
HiSTENet: History-Integrated Spatial–Temporal Information Extraction Network for Time Series Remote Sensing Image Change Detection


Abstract
:1. Introduction
- We propose HiSTENet, a new framework for TSCD that leveraging both spatio-temporal relationships and historical features for efficient change detection.
- The STREM is designed to extend sequences into the temporal dimension using two scanning strategies, alternating and concatenating, applying Mamba’s sequence modeling mechanism for spatio-temporal context extraction.
- The HIM integrates historical information by enabling efficient feature interaction across spatial and channel dimensions.
- The FAFM is proposed to explicitly estimate pixel-level offsets between bi-temporal images for spatial alignment, alleviating the issue of local misregistration.
- We conduct extensive experiments on the SpaceNet7 and DynamicearNet datasets, demonstrating that HiSTENet outperforms other methods and achieves state-of-the-art performance.
2. Related Works
2.1. Bi-Temporal Remote Sensing Image Change Detection
2.2. Time-Series Remote Sensing Image Change Detection
3. Materials and Methods
3.1. Overview
- 1.
- First, a shared-weight encoder processes each image in the time series to extract multi-scale feature maps, ensuring consistent semantic representation across temporal images.
- 2.
- Next, the extracted features are fed into the HIM, which performs feature interaction operations on the corresponding hierarchical feature maps of both the historical and bi-temporal images.
- 3.
- Then, the FAFM corrects registration errors and extracts change features using pixel-level offsets from the fused feature maps by employing deformable convolutions.
- 4.
- Meanwhile, the STREM applies two scanning strategies to the extracted features to extend sequences into the temporal dimension, capturing the spatio-temporal characteristics. These features are then concatenated and fused layer by layer with the change features.
- 5.
- Finally, two task-specific decoders upsample the fused bi-temporal feature maps. These are then skip-connected with shallow feature maps to generate segmentation outputs. The change outputs are derived from the fused change and spatio-temporal features maps.
