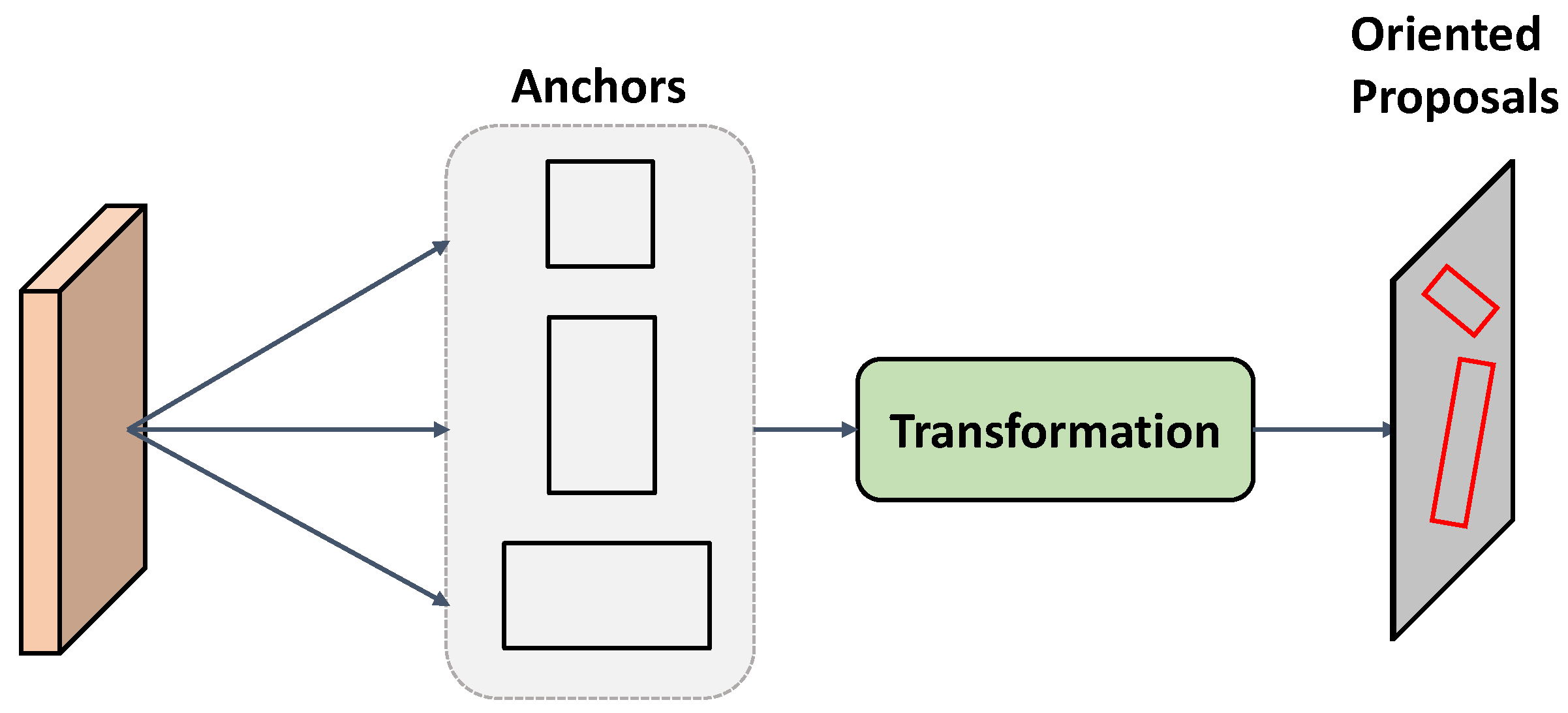
- We introduce an innovative OIH module designed for extracting orientation features across different scales and angles. By diverging from the predefined anchors and traditional feature extraction by CNN, our OIH utilizes a straightforward yet highly efficient frequency analysis approach for capturing orientation information.
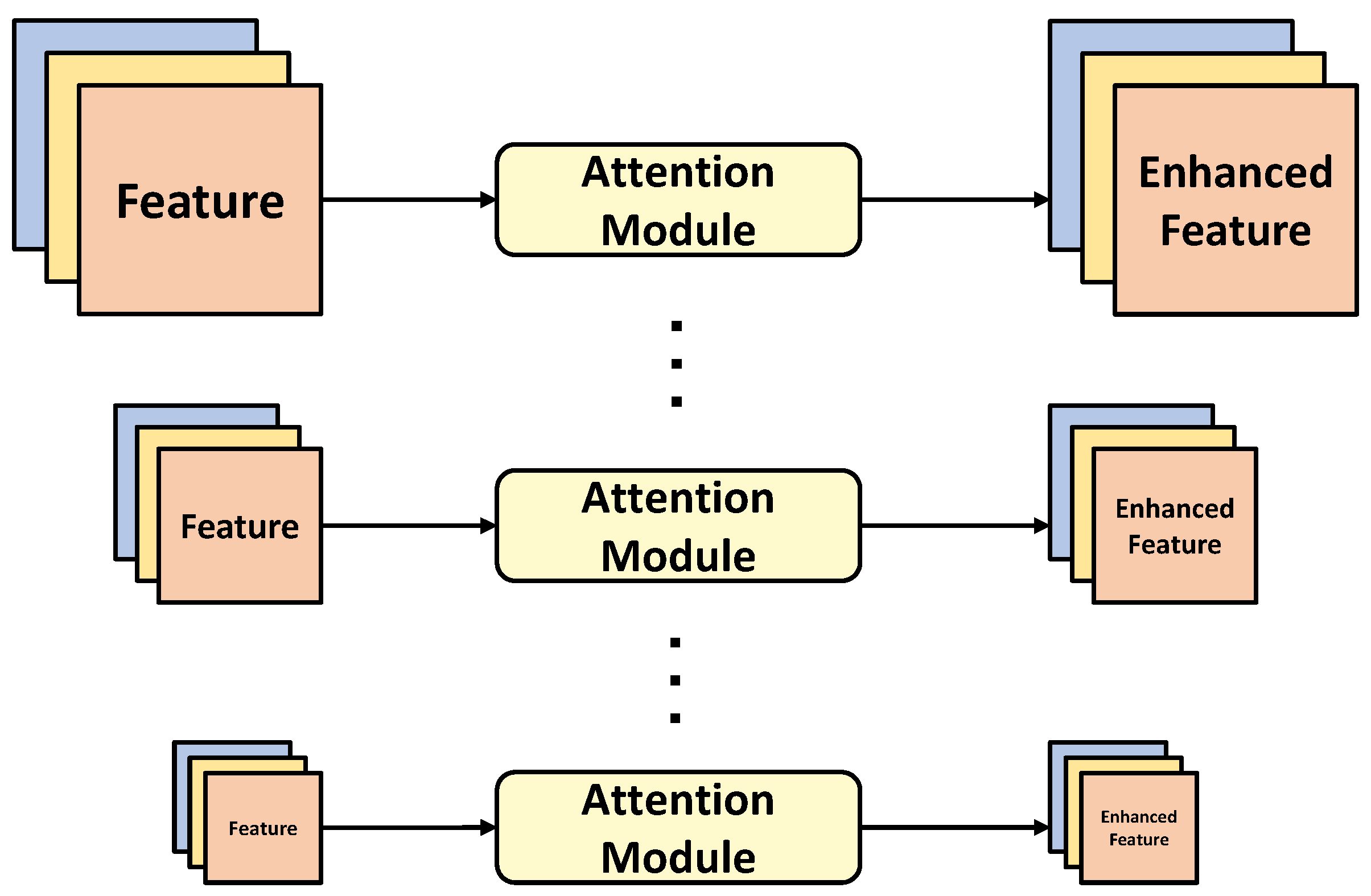
- Within the OFF module, we use a combination of a CNN attention mechanism and self-attention to generate orientation weights and original spatial weights. We integrate these two weights to reinforce our features, imbuing them with both rich orientation information and spatial positional information simultaneously.
