1. Introduction
Mesoscale eddies, which are widespread in the global ocean, exhibit circular motions of water masses with horizontal scales ranging from tens to hundreds of kilometers and lifetimes lasting from weeks to months. These eddies play a pivotal role in the transport of heat, salt, nutrients, carbon, and biological organisms across various regions, significantly influencing ocean circulation, mixing, and air–sea interactions [
1,
2,
3]. Consequently, they have far-reaching implications for the climate system and marine ecosystems. It is essential to understand the future locations and properties of mesoscale eddies to enhance ocean modeling, management, and the evaluation of their impact on marine ecosystems and the global climate.
Mesoscale eddy prediction is a challenging task. In previous research, the prediction of mesoscale eddies was categorized into traditional methods and machine learning methods. Recently, the rapid development of deep learning has led to the emergence of new methodologies in eddy prediction. However, these methods face similar challenges, such as lacking spatiotemporal modeling of various oceanic elements and being unable to predict the generation and dissipation of eddies.
We believe that accurate eddy prediction requires the model to perform spatial–temporal feature extraction and analysis on ocean data. In the field of deep learning, models such as Convolutional Neural Networks (CNNs) extract spatial features effectively through convolution and max-pooling operations. Models like Recurrent Neural Networks (RNNs) or Long Short-Term Memory (LSTM) Networks efficiently handle time-series analysis problems. However, these models struggle to establish spatio-temporal correlations in the data. In recent years, deep learning for video prediction has gained widespread attention. Video prediction involves generating future frames of a video sequence based on given previous frames. The key focus of research lies in effectively establishing spatio-temporal correlations in the data, which is essential for our task.
Considering the close relationship between mesoscale eddies and sea surface height (SSH) data, we can utilize SSH data to study and predict the evolution of mesoscale eddies. Mesoscale eddies can cause changes in SSH because the pressure anomalies at the eddy center can lead to the lifting or lowering of the sea surface [
4]. Conversely, SSH anomaly data obtained from satellite altimetry are often used to identify and track oceanic mesoscale eddies. By analyzing SSH anomaly data, we can determine the location, scale, intensity, and propagation trajectories of eddies [
5]. Furthermore, SSH anomaly data can also provide information on the vertical structure of eddies, such as their depth and vertical stratification [