3.2. Time Series Remote Sensing Images Encoder
3.3. Historical Integration Module
3.4. Feature Alignment and Fusion Module
3.5. Spatial–Temporal Relationship Extraction Module
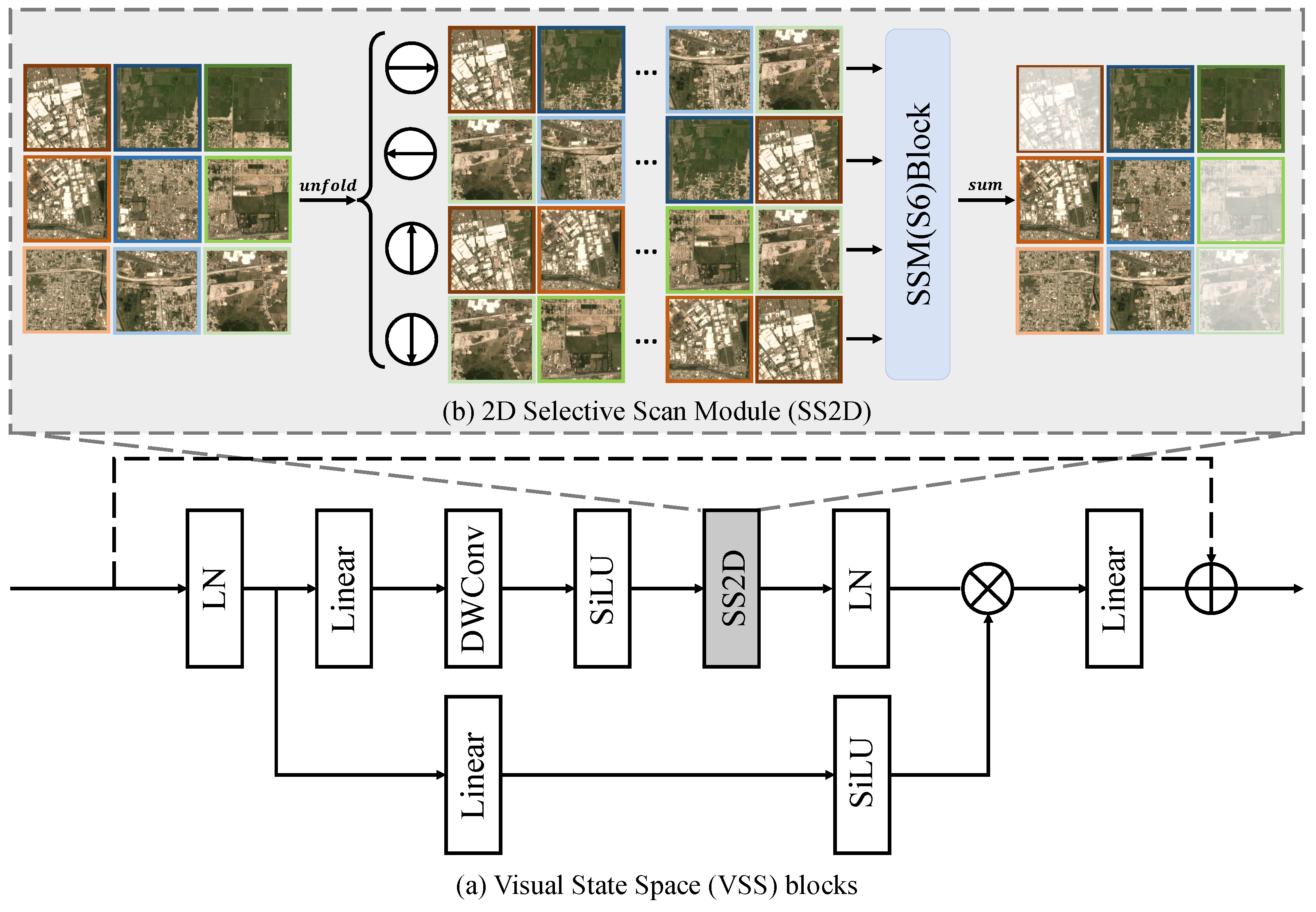
3.5.1. State Space Model
3.5.2. Spatial-Temporal Relationship Extraction Module
3.6. Multi-Task Decoders
3.7. Loss Function
4. Experiments and Results
4.1. Datasets
4.2. Evaluation Metrics
4.3. Experiment Settings
4.4. Performance Comparison
- 1.
- FC-Siam-Diff [19]: a feature-level late fusion method that uses pseudo-Siamese FCN to extract and fuse bi-temporal multi-level features through feature difference operation.
- 2.
- SNUNet [17]: uses a Siamese network as the encoder with shared parameters between the two branches. By incorporating the Ensemble Channel Attention Module (ECAM) in deep supervision, it naturally fuses shallow and deep features with semantic information, effectively reducing the semantic gap in deep supervision.
- 3.
- BIT-CD [18]: a bi-temporal image transformer network that learns a compact set of tokens to reveal changes in interest in bi-temporal images, leveraging transformers to establish relationships between semantic concepts in the token-based space-time.
- 4.
- Changevit [52]: a ViT-based framework that captures large-scale object information, complemented by a detail capture module for fine-grained features.
- 5.
- ChangeFormer [36]: a Siamese network combining a hierarchically structured Transformer encoder with an MLP decoder to capture multi-scale, long-range details necessary for change detection.
- 6.
- SCanNet [53]: a three-branch encoder–decoder network that learns semantic and change labels using concatenated image pairs and features, processed by an internal transformer to produce a binary change mask and semantic segmentation maps.
- 7.
- RSMamba [55]: designed for dense prediction tasks in remote sensing, it uses an omnidirectional selective scanning module to globally model image context and capture features from all directions.
- 8.
- MambaCD-Base/Small/Tiny [54]: uses the Mamba architecture to model global spatial and spatio-temporal relationships in multi-temporal images, with variations in the number of encoder layers and feature channels.