- Upon integrating the OIH and OFF modules within the intermediary layers connecting the backbone and neck, our proposed OII network surpasses numerous state-of-the-art methods when evaluated on the DOTA and HRSC2016 datasets. This substantiates the efficacy of incorporating orientation information into CNN features for detecting rotated objects in remote sensing scenarios.
2. Related Works
2.1. Oriented Object Detection in Remote Sensing
2.2. Attention Mechanism and Self-Attention
2.3. Application of Frequency Analysis
3. Methodology
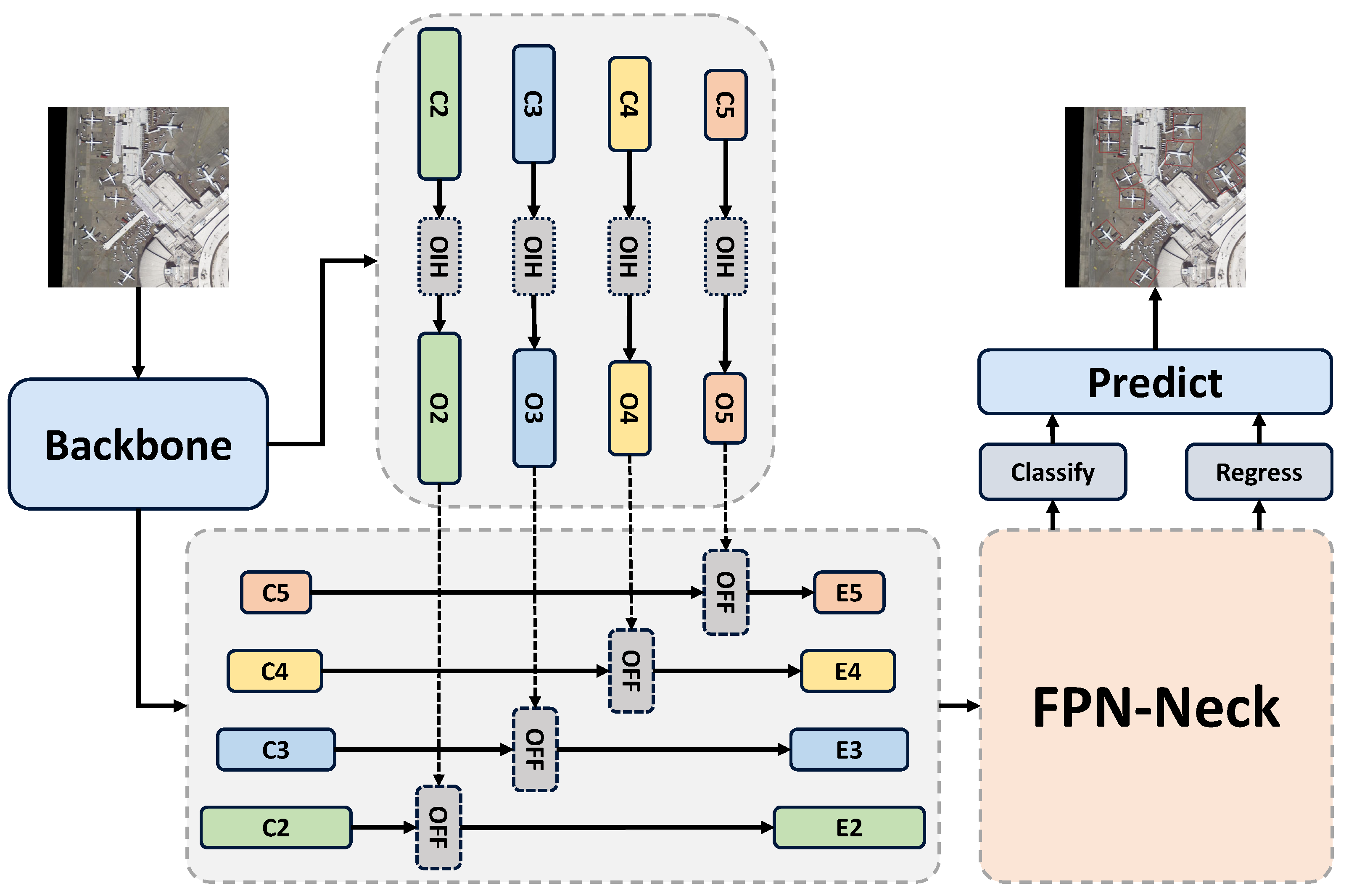
3.1. Overall Architecture
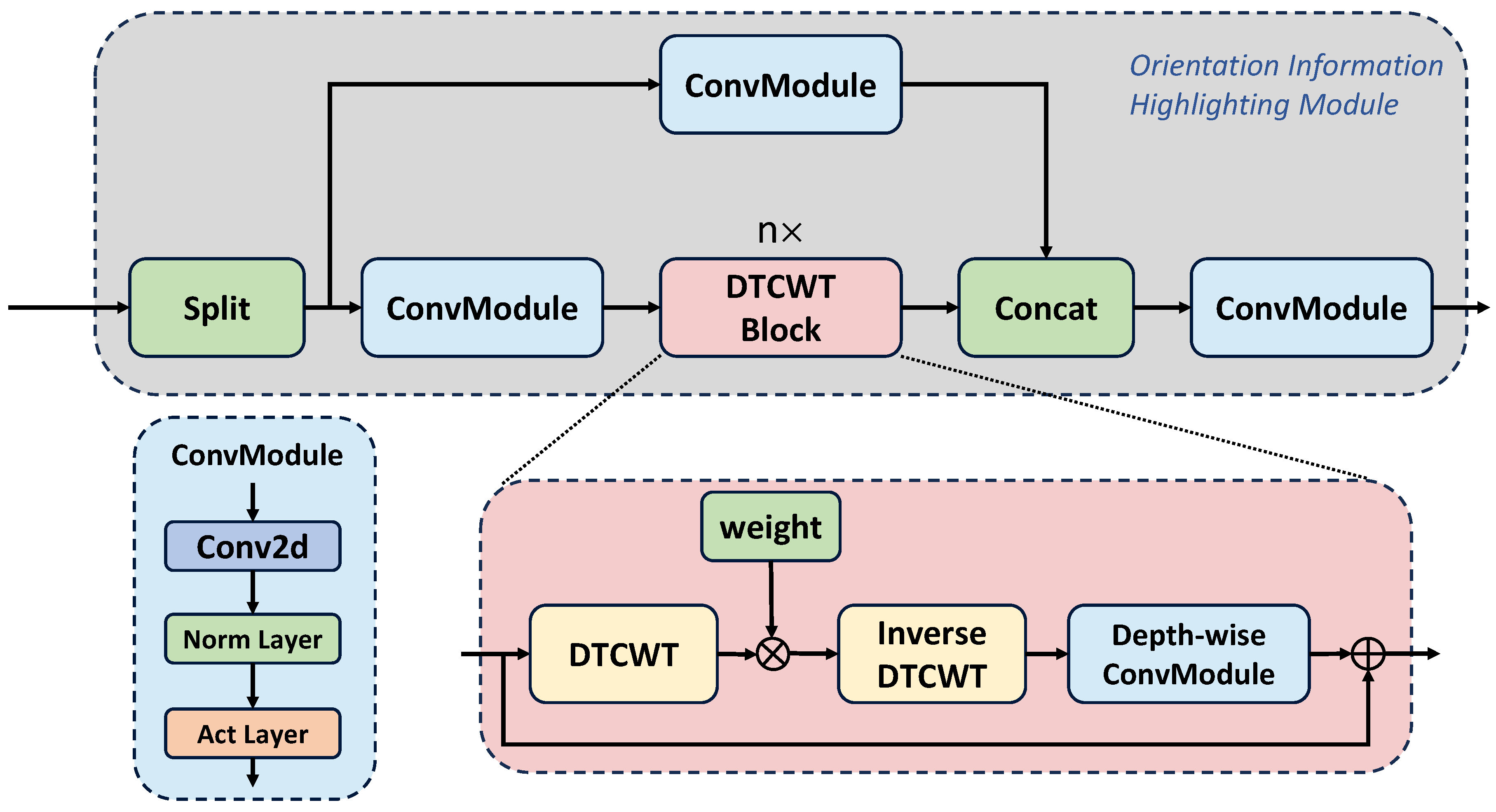
3.2. Orientation Information Highlighting Module
3.3. Orientation Feature Fusion Module
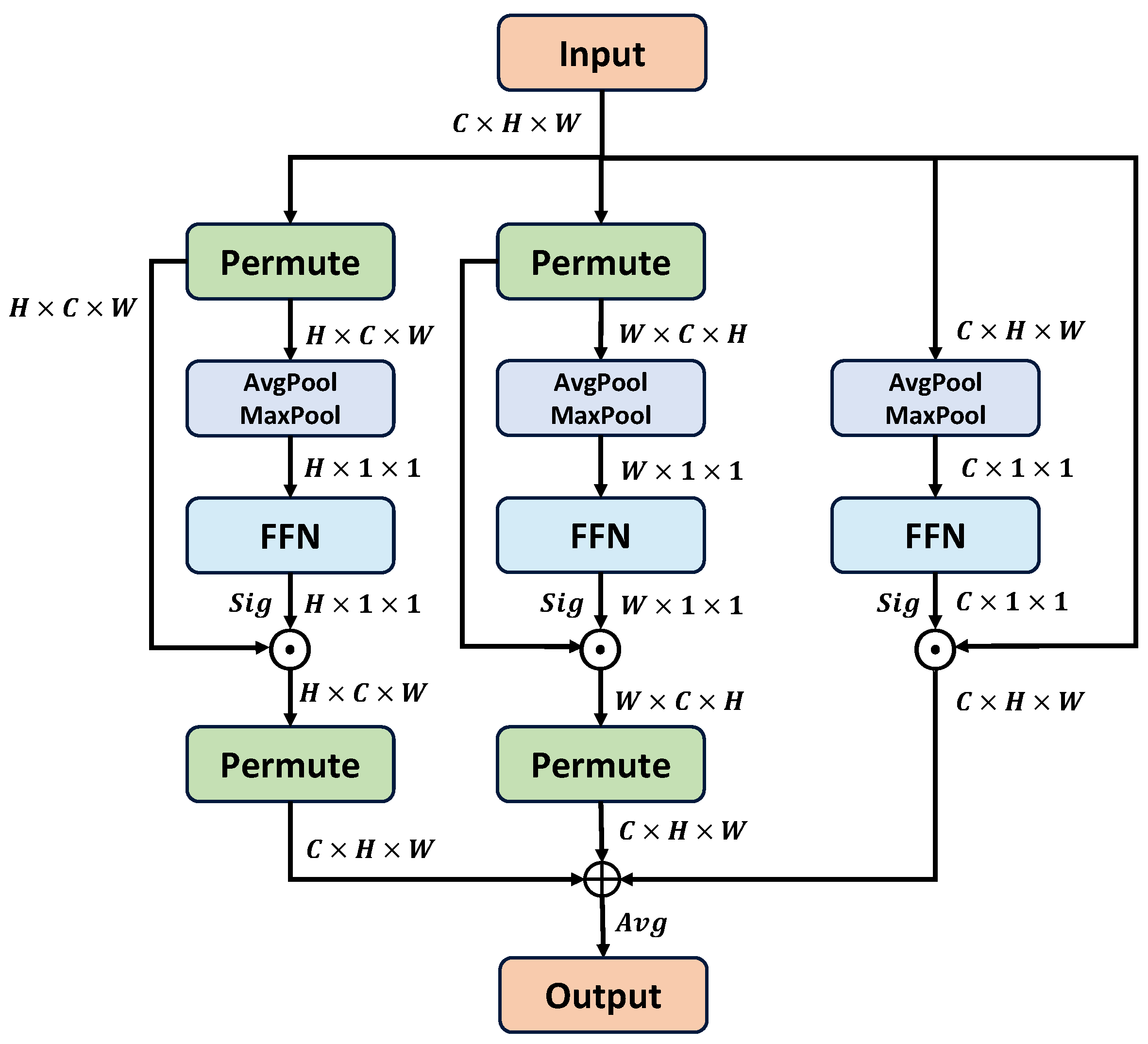
3.3.1. Multi-Dimensional Aggregation Attention
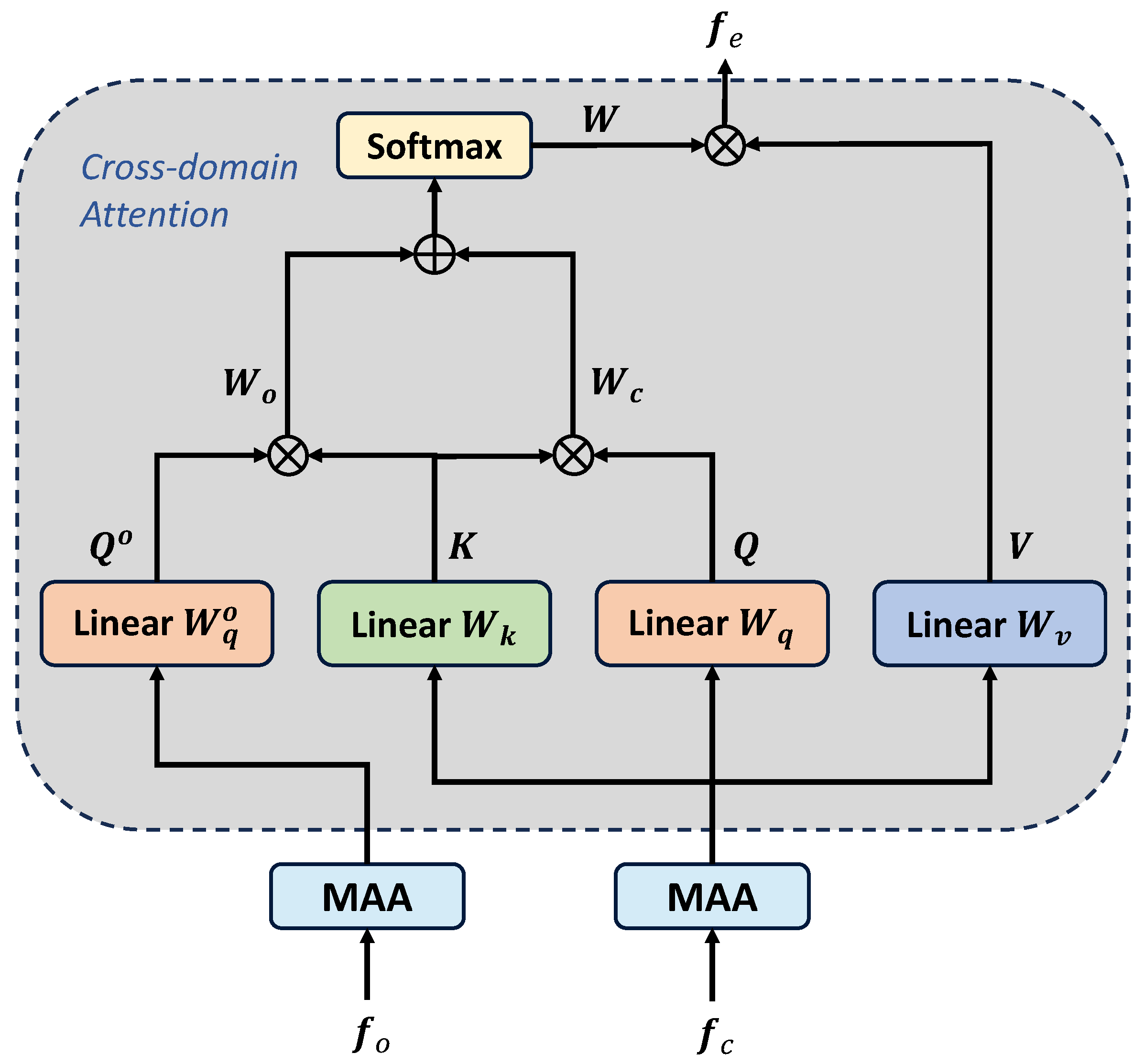
3.3.2. Cross-Domain Attention
4. Experimental Results
4.1. Datasets Description
4.1.1. DOTA
4.1.2. HRSC2016
4.2. Implementation Details and Evaluation Metrics
4.3. Main Results
4.3.1. Results for the DOTA Dataset
4.3.2. Results on the HRSC2016 Dataset
5. Discussion
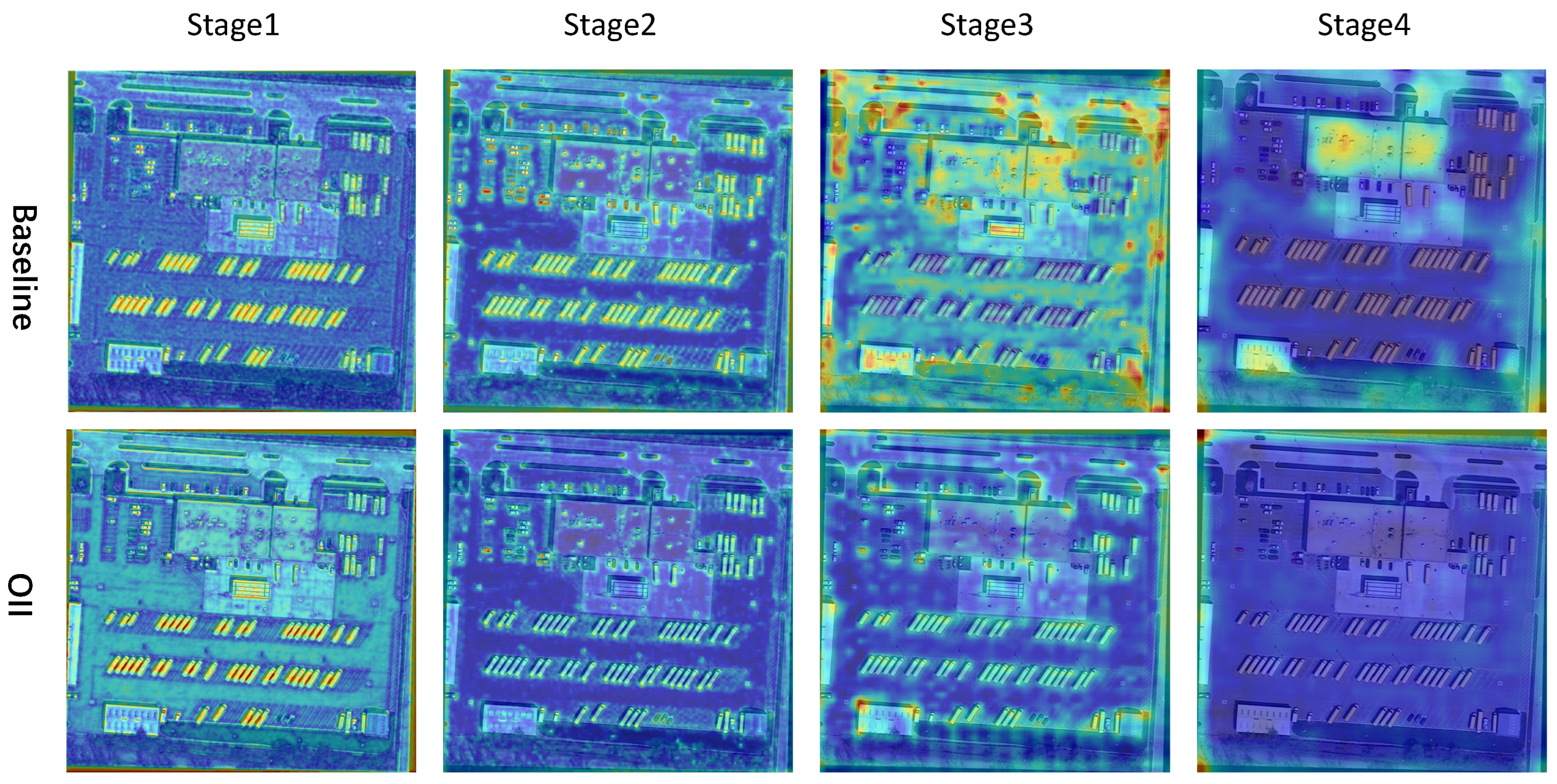
5.1. Analysis of OIH
5.2. Analysis of OFF
5.3. Effectiveness of OII
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| OII | Orientation information integrating |
| OIH | Orientation information highlighting |
| OFF | Orientation feature fusion |
| DWT | Discrete wavelet transform |
| DTCWT | Dual-tree complex wavelet transform |
| MAA | Multi-dimension aggregation attention |
| CA | Cross-domain attention |
| SA | Self-attention |
| DOTA | Dataset of object detection in aerial images |
| RPN | Region proposal networks |
| RCNN | Region convolutional neural network |
| RoI | Region of interest |
References
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning RoI transformer for oriented object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2849–2858. [Google Scholar]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2CNN: Rotational region CNN for orientation robust scene text detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic ship detection in remote sensing images from google earth of complex scenes based on multiscale rotation dense feature pyramid networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. Scrdet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 8232–8241. [Google Scholar]
- Qian, W.; Yang, X.; Peng, S.; Yan, J.; Guo, Y. Learning modulated loss for rotated object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 2458–2466. [Google Scholar]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.S.; Bai, X. Gliding vertex on the horizontal bounding box for multi-oriented object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 1452–1459. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J. Arbitrary-oriented object detection with circular smooth label. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VIII 16. Springer: Cham, Switzerland, 2020; pp. 677–694. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Zhang, Z.; Guo, W.; Zhu, S.; Yu, W. Toward arbitrary-oriented ship detection with rotated region proposal and discrimination networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1745–1749. [Google Scholar] [CrossRef]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3520–3529. [Google Scholar]
- Zhang, G.; Lu, S.; Zhang, W. CAD-Net: A context-aware detection network for objects in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10015–10024. [Google Scholar] [CrossRef]
- Wang, P.; Sun, X.; Diao, W.; Fu, K. FMSSD: Feature-merged single-shot detection for multiscale objects in large-scale remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3377–3390. [Google Scholar] [CrossRef]