6]. Given the close relationship between SSH and mesoscale eddies, as well as the proven effectiveness of video prediction models in capturing spatio-temporal correlations, we have strong grounds to employ video-prediction-based methods for forecasting sea surface height, which in turn enables the prediction of mesoscale eddies.
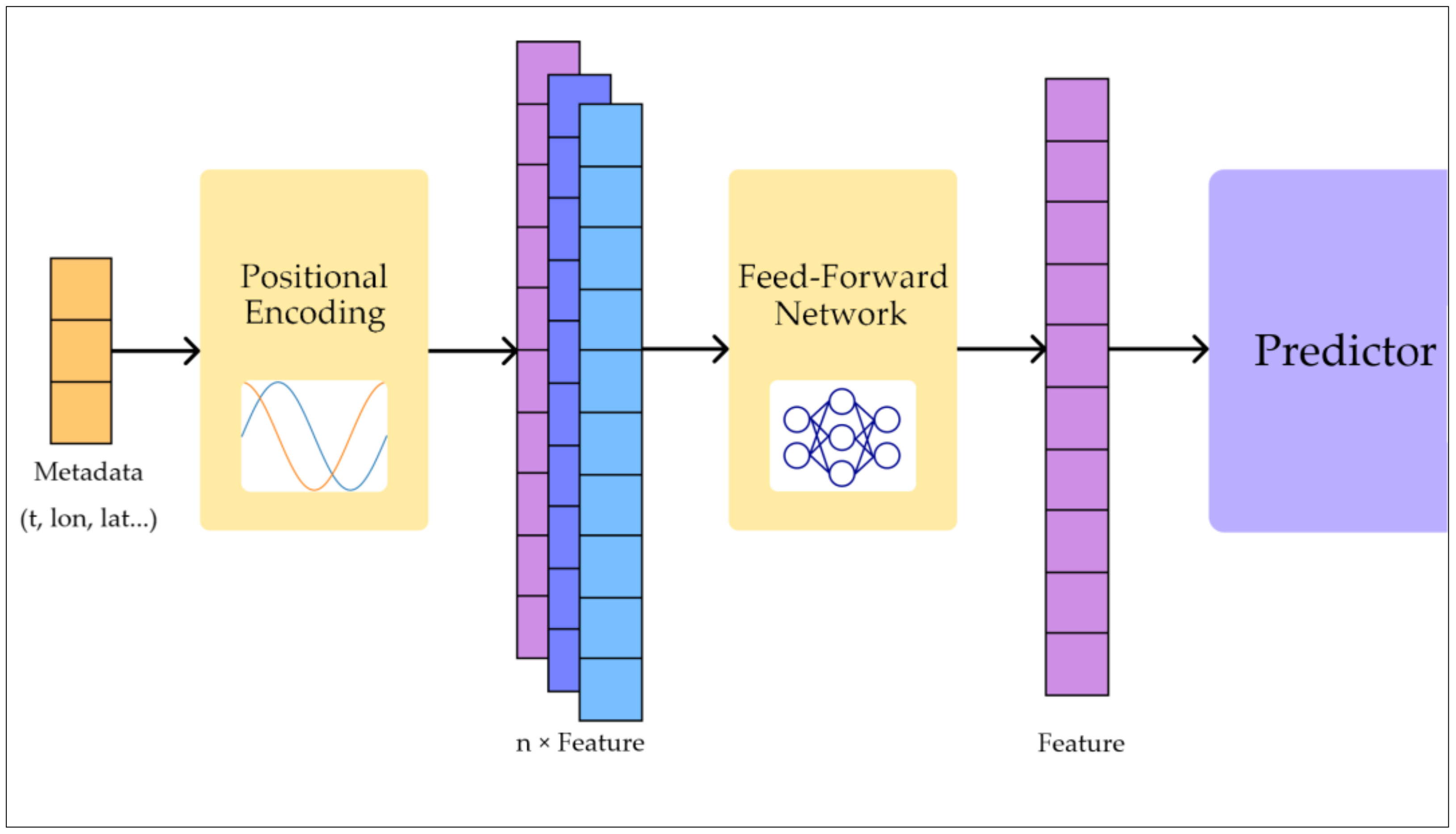
In our research, we have developed a method for predicting the movement, formation, and dissipation of mesoscale eddies. This method primarily relies on a high-performance ocean surface height prediction model that integrates past ocean surface height and geostrophic velocity grid data as model inputs to accurately predict ocean surface height grid data. We formulated the input data as spatiotemporal sequences and constructed an end-to-end trainable model based on a video prediction model. By extending the prediction model to include a Metadata Embedding (ME) module, we propose integrating remote sensing metadata with input data features, enabling multi-modal data fusion. In addition, we constructed a dataset merging sea surface height and geostrophic velocity data, along with metadata, for training and evaluation. At the final stage, we applied a mesoscale eddy detection and tracking algorithm to the predicted sea surface height data for acquiring information on the future mesoscale eddies.
Figure 1 illustrates the architecture of our mesoscale eddy prediction method.
Our main contributions are summarized as follows:
We constructed an SSH prediction model based on a video prediction model, utilizing SSH and ocean velocity data input to accurately predict sea surface height values 3 or 7 days in advance. To the best of our knowledge, our sea surface height prediction model achieved the highest accuracy compared to existing works.
We introduced a novel Metadata Embedding module to enhance the performance of remote sensing data prediction models by providing relative time and location information. This approach can be a useful extension to enhance other relevant models and datasets.
We analyzed the predicted SSH data using a mesoscale eddy detection algorithm to predict future mesoscale eddies within the focused area. This method is effective in tracking the movement and deformation of mesoscale eddies, and enables the prediction of the timing of eddy generation and disappearance, which has not been explicitly measured in the literature of mesoscale eddy prediction.
The remainder of this article is organized as follows.
Section 2 discusses related works on mesoscale eddy prediction.
Section 3 introduces the data and methods for sea surface height prediction, and the mesoscale eddy detection algorithm we used.
