
Channel Prediction for Underwater Acoustic Communication: A Review and Performance Evaluation of Algorithms





Abstract
:1. Introduction
- We introduce the application of UWA channel prediction technology in UWA communication.
- This paper classifies current UWA channel prediction techniques and introduces its principles, implementation methods, and specific applications.
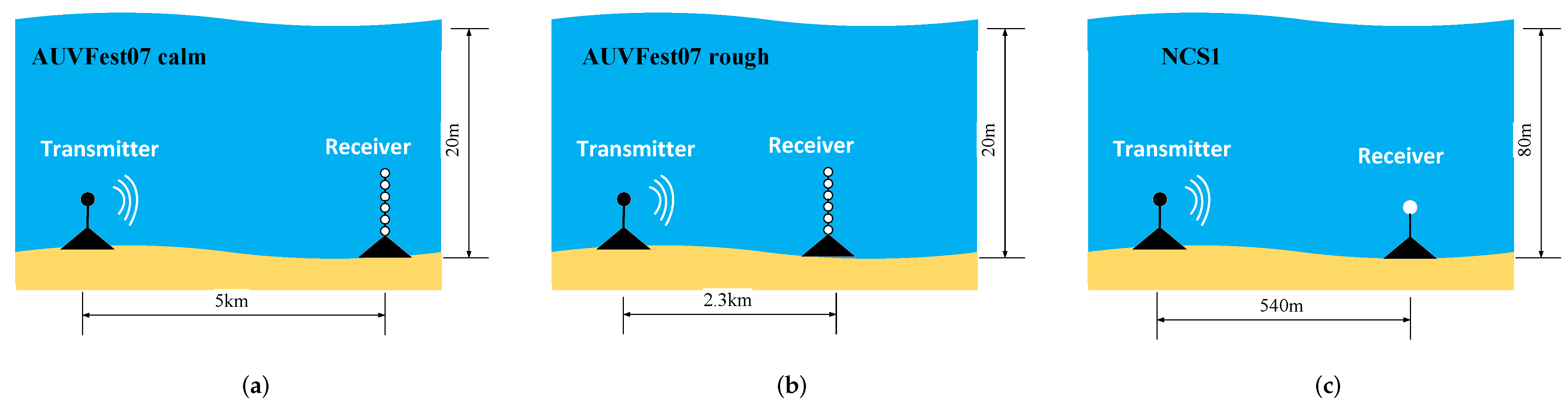
- Based on the at-sea experiment dataset from the 2007 Autonomous Underwater Vehicle Festival (AUVFest07) [24] and the UnderWater AcousTic channEl Replay benchMARK (Watermark) [25], we comprehensively compare the existing typical underwater acoustic channel prediction algorithms under a unified system framework, and objectively analyze the prediction performance and computational complexity of these algorithms.
- We analyze the advantages and limitations of different algorithms based on the experimental results. Additionally, we discuss the existing challenges and potential future development directions of UWA channel prediction.
