
A Lightning Optical Automatic Detection Method Based on a Deep Neural Network
 , ,
, ,
Abstract
:
1. Introduction
2. Data and Methods
2.1. Data Source
2.2. Batch Labeling Method
2.2.1. Pre-Screening Methods
2.2.2. Rough Batch Labeling
2.2.3. Fine Batch Labeling
2.3. Time Sequence Composite (TSC) Preprocessing Methods
2.4. Backbone Feature Extraction Network
3. Experiments
3.1. Dataset
3.2. Implementation Details
3.3. Experimental Settings
4. Results and Analysis
4.1. The Effectiveness of the Batch Labeling Method
4.2. Comparison between Different Types of Cameras
4.3. Evaluation of the Preprocessing of the TSCs
4.4. Comparison of Different Backbones
4.5. Recognition Results with a Higher Tolerability
4.6. Summary of the Two Experiments
5. Discussion
5.1. Incorrect Classification in Experiment 1
5.2. Incorrect Classification in Experiment 2
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DNN | deep neural network |
| CNN | convolutional neural network |
| BN | batch normalization |
| TSC | time sequence composite |
| FQ1 | feature quantity 1 |
| FQ2 | feature quantity 2 |
| ROC | receiver operating characteristic |
| TPR | true positive rate |
| FPR | false positive rate |
References
- Qie, X.; Kong, X. Progression Features of a Stepped Leader Process with Four Grounded Leader Branches. Geophys. Res. Lett. 2007, 34. [Google Scholar] [CrossRef]
- Qie, X.; Wang, Z.; Wang, D.; Liu, M. Characteristics of Positive Cloud-to-Ground Lightning in Da Hinggan Ling Forest Region at Relatively High Latitude, Northeastern China. J. Geophys. Res. Atmos. 2013, 118, 13393–13404. [Google Scholar] [CrossRef]
- Qie, X.; Jiang, R.; Wang, C.; Yang, J.; Wang, J.; Liu, D. Simultaneously Measured Current, Luminosity, and Electric Field Pulses in a Rocket-Triggered Lightning Flash. J. Geophys. Res. Atmos. 2011, 116, D10102. [Google Scholar] [CrossRef]
- Qie, X.; Zhang, Q.; Zhou, Y.; Feng, G.; Zhang, T.; Yang, J.; Kong, X.; Xiao, Q.; Wu, S. Artificially Triggered Lightning and Its Characteristic Discharge Parameters in Two Severe Thunderstorms. Sci. China Ser. Earth Sci. 2007, 50, 1241–1250. [Google Scholar] [CrossRef]
- Qie, X.; Pu, Y.; Jiang, R.; Sun, Z.; Liu, M.; Zhang, H.; Li, X.; Lu, G.; Tian, Y. Bidirectional Leader Development in a Preexisting Channel as Observed in Rocket-Triggered Lightning Flashes. J. Geophys. Res. Atmos. 2017, 122, 586–599. [Google Scholar] [CrossRef]
- Qie, X.; Zhao, Y.; Zhang, Q.; Yang, J.; Feng, G.; Kong, X.; Zhou, Y.; Zhang, T.; Zhang, G.; Zhang, T.; et al. Characteristics of Triggered Lightning during Shandong Artificial Triggering Lightning Experiment (SHATLE). Atmos. Res. 2009, 91, 310–315. [Google Scholar] [CrossRef]
