
Deep Learning-Based Feature Matching Algorithm for Multi-Beam and Side-Scan Images


Abstract
1. Introduction
- (1)
- Applying the LoFTR algorithm to underwater multi-beam and side-scan image matching tasks, effectively addressing the challenges posed by large geometric distortions and resolution differences in multi-beam and side-scan images;
- (2)
- Establish a multi-beam and side-scan image dataset to address the lack of such data in underwater applications;
- (3)
- Use symmetric epipolar distance as the loss function for model training to constrain mismatched keypoint pairs.
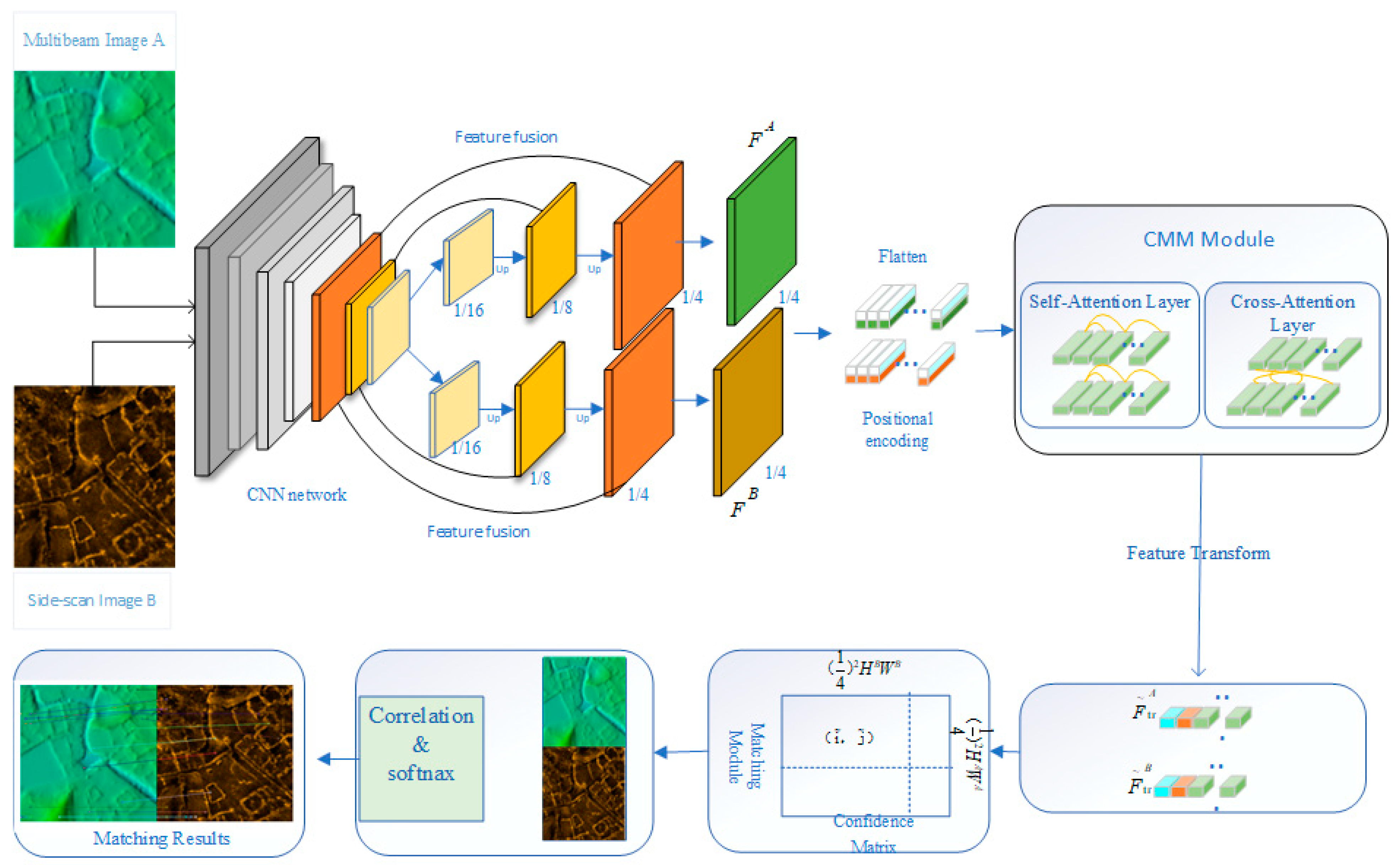
2. Model and Methods
2.1. Deep Learning-Based Multi-Beam and Side-Scan Image Feature Point Matching Model
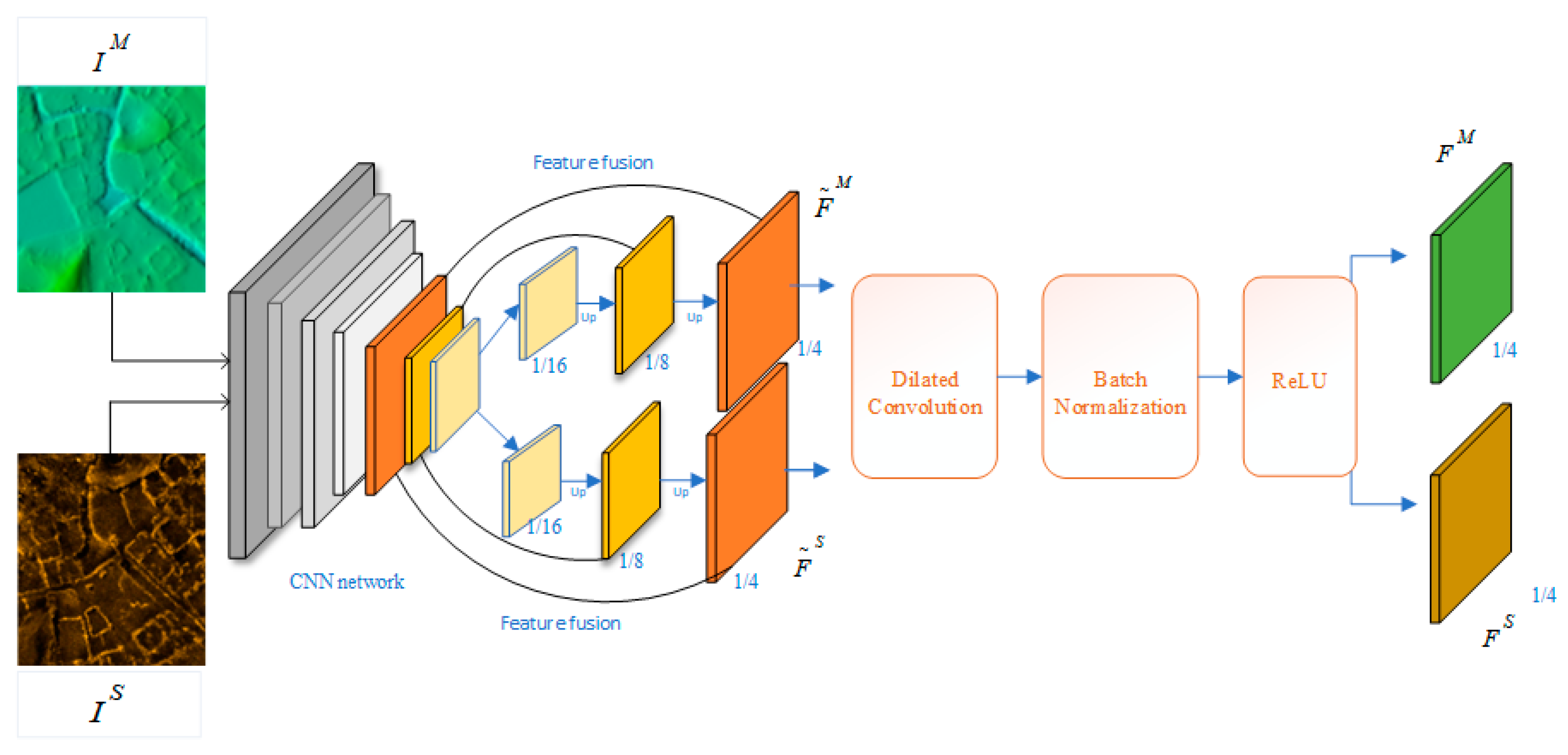
2.1.1. Feature Extraction
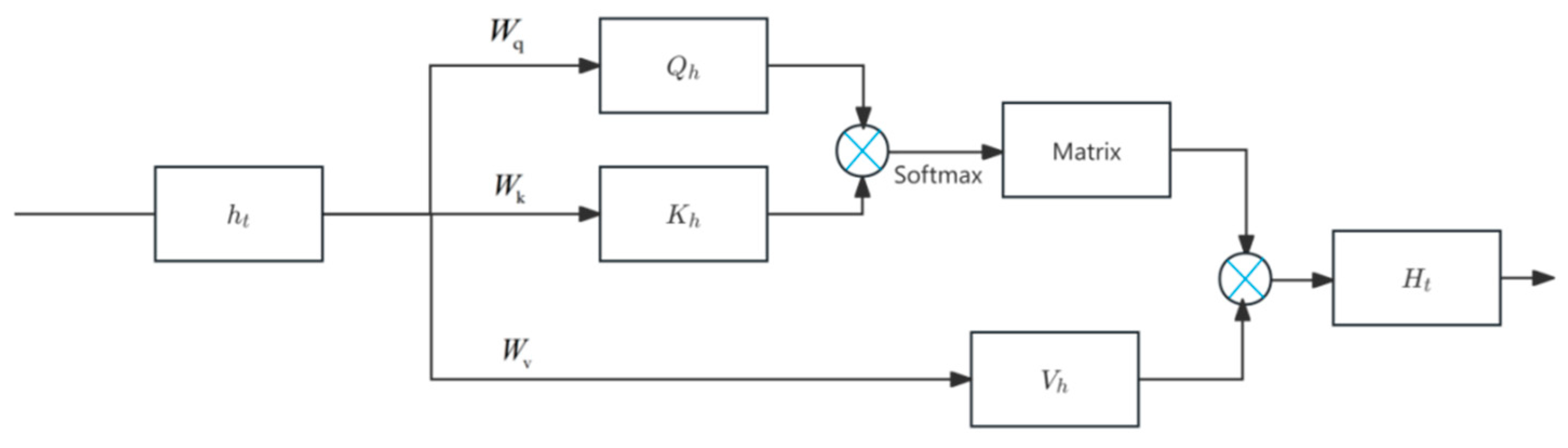
2.1.2. Attention Mechanism
Self-Attention Mechanism
Cross-Attention Mechanism
2.2. Loss Function
2.3. Evaluation Metrics
3. Experimental Area and Data
3.1. Experimental Area
3.2. Experimental Data
3.3. Dataset Construction
4. Results and Analysis
4.1. Experimental Setup
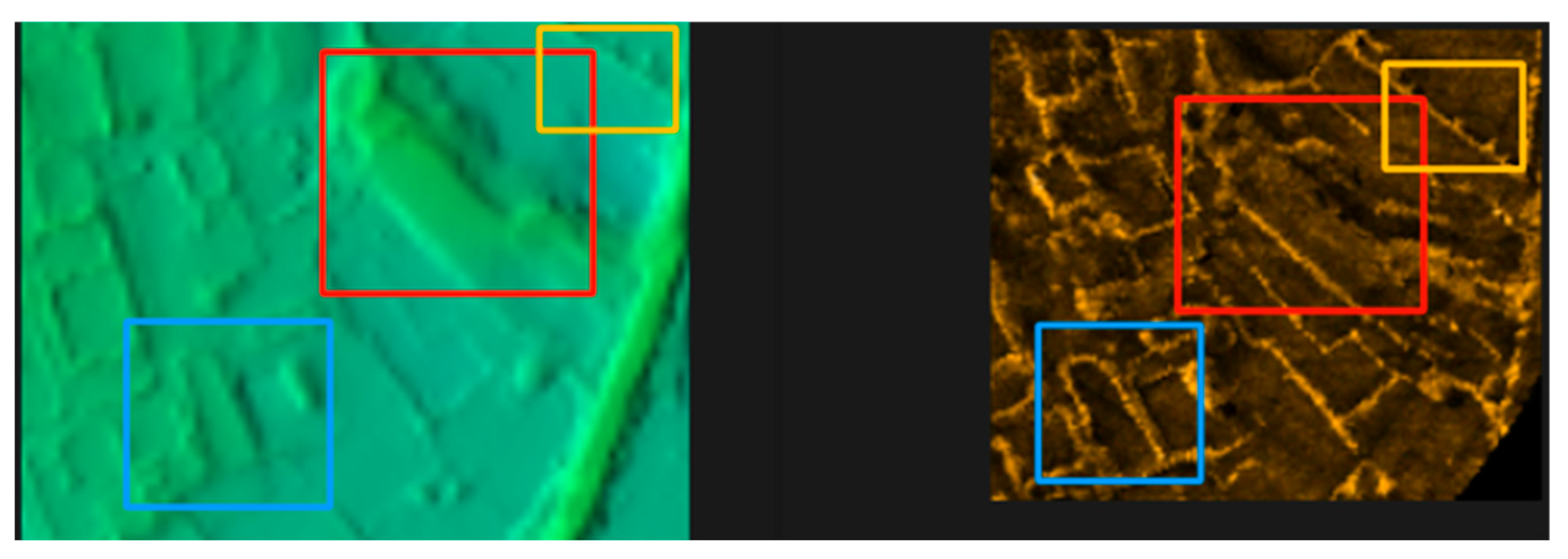
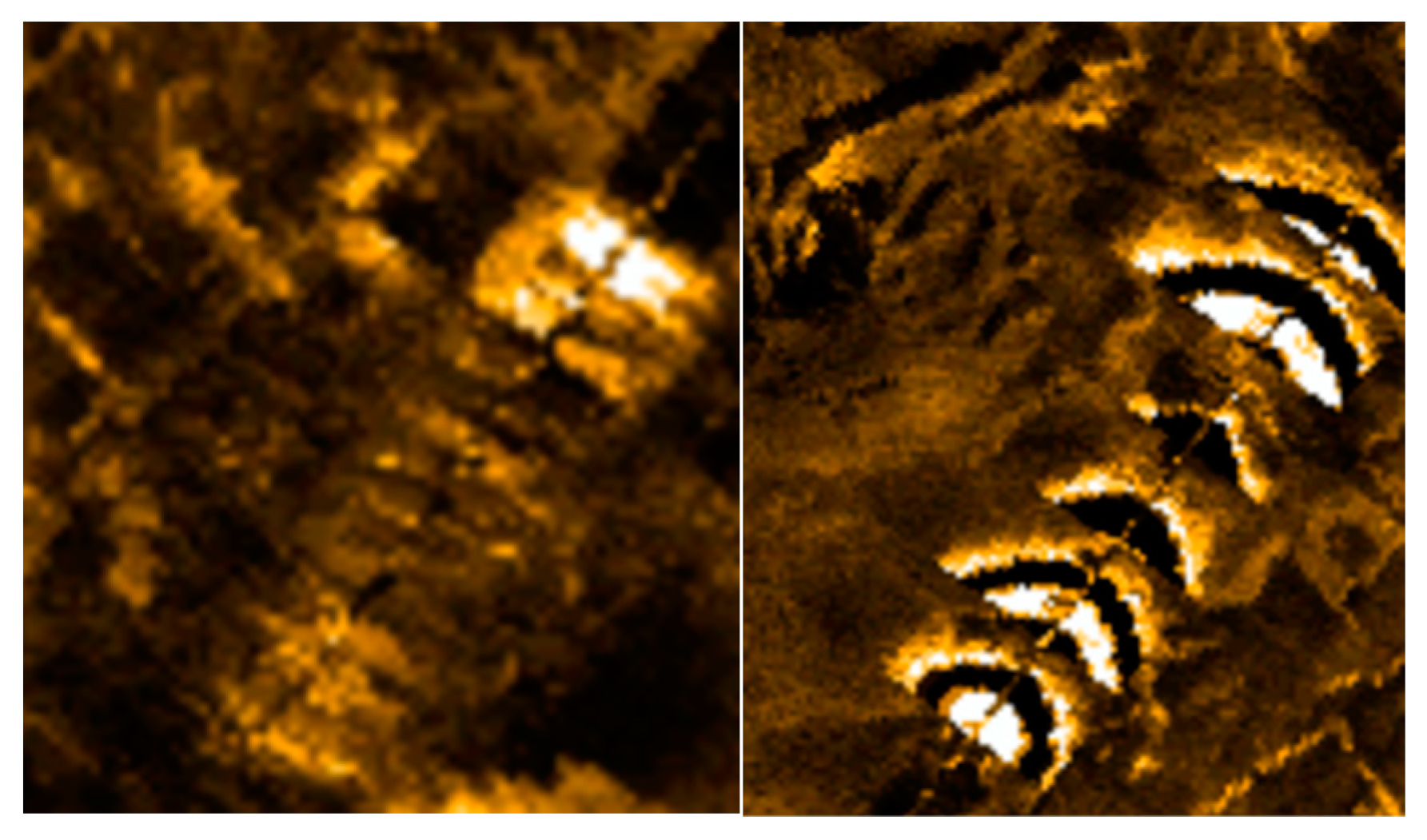
4.2. Image Matching Experiment
4.3. Ablation Experiment Results
4.4. Analysis of Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Correction Statement
References
- Hu, Y.; Liu, Y.; Ding, J.; Liu, B.; Chu, Z. Regional archaeological underwater survey method: Applications and implications. Archaeol. Prospect. 2022, 29, 607–622. [Google Scholar] [CrossRef]