Section 4 presents the experimental results of sea surface height prediction and medium-scale eddy prediction.
Section 5 summarizes the research conducted in this study.
2. Related Works
In recent decades, the accurate prediction of ocean mesoscale eddies has become a critical focus of research in oceanography. The quest for predictability in mesoscale eddies began with seminal work by Robinson et al. [
7] and Robinson and Leslie [
8], who achieved a breakthrough by demonstrating the predictability of mesoscale eddies in the northeast Pacific. Their 2-week evolution forecasts, particularly focusing on eddies off the California coast, marked a pivotal moment in the field, inspiring subsequent research endeavors.
Since those pioneering efforts, a multitude of mesoscale eddy prediction methods has emerged, broadly categorized into traditional and machine learning approaches. Traditional methods often rely on physical principles and empirical relationships to model the behavior of mesoscale eddies, while machine learning approaches leverage advanced algorithms and data-driven techniques to uncover patterns in complex oceanic processes.
2.1. Traditional Methods
In traditional oceanic mesoscale eddy prediction, the analysis of relevant remote sensing data for prediction or simulation heavily relies on the use of statistical methods, ocean circulation models (OCMs), and other numerical simulation techniques. Traditional methods struggle to model ocean spatiotemporal data, resulting in low prediction accuracy.
In the early stages of mesoscale eddy prediction research, Robinson et al. [
7] applied ocean dynamics modeling to predict the evolution of mesoscale eddies, achieving a breakthrough by demonstrating the predictability of oceanic eddy currents through real-time forecasts in the northeast Pacific. Rienecker et al. [
9] extended this effort with an ocean prediction experiment off Northern California, highlighting the positive impact of assimilating altimeter sea level anomaly data. Masina S et al. [
10] conducted a mesoscale data assimilation experiment, presenting a quasi-geostrophic numerical model with initial fields for mesoscale assimilation around the Middle Adriatic Sea, enabling a 30-day dynamical prediction of the mesoscale flow field. These works laid the foundation for understanding mesoscale eddy dynamics and underscored the potential of traditional prediction methods.
Building on traditional approaches, Isern-Fontanet et al. [
11] proposed an eddy identification and evolution model that utilizes physical characteristics of eddies for prediction. With the evolution of data assimilation strategies and the enhancement of resolution, Hurlburt et al. [
12] enhanced prediction accuracy by integrating observational data with numerical model data.
Prants et al. [
13] developed a Lagrangian methodology to simulate and track the origin and evolution of water masses within mesoscale ocean eddies using trajectories of synthetic particles advected by altimetry velocities. They applied this technique to identify the Tohoku and Hokkaido eddies contaminated by Fukushima-derived radionuclides after the 2011 disaster, and compared the modeled eddy distributions against in situ measurements.
The simulation of ocean processes and the prediction of oceanic variables are essential for predicting mesoscale eddies. HYCOM [
14] (Hybrid Coordinate Ocean Model) is an ocean model that combines the advantages of several different vertical coordinate systems to provide the most efficient representation of ocean processes in different oceanographic regimes. It uses isopycnal coordinates in the stratified ocean interior, z-level coordinates in the unstratified surface mixed layer, terrain-following sigma coordinates in shallow coastal regions, and hybrid coordinates that are isopycnal in the open, stratified ocean but revert smoothly to terrain-following coordinates in shallow coastal regions. HYCOM is designed to optimize the simulation of middle-scale phenomena such as eddies, meanders, and fronts, as well as their interaction with coastal and bathymetric features. It can be applied at both global and regional scales.
Fu et al. [
15] proposed a hybrid model combining empirical mode decomposition (EMD), singular spectrum analysis (SSA), and least square (LS) extrapolation for predicting long-term satellite-derived sea level anomalies (SLAs). The model first decomposed the SLA into intrinsic mode functions (IMFs) using EMD, then decomposed and reconstructed each IMF into identifiable principal components via SSA, and finally predicted the reconstructed components and residuals using LS extrapolation.
