
SVDDD: SAR Vehicle Target Detection Dataset Augmentation Based on Diffusion Model



Abstract
:1. Introduction
1.1. Related Works
1.2. Motivation and Contributions
- •
- A total of 9989 SAR image slices sized 512 × 512 were collected from the FARAD and MiniSAR datasets, covering the Ka, Ku, and X bands, and detailed annotations for various objects present in each slice were provided, forming a labeled dataset usable for multiple SAR image-related tasks.
- •
- Based on the dataset, we fine-tuned a Stable Diffusion model trained on optical remote sensing images, acquiring a model capable of generating various SAR images, particularly SAR image slices containing vehicle targets. We further fine-tuned the model based on ControlNet to make the positions and orientations of the vehicle targets in the generated image slices controllable.
- •
- We also propose a histogram-based image adjustment method and filtering methods based on clarity and an influence function, forming a framework to augment SAR vehicle target detection training dataset, and achieved performance improvement across five classic strong baseline detectors.
2. Materials and Methods
2.1. Preliminaries
2.1.1. DDPM
2.1.2. Latent Diffusion
2.1.3. ControlNet
2.1.4. Influence Function
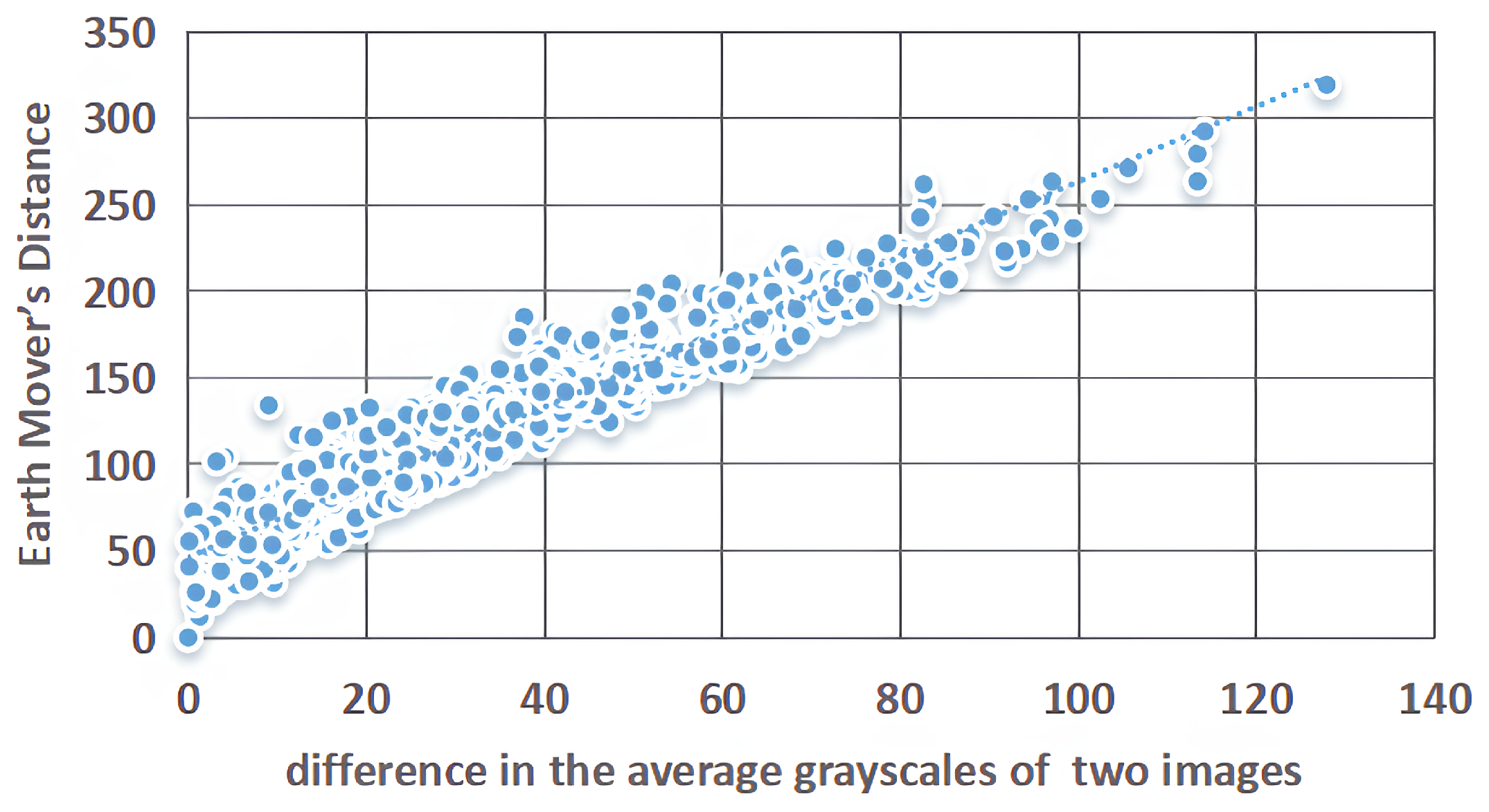
2.2. Our Method
2.3. Dataset Construction
2.3.1. Our Dataset
Original Data
Data Annotation Methods and Examples
- (1)
- The images from the aforementioned datasets were sliced into 512 × 512 pixel patches with a step size of 400 pixels, resulting in a total of 9989 patches.