- Qie, X.; Zhang, T.; Chen, C.; Zhang, G.; Zhang, T.; Wei, W. The Lower Positive Charge Center and Its Effect on Lightning Discharges on the Tibetan Plateau. Geophys. Res. Lett. 2005, 32, L05814. [Google Scholar] [CrossRef]
- Qie, X.; Wu, X.; Yuan, T.; Bian, J.; Lu, D. Comprehensive Pattern of Deep Convective Systems over the Tibetan Plateau–South Asian Monsoon Region Based on TRMM Data. J. Clim. 2014, 27, 6612–6626. [Google Scholar] [CrossRef]
- Qie, X.; Toumi, R.; Yuan, T. Lightning Activities on the Tibetan Plateau as Observed by the Lightning Imaging Sensor. J. Geophys. Res. Atmos. 2003, 108, 4551. [Google Scholar] [CrossRef]
- Qie, X.; Qie, K.; Wei, L.; Zhu, K.; Sun, Z.; Yuan, S.; Jiang, R.; Zhang, H.; Xu, C. Significantly Increased Lightning Activity Over the Tibetan Plateau and Its Relation to Thunderstorm Genesis. Geophys. Res. Lett. 2022, 49, e2022GL099894. [Google Scholar] [CrossRef]
- Kohlmann, H.; Schulz, W.; Pedeboy, S. Evaluation of EUCLID IC/CG Classification Performance Based on Ground-Truth Data. In Proceedings of the 2017 International Symposium on Lightning Protection (XIV SIPDA), Natal, Brazil, 2–6 October 2017; pp. 35–41. [Google Scholar] [CrossRef]
- Schonland, B.F.J.; Collens, H. Progressive Lightning. Trans. S. Afr. Inst. Electr. Eng. 1934, 25, 124–135. [Google Scholar]
- Yokoyama, S.; Miyake, K.; Suzuki, T.; Kanao, S. Winter Lightning on Japan Sea Coast-Development of Measuring System on Progressing Feature of Lightning Discharge. IEEE Trans. Power Deliv. 1990, 5, 1418–1425. [Google Scholar] [CrossRef]
- Jiang, R.; Wu, Z.; Qie, X.; Wang, D.; Liu, M. High-Speed Video Evidence of a Dart Leader with Bidirectional Development. Geophys. Res. Lett. 2014, 41, 5246–5250. [Google Scholar] [CrossRef]
- Pu, Y.; Qie, X.; Jiang, R.; Sun, Z.; Liu, M.; Zhang, H. Broadband Characteristics of Chaotic Pulse Trains Associated With Sequential Dart Leaders in a Rocket-Triggered Lightning Flash. J. Geophys. Res.-Atmos. 2019, 124, 4074–4085. [Google Scholar] [CrossRef]
- Jiang, R.; Srivastava, A.; Qie, X.; Yuan, S.; Zhang, H.; Sun, Z.; Wang, D.; Wang, C.; Lv, G.; Li, Z. Fine Structure of the Breakthrough Phase of the Attachment Process in a Natural Lightning Flash. Geophys. Res. Lett. 2021, 48, e2020GL091608. [Google Scholar] [CrossRef]
- Sun, Z.; Qie, X.; Jiang, R.; Liu, M.; Wu, X.; Wang, Z.; Lu, G.; Zhang, H. Characteristics of a Rocket-Triggered Lightning Flash with Large Stroke Number and the Associated Leader Propagation. J. Geophys. Res. Atmos. 2014, 119, 13388–13399. [Google Scholar] [CrossRef]
- Wang, C.-X.; Qie, X.-S.; Jiang, R.-B.; Yang, J. Propagating properties of a upward positive leader in a negative triggered lightning. ACTA Phys. Sin. 2012, 61, 039203. [Google Scholar] [CrossRef]