- Reggiannini, M.; Salvetti, O. Seafloor analysis and understanding for underwater archeology. J. Cult. Herit. 2017, 24, 147–156. [Google Scholar] [CrossRef]
- Dura, E.; Zhang, Y.; Liao, X.; Dobeck, G.J.; Carin, L. Active learning for detection of mine-like objects in side-scan sonar imagery. IEEE J. Ocean. Eng. 2005, 30, 360–371. [Google Scholar] [CrossRef]
- Wu, Z.; Yang, F.; Luo, X.; Li, S. High-Resolution Submarine Topography—Theory and Technology for Surveying and Post-Processing; Science PressEditor: Beijing, China, 2017. [Google Scholar]
- Lazaridis, G.; Petrou, M. Image registration using the Walsh transform. IEEE Trans. Image Process 2006, 15, 2343–2357. [Google Scholar] [CrossRef]
- Yang, F.; Wu, Z.; Du, Z.; Jin, X. Co-registering and Fusion of Digital Information of Multi-beam Sonar and Side-scan Sonar. Geomat. Inf. Sci. Wuhan Univ. 2006, 31, 740–743. [Google Scholar]
- Riyait, V.S.; Lawlor, M.A.; Adams, A.E.; Hinton, O.R.; Sharif, B.S. A review of the ACID synthetic aperture sonar and other sidescan sonar systems. Int. Hydrogr. Rev. 1995, 72, 285–314. [Google Scholar]
- Mayer, L.; Jakobsson, M.; Allen, G.; Dorschel, B.; Falconer, R.; Ferrini, V.; Lamarche, G.; Snaith, H.; Weatherall, P. The Nippon Foundation—GEBCO seabed 2030 project: The quest to see the world’s oceans completely mapped by 2030. Geosciences 2018, 8, 63. [Google Scholar] [CrossRef]
- Blondel, P. The Handbook of Sidescan Sonar; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Cobra, D.T.; Oppenheim, A.V.; Jaffe, J.S. Geometric distortions in side-scan sonar images: A procedure for their estimation and correction. IEEE J. Ocean. Eng. 1992, 17, 252–268. [Google Scholar] [CrossRef]
