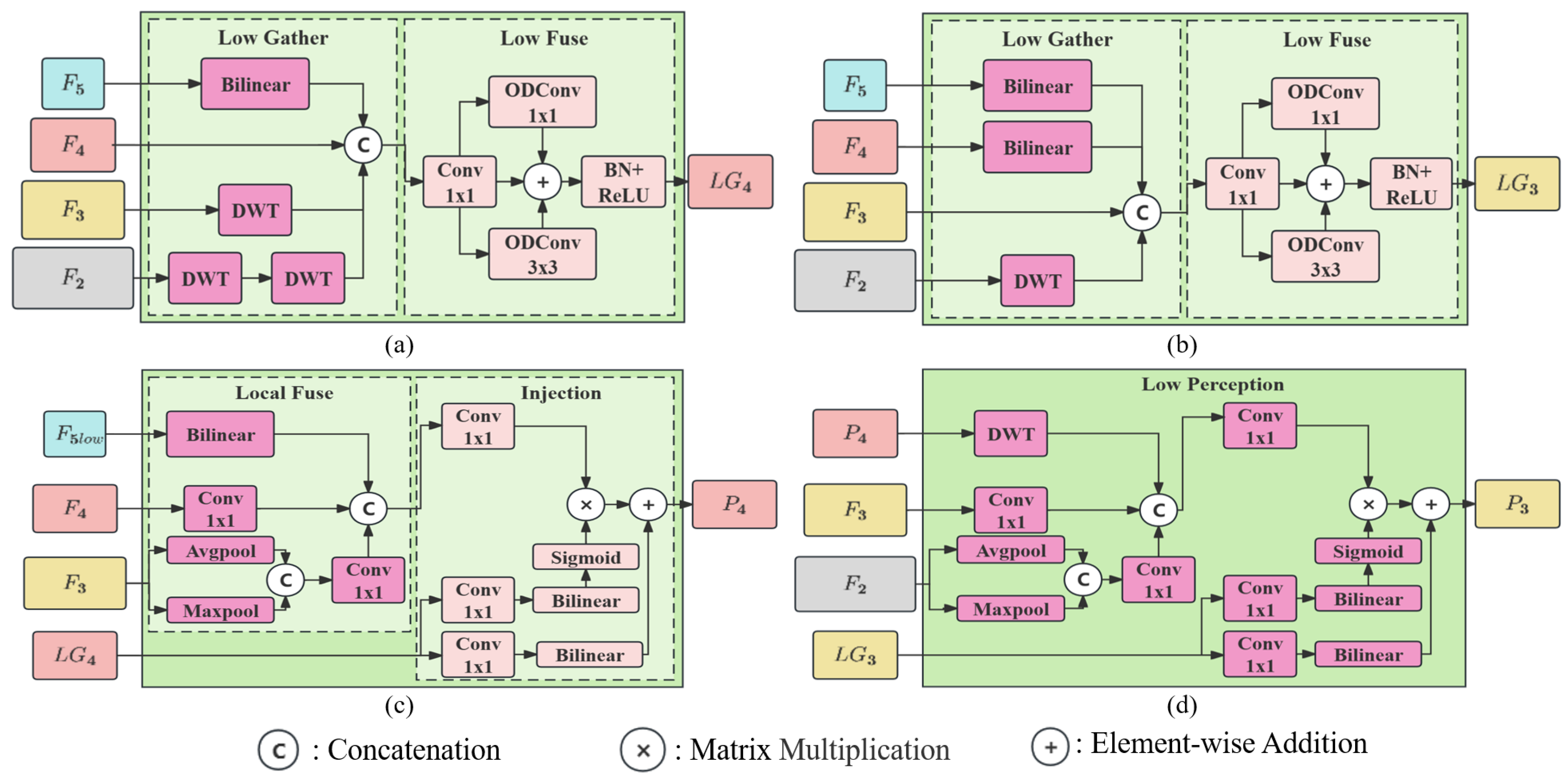
The GIP module consists of three key processes: gather, injection, and perception. In the gather stage, the goal is to collect comprehensive information from both lower and higher levels. This involves aligning multiple input feature maps to the same scale and concatenating them along the channel dimension in both Low Gather and High Gather steps. The subsequent Low Fuse and High Fuse stages merge images from various channels to create the global information. The injection process enhances the traditional interaction in FPN by fusing global information with feature maps at different levels. The perception stage focuses on adding extra global information to offset loss incurred during indirect propagation. The inputs include feature maps , , , , extracted from the five-stage backbone network, where each belongs to . Here, B represents the batch size, C signifies the channels, and R, denoting dimensions, is calculated as H × W. The dimensions of , , , , and are , , , , and , respectively.