2. Algorithms for Underwater Acoustic Channel Prediction
2.1. Linear Algorithms
| Algorithm 1 RLS prediction algorithm |
| Input: Output: Initialization: ,
|
| Algorithm 2 MMSE prediction algorithm |
| Input: Output:
|
| Algorithm 3 ES prediction algorithm |
| Input: Output: Initialization:
|
2.2. Kernel-Based Algorithms
| Algorithm 4 KRLS prediction algorithm |
| Input: Output: Initialization: ,
|
| Algorithm 5 SVR prediction algorithm |
| Input: training set testing set Output: training process: Set the values of b, , C, and use the training set to obtain the best . predicting process:
|
2.3. Deep Learning Algorithms
| Algorithm 6 CNN prediction algorithm |
| Input: training set testing set Output: training process: Set the values of , convolution kernel size, batch size, epoch, learning rate, loss function. Use the training set to obtain the best model. predicting process:
|
| Algorithm 7 LSTM prediction algorithm |
| Input: training set testing set Output: training process: Set the number of hidden layers, the number of hidden layer units, batch size, epoch, learning rate, loss function. Use the training set to obtain the best model. predicting process:
|
3. Experimental Evaluation
3.1. Dataset Description
3.2. Experimental Process
4. Experimental Results and Analysis
5. Conclusions
5.1. Discussion
5.2. Future Prospects
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sendra, S.; Lloret, J.; Jimenez, J.M.; Parra, L. Underwater acoustic modems. IEEE Sens. J. 2015, 16, 4063–4071. [Google Scholar] [CrossRef]
- Zia, M.Y.I.; Poncela, J.; Otero, P. State-of-the-art underwater acoustic communication modems: Classifications, analyses and design challenges. Wirel. Pers. Commun. 2021, 116, 1325–1360. [Google Scholar] [CrossRef]
- Stojanovic, M. Underwater acoustic communications: Design considerations on the physical layer. In Proceedings of the 2008 Fifth Annual Conference on Wireless on Demand Network Systems and Services, Garmisch-Pertenkirchen, Germany, 23–25 January 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–10. [Google Scholar]
- Radosevic, A.; Duman, T.M.; Proakis, J.G.; Stojanovic, M. Channel prediction for adaptive modulation in underwater acoustic communications. In Proceedings of the OCEANS 2011 IEEE-Spain, Santander, Spain, 6–9 June 2011; pp. 1–5. [Google Scholar]
- Rice, J.A.; Mcdonald, V.K.; Green, D.; Porta, D. Adaptive modulation for undersea acoustic telemetry. Sea Technol. 1999, 40, 29–36. [Google Scholar]
- Benson, A.; Proakis, J.; Stojanovic, M. Towards robust adaptive acoustic communications. In Proceedings of the OCEANS 2000 MTS/IEEE Conference and Exhibition. Conference Proceedings, Providence, RI, USA, 11–14 September 2000; Volume 2, pp. 1243–1249. [Google Scholar]
- Mani, S.; Duman, T.M.; Hursky, P. Adaptive coding-modulation for shallow-water UWA communications. J. Acoust. Soc. Am. 2008, 123, 3749. [Google Scholar] [CrossRef]
- Tomasi, B.; Toni, L.; Casari, P.; Rossi, L.; Zorzi, M. Performance study of variable-rate modulation for underwater communications based on experimental data. In Proceedings of the OCEANS 2010 MTS/IEEE SEATTLE, Seattle, WA, USA, 20–23 September 2010; pp. 1–8. [Google Scholar]
- Qarabaqi, P.; Stojanovic, M. Adaptive power control for underwater acoustic communications. In Proceedings of the OCEANS 2011 IEEE-Spain, Santander, Spain, 6–9 June 2011; pp. 1–7. [Google Scholar]
