Abstract
The inability of existing super-resolution methods to jointly model short-range and long-range spatial dependencies in remote sensing imagery limits reconstruction efficacy. To address this, we propose LSTMConvSR, a novel framework inspired by top-down neural attention mechanisms. Our approach pioneers an LSTM-first–CNN-next architecture. First, an LSTM-based global modeling stage efficiently captures long-range dependencies via downsampling and spatial attention, achieving 80.3% lower FLOPs and 11× faster speed. Second, a CNN-based local refinement stage, guided by the LSTM’s attention maps, enhances details in critical regions. Third, a top-down fusion stage dynamically integrates global context and local features to generate the output. Extensive experiments on Potsdam, UAVid, and RSSCN7 benchmarks demonstrate state-of-the-art performance, achieving 33.94 dB PSNR on Potsdam with 2.4× faster inference than MambaIRv2.
1. Introduction
Remote sensing imagery (RSI) has become indispensable in modern geospatial analysis and has been widely used in many tasks, including object detection [1,2,3], building extraction [4,5], and semantic segmentation [6,7,8,9]. High-resolution images are essential to capture fine-grained details such as road networks, building contours, and vegetation patterns, yet their acquisition is often restricted by hardware limitations (e.g., SAR range ambiguity suppression challenges [10]), atmospheric distortions, and cost constraints [11,12]. Single-image super-resolution (SISR) offers a promising and convenient avenue to mitigate these limitations by computationally reconstructing high-resolution (HR) images from low-resolution (LR) inputs [13,14,15]. While deep learning techniques, particularly Convolutional Neural Networks (CNNs), Vision Transformers, or Vision Mambas, have achieved breakthroughs in image super-resolution (SR), their direct application to remote sensing data remains suboptimal due to the unique characteristics of RSI, where effective reconstruction requires simultaneous modeling of both short-range and long-range spatial dependencies.
Existing methods face several major challenges in adapting to remote sensing scenarios. Conventional CNN-based methods [16,17] prioritize local texture synthesis but fail to model the long-range spatial dependencies inherent to sprawling landscapes such as mountain ranges and river systems. Vision transformers [18] address this limitation through global self-attention mechanisms but suffer from excessive computational costs when processing large-scale remote sensing data. Although approaches such as shift window mechanisms [19], overlapping windows [20], or recursive generalization [21] have enhanced the performance of low-computational-cost transformers in image super-resolution, the trade-off between computational cost and performance remains a significant challenge. Additionally, unlike CNNs or Recurrent Neural Networks (RNNs), Transformers inherently rely on positional encodings to capture sequential order information, as their core attention mechanism lacks inherent perception of input sequences or spatial position differentiation between tokens, which introduces additional complexity in practical applications. The recent introduction of Mamba [22], a novel architecture integrating an RNN-like token mixer with state space models (SSMs), offers a promising approach for tasks demanding long-sequence modeling and autoregressive characteristics [23]. With its inherent linear computational complexity, this architecture demonstrates superior performance in image super-resolution tasks [24,25,26]. Similarly, the Vision-LSTM (ViL) [27] introduces a novel adaptation of xLSTM [28] blocks to vision tasks, employing alternating row-wise processing directions to model non-sequential image patches efficiently. It offers a cost-effective alternative to quadratic-complexity Transformers with linear computational complexity akin to SSMs, while demonstrating enhanced computational efficiency and superior performance compared to Mamba [27]. However, one-dimensional sequential processing models such as Mamba and ViL still require further investigation to enhance their adaptation for two-dimensional image processing tasks, primarily due to their inadequate modeling of short-range dependencies when capturing long-range dependencies, coupled with insufficient capability in establishing comprehensive spatial representations inherent to two-dimensional visual data [24,29]. Therefore, a natural question arises: Can a more efficient yet effective solution be developed to jointly model short-range and long-range spatial dependencies in RSI, thereby achieving superior performance in RSI SR tasks?
This paper proposes LSTMConvSR, a novel framework that synergizes the global contextual awareness of ViLs with the local refinement capability of CNNs through a biologically inspired top-down attention mechanism. The framework establishes a computationally efficient and spatially aware architecture tailored to the unique demands of remote sensing image super-resolution. Our main contributions are summarized as follows:
- We propose LSTMConvSR: a framework of LSTM-first–CNN-next based on top-down neural attention for remote sensing image super-resolution.
- We propose Haar Wavelet Downsampling (HWD) and LSTM Spatial Attention (LSA) in ViL to reduce its computational complexity while maintaining reconstruction performance.
- We propose a Top-down Revisiting Method that cascades LSTM-derived features with CNN-refocused representations through concatenation–projection, establishing an LSTM-first–CNN-next framework with cross-stage feature retrospection.
We demonstrate the empirical validity of LSTMConvSR by comparing it with various competitive models on three RSI benchmark datasets showing SOTA results. Furthermore, we visualize the feature map evolution (as detailed in Section 4.3.2) of our top-down neural attention-inspired LSTM-first–CNN-next framework to validate its operational mechanism. We believe our work will advance efficient RSI SR, delivering higher fidelity and faster processing alongside robust performance for practical applications.
2. Related Works
2.1. Remote Sensing Single-Image Super-Resolution
Remote sensing single-image super-resolution (RSISR) has achieved notable progress with advancements in deep learning. Since SRCNN [16] demonstrated superior performance over traditional interpolation and reconstruction methods, a notable expansion of deep learning-based RSISR methodologies has occurred. Current methodologies focus on extracting prior knowledge from LR images, which are broadly categorized into three groups: CNNs, Transformers, and SSMs.