2.2. Machine Learning Methods
The dynamics of the ocean are intricate. Traditional methods for predicting the future development of ocean mesoscale eddies lack accuracy, while machine learning can utilize a large amount of remote sensing data and achieve more complex modeling, making it somewhat necessary to use machine learning methods. The task of mesoscale eddy prediction clearly requires machine learning models to possess strong spatiotemporal modeling capabilities. They should be able to analyze the patterns and connections in the changes in eddies or related information to predict information about eddies or related information in the next timestep.
In a study by Li et al. [
16], a predictive model for mesoscale eddy propagation trajectories was formulated using multivariate linear regression. This model showcased a notable improvement in forecasting capability over a four-week window compared to conventional persistent forecasting methods. However, it was observed that forecast accuracy is subject to sensitivity concerning eddy polarity and forecast seasons. Ma et al. [
17] achieved significant success in real-time eddy prediction by employing an enhanced Convolutional Long Short-Term Memory (ConvLSTM) network, complemented by a sea level anomaly-based eddy detection algorithm.
Building on this momentum, Wang et al. [
18] proposed a machine learning model grounded in a multi-task Convolutional Long Short-Term Memory (LSTM) network and the extra trees (ET) algorithm. This innovative approach utilized satellite altimetry data for predicting eddy properties and propagation trajectories. Nian et al. [
19] successfully forecasted the sea level anomaly (SLA) by introducing the Memory In Memory (MIM) model, integrating a deep learning architecture and making an initial attempt to unravel the predictability of eddies, demonstrating promising performance. In a parallel vein, Wang et al. [
20] introduced the MesoGRU framework, elevating eddy trajectory prediction through inventive loss functions and strategic data integration.
Furthermore, Zhu et al. [
21] introduced the Vortex-Implanted Initialization Scheme for Mesoscale Eddy Prediction (VISTMEP), significantly enhancing eddy prediction accuracy. This was achieved by constructing a synthetic eddy and embedding it into the model’s initial field, accounting for three-dimensional structure, movement trajectory, size, and intensity.
3. Preliminary
In recent years, deep learning methods have shown tremendous potential in the field of weather and climate forecasting [
22]. They represent a data-driven forecasting approach that utilizes large amounts of historical data and complex neural network models to automatically learn the intrinsic relationships and patterns between the environment and various influencing factors [
23,
24]. This method can extract valuable representation from massive ocean observation data to construct precise prediction models. Deep learning models can simultaneously consider the interactions of multiple physical variables, better reflecting the nonlinear dynamic processes of the ocean, thus providing more accurate and detailed forecasts of ocean conditions. Therefore, the application of deep learning methods in ocean forecasting has good reliability and prospects. However, there are also issues with interpretability and stability that need to be addressed. The foundation of deep learning methods lies in the structure and functioning of artificial neural networks, which will be discussed in the following section.
3.1. Neural Network Basis
Artificial Neural Networks (ANNs) are computational models that mimic the structure and function of biological neural systems. A basic neural network consists of an input layer, hidden layers, and an output layer, with each layer containing multiple neurons. Neurons receive inputs from the previous layer, process them through weighted summation and activation functions, and output the results to the next layer.
For the
j-th neuron in the
l-th layer, its output can be represented as
where
is the output of the
j-th neuron in the
l-th layer,
is the weight from the
i-th neuron in the (
l-1)-th layer to the
j-th neuron in the
l-th layer,
is the bias term of the
j-th neuron in the
l-th layer, and
is the activation function.
The introduction of nonlinear activation functions endows neural networks with nonlinear mapping capabilities, enabling them to learn nonlinear patterns and features from the input data, thereby better fitting complex data distributions. Common activation functions include Sigmoid, Tanh, and ReLU. Different activation functions have different mathematical properties and perform differently in various scenarios.
3.2. Convolution-Based Neural Networks
Convolutional Neural Networks (CNNs) are popular and effective deep learning models widely applied to tasks such as image and video processing. The design of CNNs is inspired by the biological visual system, aiming to automatically learn hierarchical feature representations.
The convolution operation in CNNs can efficiently and effectively learn representations from images. It has the characteristics of having fewer parameters and being invariant to translation and rotation. The convolutional layer performs convolution operations by sliding a kernel over the input feature maps to extract local features while preserving the spatial structure information of the input. The convolution operation involves the following key parameters:
Kernel: The kernel is a small matrix that determines the output feature map.