- Wang, Z.; Qie, X.; Jiang, R.; Wang, C.; Lu, G.; Sun, Z.; Liu, M.; Pu, Y. High-Speed Video Observation of Stepwise Propagation of a Natural Upward Positive Leader. J. Geophys. Res. Atmos. 2016, 121, 14307–14315. [Google Scholar] [CrossRef]
- Kong, X.; Qie, X.; Zhao, Y. Characteristics of Downward Leader in a Positive Cloud-to-Ground Lightning Flash Observed by High-Speed Video Camera and Electric Field Changes. Geophys. Res. Lett. 2008, 35, L05816. [Google Scholar] [CrossRef]
- Chen, L.; Lu, W.; Zhang, Y.; Wang, D. Optical Progression Characteristics of an Interesting Natural Downward Bipolar Lightning Flash. J. Geophys. Res. Atmos. 2015, 120, 708–715. [Google Scholar] [CrossRef]
- Lu, W.; Chen, L.; Zhang, Y.; Ma, Y.; Gao, Y.; Yin, Q.; Chen, S.; Huang, Z.; Zhang, Y. Characteristics of Unconnected Upward Leaders Initiated from Tall Structures Observed in Guangzhou. J. Geophys. Res. Atmos. 2012, 117, D19211. [Google Scholar] [CrossRef]
- Lu, W.; Wang, D.; Takagi, N.; Rakov, V.; Uman, M.; Miki, M. Characteristics of the Optical Pulses Associated with a Downward Branched Stepped Leader. J. Geophys. Res. Atmos. 2008, 113, D21206. [Google Scholar] [CrossRef]
- Lu, W.; Wang, D.; Zhang, Y.; Takagi, N. Two Associated Upward Lightning Flashes That Produced Opposite Polarity Electric Field Changes. Geophys. Res. Lett. 2009, 36, L05801. [Google Scholar] [CrossRef]
- Lu, W.; Chen, L.; Ma, Y.; Rakov, V.A.; Gao, Y.; Zhang, Y.; Yin, Q.; Zhang, Y. Lightning Attachment Process Involving Connection of the Downward Negative Leader to the Lateral Surface of the Upward Connecting Leader. Geophys. Res. Lett. 2013, 40, 5531–5535. [Google Scholar] [CrossRef]
- Gao, Y.; Lu, W.; Ma, Y.; Chen, L.; Zhang, Y.; Yan, X.; Zhang, Y. Three-Dimensional Propagation Characteristics of the Upward Connecting Leaders in Six Negative Tall-Object Flashes in Guangzhou. Atmos. Res. 2014, 149, 193–203. [Google Scholar] [CrossRef]
- Lu, W.; Zhang, Y.; Zhou, X.; Qie, X.; Zheng, D.; Meng, Q.; Ma, M.; Chen, S.; Wang, F.; Kong, X. Simultaneous Optical and Electrical Observations on the Initial Processes of Altitude-Triggered Negative Lightning. Atmos. Res. 2009, 91, 353–359. [Google Scholar] [CrossRef]
- Zhou, E.; Lu, W.; Zhang, Y.; Zhu, B.; Zheng, D.; Zhang, Y. Correlation Analysis between the Channel Current and Luminosity of Initial Continuous and Continuing Current Processes in an Artificially Triggered Lightning Flash. Atmos. Res. 2013, 129–130, 79–89. [Google Scholar] [CrossRef]
- Wang, J.; Su, R.; Wang, J.; Wang, F.; Cai, L.; Zhao, Y.; Huang, Y. Observation of Five Types of Leaders Contained in a Negative Triggered Lightning. Sci. Rep. 2022, 12, 6299. [Google Scholar] [CrossRef]