CNN-based methods dominate early RSISR research. LGCNet [30] became the first CNN model specifically designed for RSISR, leveraging multilevel representations to capture hierarchical image features. Subsequent improvements by Haut et al. [31] and Dong et al. [32] enhanced feature extraction through residual connections and dense sampling mechanisms. HSENet [33] strengthens feature representation by integrating single- and cross-scale self-similarity via hybrid SSEM/CCS modules for enhanced performance. HAUNet [34] enhanced global feature representation and multi-scale information fusion through hybrid attention mechanisms and a U-shaped architecture. However, their inherent locality persists in restricting long-range dependency modeling and performance breakthroughs in large-scale remote sensing scenarios. Recent hybrid approaches like FCIHMRT [35] demonstrate the potential of cross-architecture fusion (e.g., Res2Net+Transformer) for complex remote sensing tasks like scene classification, providing new perspectives for remote sensing image processing.
Transformer-based methods emerge to address the global modeling limitations of CNN. TransENet [36] improves performance by leveraging multilevel features, ESTNet [37] compresses model size via channel attention, and SCAT [38] addresses limited receptive fields and feature diversity in channel attention-based Transformers by introducing a shift channel attention block with cross-head communication and depthwise convolution. However, the core insight of Transformer lies in the self-attention mechanism, which faces efficiency limitations in processing high-resolution RSI due to its quadratic complexity. While methods like [19,21] mitigate computational costs, such efficiency-driven adaptations inherently weaken global modeling capabilities, leaving the core trade-off between scalability and representational power unresolved [39].
SSM-based methods demonstrate linear computational efficiency with global modeling capability. FMSR [39] explores the application of Mamba to RSISR. MambaHSISR [40] proposes spatial and spectral Mamba sub-networks to enhance the SR performance of hyperspectral images. The recent success of ViL [27] offers a potentially superior approach to Mamba, but its application to RSISR remains unexplored.
Despite these successes, current RSISR methods face a persistent trade-off between efficiency and effectiveness. CNNs lack global context, Transformers are computationally infeasible at scale, and SSMs/ViLs lack strong 2D spatial priors. Importantly, reconciling efficient long-range modeling with the precise local refinement demanded by the dual-scale dependency structure of RSI (see Figure 1) remains a significant challenge for existing approaches. This work pioneers the integration of ViLs with CNNs in an LSTM-first–CNN-next framework, offering a novel solution for RSISR that effectively reconciles computational efficiency with critical detail recovery.

Figure 1.
Illustration of a unique characteristic of RSI. In RSIs, objects with similar semantics often coexist. We visualize an example from the Potsdam dataset. Local Attribution Map (LAM) [41] Attribution represents the importance of each pixel in the input LR image with regard to the SR reconstruction of the region marked with a red box. When selecting a single vehicle, only adjacent pixels are required to directly contribute to the SR reconstruction of this localized area. When selecting the entire image, the global SR reconstruction necessitates the combined contribution of all vehicles to collectively drive the process. This highlights the necessity of simultaneously modeling short-range and long-range spatial dependencies for effective RSI SR.
2.2. Biomimetic Top-Down Neural Attention-Based Vision Models
The human visual system has inspired numerous sophisticated computer vision methodologies. Of particular significance is the top-down neural attention mechanism [42,43,44], which embodies a crucial biological perception paradigm. This mechanism operates through a two-phase cognitive process: initial rapid formation of global scene understanding through high-level visual processing, followed by feedback-guided refinement that directs computational resources to semantically salient regions. This neurobiological principle enables more accurate and efficient visual interpretation through iterative information prioritization.
The efficacy of this biomimetic approach has been substantiated across diverse computer vision applications [45,46,47,48]. Recent advancements by OverLoCK [49] demonstrate the potential of implementing pure convolutional architectures with biologically plausible attention mechanisms. Their framework incorporates three specialized subnets (Base/Overview/Focus) coupled with context-mixing dynamic convolution operations, achieving state-of-the-art efficiency while maintaining competitive performance across multiple vision benchmarks.
Building upon these foundations, our work introduces a novel paradigm that integrates ViLs with CNNs through biomimetic top-down attention mechanisms, with the proposed Top-down Revisiting Method enhancing model performance while providing a novel perspective for RSI SR.
3. Methodology
In this section, we first introduce the overall structure of the proposed LSTMConvSR and then describe three important modules in LSTMConvSR, namely Vision-LSTM Group (ViLG), Adaptive Residual Refocusing Group (ARRG), and Top-down Revisiting Method.
3.1. Overview of LSTMConvSR
The overall network architecture of LSTMConvSR follows the Residual in Residual structure similar to [20,26]. As shown in Figure 2, LSTMConvSR first extracts shallow features from the LR input through a convolution layer:
where and C denote the channel number of the input and the intermediate feature, respectively.
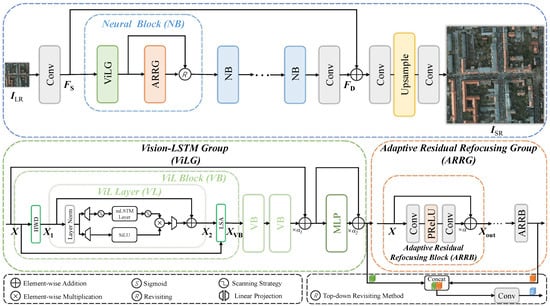
Figure 2.
LSTMConvSR overview.
Subsequently, the deep features are obtained through the deep feature extractor , where consists of N Neural Blocks (NBs) (each containing a ViLG, an ARRG, and a Top-down Revisiting Method) and one convolution layer:
Finally, the shallow features and deep features are fused through a global residual connection implemented via element-wise addition, followed by an upsampling process using the pixel-shuffle operation to produce the SR output :
where denotes the upsampling function and r denotes the scaling factor.
3.2. Vision-LSTM Group
ViL [27] pioneers the integration of xLSTM [28] into computer vision, demonstrating state-of-the-art performance. As shown in Figure 2, our ViLG adopts ViL’s architecture, where the ViL Layer (VL) serves as the primary building block. Despite VL’s powerful long-range dependency modeling capabilities, it shares a fundamental limitation with Transformers: both process images as token sequences, resulting in quadratic computational complexity as token counts scale with the square of image resolution. This quadratic growth renders VL computationally prohibitive for high-resolution imagery. To address this bottleneck, we propose HWD and LSA before and after VL, motivated by [50,51].