- Ming, Q.; Miao, L.; Zhou, Z.; Dong, Y. CFC-Net: A critical feature capturing network for arbitrary-oriented object detection in remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5605814. [Google Scholar] [CrossRef]
- Fu, K.; Chang, Z.; Zhang, Y.; Xu, G.; Zhang, K.; Sun, X. Rotation-aware and multi-scale convolutional neural network for object detection in remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 161, 294–308. [Google Scholar] [CrossRef]
- Cheng, G.; Yao, Y.; Li, S.; Li, K.; Xie, X.; Wang, J.; Yao, X.; Han, J. Dual-aligned oriented detector. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5618111. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zheng, S.; Wu, Z.; Xu, Y.; Wei, Z.; Plaza, A. Learning orientation information from frequency-domain for oriented object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5628512. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Lee, H.; Kim, H.E.; Nam, H. Srm: A style-based recalibration module for convolutional neural networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1854–1862. [Google Scholar]
- Qilong Wang, B.W.; Pengfei Zhu, P.L.; Wangmeng Zuo, Q.H. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Wang, J.; Yang, W.; Li, H.C.; Zhang, H.; Xia, G.S. Learning center probability map for detecting objects in aerial images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4307–4323. [Google Scholar] [CrossRef]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Yang, J.; Liu, Q.; Zhang, K. Stacked hourglass network for robust facial landmark localisation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 79–87. [Google Scholar]
- Han, J.; Ding, J.; Li, J.; Xia, G.S. Align deep features for oriented object detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5602511. [Google Scholar] [CrossRef]
- He, T.; Tian, Z.; Huang, W.; Shen, C.; Qiao, Y.; Sun, C. An end-to-end textspotter with explicit alignment and attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5020–5029. [Google Scholar]
- Hou, L.; Lu, K.; Xue, J.; Hao, L. Cascade detector with feature fusion for arbitrary-oriented objects in remote sensing images. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Ming, Q.; Zhou, Z.; Miao, L.; Zhang, H.; Li, L. Dynamic anchor learning for arbitrary-oriented object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 2355–2363. [Google Scholar]
- Pan, X.; Ren, Y.; Sheng, K.; Dong, W.; Yuan, H.; Guo, X.; Ma, C.; Xu, C. Dynamic refinement network for oriented and densely packed object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11207–11216. [Google Scholar]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3det: Refined single-stage detector with feature refinement for rotating object. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 3163–3171. [Google Scholar]
- Yi, J.; Wu, P.; Liu, B.; Huang, Q.; Qu, H.; Metaxas, D. Oriented object detection in aerial images with box boundary-aware vectors. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 11–17 October 2021; pp. 2150–2159. [Google Scholar]
- Zhou, X.; Yao, C.; Wen, H.; Wang, Y.; Zhou, S.; He, W.; Liang, J. East: An efficient and accurate scene text detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5551–5560. [Google Scholar]
- Li, Z.; Hou, B.; Wu, Z.; Ren, B.; Yang, C. FCOSR: A simple anchor-free rotated detector for aerial object detection. Remote Sens. 2023, 15, 5499. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Cheng, G.; Wang, J.; Li, K.; Xie, X.; Lang, C.; Yao, Y.; Han, J. Anchor-free oriented proposal generator for object detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5625411. [Google Scholar] [CrossRef]
