
Advancements in Vision–Language Models for Remote Sensing: Datasets, Capabilities, and Enhancement Techniques

 and
and
Abstract
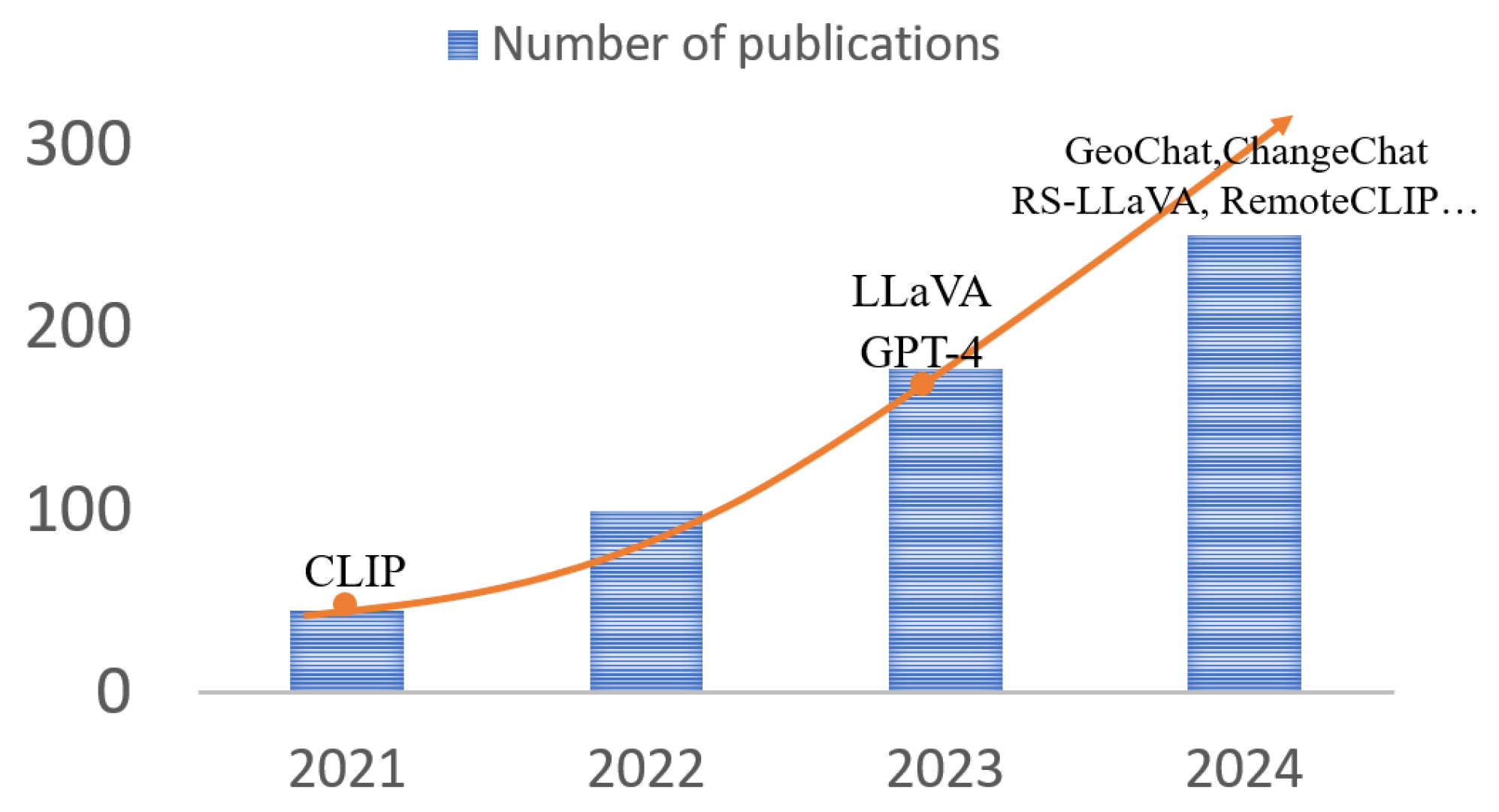
1. Introduction
2. Foundation Models
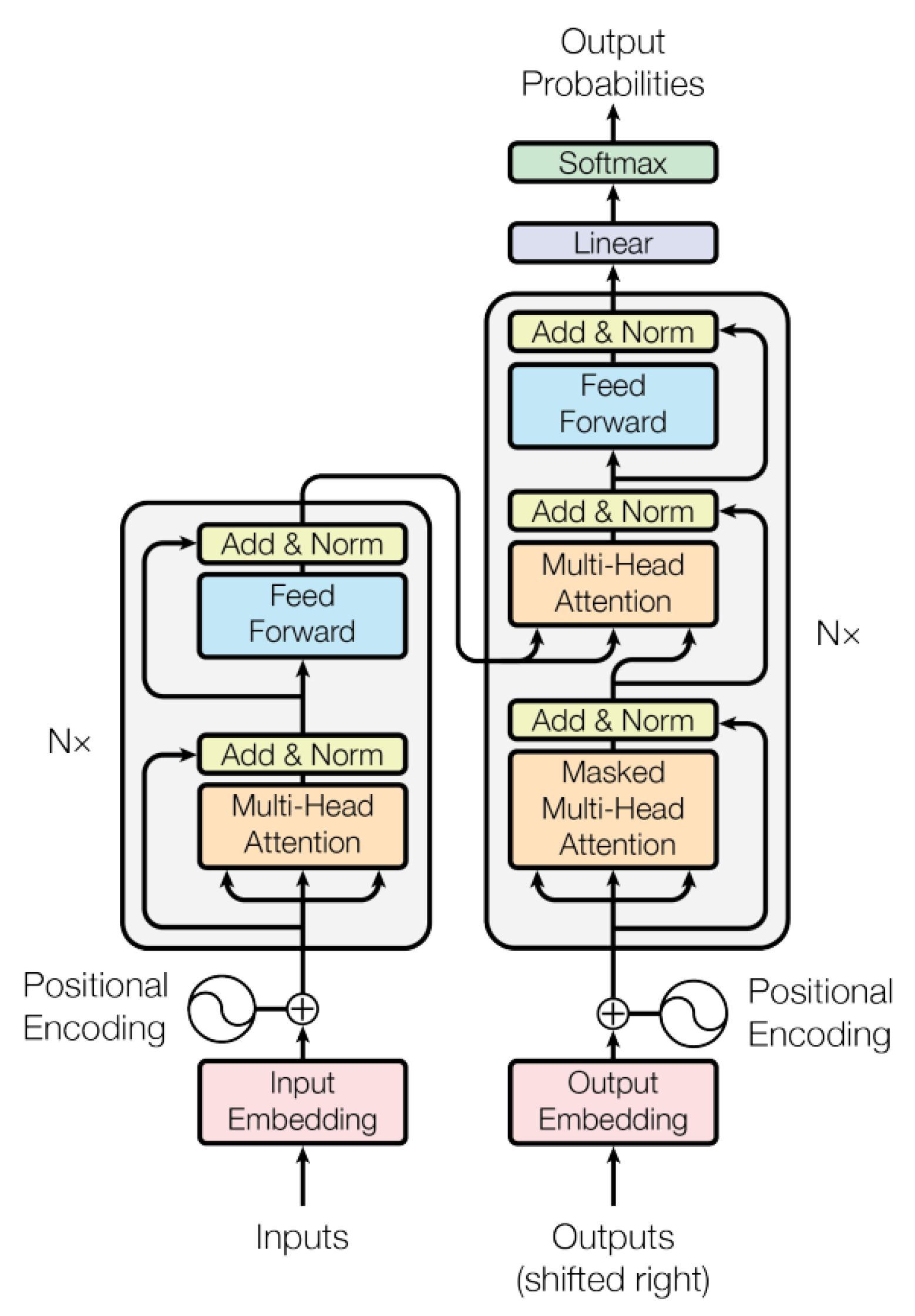
2.1. Transformer