ViLG. As illustrated in Figure 2, the proposed ViLG consists of three ViL Blocks (VB) and one Multilayer Perceptron (MLP). Three VBs use three different scanning strategies: forward scanning, reverse scanning, and Hilbert Curve scanning for improved local feature extraction [52]. Given an input feature map , the whole process of ViLG is computed as
where and are learnable scaling parameters that dynamically adjust feature fusion ratios between residual connections and processed features.
HWD. In SISR tasks, LR inputs inherently suffer from severe high-frequency information loss. Our proposed HWD mitigates secondary degradation while maintaining SR performance in remote sensing applications. As illustrated in Figure 3, given an input feature map , the HWD module first reshapes the tensor to spatial dimensions , where denotes the original token count. A 2D Haar wavelet decomposition is then applied, producing four sub-bands: LL (low-frequency component) and LH/HL/HH (high-frequency components representing horizontal/vertical/diagonal details). The sub-bands are concatenated along the channel dimension, forming . Channel compression is achieved via convolution, reducing dimensionality to . Spatial features are refined by a depthwise convolution, yielding . Finally, the tensor is rearranged to .
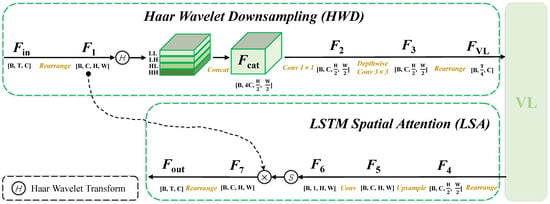
Figure 3.
Structure of Haar wavelet-based downsampling and LSTM Spatial Attention in ViLG.
LSA. Unlike conventional self-attention mechanisms in Transformers, LSA operates on compressed token sequences generated by HWD, significantly reducing computational overhead. As illustrated in Figure 3, LSA begins with the compressed VL-processed features and the original input feature map . To dynamically recalibrate spatial importance, LSA first rearranges into a partial spatial representation , restoring intermediate spatial structure while preserving channel-wise dependencies learned by VL. A bilinear upsampling layer then scales to match the original resolution, yielding , which aligns spatially with .
Subsequently, a convolution refines into a single-channel feature map , followed by a sigmoid activation to generate a spatial attention mask . Crucially, LSA leverages the global contextual priors encoded by VL to guide the mask generation, serving as the top-level attention guidance. The attention-guided modulation is achieved through element-wise multiplication between and the original features , producing recalibrated features . Finally, is rearranged into token format to seamlessly integrate with subsequent layers.
The collaboration between HWD and LSA reduces the sequence length from T (original tokens) to (compressed tokens processed by VL), thereby decreasing the computational complexity of token interactions from to .
3.3. Adaptive Residual Refocusing Group
Building upon the top-level attention guidance from ViLG, the ARRG performs down-level attention refocusing to hierarchically refine spatial features under global structural priors. The ARRG employs stacked ARRBs to refine features, and each ARRB enhances local details through a global adaptive residual scaling mechanism, enabling dynamic focus on critical regions. As illustrated in Figure 2, the ARRB processes input features through two convolutional layers with a PReLU [53] activation:
where is a global learnable scaling coefficient initialized to 1 and optimized during training. The first convolution extracts intermediate features, which are nonlinearly activated by PReLU (introducing learnable negative slope parameters). The second convolution further transforms these features, while the scalar dynamically scales the entire processed branch’s contribution. This allows the block to amplify high-frequency details identified by ViLG’s global attention, while retaining low-frequency structural integrity through the identity term .
3.4. Top-Down Revisiting Method
The Top-down Revisiting Method bridges the LSTM-first and CNN-next paradigm, enabling cross-stage retrospection by dynamically reconciling ViLG’s top-level global attention guidance with ARRG’s down-level locally refocused features. Given ViLG’s output and ARRG’s refined features , the method first concatenates them along the channel dimension:
A convolution then projects the fused features to the original channel dimension:
4. Experiments
4.1. Datasets and Evaluation
This paper reports the performance of SR on three RSI datasets, including the publicly available Potsdam, UAVid [54], and RSSCN7 [55].
Potsdam. The Potsdam dataset serves as a widely adopted benchmark for remote sensing semantic segmentation tasks. It contains 38 high-resolution TOP image tiles, each measuring pixels with a ground sampling distance of 5 cm. Notably, objects sharing similar semantic labels frequently coexist within this dataset, as visually demonstrated in Figure 1. In our experiments, tiles (ID: 2_11, 3_10, 4_10, 5_10, 6_7, 7_7) were allocated for training, tile ID: 2_10 served for validation, and tiles (ID: 2_13, 2_14, 3_13, 3_14, 4_13, 4_14, 4_15, 5_13, 5_14, 5_15, 6_13, 6_14, 6_15, 7_13) constituted the test set. This resulted in a training set of 864 images, a validation set of 144 images, and a test set of 2016 images. Only the red, green, and blue spectral bands were utilized. Original image tiles were cropped into HR patches of pixels, with corresponding LR counterparts downscaled to pixels.
UAVid. The UAVid dataset is a fine-resolution Unmanned Aerial Vehicle semantic segmentation benchmark focusing on complex urban street scenes, with images captured at two spatial resolutions ( and pixels). Its challenging nature stems from fine spatial details, heterogeneous spatial variations, semantically ambiguous categories, and intricate scene compositions. From the original 42 sequences, we selected frames 000000 and 000900 from each sequence to construct the experimental dataset. Sequences 1 to 15 and 31 to 35 were allocated for training, sequences 16 to 20, 36, and 37 for validation, and sequences 21 to 30 and 38 to 42 for testing. This resulted in a training set of 1600 images, a validation set of 560 images, and a test set of 1200 images. Consistent with the Potsdam experimental setup, all images were processed at the same size.