- Dai, L.; Liu, H.; Tang, H.; Wu, Z.; Song, P. Ao2-detr: Arbitrary-oriented object detection transformer. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 2342–2356. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J.; Ming, Q.; Wang, W.; Zhang, X.; Tian, Q. Rethinking rotated object detection with gaussian wasserstein distance loss. In Proceedings of the International Conference on Machine Learning (PMLR), Virtual, 18–24 July 2021; pp. 11830–11841. [Google Scholar]
- Hou, L.; Lu, K.; Yang, X.; Li, Y.; Xue, J. G-rep: Gaussian representation for arbitrary-oriented object detection. Remote Sens. 2023, 15, 757. [Google Scholar] [CrossRef]
- Xu, C.; Ding, J.; Wang, J.; Yang, W.; Yu, H.; Yu, L.; Xia, G.S. Dynamic Coarse-to-Fine Learning for Oriented Tiny Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7318–7328. [Google Scholar]
- Yu, Y.; Da, F. Phase-shifting coder: Predicting accurate orientation in oriented object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 13354–13363. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Vedaldi, A. Gather-excite: Exploiting feature context in convolutional neural networks. Adv. Neural Inf. Process. Syst. 2018, 31, 1–11. [Google Scholar]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic convolution: Attention over convolution kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11030–11039. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Yang, B.; Bender, G.; Le, Q.V.; Ngiam, J. Condconv: Conditionally parameterized convolutions for efficient inference. Adv. Neural Inf. Process. Syst. 2019, 32, 1–12. [Google Scholar]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Wang, C.; Feng, J. Improving convolutional networks with self-calibrated convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10096–10105. [Google Scholar]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.M.; Yang, J.; Li, X. Large Selective Kernel Network for Remote Sensing Object Detection. arXiv 2023, arXiv:2303.09030. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the ICLR 2021, Virtual, 3–7 May 2021. [Google Scholar]
- Yu, H.; Tian, Y.; Ye, Q.; Liu, Y. Spatial Transform Decoupling for Oriented Object Detection. arXiv 2023, arXiv:2308.10561. [Google Scholar]
- Ehrlich, M.; Davis, L.S. Deep residual learning in the jpeg transform domain. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 3484–3493. [Google Scholar]
- Wu, X.; Hong, D.; Tian, J.; Chanussot, J.; Li, W.; Tao, R. ORSIm detector: A novel object detection framework in optical remote sensing imagery using spatial-frequency channel features. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5146–5158. [Google Scholar] [CrossRef]
- Rao, Y.; Zhao, W.; Zhu, Z.; Lu, J.; Zhou, J. Global filter networks for image classification. Adv. Neural Inf. Process. Syst. 2021, 34, 980–993. [Google Scholar]
- Chakraborty, T.; Trehan, U. Spectralnet: Exploring spatial-spectral waveletcnn for hyperspectral image classification. arXiv 2021, arXiv:2104.00341. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Ngo, C.W.; Mei, T. Wave-vit: Unifying wavelet and transformers for visual representation learning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 328–345. [Google Scholar]
- Nguyen, T.; Pham, M.; Nguyen, T.; Nguyen, K.; Osher, S.; Ho, N. Fourierformer: Transformer meets generalized fourier integral theorem. Adv. Neural Inf. Process. Syst. 2022, 35, 29319–29335. [Google Scholar]
- Patro, B.N.; Namboodiri, V.P.; Agneeswaran, V.S. SpectFormer: Frequency and Attention is what you need in a Vision Transformer. arXiv 2023, arXiv:2304.06446. [Google Scholar]