Stride: The step size at which the kernel slides over the input.
The formula of a convolution operation is
where
is the input feature map,
is the kernel weight, and
is the bias term. By applying the kernel at every position of the image or feature map, a new feature map is obtained.
3.3. Model Training Process
The training process of deep learning models typically includes two stages: forward propagation and backward propagation. Forward propagation calculates the model’s output and loss function value, while backward propagation updates the model parameters based on the loss function.
Given a training sample
, the model’s predicted output is
, where
represents the model parameters. The loss function
measures the difference between the predicted output and the true label. In our task, we used Mean Squared Error (MSE) as the loss function. Its formula is as follows:
where
n is the number of samples,
is the true/target value, and
is the predicted value.
Backward propagation calculates the gradients of the loss function with respect to the parameters of each layer using the chain rule:
where
and
.
The optimizer can utilize the results of backpropagation to update the model’s parameters, , thereby reducing the loss between the model’s output and the true values.
5. Experiments
5.1. Setup
The model training and prediction were performed using the following computer hardware and software configuration: NVIDIA RTX 4090 graphics card; Intel(R) Core (TM) i7-13700F CPU; 64 GB RAM; Windows 11 22H2 operating system; Python 3.10.13 interpreter; NumPy 1.26.0; PyTorch 2.1.0. We used the AdamW [
36] Optimizer with parameters
and Mean Square Loss (MSE) loss function for our model training. Due to limited memory, the batch size for training was set at 10.
5.2. Metrics
5.2.1. Root Mean Square Error (RMSE)
Root Mean Square Error (RMSE) is a measure of the accuracy of the SSH prediction model. It indicates the average deviation between the predicted values and the true values, the smaller the better. The formula for RMSE is as follows:
where
is the number of samples,
is the true value of the i-th sample, and
is the predicted value of the
i-th sample.
5.2.2. Mean Absolute Error (MAE)
Mean Absolute Error (MAE) is a metric used to evaluate the performance of the SSH prediction model. It is defined as the average absolute difference between the predicted values of the model and the true values of the data. The MAE is calculated using the following formula:
where
is the number of observations in the data,
is the true value of the
i-th observation, and
is the predicted value of the i-th observation.
5.2.3. Average Center Distance and Match Rate
The main indicators used to evaluate the effectiveness of mesoscale eddy prediction in our study were the average center distance and the match rate. For a predicted sea surface height image
and the corresponding ground truth image
, we first applied an eddy detection algorithm
to obtain the set of center points of mesoscale eddies on the sea surface height images, denoted as
and
. Subsequently, we constructed a bipartite graph using
as the vertex set, with the edge weight being the absolute distance between the eddy center points, to perform a minimum weight matching to obtain the set of matched points. This process allowed us to calculate the Average Center Distance as follows:
The variable represents the weight of the i-th edge of matching, representing the distance between the predicted eddy center and the actual value, measured in kilometers. denotes the total number of matched points.
The Match Rate indicates the frequency at which the eddy centers in the actual values are successfully matched. It can be calculated by the following formula:
The variable denotes the total number of ground truth eddy center points.
5.3. Sea Surface Height (SSH) Prediction Results
In this section, we employed large-scale ADT prediction and single-window SLA prediction methods to assess the performance variations of our different models across various time intervals and datasets. Large-area prediction involves the use of a sliding window to sample the dataset within a large area, allowing for predictions of sea surface heights at any window position within the area. On the other hand, single-window area prediction focuses only on a fixed small area, aiming to achieve better results than large-area prediction. The large-area predictive model saves computational resources significantly, while the single-window predictive model provides a significant improvement in effectiveness compared to the large-area predictive model.