- 9.
- ConvLSTM [56]: convolutional LSTM replaces the fully connected layer in traditional LSTM with a convolutional layer to exploit spatial information, enhancing long-term dependency capture in sequential data.
- 10.
- L-UNet [15]: a UNet-like architecture that integrates ConvLSTM into its structure. In the decoding stage, ConvLSTM captures temporal relationships among TSIs. Its output is then passed to the decoder via a skip connection, enabling the fusion of temporal features at multiple scales.
- 11.
- SitsSCD [60]: uses TSIs to handle semantic change detection, modifying the UTAE’s temporal attention mechanism to generate binary change maps and semantic segmentation maps for each image.
- 12.
- MTL-UNet [57]: a fully convolutional LSTM network that models temporal relationships of spatial features, jointly learning construction extraction and change detection.
- 13.
- Unet3D [59]: extends the UNet architecture with 3D convolution to simultaneously process spatial and temporal information for spatio-temporal feature modeling.
- 14.
- U-TAE [58]: encodes temporal features in latent space through self-attention, leveraging multi-temporal remote sensing images to model temporal information. It uses a U-Net architecture with a Temporal Attention Encoder.
4.5. Ablation Experiments
4.6. Computational Efficiency
5. Discussion
- 1.
- We designed the STREM to model the spatio-temporal features of image sequences, enabling our method to comprehensively reference both temporal and spatial dimensions, thereby better capturing change information.
- 2.
- The HIM effectively and efficiently integrates features from historical images, allowing the model to better understand the attributes of objects under varying imaging conditions, thus enhancing its ability to recognize changes in interest.
- 3.
- By applying the FAFM to learn and correct pixel shifts in the feature space for the image pairs being analyzed, the model mitigates the occurrence of pseudo-changes caused by local mismatches.
- 4.
- The introduction of a semantic consistency loss helps address the issue of imbalance between positive and negative samples in change detection datasets, improving the stability of model training.
- 1.
- Simplistic feature selection for historical images: The feature selection process for historical images is relatively simple, relying only on randomly generated hard labels and focusing solely on unchanged regions during feature exchange. This approach heavily depends on ground-truth labels and fails to fully exploit the potential information and contextual relationships in the data. Such a random feature selection strategy does not make the most of the available information. Therefore, future research could explore the incorporation of temporal attention mechanisms to enable adaptive selection and utilization of important features. This would enhance the model’s understanding of temporal changes, allowing it to more accurately extract critical information from historical images for change detection tasks.
- 2.
- Limited feature exchange for multi-modal data: The current feature exchange process only handles homologous features, which works well for single-mode data but struggles with multi-modal data. Multi-modal datasets often involve information from different sensors or sources, with significant differences in feature distribution, scale, and semantics. To address this, future research could focus on unifying feature representations across modalities by introducing cross-modal feature alignment techniques or modality-adaptive modules, enhancing the model’s ability to handle multi-modal data.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| HiSTENet | History-Integrated Spatial-Temporal Information Extraction Network |