- Selesnick, I.W.; Baraniuk, R.G.; Kingsbury, N.C. The dual-tree complex wavelet transform. IEEE Signal Process. Mag. 2005, 22, 123–151. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Liu, Z.; Wang, H.; Weng, L.; Yang, Y. Ship rotated bounding box space for ship extraction from high-resolution optical satellite images with complex backgrounds. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1074–1078. [Google Scholar] [CrossRef]
- Zhou, Y.; Yang, X.; Zhang, G.; Wang, J.; Liu, Y.; Hou, L.; Jiang, X.; Liu, X.; Yan, J.; Lyu, C.; et al. MMRotate: A Rotated Object Detection Benchmark using PyTorch. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10 October 2022. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Azimi, S.M.; Vig, E.; Bahmanyar, R.; Körner, M.; Reinartz, P. Towards multi-class object detection in unconstrained remote sensing imagery. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Springer: Cham, Switzerland, 2018; pp. 150–165. [Google Scholar]
- Li, C.; Xu, C.; Cui, Z.; Wang, D.; Zhang, T.; Yang, J. Feature-attentioned object detection in remote sensing imagery. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3886–3890. [Google Scholar]
- Han, J.; Ding, J.; Xue, N.; Xia, G.S. Redet: A rotation-equivariant detector for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2786–2795. [Google Scholar]
- Li, C.; Xu, C.; Cui, Z.; Wang, D.; Jie, Z.; Zhang, T.; Yang, J. Learning object-wise semantic representation for detection in remote sensing imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019; pp. 20–27. [Google Scholar]
- Liang, D.; Geng, Q.; Wei, Z.; Vorontsov, D.A.; Kim, E.L.; Wei, M.; Zhou, H. Anchor retouching via model interaction for robust object detection in aerial images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5619213. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Lyu, C.; Zhang, W.; Huang, H.; Zhou, Y.; Wang, Y.; Liu, Y.; Zhang, S.; Chen, K. Rtmdet: An empirical study of designing real-time object detectors. arXiv 2022, arXiv:2212.07784. [Google Scholar]
- Chen, Z.; Chen, K.; Lin, W.; See, J.; Yu, H.; Ke, Y.; Yang, C. Piou loss: Towards accurate oriented object detection in complex environments. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VIII 16. Springer: Cham, Switzerland, 2020; pp. 195–211. [Google Scholar]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. Reppoints: Point set representation for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 9657–9666. [Google Scholar]
- Li, W.; Chen, Y.; Hu, K.; Zhu, J. Oriented reppoints for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1829–1838. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Input Size | Batch Size | Learning Rate | Momentum | Weight Decay | NMS Thres | Epoch |
|---|---|---|---|---|---|---|---|
| DOTA | 1024 × 1024 | 2 | 0.05 | 0.9 | 0.0001 | 0.1 | 12 |
| HRSC2016 | 800 × 800 | 2 | 0.005 | 0.9 | 0.0001 | 0.1 | 36 |
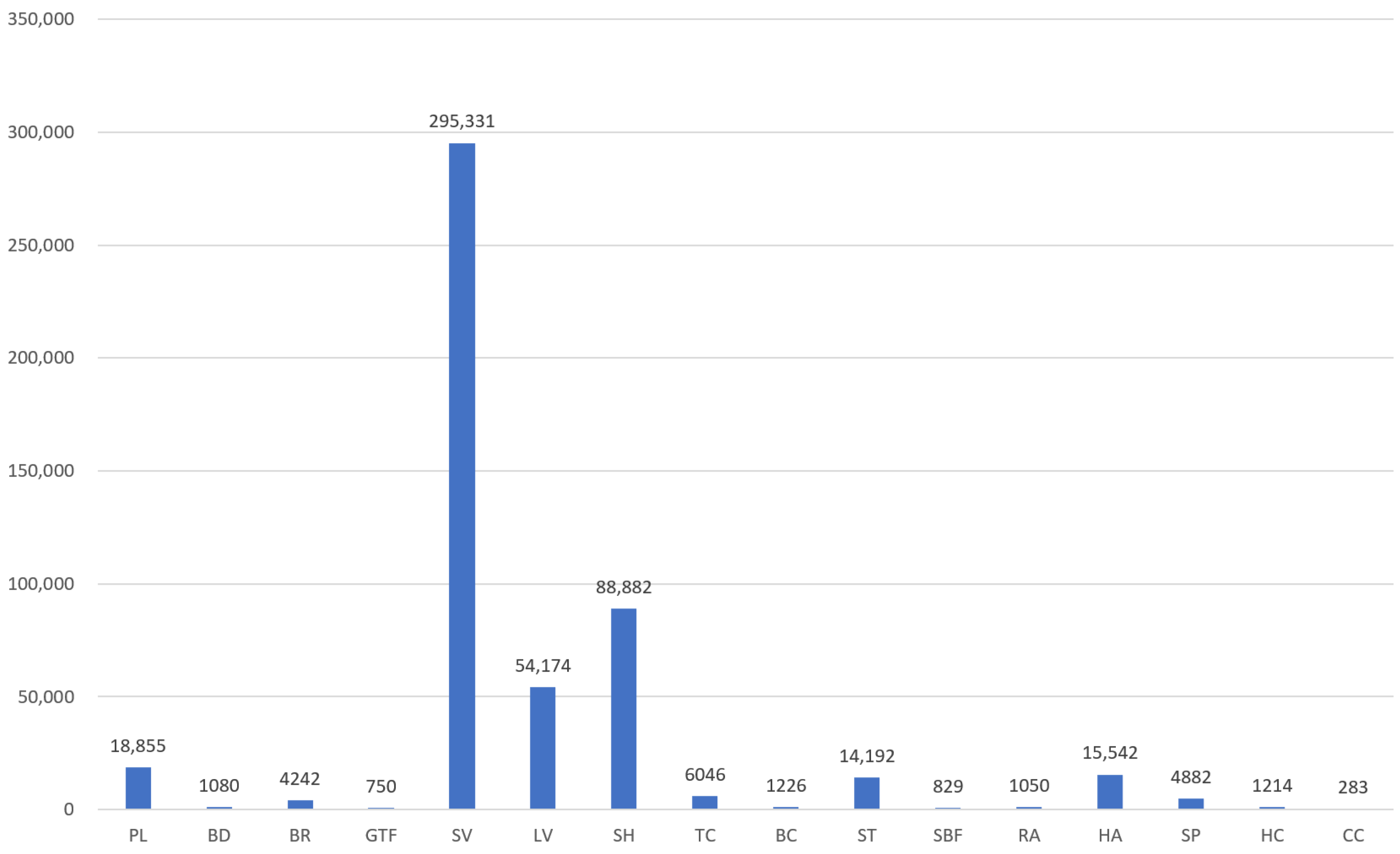
| Method | Backbone | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Single-scale | |||||||||||||||||
| FR-O [61] | R-101 | 79.42 | 77.13 | 17.70 | 64.05 | 35.30 | 38.02 | 37.16 | 89.41 | 69.64 | 59.28 | 50.30 | 52.91 | 47.89 | 47.40 | 46.30 | 54.13 |
| ICN [65] | R-101 | 81.36 | 74.30 | 47.70 | 70.32 | 64.89 | 67.82 | 69.98 | 90.76 | 79.06 | 78.20 | 53.64 | 62.90 | 67.02 | 64.17 | 50.23 | 68.16 |
| CADNet [11] | R-101 | 87.80 | 82.40 | 49.40 | 73.50 | 71.10 | 63.50 | 76.60 | 90.90 | 79.20 | 73.30 | 48.40 | 60.90 | 62.00 | 67.00 | 62.20 | 69.90 |
| Rol Transformer [1] | R-101 | 88.64 | 78.52 | 43.44 | 75.92 | 68.81 | 73.68 | 83.59 | 90.74 | 77.27 | 81.46 | 58.39 | 53.54 | 62.83 | 58.93 | 47.67 | 69.56 |