- Pelekanakis, K.; Cazzanti, L. On adaptive modulation for low SNR underwater acoustic communications. In Proceedings of the OCEANS 2018 MTS/IEEE Charleston, Charleston, SC, USA, 22–25 October 2018; pp. 1–6. [Google Scholar]
- Huda, M.; Putri, N.B.; Santoso, T.B. OFDM system with adaptive modulation for shallow water acoustic channel environment. In Proceedings of the 2017 IEEE International Conference on Communication, Networks and Satellite, Semarang, Indonesia, 5–7 October 2017; pp. 55–58. [Google Scholar]
- Barua, S.; Rong, Y.; Nordholm, S.; Chen, P. Adaptive modulation for underwater acoustic OFDM communication. In Proceedings of the OCEANS 2019-Marseille, Marseille, France, 17–20 June 2019; pp. 1–5. [Google Scholar]
- Zhang, R.; Ma, X.; Wang, D.; Yuan, F.; Cheng, E. Adaptive coding and bit-power loading algorithms for underwater acoustic transmissions. IEEE Trans. Wirel. Commun. 2021, 20, 5798–5811. [Google Scholar] [CrossRef]
- Qiao, G.; Liu, L.; Ma, L.; Yin, Y. Adaptive downlink OFDMA system with low-overhead and limited feedback in time-varying underwater acoustic channel. IEEE Access 2019, 7, 12729–12741. [Google Scholar] [CrossRef]
- Radosevic, A.; Duman, T.M.; Proakis, J.G.; Stojanovic, M. Adaptive OFDM for underwater acoustic channels with limited feedback. In Proceedings of the 2011 Conference Record of the Forty Fifth Asilomar Conference on Signals, Systems and Computers (ASILOMAR), Pacific Grove, CA, USA, 6–9 November 2011; pp. 975–980. [Google Scholar]
- Cheng, X.; Yang, L.; Cheng, X. Adaptive relay-aided OFDM underwater acoustic communications. In Proceedings of the 2015 IEEE International Conference on Communications (ICC), London, UK, 8–12 June 2015; pp. 1535–1540. [Google Scholar]
- Liu, Y.; Blostein, S.D. Identification of frequency non-selective fading channels using decision feedback and adaptive linear prediction. IEEE Trans. Commun. 1995, 43, 1484–1492. [Google Scholar]
- Duel-Hallen, A. Fading channel prediction for mobile radio adaptive transmission systems. Proc. IEEE 2007, 95, 2299–2313. [Google Scholar] [CrossRef]
- Schafhuber, D.; Matz, G. MMSE and adaptive prediction of time-varying channels for OFDM systems. IEEE Trans. Wirel. Commun. 2005, 4, 593–602. [Google Scholar] [CrossRef]
- Falahati, S.; Svensson, A.; Ekman, T.; Sternad, M. Adaptive modulation systems for predicted wireless channels. IEEE Trans. Commun. 2004, 52, 307–316. [Google Scholar] [CrossRef]
- Oien, G.; Holm, H.; Hole, K.J. Impact of channel prediction on adaptive coded modulation performance in Rayleigh fading. IEEE Trans. Veh. Technol. 2004, 53, 758–769. [Google Scholar] [CrossRef]
- Ding, T.; Hirose, A. Fading channel prediction based on combination of complex-valued neural networks and chirp Z-transform. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 1686–1695. [Google Scholar] [CrossRef]
- Luo, C.; Ji, J.; Wang, Q.; Chen, X.; Li, P. Channel state information prediction for 5G wireless communications: A deep learning approach. IEEE Trans. Netw. Sci. Eng. 2018, 7, 227–236. [Google Scholar] [CrossRef]
- Huang, S.; Yang, T.; Huang, C.F. Multipath correlations in underwater acoustic communication channels. J. Acoust. Soc. Am. 2013, 133, 2180–2190. [Google Scholar] [CrossRef] [PubMed]
- van Walree, P.A.; Socheleau, F.X.; Otnes, R.; Jenserud, T. The watermark benchmark for underwater acoustic modulation schemes. IEEE J. Ocean. Eng. 2017, 42, 1007–1018. [Google Scholar] [CrossRef]
- Radosevic, A.; Ahmed, R.; Duman, T.M.; Proakis, J.G.; Stojanovic, M. Adaptive OFDM modulation for underwater acoustic communications: Design considerations and experimental results. IEEE J. Ocean. Eng. 2013, 39, 357–370. [Google Scholar] [CrossRef]