- (2)
- Each patch was annotated with the objects present in it. Specifically, we annotated seven categories of objects in the images: playground, hill, river, road, vehicle, building, and tree. Each patch may contain multiple labels from the above categories.
Data Distribution
2.3.2. SIVED
3. Experimental Results and Analysis
3.1. Train and Infer
3.2. Computational Resources
3.3. Experiment Settings
- Rotated Faster R-CNN [32]: This is a two-stage rotatable bounding box object detection algorithm that extracts feature maps from the target images using a backbone. The Region Proposal Network (RPN) screens all potential bounding box locations, and through ROI pooling, fixed-size features are obtained for each location’s box. Finally, classification and regression are performed to determine the box size and rotation angle.
- Gliding Vertex [33]: Gliding Vertex is a regression strategy for rotatable bounding boxes. It predicts the positions of the four corners of the rotatable box by estimating the movement distances of the four corner points of a horizontal box along its edges. The entire detector framework is based on Rotated Faster R-CNN.
- R3Det [34]: R3Det is a single-stage object detector based on RetinaNet that combines the advantages of horizontal and rotatable boxes. It features a Fine-grained Refinement Module (FRM) that utilizes the location information of Refined Anchors to reconstruct the feature map for feature alignment.
- KLD [35]: KLD is another regression strategy for rotatable bounding boxes. It converts the rotatable bounding box into a two-dimensional Gaussian distribution and calculates the KL divergence between the Gaussian distributions as the regression loss. This paper conducts experiments by adding the KLD structure to R3Det.
- Oriented Reppoints [36]: Oriented Reppoints is a single-stage object detector based on an adaptive point representation learning method, which can generate adaptive point sets for geometrical structures in any orientation. It accurately classifies and locates targets using three directed transformation functions.
3.4. Visual Analysis
3.4.1. Visual Analysis on Diversity
3.4.2. Visual Analysis on Detection Performance
3.5. Metrics
3.6. Main Results
3.7. Ablation Test
3.8. Experiments on Num of Added Data
3.9. Experiments on Influence Function of Different Detectors
4. Discussion
Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, Z.; Zhao, L.; Ji, K.; Kuang, G. A domain adaptive few-shot SAR ship detection algorithm driven by the latent similarity between optical and SAR images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–18. [Google Scholar] [CrossRef]
- He, Q.; Zhao, L.; Ji, K.; Kuang, G. SAR target recognition based on task-driven domain adaptation using simulated data. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Keydel, E.R.; Lee, S.W.; Moore, J.T. MSTAR extended operating conditions: A tutorial. Algorithms Synth. Aperture Radar Imag. III 1996, 2757, 228–242. [Google Scholar]
- Long, Y.; Jiang, X.; Liu, X.; Zhang, Y. SAR ATR with rotated region based on convolution neural network. In Proceedings of the IGARSS 2019–2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1184–1187. [Google Scholar]
- Zhang, X.; Chai, X.; Chen, Y.; Yang, Z.; Liu, G.; He, A.; Li, Y. A novel data augmentation method for sar image target detection and recognition. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 3581–3584. [Google Scholar]
- Sun, Y.; Wang, W.; Zhang, Q.; Ni, H.; Zhang, X. Improved YOLOv5 with transformer for large scene military vehicle detection on SAR image. In Proceedings of the 2022 7th International Conference on Image, Vision and Computing (ICIVC), Xi’an, China, 26–28 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 87–93. [Google Scholar]
- Lin, X.; Zhang, B.; Wu, F.; Wang, C.; Yang, Y.; Chen, H. SIVED: A SAR Image Dataset for Vehicle Detection Based on Rotatable Bounding Box. Remote Sens. 2023, 15, 2825. [Google Scholar] [CrossRef]
- Sandia National Laboratory. Complex SAR Data. Available online: https://www.sandia.gov/radar/pathfinder-radar-isr-and-synthetic-aperture-radar-sarsystems/complex-data/ (accessed on 12 November 2023).