- Clarke, J.E.H. Dynamic motion residuals in swath sonar data: Ironing out the creases. Int. Hydrogr. Rev. 2003, 4. [Google Scholar]
- Cervenka, P.; de Moustier, C.; Lonsdale, P.F. Geometric corrections on sidescan sonar images based on bathymetry. Application with SeaMARC II and Sea Beam data. Mar. Geophys. Res. 1995, 17, 217–219. [Google Scholar] [CrossRef]
- Cervenka, P.; de Moustier, C. Postprocessing and corrections of bathymetry derived from sidescan sonar systems: Application with SeaMARC II. IEEE J. Ocean. Eng. 1994, 19, 619–629. [Google Scholar] [CrossRef]
- Zhao, J.; Wag, J. Study on Fusion Method of the Block Image of MBS and SSS. Geomat. Inf. Sci. Wuhan Univ. 2013, 38, 287–290. [Google Scholar]
- Chen, G.; Mao, Z.; Shen, J. Advanced Object Detection in Multibeam Forward-Looking Sonar Images Using Linear Cross-Attention Techniques. In Proceedings of the 2024 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 27–30 October 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1026–1031. [Google Scholar]
- Schimel, A.C.; Beaudoin, J.; Parnum, I.M.; Le Bas, T.; Schmidt, V.; Keith, G.; Ierodiaconou, D. Multibeam sonar backscatter data processing. Mar. Geophys. Res. 2018, 39, 121–137. [Google Scholar] [CrossRef]
- Lucieer, V.; Roche, M.; Degrendele, K.; Malik, M.; Dolan, M.; Lamarche, G. User expectations for multibeam echo sounders backscatter strength data-looking back into the future. Mar. Geophys. Res. 2018, 39, 23–40. [Google Scholar] [CrossRef]