| TSIs | Time series remote sensing images |
| BTCD | Bi-temporal remote sensing image change detection |
| TSCD | Time series remote sensing image change detection |
| STREM | Spatial-Temporal Relationship Extraction Module |
| HIM | Historical Integration Module |
| FAFM | Feature Alignment Fusion Module |
| CNN | Convolutional neural networks |
| CD | Change detection |
| FCN | Fully convolutional networks |
| VIT | Vision Transformer |
| CVA | Change Vector Analysis |
| PCA | Principal Component Analysis |
| FC-Siam-conc | Fully Convolutional Siamese-concatenation |
| FC-Siam-diff | Fully Convolutional Siamese-difference |
| LSTM | Long Short-Term Memory |
| SSM | State Space Model |
| TN | True negative |
| TP | True positive |
| FN | False negative |
| FP | False positive |
| OA | Overall accuracy |
| Adam | Adaptive moment estimation |
References
- Singh, A. Review article digital change detection techniques using remotely-sensed data. Int. J. Remote Sens. 1989, 10, 989–1003. [Google Scholar] [CrossRef]
- Wan, L.; Tian, Y.; Kang, W.; Ma, L. D-TNet: Category-awareness based difference-threshold alternative learning network for remote sensing image change detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5633316. [Google Scholar] [CrossRef]
- Liu, C.; Zhao, R.; Chen, J.; Qi, Z.; Zou, Z.; Shi, Z. A Decoupling Paradigm with Prompt Learning for Remote Sensing Image Change Captioning. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5622018. [Google Scholar] [CrossRef]
- Wan, L.; Tian, Y.; Kang, W.; Ma, L. CLDRNet: A Difference Refinement Network based on Category Context Learning for Remote Sensing Image Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2023, 17, 2133–2148. [Google Scholar] [CrossRef]
- Giustarini, L.; Hostache, R.; Matgen, P.; Schumann, G.J.P.; Bates, P.D.; Mason, D.C. A Change Detection Approach to Flood Mapping in Urban Areas Using TerraSAR-X. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2417–2430. [Google Scholar] [CrossRef]
- Bovolo, F.; Bruzzone, L. A Split-Based Approach to Unsupervised Change Detection in Large-Size Multitemporal Images: Application to Tsunami-Damage Assessment. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1658–1670. [Google Scholar] [CrossRef]
- Gupta, R.; Goodman, B.; Patel, N.N.; Hosfelt, R.; Sajeev, S.; Heim, E.T.; Doshi, J.; Lucas, K.; Choset, H.; Gaston, M.E. xBD: A Dataset for Assessing Building Damage from Satellite Imagery. arXiv 2019, arXiv:1911.09296. [Google Scholar]
- Willis, K.S. Remote sensing change detection for ecological monitoring in United States protected areas. Biol. Conserv. 2015, 182, 233–242. [Google Scholar] [CrossRef]
- Ji, R.; Tan, K.; Wang, X.; Pan, C.; Xin, L. Spatiotemporal Monitoring of a Grassland Ecosystem and Its Net Primary Production Using Google Earth Engine: A Case Study of Inner Mongolia from 2000 to 2020. Remote Sens. 2021, 13, 4480. [Google Scholar] [CrossRef]
- Zhu, Z.; Qiu, S.; Ye, S. Remote sensing of land change: A multifaceted perspective. Remote Sens. Environ. 2022, 282, 113266. [Google Scholar] [CrossRef]
- Li, J.; Wu, C. Using difference features effectively: A multi-task network for exploring change areas and change moments in time series remote sensing images. ISPRS J. Photogramm. Remote Sens. 2024, 218, 487–505. [Google Scholar] [CrossRef]