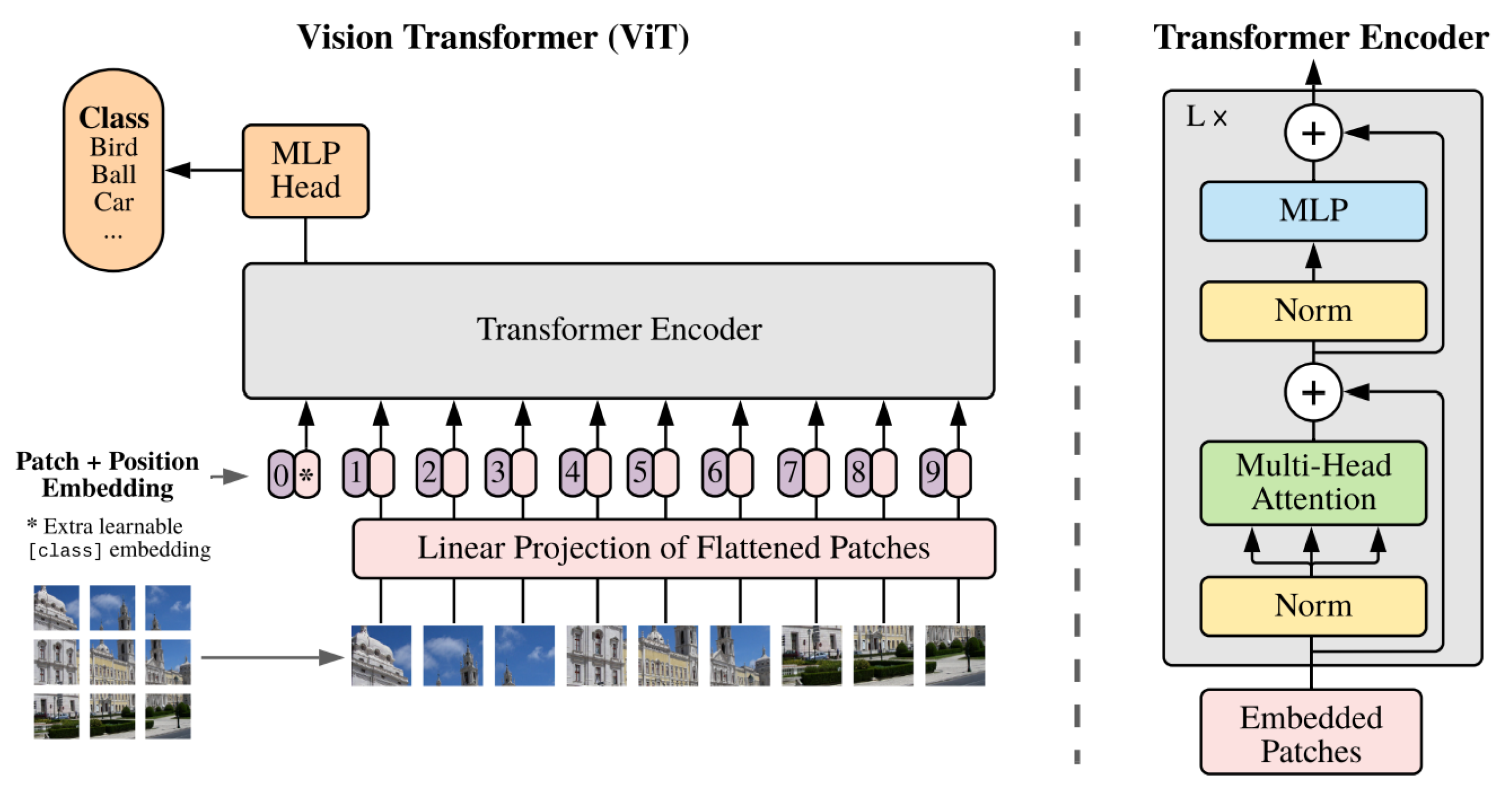
2.2. Vision Transformer
2.3. Vision–Language Models
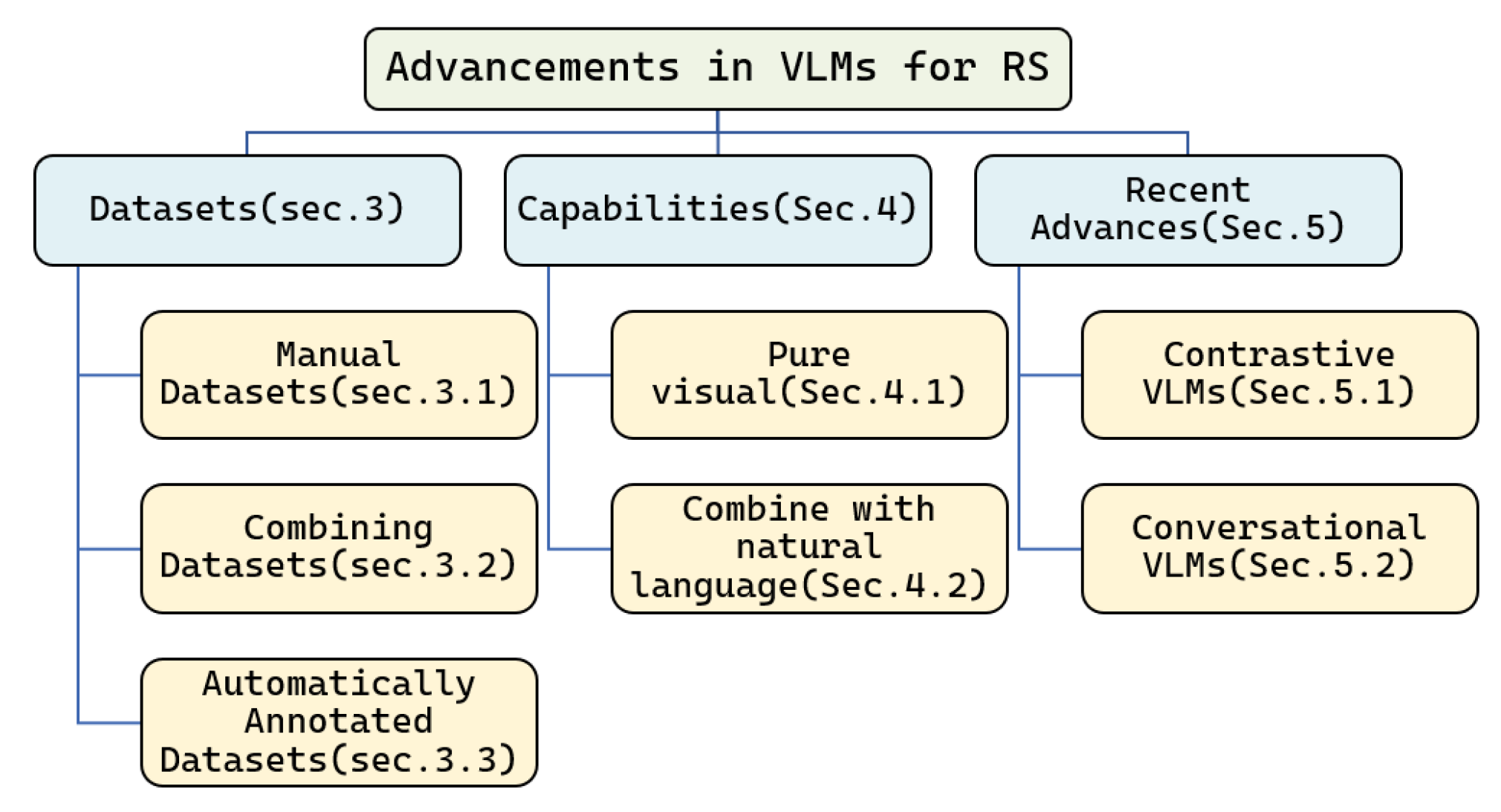
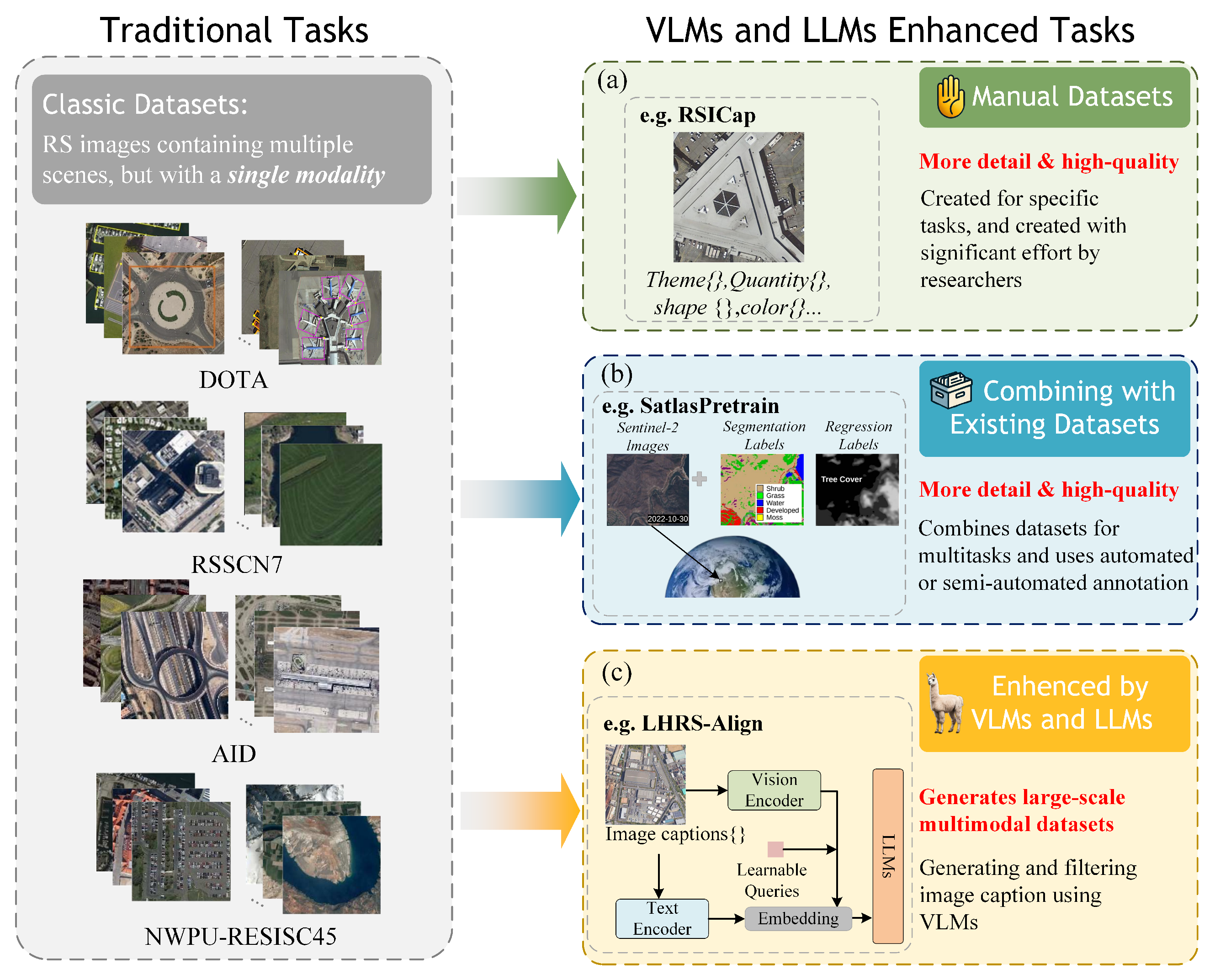
3. Datasets
- Manual datasets, which are completely manually annotated by humans based on specific task requirements.