- Yang, W.; Hou, Y.; Liu, L.; Liu, Y.; Li, X. SARATR-X: A foundation model for synthetic aperture radar images target recognition. arXiv 2024, arXiv:2405.09365. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Kong, J.; Zhang, F. SAR target recognition with generative adversarial network (GAN)-based data augmentation. In Proceedings of the 2021 13th International Conference on Advanced Infocomm Technology (ICAIT), Yanji, China, 15–18 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 215–218. [Google Scholar]
- Mao, C.; Huang, L.; Xiao, Y.; He, F.; Liu, Y. Target recognition of SAR image based on CN-GAN and CNN in complex environment. IEEE Access 2021, 9, 39608–39617. [Google Scholar] [CrossRef]
- Cui, Z.; Zhang, M.; Cao, Z.; Cao, C. Image data augmentation for SAR sensor via generative adversarial nets. IEEE Access 2019, 7, 42255–42268. [Google Scholar] [CrossRef]
- Zhu, M.; Zang, B.; Ding, L.; Lei, T.; Feng, Z.; Fan, J. LIME-based data selection method for SAR images generation using GAN. Remote Sens. 2022, 14, 204. [Google Scholar] [CrossRef]
- Du, S.; Hong, J.; Wang, Y.; Xing, K.; Qiu, T. Multi-category SAR images generation based on improved generative adversarial network. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 4260–4263. [Google Scholar]
- Kwon, H.; Jeong, S.; Kim, S.; Lee, J.; Sohn, K. Deep-learning based SAR Ship Detection with Generative Data Augmentation. J. Korea Multimed. Soc. 2022, 25, 1–9. [Google Scholar]
- Huang, Y.; Mei, W.; Liu, S.; Li, T. Asymmetric training of generative adversarial network for high fidelity SAR image generation. In Proceedings of the IGARSS 2022–2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1576–1579. [Google Scholar]
- Wu, B.; Wang, H.; Zhang, C.; Chen, J. Optical-to-SAR Translation Based on CDA-GAN for High-Quality Training Sample Generation for Ship Detection in SAR Amplitude Images. Remote Sens. 2024, 16, 3001. [Google Scholar] [CrossRef]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Qosja, D.; Wagner, S.; O’Hagan, D. SAR Image Synthesis with Diffusion Models. In Proceedings of the 2024 IEEE Radar Conference (RadarConf24), Denver, CO, USA, 6–10 May 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar]
- Zhang, X.; Li, Y.; Li, F.; Jiang, H.; Wang, Y.; Zhang, L.; Zheng, L.; Ding, Z. Ship-Go: SAR ship images inpainting via instance-to-image generative diffusion models. ISPRS J. Photogramm. Remote Sens. 2024, 207, 203–217. [Google Scholar] [CrossRef]
- Zhou, J.; Xiao, C.; Peng, B.; Liu, Z.; Liu, L.; Liu, Y.; Li, X. DiffDet4SAR: Diffusion-based aircraft target detection network for SAR images. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Perera, M.V.; Nair, N.G.; Bandara, W.G.C.; Patel, V.M. SAR despeckling using a denoising diffusion probabilistic model. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Seo, M.; Oh, Y.; Kim, D.; Kang, D.; Choi, Y. Improved flood insights: Diffusion-based sar to eo image translation. arXiv 2023, arXiv:2307.07123. [Google Scholar]
- Guo, Z.; Liu, J.; Cai, Q.; Zhang, Z.; Mei, S. Learning SAR-to-Optical Image Translation via Diffusion Models with Color Memory. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 14454–14470. [Google Scholar] [CrossRef]