- Le Bas, T.P.; Huvenne, V. Acquisition and processing of backscatter data for habitat mapping-comparison of multibeam and sidescan systems. Appl. Acoust. 2009, 70, 1248–1257. [Google Scholar] [CrossRef]
- Mitchell, G.A.; Orange, D.L.; Gharib, J.J.; Kennedy, P. Improved detection and mapping of deepwater hydrocarbon seeps: Optimizing multibeam echosounder seafloor backscatter acquisition and processing techniques. Mar. Geophys. Res. 2018, 39, 323–347. [Google Scholar] [CrossRef]
- Fakiris, E.; Blondel, P.; Papatheodorou, G.; Christodoulou, D.; Dimas, X.; Georgiou, N.; Kordella, S.; Dimitriadis, C.; Rzhanov, Y.; Geraga, M. Multi-frequency, multi-sonar mapping of shallow habitats—Efficacy and management implications in the national marine park of Zakynthos, Greece. Remote Sens. 2019, 11, 461. [Google Scholar] [CrossRef]
- Zhou, X.; Yu, C.; Yuan, X.; Luo, C. A Matching Algorithm for Underwater Acoustic and Optical Images Based on Image Attribute Transfer and Local Features. Sensors 2021, 21, 7043. [Google Scholar] [CrossRef]
- Aykin, M.D.; Negahdaripour, S. On feature matching and image registration for two-dimensional forward-scan sonar imaging. J. Field Robot. 2013, 30, 602–623. [Google Scholar] [CrossRef]
- ZHANG Ning, J.S.B.G. An iterative and adaptive registration method for multi-beam and side-scan sonar images. Acta Geod. Et. Cartogr. Sin. 2022, 51, 1951–1958. [Google Scholar]
- Shang, X.J.Z. Obtaining High-Resolution Seabed Topography and Surface Details by Co-Registration of Side-Scan Sonar and Multibeam Echo Sounder Images. Remote Sens. 2019, 11, 1496. [Google Scholar] [CrossRef]