RSSCN7. The RSSCN7 dataset comprises 2800 high-resolution images sourced from Google Earth, organized into seven distinct categories: grasslands, farmlands, industrial areas, rivers and lakes, forests, residential areas, and parking lots. Each category contains 400 images equally distributed across four sampling scales (100 images per scale), with substantial variations in seasonal conditions, weather patterns, and spatial perspectives contributing to the dataset’s complexity. In our experiments, the RSSCN7 was partitioned equally: 1400 images formed the training set, while the remaining 1400 constituted the test set. Within the training subset, 20% (280 images) served as a validation set. All HR patches were pixels, with corresponding LR counterparts downscaled to pixels.
Evaluation Metrics. We employed two full-reference metrics, Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) [56], with both computed specifically on the luminance channel (Y) in YCbCr color space. Additionally, two no-reference metrics were utilized to analyze perceptual quality: the LPIPS [57] and CLIPIQA [58]. All quantitative evaluations were performed using the IQA toolbox (https://github.com/chaofengc/IQA-PyTorch (accessed on 1 May 2025)).
4.2. Implementation Details
LSTMConvSR incorporates 4 NBs. Each NB consists of 1 ViLG and 1 ARRG, with each ARRG containing 12 ARRBs. We empirically set the internal channel dimension C to 128. For the smaller variant (LSTMConvSR_s), C is reduced to 64.
This paper focuses on SR. During training, models were trained on randomly cropped patches from LR RSIs. We used a batch size of 16 and optimized with the Adam optimizer (, ) with an initial learning rate of . Training proceeded for 500 epochs, with the learning rate halved at epoch 250 using a step scheduler. All SR models were implemented in PyTorch version 2.7.1. The FLOPs results were calculated using an input tensor of size , and the computations were performed using torch-operation-counter (https://github.com/SamirMoustafa/torch-operation-counter (accessed on 1 May 2025)). The inference times were tested on 300 random images with a size of . Experiments were conducted on an NVIDIA A800 80 GB GPU.
4.3. Ablation Study
In this section, we discuss the proposed LSTMConvSR in depth by investigating the effect of its major components and their variants. All models were trained on three datasets with a scale factor .
4.3.1. Effect of Key Modules
(a) Effect of ViLG’s top-level attention guidance. ViLG’s LSTM-driven attention guidance consistently improved reconstruction fidelity by modeling long-range spatial dependencies in RSIs. As shown in Table 1, enabling ViLG (ViLG = 1) in the 1-ARRB configuration improved PSNR by 0.22 dB on Potsdam, 0.12 dB on UAVid, and 0.03 dB on RSSCN7 compared to non-ViLG counterparts. The SSIM and LPIPS metrics also demonstrated consistent gains, with LPIPS decreasing by 0.65% on Potsdam and 0.69% on RSSCN7. This significant gain demonstrated ViLG’s critical role in resolving reconstruction ambiguities when local features alone were insufficient. The guidance mechanism proved particularly valuable in scenes with semantically similar objects (Potsdam and UAVid). With 12 ARRBs, ViLG still maintained performance gains but with reduced magnitude (e.g., +0.04 dB vs. +0.22 dB on Potsdam). This attenuation occurred because deeper ARRG stacks could independently recover more local details, decreasing reliance on ViLG’s guidance. Nevertheless, ViLG’s global structural priors remained essential for enhancing SR performance.

Table 1.
Ablation study on ViLG. ViLG = 1 enables LSTM-driven top-level attention guidance; ARRBs denote block counts. ViLG consistently enhanced performance, particularly with limited refinement (1 ARRB). The 12-ARRB configuration was determined optimal through comprehensive analysis in Table 2.
(b) Effect of ARRG’s down-level attention refocusing. The hierarchical feature refinement through stacked ARRBs progressively enhanced spatial detail recovery under ViLG’s global guidance. As demonstrated in Table 2, increasing ARRB counts yielded consistent performance gains across datasets. From 0 to 12 ARRBs, PSNR increased by 0.34 dB on Potsdam and 0.23 dB on UAVid, while LPIPS decreased significantly by 1.16% and 1.04%, respectively. The most pronounced LPIPS improvement occurred in RSSCN7 with a 1.56% reduction, indicating superior perceptual quality despite marginal PSNR gains. Notably, performance plateaued beyond 12 ARRBs, with only marginal gains observed from 12 to 16 blocks. This confirmed the sufficiency of a 12-block configuration for comprehensive feature refinement under global guidance. The LPIPS and CLIPIQA metrics showed continuous improvement even beyond PSNR saturation in RSSCN7, validating ARRG’s effectiveness in enhancing visual quality for RSI applications.
Table 2.
Ablation study on ARRG. Increasing ARRBs progressively enhanced reconstruction quality, with diminishing returns beyond 12 blocks. The hierarchical refinement maximized perceptual fidelity under ViLG’s guidance.
(c) Effect of Top-down Revisiting Method. The top-down revisiting mechanism enhanced reconstruction quality across all datasets by dynamically combining LSTM-derived structural priors with CNN-recovered spatial details. As quantified in Table 3, introducing this method improved PSNR by 0.03 dB on Potsdam and 0.02 dB on RSSCN7, while SSIM increased by 0.05% on Potsdam. These gains were achieved simply through feature concatenation and projection operations that reconciled ViLG’s global attention maps with ARRG’s locally refined features. The stability of the LPIPS and CLIPIQA metrics showed that these gains were achieved without compromising perceptual naturalness.
Table 3.
Ablation study on Top-down Revisiting Method.
(d) Effect of HWD and LSA. The HWD and LSA modules maintained reconstruction quality while significantly improving computational efficiency. As shown in Table 4, their inclusion preserved nearly identical PSNR and SSIM values across all datasets, with Potsdam retaining 33.94 dB PSNR and RSSCN7 maintaining 26.36 dB PSNR. Minor variations in LPIPS and CLIPIQA indicated negligible perceptual impact.
Table 4.
Ablation study on HWD and LSA reconstruction quality.