- Zhang, L.; Rao, A.; Agrawala, M. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 3836–3847. [Google Scholar]
- Koh, P.W.; Liang, P. Understanding black-box predictions via influence functions. In Proceedings of the International Conference on Machine Learning, (PMLR: 2017), Sydney, Australia, 6–11 August 2017; pp. 1885–1894. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, (PMLR: 2017), Shenzhen, China, 26 February–1 March 2021; pp. 8748–8763. [Google Scholar]
- Rubner, Y.; Tomasi, C.; Guibas, L.J. The earth mover’s distance as a metric for image retrieval. Int. J. Comput. Vis. 2000, 40, 99–121. [Google Scholar] [CrossRef]
- Yuan, Z. Stable Diffusion for Remote Sensing Image Generation. Available online: https://github.com/xiaoyuan1996/Stable-Diffusion-for-Remote-Sensing-Image-Generation (accessed on 27 October 2024).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.S.; Bai, X. Gliding vertex on the horizontal bounding box for multi-oriented object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 1452–1459. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3det: Refined single-stage detector with feature refinement for rotating object. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 19–21 May 2021; Volume 35, pp. 3163–3171. [Google Scholar]
- Yang, X.; Yang, X.; Yang, J.; Ming, Q.; Wang, W.; Tian, Q.; Yan, J. Learning high-precision bounding box for rotated object detection via kullback-leibler divergence. Adv. Neural Inf. Process. Syst. 2021, 34, 18381–18394. [Google Scholar]
- Li, W.; Chen, Y.; Hu, K.; Zhu, J. Oriented reppoints for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1829–1838. [Google Scholar]
- Zhou, Y.; Yang, X.; Zhang, G.; Wang, J.; Liu, Y.; Hou, L.; Jiang, X.; Liu, X.; Yan, J.; Lyu, C.; et al. Mmrotate: A rotated object detection benchmark using pytorch. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 7331–7334. [Google Scholar]
- Zhu, J.Y.; Zhang, R.; Pathak, D.; Darrell, T.; Efros, A.A.; Wang, O.; Shechtman, E. Toward multimodal image-to-image translation. Adv. Neural Inf. Process. Syst. 2017, 30, 465–476. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Saharia, C.; Chan, W.; Chang, H.; Lee, C.; Ho, J.; Salimans, T.; Fleet, D.; Norouzi, M. Palette: Image-to-image diffusion models. In Proceedings of the ACM SIGGRAPH 2022 Conference Proceedings, Vancouver, BC, Canada, 7–11 August 2022; pp. 1–10. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Source | Location | Bands | Polarization | Resolution |
|---|---|---|---|---|---|
| FARAD | Sandia National Laboratory | Albuquerque, NM, USA | Ka/X | VV/HH | 0.1 m × 0.1 m |
| MiniSAR | Sandia National Laboratory | Albuquerque, NM, USA | Ku | - | 0.1 m × 0.1 m |
| Label | Playground | Hill | River | Road | Vehicle | Building | Tree |
|---|---|---|---|---|---|---|---|
| number | 68 | 101 | 710 | 2411 | 2122 | 3784 | 5745 |
| percentage | 0.7% | 1.0% | 7.1% | 24.1% | 21.2% | 37.9% | 57.5% |
| Label | Playground | Road | Building | Tree |
|---|---|---|---|---|
| Number | 2 | 697 | 1076 | 1429 |
| Percentage | 0.08% | 30.1% | 46.6% | 61.8% |
| GPU | Time | |
|---|---|---|
| Fine-tuning Stable Diffusion | 1 × V100 | 11 days |
| Training ControlNet | 1 × 3090 | 1 day |
| Generating an image | 1 × 3090 | A few seconds |