- Verbesselt, J.; Hyndman, R.; Zeileis, A.; Culvenor, D. Phenological change detection while accounting for abrupt and gradual trends in satellite image time series. Remote Sens. Environ. 2010, 114, 2970–2980. [Google Scholar] [CrossRef]
- Kennedy, R.E.; Yang, Z.; Cohen, W.B. Detecting trends in forest disturbance and recovery using yearly Landsat time series: 1. LandTrendr—Temporal segmentation algorithms. Remote Sens. Environ. 2010, 114, 2897–2910. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Continuous change detection and classification of land cover using all available Landsat data. Remote Sens. Environ. 2014, 144, 152–171. [Google Scholar] [CrossRef]
- Sun, S.; Mu, L.; Wang, L.; Liu, P. L-UNet: An LSTM Network for Remote Sensing Image Change Detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8004505. [Google Scholar] [CrossRef]
- Li, J.; Hu, M.; Wu, C. Multiscale change detection network based on channel attention and fully convolutional BiLSTM for medium-resolution remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2023, 16, 9735–9748. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A Densely Connected Siamese Network for Change Detection of VHR Images. IEEE Geosci. Remote. Sens. Lett. 2021, 19, 8007805. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote sensing image change detection with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5607514. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully convolutional siamese networks for change detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Xiao, W.; Cao, H.; Lei, Y.; Zhu, Q.; Chen, N. Cross-temporal and spatial information fusion for multi-task building change detection using multi-temporal optical imagery. Int. J. Appl. Earth Obs. Geoinf. 2024, 132, 104075. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, J.; Bruzzone, L. MixCDNet: A Lightweight Change Detection Network Mixing Features across CNN and Transformer. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 4411915. [Google Scholar] [CrossRef]
- He, L.; Zhang, M.; Li, Y.; Zhang, J.; Luo, S.; Li, S.; Zhang, X. Change-Guided Similarity Pyramid Network for Semantic Change Detection. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 5637917. [Google Scholar] [CrossRef]
- Ren, W.; Wang, Z.; Xia, M.; Lin, H. MFINet: Multi-scale feature interaction network for change detection of high-resolution remote sensing images. Remote Sens. 2024, 16, 1269. [Google Scholar] [CrossRef]
- Gu, A. Modeling Sequences with Structured State Spaces. Ph.D Thesis, Stanford University, Stanford, CA, USA, 2023. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar]
- Chen, J.; Chen, X.; Cui, X.; Chen, J. Change Vector Analysis in Posterior Probability Space: A New Method for Land Cover Change Detection. IEEE Geosci. Remote Sens. Lett. 2011, 8, 317–321. [Google Scholar] [CrossRef]
- Mu, C.; Huo, L.; Liu, Y.; Liu, R.; Jiao, L. Change detection for remote sensing images based on wavelet fusion and PCA-kernel fuzzy clustering. Acta Electron. Sin 2015, 43, 1375–1381. [Google Scholar]
- Daudt, R.C.; Saux, B.L.; Boulch, A.; Gousseau, Y. Urban Change Detection for Multispectral Earth Observation Using Convolutional Neural Networks. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Basavaraju, K.S.; Sravya, N.; Lal, S.; Nalini, J.; Reddy, C.S.; Dell’Acqua, F. UCDNet: A Deep Learning Model for Urban Change Detection From Bi-Temporal Multispectral Sentinel-2 Satellite Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5408110. [Google Scholar] [CrossRef]