- Combined datasets, which are built by combining several existing datasets and adding part-new language annotations.
- Automatically annotated datasets. This type of data construction involves minimal human participation and relies on various multimodal models for filtering and annotating image data.
3.1. Manual Datasets
3.2. Combining Datasets
3.3. Automatically Annotated Datasets
3.4. Summary
- Manually annotated datasets generally have higher quality and are most closely aligned with specific problems. But these datasets, typically consisting of only a few hundred or thousand images, are limited in scale compared to combined datasets and VLM datasets, which can reach tens of millions of images. The size of a dataset is crucial for model training, as larger and richer datasets yield more accurate and versatile models. Manually annotated datasets can be used to fine-tune large models, but they struggle to support training large models from scratch.
- Combined datasets. By merging existing datasets, large-scale datasets can be constructed at a low cost. This type of data can easily reach millions of entries. However, datasets created in this manner typically have lower annotation quality compared to manually annotated datasets and may not fully align with specific tasks. Nonetheless, they can be utilized for model pre-training.
- Automatically annotated datasets. Mainstream VLM dataset production methods leverage state-of-the-art LLMs and VLMs to generate high-quality captions or annotations for large-scale remote sensing images. This approach produces flexible image–text pairs, including long sentences, comments, and local descriptions, without requiring human supervision, thus meeting the needs of various tasks. Researchers may need to craft prompts and commands to guide LLMs and VLMs in generating the desired texts.
4. Capabilities
4.1. Pure Visual
- Scene Classification (SC): RS Scene Classification entails the classification of satellite or aerial images into distinct land-cover or land-use categories with the objective of deriving valuable insights about the Earth’s surface. It offers valuable information regarding the spatial distribution and temporal changes in various land-cover categories, such as forests, agricultural fields, water bodies, urban areas, and natural landscapes. The three most commonly used datasets in this field are AID [69], NWPU-RESISC45 [70] and UCM [71], which contain 10,000, 31,500, and 2100 images, and 30, 45, and 21 categories, respectively.
- Object Detection (OD): RSOD aims to determine whether or not objects of interest exist in a given RSI and return the category and position of each predicted object. In this domain, the most widely used datasets are DOTA [81] and DIOR [73]. DOTA [81] contains 2806 aerial images which are annotated by experts in aerial image interpretation, with respect to 15 common object categories. DIOR [73] contains 23,463 images and 192,472 instances, covering 20 object classes, with much more detail than DOTA [81].
- Semantic Segmentation (SS): Semantic segmentation is a computer vision task in which the goal is to categorize each pixel in an image into a class or object. For RS images, it plays an irreplaceable role in disaster assessment, crop yield estimation, and land change monitoring. The most widely used datasets are ISPRS Vaihingen and Potsdam, which contain 33 true orthophoto (TOP) images and 38 image tiles with a spatial resolution of 5 cm, respectively. Another widely used dataset iSAID [74] contains 2806 aerial images, which were mainly collected from Google Earth.
- Change Detection (CD): Change Detection in remote sensing refers to the process of identifying differences in the structure of objects and phenomena on Earth surface by analyzing two or more images taken at different times. It plays an important role in urban expansion, deforestation, and damage assessment. LEVIR-CD [75], AICD [82] and the Google Data Set focus on changes in buildings. Other types of changes such as roads and groundwork are commonly included in CD datasets.
- Object Counting (OC): RSOC aims to automatically estimate the number of object instances in an RSI. It plays an important role in many areas, such as urban planning, disaster response and assessment, environment control, and mapping. RemoteCount [29] is a manual dataset for object counting in remote sensing imagery consisting of 947 image–text pairs and 13 categories, which are mainly selected from the validation set of the DOTA dataset.
4.2. Combine with Natural Language
- Image Retrieval (IR): IR from RS aims to retrieve RS images of interest from massive RS image repositories. With the launch of more and more Earth observation satellites and the emergence of large-scale remote sensing datasets, RS image retrieval can prepare auxiliary data or narrow the search space for a large number of RS image processing tasks.
- Visual Question Answering (VQA): VQA is a task that seeks to provide answers to free-form and open-ended questions about a given image. As the questions can be unconstrained, a VQA model applied to remote sensing data could serve as a generic solution to classical problems but also very specific tasks involving relations between objects of different nature [83]. VQA was first proposed by Anto et al. [84] in 2015, and then applied to the RS domain by RSVQA [68] in 2020. This work contributed an RSVQA framework and two VQA datasets, RSVQA-LR and RSVQA-HR, which are widely utilized in further works.
- Image Captioning (IC): IC aims to generate natural language descriptions that summarize the content of an image. It requires representing the semantic relationships among objects and generating an exact and descriptive sentence, so it is more complex and challenging than image detection, classification, and segmentation tasks. In this domain, the commonly used datasets are Syndney-Captions [85], RSICD [86], NWPU-Captions [87], and UCM-Captions [85]. Recently, CapERA [88] provided UAV video with diverse textual descriptions to advance visual–language-understanding tasks.
- Visual Grounding (VG): RSVG aims to localize specific objects in remote sensing images with the guidance of natural language. It was first introduced in [89] in 2022. In 2023, Yang [51] et al. not only built the new large-scale benchmark of RSVG based on detection in the DIOR dataset, termed RSVGD, but designed a novel transformer-based MGVLF module to address the problems of scale variation and cluttered background in RS images.
- Remote Sensing Image Change Captioning (RSICC): A new task aiming to generate human-like language descriptions for the land-cover changes in multitemporal RS images. It is a combination of IC and CD tasks, offering important application prospects in damage assessment, environmental protection, and land planning. Chenyang et al. [90] first introduced the CC task into the RS domain in 2022 and proposed a large-scale dataset LEVIR-CC, containing 10,077 pairs of bitemporal RS images and 50,385 sentences describing the differences between the images. In 2023, they proposed a pure Transformer-based model [91] to further improve the performance of the RSICC task.
