
DyGS-SLAM: Realistic Map Reconstruction in Dynamic Scenes Based on Double-Constrained Visual SLAM



Abstract

1. Introduction
- We introduce DyGS-SLAM, a double constrained dynamic Visual SLAM system based on 3D Gaussian, capable of accurately predicting camera poses, reconstructing high-quality dense maps, and synthesizing novel view images in dynamic scenes.
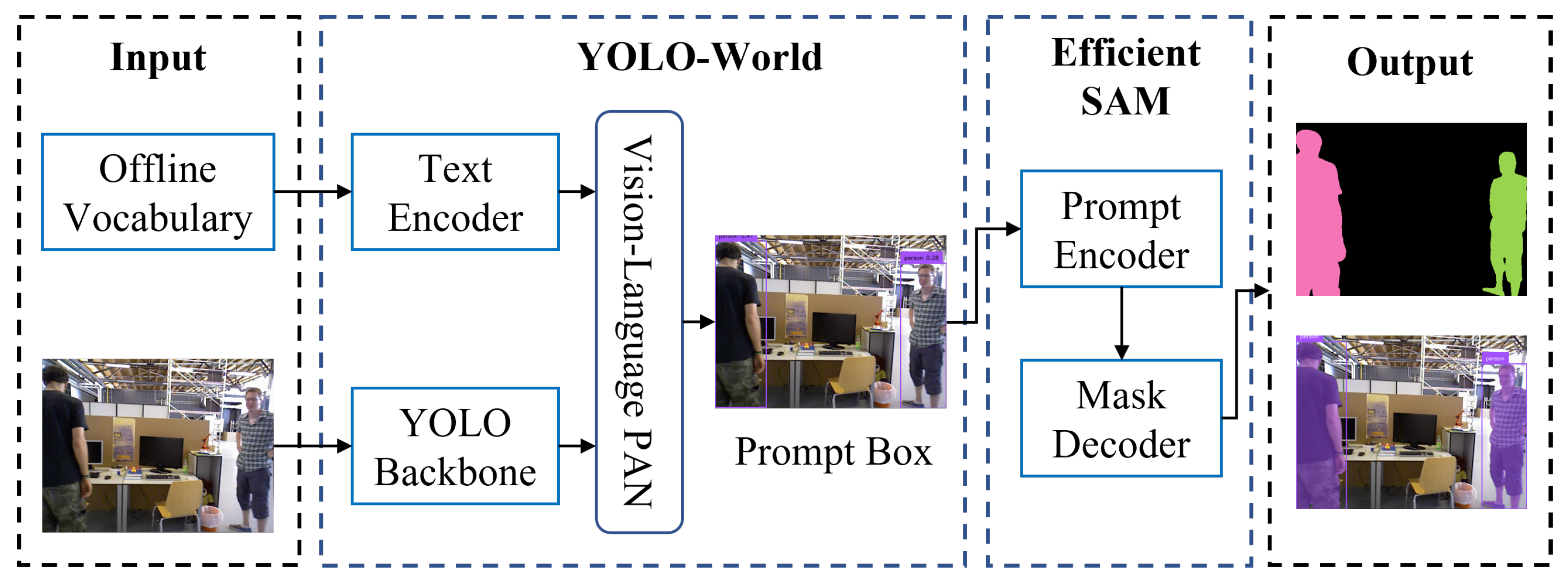
- A zero-shot dynamic feature point removal method is proposed. We enhanced the Segment Anything Model (SAM) and combined it with multi-view geometry methods to achieve dynamic feature point removal. This enables our method to have a wider application space than other methods. Simultaneously, a background inpainting module is provided to repair static structures occluded by dynamic objects.
- A novel 3D Gaussian-based scene representation and map optimization method is proposed. Underlying Gaussian map construction and differentiable rendering are performed on the resulting camera pose and point cloud, while the 3D scene is optimized based on the inpainted frames. This method addresses the interference of dynamic information in Gaussian map optimization, enabling the synthesis of novel view images and the generation of more realistic 3D scenes.
- We conducted extensive experiments on multiple datasets, demonstrating that our method achieves state-of-the-art (SOTA) performance in pose estimation and mapping.