- Ma, L.; Xiao, F.; Li, M. Research on time-varying sparse channel prediction algorithm in underwater acoustic channels. In Proceedings of the 2019 3rd International Conference on Electronic Information Technology and Computer Engineering (EITCE), Xiamen, China, 18–20 October 2019; pp. 2014–2018. [Google Scholar]
- Lin, N.; Sun, H.; Cheng, E.; Qi, J.; Kuai, X.; Yan, J. Prediction based sparse channel estimation for underwater acoustic OFDM. Appl. Acoust. 2015, 96, 94–100. [Google Scholar] [CrossRef]
- Cheng, E.; Lin, N.; Sun, H.; Yan, J.; Qi, J. Precoding based channel prediction for underwater acoustic OFDM. China Ocean. Eng. 2017, 31, 256–260. [Google Scholar] [CrossRef]
- Zhang, Y.; Venkatesan, R.; Dobre, O.A.; Li, C. Efficient estimation and prediction for sparse time-varying underwater acoustic channels. IEEE J. Ocean. Eng. 2019, 45, 1112–1125. [Google Scholar] [CrossRef]
- Sun, W.; Wang, Z. Modeling and prediction of large-scale temporal variation in underwater acoustic channels. In Proceedings of the OCEANS 2016-Shanghai, Shanghai, China, 10–13 April 2016; pp. 1–6. [Google Scholar]
- Aval, Y.M.; Wilson, S.K.; Stojanovic, M. On the achievable rate of a class of acoustic channels and practical power allocation strategies for OFDM systems. IEEE J. Ocean. Eng. 2015, 40, 785–795. [Google Scholar] [CrossRef]
- Kuai, X.; Sun, H.; Qi, J.; Cheng, E.; Xu, X.; Guo, Y.; Chen, Y. CSI feedback-based CS for underwater acoustic adaptive modulation OFDM system with channel prediction. China Ocean. Eng. 2014, 28, 391–400. [Google Scholar] [CrossRef]
- Brown, R.G.; Meyer, R.F. The fundamental theorem of exponential smoothing. Oper. Res. 1961, 9, 673–685. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, C.; Sun, W. Adaptive transmission scheduling in time-varying underwater acoustic channels. In Proceedings of the OCEANS 2015-MTS/IEEE Washington, Washington, DC, USA, 19–22 October 2015; pp. 1–6. [Google Scholar]
- Li, Y.; Li, B.; Zhang, Y. A channel state information feedback and prediction scheme for time-varying underwater acoustic channels. In Proceedings of the 2018 International Conference on Intelligent Transportation, Big Data & Smart City (ICITBS), Xiamen, China, 25–26 January 2018; pp. 141–144. [Google Scholar]
- Iltis, R.A. A sparse Kalman filter with application to acoustic communications channel estimation. In Proceedings of the OCEANS 2006, Boston, MA, USA, 18–22 September 2006; pp. 1–5. [Google Scholar]
- Tao, J.; Wu, Y.; Wu, Q.; Han, X. Kalman filter based equalization for underwater acoustic communications. In Proceedings of the OCEANS 2019-Marseille, Marseille, France, 17–20 June 2019; pp. 1–5. [Google Scholar]
- Huang, Q.; Li, W.; Zhan, W.; Wang, Y.; Guo, R. Dynamic underwater acoustic channel tracking for correlated rapidly time-varying channels. IEEE Access 2021, 9, 50485–50495. [Google Scholar] [CrossRef]
- Huang, S.H.; Tsao, J.; Yang, T.; Cheng, S.W. Model-based signal subspace channel tracking for correlated underwater acoustic communication channels. IEEE J. Ocean. Eng. 2013, 39, 343–356. [Google Scholar] [CrossRef]
- Huang, S.; Yang, T.; Tsao, J. Improving channel estimation for rapidly time-varying correlated underwater acoustic channels by tracking the signal subspace. Ad Hoc Netw. 2015, 34, 17–30. [Google Scholar] [CrossRef]