- Pang, S.; Zhang, A.; Hao, J.; Liu, F.; Chen, J. SCA-CDNet: A robust siamese correlation-and-attention-based change detection network for bitemporal VHR images. Int. J. Remote. Sens. 2021, 43, 6102–6123. [Google Scholar] [CrossRef]
- Jian, P.; Chen, K.; Cheng, W. Gan-based one-class classification for remote-sensing image change detection. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8009505. [Google Scholar] [CrossRef]
- Alexey, D. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Shi, N.; Chen, K.; Zhou, G. A divided spatial and temporal context network for remote sensing change detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4897–4908. [Google Scholar] [CrossRef]
- Bandara, W.G.C.; Patel, V.M. A transformer-based siamese network for change detection. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 207–210. [Google Scholar]
- Feng, J.; Yang, X.; Gu, Z. SGNet: A Transformer-Based Semantic-Guided Network for Building Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2024, 17, 9922–9935. [Google Scholar] [CrossRef]
- Zhang, Z.; Fan, X.; Wang, X.; Qin, Y.; Xia, J. A Novel Remote Sensing Image Change Detection Approach Based on Multi-level State Space Model. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 4417014. [Google Scholar] [CrossRef]
- Wang, H.; Ye, Z.; Xu, C.; Mei, L.; Lei, C.; Wang, D. TTMGNet: Tree Topology Mamba-Guided Network Collaborative Hierarchical Incremental Aggregation for Change Detection. Remote Sens. 2024, 16, 4068. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Saha, S.; Bovolo, F.; Bruzzone, L. Change detection in image time-series using unsupervised LSTM. IEEE Geosci. Remote Sens. Lett. 2020, 19, 8005205. [Google Scholar] [CrossRef]
- Kalinicheva, E.; Ienco, D.; Sublime, J.; Trocan, M. Unsupervised change detection analysis in satellite image time series using deep learning combined with graph-based approaches. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1450–1466. [Google Scholar] [CrossRef]
- Yang, B.; Qin, L.; Liu, J.; Liu, X. UTRNet: An unsupervised time-distance-guided convolutional recurrent network for change detection in irregularly collected images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4410516. [Google Scholar] [CrossRef]
- Yang, B.; Qin, L.; Liu, J.; Liu, X. IRCNN: An irregular-time-distanced recurrent convolutional neural network for change detection in satellite time series. IEEE Geosci. Remote Sens. Lett. 2022, 19, 2503905. [Google Scholar] [CrossRef]
- Meshkini, K.; Bovolo, F.; Bruzzone, L. An unsupervised change detection approach for dense satellite image time series using 3d cnn. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 12–16 July 2021; pp. 4336–4339. [Google Scholar]
- Meshkini, K.; Bovolo, F.; Bruzzone, L. Multi-Annual Change Detection Using a Weakly Supervised 3D CNN in HR SITS. IEEE Geosci. Remote. Sens. Lett. 2024, 21, 5001405. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Li, Z. Changer: Feature Interaction is What You Need for Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5610111. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 27–29 October 2017; pp. 764–773. [Google Scholar]
- Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; Liu, Y. VMamba: Visual State Space Model. arXiv 2024, arXiv:2401.10166. [Google Scholar]
