
ATIS-Driven 3DCNet: A Novel Three-Stream Hyperspectral Fusion Framework with Knowledge from Downstream Classification Performance


Abstract
1. Introduction
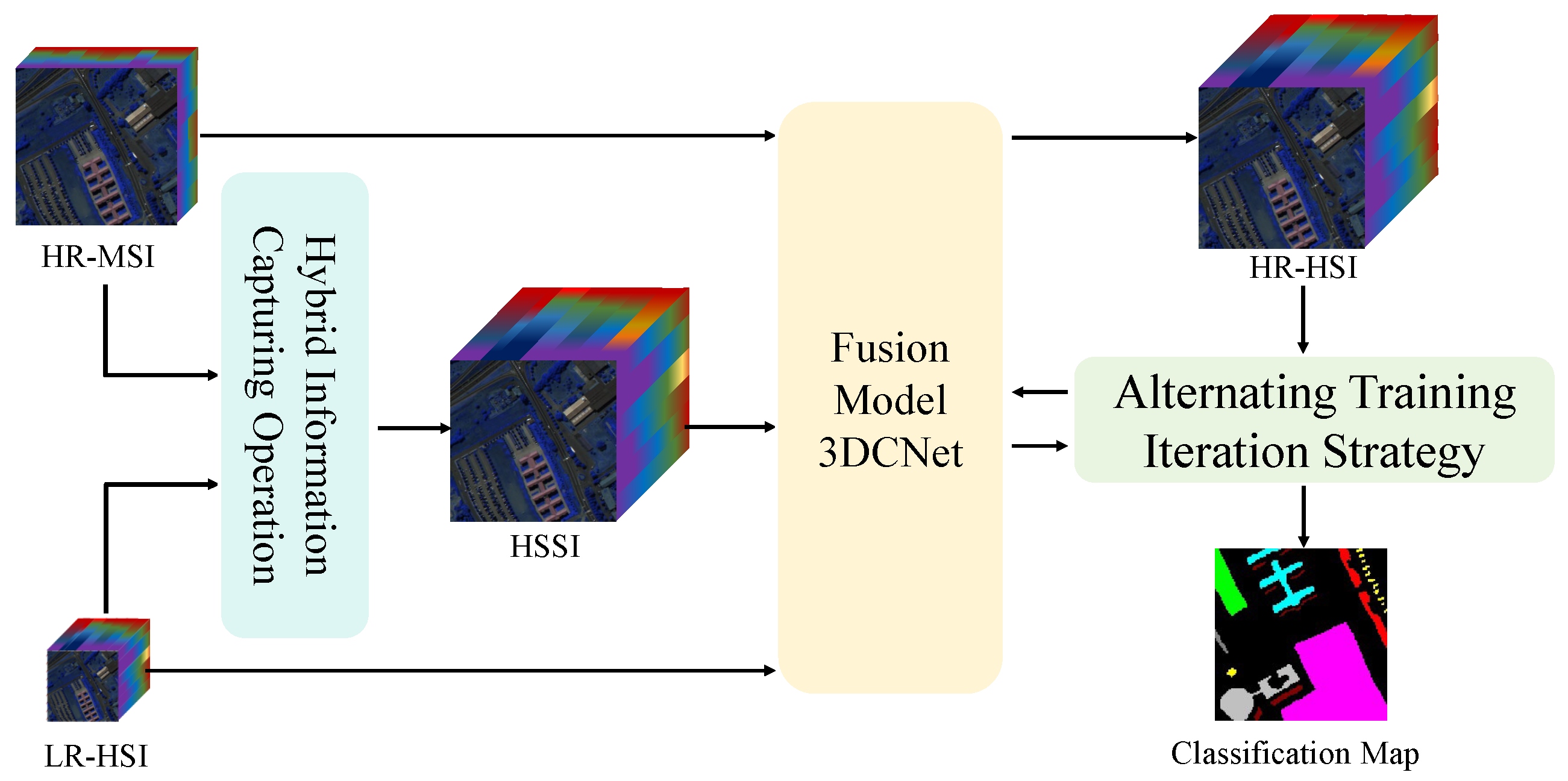
- A novel, efficient three-stream fusion network, 3DCNet, is proposed for high-precision LR-HSI and HR-MSI fusion. Three stream means that three branches distill the features in the LR-HSI, HR-MSI, and hybrid spatial–spectral image (HSSI), respectively.
- For spatial and spectral feature extraction, low-cost linear transformation operations are utilized in spatial blocks (SpatBs) to effectively extract spatial information, while the channel attention mechanism in spectral blocks (SpecBs) is leveraged to capture global spectral information.
- In order to direct our 3DCNet to acquire precise feature representations, the loss function is segmented into three distinct parts: , , and . Beyond the global control of HR-HSI generation by , the Canny operator is employed to constrain the neural network, focusing it on the reconstruction of spatial texture details, while is utilized to control the fidelity of the generated HR-HSI by minimizing the variation in the spectral dimension.
- For downstream classification application, the alternating training iteration strategy (ATIS) is designed to iteratively train our fusion network alongside the classification network DBDA [18], with the aim of leveraging knowledge from each other, generating an HR-HSI that not only excels in visual and statistical performance but also minimizes the error in accuracy for the downstream high-level classification task.