- Referring Remote Sensing Image Segmentation (RRSIS): RRSIS provides a pixel-level mask of desired objects based on the content of given remote sensing images and natural language expressions. It was first proposed by Zhenghang et al. [52] in 2024, who created a new dataset, called RefSegRS, for this task. In the same year, Sihan et al. [57] curated an expansive dataset comprising 17,402 image–caption–mask triplets, called RRSIS-D, and proposed a series of models to meet the ubiquitous rotational phenomena in RRSIS.
5. Recent Advances
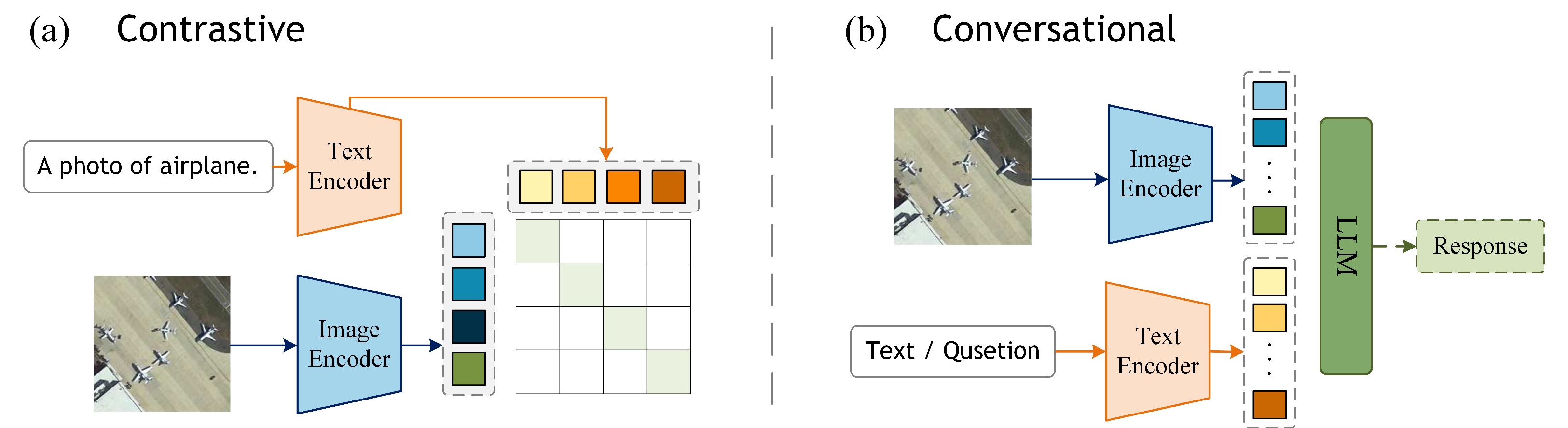
5.1. Advancements in Contrastive VLMs
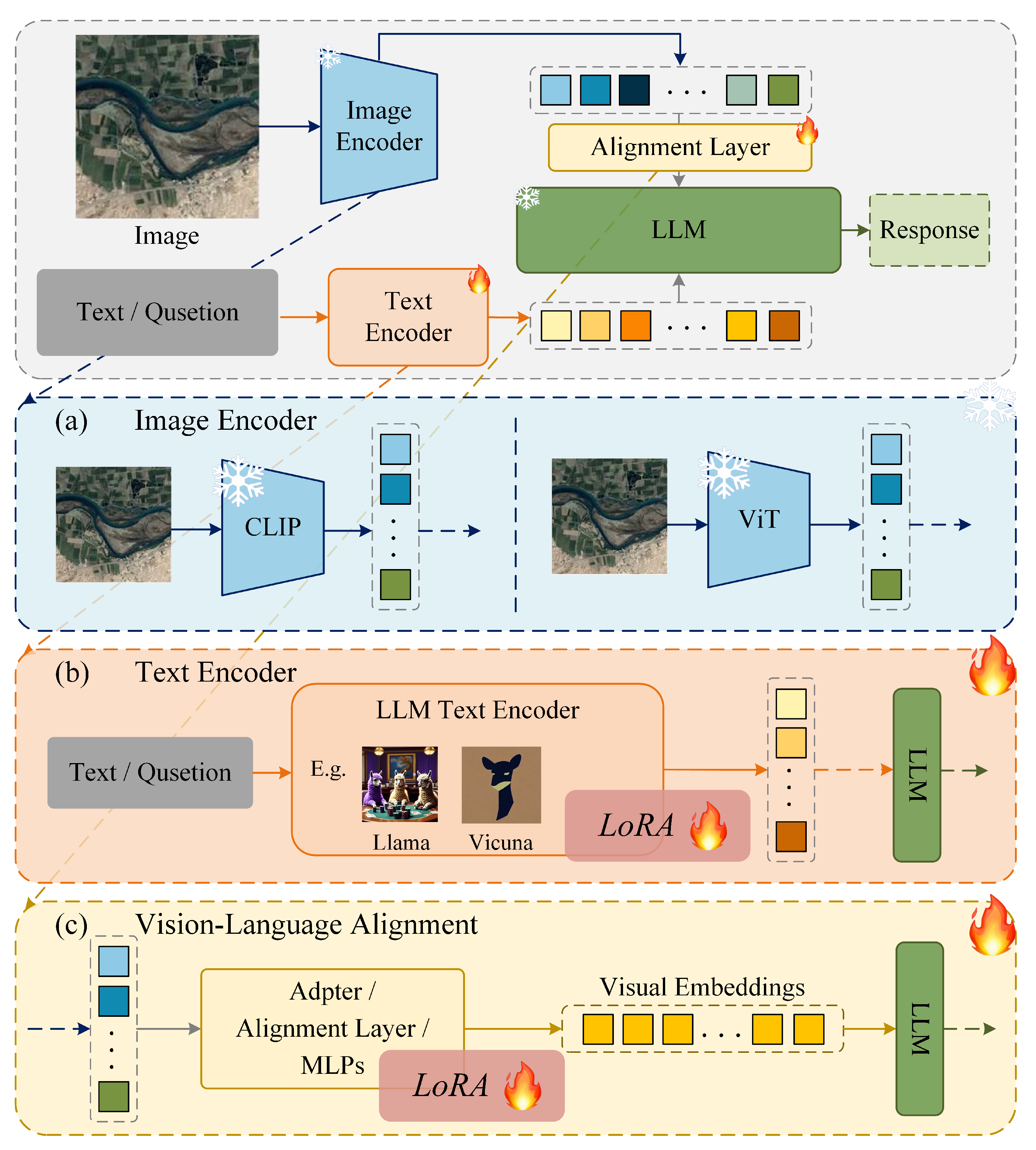
5.2. Advancements in Conversational VLMs
5.3. Other Models

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Year | Enhancement Technique |
|---|---|---|
| Txt2Img [104] | 2023 | Employs modern Hopfield layers for hierarchical prototype learning of text and image embeddings. |
| CPSeg [105] | 2024 | Utilizes a “chain of thought” process that leverages textual information associated with the image. |
| SHRNet [106] | 2023 | Utilizes a hash-based architecture to extract multi-scale image features. |
| MGeo [107] | 2023 | Introduces the geographic environment (GC) extracting multimodal correlations for accurate query–POI matching. |
| GeoCLIP [108] | 2023 | Via an image-to-GPS retrieval approach by explicitly aligning image features with corresponding GPS locations. |
| SpectralGPT [109] | 2024 | Provides a foundational model for the spectral data based on the MAE [110] architecture. |
| TEMO [112] | 2023 | Captures long-term dependencies from description sentences of varying lengths, generating text-modal features for each category. |
5.4. Performance Comparison
6. Conclusions and Future Work
- Addressing regression problems. Currently, the mainstream approach in VLM typically involves using a tokenizer to vectorize text, aligning the visual information with word vectors, and then feeding these into LLMs. However, this method fails to capture numerical relationships effectively, which leads to problems in regression tasks. For instance, a number like ‘100’ may be tokenized as ‘1’, ‘00’, or ‘100’, causing loss of precision and affecting regression accuracy. Future work should focus on enhancing VLMs for regression tasks by addressing this limitation. One promising direction is to develop specialized tokenizers for numerical values, which would ensure more accurate representation of numbers in text. Additionally, exploring the integration of task-specific regression heads into the existing VLM framework can help the model achieve a more efficient inference process. For example, REO-VLM [116] designs a regression head with a four-layer MLP-mixer-like structure that integrates knowledge embeddings derived from LLM hidden tokens with complex visual tokens. This innovative approach enables VLMs to effectively handle regression tasks such as Above-Ground Biomass (AGB) [117,118] estimation in Earth observation (EO) applications. Task-specific regression heads enable the model to directly output data in formats that meet the specific requirements of the task, rather than being limited to regression on text tokens. Moreover, these heads can be dynamically adjusted based on the needs of different tasks, making the regression output more accurate and efficient. Introducing the Mixture of Experts (MOE) architecture to improve the adaptability and accuracy of regression tasks is also an excellent choice. When deployed in VLMs, it can use a gating mechanism to dynamically match the appropriate expert modules for different tasks, enabling the model to effectively handle multi-task learning with sufficient capability.
- Aligning with the structural characteristics of remote sensing images. Current VLMs in remote sensing largely adopt frameworks developed for conventional computer vision tasks and rely on models pre-trained exclusively on RGB imagery, thereby failing to fully account for the distinctive structural and spectral characteristics of remote sensing data. This limitation is particularly evident for modalities such as SAR and HSI, where crucial features remain poorly captured by general-purpose extractors. As a result, while existing VLMs may perform reasonably well on RGB data, they struggle with SAR and HSI inputs and often depend on superficial fine-tuning with limited datasets. To address this gap, future research should emphasize both the design of specialized feature extractors tailored to the complexities of multispectral and SAR data, and the development of algorithms capable of handling multidimensional inputs. REO-VLM [116] makes effective attempts by introducing spectral recombination and pseudo-RGB strategies. It splits the high-dimensional MS image into multiple three-channel images and generates a third channel for the SAR images, which typically contain two polarization channels, thus creating a pseudo-RGB representation compatible with the pre-trained visual encoder. Expanding and diversifying remote sensing datasets to include large-scale image–text pairs from multiple modalities (e.g., RGB, SAR, HSI, LiDAR) will be essential for training VLMs that can achieve robust visual–text alignment across all data types. By integrating richer and more comprehensive feature representations, as well as exploring data fusion strategies, it will be possible to enhance VLM performance in a wide range of complex remote sensing applications, including land-use classification, urban monitoring, and disaster response.
- Multimodal output. Early methods, such as classification models, were constrained by their output format and thus limited to a single task. Although most current VLMs, which produce text outputs, have broadened their scope and can effectively handle numerous tasks, they still fall short for dense prediction tasks like segmentation and Change Detection. To overcome this limitation, future research should focus on enabling VLMs to produce truly multimodal outputs—such as images, videos, and even 3D data. Recent studies have begun exploring the enhancement of traditional proprietary models by adding a text branch as an auxiliary component, thereby fostering richer multimodal feature interaction and improving image feature extraction and interpretation while preserving existing output heads. Building on this idea, another promising direction is to use a VLM as an agent that interfaces with multiple specialized model output heads and activates the most suitable one based on the task identified, thus effectively combining the reasoning power of LLMs with the expertise of dedicated models. In addition, a recent insightful approach is to use next-token prediction to achieve multimodal output. For example, Emu3 [119] adopts a completely next-token prediction-based architecture, avoiding the complex diffusion models or combinatorial methods used in the past. It innovatively uses visual tokens as part of the output to generate images and videos, and outperforms well-known open-source models.