2. Related Works
2.1. Traditional Dynamic Visual SLAM
2.2. Dynamic Visual SLAM with Inpainting
2.3. Neural Radiance Field-Based SLAM
2.4. Gaussian Radiance Field-Based SLAM
3. Method
3.1. Dynamic Object Elimination with Double-Constrained
3.1.1. Open-World Semantic Segmentation
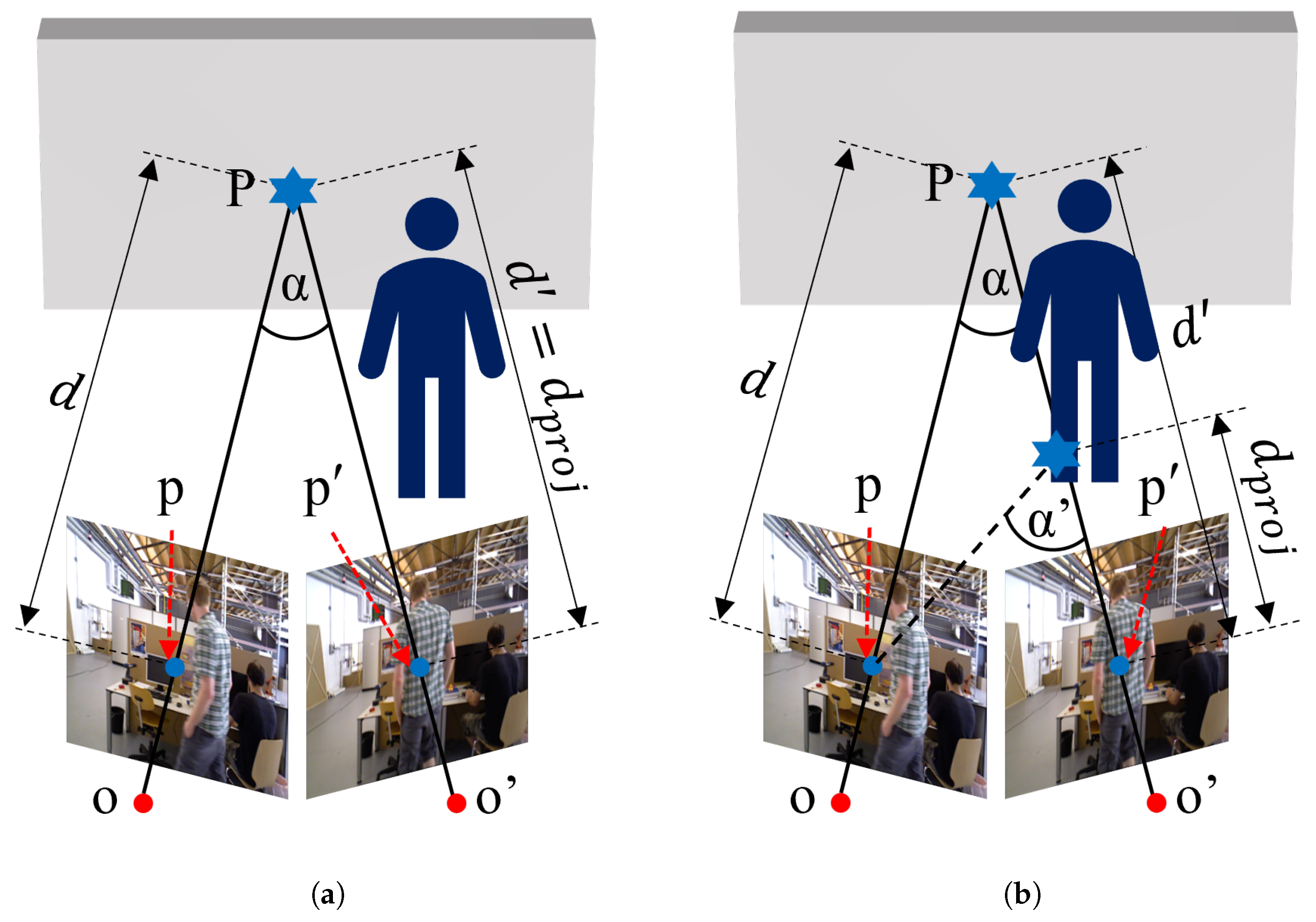
3.1.2. Multiple View Geometry Constraint
3.1.3. Background Inpainting
3.2. High-Quality Keyframe Selection
3.3. Scene Representation and Rendering
3.3.1. Gaussian Map Representation
3.3.2. Image Formation Model and Differentiable Rendering
3.3.3. Gaussian Map Optimization
4. Experimental Results
4.1. Experimental Setup
4.1.1. Implementation Details
4.1.2. Datasets
4.1.3. Baselines
4.1.4. Metrics
4.2. Evaluation on the TUM Dataset
4.2.1. Evaluation of Trajectory
4.2.2. Evaluation of Reconstruction Quality
4.3. Evaluation on the Bonn Dataset
4.3.1. Evaluation of Trajectory
4.3.2. Evaluation of Reconstruction Quality
4.4. Evaluation on the Replica Dataset
4.5. Evaluation in Real Environment
4.6. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Huang, Y.; Xie, F.; Zhao, J.; Gao, Z.; Chen, J.; Zhao, F.; Liu, X. ULG-SLAM: A Novel Unsupervised Learning and Geometric Feature-Based Visual SLAM Algorithm for Robot Localizability Estimation. Remote Sens. 2024, 16, 1968. [Google Scholar] [CrossRef]
- Wang, W.; Wang, C.; Liu, J.; Su, X.; Luo, B.; Zhang, C. HVL-SLAM: Hybrid Vision and LiDAR Fusion for SLAM. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5706514. [Google Scholar] [CrossRef]
- Yang, D.; Bi, S.; Wang, W.; Yuan, C.; Qi, X.; Cai, Y. DRE-SLAM: Dynamic RGB-D encoder SLAM for a differential-drive robot. Remote Sens. 2019, 11, 380. [Google Scholar] [CrossRef]
- Chen, Z.; Zhu, H.; Yu, B.; Jiang, C.; Hua, C.; Fu, X.; Kuang, X. IGE-LIO: Intensity Gradient Enhanced Tightly-Coupled LiDAR-Inertial Odometry. IEEE Trans. Instrum. Meas. 2024, 73, 8506411. [Google Scholar] [CrossRef]
- Wu, H.; Liu, Y.; Wang, C.; Wei, Y. An Effective 3D Instance Map Reconstruction Method Based on RGBD Images for Indoor Scene. Remote Sens. 2025, 17, 139. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardos, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodriguez, J.J.G.; Montiel, J.M.M.; Tardos, J.D. Orb-slam3: An accurate open-source library for visual, visual-inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.L.; Shen, S.J. Vins-mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Xu, X.; Zhang, L.; Yang, J.; Cao, C.; Wang, W.; Ran, Y.; Tan, Z.; Luo, M. A review of multi-sensor fusion slam systems based on 3D LIDAR. Remote Sens. 2022, 14, 2835. [Google Scholar] [CrossRef]