2. Related Work
2.1. Traditional Fusion Methods
2.2. Deep Learning-Based Fusion Methods
2.3. Fusion Methods for Downstream Applications
3. Methodology
3.1. Hybrid Spatial–Spectral Image
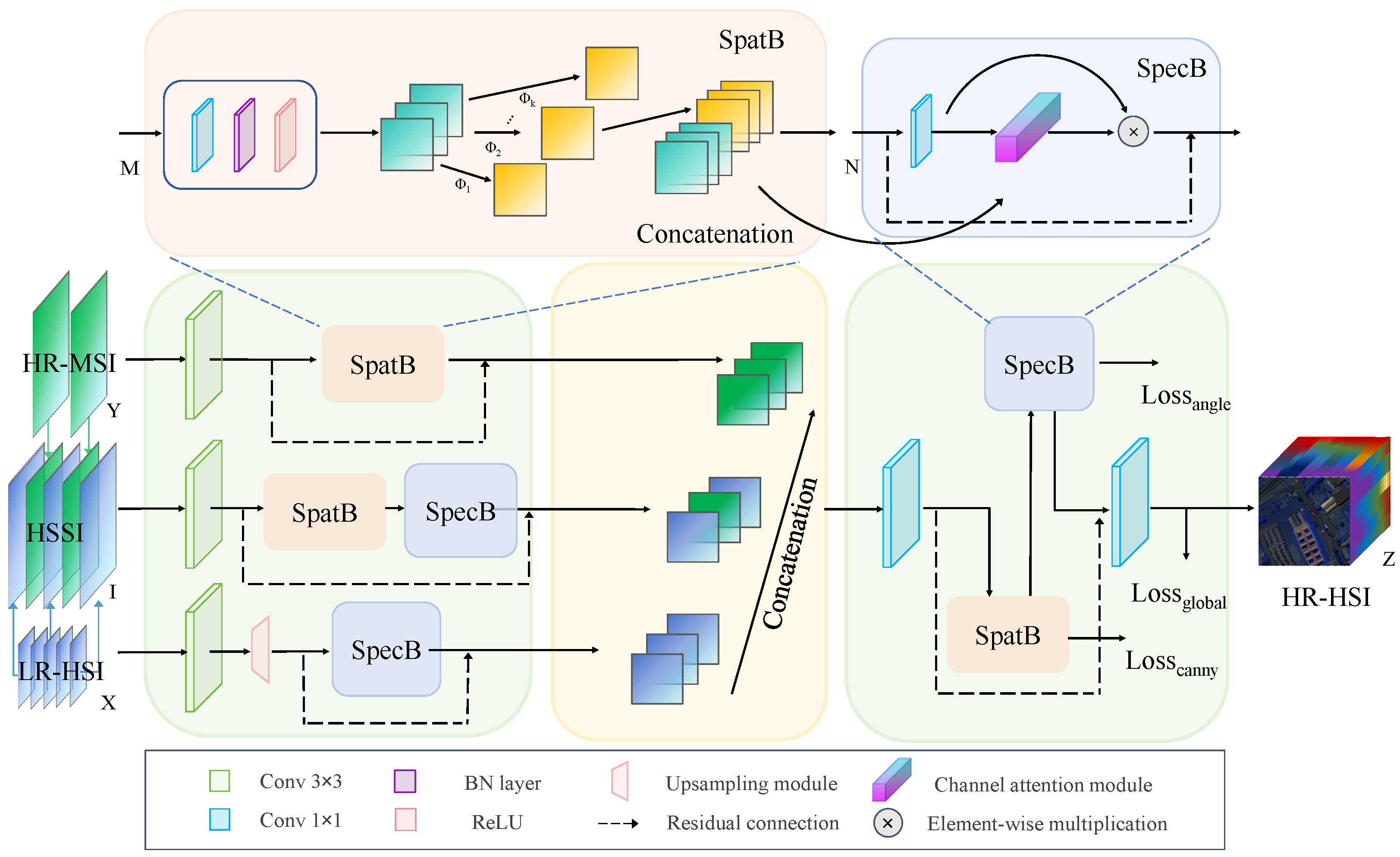
3.2. Three-Stream HSI and MSI Fusion Network
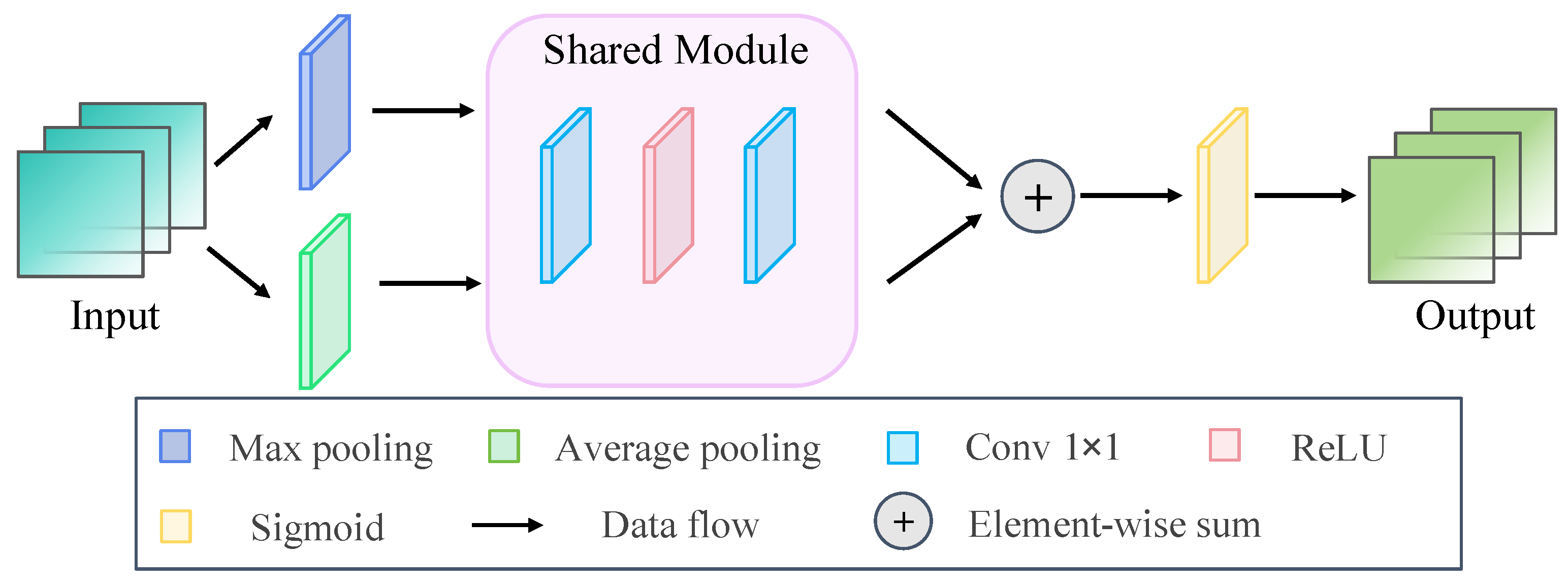
3.3. SpatB and SpecB
3.4. Loss Function
3.5. Alternating Training Iteration Strategy
| Algorithm 1 Alternating Training Iteration Strategy |
| 1: Input: LR-HSI and HR-MSI 2: Output: Fused HR-HSI 3: Initial: Loop variable 4: while do 5: for p iterations do 6: Randomly select the LR-HSI region and the corresponding HR-MSI region ; 7: Calculate the fusion loss: ; 8: Update parameters of the fusion network by Adam optimizer: ; 9: end for 10: Generate fused HR-HSI from and using the training set; 11: Select labeled data from the fused HR-HSI as training data ; 12: for q epochs do 13: Select batched training samples ; 14: Calculate the classification loss: ; 15: Update parameters of the classification network by another Adam optimizer: ; 16: end for 17: ; 18: end while |
4. Experiments
4.1. Dataset
4.2. Evaluation Metrics
4.3. Implementation Details
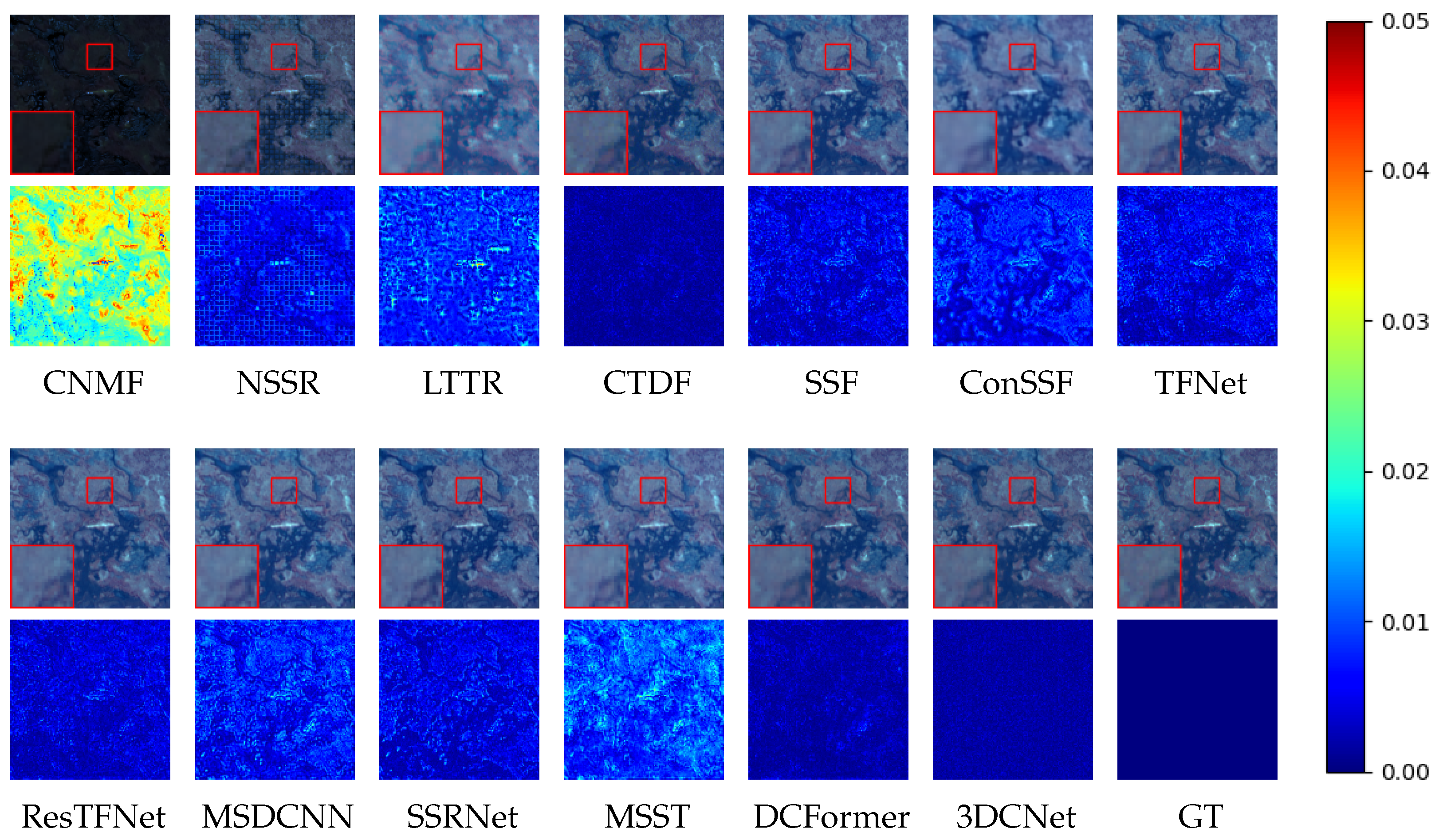
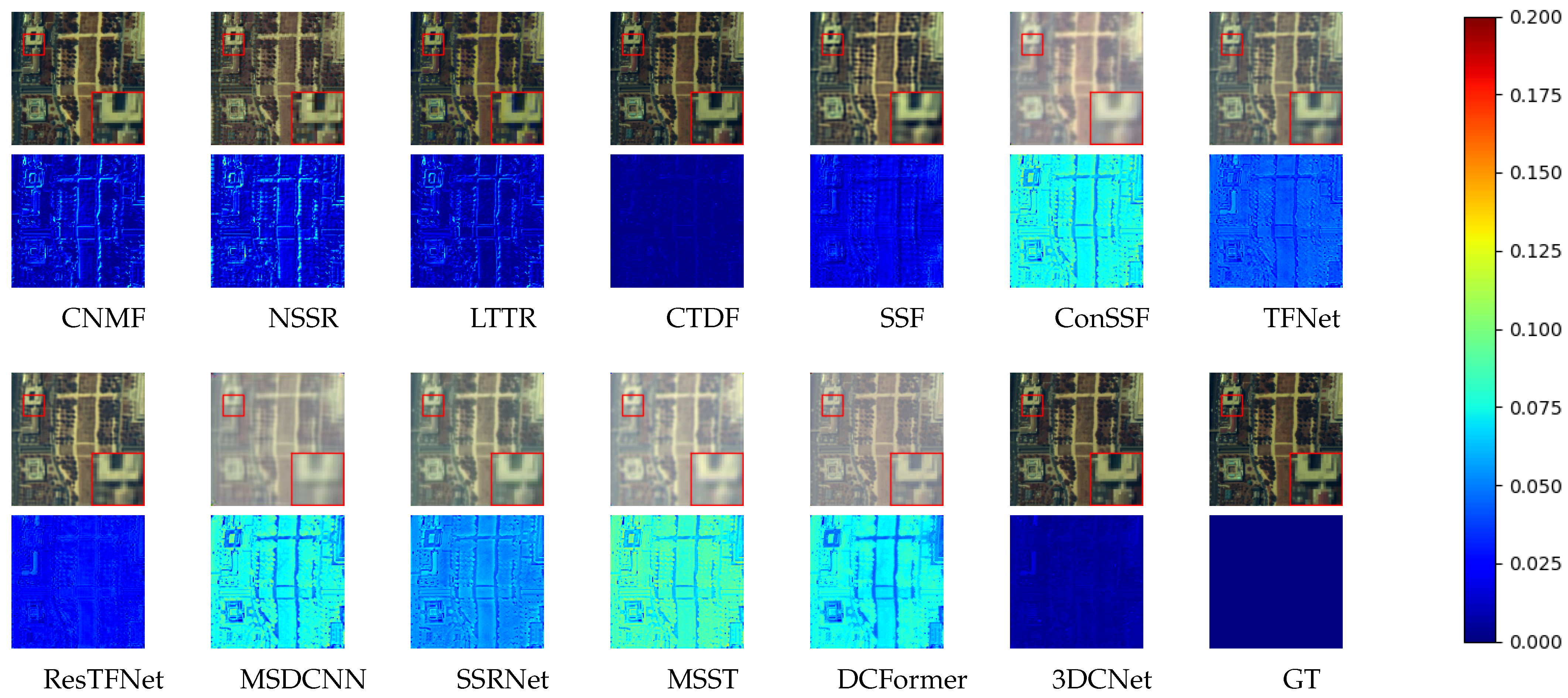
4.4. Fusion Performance Comparison
4.5. Downstream Classification Performance Comparison
4.6. Ablation Experiments
4.7. Efficiency Experiments
4.8. Hyperparameter Sensitivity Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhou, S.; Sun, L.; Xing, W.; Feng, G.; Ji, Y.; Yang, J.; Liu, S. Hyperspectral imaging of beet seed germination prediction. Infrared Phys. Technol. 2020, 108, 103363. [Google Scholar] [CrossRef]
- Ghanbari, H.; Antoniades, D. Convolutional neural networks for mapping of lake sediment core particle size using hyperspectral imaging. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102906. [Google Scholar] [CrossRef]
- Akbari, H.; Kosugi, Y.; Kojima, K.; Tanaka, N. Detection and analysis of the intestinal ischemia using visible and invisible hyperspectral imaging. IEEE Trans. Biomed. Eng. 2010, 57, 2011–2017. [Google Scholar] [CrossRef] [PubMed]
- Kawakami, R.; Matsushita, Y.; Wright, J.; Ben-Ezra, M.; Tai, Y.W.; Ikeuchi, K. High-resolution hyperspectral imaging via matrix factorization. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; IEEE: New York, NY, USA, 2011; pp. 2329–2336. [Google Scholar]