- Yang, G.; Yin, J.; Huang, D.; Jin, L.; Zhou, H. A Kalman filter-based blind adaptive multi-user detection algorithm for underwater acoustic networks. IEEE Sens. J. 2015, 16, 4023–4033. [Google Scholar] [CrossRef]
- Petroni, A.; Scarano, G.; Cusani, R.; Biagi, M. On the Effect of Channel Knowledge in Underwater Acoustic Communications: Estimation, Prediction and Protocol. Electronics 2023, 12, 1552. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Liu, W.; Pokharel, P.P.; Principe, J.C. The kernel least-mean-square algorithm. IEEE Trans. Signal Process. 2008, 56, 543–554. [Google Scholar] [CrossRef]
- Engel, Y.; Mannor, S.; Meir, R. The kernel recursive least-squares algorithm. IEEE Trans. Signal Process. 2004, 52, 2275–2285. [Google Scholar] [CrossRef]
- Liu, W.; Príncipe, J.C. Kernel affine projection algorithms. EURASIP J. Adv. Signal Process. 2008, 2008, 784292. [Google Scholar] [CrossRef]
- Van Vaerenbergh, S.; Santamaría, I. A comparative study of kernel adaptive filtering algorithms. In Proceedings of the 2013 IEEE Digital Signal Processing and Signal Processing Education Meeting (DSP/SPE), Napa, CA, USA, 11–14 August 2013; pp. 181–186. [Google Scholar]
- Van Vaerenbergh, S.; Via, J.; Santamaría, I. A sliding-window kernel RLS algorithm and its application to nonlinear channel identification. In Proceedings of the 2006 IEEE International Conference on Acoustics Speech and Signal Processing Proceedings, Toulouse, France, 14–19 May 2006; Volume 5, pp. V–V. [Google Scholar]
- Van Vaerenbergh, S.; Santamaría, I.; Liu, W.; Príncipe, J.C. Fixed-budget kernel recursive least-squares. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; pp. 1882–1885. [Google Scholar]
- Ma, W.; Duan, J.; Man, W.; Zhao, H.; Chen, B. Robust kernel adaptive filters based on mean p-power error for noisy chaotic time series prediction. Eng. Appl. Artif. Intell. 2017, 58, 101–110. [Google Scholar] [CrossRef]
- Shi, L.; Tan, J.; Wang, J.; Li, Q.; Lu, L.; Chen, B. Robust kernel adaptive filtering for nonlinear time series prediction. Signal Process. 2023, 210, 109090. [Google Scholar] [CrossRef]
- Shi, L.; Lu, R.; Liu, Z.; Yin, J.; Chen, Y.; Wang, J.; Lu, L. An Improved Robust Kernel Adaptive Filtering Method for Time Series Prediction. IEEE Sens. J. 2023. [Google Scholar] [CrossRef]
- Ai, X.; Zhao, J.; Zhang, H.; Sun, Y. Sparse Sliding-Window Kernel Recursive Least-Squares Channel Prediction for Fast Time-Varying MIMO Systems. Sensors 2022, 22, 6248. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Cai, L.; Ma, L.; Qiao, G. Channel state information prediction for adaptive underwater acoustic downlink OFDMA system: Deep neural networks based approach. IEEE Trans. Veh. Technol. 2021, 70, 9063–9076. [Google Scholar] [CrossRef]
- Liu, L.; Ma, C.; Duan, Y. Channel temporal correlation-based optimization method for imperfect underwater acoustic channel state information. Phys. Commun. 2023, 58, 102021. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Xinhua, Z.; Zhenbo, L.; Chunyu, K. Underwater acoustic targets classification using support vector machine. In Proceedings of the International Conference on Neural Networks and Signal Processing, 2003, Nanjing, China, 14–17 December 2003; Volume 2, pp. 932–935. [Google Scholar]
- Zhang, G.; Yang, L.; Chen, L.; Zhao, B.; Li, Y.; Wei, W. Blind equalization algorithm for underwater acoustic channel based on support vector regression. In Proceedings of the 2019 11th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 24–25 August 2019; Volume 2, pp. 163–166. [Google Scholar]