- Multitemporal Regression and Trend Inference. Current VLM research in the remote sensing field often focuses solely on static images, overlooking the potential of multitemporal data. Since remote sensing data can capture information that changes over time, future research should explore how to extend VLMs to handle multitemporal regression tasks. This involves not only spatial feature recognition but also the ability to infer temporal trends and dynamics. A key research direction is to develop methods that utilize historical remote sensing data to analyze and predict long-term environmental or ecological changes. This is particularly important for applications such as climate change monitoring, land-use change prediction, and ecosystem management, where temporal patterns play a crucial role. Remote sensing images with temporal continuity can be encoded as sequences, providing multitemporal data as input for training VLMs. By adding multitemporal regression capabilities to VLMs, the model could provide more context-aware predictions, improving the accuracy of long-term environmental assessments.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yang, K. Progress, Challenge and Prospect for Remote Sensing Monitoring of Flood and Drought Disasters in China. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 4280–4283. [Google Scholar] [CrossRef]
- Shahtahmassebi, A.R.; Li, C.; Fan, Y.; Wu, Y.; Lin, Y.; Gan, M.; Wang, K.; Malik, A.; Blackburn, G.A. Remote sensing of urban green spaces: A review. Urban For. Urban Green. 2021, 57, 126946. [Google Scholar] [CrossRef]
- Tan, C.; Cao, Q.; Li, Y.; Zhang, J.; Yang, X.; Zhao, H.; Wu, Z.; Liu, Z.; Yang, H.; Wu, N.; et al. On the Promises and Challenges of Multimodal Foundation Models for Geographical, Environmental, Agricultural, and Urban Planning Applications. arXiv 2023, arXiv:2312.17016. [Google Scholar]
- Meng, L.; Yan, X.H. Remote Sensing for Subsurface and Deeper Oceans: An overview and a future outlook. IEEE Geosci. Remote Sens. Mag. 2022, 10, 72–92. [Google Scholar] [CrossRef]
- Parra, L. Remote sensing and GIS in environmental monitoring. Appl. Sci. 2022, 12, 8045. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. arXiv 2015, arXiv:1412.0767. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zhang, Y.; Ye, M.; Zhu, G.; Liu, Y.; Guo, P.; Yan, J. FFCA-YOLO for small object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5611215. [Google Scholar] [CrossRef]
- Zhang, J.; Li, S.; Long, T. Enhanced Target Detection: Fusion of SPD and CoTC3 Within YOLOv5 Framework. IEEE Trans. Geosci. Remote Sens. 2025, 63, 3000114. [Google Scholar] [CrossRef]
- Liu, H.; He, J.; Li, Y.; Bi, Y. Multilevel Prototype Alignment for Cross-Domain Few-Shot Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2025, 63, 4400115. [Google Scholar] [CrossRef]
- Xie, Y.; Liu, S.; Chen, H.; Cao, S.; Zhang, H.; Feng, D.; Wan, Q.; Zhu, J.; Zhu, Q. Localization, Balance, and Affinity: A Stronger Multifaceted Collaborative Salient Object Detector in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2025, 63, 4700117. [Google Scholar] [CrossRef]
- Zhou, H.; Wang, Y.; Liu, W.; Tao, D.; Ma, W.; Liu, B. MSC-GAN: A Multistream Complementary Generative Adversarial Network with Grouping Learning for Multitemporal Cloud Removal. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5400117. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2023, arXiv:1706.03762. [Google Scholar]
- OpenAI. ChatGPT. 2023. Available online: https://chatgpt.com/ (accessed on 5 October 2024).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NaacL-HLT, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Wang, A.; Pruksachatkun, Y.; Nangia, N.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Lewis, M.; Zettlemoyer, L. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), Association for Computational Linguistics, Brussels, Belgium, 31 October–4 November 2018; pp. 3531–3541. [Google Scholar]
- Williams, A.; Nangia, N.; Bowman, S.R. A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference. arXiv 2018, arXiv:1704.05426. [Google Scholar]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. SQuAD: 100,000+ Questions for Machine Comprehension of Text. arXiv 2016, arXiv:1606.05250. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- OpenAI. GPT-3: Language Models Are Few-Shot Learners. 2020. Available online: https://openai.com/research/gpt-3 (accessed on 5 October 2024).
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models from Natural Language Supervision. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Li, L.H.; Zhang, P.; Zhang, H.; Yang, J.; Li, C.; Zhong, Y.; Wang, L.; Yuan, L.; Zhang, L.; Hwang, J.N.; et al. Grounded Language-Image Pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Liu, H.; Li, C.; Wu, Q.; Lee, Y.J. Visual instruction tuning. Adv. Neural Inf. Process. Syst. 2023, 36, 34892–34916. [Google Scholar]
- OpenAI. GPT-4. 2023. Available online: https://openai.com/research/gpt-4 (accessed on 5 October 2024).
- Al Rahhal, M.M.; Bazi, Y.; Elgibreen, H.; Zuair, M. Vision-Language Models for Zero-Shot Classification of Remote Sensing Images. Appl. Sci. 2023, 13, 12462. [Google Scholar] [CrossRef]
- Liu, F.; Chen, D.; Guan, Z.; Zhou, X.; Zhu, J.; Ye, Q.; Fu, L.; Zhou, J. Remoteclip: A vision language foundation model for remote sensing. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5622216. [Google Scholar] [CrossRef]
- Kuckreja, K.; Danish, M.S.; Naseer, M.; Das, A.; Khan, S.; Khan, F.S. Geochat: Grounded large vision-language model for remote sensing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 27831–27840. [Google Scholar]
- Zhang, Z.; Zhao, T.; Guo, Y.; Yin, J. RS5M and GeoRSCLIP: A Large Scale Vision-Language Dataset and A Large Vision-Language Model for Remote Sensing. arXiv 2024, arXiv:2306.11300. [Google Scholar] [CrossRef]
- Wang, Z.; Prabha, R.; Huang, T.; Wu, J.; Rajagopal, R. Skyscript: A large and semantically diverse vision-language dataset for remote sensing. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 5805–5813. [Google Scholar]
- Wang, L.; Dong, S.; Chen, Y.; Meng, X.; Fang, S. MetaSegNet: Metadata-collaborative Vision-Language Representation Learning for Semantic Segmentation of Remote Sensing Images. arXiv 2023, arXiv:2312.12735. [Google Scholar] [CrossRef]
- Deng, P.; Zhou, W.; Wu, H. ChangeChat: An Interactive Model for Remote Sensing Change Analysis via Multimodal Instruction Tuning. arXiv 2024, arXiv:2409.08582. [Google Scholar]
- Hu, Y.; Yuan, J.; Wen, C.; Lu, X.; Li, X. Rsgpt: A remote sensing vision language model and benchmark. arXiv 2023, arXiv:2307.15266. [Google Scholar]
- Wang, J.; Sun, H.; Tang, T.; Sun, Y.; He, Q.; Lei, L.; Ji, K. Leveraging Visual Language Model and Generative Diffusion Model for Zero-Shot SAR Target Recognition. Remote Sens. 2024, 16, 2927. [Google Scholar] [CrossRef]
- Zheng, Z.; Ermon, S.; Kim, D.; Zhang, L.; Zhong, Y. Changen2: Multi-Temporal Remote Sensing Generative Change Foundation Model. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: Piscataway, NJ, USA, 2024; pp. 1–17. [Google Scholar] [CrossRef]
- Ageospatial. GeoForge. 2024. Available online: https://medium.com/@ageospatial/geoforge-geospatial-analysis-with-large-language-models-geollms-2d3a0eaff8aa (accessed on 20 February 2024).
- Li, X.; Wen, C.; Hu, Y.; Yuan, Z.; Zhu, X.X. Vision-Language Models in Remote Sensing: Current progress and future trends. IEEE Geosci. Remote Sens. Mag. 2024, 12, 32–66. [Google Scholar] [CrossRef]