- Akhtar, N.; Shafait, F.; Mian, A. Sparse spatio-spectral representation for hyperspectral image super-resolution. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part VII 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 63–78. [Google Scholar]
- Simoes, M.; Bioucas-Dias, J.; Almeida, L.B.; Chanussot, J. A convex formulation for hyperspectral image superresolution via subspace-based regularization. IEEE Trans. Geosci. Remote. Sens. 2014, 53, 3373–3388. [Google Scholar] [CrossRef]
- Dong, W.; Fu, F.; Shi, G.; Cao, X.; Wu, J.; Li, G.; Li, X. Hyperspectral image super-resolution via non-negative structured sparse representation. IEEE Trans. Image Process. 2016, 25, 2337–2352. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Dian, R.; Fang, L.; Bioucas-Dias, J.M. Fusing hyperspectral and multispectral images via coupled sparse tensor factorization. IEEE Trans. Image Process. 2018, 27, 4118–4130. [Google Scholar] [CrossRef]
- Kanatsoulis, C.I.; Fu, X.; Sidiropoulos, N.D.; Ma, W.K. Hyperspectral super-resolution: A coupled tensor factorization approach. IEEE Trans. Signal Process. 2018, 66, 6503–6517. [Google Scholar] [CrossRef]
- Dian, R.; Li, S. Hyperspectral image super-resolution via subspace-based low tensor multi-rank regularization. IEEE Trans. Image Process. 2019, 28, 5135–5146. [Google Scholar] [CrossRef] [PubMed]
- Hardie, R.C.; Eismann, M.T.; Wilson, G.L. MAP estimation for hyperspectral image resolution enhancement using an auxiliary sensor. IEEE Trans. Image Process. 2004, 13, 1174–1184. [Google Scholar] [CrossRef]
- Zhang, Y.; De Backer, S.; Scheunders, P. Noise-resistant wavelet-based Bayesian fusion of multispectral and hyperspectral images. IEEE Trans. Geosci. Remote. Sens. 2009, 47, 3834–3843. [Google Scholar] [CrossRef]
- Akhtar, N.; Shafait, F.; Mian, A. Bayesian sparse representation for hyperspectral image super resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3631–3640. [Google Scholar]
- Zhang, X.; Huang, W.; Wang, Q.; Li, X. SSR-NET: Spatial–spectral reconstruction network for hyperspectral and multispectral image fusion. IEEE Trans. Geosci. Remote. Sens. 2020, 59, 5953–5965. [Google Scholar] [CrossRef]
- Yang, J.; Zhao, Y.Q.; Chan, J.C.W. Hyperspectral and multispectral image fusion via deep two-branches convolutional neural network. Remote. Sens. 2018, 10, 800. [Google Scholar] [CrossRef]