- Sapankevych, N.I.; Sankar, R. Time series prediction using support vector machines: A survey. IEEE Comput. Intell. Mag. 2009, 4, 24–38. [Google Scholar] [CrossRef]
- Huang, J.; Diamant, R. Adaptive modulation for long-range underwater acoustic communication. IEEE Trans. Wirel. Commun. 2020, 19, 6844–6857. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Lim, B.; Zohren, S. Time-series forecasting with deep learning: A survey. Philos. Trans. R. Soc. A 2021, 379, 20200209. [Google Scholar] [CrossRef]
- Borovykh, A.; Bohte, S.; Oosterlee, C.W. Conditional time series forecasting with convolutional neural networks. arXiv 2017, arXiv:1703.04691. [Google Scholar]
- Lim, B.; Zohren, S.; Roberts, S. Recurrent neural filters: Learning independent bayesian filtering steps for time series prediction. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Jiang, W.; Schotten, H.D. Neural network-based fading channel prediction: A comprehensive overview. IEEE Access 2019, 7, 118112–118124. [Google Scholar] [CrossRef]
- Jiang, W.; Schotten, H.D. Deep learning for fading channel prediction. IEEE Open J. Commun. Soc. 2020, 1, 320–332. [Google Scholar] [CrossRef]
- Jiang, W.; Schotten, H.D. Recurrent neural networks with long short-term memory for fading channel prediction. In Proceedings of the 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Antwerp, Belgium, 25–28 May 2020; pp. 1–5. [Google Scholar]
- Wang, X.; Jiao, J.; Yin, J.; Zhao, W.; Han, X.; Sun, B. Underwater sonar image classification using adaptive weights convolutional neural network. Appl. Acoust. 2019, 146, 145–154. [Google Scholar] [CrossRef]
- Lucas, E.; Wang, Z. Performance prediction of underwater acoustic communications based on channel impulse responses. Appl. Sci. 2022, 12, 1086. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhu, J.; Liu, Y.; Wang, B. Underwater Acoustic Adaptive Modulation with Reinforcement Learning and Channel Prediction. In Proceedings of the 15th International Conference on Underwater Networks & Systems, Shenzhen, China, 22–24 November 2021; pp. 1–2. [Google Scholar]
- Zhu, Z.; Tong, F.; Zhou, Y.; Zhang, Z.; Zhang, F. Deep Learning Prediction of Time-Varying Underwater Acoustic Channel Based on LSTM with Attention Mechanism. J. Mar. Sci. Appl. 2023, 22, 650–658. [Google Scholar] [CrossRef]
- Yang, T. Properties of underwater acoustic communication channels in shallow water. J. Acoust. Soc. Am. 2012, 131, 129–145. [Google Scholar] [CrossRef]
- van Walree, P.; Otnes, R.; Jenserud, T. Watermark: A realistic benchmark for underwater acoustic modems. In Proceedings of the 2016 IEEE Third Underwater Communications and Networking Conference (UComms), Lerici, Italy, 30 August–1 September 2016; pp. 1–4. [Google Scholar]
- Yang, T. Measurements of temporal coherence of sound transmissions through shallow water. J. Acoust. Soc. Am. 2006, 120, 2595–2614. [Google Scholar] [CrossRef]
- Berger, C.R.; Wang, Z.; Huang, J.; Zhou, S. Application of compressive sensing to sparse channel estimation. IEEE Commun. Mag. 2010, 48, 164–174. [Google Scholar] [CrossRef]
- Bajwa, W.U.; Haupt, J.; Sayeed, A.M.; Nowak, R. Compressed channel sensing: A new approach to estimating sparse multipath channels. Proc. IEEE 2010, 98, 1058–1076. [Google Scholar] [CrossRef]
- Qiao, G.; Song, Q.; Ma, L.; Sun, Z.; Zhang, J. Channel prediction based temporal multiple sparse bayesian learning for channel estimation in fast time-varying underwater acoustic OFDM communications. Signal Process. 2020, 175, 107668. [Google Scholar] [CrossRef]