- Cai, L.; Chu, W.; Zhou, M.; Su, R.; Xu, C.; Wang, J.; Fan, Y. Observation and Modeling of Attempted Leaders in a Multibranched Altitude-Triggered Lightning Flash. IEEE Trans. Electromagn. Compat. 2023, 65, 1133–1142. [Google Scholar] [CrossRef]
- Winckler, J.R.; Malcolm, P.R.; Arnoldy, R.L.; Burke, W.J.; Erickson, K.N.; Ernstmeyer, J.; Franz, R.C.; Hallinan, T.J.; Kellogg, P.J.; Monson, S.J.; et al. ECHO 7: An Electron Beam Experiment in the Magnetosphere. Eos Trans. Am. Geophys. Union 1989, 70, 657–668. [Google Scholar] [CrossRef]
- Pasko, V.P.; Stanley, M.A.; Mathews, J.D.; Inan, U.S.; Wood, T.G. Electrical Discharge from a Thundercloud Top to the Lower Ionosphere. Nature 2002, 416, 152–154. [Google Scholar] [CrossRef] [PubMed]
- Soula, S.; van der Velde, O.; Montanyà, J.; Neubert, T.; Chanrion, O.; Ganot, M. Analysis of Thunderstorm and Lightning Activity Associated with Sprites Observed during the EuroSprite Campaigns: Two Case Studies. Atmos. Res. 2009, 91, 514–528. [Google Scholar] [CrossRef]
- Yang, J.; Lu, G.; Liu, N.; Cui, H.; Wang, Y.; Cohen, M. Analysis of a Mesoscale Convective System That Produced a Single Sprite. Adv. Atmos. Sci. 2017, 34, 258–271. [Google Scholar] [CrossRef]
- Wang, X.; Wang, H.; Lyu, W.; Chen, L.; Ma, Y.; Qi, Q.; Wu, B.; Xu, W.; Hua, L.; Yang, J.; et al. First Experimental Verification of Opacity for the Lightning Near-Infrared Spectrum. Geophys. Res. Lett. 2022, 49, e2022GL098883. [Google Scholar] [CrossRef]
- Wan, R.; Yuan, P.; An, T.; Liu, G.; Wang, X.; Wang, W.; Huang, X.; Deng, H. Effects of Atmospheric Attenuation on the Lightning Spectrum. J. Geophys. Res. Atmos. 2021, 126, e2021JD035387. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2012; Volume 25. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. arXiv 2017, arXiv:1605.07146. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Zhao, B.; Li, X.; Lu, X.; Wang, Z. A CNN-RNN Architecture for Multi-Label Weather Recognition. Neurocomputing 2018, 322, 47–57. [Google Scholar] [CrossRef]
- Lv, Q.; Li, Q.; Chen, K.; Lu, Y.; Wang, L. Classification of Ground-Based Cloud Images by Contrastive Self-Supervised Learning. Remote Sens. 2022, 14, 5821. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar] [CrossRef]

















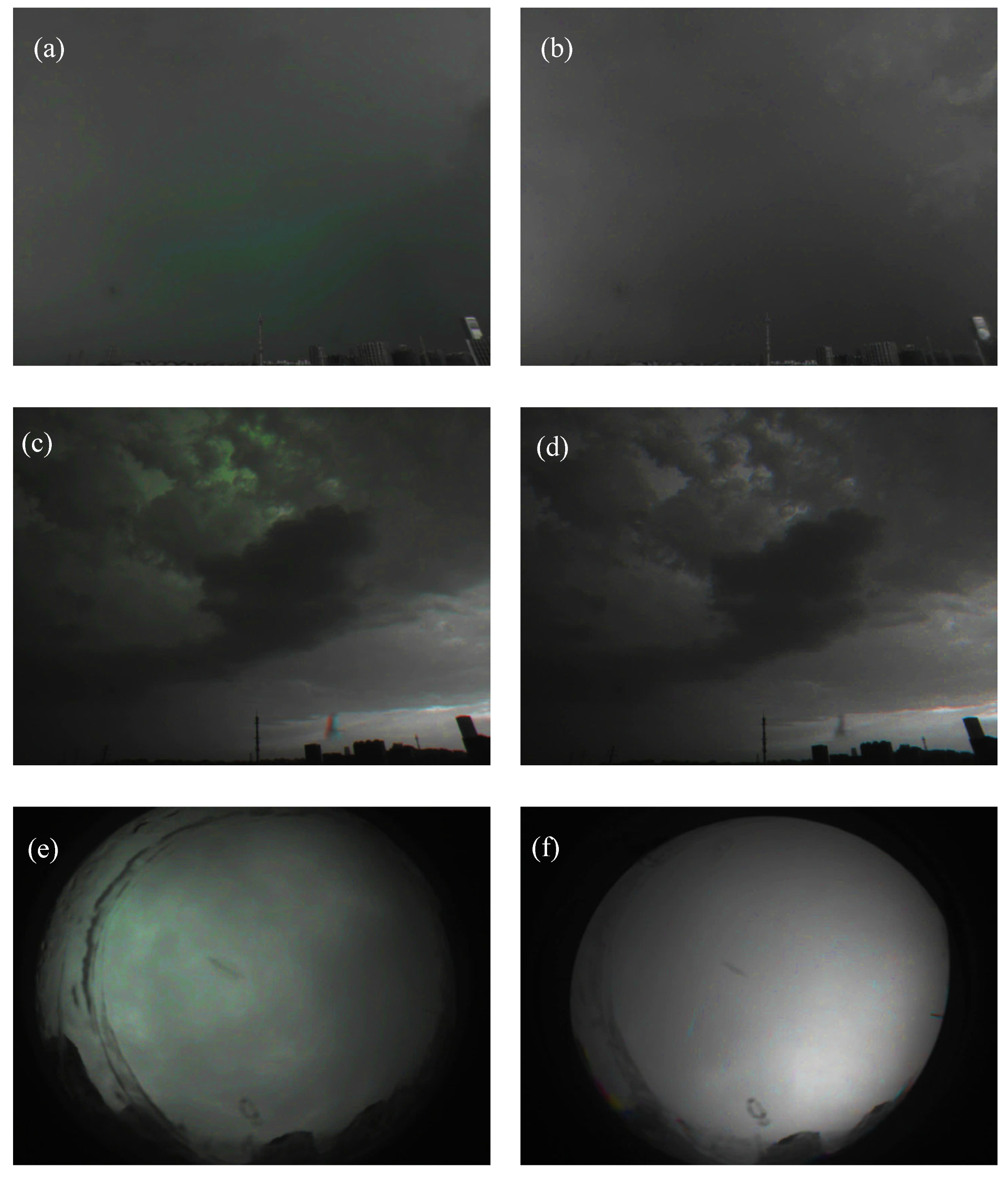

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | ResNet152 | ResNeXt101 (64 × 4d) | WideResNet101-2 | DenseNet161 |
|---|---|---|---|---|
| 1 | ||||
| 2 | ||||
| 3 | ||||
| 4 | ||||
| 5 | ||||
| Experiment | Training Set | Test Set | ||
|---|---|---|---|---|
| Lightning | Non-Lightning | Lightning | Non-Lightning | |
| 1 | 3256 | 11,542 | 814 | 12,354 |