- Jia, S.; Min, Z.; Fu, X. Multiscale spatial–spectral transformer network for hyperspectral and multispectral image fusion. Inf. Fusion 2023, 96, 117–129. [Google Scholar] [CrossRef]
- He, C.; Xu, Y.; Wu, Z.; Wei, Z. Connecting Low-Level and High-Level Visions: A Joint Optimization for Hyperspectral Image Super-Resolution and Target Detection. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 5514116. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Duan, C.; Yang, Y.; Wang, X. Classification of hyperspectral image based on double-branch dual-attention mechanism network. Remote. Sens. 2020, 12, 582. [Google Scholar] [CrossRef]
- Lawrence, S.; Giles, C.L.; Tsoi, A.C.; Back, A.D. Face recognition: A convolutional neural-network approach. IEEE Trans. Neural Netw. 1997, 8, 98–113. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. Acm 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Tang, X.; Li, C.; Peng, Y. Unsupervised joint adversarial domain adaptation for cross-scene hyperspectral image classification. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Li, C.; Tang, X.; Shi, L.; Peng, Y.; Zhou, T. An efficient joint framework assisted by embedded feature smoother and sparse skip connection for hyperspectral image classification. Infrared Phys. Technol. 2023, 135, 104985. [Google Scholar] [CrossRef]
- Bhatti, U.A.; Huang, M.; Neira-Molina, H.; Marjan, S.; Baryalai, M.; Tang, H.; Wu, G.; Bazai, S.U. MFFCG–Multi feature fusion for hyperspectral image classification using graph attention network. Expert Syst. Appl. 2023, 229, 120496. [Google Scholar] [CrossRef]
- Li, C.; Rasti, B.; Tang, X.; Duan, P.; Li, J.; Peng, Y. Channel-Layer-Oriented Lightweight Spectral-Spatial Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 5504214. [Google Scholar] [CrossRef]
- Zhu, C.; Dai, R.; Gong, L.; Gao, L.; Ta, N.; Wu, Q. An adaptive multi-perceptual implicit sampling for hyperspectral and multispectral remote sensing image fusion. Int. J. Appl. Earth Obs. Geoinf. 2023, 125, 103560. [Google Scholar] [CrossRef]
- Masi, G.; Cozzolino, D.; Verdoliva, L.; Scarpa, G. Pansharpening by convolutional neural networks. Remote. Sens. 2016, 8, 594. [Google Scholar] [CrossRef]
- Xu, S.; Amira, O.; Liu, J.; Zhang, C.X.; Zhang, J.; Li, G. HAM-MFN: Hyperspectral and multispectral image multiscale fusion network with RAP loss. IEEE Trans. Geosci. Remote. Sens. 2020, 58, 4618–4628. [Google Scholar] [CrossRef]