Table 5 demonstrated that HWD and LSA reduced FLOPs by 80.3% while increasing inference speed 11-fold and decreasing memory consumption by 93.4%. This comprehensive optimization resulted from token sequence compression, which reduced VL processing length to and lowered complexity from to . The 4.4% parameter increase represented a negligible trade-off for the computational benefits. These hardware-aware metrics confirmed that HWD and LSA effectively addressed VL’s quadratic complexity limitation in high-resolution processing while optimizing critical deployment constraints without compromising reconstruction quality.
Table 5.
Computational efficiency of HWD and LSA. Full hardware specifications and testing protocols are detailed in Section 4.2.
4.3.2. Visualization of LSTM-First-CNN-Next
Feature map visualizations in Figure 4 demonstrated the operational dynamics of our LSTM-first–CNN-next architecture. The ViLG module (LSTM-first) generated semantically structured representations, clearly preserving vehicle outlines through its global attention mechanism. This aligned with ViLG’s design to encode long-range contextual priors for top-level guidance.
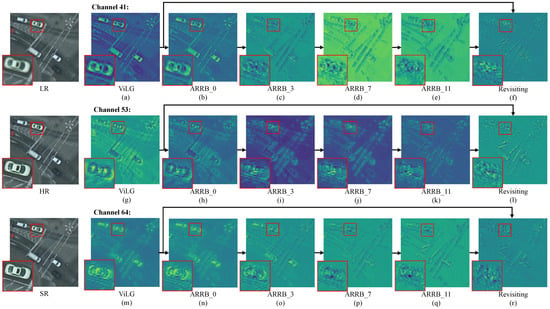
Figure 4.
Feature map evolution in the LSTM-first–CNN-next framework (channels 41, 53, 64). ViLG preserved semantic structures, ARRBs progressively shifted to pixel-level refinements, and the revisiting method fused both representations for SR.
Subsequent ARRBs progressively transformed semantic priors into localized refinements. While ARRB_0 retained residual semantic information, deeper blocks (ARRB_3, ARRB_7, ARRB_11) increasingly focused on pixel-level texture details, gradually dissolving recognizable vehicle shapes. This transition validated ARRG’s hierarchical refinement mechanism, where stacked blocks shift focus from global structures to local textures under ViLG’s guidance.
The revisiting method’s output exhibited pixel-focused patterns similar to later ARRBs rather than ViLG’s semantic structures. This occurred because the concatenation–projection fusion (Equations (9) and (10)) prioritized spatial refinements essential for the low-level SR task, while ViLG’s structural guidance operated implicitly to maintain coherence. This visualization illustrates the framework’s workflow: ViLG preserved structural priors, ARRG refocused pixel-level details, and the revisiting method integrated both for optimal reconstruction.
4.4. Comparisons with State of the Art
4.4.1. Comparative Methods
To evaluate the SR performance of our LSTMConvSR against SOTA methods on RSIs, advanced CNN-, Transformer-, and Mamba-based models were involved for comprehensive comparison, including SRCNN [16], EDSR [17], HAT [20], RGT [21], ATD [59], SPT [60], and MambaIRv2 [26].
4.4.2. Quantitative Evaluations
Comprehensive quantitative evaluations across three remote sensing datasets demonstrated the superiority of our approach. As presented in Table 6, our full model (LSTMConvSR) achieved state-of-the-art performance on Potsdam, securing the highest scores across all four metrics: 33.94 dB PSNR (+0.08 dB over RGT), 0.8684 SSIM (+0.09% over RGT), 0.2727 LPIPS (−0.31% over RGT), and 0.2203 CLIPIQA. On UAVid, LSTMConvSR matched the best LPIPS (0.3287) while achieving competitive PSNR (28.24 dB) and SSIM (0.7521). For RSSCN7, LSTMConvSR delivered optimal SSIM (0.6336) and LPIPS (0.5186), with PSNR within 0.03 dB of the leader (ATD).
Table 6.
Quantitative comparisons on Potsdam, UAVid, and RSSCN7 datasets ( SR). Best results are in red.
The compact variant (LSTMConvSR_s) with halved channels maintained strong competitiveness, demonstrating the architecture’s efficiency. Notably, LSTMConvSR consistently outperformed Transformer-based models (HAT, RGT, ATD, SPT) and Mamba-based MambaIRv2 across perceptual metrics (LPIPS), highlighting the effectiveness of our LSTM-first–CNN-next paradigm in preserving structural integrity and perceptual quality. These results confirmed that the integration of ViLG’s global attention guidance and ARRG’s local refinements significantly enhanced reconstruction quality for RSI.
Notably, the observed divergence in CLIPIQA metrics warrants specific consideration given RSSCN7’s unique characteristics. While LSTMConvSR achieved superior SSIM (0.6336) and LPIPS (0.5186) on this dataset, its CLIPIQA score (0.2242) trailed RGT’s 0.2319. This discrepancy aligns with CLIPIQA’s documented sensitivity to abstract perceptual attributes beyond structural fidelity [58]. RSSCN7’s extreme seasonal variations introduce non-structural elements like foliage color shifts that significantly influence human aesthetic perception but minimally affect pixel-level reconstruction. The Transformer-based RGT’s expansive receptive field better preserves these seasonal semantics, whereas our method prioritizes geometric integrity, which explains its dominance in SSIM/LPIPS but a relative deficit in this abstract perception-oriented metric. This divergence highlights the nuanced relationship between structural accuracy and semantic preservation in seasonal-variant remote sensing imagery.
4.4.3. Complexity and Efficiency Evaluation
Computational efficiency comparisons in Table 7 demonstrated our model’s superior balance between performance and resource utilization. The full LSTMConvSR model achieved competitive efficiency with 19.20 M parameters and 405.66 G FLOPs while maintaining 9.9 FPS inference speed. This represents an up to 2.06× speedup over comparable Transformer-based methods like HAT (7.7 FPS) and ATD (4.8 FPS), despite similar parameter counts. This efficiency advantage was particularly significant given our model’s superior performance in quantitative evaluations (Table 6).
