
S3DR-Det: A Rotating Target Detection Model for High Aspect Ratio Shipwreck Targets in Side-Scan Sonar Images


Abstract
:1. Introduction
2. Related Work
2.1. Oriented Object Detection
2.2. Sample Selection for Object Detection
3. Method
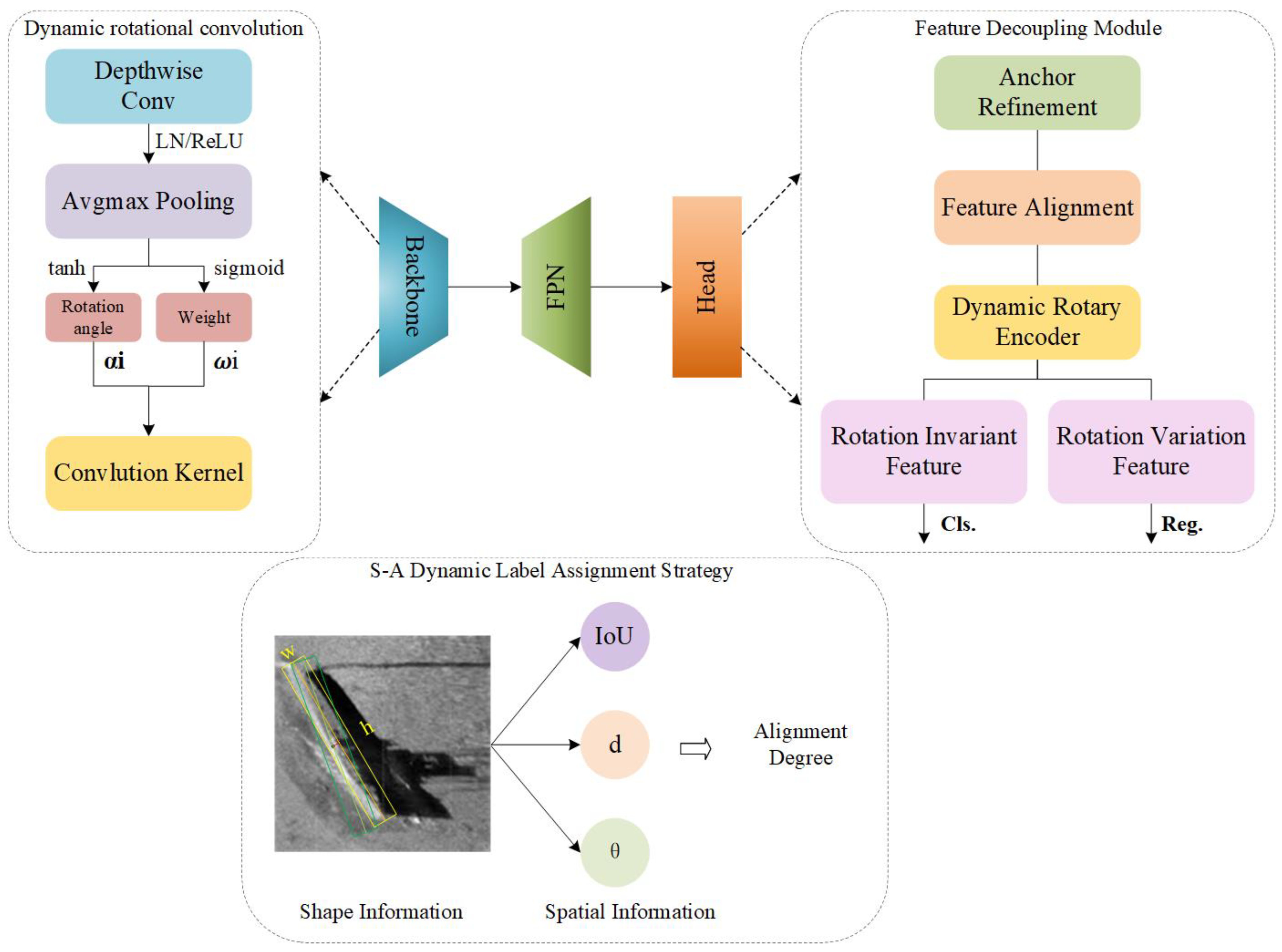
3.1. Network Architecture
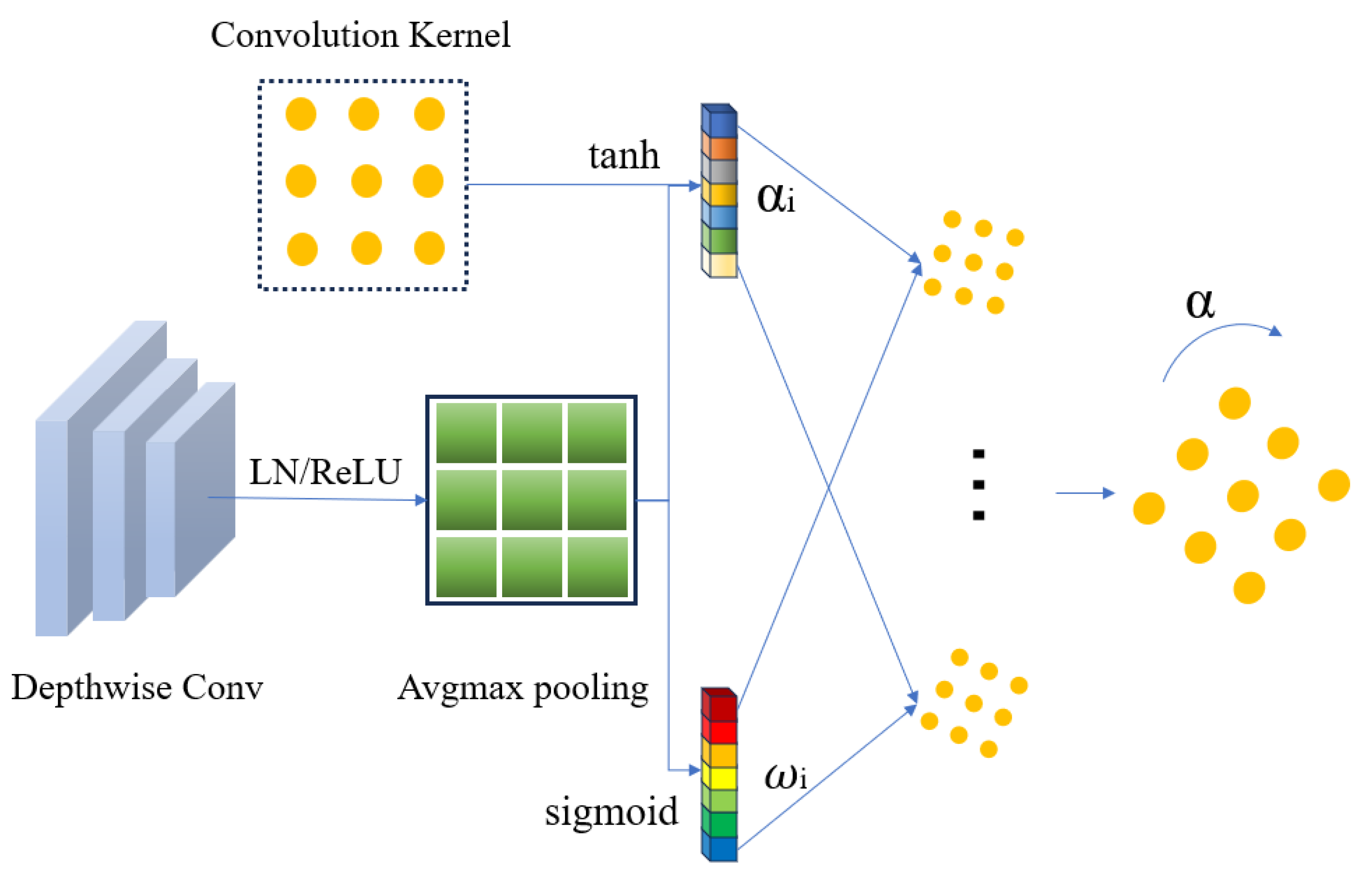
3.2. Dynamic Rotational Convolution Module
3.3. Feature Decoupling Module
3.4. S-A Dynamic Label Assignment Strategy
4. Experiment and Results
4.1. Dataset
4.2. Implementation Details
Evaluation Metrics
4.3. Results
Comparison of S3DR-Det with Existing Methods
4.4. Ablation Study
4.4.1. FDM
4.4.2. S-A
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tang, Y.; Li, H.; Zhang, W.; Bian, S.; Zhai, G.; Liu, M.; Zhang, X. Light weight DETR-YOLO method for detecting shipwreck target in side-scan sonar. Syst. Eng. Electron. 2022, 44, 2427–2436. [Google Scholar]
- Yu, Y.; Zhao, J.; Gong, Q.; Huang, C.; Zheng, G.; Ma, J. Real-Time Underwater Maritime Object Detection in Side-Scan Sonar Images Based on Transformer-YOLOv5. Remote Sens. 2021, 13, 3555. [Google Scholar] [CrossRef]
- Yulin, T.; Jin, S.; Bian, G.; Zhang, Y. Shipwreck Target Recognition in Side-Scan Sonar Images by Improved YOLOv3 Model Based on Transfer Learning. IEEE Access 2020, 8, 173450–173460. [Google Scholar] [CrossRef]
- Yulin, T.; Shaohua, J.; Gang, B.; Yonzhou, Z.; Fan, L. Wreckage Target Recognition in Side-scan Sonar Images Based on an Improved Faster R-CNN Model. In Proceedings of the 2020 International Conference on Big Data & Artificial Intelligence & Software Engineering (ICBASE), Bangkok, Thailand, 30 October–1 November 2020; pp. 348–354. [Google Scholar] [CrossRef]
- Yulin, T.; Shaohua, J.; Fuming, X.; Gang, B.; Yonghou, Z. Recognition of Side-scan Sonar Shipwreck Image Using Convolutional Neural Network. In Proceedings of the 2020 2nd International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Taiyuan, China, 23–25 October 2020; pp. 529–533. [Google Scholar] [CrossRef]
- Ma, Q.; Jin, S.; Bian, G.; Cui, Y. Multi-Scale Marine Object Detection in Side-Scan Sonar Images Based on BES-YOLO. Sensors 2024, 24, 4428. [Google Scholar] [CrossRef]
- Tang, Y.; Wang, L.; Jin, S.; Zhao, J.; Huang, C.; Yu, Y. AUV-Based Side-Scan Sonar Real-Time Method for Underwater-Target Detection. J. Mar. Sci. Eng. 2023, 11, 690. [Google Scholar] [CrossRef]