- Palsson, F.; Sveinsson, J.R.; Ulfarsson, M.O. Multispectral and hyperspectral image fusion using a 3-D-convolutional neural network. IEEE Geosci. Remote. Sens. Lett. 2017, 14, 639–643. [Google Scholar] [CrossRef]
- Yao, J.; Hong, D.; Chanussot, J.; Meng, D.; Zhu, X.; Xu, Z. Cross-attention in coupled unmixing nets for unsupervised hyperspectral super-resolution. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXIX 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 208–224. [Google Scholar]
- Zhu, C.; Deng, S.; Zhou, Y.; Deng, L.J.; Wu, Q. QIS-GAN: A lightweight adversarial network with quadtree implicit sampling for multispectral and hyperspectral image fusion. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 1–15. [Google Scholar] [CrossRef]
- Tang, L.; Yuan, J.; Ma, J. Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network. Inf. Fusion 2022, 82, 28–42. [Google Scholar] [CrossRef]
- Tang, L.; Zhang, H.; Xu, H.; Ma, J. Rethinking the necessity of image fusion in high-level vision tasks: A practical infrared and visible image fusion network based on progressive semantic injection and scene fidelity. Inf. Fusion 2023, 99, 101870. [Google Scholar] [CrossRef]
- Sun, H.; Zheng, X.; Lu, X. A supervised segmentation network for hyperspectral image classification. IEEE Trans. Image Process. 2021, 30, 2810–2825. [Google Scholar] [CrossRef] [PubMed]
- Zhang, G.; Zhao, S.; Li, W.; Du, Q.; Ran, Q.; Tao, R. HTD-Net: A deep convolutional neural network for target detection in hyperspectral imagery. Remote. Sens. 2020, 12, 1489. [Google Scholar] [CrossRef]
- Liu, X.; Liu, Q.; Wang, Y. Remote sensing image fusion based on two-stream fusion network. Inf. Fusion 2020, 55, 1–15. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Yokoya, N.; Yairi, T.; Iwasaki, A. Coupled nonnegative matrix factorization unmixing for hyperspectral and multispectral data fusion. IEEE Trans. Geosci. Remote. Sens. 2011, 50, 528–537. [Google Scholar] [CrossRef]
- Wycoff, E.; Chan, T.H.; Jia, K.; Ma, W.K.; Ma, Y. A non-negative sparse promoting algorithm for high resolution hyperspectral imaging. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; IEEE: New York, NY, USA, 2013; pp. 1409–1413. [Google Scholar]
- Jiang, J.; Sun, H.; Liu, X.; Ma, J. Learning spatial-spectral prior for super-resolution of hyperspectral imagery. IEEE Trans. Comput. Imaging 2020, 6, 1082–1096. [Google Scholar] [CrossRef]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 679–698. [Google Scholar] [CrossRef]