- Yang, Q.; Mashhadi, M.B.; Gündüz, D. Deep convolutional compression for massive MIMO CSI feedback. In Proceedings of the 2019 IEEE 29th international workshop on machine learning for signal processing (MLSP), Pittsburgh, PA, USA, 13–16 October 2019; pp. 1–6. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acronym | Full Name | Acronym | Full Name |
|---|---|---|---|
| UWA | underwater acoustic | CS | compressed sensing |
| CSI | channel state information | SNR | signal-to-noise ratio |
| BER | bit error ratio | NMSE | normalized mean square error |
| CIR | channel impulse response | KAF | kernel adaptive filter |
| OFDM | orthogonal frequency-division multiplexing | KRLS | kernel recursive least squares |
| RLS | recursive least squares | SVM | support vector machine |
| MMSE | minimum mean square error | SVR | support vector regression |
| LMMSE | linear minimum mean square error | RNN | recurrent neural networks |
| ES | exponential smoothing | LSTM | long short-term memory |
| Variable | Definition |
|---|---|
| P | Number of channel taps (number of predictors) |
| M | Number of historical channels for prediction |
| N | Predicting the channel after N steps |
| Number of training set channels | |
| Number of testing set channels | |
| Estimated channel at time n | |
| Predicted channel at time n + N | |
| Estimated channel at time n + N, which is used to calculate the channel prediction error | |
| Input of the predictor for the p-th tap | |
| Output of the predictor for the p-th tap | |
| Estimate value of the p-th tap at the time n + N, which is used to calculate the predictor error |
| Algorithm | Algorithm Classification | Whether the Algorithm Needs Historical Channel Data to Train |
|---|---|---|
| RLS [4] | Linear Algorithm | No |
| LMMSE [33] | Linear Algorithm | No |
| ES [36] | Linear Algorithm | No |
| Kalman filtering [43] | Linear Algorithm | No |
| KRLS [56] | Kernel-Based Algorithm | No |
| SVR [62] | Kernel-Based Algorithm | Yes |
| LSTM [73] | Deep Learning Algorithm | Yes |
| Algorithm | AUVFest07 Calm | AUVFest07 Rough | NCS1 |
|---|---|---|---|
| Outdated data | 0.0995 | 0.8952 | 0.4097 |
| RLS | 0.0792 | 0.7190 | 0.3700 |
| LMMSE | 0.0754 | 0.6312 | 0.3352 |
| ES | 0.0826 | 0.7992 | 0.4080 |
| Kalman filtering | 0.0811 | 0.6697 | 0.3363 |
| KRLS | 0.0784 | 0.6593 | 0.3496 |
| SVR | 0.2640 | 0.6276 | 0.3147 |
| LSTM | 0.2125 | 0.6128 | 0.3054 |
| Algorithm | RLS | LMMSE | ES | Kalman Filtering | KRLS | SVR | LSTM |
|---|---|---|---|---|---|---|---|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Ma, L.; Wang, Z.; Qiao, G. Channel Prediction for Underwater Acoustic Communication: A Review and Performance Evaluation of Algorithms. Remote Sens. 2024, 16, 1546. https://doi.org/10.3390/rs16091546
Liu H, Ma L, Wang Z, Qiao G. Channel Prediction for Underwater Acoustic Communication: A Review and Performance Evaluation of Algorithms. Remote Sensing. 2024; 16(9):1546. https://doi.org/10.3390/rs16091546
Chicago/Turabian StyleLiu, Haotian, Lu Ma, Zhaohui Wang, and Gang Qiao. 2024. "Channel Prediction for Underwater Acoustic Communication: A Review and Performance Evaluation of Algorithms" Remote Sensing 16, no. 9: 1546. https://doi.org/10.3390/rs16091546
APA StyleLiu, H., Ma, L., Wang, Z., & Qiao, G. (2024). Channel Prediction for Underwater Acoustic Communication: A Review and Performance Evaluation of Algorithms. Remote Sensing, 16(9), 1546. https://doi.org/10.3390/rs16091546