- Shaw, P.; Uszkoreit, J.; Vaswani, A.; Parmar, N.; Kiros, R.; Uszkoreit, J.; Jones, L. Self-Attention with Relative Position Representations. In Proceedings of the 35th International Conference on Machine Learning (ICML), PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 5687–5695. [Google Scholar]
- Zhang, Y.; Yu, X.; Yang, J.; Zhang, Y.; Hu, X. Conditional Position Embedding for Neural Machine Translation. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, Seattle, WA, USA, 10–15 July 2022; pp. 1641–1651. [Google Scholar]
- Su, J.; Zhang, H.; Li, X.; Zhang, J.; Li, Y. RoFormer: Enhanced Transformer with Rotary Position Embedding. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL-IJCNLP), Association for Computational Linguistics, Online, 1–6 August 2021; pp. 1915–1925. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Hu, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Touvron, H.; Cord, M.; Sablayrolles, A.; Dehghani, G. Training data-efficient image transformers & distillation through attention. In Proceedings of the 9th International Conference on Learning Representations (ICLR), Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Yan, D.; Li, P.; Li, Y.; Chen, H.; Chen, Q.; Luo, W.; Dong, W.; Yan, Q.; Zhang, H.; Shen, C. TG-LLaVA: Text Guided LLaVA via Learnable Latent Embeddings. arXiv 2024, arXiv:2409.09564. [Google Scholar]
- Liu, F.; Guan, T.; Li, Z.; Chen, L.; Yacoob, Y.; Manocha, D.; Zhou, T. Hallusionbench: You see what you think? or you think what you see? an image-context reasoning benchmark challenging for gpt-4v (ision), llava-1.5, and other multi-modality models. arXiv 2023, arXiv:2310.14566. [Google Scholar]
- Zhang, M.; Chen, F.; Li, B. Multistep Question-Driven Visual Question Answering for Remote Sensing. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4704912. [Google Scholar] [CrossRef]
- Roberts, J.; Han, K.; Albanie, S. Satin: A multi-task metadataset for classifying satellite imagery using vision-language models. arXiv 2023, arXiv:2304.11619. [Google Scholar]
- Mendieta, M.; Han, B.; Shi, X.; Zhu, Y.; Chen, C. Towards geospatial foundation models via continual pretraining. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 16806–16816. [Google Scholar]
- Bastani, F.; Wolters, P.; Gupta, R.; Ferdinando, J.; Kembhavi, A. Satlaspretrain: A large-scale dataset for remote sensing image understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 16772–16782. [Google Scholar]
- Zhan, Y.; Xiong, Z.; Yuan, Y. Rsvg: Exploring data and models for visual grounding on remote sensing data. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5604513. [Google Scholar] [CrossRef]
- Yuan, Z.; Mou, L.; Hua, Y.; Zhu, X.X. Rrsis: Referring remote sensing image segmentation. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 5613312. [Google Scholar] [CrossRef]
- Zhan, Y.; Xiong, Z.; Yuan, Y. Skyeyegpt: Unifying remote sensing vision-language tasks via instruction tuning with large language model. arXiv 2024, arXiv:2401.09712. [Google Scholar]
- Zhang, W.; Cai, M.; Zhang, T.; Zhuang, Y.; Mao, X. Earthgpt: A universal multi-modal large language model for multi-sensor image comprehension in remote sensing domain. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 5917820. [Google Scholar]
- Pang, C.; Wu, J.; Li, J.; Liu, Y.; Sun, J.; Li, W.; Weng, X.; Wang, S.; Feng, L.; Xia, G.S.; et al. H2RSVLM: Towards Helpful and Honest Remote Sensing Large Vision Language Model. arXiv 2024, arXiv:2403.20213. [Google Scholar]
- Zhao, D.; Yuan, B.; Chen, Z.; Li, T.; Liu, Z.; Li, W.; Gao, Y. Panoptic perception: A novel task and fine-grained dataset for universal remote sensing image interpretation. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 5620714. [Google Scholar] [CrossRef]
- Liu, S.; Ma, Y.; Zhang, X.; Wang, H.; Ji, J.; Sun, X.; Ji, R. Rotated multi-scale interaction network for referring remote sensing image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 26658–26668. [Google Scholar]
- Sun, X.; Wang, P.; Lu, W.; Zhu, Z.; Lu, X.; He, Q.; Li, J.; Rong, X.; Yang, Z.; Chang, H.; et al. RingMo: A remote sensing foundation model with masked image modeling. IEEE Trans. Geosci. Remote Sens. 2022, 61, 5612822. [Google Scholar] [CrossRef]
- Mall, U.; Phoo, C.P.; Liu, M.K.; Vondrick, C.; Hariharan, B.; Bala, K. Remote Sensing Vision-Language Foundation Models without Annotations via Ground Remote Alignment. arXiv 2023, arXiv:2312.06960. [Google Scholar]
- Guo, X.; Lao, J.; Dang, B.; Zhang, Y.; Yu, L.; Ru, L.; Zhong, L.; Huang, Z.; Wu, K.; Hu, D.; et al. Skysense: A multi-modal remote sensing foundation model towards universal interpretation for earth observation imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 27672–27683. [Google Scholar]
- Wang, J.; Zheng, Z.; Chen, Z.; Ma, A.; Zhong, Y. Earthvqa: Towards queryable earth via relational reasoning-based remote sensing visual question answering. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 5481–5489. [Google Scholar]
- Dong, Z.; Gu, Y.; Liu, T. Generative ConvNet Foundation Model with Sparse Modeling and Low-Frequency Reconstruction for Remote Sensing Image Interpretation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5603816. [Google Scholar] [CrossRef]
- Muhtar, D.; Li, Z.; Gu, F.; Zhang, X.; Xiao, P. Lhrs-bot: Empowering remote sensing with vgi-enhanced large multimodal language model. arXiv 2024, arXiv:2402.02544. [Google Scholar]
- Li, L.; Ye, Y.; Jiang, B.; Zeng, W. GeoReasoner: Geo-localization with Reasoning in Street Views using a Large Vision-Language Model. In Proceedings of the Forty-First International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024. [Google Scholar]
- Yuan, Z.; Xiong, Z.; Mou, L.; Zhu, X.X. Chatearthnet: A global-scale, high-quality image-text dataset for remote sensing. arXiv 2024, arXiv:2402.11325. [Google Scholar]
- Li, X.; Ding, J.; Elhoseiny, M. VRSBench: A Versatile Vision-Language Benchmark Dataset for Remote Sensing Image Understanding. arXiv 2024, arXiv:2406.12384. [Google Scholar]
- Luo, J.; Pang, Z.; Zhang, Y.; Wang, T.; Wang, L.; Dang, B.; Lao, J.; Wang, J.; Chen, J.; Tan, Y.; et al. Skysensegpt: A fine-grained instruction tuning dataset and model for remote sensing vision-language understanding. arXiv 2024, arXiv:2406.10100. [Google Scholar]
- Lobry, S.; Marcos, D.; Murray, J.; Tuia, D. RSVQA: Visual Question Answering for Remote Sensing Data. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8555–8566. [Google Scholar] [CrossRef]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A Benchmark Data Set for Performance Evaluation of Aerial Scene Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote Sensing Image Scene Classification: Benchmark and State of the Art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 3–5 November 2010; GIS ’10. pp. 270–279. [Google Scholar] [CrossRef]
- Sun, X.; Wang, P.; Yan, Z.; Xu, F.; Wang, R.; Diao, W.; Chen, J.; Li, J.; Feng, Y.; Xu, T.; et al. FAIR1M: A benchmark dataset for fine-grained object recognition in high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2022, 184, 116–130. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Gupta, A.; Khan, S.H.; Sun, G.; Khan, F.S.; Zhu, F.; Shao, L.; Xia, G.; Bai, X. iSAID: A Large-scale Dataset for Instance Segmentation in Aerial Images. arXiv 2019, arXiv:1905.12886. [Google Scholar]
- Chen, H.; Shi, Z. A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image Change Detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Long, Y.; Xia, G.S.; Li, S.; Yang, W.; Yang, M.Y.; Zhu, X.X.; Zhang, L.; Li, D. On Creating Benchmark Dataset for Aerial Image Interpretation: Reviews, Guidances and Million-AID. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4205–4230. [Google Scholar] [CrossRef]