- Wald, L. Quality of high resolution synthesised images: Is there a simple criterion? In Proceedings of the Third Conference “Fusion of Earth Data: Merging Point Measurements, Raster Maps and Remotely Sensed Images”, Sophia Antipolis, France, 26–28 January 2000; SEE/URISCA: Nice, France, 2000; pp. 99–103. [Google Scholar]
- Yuhas, R.H.; Goetz, A.F.; Boardman, J.W. Discrimination among semi-arid landscape endmembers using the spectral angle mapper (SAM) algorithm. In Proceedings of the JPL, Summaries of the Third Annual JPL Airborne Geoscience Workshop. Volume 1: AVIRIS Workshop, Pasadena, CA, USA, 1–5 June 1992. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Dian, R.; Li, S.; Fang, L. Learning a low tensor-train rank representation for hyperspectral image super-resolution. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2672–2683. [Google Scholar] [CrossRef]
- Xu, T.; Huang, T.Z.; Deng, L.J.; Xiao, J.L.; Broni-Bediako, C.; Xia, J.; Yokoya, N. A Coupled Tensor Double-Factor Method for Hyperspectral and Multispectral Image Fusion. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 5515417. [Google Scholar] [CrossRef]
- Han, X.H.; Shi, B.; Zheng, Y. SSF-CNN: Spatial and spectral fusion with CNN for hyperspectral image super-resolution. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), IEEE, Athens, Greece, 7–10 October 2018; 2018; pp. 2506–2510. [Google Scholar]
- Yuan, Q.; Wei, Y.; Meng, X.; Shen, H.; Zhang, L. A multiscale and multidepth convolutional neural network for remote sensing imagery pan-sharpening. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2018, 11, 978–989. [Google Scholar] [CrossRef]
- Ma, Q.; Jiang, J.; Liu, X.; Ma, J. Reciprocal transformer for hyperspectral and multispectral image fusion. Inf. Fusion 2024, 104, 102148. [Google Scholar] [CrossRef]
- Wang, Y.; Yu, X.; Wen, X.; Li, X.; Dong, H.; Zang, S. Learning a 3D-CNN and Convolution Transformers for Hyperspectral Image Classification. IEEE Geosci. Remote. Sens. Lett. 2024, 21, 5504505. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Pixel Size | Left Top Position |
|---|---|---|
| Pavia University | ||
| Pavia Center | ||
| Indian Pines | ||
| Botswana | ||
| Washington DC Mall | ||
| Urban |
| Method | Pavia University | ||||
|---|---|---|---|---|---|
| RMSE | PSNR | ERGAS | SAM | SSIM | |
| Best Value | 0 | 0 | 0 | 1 | |