5.3.1. Large Area ADT Prediction Results
In this section, we utilize the ADT and UGOS, VGOS data from the “Global Ocean Gridded L4 Sea Surface Heights And Derived Variables Nrt” product to train models for predicting future ADT data in a large region. The study area was defined by the region bounded by 107.875°E to 179.875°E in longitude and 39.875°N to 39.875°S in latitude. Due to the larger size of the target region for training and prediction compared to the input–output area of the model, we employed a sliding window approach to extract data of the same size as the model’s input and output from the larger dataset. We then gathered the metadata proposed in
Section 4.2.2 to form the dataset. The training and validation data were from the years 2019 to 2020, while the testing data were from 2021. We selected 11 consecutive time steps with a time interval of 3 days between each time step, setting the window size to be
pixels, corresponding to the spatial resolution of the data product. Each pixel represented a
grid cell on the Earth surface. The window was moved in both longitude and latitude directions with a stride of 24 pixels.
In 3-day prediction, the input data’s time series were derived from the remote sensing image frames of the past 28 days, with 10 frames sampled as input at 3-day intervals. In 7-day prediction, we used a specific time interval sequence of past SSH frames to help the model better capture the long-term and short-term changes in the ocean. In brief, the input consisted of 10 frames with relative days of i, i + 7, i + 14, i + 17, i + 20, i + 23, i + 26, i + 27, i + 28, and i + 29, while the predicted frame, or label, corresponded to day i + 36. We trained these models for 100 epochs.
We divided the experiment into four groups: the first group trained using ADT and UGOS, VGOS channels with the Metadata Embedding module (3dim-ME), the second group trained using ADT and UGOS, VGOS channels without the Metadata Embedding module (3dim), the third group trained using only the ADT channel with the Metadata Embedding module (1dim-ME), and the fourth group trained using only velocity channels with the Metadata Embedding module (UV-ME). We also employed a ConvLSTM [
37] with 5 hidden layers and a hidden dimension of 64 for comparison.
Table 3 shows the performances of these models. The model performed best when using velocity input combined with Metadata Embedding. It obtained an RMSE of 0.0108 m and MAE of 0.0084 m for 3-day prediction, and an RMSE of 0.0216 m and MAE of 0.0167 m for 7-day prediction. The model’s performance using only ADT as input with Metadata Embedding was second-best, achieving an RMSE of 0.0110 m and MAE of 0.0085 m for the 3-day prediction and an RMSE of 0.0221 m and MAE of 0.0172 m for the 7-day prediction. The model performed less well when using velocity input without Metadata Embedding, achieving RMSE and MAE values of 0.0111 m and 0.0087 m for the 3-day prediction, and 0.0228 m and 0.0177 m for the 7-day prediction. When using only velocity input along with metadata embedding, the model attained an RMSE of 0.0476 m and an MAE of 0.0381 m for 3-day prediction. As for 7-day prediction, the RMSE and MAE values were 0.0515 m and 0.0380 m, respectively. ConvLSTM exhibited poorer performance, achieving RMSE and MAE values of 0.0541 m and 0.0425 m for the 3-day prediction and 0.0564 m and 0.0440 m for the 7-day prediction.
Figure 4 shows the error distribution of our model on the test dataset. It can be observed that the absolute error in the 3-day prediction was almost always within 0.05 m, while the performance in the 7-day prediction was noticeably worse. Overall, the prediction performance of 7-day prediction was significantly inferior to 3-day prediction.
When the model is trained and used to make predictions based on data from a large area, the varying locations of data sources significantly impact the accuracy of the model’s predictions. In other words, the difficulty of predicting data varies across different locations.
Figure 5 illustrates the distribution of RMSE in predicting the model at different locations within the area we studied for 3-day and 7-day prediction. There are many parts in the image without points due to missing data in the dataset, mainly caused by missing data in land areas. It can be observed from the figure that the model seems to perform worse near the missing values and better and more consistently in areas without missing values.
5.3.2. Single-Window Area SLA Prediction Results
In this section, we used single-window-size area data from the “Global Ocean Gridded L4 Sea Surface Heights and Derived Variables Reprocessed 1993 Ongoing” product to predict the sea level anomaly (SLA) 3 or 7 days later. Training in a single-window-size area means that only the sea surface height within that particular window can be predicted, but it is apparent that higher accuracy can be achieved. Multiple models can be trained using this method to predict sea surface height in larger areas. Since the prediction location is static, the Metadata Embedding module only provides relative time information
proposed in
Section 4.2.2, as the location metadata is static.