- Kong, W.; Hong, J.; Jia, M.; Yao, J.; Cong, W.; Hu, H. YOLOv3-DPFIN: A Dual-Path Feature Fusion Neural Network for Robust Real-Time Sonar Target Detection. IEEE Sens. J. 2020, 20, 3745–3756. [Google Scholar] [CrossRef]
- Zhao, J.; Li, J.; Li, M. Progress and Future Trend of Hydrographic Surveying and Charting. J. Geomat. 2009, 34, 25–27. [Google Scholar]
- Wang, J.; Cao, J.; Lu, B.; He, B. Underwater Target Detection Project Equipment Application and Development Trend. China Water Transp. 2016, 11, 43–44. [Google Scholar]
- Wang, X.; Wang, A.; Jiang, T. Review of application areas for side scan sonar image. Surv. Mapp. Bull. 2019, 1, 1–4. [Google Scholar] [CrossRef]
- Wang, J.; Zhou, J. Comprehensive Application of Side-scan Sonar and Multi-beam System in Shipwreck Survey. China Water Transp. 2010, 10, 35–37. [Google Scholar]
- Lu, Z.; Zhu, T.; Zhou, H.; Zhang, L.; Jia, C. An Image Enhancement Method for Side-Scan Sonar Images Based on Multi-Stage Repairing Image Fusion. Electronics 2023, 12, 3553. [Google Scholar] [CrossRef]
- Xie, Y.; Bore, N.; Folkesson, J. Bathymetric Reconstruction From Sidescan Sonar With Deep Neural Networks. IEEE J. Ocean. Eng. 2023, 48, 372–383. [Google Scholar] [CrossRef]
- Neupane, D.; Seok, J. A Review on Deep Learning-Based Approaches for Automatic Sonar Target Recognition. Elecronics 2020, 9, 1972. [Google Scholar] [CrossRef]
- Yang, D.; Wang, C.; Cheng, C.; Pan, G.; Zhang, F. Semantic Segmentation of Side-Scan Sonar Images with Few Samples. Electronics 2022, 11, 3002. [Google Scholar] [CrossRef]
- Hsu, W.-Y.; Lin, W.-Y. Ratio-and-Scale-Aware YOLO for Pedestrian Detection. IEEE Trans. Image Process. 2021, 30, 934–947. [Google Scholar] [CrossRef]
- Li, T.; Zhang, Z.; Zhu, M.; Cui, Z.; Wei, D. Combining transformer global and local feature extraction for object detection. Complex Intell. Syst. 2024, 10, 4897–4920. [Google Scholar] [CrossRef]
- Zhang, M.; Xu, S.; Song, W.; He, Q.; Wei, Q. Lightweight Underwater Object Detection Based on YOLO v4 and Multi-Scale Attentional Feature Fusion. Remote Sens. 2021, 13, 4706. [Google Scholar] [CrossRef]
- Dong, X.; Yan, S.; Duan, C. A lightweight vehicles detection network model based on YOLOv5. Eng. Appl. Artif. Intell. 2022, 113, 104914. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–24 June 2013; pp. 580–587. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016. ECCV 2016. Lecture Notes in Computer Science; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; Volume 9905. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Ali, F. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, Z.; Wang, H.; Weng, L.; Yang, Y. Ship Rotated Bounding Box Space for Ship Extraction From High-Resolution Optical Satellite Images With Complex Backgrounds. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1074–1078. [Google Scholar] [CrossRef]
- Zhang, Z.; Guo, W.; Zhu, S.; Yu, W. Toward Arbitrary-Oriented Ship Detection With Rotated Region Proposal and Discrimination Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1745–1749. [Google Scholar] [CrossRef]
- Deng, L.; Gong, Y.; Lu, X.; Lin, Y.; Ma, Z.; Xie, M. STELA: A Real-Time Scene Text Detector With Learned Anchor. IEEE Access 2019, 7, 153400–153407. [Google Scholar] [CrossRef]
- Yang, X.; Fu, K.; Sun, H.; Yang, J. R2CNN++: Multi-Dimensional Attention Based Rotation Invariant Detector with Robust Anchor Strategy. arXiv 2018, arXiv:1811.07126. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.; Lu, Q. Learning RoI Transformer for Detecting Oriented Objects in Aerial Images. arXiv 2018, arXiv:1812.00155. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-Oriented Scene Text Detection via Rotation Proposals. IEEE Trans. Multimed. 2017, 20, 3111–3122. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, G.; Yang, X.; Zhou, Y.; Wang, W.; Tang, J.; He, T.; Yan, J. Detecting Rotated Objects as Gaussian Distributions and its 3-D Generalization. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 4335–4354. [Google Scholar] [CrossRef]
- Yang, X.; Zhou, Y.; Zhang, G.; Yang, J.; Wang, W.; Yan, J.; Zhang, X.; Tian, Q. The KFIoU Loss for Rotated Object Detection. arXiv 2022, arXiv:2201.12558. [Google Scholar]
- Yi, Y.; Da, F. Phase-Shifting Coder: Predicting Accurate Orientation in Oriented Object Detection. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2022; pp. 13354–13363. [Google Scholar]
- Zhang, G.; Lu, S.; Zhang, W. CAD-Net: A Context-Aware Detection Network for Objects in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10015–10024. [Google Scholar] [CrossRef]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.-S.; Bai, X. Gliding Vertex on the Horizontal Bounding Box for Multi-Oriented Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1452–1459. [Google Scholar] [CrossRef] [PubMed]