2.2.1. Low Stage Branch
Based on the configuration of input feature maps in [
30], this branch only uses
,
,
, and
generated by the backbone as inputs to gather detailed information about the target object at lower levels, as shown in
Figure 3.
Low Gather Module. This module employs intermediate feature map sizes of
and
to generate global information
and
, respectively, as illustrated in
Figure 3a,b. A significant difference from Gold-YOLO [
30] is the use of the Discrete Wavelet Transform (DWT) for processing downscaled feature maps larger than
and
. Traditional downsampling through pooling can result in the loss of high-frequency information [
31]. In contrast, wavelet transform, a mathematical method for signal decomposition, separates signals into various frequency components represented by wavelet coefficients in images [
32,
33]. An example is Haar filtering, which performs convolution-like operations using four filters: a low-pass filter
and three high-pass filters
,
, and
. Notably, these filters utilize a stride of 2 for downsampling. The Haar filter definition is detailed further below.
These four filters are orthogonal and create a reversible matrix. The Discrete Wavelet Transform (DWT) functions in the following manner: , , , .
Here,
x symbolizes the input two-dimensional image matrix. The symbol ⊗ represents the convolution operation, and ↓2 signifies standard downsampling by a factor of 2. Essentially, the DWT involves four predetermined convolution filters, each with a stride of 2, to execute the downsampling process. As per Haar transform theory, the values of
,
,
, and
at a given position (i, j) after undergoing a two-dimensional Haar transform are defined by the subsequent formulas.
The terms
,
,
, and
correspond to four downsampled images. They retain various frequency information:
for low-frequency details in both horizontal and vertical directions;
for high-frequency in horizontal and low-frequency in vertical;
for low-frequency in horizontal and high-frequency in vertical; and
for high-frequency information in both directions. The Discrete Wavelet Transform (DWT) incorporates a downsampling phase, yet thanks to the orthogonality of its filters, it allows for the original image to be losslessly reconstructed from these components. The mathematical representation of this process is detailed below.
This suggests that using
,
,
and
, one can infer the pixel values at any location in the two-dimensional image matrix
x. As a result, applying DWT makes it feasible to adjust the dimensions of
to align with those of
and
, and similarly for
with
. Nevertheless, the wavelet transform’s effective information preservation incurs an increase in channel dimensions. Following a single wavelet transform, the height and width of images are reduced by half, while the channel count quadruples from
C to
, leading to higher computational demands. To address this, in the initial stage,
, derived from the wavelet transform, is chosen for subsequent multi-level DWT iterations to match
’s size, as depicted in
Figure 3a.
For aligning feature maps of smaller scales, such as adjusting
to match
’s scale and then aligning both
and
with
, bilinear interpolation is utilized. The aligned feature maps are then concatenated, as depicted in
Figure 3a,b.
Low Fuse Module. This module represents a departure from the approach used in Gold-YOLO [
30]. Instead of traditional methods,
and
multidimensional attention dynamic convolutions, termed ODConv, are implemented on the RepVGG architectural foundation [
34,
35]. These replace the original convolutions. ODConv enables the learning of specific attentions in various dimensions: spatial, input channel, output channel, and convolution kernel quantity. ODConv is detailed in Equation (
4).
The Low Fuse Module encompasses several attention mechanisms on different dimensions of the convolutional kernel. Attention is allocated as follows: for the convolution weight dimension, for the input image channel, for the output image channel, and for the image’s spatial dimension. Element-wise product, denoted by ⊙, is utilized across various kernel space dimensions. And x means input images matrix. Detailed discussion of attention calculation is deferred to subsequent sections. This design enhances the convolution operation’s ability to extract comprehensive contextual information from multiple dimensions.
The module computes results through three distinct pathways:
and
dynamic convolution, and direct input matrix processing. Post-computation, batch normalization, element-wise addition, and ReLU activation are performed, as illustrated in
Figure 3a,b. This process generates low global information, expressed as
based on
and
based on
.