Table 7.
Comparisons of model complexity and efficiency. Full hardware specifications and testing protocols are detailed in Section 4.2.
The compact variant LSTMConvSR_s delivered exceptional efficiency with only 5.09 M parameters and 142.06 G FLOPs while achieving 11.6 FPS—3.2× faster than RGT (3.6 FPS) and 2.8× faster than MambaIRv2 (4.1 FPS). Notably, both our variants outperformed all Transformer and Mamba counterparts in FPS, with LSTMConvSR_s approaching a CNN model EDSR speed (45.3 FPS) while delivering competitive reconstruction quality (Table 6).
These results validated our architectural innovations, where LSTM-based global modeling reduced quadratic complexity, CNN-based local refinement enabled parallel processing, and top-down revisiting facilitated efficient feature integration without computational overhead. The efficiency gains highlighted the practical advantage of our LSTM-first–CNN-next framework for real-world remote sensing applications.
4.4.4. Qualitative Results
Visual comparisons in Figure 5, Figure 6, Figure 7 and Figure 8 demonstrated our model’s balanced reconstruction capabilities. For Figure 5, LSTMConvSR and EDSR accurately reconstructed intricate roof textures, while Transformer-based methods HAT and RGT produced inconsistent patterns with large erroneous texture blocks. This reflects the effectiveness of our ARRG’s convolutional refinements in recovering detailed textures.

Figure 5.
Visual comparison on UAVid sequence 38 frame 000000. Zoom in for better observation.

Figure 6.
Visual results on UAVid sequence 25 frame 000900. Zoom in for better observation.

Figure 7.
Visual results on Potsdam (tile ID: 5_15). Zoom in for better observation.

Figure 8.
Visual results on RSSCN7 (image: g061). Zoom in for better observation.
In Figure 6, LSTMConvSR achieved superior reconstruction quality with consistent roof patterns and minimal artifacts. While Transformer-based (HAT, RGT, ATD) and Mamba-based (MambaIRv2) methods showed reasonable results in terms of PSNR and SSIM, they exhibited localized texture inconsistencies. Conversely, CNN-based EDSR exhibited significant failure with large-scale texture corruption visible specifically in the left roof section of subfigure (e) in Figure 6. This indicated that ViLG’s global attention mechanism enabled our model to maintain structural integrity across the entire roof surface, preventing the catastrophic failure exhibited in EDSR.
These comparisons confirmed our architecture’s dual capability to maintain structural coherence through ViLG’s global modeling while achieving texture fidelity via ARRG’s local refinements, demonstrating robustness to varying architectural patterns.
5. Conclusions and Future Work
In this study, we first introduce the Vision-LSTM for RSI SR. Our LSTMConvSR effectively combines Vision-LSTM and CNNs to achieve efficient yet effective RSI SR. Specifically, we incorporate Haar wavelet-based downsampling (HWD) and LSTM Spatial Attention (LSA) into Vision-LSTM to form Vision-LSTM Groups (ViLG), addressing the quadratic complexity limitation of sequence processing in high-resolution image processing. Meanwhile, inspired by biomimetic top-down neural attention mechanisms, we design Adaptive Residual Refocusing Groups (ARRB) to establish an LSTM-first–CNN-next framework. This framework employs Vision-LSTM for top-level attention guidance, followed by CNN-based down-level attention refocusing. Furthermore, we propose a top-down revisiting method to enable cross-stage retrospection, further enhancing performance. Extensive quantitative and qualitative experiments conducted on the Potsdam, UAVid, and RSSCN7 benchmarks demonstrate that our method achieves superior performance in RSI SR tasks compared to state-of-the-art CNN-, Transformer-, and Mamba-based SR models.
Nevertheless, our LSTMConvSR does exhibit some shortcomings. Analysis of LAM in Figure 9 reveals a receptive field constraint in our architecture. While achieving superior reconstruction quality in Figure 5, LSTMConvSR exhibits a receptive field comparable to CNN-based EDSR, significantly smaller than Transformer-based RGT’s broad attention coverage. This limitation stems from our sequential LSTM-first–CNN-next framework, where convolutional operations in the later refocusing stage inherently constrain the effective feature extraction range.
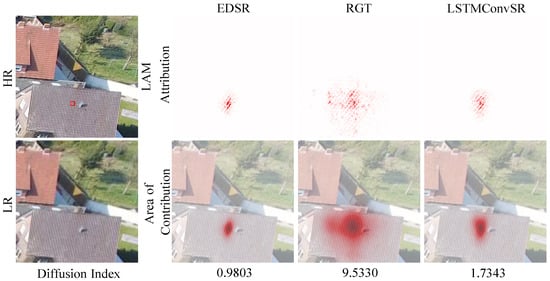
Figure 9.
LAM visualization for Figure 5 comparing receptive fields.
This constrained receptive field may impact performance in scenes requiring ultra-long-range dependency modeling, such as large-scale geological formations or extensive urban landscapes where global context integration is critical. Future work will address this limitation by investigating enhanced refocusing units with adaptive receptive field mechanisms and exploring hybrid architectures that strategically incorporate transformer blocks at the refocusing stage to extend context capture range while preserving computational efficiency.
Moreover, while prior research [17,39] indicates that excellence in SR generally predicts strong performance on lower scaling factors, we recognize the importance of multi-scale evaluation for comprehensive generality assessment. Our current computational resource allocation prioritized depth over breadth, focusing exclusively on SR to establish robust baseline performance. This concentrated approach conserved resources but limited explicit validation on / scales. Future work will rigorously extend LSTMConvSR to incorporate adaptive scaling mechanisms, systematically evaluating performance across , , and factors to fully characterize cross-scale robustness while maintaining efficiency.