- Yan, L.; Hu, X.; Zhao, L.; Chen, Y.; Wei, P.; Xie, H. Dgs-slam: A fast and robust rgbd slam in dynamic environments combined by geometric and semantic information. Remote Sens. 2022, 14, 795. [Google Scholar] [CrossRef]
- Yuan, C.; Xu, Y.; Zhou, Q. PLDS-SLAM: Point and line features SLAM in dynamic environment. Remote Sens. 2023, 15, 1893. [Google Scholar] [CrossRef]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2022, 65, 99–106. [Google Scholar] [CrossRef]
- Müller, T.; Evans, A.; Schied, C.; Keller, A. Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans. Graph. 2022, 41, 1–15. [Google Scholar] [CrossRef]
- Xu, Q.G.; Xu, Z.X.; Philip, J.; Bi, S.; Shu, Z.X.; Sunkavalli, K.; Neumann, U. Point-nerf: Point-based neural radiance fields. In Proceedings of the 2022 IEEE/Cvf Conference on Computer Vision and Pattern Recognition (Cvpr 2022), New Orleans, LA, USA, 18–24 June 2022; pp. 5428–5438. [Google Scholar]
- Sucar, E.; Liu, S.K.; Ortiz, J.; Davison, A.J. Imap: Implicit mapping and positioning in real-time. In Proceedings of the 2021 IEEE/Cvf International Conference on Computer Vision (ICCV 2021), Virtual Conference, 11–17 October 2021; pp. 6209–6218. [Google Scholar]
- Zhu, Z.; Peng, S.; Larsson, V.; Xu, W.; Bao, H.; Cui, Z.; Oswald, M.R.; Pollefeys, M. Nice-slam: Neural implicit scalable encoding for slam. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, 18–24 June 2022; IEEE Computer Society. Volume 2022, pp. 12776–12786. [Google Scholar]
- Sandström, E.; Li, Y.; Gool, L.V.; Oswald, M.R. Point-slam: Dense neural point cloud-based slam. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 18433–18444. [Google Scholar]
- Yang, X.; Li, H.; Zhai, H.; Ming, Y.; Liu, Y.; Zhang, G. Vox-fusion: Dense tracking and mapping with voxel-based neural implicit representation. In Proceedings of the 21st IEEE International Symposium on Mixed and Augmented Reality, ISMAR 2022, Singapore, 17–21 October 2022; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2022; pp. 499–507. [Google Scholar]
- Ruan, C.Y.; Zang, Q.Y.; Zhang, K.H.; Huang, K. Dn-slam: A visual slam with orb features and nerf mapping in dynamic environments. IEEE Sens. J. 2024, 24, 5279–5287. [Google Scholar] [CrossRef]
- Kerbl, B.; Kopanas, G.; Leimkühler, T.; Drettakis, G. 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph. 2023, 42, 1–14. [Google Scholar] [CrossRef]
- Zhu, H.; Kuang, X.; Su, T.; Chen, Z.; Yu, B.; Li, B. Dual-Constraint Registration LiDAR SLAM Based on Grid Maps Enhancement in Off-Road Environment. Remote Sens. 2022, 14, 5705. [Google Scholar] [CrossRef]