Low Injection Module. This module leverages low-frequency images,
, derived from DWT processing. In these images,
and
serve as inputs for feature information learning, as depicted in
Figure 3c. The process involves downsampling of
, targeting the output size of
. To avoid the overuse of deep recursive layers in DWT, adaptive max pooling is incorporated. This step is followed by a channel-wise concatenation to preserve critical information during downsampling. The smaller feature map of
is resized to align with
’s dimensions using bilinear interpolation and then concatenated along the channel dimension. A
convolution is subsequently employed to modify the output channel, producing the targeted low-level local information. The final step integrates the global information
with the local fusion information using a
convolution and a Sigmoid activation function, culminating in
.
Low Perception Module. The Low Stage features interactions among four feature maps. However, in fusing
and
, there is an indirect and insufficient capture of information from
. This shortfall persists despite strategies to select intermediate feature maps that aim to cover adjacent levels. To overcome this, a new integration approach is needed. It involves combining
with
—derived from the Low Gather process based on
. This integration is part of the local information fusion, as illustrated in
Figure 3d. Feature maps larger than
undergo DWT, while smaller ones are resized using bilinear interpolation. The final step involves a
convolution to refine the output channel count, producing
.
Therefore, the general formula for the Low Stage Branch is shown below.
In summary, the design of the proposed Low Stage Branch significantly deviates from the downsampling method utilized in Gold-YOLO [
30], which predominantly employs adaptive average pooling to modify feature map sizes. This simpler pooling approach might result in the loss of critical information, inadequately addressing the challenges that the framework intends to resolve. To counter this limitation, the proposed method integrates a fully reversible discrete wavelet transform for downsampling. This technique effectively isolates low-frequency and high-frequency components, ensuring the retention of vital image details. Additionally, to rectify the issue of limited information exchange between
and
, a perception module is incorporated. This module is specifically designed to enrich both
and
with
information, facilitating a more integrated fusion.
2.2.2. High Stage Branch
This branch represents a departure from the low stage, focusing more on high-dimensional semantic information in the image. It utilizes
,
, and
as inputs, as depicted in
Figure 4.
High Gather Module. In this module, with an emphasis on higher-level information, the target outputs are set as images of and . To facilitate self-attention computations and reduce computational demands, both adaptive max pooling and adaptive average pooling are applied to downscale and . Adaptive max pooling is utilized to capture the maximum value in each pooling window, highlighting prominent features and maintaining local details. Conversely, adaptive average pooling calculates the average value in each window, aiding in the preservation of overarching information while softening finer details. For resizing, small-scale feature maps are adjusted using bilinear interpolation, whereas large-scale maps are refined through the two pooling methods. Ultimately, these varied feature maps are concatenated together.
High Fuse Module. This module adopts a dual-branch attention mechanism to capture both high-frequency and low-frequency features from the global information at the high stage. While traditional self-attention modules are adept at capturing low-frequency global information, they struggle with high-frequency local details [
36,
37]. Hence, for processing low-frequency information, the standard self-attention mechanism is employed. The process begins with a linear transformation
, resulting in
Q,
K, and
V that align with conventional attention standards, where
denotes the input [
38,
39]. In this branch,
K and
V are downscaled prior to undergoing the standard attention procedure with
Q,
K, and
V. The formula is described as follows:
In the branch dedicated to high-frequency information, aggregation of local details initiates with DWConv processing, demonstrated by the formula
. Following this,
Q and
K independently gather local details, guided by the DWConv weights. The element-wise product ⊙ is calculated between
Q and
K, which then undergoes a transformation to produce context-aware weights. This phase incorporates Swish and tanh functions to add enhanced nonlinear perception capabilities. Ultimately, the synthesized weights are utilized to amplify local features, as expressed in the formula:
where
d represents the channel count of each token. The high-frequency local information
and the low-frequency information
are then merged to form
and
. This process is illustrated in
Figure 4a,b.