| Calculating for one detector | 1 × 3090 | 0.5 days |
| Metric | Method | Rotated Faster R-CNN | Gliding Vertex | R3Det | KLD | Oriented Reppoints |
|---|---|---|---|---|---|---|
| No Augmentation | 79.1% | 76.0% | 76.6% | 82.3% | 82.0% | |
| BicycleGAN [38] | 79.3% | 76.0% | 77.2% | 81.7% | 82.4% | |
| Pix2pix [39] | 79.6% | 75.1% | 78.0% | 81.9% | 83.1% | |
| Palette [40] | 79.0% | 75.4% | 78.5% | 82.7% | 82.8% | |
| Our Method | 81.1% | 77.6% | 78.2% | 83.2% | 83.6% | |
| No Augmentation | 64.7% | 63.6% | 64.3% | 74.7% | 72.4% | |
| BicycleGAN | 64.2% | 63.0% | 65.4% | 74.6% | 72.6% | |
| Pix2pix | 65.5% | 63.8% | 64.8% | 75.0% | 73.0% | |
| Palette | 63.8% | 63.0% | 65.9% | 75.7% | 72.8% | |
| Our Method | 71.3% | 64.4% | 65.4% | 75.7% | 74.5% |
| Clarity Filter | HSGAGM | Influence Function Filter | Recall | mAP75 |
|---|---|---|---|---|
| ✓ | ✓ | ✓ | 83.6% | 74.5% |
| ✓ | ✓ | 83.4% | 74.1% | |
| ✓ | ✓ | 83.1% | 73.6% | |
| ✓ | ✓ | 83.6% | 74.0% | |
| ✓ | 82.9% | 72.6% | ||
| ✓ | 83.2% | 73.5% | ||
| ✓ | 83.0% | 73.3% | ||
| 82.8% | 72.9% |
| Method | Numn/Numo* | Rotated Faster R-CNN | Gliding Vertex | R3Det | KLD | Oriented Reppoints |
|---|---|---|---|---|---|---|
| No Augmentation | 0 | 64.7% | 63.6% | 64.3% | 74.7% | 72.4% |
| Our Method | 6.25% | 65.5% | 63.3% | 64.2% | 74.9% | 73.0% |
| 12.5% | 71.3% | 64.4% | 65.1% | 75.7% | 73.7% | |
| 18.75% | 66.8% | 63.7% | 65.4% | 75.2% | 73.3% | |
| 25% | 64.7% | 63.5% | 64.6% | 75.0% | 74.5% | |
| 31.25% | 63.5% | 62.7% | 64.7% | 75.2% | 73.1% | |
| 37.5% | 62.6% | 63.0% | 63.3% | 74.3% | 73.2% | |
| 43.75% | 61.6% | 61.9% | 63.3% | 73.4% | 72.3% | |
| 50% | 62.1% | 59.4% | 63.0% | 73.5% | 73.4% | |
| BicycleGAN | 12.5% | 64.2% | 63.0% | 65.4% | 74.6% | 72.6% |
| 25% | 63.6% | 62.6% | 65.1% | 74.3% | 72.6% | |
| Pix2Pix | 12.5% | 65.5% | 63.8% | 64.8% | 75.0% | 72.7% |
| 25% | 65.0% | 63.6% | 64.0% | 74.6% | 73.0% | |
| Palette | 12.5% | 63.8% | 63.0% | 65.9% | 75.7% | 72.4% |
| 25% | 63.0% | 63.0% | 65.4% | 75.2% | 72.8% |
| Influece Function | Rotated Faster R-CNN | Gliding Vertex | R3Det | KLD | Oriented Reppoints |
|---|---|---|---|---|---|
| Rotated Faster R-CNN | 71.3% | 62.7% | 64.8% | 73.8% | 73.4% |
| Gliding Vertex | 71.3% | 64.4% | 65.2% | 74.4% | 73.3% |
| R3Det | 64.2% | 64.2% | 65.4% | 75.2% | 73.1% |
| KLD | 72.1% | 63.5% | 65.4% | 75.7% | 73.6% |
| Oriented Reppoints | 64.6% | 63.7% | 64.5% | 74.6% | 74.5% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, K.; Pan, Z.; Wen, Z. SVDDD: SAR Vehicle Target Detection Dataset Augmentation Based on Diffusion Model. Remote Sens. 2025, 17, 286. https://doi.org/10.3390/rs17020286
Wang K, Pan Z, Wen Z. SVDDD: SAR Vehicle Target Detection Dataset Augmentation Based on Diffusion Model. Remote Sensing. 2025; 17(2):286. https://doi.org/10.3390/rs17020286
Chicago/Turabian StyleWang, Keao, Zongxu Pan, and Zixiao Wen. 2025. "SVDDD: SAR Vehicle Target Detection Dataset Augmentation Based on Diffusion Model" Remote Sensing 17, no. 2: 286. https://doi.org/10.3390/rs17020286
APA StyleWang, K., Pan, Z., & Wen, Z. (2025). SVDDD: SAR Vehicle Target Detection Dataset Augmentation Based on Diffusion Model. Remote Sensing, 17(2), 286. https://doi.org/10.3390/rs17020286