| DRN [31] | H-104 | 88.91 | 80.22 | 43.52 | 63.35 | 73.48 | 70.69 | 84.94 | 90.14 | 83.85 | 84.11 | 50.12 | 58.41 | 67.62 | 68.60 | 52.50 | 70.70 |
| CenterMap [23] | R-50 | 88.88 | 81.24 | 53.15 | 60.65 | 78.62 | 66.55 | 78.10 | 88.83 | 77.80 | 83.61 | 49.36 | 66.19 | 72.10 | 72.36 | 58.70 | 71.74 |
| SCRDet [4] | R-101 | 89.98 | 80.65 | 52.09 | 68.36 | 68.36 | 60.32 | 72.41 | 90.85 | 87.94 | 86.86 | 65.02 | 66.68 | 66.25 | 68.24 | 65.21 | 72.61 |
| FAOD [66] | R-101 | 90.21 | 79.58 | 45.49 | 76.41 | 73.18 | 68.27 | 79.56 | 90.83 | 83.40 | 84.68 | 53.40 | 65.42 | 74.17 | 69.69 | 64.86 | 73.28 |
| R3Det [32] | R-152 | 89.49 | 81.17 | 50.53 | 66.10 | 70.92 | 78.66 | 78.21 | 90.81 | 85.26 | 84.23 | 61.81 | 63.77 | 68.16 | 69.83 | 67.17 | 73.74 |
| S2A-Net [27] | R-50 | 89.11 | 82.84 | 48.37 | 71.11 | 78.11 | 78.39 | 87.25 | 90.83 | 84.90 | 85.64 | 60.36 | 62.60 | 65.26 | 69.13 | 57.94 | 74.12 |
| Oriented R-CNN [10] | R-50 | 88.79 | 82.18 | 52.64 | 72.14 | 78.75 | 82.35 | 87.68 | 90.76 | 85.35 | 84.68 | 61.44 | 64.99 | 67.40 | 69.19 | 57.01 | 75.00 |
| Oriented R-CNN [10] | R-101 | 89.08 | 81.38 | 54.06 | 72.71 | 78.62 | 82.28 | 87.72 | 90.80 | 85.68 | 83.86 | 62.63 | 69.00 | 74.81 | 70.32 | 54.08 | 75.80 |
| ReDet [67] | ReR-50 | 88.79 | 82.64 | 53.97 | 74.00 | 78.13 | 84.06 | 88.04 | 90.89 | 87.78 | 85.75 | 61.76 | 60.39 | 75.96 | 68.07 | 63.59 | 76.25 |
| OII (ours) | R-101 | 89.67 | 83.48 | 54.36 | 76.20 | 78.71 | 83.48 | 88.35 | 90.90 | 87.97 | 86.89 | 63.70 | 66.82 | 75.93 | 68.61 | 59.59 | 76.98 |
| Multi-scale | |||||||||||||||||
| FR-O [61] | R-101 | 88.44 | 73.06 | 44.86 | 59.09 | 73.25 | 71.49 | 77.11 | 90.84 | 78.94 | 83.90 | 48.59 | 62.95 | 62.18 | 64.91 | 56.18 | 69.05 |
| Rol Transformer [1] | R-101 | 88.64 | 78.52 | 43.44 | 75.92 | 68.81 | 73.68 | 83.59 | 90.74 | 77.27 | 81.46 | 58.39 | 53.54 | 62.83 | 58.93 | 47.67 | 69.56 |
| DRN [31] | H-104 | 89.71 | 82.34 | 47.22 | 64.10 | 76.22 | 74.43 | 85.84 | 90.57 | 86.18 | 84.89 | 57.65 | 61.93 | 69.30 | 69.63 | 58.48 | 73.23 |
| FAOD [66] | R-101 | 90.21 | 79.58 | 45.49 | 76.41 | 73.18 | 68.27 | 79.56 | 90.83 | 83.40 | 84.68 | 53.40 | 65.42 | 74.17 | 69.69 | 64.86 | 73.28 |
| Gliding Vertex [6] | R-101 | 89.64 | 85.00 | 52.26 | 77.34 | 73.01 | 73.14 | 86.82 | 90.74 | 79.02 | 86.81 | 59.55 | 70.91 | 72.94 | 70.86 | 57.32 | 75.02 |
| CenterMap [23] | R-101 | 89.83 | 84.41 | 54.60 | 70.25 | 77.66 | 78.32 | 87.19 | 90.66 | 84.89 | 85.27 | 56.46 | 69.23 | 74.13 | 71.56 | 66.06 | 76.03 |
| OWSR [68] | R-101 | 90.41 | 85.21 | 55.00 | 78.27 | 76.19 | 72.19 | 82.14 | 90.70 | 87.22 | 86.87 | 66.62 | 68.43 | 75.43 | 72.70 | 57.99 | 76.36 |
| S2A-Net [27] | R-50 | 88.89 | 83.60 | 57.74 | 81.95 | 79.94 | 83.19 | 89.11 | 90.78 | 84.87 | 87.81 | 70.30 | 68.25 | 78.30 | 77.01 | 69.58 | 79.42 |
| ReDet [67] | ReR-50 | 88.81 | 82.48 | 60.83 | 80.82 | 78.34 | 86.06 | 88.31 | 90.87 | 88.77 | 87.03 | 68.65 | 66.90 | 79.26 | 79.71 | 74.67 | 80.10 |
| GWD [39] | R-152 | 89.66 | 84.99 | 59.26 | 82.19 | 78.97 | 84.83 | 87.70 | 90.21 | 86.54 | 86.85 | 73.47 | 67.77 | 76.92 | 79.22 | 74.92 | 80.23 |
| EDA [69] | ReR-50 | 89.92 | 83.84 | 59.65 | 79.88 | 80.11 | 87.96 | 88.17 | 90.31 | 88.93 | 88.46 | 68.93 | 65.94 | 78.04 | 79.69 | 75.78 | 80.37 |
| FDOL [17] | ReR-50 | 88.90 | 84.57 | 60.73 | 80.83 | 78.42 | 85.82 | 88.33 | 90.90 | 88.28 | 86.93 | 71.44 | 67.13 | 79.00 | 80.35 | 74.59 | 80.41 |
| Oriented R-CNN [10] | R-101 | 90.26 | 84.74 | 62.01 | 80.42 | 79.04 | 85.07 | 88.52 | 90.85 | 87.24 | 87.96 | 72.26 | 70.03 | 82.93 | 78.46 | 68.05 | 80.52 |
| OII (ours) | R-101 | 89.52 | 84.97 | 61.71 | 81.11 | 79.63 | 85.59 | 88.67 | 90.88 | 86.82 | 87.94 | 72.27 | 70.06 | 82.58 | 78.14 | 72.42 | 80.82 |