- Wynn, W.; Frahm, C.; Carroll, P.; Clark, R.; Wellhoner, J.; Wynn, M. Advanced superconducting gradiometer/magnetometer arrays and a novel signal processing technique. IEEE Trans. Magn. 1975, 11, 701–707. [Google Scholar] [CrossRef]
- Revaud, J.; De Souza, C.; Humenberger, M.; Weinzaepfel, P. R2d2: Reliable and repeatable detector and descriptor. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Sun, J. LoFTR: Detector-Free Local Feature Matching with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- Honghua, J. Research on UAV remote sensing image registration based on BBF optimization algorithm. Comput. Meas. Control 2023, 32, 232–237. [Google Scholar]
- Xiang, H.; Xuefei, L.; Yineng, L.I. Heterogeneous Image Matching Algorithm Based on Feature Fusion. Navig. Control 2023, 22, 106–115. [Google Scholar]
- LAN Chaozhen, L.W.Y.J. Deep learning algorithm for feature matching of cross modality remote sensing images. Acta Geod. Et. Cartogr. Sin. 2021, 50, 189–202. [Google Scholar]
- Shafiq, M.; Gu, Z. Deep residual learning for image recognition: A survey. Appl. Sci. 2022, 12, 8972. [Google Scholar] [CrossRef]
- Song, Z.L. Remote Sensing Image Registration Based on Retrofitted SURF Algorithm and Trajectories Generated From Lissajous Figures. IEEE Geosci. Remote Sens. Lett. 2010, 7, 491–495. [Google Scholar] [CrossRef]
- Yu, C.; Li, S.; Feng, W.; Zheng, T.; Liu, S. SACA-fusion: A low-light fusion architecture of infrared and visible images based on self- and cross-attention. Vis. Comput. 2024, 40, 3347–3356. [Google Scholar] [CrossRef]