- Wu, C.; Duan, Y.; Zhang, X.; Sheng, Y.; Ji, J.; Zhang, Y. Mm-gaussian: 3D gaussian-based multi-modal fusion for localization and reconstruction in unbounded scenes. IEEE/RSJ Int. Conf. Intell. Robots Syst. (IROS) 2024, 12287–12293. [Google Scholar]
- Matsuki, H.; Murai, R.; Kelly, P.H.; Davison, A.J. Gaussian splatting slam. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 18039–18048. [Google Scholar]
- Yan, C.; Qu, D.; Xu, D.; Zhao, B.; Wang, Z.; Wang, D.; Li, X. Gs-slam: Dense visual slam with 3d gaussian splatting. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 19595–19604. [Google Scholar]
- Huang, H.; Li, L.; Cheng, H.; Yeung, S.K. Photo-SLAM: Real-time Simultaneous Localization and Photorealistic Mapping for Monocular Stereo and RGB-D Cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 21584–21593. [Google Scholar]
- Keetha, N.; Karhade, J.; Jatavallabhula, K.M.; Yang, G.; Scherer, S.; Ramanan, D.; Luiten, J. SplaTAM: Splat Track & Map 3D Gaussians for Dense RGB-D SLAM. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 21357–21366. [Google Scholar]
- Tosi, F.; Zhang, Y.; Gong, Z.; Sandström, E.; Mattoccia, S.; Oswald, M.R.; Poggi, M. How nerfs and 3d gaussian splatting are reshaping slam: A survey. arXiv 2024, arXiv:2402.13255. [Google Scholar]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. Svo: Fast semi-direct monocular visual odometry. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; IEEE: New York, NY, USA, 2014; pp. 15–22. [Google Scholar]
- Chen, W.; Zhou, C.; Shang, G.; Wang, X.; Li, Z.; Xu, C.; Hu, K. SLAM overview: From single sensor to heterogeneous fusion. Remote Sens. 2022, 14, 6033. [Google Scholar] [CrossRef]
- Klein, G.; Murray, D. Parallel tracking and mapping for small ar workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; pp. 225–234. [Google Scholar]
- Zhang, C.; Zhang, R.; Jin, S.; Yi, X. PFD-SLAM: A new RGB-D SLAM for dynamic indoor environments based on non-prior semantic segmentation. Remote Sens. 2022, 14, 2445. [Google Scholar] [CrossRef]
- Yu, H.; Wang, Q.; Yan, C.; Feng, Y.; Sun, Y.; Li, L. DLD-SLAM: RGB-D Visual Simultaneous Localisation and Mapping in Indoor Dynamic Environments Based on Deep Learning. Remote Sens. 2024, 16, 246. [Google Scholar] [CrossRef]
- Cheng, S.H.; Sun, C.H.; Zhang, S.J.; Zhang, D.F. Sg-slam: A real-time rgb-d visual slam toward dynamic scenes with semantic and geometric information. IEEE Trans. Instrum. Meas. 2023, 72, 7501012. [Google Scholar] [CrossRef]
- Bescos, B.; Facil, J.M.; Civera, J.; Neira, J. Dynaslam: Tracking, mapping, and inpainting in dynamic scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef]