| 2 | 6741 | 15,027 | 1686 | 11,482 |
| ResNet152 | ResNeXt101 (64 × 4d) | WideResNet101-2 | DenseNet161 | |||||
|---|---|---|---|---|---|---|---|---|
| TPR (%) | FPR (%) | TPR (%) | FPR (%) | TPR (%) | FPR (%) | TPR (%) | FPR (%) | |
| Not using TSC | 53.4 | 3.1 | 54.9 | 3.5 | 51.6 | 2.1 | 58.4 | 3.0 |
| Using TSC | 93.0 | 0.8 | 91.7 | 0.8 | 93.4 | 0.8 | 91.6 | 1.0 |
| Experiment 1 | Experiment 2 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ResNet152 | ResNeXt (64 × 4d) | Wide-ResNet101-2 | DenseNet161 | DenseNet161 | |||||||
| Epoch | TPR (%) | NFP | TPR (%) | NFP | TPR (%) | NFP | TPR (%) | NFP | TPR (%) | NFP | |
| Using TSCs | 25 | 61.23 | 17 | 39.63 | 17 | 48.10 | 17 | 71.29 | 16 | 67.46 | 26 |
| 50 | 72.39 | 17 | 80.74 | 17 | 77.67 | 17 | 78.53 | 24 | 6.22 | 26 | |
| 75 | 77.06 | 17 | 83.19 | 16 | 84.91 | 15 | 71.90 | 22 | 21.64 | 26 | |
| 100 | 85.15 | 17 | 75.71 | 17 | 83.93 | 17 | 73.37 | 24 | 27.98 | 26 | |
| 125 | 82.33 | 17 | 82.70 | 15 | 75.95 | 17 | 79.26 | 16 | 35.68 | 26 | |
| 150 | 79.75 | 16 | 80.86 | 17 | 80.61 | 17 | 80.37 | 16 | 24.36 | 26 | |
| 175 | 85.77 | 16 | 78.04 | 17 | 79.88 | 16 | 86.50 | 16 | 13.52 | 26 | |
| 200 | 81.35 | 17 | 78.40 | 17 | 79.63 | 17 | 80.74 | 16 | 27.15 | 26 | |
| 225 | 80.86 | 17 | 77.67 | 15 | 80.86 | 17 | 80.90 | 16 | 19.92 | 26 | |
| non- TSC | 25 | 37.67 | 96 | 38.53 | 99 | 23.93 | 99 | 34.72 | 95 | ||
| 50 | 31.29 | 96 | 37.18 | 98 | 42.33 | 96 | 35.83 | 99 | |||
| 75 | 37.79 | 99 | 35.95 | 96 | 40.12 | 99 | 39.02 | 99 | |||
| 100 | 34.72 | 98 | 36.56 | 99 | 35.46 | 99 | 35.95 | 99 | |||
| 125 | 35.21 | 99 | 36.81 | 99 | 35.83 | 99 | 38.16 | 97 | |||
| 150 | 37.55 | 99 | 34.48 | 99 | 35.71 | 95 | 38.77 | 99 | |||
| 175 | 35.95 | 96 | 37.06 | 99 | 35.71 | 99 | 35.71 | 99 | |||
| 200 | 36.44 | 98 | 38.28 | 99 | 35.21 | 96 | 39.63 | 99 | |||
| 225 | 35.58 | 98 | 35.21 | 99 | 32.27 | 99 | 18.77 | 66 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Song, L.; Zhang, Q.; Li, J.; Ge, Q.; Yan, S.; Wu, G.; Yang, J.; Zhong, Y.; Li, Q. A Lightning Optical Automatic Detection Method Based on a Deep Neural Network. Remote Sens. 2024, 16, 1151. https://doi.org/10.3390/rs16071151
Wang J, Song L, Zhang Q, Li J, Ge Q, Yan S, Wu G, Yang J, Zhong Y, Li Q. A Lightning Optical Automatic Detection Method Based on a Deep Neural Network. Remote Sensing. 2024; 16(7):1151. https://doi.org/10.3390/rs16071151
Chicago/Turabian StyleWang, Jialei, Lin Song, Qilin Zhang, Jie Li, Quanbo Ge, Shengye Yan, Gaofeng Wu, Jing Yang, Yuqing Zhong, and Qingda Li. 2024. "A Lightning Optical Automatic Detection Method Based on a Deep Neural Network" Remote Sensing 16, no. 7: 1151. https://doi.org/10.3390/rs16071151