Author Contributions
Conceptualization, Q.Z. and G.Z.; methodology, Q.Z.; software, Q.Z.; investigation, Q.Z. and X.W.; writing—original draft preparation, Q.Z. and G.Z.; writing—review and editing, Q.Z. and J.H.; project administration, G.Z.; funding acquisition, X.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Natural Science Foundation of Qinghai Province (No. 2023-ZJ-906M), and the National Natural Science Foundation of China (No. 62162053). This research was supported by the High-performance Computing Center of Qinghai University.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zhang, J.; Lei, J.; Xie, W.; Fang, Z.; Li, Y.; Du, Q. SuperYOLO: Super Resolution Assisted Object Detection in Multimodal Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5605415. [Google Scholar] [CrossRef]
- Feng, H.; Zhang, L.; Yang, X.; Liu, Z. Enhancing class-incremental object detection in remote sensing through instance-aware distillation. Neurocomputing 2024, 583, 127552. [Google Scholar] [CrossRef]
- Bashir, S.M.A.; Wang, Y. Small object detection in remote sensing images with residual feature aggregation-based super-resolution and object detector network. Remote Sens. 2021, 13, 1854. [Google Scholar] [CrossRef]
- Zhang, L.; Dong, R.; Yuan, S.; Li, W.; Zheng, J.; Fu, H. Making low-resolution satellite images reborn: A deep learning approach for super-resolution building extraction. Remote Sens. 2021, 13, 2872. [Google Scholar] [CrossRef]
- Li, J.; He, W.; Cao, W.; Zhang, L.; Zhang, H. UANet: An Uncertainty-Aware Network for Building Extraction From Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5608513. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, D.; Shi, B.; Zhou, Y.; Chen, J.; Yao, R.; Xue, Y. Multi-source collaborative enhanced for remote sensing images semantic segmentation. Neurocomputing 2022, 493, 76–90. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Wu, H.; Huang, P.; Zhang, M.; Tang, W.; Yu, X. CMTFNet: CNN and Multiscale Transformer Fusion Network for Remote-Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 2004612. [Google Scholar] [CrossRef]
- Cui, B.; Zhang, H.; Jing, W.; Liu, H.; Cui, J. SRSe-net: Super-resolution-based semantic segmentation network for green tide extraction. Remote Sens. 2022, 14, 710. [Google Scholar] [CrossRef]
- Deng, Y.; Tang, S.; Chang, S.; Zhang, H.; Liu, D.; Wang, W. A Novel Scheme for Range Ambiguity Suppression of Spaceborne SAR Based on Underdetermined Blind Source Separation. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5207915. [Google Scholar] [CrossRef]
- Guo, D.; Xia, Y.; Xu, L.; Li, W.; Luo, X. Remote sensing image super-resolution using cascade generative adversarial nets. Neurocomputing 2021, 443, 117–130. [Google Scholar] [CrossRef]
- Salvetti, F.; Mazzia, V.; Khaliq, A.; Chiaberge, M. Multi-image super resolution of remotely sensed images using residual attention deep neural networks. Remote Sens. 2020, 12, 2207. [Google Scholar] [CrossRef]
- Gu, J.; Sun, X.; Zhang, Y.; Fu, K.; Wang, L. Deep Residual Squeeze and Excitation Network for Remote Sensing Image Super-Resolution. Remote Sens. 2019, 11, 1817. [Google Scholar] [CrossRef]
- Huang, B.; He, B.; Wu, L.; Guo, Z. Deep residual dual-attention network for super-resolution reconstruction of remote sensing images. Remote Sens. 2021, 13, 2784. [Google Scholar] [CrossRef]
- Wang, X.; Yi, J.; Guo, J.; Song, Y.; Lyu, J.; Xu, J.; Yan, W.; Zhao, J.; Cai, Q.; Min, H. A Review of Image Super-Resolution Approaches Based on Deep Learning and Applications in Remote Sensing. Remote Sens. 2022, 14, 5423. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 184–199. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Chen, X.; Wang, X.; Zhou, J.; Qiao, Y.; Dong, C. Activating more pixels in image super-resolution transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22367–22377. [Google Scholar]
- Chen, Z.; Zhang, Y.; Gu, J.; Kong, L.; Yang, X. Recursive Generalization Transformer for Image Super-Resolution. In Proceedings of the Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar] [CrossRef]
- Yu, W.; Wang, X. MambaOut: Do We Really Need Mamba for Vision? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 11–15 June 2025.