| CNMF | 11.047 | 26.951 | 5.431 | 10.758 | 0.845 |
| NSSR | 6.467 | 31.602 | 3.241 | 6.268 | 0.939 |
| LTTR | 4.994 | 33.846 | 2.505 | 4.279 | 0.948 |
| CTDF | 2.136 | 41.224 | 1.467 | 2.551 | 0.977 |
| SSF | 2.033 | 41.654 | 1.341 | 2.254 | 0.984 |
| ConSSF | 2.681 | 39.250 | 1.697 | 2.563 | 0.977 |
| TFNet | 2.313 | 40.533 | 1.518 | 2.487 | 0.979 |
| ResTFNet | 2.144 | 41.193 | 1.439 | 2.375 | 0.981 |
| MSDCNN | 2.432 | 40.097 | 1.581 | 2.671 | 0.980 |
| SSRNet | 1.756 | 42.928 | 1.175 | 1.996 | 0.987 |
| MSST | 2.833 | 38.772 | 1.788 | 2.767 | 0.976 |
| DCFormer | 2.666 | 39.298 | 1.614 | 2.079 | 0.986 |
| 3DCNet | 1.601 | 43.729 | 1.101 | 1.885 | 0.988 |
| Method | Pavia Center | ||||
|---|---|---|---|---|---|
| RMSE | PSNR | ERGAS | SAM | SSIM | |
| Best Value | 0 | 0 | 0 | 1 | |
| CNMF | 4.530 | 35.010 | 2.820 | 5.465 | 0.938 |
| NSSR | 3.643 | 36.901 | 2.396 | 4.438 | 0.964 |
| LTTR | 3.714 | 36.733 | 2.247 | 4.092 | 0.956 |
| CTDF | 2.158 | 41.449 | 1.789 | 3.398 | 0.970 |
| SSF | 1.818 | 42.941 | 1.545 | 2.725 | 0.981 |
| ConSSF | 5.015 | 34.125 | 3.341 | 6.061 | 0.964 |
| TFNet | 2.185 | 41.340 | 1.818 | 3.111 | 0.975 |
| ResTFNet | 1.988 | 42.163 | 1.708 | 2.927 | 0.977 |
| MSDCNN | 2.126 | 41.580 | 1.776 | 3.141 | 0.976 |
| SSRNet | 1.647 | 43.796 | 1.440 | 2.509 | 0.984 |
| MSST | 1.769 | 43.175 | 1.566 | 2.695 | 0.981 |
| DCFormer | 2.172 | 41.395 | 1.655 | 2.653 | 0.983 |
| 3DCNet | 1.531 | 44.432 | 1.382 | 2.430 | 0.985 |
| Method | Indian Pines | ||||
|---|---|---|---|---|---|
| RMSE | PSNR | ERGAS | SAM | SSIM | |
| Best Value | 0 | 0 | 0 | 1 | |
| CNMF | 5.038 | 34.085 | 2.475 | 4.480 | 0.770 |
| NSSR | 5.168 | 33.865 | 2.536 | 4.238 | 0.780 |
| LTTR | 4.695 | 34.699 | 2.308 | 4.607 | 0.777 |
| CTDF | 3.237 | 37.062 | 1.387 | 2.508 | 0.946 |
| SSF | 9.272 | 28.787 | 9.784 | 7.582 | 0.838 |
| ConSSF | 7.623 | 30.489 | 15.587 | 5.949 | 0.612 |
| TFNet | 5.515 | 33.301 | 2.673 | 3.799 | 0.917 |
| ResTFNet | 5.203 | 33.806 | 2.615 | 3.611 | 0.923 |
| MSDCNN | 5.355 | 33.556 | 2.832 | 3.763 | 0.917 |
| SSRNet | 5.028 | 34.103 | 7.977 | 3.598 | 0.874 |
| MSST | 5.099 | 33.115 | 2.450 | 3.476 | 0.922 |
| DCFormer | 4.191 | 34.817 | 1.619 | 2.806 | 0.945 |
| 3DCNet | 2.679 | 38.706 | 1.599 | 1.997 | 0.970 |
| Method | Botswana | ||||
|---|---|---|---|---|---|
| RMSE | PSNR | ERGAS | SAM | SSIM | |
| Best Value | 0 | 0 | 0 | 1 | |
| CNMF | 2.166 | 26.444 | 7.787 | 8.903 | 0.832 |