We conducted tests on data from three different regions. Our training data were sourced from the region with the specified latitude and longitude (Region 1, 13.375°N~29.125°N, 139.375°E~123.125°E) and two areas in Kuroshio Extension (Region 2, 26.125°N~41.875°N, 179.875°E~163.625°E; Region 3, 26.125°N~41.875°N, 167.875°E~151.625°E) as our research sample to predict mesoscale eddies. Due to the lower accuracy of edge areas in the predicted numerical image compared to the center areas [
4], we only selected the central 50 × 50 region of the numerical image for output to calculate the loss and assess the accuracy. The training and validation data were from the years 1993 to 2017, while the testing data span from 2018 to 2021. To the best of our knowledge, our model performed the best among all known methods for this specific task.
First, we trained a 7-day prediction for Region 1 for 100 epochs. Region 1 was chosen to compare performance with Enhanced MIM [
19] for SLA prediction.
Table 4 shows the performances of these models. Even though the Enhanced MIM paper did not include a 7-day prediction experiment, our 7-day prediction in this area resulted in an RMSE of 0.0110 m and MAE of 0.0083 m, significantly outperforming their 6-day prediction with an RMSE of 0.017 m.
Then, we used the weights of this model as pre-training weights for training models in Regions 2 and 3. Using the pre-training weights, only 5 to 10 epochs of fine-tuning are needed to achieve good results, as higher numbers of epochs can lead to severe overfitting.
Table 5 shows the performance of our single-window-size SSH prediction model. The results indicate that the RMSE values for the 3-day prediction in two regions were 0.0033 m and 0.0030 m, with corresponding MAE values of 0.0025 m and 0.0023 m. For the 7-day prediction in two regions, the RMSE values were 0.0097 m and 0.0087 m, with MAE values of 0.0076 m and 0.0061 m.
Figure 6 and
Figure 7 display the performance of 3-day and 7-day predictions. The results demonstrate that employing single-window area prediction significantly enhances prediction accuracy, with considerable differences in accuracy observed across different regions.
In addition, the spatial distribution of errors in the 3-day prediction is relatively uniform, while in the 7-day prediction, the spatial distribution of errors is more uneven.
Figure 8 depicts the distribution of errors for 3-day and 7-day prediction. The results indicate that the error for the 3-day predictions was nearly always below 0.01 m, whereas the accuracy of the 7-day prediction was slightly lower.
5.4. Mesoscale Eddy Prediction Results
In this section, we tested and evaluated the predictions of mesoscale eddies in the Kuroshio Extension region. We utilized the model from
Section 4.2 to predict the sea level anomaly (SLA) gridded data for the Kuroshio Extension region for the period from 8 February 2022 to 31 July 2022. The test areas were as follows: (Area 1: 27.875°N~40.125°N, 166.125°E~153.875°E) and (Area 2: 27.875°N~40.125°N, 178.125°E~165.875°E), corresponding to the Region 2 and 3 cropping of a 50 × 50 center area mentioned in
Section 5.3.2. We applied the AMEDA algorithm to detect mesoscale eddies in both predicted and ground truth sea level anomaly (SLA) series and compared the results from both sets of eddy detections. The performance evaluation will focus on the deviation of the eddy center and the prediction of the mesoscale eddies’ lifespan.
Figure 9 shows examples of eddy detection results with SLA maps. The result demonstrates that our method accurately predicts larger mesoscale eddies, but may inaccurately predict or fail to predict the location of some smaller mesoscale eddies.
First, we conducted a statistical analysis of the total detection counts for cyclonic and anticyclonic eddies.
Figure 10 shows the total counts of cyclonic and anticyclonic eddies for different datasets. We found that the original dataset had the highest detection capabilities for eddies, followed by the 3-day prediction and the 7-day prediction, which detected fewer eddies. We found that this method performs less well for smaller eddies, primarily due to the lag in predicting the appearance of eddies and the tendency to anticipate the disappearance of eddies.