- Pu, Y.; Wang, Y.; Xia, Z.; Han, Y.; Wang, Y.; Gan, W.; Wang, Z.; Song, S.; Huang, G. Adaptive Rotated Convolution for Rotated Object Detection. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Vancouver, BC, Canada, 17–24 June 2022; pp. 6566–6577. [Google Scholar]
- Han, J.; Ding, J.; Xue, N.; Xia, G.-S. ReDet: A Rotation-equivariant Detector for Aerial Object Detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2785–2794. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object. arXiv 2019, arXiv:1908.05612. [Google Scholar] [CrossRef]
- Pan, X.; Ren, Y.; Sheng, K.; Dong, W.; Yuan, H.; Guo, X.; Ma, C.; Xu, C. Dynamic Refinement Network for Oriented and Densely Packed Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11204–11213. [Google Scholar]
- Han, J.; Ding, J.; Li, J.; Xia, G.-S. Align Deep Features for Oriented Object Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J. On the Arbitrary-Oriented Object Detection: Classification Based Approaches Revisited. Int. J. Comput. Vis. 2022, 130, 1340–1365. [Google Scholar] [CrossRef]
- Zhu, Y.; Du, J.; Wu, X. Adaptive Period Embedding for Representing Oriented Objects in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7247–7257. [Google Scholar] [CrossRef]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the Gap Between Anchor-Based and Anchor-Free Detection via Adaptive Training Sample Selection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9756–9765. [Google Scholar]
- Hou, L.; Lu, K.; Xue, J.; Li, Y. Shape-Adaptive Selection and Measurement for Oriented Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 22 February–1 March 2022; Volume 36, pp. 923–932. [Google Scholar] [CrossRef]
- Ming, Q.; Zhou, Z.; Miao, L.; Zhang, H.; Li, L. Dynamic Anchor Learning for Arbitrary-Oriented Object Detection. arXiv 2020, arXiv:2012.04150. [Google Scholar] [CrossRef]
- Huang, Z.; Li, W.; Xia, X.-G.; Tao, R. A General Gaussian Heatmap Label Assignment for Arbitrary-Oriented Object Detection. IEEE Trans. Image Process. 2022, 31, 1895–1910. [Google Scholar] [CrossRef]
- Li, W.; Zhu, J. Oriented RepPoints for Aerial Object Detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2022; pp. 1819–1828. [Google Scholar]
- Xiao, Z.; Wang, K.; Wan, Q.; Tan, X.; Xu, C.; Xia, F. A2S-Det: Efficiency Anchor Matching in Aerial Image Oriented Object Detection. Remote Sens. 2021, 13, 73. [Google Scholar] [CrossRef]
- Peng, C.; Jin, S.; Bian, G.; Cui, Y. SIGAN: A Multi-Scale Generative Adversarial Network for Underwater Sonar Image Super-Resolution. J. Mar. Sci. Eng. 2024, 12, 1057. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Dataset | R (%) | AP (%) | Dataset | R (%) | AP (%) | |