- Li, A.; Wang, J.; Xu, M.; Chen, Z. Dp-slam: A visual slam with moving probability towards dynamic environments. Inf. Sci. 2021, 556, 128–142. [Google Scholar] [CrossRef]
- Ran, T.; Yuan, L.; Zhang, J.; Tang, D.; He, L. Rs-slam: A robust semantic slam in dynamic environments based on rgb-d sensor. IEEE Sens. J. 2021, 21, 20657–20664. [Google Scholar] [CrossRef]
- He, J.M.; Li, M.R.; Wang, Y.Y.; Wang, H.Y. Ovd-slam: An online visual slam for dynamic environments. IEEE Sens. J. 2023, 23, 13210–13219. [Google Scholar] [CrossRef]
- Chang, J.; Dong, N.; Li, D. A real-time dynamic object segmentation framework for SLAM system in dynamic scenes. IEEE Trans. Instrum. Meas. 2021, 70, 1–9. [Google Scholar] [CrossRef]
- Trombley, C.M.; Das, S.K.; Popa, D.O. Dynamic-gan: Learning spatial-temporal attention for dynamic object removal in feature dense environments. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; IEEE: New York, NY, USA, 2022; pp. 12189–12195. [Google Scholar]
- Bescos, B.; Cadena, C.; Neira, J. Empty cities: A dynamic-object-invariant space for visual slam. IEEE Trans. Robot. 2021, 37, 433–451. [Google Scholar] [CrossRef]
- Johari, M.M.; Carta, C.; Fleuret, F. Eslam: Efficient dense slam system based on hybrid representation of signed distance fields. In Proceedings of the 2023 IEEE/Cvf Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 17408–17419. [Google Scholar]
- Xu, Z.; Niu, J.; Li, Q.; Ren, T.; Chen, C. Nid-slam: Neural implicit representation-based rgb-d slam in dynamic environments. arXiv 2024, arXiv:2401.01189. [Google Scholar]
- Li, M.; He, J.; Jiang, G.; Wang, H. Ddn-slam: Real-time dense dynamic neural implicit slam with joint semantic encoding. arXiv 2024, arXiv:2401.01545. [Google Scholar]
- Lin, J.; Li, Z.; Tang, X.; Liu, J.; Liu, S.; Liu, J.; Lu, Y.; Wu, X.; Xu, S.; Yan, Y.; et al. Vastgaussian: Vast 3d gaussians for large scene reconstruction. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 5166–5175. [Google Scholar]
- Zhong, Y.; Hu, S.; Huang, G.; Bai, L.; Li, Q. Wf-slam: A robust vslam for dynamic scenarios via weighted features. IEEE Sens. J. 2022, 22, 10818–10827. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 4015–4026. [Google Scholar]
- Xiong, Y.; Varadarajan, B.; Wu, L.; Xiang, X.; Xiao, F.; Zhu, C.; Dai, X.; Wang, D.; Sun, F.; Iandola, F.; et al. Efficientsam: Leveraged masked image pretraining for efficient segment anything. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16111–16121. [Google Scholar]
- Cheng, T.; Song, L.; Ge, Y.; Liu, W.; Wang, X.; Shan, Y. Yolo-world: Real-time open-vocabulary object detection. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 16901–16911. [Google Scholar]