| Method | Backbone | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | CC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Single-scale | ||||||||||||||||||
| RetainaNet-O [36] | R-50 | 71.43 | 77.64 | 42.12 | 64.65 | 44.53 | 56.79 | 73.31 | 90.84 | 76.02 | 59.96 | 46.95 | 69.24 | 59.65 | 64.52 | 48.06 | 0.83 | 59.16 |
| FR-O [61] | R-101 | 71.89 | 74.47 | 44.45 | 59.87 | 51.28 | 69.98 | 79.37 | 90.78 | 77.38 | 67.50 | 47.75 | 69.72 | 61.22 | 65.28 | 60.47 | 1.54 | 62.00 |
| Mask R-CNN [70] | R-101 | 76.84 | 73.51 | 49.90 | 57.80 | 51.31 | 71.34 | 79.75 | 90.46 | 74.21 | 66.07 | 46.21 | 70.61 | 63.07 | 64.46 | 57.81 | 9.42 | 62.67 |
| ReDet [67] | ReR-50 | 79.20 | 82.81 | 51.92 | 71.41 | 52.38 | 75.73 | 80.92 | 90.83 | 75.81 | 68.64 | 49.29 | 72.03 | 73.36 | 70.55 | 63.33 | 11.53 | 66.86 |
| OII (ours) | R-101 | 77.79 | 82.03 | 49.45 | 71.37 | 59.33 | 80.30 | 85.39 | 90.88 | 80.73 | 70.26 | 51.81 | 71.59 | 75.81 | 72.19 | 54.36 | 15.01 | 68.02 |
| Multi-scale | ||||||||||||||||||
| FDOL [17] | ReR-50 | 88.41 | 86.30 | 61.25 | 82.30 | 68.00 | 84.12 | 89.95 | 90.83 | 84.31 | 76.81 | 70.74 | 73.24 | 78.72 | 73.15 | 75.54 | 16.23 | 75.62 |
| OWSR [68] | R-101 | 88.19 | 86.41 | 59.35 | 80.23 | 68.10 | 75.62 | 87.21 | 90.12 | 85.32 | 84.04 | 73.82 | 77.45 | 76.43 | 73.71 | 69.48 | 49.66 | 76.57 |
| RTMDet-R-m [71] | CSPNeXt | 89.07 | 86.71 | 52.57 | 82.47 | 66.13 | 82.55 | 89.77 | 90.88 | 84.39 | 83.34 | 69.51 | 73.03 | 77.82 | 75.98 | 80.21 | 42.00 | 76.65 |
| ReDet [67] | ReR-50 | 88.51 | 86.45 | 61.23 | 81.20 | 67.60 | 83.65 | 90.00 | 90.86 | 84.30 | 75.33 | 71.49 | 72.06 | 78.32 | 74.73 | 76.10 | 46.98 | 76.80 |
| RTMDet-R-l [71] | CSPNeXt | 89.31 | 86.38 | 55.09 | 83.17 | 66.11 | 82.44 | 89.85 | 90.84 | 86.95 | 83.76 | 68.35 | 74.36 | 77.60 | 77.39 | 77.87 | 60.37 | 78.12 |
| OII (ours) | R-101 | 87.52 | 86.22 | 61.09 | 81.19 | 67.31 | 81.47 | 88.87 | 90.48 | 85.93 | 84.65 | 69.53 | 73.26 | 75.93 | 76.98 | 79.73 | 50.48 | 77.55 |
| Method | Backbone | Pretrained | mAP(07) | mAP(12) |
|---|---|---|---|---|
| RetinaNet-O [36] | R-50 | IN | 73.42 | 77.83 |
| DRN [31] | H-34 | IN | - | 92.70 |
| CenterMap [23] | R-50 | IN | - | 92.80 |
| RoI Transformer [1] | R-101 | IN | 86.20 | - |
| Gliding Vertex [6] | R-101 | IN | 88.20 | - |
| PIoU [72] | DLA-34 | - | 89.20 | - |
| R3Det [32] | R-101 | IN | 89.26 | 96.01 |
| DAL [30] | R-101 | IN | 89.77 | - |
| GWD [39] | R-50 | IN | 89.85 | 97.37 |
| S2ANet [27] | R-101 | IN | 90.17 | 95.01 |
| AOPG [37] | R-50 | IN | 90.34 | 96.22 |
| Oriented R-CNN [10] | R-50 | IN | 90.40 | 96.50 |
| ReDet [67] | ReR-50 | IN | 90.46 | 97.63 |
| Oriented R-CNN [10] | R-101 | IN | 90.50 | 97.60 |
| RTMDet-R [71] | CSPNeXt | COCO | 90.60 | 97.10 |
| OII (ours) | R-101 | IN | 90.63 | 98.23 |
| Method | Image Approx | Stage Features | mAP |
|---|---|---|---|
| DWT | ✓ | 75.54 | |
| DWT | ✓ | 75.37 | |
| DTCWT | ✓ | 75.84 | |
| DTCWT | ✓ | 76.26 |
| Method | Image Approx | Stage Features | mAP(07) | mAP(12) |
|---|---|---|---|---|
| DWT | ✓ | 89.61 | 95.10 | |
| DWT | ✓ | 90.23 | 95.87 | |
| DTCWT | ✓ | 90.42 | 96.45 | |
| DTCWT | ✓ | 90.57 | 97.50 |
| Num | Params (M) | FLOPs (G) | mAP |
|---|---|---|---|
| 0 | 52.30 | 259.90 | 75.43 |
| 1 | 53.97 | 264.43 | 75.72 |
| 2 | 55.65 | 268.96 | 76.04 |
| 3 | 57.33 | 273.49 | 76.26 |
| 4 | 59.01 | 278.02 | 76.24 |
| 5 | 60.69 | 282.55 | 76.13 |
| Attention Method | Params (M) | FLOPs (G) | mAP |
|---|---|---|---|
| None | 57.32 | 273.44 | 75.79 |
| Channel Attention | 57.32 | 273.44 | 75.88 |
| Spatial Attention | 57.32 | 273.44 | 75.82 |
| Channel Attention + Spatia Attention | 57.32 | 273.46 | 75.94 |