|---|---|---|---|---|---|---|---|
| two-stage | RoI Transformer | SSUTD | 91.83 | 89.19 | DNASI | 90.85 | 87.64 |
| Oriented R-CNN | 91.23 | 88.76 | 90.50 | 85.82 | |||
| Rotated Faster R-CNN | 86.77 | 74.98 | 86.12 | 73.64 | |||
| Gliding Vertex | 75.68 | 63.12 | 78.74 | 64.28 | |||
| CFA | 86.12 | 73.64 | 87.33 | 75.87 | |||
| one-stage | Rotated RetinaNet | SSUTD | 81.53 | 76.21 | DNASI | 83.58 | 76.28 |
| S2Anet | 88.74 | 81.06 | 87.52 | 79.63 | |||
| ATSS | 83.1 | 76.7 | 83.37 | 75.92 | |||
| DRN | 83.58 | 76.28 | 85.12 | 77.56 | |||
| R3Det | 84.11 | 77.75 | 81.53 | 76.21 | |||
| R3Det-KFIoU | 87.52 | 79.63 | 89.16 | 81.20 | |||
| S3DR-Det | 92.70 | 89.68 | 93.98 | 90.19 |
| AFO | DRM | R (%) | AP (%) |
|---|---|---|---|
| √ | - | 90.12 | 87.24 |
| - | √ | 88.98 | 86.12 |
| √ | √ | 92.70 | 89.68 |
| α | β | γ | AP (%) |
|---|---|---|---|
| 0.4 | 0.3 | 0.3 | 88.42 |
| 0.2 | 0.4 | 83.15 | |
| 0.1 | 0.5 | 79.54 | |
| 0.5 | 0.3 | 0.2 | 88.82 |
| 0.2 | 0.3 | 89.68 | |
| 0.1 | 0.4 | 84.10 | |
| 0.6 | 0.3 | 0.1 | 77.95 |
| 0.2 | 0.2 | 83.62 | |
| 0.1 | 0.3 | 75.56 |
| DRC | FDM | S-A | R (%) | AP (%) |
|---|---|---|---|---|
| - | - | - | 88.74 | 81.06 |
| √ | √ | - | 90.54 | 85.41 |
| √ | - | √ | 90.69 | 85.92 |
| - | √ | √ | 89.48 | 84.38 |
| √ | √ | √ | 92.70 | 89.68 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Q.; Jin, S.; Bian, G.; Cui, Y.; Liu, G.; Wang, Y. S3DR-Det: A Rotating Target Detection Model for High Aspect Ratio Shipwreck Targets in Side-Scan Sonar Images. Remote Sens. 2025, 17, 312. https://doi.org/10.3390/rs17020312
Ma Q, Jin S, Bian G, Cui Y, Liu G, Wang Y. S3DR-Det: A Rotating Target Detection Model for High Aspect Ratio Shipwreck Targets in Side-Scan Sonar Images. Remote Sensing. 2025; 17(2):312. https://doi.org/10.3390/rs17020312
Chicago/Turabian StyleMa, Quanhong, Shaohua Jin, Gang Bian, Yang Cui, Guoqing Liu, and Yihan Wang. 2025. "S3DR-Det: A Rotating Target Detection Model for High Aspect Ratio Shipwreck Targets in Side-Scan Sonar Images" Remote Sensing 17, no. 2: 312. https://doi.org/10.3390/rs17020312
APA StyleMa, Q., Jin, S., Bian, G., Cui, Y., Liu, G., & Wang, Y. (2025). S3DR-Det: A Rotating Target Detection Model for High Aspect Ratio Shipwreck Targets in Side-Scan Sonar Images. Remote Sensing, 17(2), 312. https://doi.org/10.3390/rs17020312