We matched the actual and predicted positions of the eddy centers at the same time and location to evaluate the performance of the eddy prediction. To address the problem of aligning predicted and actual eddy center positions, we transformed the sets of predicted and actual eddy centers for each day into a bipartite graph. We then determined the minimum-weight matching by considering the actual distances between the points. During the construction of the bipartite graph, edges with real distances (edge weights) exceeding 100 km are ignored due to the significant deviation of eddy centers, which may likely not represent a correct match.
Table 6 presents the results of the evaluation of eddy prediction after matching. In the 3-day prediction, Area 1 achieved an Average Center Distance of 4.5566 km and a Match Rate of 94.02%, while Area 2 had an Average Center Distance of 6.6462 km and a Match Rate of 92.48%. In the 7-day prediction, Area 1 achieved an Average Center Distance of 11.6794 km and a Match Rate of 86.57%, while Area 2 had an Average Center Distance of 15.5567 km and a Match Rate of 82.28%. As the prediction time increases, the difficulty of prediction also rises, resulting in lower accuracy of the predicted eddy. The decrease in match rate is associated with lagging predictions of eddy appearance and a loss of image details, leading to undetectable eddies.
Figure 11 illustrates the distribution of distances between the predicted eddy centers and the actual values. We found that predicting mesoscale eddies using the 3-day prediction of sea surface height has very high accuracy. Most of the predicted eddy centers deviated from the true values by less than 20 km. However, the accuracy slightly decreased in the 7-day prediction, and the match rate also declined. Combining with the results in
Figure 9, this may be attributed to the higher difficulty in predicting sea surface height, leading to inaccuracies in the reflected eddy information in the predicted SSH data.
Table 7 presents a comparison of various mesoscale eddy prediction methods, including our proposed IAM4VP with ME approach. The methods are evaluated based on the datasets used, the geographical data range, the average center offset distance at different time offsets, and their ability to predict the generation and disappearance of mesoscale eddies.
Among the compared methods, our IAM4VP with ME approach demonstrated superior performance in terms of the average center offset distance, achieving 5.6267 km at a 3-day time offset and 13.6315 km at a 7-day time offset. Furthermore, our method was capable of predicting both the generation and disappearance of mesoscale eddies, a feature that is only shared by the Enhanced MIM method. The other methods, such as LSTM and ET and MesoGRU, do not provide this capability. In conclusion, our IAM4VP with ME approach exhibited high performance in mesoscale eddy prediction, offering accurate predictions of eddy center positions and the ability to forecast the generation and disappearance of eddies.
6. Conclusions
In our study, we employed a deep learning SSH prediction model to predict sea surface height. Then, we utilized the predicted sea surface height data for eddy detection to predict mesoscale eddies. For the sea surface height prediction, we incorporated ADT and SLA data from CMEMS, and integrated geostrophic velocity data as the training dataset. We constructed a sea surface height prediction model based on the deep learning model IAM4VP and incorporated a Metadata Embedding module to enable the model to learn the patterns of sea surface height variations in different regions and times. The experimental results demonstrated that the fusion of velocity data and the Metadata Embedding module enhanced the performance of the sea surface height prediction model. Furthermore, in addition to training the model with large-area sea surface height data, we also explored the use of a fixed small area for single-window area SSH prediction. This approach allowed the model to focus on prior knowledge within the same geographical location and predict the sea surface height exclusively within that small region, significantly improving prediction accuracy. Our model obtained RMSE values of 0.0033 m and 0.0030 m, as well as MAE values of 0.0025 m and 0.0023 m, respectively, in two chosen regions for 3-day prediction. For the 7-day prediction in two regions, we achieved RMSE 0.0097 m and 0.0087 m, with MAE 0.0076 m and 0.0061 m. The empirical results validated that our model outperformed the best-known models of the same type. Lastly, we employed the AMEDA algorithm to perform eddy detection on the predicted sea surface height data and thus obtained the prediction results for mesoscale eddies. We analyzed the errors in the 3-day and 7-day prediction results in comparison to the ground truth values. The results indicate that both the 3-day and 7-day predictions have high accuracy. In the 3-day prediction in two selected areas, the average distance of the eddy center deviation reached 4.5566 km and 6.6462 km, while in the 7-day prediction, it reached 11.6794 km and 15.5567 km.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}