- Tan, W.; Liu, H.M.; Dong, Z.L.; Zhang, G.F.; Bao, H.J. Robust monocular slam in dynamic environments. In Proceedings of the 2013 IEEE International Symposium on Mixed and Augmented Reality (Ismar)—Science and Technology, Adelaide, Australia, 1–4 October 2013; pp. 209–218. [Google Scholar]
- Zhou, S.; Li, C.; Chan, K.C.; Loy, C.C. Propainter: Improving propagation and transformer for video inpainting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 10477–10486. [Google Scholar]
- Liu, Y.L.; Gao, C.; Meuleman, A.; Tseng, H.Y.; Saraf, A.; Kim, C.; Chuang, Y.Y.; Kopf, J.; Huang, J.B. Robust dynamic radiance fields. In Proceedings of the 2023 IEEE/Cvf Conference on Computer Vision and Pattern Recognition, CVPR, Vancouver, BC, Canada, 17–24 June 2023; pp. 13–23. [Google Scholar]
- Du, Z.J.; Huang, S.S.; Mu, T.J.; Zhao, Q.; Martin, R.R.; Xu, K. Accurate dynamic slam using crf-based long-term consistency. IEEE Trans. Vis. Comput. Graph. 2022, 28, 1745–1757. [Google Scholar] [CrossRef]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of rgb-d slam systems. In Proceedings of the 2012 IEEE/Rsj International Conference on Intelligent Robots and Systems (IROS), Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
- Palazzolo, E.; Behley, J.; Lottes, P.; Giguère, P.; Stachniss, C. Refusion: 3D reconstruction in dynamic environments for rgb-d cameras exploiting residuals. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 7855–7862. [Google Scholar]
- Straub, J.; Whelan, T.; Ma, L.; Chen, Y.; Wijmans, E.; Green, S.; Engel, J.J.; Mur-Artal, R.; Ren, C.; Verma, S.; et al. The Replica dataset: A digital replica of indoor spaces. arXiv 2019, arXiv:1906.05797. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | ORB-SLAM3 | DynaSLAM | LC-SLAM | NICE-SLAM | SplaTAM | DN-SLAM | DyGS-SLAM |
|---|---|---|---|---|---|---|---|
| w_xyz | 0.358 | 0.015 | 0.022 | 0.826 | 1.292 | 0.015 | 0.014 |
| w_rpy | 0.752 | 0.085 | 0.053 | 1.275 | 1.442 | 0.032 | 0.045 |
| w_static | 0.309 | 0.009 | 0.022 | 0.327 | 0.778 | 0.008 | 0.008 |
| w_halfsphere | 0.445 | 0.040 | 0.036 | 0.795 | 0.997 | 0.026 | 0.035 |
| s_xyz | 0.010 | 0.013 | 0.012 | 0.211 | 0.016 | 0.011 | 0.009 |
| s_halfsphere | 0.029 | 0.023 | 0.024 | 0.542 | 0.139 | 0.014 | 0.013 |
| Sequence | ORB-SLAM3 | DynaSLAM | LC-SLAM | NICE-SLAM | SplaTAM | DN-SLAM | DyGS-SLAM |
|---|---|---|---|---|---|---|---|
| balloon | 0.052 | 0.031 | 0.032 | 2.853 | 0.357 | 0.030 | 0.030 |
| balloon2 | 0.211 | 0.034 | 0.028 | 1.946 | 0.372 | 0.025 | 0.025 |
| crowd | 0.386 | 0.022 | 0.023 | 1.757 | 1.767 | 0.025 | 0.020 |
| crowd2 | 1.224 | 0.030 | 0.067 | 3.887 | 4.731 | 0.028 | 0.027 |