- Li, J.; Li, D.; Savarese, S.; Hoi, S. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In Proceedings of the International Conference on Machine Learning, PMLR, Hangzhou, China, 17–19 February 2023; pp. 19730–19742. [Google Scholar]
- Zheng, L.; Chiang, W.L.; Sheng, Y.; Zhuang, S.; Wu, Z.; Zhuang, Y.; Lin, Z.; Li, Z.; Li, D.; Xing, E.; et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Adv. Neural Inf. Process. Syst. 2024, 36, 46595–46623. [Google Scholar]
- Google. Gemini-1.0-Pro-Vision. 2024. Available online: https://ai.google.dev/docs/gemini_api_overview (accessed on 5 October 2024).
- Zhou, B.; Hu, Y.; Weng, X.; Jia, J.; Luo, J.; Liu, X.; Wu, J.; Huang, L. TinyLLaVA: A Framework of Small-scale Large Multimodal Models. arXiv 2024, arXiv:2402.14289. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar] [CrossRef]
- Han, P.; Ma, C.; Li, Q.; Leng, P.; Bu, S.; Li, K. Aerial image change detection using dual regions of interest networks. Neurocomputing 2019, 349, 190–201. [Google Scholar] [CrossRef]
- Lobry, S.; Tuia, D. Chapter 11 - Visual question answering on remote sensing images. In Advances in Machine Learning and Image Analysis for GeoAI; Prasad, S., Chanussot, J., Li, J., Eds.; Elsevier: Amsterdam, The Netherlands, 2024; pp. 237–254. [Google Scholar] [CrossRef]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D. VQA: Visual Question Answering. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2425–2433. [Google Scholar] [CrossRef]
- Qu, B.; Li, X.; Tao, D.; Lu, X. Deep semantic understanding of high resolution remote sensing image. In Proceedings of the 2016 International Conference on Computer, Information and Telecommunication Systems (CITS), Kunming, China, 6–8 July 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Lu, X.; Wang, B.; Zheng, X.; Li, X. Exploring Models and Data for Remote Sensing Image Caption Generation. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2183–2195. [Google Scholar] [CrossRef]
- Cheng, Q.; Huang, H.; Xu, Y.; Zhou, Y.; Li, H.; Wang, Z. NWPU-Captions Dataset and MLCA-Net for Remote Sensing Image Captioning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5629419. [Google Scholar] [CrossRef]
- Bashmal, L.; Bazi, Y.; Al Rahhal, M.M.; Zuair, M.; Melgani, F. Capera: Captioning events in aerial videos. Remote Sens. 2023, 15, 2139. [Google Scholar] [CrossRef]
- Sun, Y.; Feng, S.; Li, X.; Ye, Y.; Kang, J.; Huang, X. Visual Grounding in Remote Sensing Images. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; MM ’22. pp. 404–412. [Google Scholar] [CrossRef]
- Liu, C.; Zhao, R.; Chen, H.; Zou, Z.; Shi, Z. Remote Sensing Image Change Captioning with Dual-Branch Transformers: A New Method and a Large Scale Dataset. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5633520. [Google Scholar] [CrossRef]
- Liu, C.; Zhao, R.; Chen, J.; Qi, Z.; Zou, Z.; Shi, Z. A decoupling paradigm with prompt learning for remote sensing image change captioning. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 5622018. [Google Scholar] [CrossRef]
- Li, Z.; Zhao, W.; Du, X.; Zhou, G.; Zhang, S. Cross-modal retrieval and semantic refinement for remote sensing image captioning. Remote Sens. 2024, 16, 196. [Google Scholar] [CrossRef]
- Mao, C.; Hu, J. ProGEO: Generating Prompts through Image-Text Contrastive Learning for Visual Geo-localization. arXiv 2024, arXiv:2406.01906. [Google Scholar]
- Dong, S.; Wang, L.; Du, B.; Meng, X. ChangeCLIP: Remote sensing change detection with multimodal vision-language representation learning. ISPRS J. Photogramm. Remote Sens. 2024, 208, 53–69. [Google Scholar] [CrossRef]
- Singha, M.; Jha, A.; Solanki, B.; Bose, S.; Banerjee, B. Applenet: Visual attention parameterized prompt learning for few-shot remote sensing image generalization using clip. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Mo, S.; Kim, M.; Lee, K.; Shin, J. S-clip: Semi-supervised vision-language learning using few specialist captions. Adv. Neural Inf. Process. Syst. 2024, 36, 61187–61212. [Google Scholar]
- Li, X.; Wen, C.; Hu, Y.; Zhou, N. RS-CLIP: Zero shot remote sensing scene classification via contrastive vision-language supervision. Int. J. Appl. Earth Obs. Geoinf. 2023, 124, 103497. [Google Scholar] [CrossRef]
- Sun, Q.; Fang, Y.; Wu, L.; Wang, X.; Cao, Y. Eva-clip: Improved training techniques for clip at scale. arXiv 2023, arXiv:2303.15389. [Google Scholar]
- Bazi, Y.; Bashmal, L.; Al Rahhal, M.M.; Ricci, R.; Melgani, F. Rs-llava: A large vision-language model for joint captioning and question answering in remote sensing imagery. Remote Sens. 2024, 16, 1477. [Google Scholar] [CrossRef]
- Silva, J.D.; Magalhães, J.; Tuia, D.; Martins, B. Large language models for captioning and retrieving remote sensing images. arXiv 2024, arXiv:2402.06475. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Tong, S.; Liu, Z.; Zhai, Y.; Ma, Y.; LeCun, Y.; Xie, S. Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Dai, W.; Li, J.; LI, D.; Tiong, A.; Zhao, J.; Wang, W.; Li, B.; Fung, P.N.; Hoi, S. InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning. In Advances in Neural Information Processing Systems; Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S., Eds.; Curran Associates, Inc.: Nice, France, 2023; Volume 36, pp. 49250–49267. [Google Scholar]
- Xu, Y.; Yu, W.; Ghamisi, P.; Kopp, M.; Hochreiter, S. Txt2Img-MHN: Remote sensing image generation from text using modern Hopfield networks. IEEE Trans. Image Process. 2023, 32, 5737–5750. [Google Scholar] [CrossRef]
- Li, L. Cpseg: Finer-grained image semantic segmentation via chain-of-thought language prompting. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 513–522. [Google Scholar]
- Zhang, Z.; Jiao, L.; Li, L.; Liu, X.; Chen, P.; Liu, F.; Li, Y.; Guo, Z. A Spatial Hierarchical Reasoning Network for Remote Sensing Visual Question Answering. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4400815. [Google Scholar] [CrossRef]
- Ding, R.; Chen, B.; Xie, P.; Huang, F.; Li, X.; Zhang, Q.; Xu, Y. Mgeo: Multi-modal geographic language model pre-training. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, Taiwan, China, 23–27 July 2023; pp. 185–194. [Google Scholar]
- Vivanco Cepeda, V.; Nayak, G.K.; Shah, M. Geoclip: Clip-inspired alignment between locations and images for effective worldwide geo-localization. Adv. Neural Inf. Process. Syst. 2023, 36, 8690–8701. [Google Scholar]
- Hong, D.; Zhang, B.; Li, X.; Li, Y.; Li, C.; Yao, J.; Yokoya, N.; Li, H.; Ghamisi, P.; Jia, X.; et al. SpectralGPT: Spectral remote sensing foundation model. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 5227–5244. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked Autoencoders Are Scalable Vision Learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. EuroSAT: A Novel Dataset and Deep Learning Benchmark for Land Use and Land Cover Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2217–2226. [Google Scholar] [CrossRef]
- Lu, X.; Sun, X.; Diao, W.; Mao, Y.; Li, J.; Zhang, Y.; Wang, P.; Fu, K. Few-Shot Object Detection in Aerial Imagery Guided by Text-Modal Knowledge. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5604719. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Dai, D.; Yang, W. Satellite Image Classification via Two-Layer Sparse Coding with Biased Image Representation. IEEE Geosci. Remote Sens. Lett. 2011, 8, 173–176. [Google Scholar] [CrossRef]
- Zheng, X.; Wang, B.; Du, X.; Lu, X. Mutual Attention Inception Network for Remote Sensing Visual Question Answering. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5606514. [Google Scholar] [CrossRef]