- Ben-Artzi, G.; Halperin, T.; Werman, M.; Peleg, S. Epipolar geometry based on line similarity. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1864–1869. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Deshmukh, M.; Bhosle, U. A survey of image registration. Int. J. Image Process. 2011, 5, 245. [Google Scholar]
- Yang, F.; Xu, F.; Zhang, K.; Bu, X.; Hu, H.; Anokye, M. Characterisation of terrain variations of an underwater ancient town in Qiandao Lake. Remote Sens. 2020, 12, 268. [Google Scholar] [CrossRef]
- Wei, M.; Xiwei, P. WLIB-SIFT: A Distinctive Local Image Feature Descriptor. In Proceedings of the 2019 IEEE 2nd International Conference on Information Communication and Signal Processing (ICICSP), Weihai, China, 28–30 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 379–383. [Google Scholar]
- Justinn Barr, R.G.L.W. The Drosophila CPEB Protein Orb Specifies Oocyte Fate by a 39UTR-Dependent Autoregulatory Loop. Genetics 2019, 213, 1431–1446. [Google Scholar] [CrossRef] [PubMed]
- Yabuta, S.Y.Y. Solution for Corresponding Problem of Stereovision By Using AKAZE features. In Proceedings of the 2020 21st International Conference on Research and Education in Mechatronics (REM), Cracow, Poland, 9–11 December 2020. [Google Scholar]
- Liu, Y.; Zhang, H.; Guo, H.; Xiong, N.N. A FAST-BRISK Feature Detector with Depth Information. Sensors 2018, 18, 3908. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Groupings | CMP/Points | MSR/% | RMSE | Image Size | Time/s |
|---|---|---|---|---|---|
| AKAZE | 11 | 36% | 162.72 | 448 × 448 | 0.0589 |
| BRISK | 7 | 21.82% | 149.04 | 448 × 448 | 0.0208 |
| ORB | 33 | 24% | 118.31 | 448 × 448 | 0.0230 |
| SIFT | 14 | 43% | 133.40 | 448 × 448 | 0.0437 |