- Guo, H.; Li, J.; Dai, T.; Ouyang, Z.; Ren, X.; Xia, S.T. Mambair: A simple baseline for image restoration with state-space model. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Cham, Switzerland, 2024; pp. 222–241. [Google Scholar]
- Zhu, Q.; Zhang, G.; Zou, X.; Wang, X.; Huang, J.; Li, X. ConvMambaSR: Leveraging State-Space Models and CNNs in a Dual-Branch Architecture for Remote Sensing Imagery Super-Resolution. Remote Sens. 2024, 16, 3254. [Google Scholar] [CrossRef]
- Guo, H.; Guo, Y.; Zha, Y.; Zhang, Y.; Li, W.; Dai, T.; Xia, S.T.; Li, Y. MambaIRv2: Attentive State Space Restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 11–15 June 2025. [Google Scholar]
- Alkin, B.; Beck, M.; Pöppel, K.; Hochreiter, S.; Brandstetter, J. Vision-LSTM: XLSTM as Generic Vision Backbone. In Proceedings of the Thirteenth International Conference on Learning Representations, Singapore, 24–28 April 2025. [Google Scholar]
- Pöppel, K.; Beck, M.; Spanring, M.; Auer, A.; Prudnikova, O.; Kopp, M.K.; Klambauer, G.; Brandstetter, J.; Hochreiter, S. xLSTM: Extended Long Short-Term Memory. In Proceedings of the First Workshop on Long-Context Foundation Models @ ICML 2024, Vienna, Austria, 27 July 2024. [Google Scholar]
- Xie, F.; Zhang, W.; Wang, Z.; Ma, C. Quadmamba: Learning quadtree-based selective scan for visual state space model. Adv. Neural Inf. Process. Syst. 2024, 37, 117682–117707. [Google Scholar]
- Lei, S.; Shi, Z.; Zou, Z. Super-Resolution for Remote Sensing Images via Local-Global Combined Network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1243–1247. [Google Scholar] [CrossRef]
- Haut, J.M.; Paoletti, M.E.; Fernández-Beltran, R.; Plaza, J.; Plaza, A.; Li, J. Remote sensing single-image superresolution based on a deep compendium model. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1432–1436. [Google Scholar] [CrossRef]
- Dong, X.; Sun, X.; Jia, X.; Xi, Z.; Gao, L.; Zhang, B. Remote sensing image super-resolution using novel dense-sampling networks. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1618–1633. [Google Scholar] [CrossRef]
- Lei, S.; Shi, Z. Hybrid-Scale Self-Similarity Exploitation for Remote Sensing Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5401410. [Google Scholar] [CrossRef]
- Wang, J.; Wang, B.; Wang, X.; Zhao, Y.; Long, T. Hybrid Attention-Based U-Shaped Network for Remote Sensing Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5612515. [Google Scholar] [CrossRef]
- Huo, Y.; Gang, S.; Guan, C. FCIHMRT: Feature Cross-Layer Interaction Hybrid Method Based on Res2Net and Transformer for Remote Sensing Scene Classification. Electronics 2023, 12, 4362. [Google Scholar] [CrossRef]
- Lei, S.; Shi, Z.; Mo, W. Transformer-Based Multistage Enhancement for Remote Sensing Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5615611. [Google Scholar] [CrossRef]
- Kang, X.; Duan, P.; Li, J.; Li, S. Efficient Swin Transformer for Remote Sensing Image Super-Resolution. IEEE Trans. Image Process. 2024, 33, 6367–6379. [Google Scholar] [CrossRef]
- Kang, Y.; Zhang, X.; Wang, S.; Jin, G. SCAT: Shift Channel Attention Transformer for Remote Sensing Image Super-Resolution. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 10337–10347. [Google Scholar] [CrossRef]
- Xiao, Y.; Yuan, Q.; Jiang, K.; Chen, Y.; Zhang, Q.; Lin, C.W. Frequency-Assisted Mamba for Remote Sensing Image Super-Resolution. IEEE Trans. Multimed. 2025, 27, 1783–1796. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, H.; Zhou, F.; Luo, C.; Sun, X.; Rahardja, S.; Ren, P. MambaHSISR: Mamba Hyperspectral Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2025, 63, 1–16. [Google Scholar] [CrossRef]
- Gu, J.; Dong, C. Interpreting super-resolution networks with local attribution maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9199–9208. [Google Scholar]
- Gilbert, C.D.; Sigman, M. Brain states: Top-down influences in sensory processing. Neuron 2007, 54, 677–696. [Google Scholar] [CrossRef] [PubMed]
- Saalmann, Y.B.; Pigarev, I.N.; Vidyasagar, T.R. Neural mechanisms of visual attention: How top-down feedback highlights relevant locations. Science 2007, 316, 1612–1615. [Google Scholar] [CrossRef]
- Li, Z. Understanding Vision: Theory, Models, and Data; University Press: Oxford, UK, 2014. [Google Scholar]
- Hu, P.; Ramanan, D. Bottom-up and top-down reasoning with hierarchical rectified gaussians. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5600–5609. [Google Scholar]
- Zhang, J.; Bargal, S.A.; Lin, Z.; Brandt, J.; Shen, X.; Sclaroff, S. Top-down neural attention by excitation backprop. Int. J. Comput. Vis. 2018, 126, 1084–1102. [Google Scholar] [CrossRef]
- Pang, B.; Li, Y.; Li, J.; Li, M.; Cao, H.; Lu, C. Tdaf: Top-down attention framework for vision tasks. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 2384–2392. [Google Scholar]
- Shi, B.; Darrell, T.; Wang, X. Top-down visual attention from analysis by synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2102–2112. [Google Scholar]
- Lou, M.; Yu, Y. OverLoCK: An Overview-first-Look-Closely-next ConvNet with Context-Mixing Dynamic Kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 11–15 June 2025. [Google Scholar]
- Xiao, M.; Zheng, S.; Liu, C.; Wang, Y.; He, D.; Ke, G.; Bian, J.; Lin, Z.; Liu, T.Y. Invertible image rescaling. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 126–144. [Google Scholar]
- Xu, G.; Liao, W.; Zhang, X.; Li, C.; He, X.; Wu, X. Haar wavelet downsampling: A simple but effective downsampling module for semantic segmentation. Pattern Recognit. 2023, 143, 109819. [Google Scholar] [CrossRef]
- Wu, H.; Yang, Y.; Xu, H.; Wang, W.; Zhou, J.; Zhu, L. RainMamba: Enhanced Locality Learning with State Space Models for Video Deraining. In Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne, VIC, Australia, 28 October–1 November 2024; pp. 7881–7890. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Lyu, Y.; Vosselman, G.; Xia, G.S.; Yilmaz, A.; Yang, M.Y. UAVid: A semantic segmentation dataset for UAV imagery. ISPRS J. Photogramm. Remote Sens. 2020, 165, 108–119. [Google Scholar] [CrossRef]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep Learning Based Feature Selection for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Wang, J.; Chan, K.C.; Loy, C.C. Exploring clip for assessing the look and feel of images. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 2555–2563. [Google Scholar]
- Zhang, L.; Li, Y.; Zhou, X.; Zhao, X.; Gu, S. Transcending the Limit of Local Window: Advanced Super-Resolution Transformer with Adaptive Token Dictionary. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 2856–2865. [Google Scholar]
- Hao, J.; Li, W.; Lu, Y.; Jin, Y.; Zhao, Y.; Wang, S.; Wang, B. Scale-Aware Backprojection Transformer for Single Remote Sensing Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5649013. [Google Scholar] [CrossRef]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).