- Xue, X.; Wei, G.; Chen, H.; Zhang, H.; Lin, F.; Shen, C.; Zhu, X.X. REO-VLM: Transforming VLM to Meet Regression Challenges in Earth Observation. arXiv 2024, arXiv:2412.16583. [Google Scholar]
- Lang, N.; Jetz, W.; Schindler, K.; Wegner, J.D. A high-resolution canopy height model of the Earth. Nat. Ecol. Evol. 2023, 7, 1778–1789. [Google Scholar] [CrossRef] [PubMed]
- Sialelli, G.; Peters, T.; Wegner, J.D.; Schindler, K. AGBD: A Global-scale Biomass Dataset. arXiv 2024, arXiv:2406.04928. [Google Scholar]
- Wang, X.; Zhang, X.; Luo, Z.; Sun, Q.; Cui, Y.; Wang, J.; Zhang, F.; Wang, Y.; Li, Z.; Yu, Q.; et al. Emu3: Next-Token Prediction is All You Need. arXiv 2024, arXiv:2409.18869. [Google Scholar]
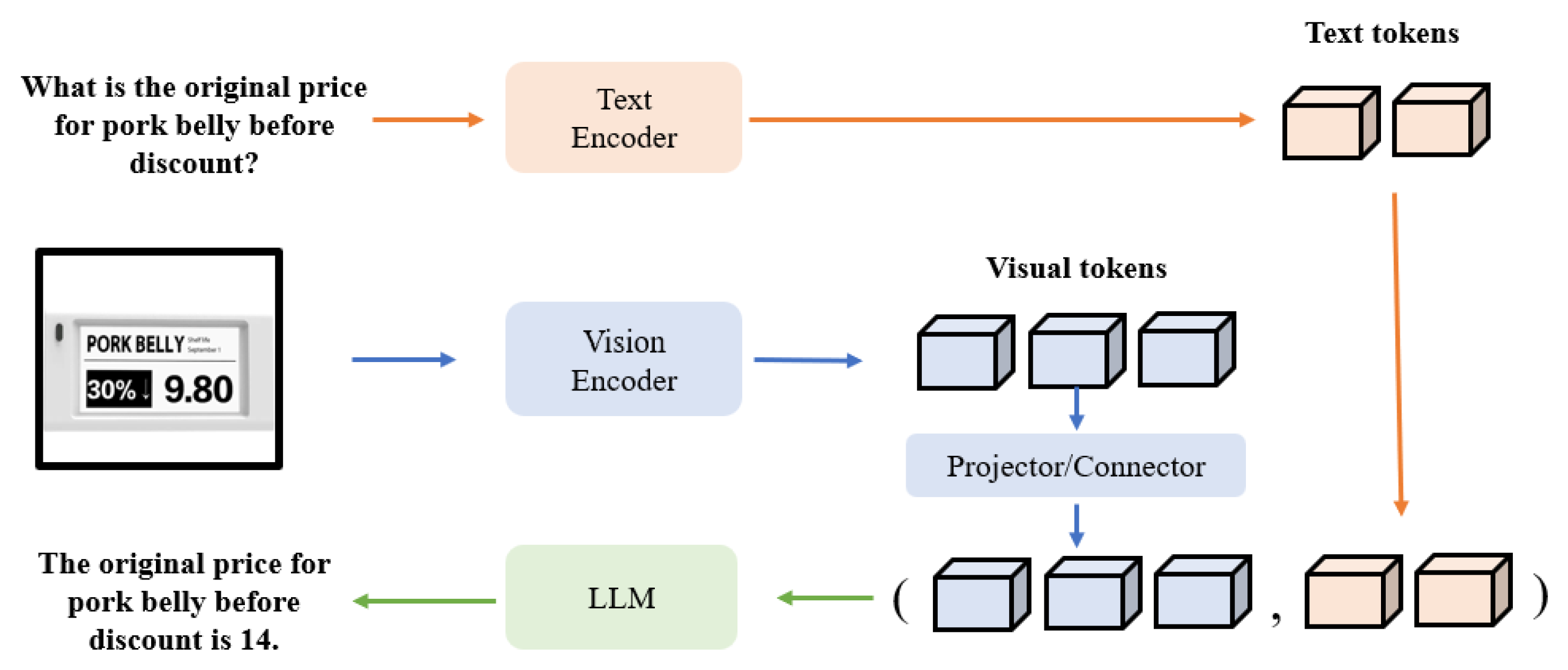


| Method | Dataset | Year | Source | Image | Image Size | Task |
|---|---|---|---|---|---|---|
| Manual Datasets | HallusionBench [46] | 2023 | - | 346 | - | VQA |
| RSICap [35] | 2023 | DOTA | 2585 | 512 | IC | |
| CRSVQA [47] | 2023 | AID | 4639 | 600 | VQA | |
| Combining Datasets | SATIN [48] | 2023 | Million-AID, WHU-RS19, SAT-4, AID 1 | ≈775 K | - | SC |
| GeoPile [49] | 2023 | NAIP, RSD46-WHU, MLRSNet, RESISC45, PatternNet | 600 K | - | - | |
| SatlasPretrain [50] | 2023 | UCM, BigEarthNet, AID, Million-AID, RESISC45, FMoW, DOTA, iSAID | 856 K | 512 | - | |
| RSVGD [51] | 2023 | DIOR | 17,402 | 800 | VG | |
| RefsegRS [52] | 2024 | SkyScapes | 4420 | 512 | RRSIS | |
| SkyEye-968 K [53] | 2024 | RSICD, RSITMD, RSIVQA, RSVG 1 | 968 K | - | - | |
| MMRS-1M [54] | 2024 | AID, RSIVQA, Syndney-Captions 1 | 1 M | - | - | |
| RSSA [55] | 2024 | DOTA-v2, FAIR1M | 44 K | 512 | - | |
| FineGrip [56] | 2024 | MAR20 | 2649 | - | - | |
| RRSIS-D [57] | 2024 | - | 17,402 | 800 | RRSIS | |
| RingMo [58] | 2022 | Gaofen, GeoEye, WorldView, QuickBird 1 | ≈2 M | 448 | - | |
| GRAFT [59] | 2023 | NAIP, Sentinel-2 | - | - | - | |
| SkySense [60] | 2024 | WorldView, Sentinel-1, Sentinel-2 | 21.5 M | - | - | |
| EarthVQA [61] | 2024 | LoveDA, WorldView | 6000 | - | VQA | |
| GeoSense [62] | 2024 | Sentinel-2, Gaofen, Landsat, QuickBird | ≈9 M | 224 | - | |
| Automatically Annotated Datasets | RS5M [31] | 2024 | LAION2B-en, LAION400M, LAIONCOCO 1 | 5M | - | - |
| SkyScript [32] | 2024 | Google Earth Engine, OpenStreetMap | 2.6 M | - | - | |
| LHRS-Align [63] | 2024 | Google Earth Engine, OpenStreetMap | 1.15 M | - | - | |
| GeoChat [30] | 2024 | SAMRS, NWPU-RESISC-45, LRBEN, Floodnet | 318 K | - | - | |
| GeoReasoner [64] | 2024 | Google Street View, OpenStreetMap | 70 K+ | - | StreetView | |
| HqDC-1.4 M [55] | 2024 | Million-AID, CrowdAI, fMoW, CVUSA, CVACT, LoveDA | ≈1.4 M | 512 | - | |
| ChatEarthNet [65] | 2024 | Sentinel-2, WorldCover | 163,488 | 256 | - | |
| VRSBench [66] | 2024 | DOTA-v2, DIOR | 29,614 | 512 | - | |
| FIT-RS [67] | 2024 | STAR | 1800.8 K | 512 | - |
| Model | Year | Image Encoder | Text Encoder | Capability |
|---|---|---|---|---|
| RemoteCLIP [29] | 2024 | ViT-B (CLIP) | Transformer | SC, IC, IR, OC |
| CRSR [92] | 2024 | ViT-B (CLIP) | - | IC |
| ProGEO [93] | 2024 | ViT-B (CLIP) | BERT | VG |
| GRAFT [59] | 2023 | ViT-B (CLIP) | - | SC, VQA, IR |
| GeoRSCLIP [31] | 2024 | ViT-H (CLIP) | - | SC, IR |
| ChangeCLIP [94] | 2024 | CLIP | - | CD |
| APPLeNet [95] | 2023 | CLIP | - | SC, IC |
| MGVLF [51] | 2023 | ResNet-50 | BERT | VG |
| Model | Year | Image Encoder | Text Encoder | Capability |
|---|---|---|---|---|
| RS-LLaVA [99] | 2024 | ViT-L(CLIP) * | Vicuna-v1.5-13B * | IC, VQA |
| H2RSVLM [55] | 2024 | ViT-L (CLIP) * | Vicuna-v1.5-7B * | SC, VQA, VG |
| SkySenseGPT [67] | 2024 | ViT-L (CLIP) * | Vicuna-v1.5-7B ▲ | SC, IC, VQA, OD |
| GeoChat [30] | 2024 | ViT-L (CLIP) * | Vicuna-v1.5-7B ▲ | SC, VQA, VGRegion Caption |
| RSGPT [35] | 2023 | ViT-G (EVA) * | Vicuna-v1.5-7B * | IC, VQA |
| SkyEyeGPT [53] | 2024 | ViT-G (EVA) * | LLaMA2-7B * | IC, VQA, VG |
| RS-CapRet [100] | 2024 | ViT-L (CLIP) ▲ | LLaMA2-7B * | IC, IR |
| LHRS-Bot [63] | 2024 | ViT-L (CLIP) * | LLaMA2-7B * | SC, VQA, VG |
| EarthGPT [54] | 2024 | ViT-L (DINOv2) * ConvNeXt-L (CLIP) * | LLaMA2-7B ▲ | SC, VQA, IC, VG, OD |
| Liu et al. [91] | 2023 | ViT-B(CLIP) * | GPT-2 * | RSICC |
| Category | Model | AID [69] | RSVGD [51] | NWPU-RESISC45 [70] | WHU-RS19 [114] | EuroSAT [111] |
|---|---|---|---|---|---|---|
| Contrastive | RemoteCLIP [29] | 91.30 | - | 79.84 | 96.12 | 60.21 |
| GeoRSCLIP [31] | 76.33 * | - | 73.83 * | - | 67.47 | |
| APPLeNet [95] | - | - | 72.73 * | - | - | |
| GRAFT [59] | - | - | - | - | 63.76 | |
| Conversational | SkySenseGPT [67] | 92.25 | - | - | 97.02 | - |
| LHRS-Bot [63] | 91.26 | 88.10 | - | 93.17 | 51.40 | |
| H2RSVLM [55] | 89.33 | 48.04 * | - | 97.00 | - | |
| GeoChat [30] | 72.03 * | - | - | - | - | |
| SkyEyeGPT [53] | - | 88.59 | - | - | - | |
| EarthGPT [54] | - | 81.54 | 93.84 | - | - | |
| Others | RSVG [51] | - | 78.41 | - | - | - |
| Model | RSVQA-LR [68] | RSVQA-HR [68] | RSIVQA [115] |
|---|---|---|---|
| SkySenseGPT [67] | 92.69 | 76.64 * | - |
| RSGPT [35] | 92.29 | 92.00 | - |
| GeoChat [30] | 90.70 | 72.30 * | - |
| LHRS-Bot [63] | 89.19 | 92.55 | - |
| H2RSVLM [55] | 89.12 | 74.35 * | - |
| RS-LLaVA [99] | 88.56 | - | - |
| SkyEyeGPT [53] | 88.23 | 86.87 | - |
| EarthGPT [54] | - | 72.06 * | - |
| SHRNet [106] 1 | 85.85 | 85.39 | 84.46 |
| MQVQA [47] 1 | - | - | 82.18 |
| Dataset | Model | BLEU1 | BLEU2 | BLEU3 | BLEU4 | METEOR | ROUGEH | CIDEr |
|---|---|---|---|---|---|---|---|---|
| UCM- Captions [71] | CRSR 1 [92] | 90.60 | 85.61 | 81.22 | 76.81 | 49.56 | 85.86 | 380.69 |
| SkyEyeGPT [53] | 90.71 | 85.69 | 81.56 | 78.41 | 46.24 | 79.49 | 236.75 | |
| RS-LLaVA [99] | 90.00 | 84.88 | 80.30 | 76.03 | 49.21 | 85.78 | 355.61 | |
| RSGPT [35] | 86.12 | 79.14 | 72.31 | 65.74 | 42.21 | 78.34 | 333.23 | |
| RS-CapRet [100] | 84.30 | 77.90 | 72.20 | 67.00 | 47.20 | 81.70 | 354.80 | |
| Syndney- Captions [85] | CRSR 1 [92] | 79.94 | 74.4 | 69.87 | 66.02 | 41.50 | 74.88 | 289.00 |
| SkyEyeGPT [53] | 91.85 | 85.64 | 80.88 | 77.40 | 46.62 | 77.74 | 181.06 | |
| RSGPT [35] | 82.26 | 75.28 | 68.57 | 62.23 | 41.37 | 74.77 | 273.08 | |
| RS-CapRet [100] | 78.70 | 70.00 | 62.80 | 56.40 | 38.80 | 70.70 | 239.20 | |
| RSICD [86] | CRSR 1 [92] | 81.92 | 71.71 | 63.07 | 55.74 | 40.15 | 71.34 | 306.87 |
| SkyEyeGPT [53] | 87.33 | 77.70 | 68.90 | 61.99 | 36.23 | 63.54 | 89.37 | |
| RSGPT [35] | 70.32 | 54.23 | 44.02 | 36.83 | 30.1 | 53.34 | 102.94 | |
| RS-CapRet [100] | 72.00 | 59.90 | 50.60 | 43.30 | 37.00 | 63.30 | 250.20 | |
| NWPU- Captions [87] | RS-CapRet [100] | 87.10 | 78.70 | 71.70 | 65.60 | 43.60 | 77.60 | 192.90 |
| EarthGPT [54] | 87.10 | 78.70 | 71.60 | 65.50 | 44.50 | 78.20 | 192.60 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tao, L.; Zhang, H.; Jing, H.; Liu, Y.; Yan, D.; Wei, G.; Xue, X. Advancements in Vision–Language Models for Remote Sensing: Datasets, Capabilities, and Enhancement Techniques. Remote Sens. 2025, 17, 162. https://doi.org/10.3390/rs17010162
Tao L, Zhang H, Jing H, Liu Y, Yan D, Wei G, Xue X. Advancements in Vision–Language Models for Remote Sensing: Datasets, Capabilities, and Enhancement Techniques. Remote Sensing. 2025; 17(1):162. https://doi.org/10.3390/rs17010162
Chicago/Turabian StyleTao, Lijie, Haokui Zhang, Haizhao Jing, Yu Liu, Dawei Yan, Guoting Wei, and Xizhe Xue. 2025. "Advancements in Vision–Language Models for Remote Sensing: Datasets, Capabilities, and Enhancement Techniques" Remote Sensing 17, no. 1: 162. https://doi.org/10.3390/rs17010162
APA StyleTao, L., Zhang, H., Jing, H., Liu, Y., Yan, D., Wei, G., & Xue, X. (2025). Advancements in Vision–Language Models for Remote Sensing: Datasets, Capabilities, and Enhancement Techniques. Remote Sensing, 17(1), 162. https://doi.org/10.3390/rs17010162