| Ours | 29 | 93.12% | 1.97 | 448 × 448 | 0.0100 |
| Groupings | CMP/Points | MSR/% | RMSE | Image Size | Time/s |
|---|---|---|---|---|---|
| Group a | 16 | 93.75% | 3.05 | 448 × 448 | 0.0189 |
| Group b | 40 | 97.45% | 1.75 | 448 × 448 | 0.0100 |
| Group c | 29 | 81.82% | 1.67 | 448 × 448 | 0.0108 |
| Group d | 26 | 89.85% | 3.42 | 448 × 448 | 0.0100 |
| Group e | 18 | 80.21% | 5.13 | 448 × 448 | 0.0050 |
| Group f | 46 | 92.62% | 1.97 | 448 × 448 | 0.0015 |
| Group g | 36 | 89.65% | 3.22 | 448 × 448 | 0.0021 |
| Group h | 20 | 86.00% | 2.31 | 448 × 448 | 0.0005 |
| Group i | 25 | 91.85% | 4.32 | 448 × 448 | 0.0021 |
| Group j | 26 | 90.21% | 2.03 | 448 × 448 | 0.0012 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, Y.; Luo, X.; Qin, X.; Wan, H.; Cui, J.; Huang, Z. Deep Learning-Based Feature Matching Algorithm for Multi-Beam and Side-Scan Images. Remote Sens. 2025, 17, 675. https://doi.org/10.3390/rs17040675
Fu Y, Luo X, Qin X, Wan H, Cui J, Huang Z. Deep Learning-Based Feature Matching Algorithm for Multi-Beam and Side-Scan Images. Remote Sensing. 2025; 17(4):675. https://doi.org/10.3390/rs17040675
Chicago/Turabian StyleFu, Yu, Xiaowen Luo, Xiaoming Qin, Hongyang Wan, Jiaxin Cui, and Zepeng Huang. 2025. "Deep Learning-Based Feature Matching Algorithm for Multi-Beam and Side-Scan Images" Remote Sensing 17, no. 4: 675. https://doi.org/10.3390/rs17040675
APA StyleFu, Y., Luo, X., Qin, X., Wan, H., Cui, J., & Huang, Z. (2025). Deep Learning-Based Feature Matching Algorithm for Multi-Beam and Side-Scan Images. Remote Sensing, 17(4), 675. https://doi.org/10.3390/rs17040675