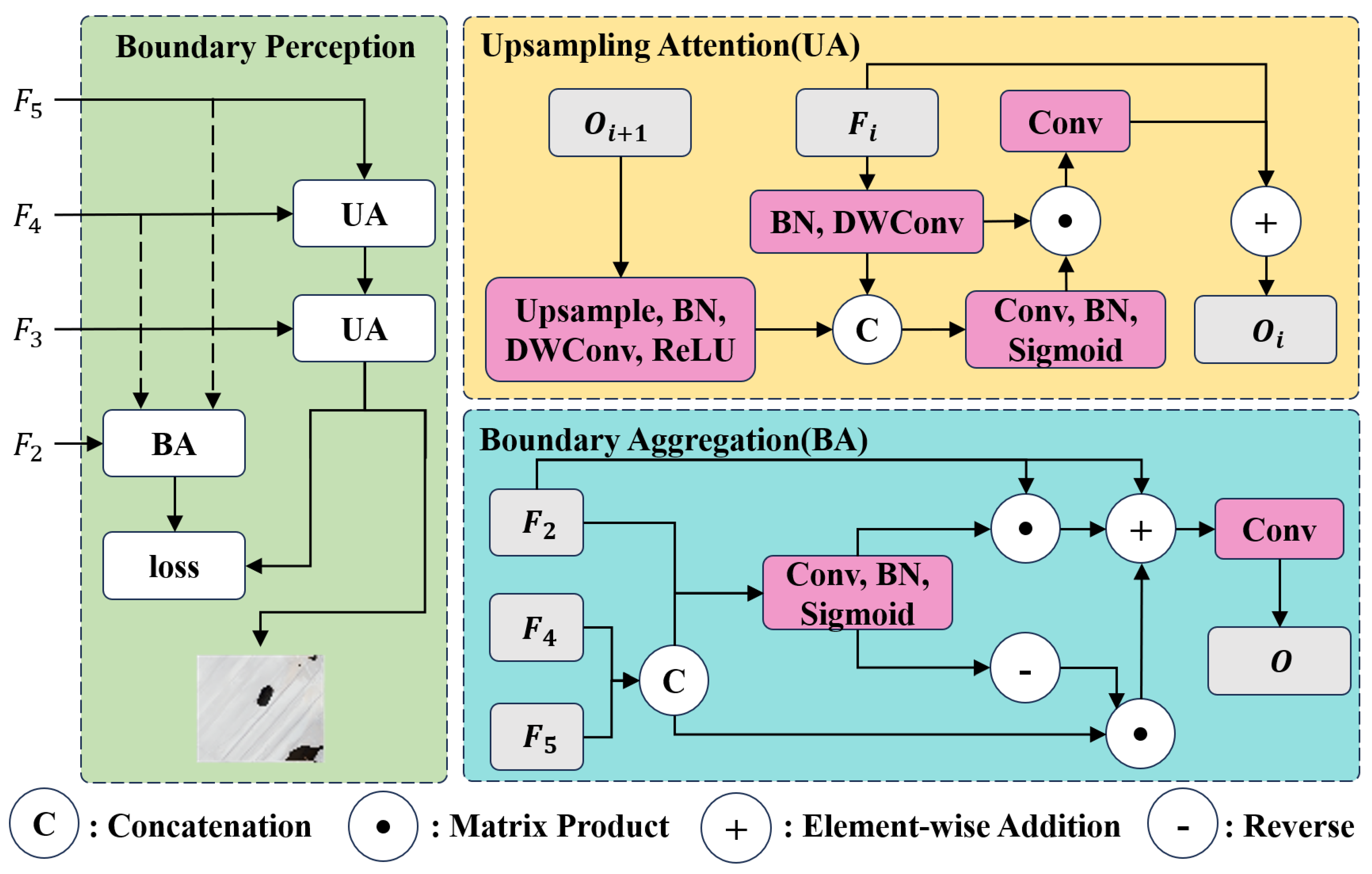
High Injection Module. This module serves to downsample the
scale by utilizing both average pooling and max pooling, while also adjusting the channel dimensions. The process then merges this downscaled output with the high-frequency information
, which is derived from the dual-branch attention mechanism like Equation (
7). This injection procedure reflects the techniques used in the Low Stage, culminating in the integration of hierarchical and global information
at the F4 scale.
High Perception Module. This module is crafted to handle the high-dimension target size located at the edge level . This setup results in a scenario where information transmission from is indirect. To manage this, a specialized perception mechanism has been integrated. The mechanism processes inputs from and , subsequently enhancing the based on , ultimately leading to the creation of .
Therefore, the general formula for the high stage branch is shown below.
In conclusion, this branch exhibits advancements in attention mechanisms over the Gold-YOLO model [
30]. It integrates modules that prioritize local high-frequency details, thus boosting perceptual abilities. Moreover, to tackle the challenges associated with indirect information transfer, perceptual modules have been utilized to enrich feature map information between non-adjacent hierarchical levels.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}