| Channel Attention & Spatial Attention | 57.32 | 273.46 | 75.96 |
| CBAM [18] | 57.32 | 273.46 | 76.05 |
| SRM [19] | 57.32 | 273.44 | 76.18 |
| ECA [20] | 57.32 | 273.44 | 76.23 |
| MAA (ours) | 57.33 | 273.49 | 76.26 |
| Methods | Backbone | mAP(07) | mAP(12) |
|---|---|---|---|
| None | R-50 | 90.31 | 96.24 |
| SA | R-50 | 90.44 | 96.53 |
| CA | R-50 | 90.57 | 97.50 |
| Method | Param (M) | FLOPs (G) | FPS |
|---|---|---|---|
| One-Stage | |||
| Rotated-RepPoints [73] | 36.82 | 184.18 | 46.62 |
| R3Det [32] | 42.12 | 335.32 | 32.32 |
| OrientedRepPoints [74] | 36.61 | 194.32 | 46.79 |
| Two-Stage | |||
| Gliding Vertex [6] | 41.47 | 225.22 | 26.35 |
| Rotated Faster RCNN [21] | 41.73 | 224.95 | 25.91 |
| Oriented RCNN [10] | 41.42 | 225.35 | 20.33 |
| OII (ours) | 57.33 | 273.49 | 20.48 |
| Method | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| One-Stage | ||||||||||||||||
| Rotated-RepPoints [73] | 83.42 | 65.36 | 36.25 | 51.05 | 71.25 | 51.84 | 72.47 | 90.52 | 70.16 | 81.99 | 47.84 | 58.91 | 50.68 | 55.53 | 2.60 | 59.33 |
| Rotated-RepPoints + OII | 85.64 | 67.63 | 37.46 | 51.66 | 72.70 | 52.14 | 72.04 | 91.29 | 70.19 | 80.16 | 48.86 | 58.32 | 51.11 | 56.76 | 3.76 | 60.22 (+0.89) |
| R3Det [32] | 89.02 | 75.65 | 47.33 | 72.03 | 74.58 | 73.71 | 82.76 | 90.82 | 80.12 | 81.32 | 59.45 | 62.87 | 60.79 | 65.21 | 32.59 | 69.82 |
| R3Det + OII | 89.30 | 76.00 | 44.00 | 69.03 | 77.68 | 74.48 | 85.49 | 90.84 | 79.69 | 84.28 | 55.71 | 63.31 | 63.52 | 66.21 | 36.61 | 70.41 (+0.59) |
| OrientedRepPoints [74] | 87.75 | 77.92 | 49.59 | 66.72 | 78.47 | 73.13 | 86.58 | 90.87 | 83.85 | 84.34 | 53.06 | 65.54 | 63.73 | 68.70 | 45.91 | 71.74 |
| OrientedRepPoints + OII | 87.94 | 77.87 | 51.68 | 71.26 | 78.39 | 76.81 | 86.91 | 90.87 | 83.20 | 83.12 | 50.41 | 65.16 | 65.02 | 68.97 | 44.74 | 72.14 (+0.40) |
| Two-Stage | ||||||||||||||||
| Gliding Vertex [6] | 83.27 | 77.41 | 46.55 | 64.17 | 74.66 | 71.25 | 83.90 | 85.24 | 83.11 | 84.55 | 47.32 | 65.14 | 61.59 | 63.81 | 54.19 | 69.74 |
| Gliding Vertex + OII | 84.26 | 79.89 | 48.02 | 64.83 | 75.88 | 71.24 | 83.31 | 84.76 | 82.91 | 84.59 | 50.69 | 62.99 | 60.27 | 66.71 | 53.94 | 70.29 (+0.55) |
| Rotated Faster RCNN [21] | 88.99 | 82.05 | 50.01 | 69.94 | 77.97 | 74.08 | 86.08 | 90.81 | 83.26 | 85.57 | 57.59 | 61.17 | 66.44 | 69.35 | 57.79 | 73.41 |
| Rotated Faster RCNN + OII | 89.43 | 80.97 | 51.56 | 68.78 | 78.46 | 74.43 | 86.40 | 90.86 | 86.29 | 85.26 | 57.58 | 63.73 | 66.58 | 67.25 | 58.21 | 73.85 (+0.44) |
| Oriented R-CNN [10] | 88.79 | 82.18 | 52.64 | 72.14 | 78.75 | 82.35 | 87.68 | 90.76 | 85.35 | 84.68 | 61.44 | 64.99 | 67.40 | 69.19 | 57.01 | 75.00 |
| Oriented R-CNN + OII | 89.29 | 82.50 | 55.19 | 71.43 | 78.69 | 82.61 | 88.17 | 90.83 | 86.58 | 85.04 | 63.38 | 61.13 | 73.39 | 65.09 | 64.27 | 75.84 (+0.84) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Jiang, W. OII: An Orientation Information Integrating Network for Oriented Object Detection in Remote Sensing Images. Remote Sens. 2024, 16, 731. https://doi.org/10.3390/rs16050731
Liu Y, Jiang W. OII: An Orientation Information Integrating Network for Oriented Object Detection in Remote Sensing Images. Remote Sensing. 2024; 16(5):731. https://doi.org/10.3390/rs16050731
Chicago/Turabian StyleLiu, Yangfeixiao, and Wanshou Jiang. 2024. "OII: An Orientation Information Integrating Network for Oriented Object Detection in Remote Sensing Images" Remote Sensing 16, no. 5: 731. https://doi.org/10.3390/rs16050731
APA StyleLiu, Y., & Jiang, W. (2024). OII: An Orientation Information Integrating Network for Oriented Object Detection in Remote Sensing Images. Remote Sensing, 16(5), 731. https://doi.org/10.3390/rs16050731