- Van Etten, A.; Hogan, D.; Manso, J.M.; Shermeyer, J.; Weir, N.; Lewis, R. The multi-temporal urban development spacenet dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6398–6407. [Google Scholar]
- Toker, A.; Kondmann, L.; Weber, M.; Eisenberger, M.; Camero, A.; Hu, J.; Hoderlein, A.P.; Şenaras, Ç.; Davis, T.; Cremers, D.; et al. Dynamicearthnet: Daily multi-spectral satellite dataset for semantic change segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 21158–21167. [Google Scholar]
- Zhu, D.; Huang, X.; Huang, H.; Shao, Z.; Cheng, Q. ChangeViT: Unleashing Plain Vision Transformers for Change Detection. arXiv 2024, arXiv:2406.12847. [Google Scholar]
- Ding, L.; Zhang, J.; Guo, H.; Zhang, K.; Liu, B.; Bruzzone, L. Joint spatio-temporal modeling for semantic change detection in remote sensing images. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 5610814. [Google Scholar] [CrossRef]
- Chen, H.; Song, J.; Han, C.; Xia, J.; Yokoya, N. Changemamba: Remote sensing change detection with spatio-temporal state space model. arXiv 2024, arXiv:2404.03425. [Google Scholar]
- Zhao, S.; Chen, H.; Zhang, X.; Xiao, P.; Bai, L.; Ouyang, W. Rs-mamba for large remote sensing image dense prediction. arXiv 2024, arXiv:2404.02668. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.c. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28, 802–810. [Google Scholar]
- Papadomanolaki, M.; Vakalopoulou, M.; Karantzalos, K. A deep multitask learning framework coupling semantic segmentation and fully convolutional LSTM networks for urban change detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7651–7668. [Google Scholar] [CrossRef]
- Garnot, V.S.F.; Landrieu, L. Panoptic segmentation of satellite image time series with convolutional temporal attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4872–4881. [Google Scholar]
- M Rustowicz, R.; Cheong, R.; Wang, L.; Ermon, S.; Burke, M.; Lobell, D. Semantic segmentation of crop type in Africa: A novel dataset and analysis of deep learning methods. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 75–82. [Google Scholar]
- Vincent, E.; Ponce, J.; Aubry, M. Satellite Image Time Series Semantic Change Detection: Novel Architecture and Analysis of Domain Shift. arXiv 2024, arXiv:2407.07616. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Method | SpaceNet7 | DynamicEarthNet | ||
|---|---|---|---|---|---|
| PR/RC/F1/KP | PR/RC/F1/KP | ||||
| B | FC-Siam-Diff [19] | 19.89/22.52/21.12/21.06 | 8.01/40.03/13.35/11.78 | ||
| SNUNet [17] | 23.52/29.19/26.05/26.01 | 15.58/34.95/21.55/18.88 | |||
| BIT-CD [18] | 17.04/23.00/19.58/19.53 | 58.39/11.12/18.68/10.67 | |||
| ChangeVit [52] | 25.35/31.45/28.07/28.02 | 15.93/35.32/21.96/19.28 | |||
| ChangeFormer [36] | 13.82/39.27/20.45/20.41 | 9.97/34.44/15.47/13.39 | |||
| SCanNet [53] | 20.85/24.50/22.53/20.16 | 28.87/25.58/27.13/22.75 | |||
| RSMamba [55] | 23.26/25.73/24.43/24.38 | 16.78/30.65/21.68/18.61 | |||
| MambaCD-Base [54] | 22.39/34.13/27.04/27.00 | 16.76/32.64/22.15/19.22 | |||
| MambaCD-Small [54] | 23.46/35.01/28.09/28.05 | 20.04/41.96/27.12/24.52 | |||
| MambaCD-Tiny [54] | 26.06/30.00/27.89/27.85 | 12.33/42.74/19.14/17.16 | |||
| M | ConvLSTM [56] | 12.17/26.30/16.64/16.60 | 7.14/38.01/12.02/10.51 | ||
| L-UNet [15] | 13.43/28.51/18.26/18.22 | 20.97/17.62/19.15/19.09 | |||
| SitsSCD [60] | 19.29/10.95/13.97/13.89 | 18.37/14.57/16.25/10.95 | |||
| MTL-UNet [57] | 20.97/17.62/19.15/19.09 | 10.52/36.89/16.37/14.34 | |||
| UNet3D [59] | 24.31/26.24/25.24/25.19 | 22.41/28.40/25.05/21.35 | |||
| UTAE [58] | 24.67/29.31/26.79/26.74 | 24.10/28.66/26.18/22.39 | |||