| crowd3 | 0.897 | 0.039 | 0.037 | 1.430 | 1.924 | 0.026 | 0.036 |
| move_no_b | 0.176 | 0.023 | 0.025 | 0.178 | 0.058 | 0.026 | 0.022 |
| move_o_b2 | 0.693 | 0.286 | 0.297 | 0.832 | 0.600 | 0.120 | 0.208 |
| person1 | 0.074 | 0.064 | 0.050 | 0.398 | 1.374 | 0.038 | 0.048 |
| person2 | 1.051 | 0.114 | 0.055 | 0.843 | 0.918 | 0.042 | 0.040 |
| Methods | Metrics | Room0 | Room1 | Room2 | Office0 | Office1 | Office2 | Office3 | Office4 |
|---|---|---|---|---|---|---|---|---|---|
| NICE-SLAM | PSNR ↑ | 22.12 | 22.47 | 24.52 | 29.07 | 30.34 | 19.66 | 22.23 | 24.94 |
| SSIM ↑ | 0.69 | 0.76 | 0.81 | 0.87 | 0.89 | 0.80 | 0.80 | 0.86 | |
| LPIPS ↓ | 0.33 | 0.27 | 0.21 | 0.23 | 0.18 | 0.24 | 0.21 | 0.20 | |
| SplaTAM | PSNR ↑ | 32.86 | 33.89 | 35.25 | 38.26 | 39.17 | 31.97 | 29.70 | 31.81 |
| SSIM ↑ | 0.98 | 0.97 | 0.98 | 0.98 | 0.98 | 0.97 | 0.95 | 0.95 | |
| LPIPS ↓ | 0.07 | 0.10 | 0.08 | 0.09 | 0.09 | 0.10 | 0.12 | 0.15 | |
| DyGS-SLAM | PSNR ↑ | 33.51 | 34.25 | 35.57 | 37.54 | 39.87 | 32.59 | 31.48 | 34.19 |
| SSIM ↑ | 0.97 | 0.97 | 0.98 | 0.99 | 0.98 | 0.97 | 0.96 | 0.98 | |
| LPIPS ↓ | 0.08 | 0.09 | 0.08 | 0.07 | 0.08 | 0.10 | 0.11 | 0.13 |
| Tasks | Runtime/Frame |
|---|---|
| Feature Extraction | 0.01 s |
| Dynamic Object Elimination | 0.18 s |
| Background Inpainting | 0.09 s |
| Rendering | 0.13 s |
| Sequence | Learning | Geometry | Learning + Geometry |
|---|---|---|---|
| walking_xyz | 0.015 | 0.016 | 0.014 |
| walking_rpy | 0.052 | 0.105 | 0.045 |
| walking_static | 0.007 | 0.008 | 0.008 |
| walking_halfsphere | 0.035 | 0.116 | 0.035 |
| sitting_xyz | 0.015 | 0.010 | 0.009 |
| sitting_halfsphere | 0.022 | 0.019 | 0.013 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, F.; Zhao, Y.; Chen, Z.; Jiang, C.; Zhu, H.; Hu, X. DyGS-SLAM: Realistic Map Reconstruction in Dynamic Scenes Based on Double-Constrained Visual SLAM. Remote Sens. 2025, 17, 625. https://doi.org/10.3390/rs17040625
Zhu F, Zhao Y, Chen Z, Jiang C, Zhu H, Hu X. DyGS-SLAM: Realistic Map Reconstruction in Dynamic Scenes Based on Double-Constrained Visual SLAM. Remote Sensing. 2025; 17(4):625. https://doi.org/10.3390/rs17040625
Chicago/Turabian StyleZhu, Fan, Yifan Zhao, Ziyu Chen, Chunmao Jiang, Hui Zhu, and Xiaoxi Hu. 2025. "DyGS-SLAM: Realistic Map Reconstruction in Dynamic Scenes Based on Double-Constrained Visual SLAM" Remote Sensing 17, no. 4: 625. https://doi.org/10.3390/rs17040625
APA StyleZhu, F., Zhao, Y., Chen, Z., Jiang, C., Zhu, H., & Hu, X. (2025). DyGS-SLAM: Realistic Map Reconstruction in Dynamic Scenes Based on Double-Constrained Visual SLAM. Remote Sensing, 17(4), 625. https://doi.org/10.3390/rs17040625