| Ours | 28.88/39.01/33.19/33.14 | 28.20/33.89/30.78/27.25 |
| Baseline | STREM | HIM | FAFM | Loss | SpaceNet7 | DynamicEarthNet | |||
|---|---|---|---|---|---|---|---|---|---|
| PR/RC/F1 | PR/RC/F1 | ||||||||
| ✔ | 27.88/30.13/28.96 | 24.98/28.04/26.42 | |||||||
| ✔ | ✔ | 27.67/35.31/31.02 | 28.73/31.50/30.05 | ||||||
| ✔ | ✔ | 29.78/30.97/30.36 | 31.50/24.37/27.48 | ||||||
| ✔ | ✔ | 24.98/35.57/29.35 | 25.01/29.30/26.98 | ||||||
| ✔ | ✔ | 26.10/34.10/29.57 | 27.67/26.50/27.07 | ||||||
| ✔ | ✔ | ✔ | 28.33/35.12/31.36 | 29.52/27.78/28.63 | |||||
| ✔ | ✔ | ✔ | ✔ | 26.08/40.62/31.77 | 30.18/28.96/29.56 | ||||
| ✔ | ✔ | ✔ | ✔ | ✔ | 28.88/39.01/33.19 | 28.02/33.89/30.78 |
| Model | AS | CS | SpaceNet7 | DynamicEarthNet | |||
|---|---|---|---|---|---|---|---|
| PR/RC/F1 | PR/RC/F1 | ||||||
| HiSTENet | 26.06/32.69/29.00 | 31.05/28.05/29.48 | |||||
| HiSTENet | ✔ | 29.02/31.60/30.25 | 27.79/32.70/30.05 | ||||
| HiSTENet | ✔ | 30.96/29.73/30.33 | 32.71/28.02/30.18 | ||||
| HiSTENet | ✔ | ✔ | 28.88/39.01/33.19 | 28.02/33.89/30.78 |
| Model | All | Unique | SpaceNet7 | DynamicEarthNet | |||
|---|---|---|---|---|---|---|---|
| PR/RC/F1 | PR/RC/F1 | ||||||
| HiSTENet | 26.17/33.31/29.31 | 31.05/28.05/29.47 | |||||
| HiSTENet | ✔ | 27.95/32.63/30.11 | 31.62/27.92/29.66 | ||||
| HiSTENet | ✔ | 28.88/39.01/33.19 | 28.02/33.89/30.78 |
| Type | Method | FLOPs (G) | Params. (M) | Time (s) | F1 (%) |
|---|---|---|---|---|---|
| B | FC-Siam-Diff [19] | 4.73 | 1.35 | 0.067497 | 21.12/13.35 |
| SNUNet [17] | 54.83 | 12.03 | 0.030320 | 26.05/21.55 | |
| BIT-CD [18] | 10.61 | 3.50 | 0.057397 | 19.58/18.68 | |
| ChangeVit [52] | 38.81 | 32.14 | 0.082682 | 28.07/21.96 | |
| ChangeFormer [36] | 202.79 | 41.03 | 0.102586 | 20.45/15.47 | |
| SCanNet [53] | 66.23 | 27.90 | 0.056208 | 22.53/27.13 | |
| RSMamba [55] | 18.33 | 42.30 | 0.136785 | 24.43/21.68 | |
| MambaCD-Base [54] | 44.83 | 85.53 | 0.419819 | 27.04/22.15 | |
| MambaCD-Small [54] | 28.7 | 49.94 | 0.183827 | 28.09/27.12 | |
| MambaCD-Tiny [54] | 17.54 | 27.54 | 0.130364 | 27.89/19.14 | |
| M | ConvLSTM [56] | 60.71 | 0.31 | 0.008655 | 16.64/12.02 |
| L-Unet [15] | 30.57 | 8.45 | 0.195141 | 18.26/19.15 | |
| SitsSCD [60] | 854.68 | 16.16 | 0.088565 | 13.97/16.25 | |
| MTL-UNet [57] | 48.89 | 9.43 | 0.215808 | 19.15/16.37 | |
| UNet3D [59] | 26.99 | 0.34 | 0.023896 | 25.24/25.05 | |
| UTAE [58] | 40.9 | 1.08 | 0.281565 | 26.79/26.18 | |
| Ours | 156.57 | 17.62 | 0.184011 | 33.19/30.78 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, L.; Wan, L.; Ma, L.; Zhang, Y. HiSTENet: History-Integrated Spatial–Temporal Information Extraction Network for Time Series Remote Sensing Image Change Detection. Remote Sens. 2025, 17, 792. https://doi.org/10.3390/rs17050792
Zhao L, Wan L, Ma L, Zhang Y. HiSTENet: History-Integrated Spatial–Temporal Information Extraction Network for Time Series Remote Sensing Image Change Detection. Remote Sensing. 2025; 17(5):792. https://doi.org/10.3390/rs17050792
Chicago/Turabian StyleZhao, Lu, Ling Wan, Lei Ma, and Yiming Zhang. 2025. "HiSTENet: History-Integrated Spatial–Temporal Information Extraction Network for Time Series Remote Sensing Image Change Detection" Remote Sensing 17, no. 5: 792. https://doi.org/10.3390/rs17050792
APA StyleZhao, L., Wan, L., Ma, L., & Zhang, Y. (2025). HiSTENet: History-Integrated Spatial–Temporal Information Extraction Network for Time Series Remote Sensing Image Change Detection. Remote Sensing, 17(5), 792. https://doi.org/10.3390/rs17050792