| NSSR | 1.025 | 32.945 | 3.640 | 5.764 | 0.864 |
| LTTR | 0.817 | 34.919 | 2.808 | 6.943 | 0.866 |
| CTDF | 0.396 | 39.275 | 2.682 | 1.923 | 0.998 |
| SSF | 0.843 | 34.645 | 11.509 | 4.322 | 0.982 |
| ConSSF | 1.095 | 32.368 | 15.277 | 4.865 | 0.960 |
| TFNet | 0.521 | 38.821 | 3.198 | 2.579 | 0.997 |
| ResTFNet | 0.469 | 39.743 | 2.981 | 2.368 | 0.997 |
| MSDCNN | 0.591 | 37.730 | 3.602 | 2.928 | 0.996 |
| SSRNet | 0.522 | 38.809 | 6.719 | 2.657 | 0.992 |
| MSST | 0.683 | 34.533 | 3.000 | 2.620 | 0.995 |
| DCFormer | 0.352 | 40.292 | 2.538 | 1.617 | 0.998 |
| 3DCNet | 0.319 | 42.521 | 2.474 | 1.523 | 0.998 |
| Method | Washington DC Mall | ||||
|---|---|---|---|---|---|
| RMSE | PSNR | ERGAS | SAM | SSIM | |
| Best Value | 0 | 0 | 0 | 1 | |
| CNMF | 0.954 | 45.879 | 0.175 | 0.308 | 0.995 |
| NSSR | 2.708 | 36.814 | 0.497 | 0.848 | 0.958 |
| LTTR | 1.356 | 42.825 | 0.249 | 0.358 | 0.985 |
| CTDF | 1.263 | 43.442 | 0.230 | 0.514 | 0.983 |
| SSF | 19.545 | 19.646 | 3.639 | 8.220 | 0.941 |
| ConSSF | 13.611 | 22.789 | 2.602 | 5.701 | 0.933 |
| TFNet | 1.923 | 39.786 | 0.337 | 0.646 | 0.969 |
| ResTFNet | 1.824 | 40.249 | 0.319 | 0.613 | 0.973 |
| MSDCNN | 3.056 | 35.765 | 0.535 | 1.009 | 0.928 |
| SSRNet | 2.291 | 38.266 | 0.401 | 0.801 | 0.957 |
| MSST | 2.372 | 37.964 | 0.413 | 0.738 | 0.953 |
| DCFormer | 1.550 | 41.659 | 0.278 | 0.541 | 0.992 |
| 3DCNet | 0.830 | 47.083 | 0.148 | 0.301 | 0.995 |
| Method | Urban | ||||
|---|---|---|---|---|---|
| RMSE | PSNR | ERGAS | SAM | SSIM | |
| Best Value | 0 | 0 | 0 | 1 | |
| CNMF | 7.133 | 28.818 | 3.621 | 8.083 | 0.923 |
| NSSR | 6.120 | 30.148 | 3.105 | 6.459 | 0.950 |
| LTTR | 7.024 | 28.952 | 3.575 | 6.839 | 0.911 |
| CTDF | 2.276 | 38.741 | 1.391 | 2.666 | 0.988 |
| SSF | 9.032 | 26.767 | 4.696 | 8.796 | 0.963 |
| ConSSF | 3.951 | 33.948 | 1.971 | 3.236 | 0.972 |
| TFNet | 3.127 | 35.979 | 1.763 | 2.957 | 0.983 |
| ResTFNet | 2.947 | 36.496 | 1.623 | 2.738 | 0.984 |
| MSDCNN | 2.966 | 36.438 | 1.692 | 2.992 | 0.983 |
| SSRNet | 2.483 | 37.985 | 1.280 | 2.455 | 0.988 |
| MSST | 3.460 | 35.102 | 1.904 | 3.133 | 0.977 |
| DCFormer | 3.747 | 34.410 | 2.121 | 2.063 | 0.987 |
| 3DCNet | 2.062 | 39.598 | 1.079 | 2.062 | 0.991 |
| Method | CAVE | ||||
|---|---|---|---|---|---|
| RMSE | PSNR | ERGAS | SAM | SSIM | |
| Best Value | 0 | 0 | 0 | 1 | |
| CNMF | 5.493 | 33.436 | 3.484 | 13.848 | 0.927 |
| NSSR | 5.962 | 34.529 | 4.871 | 10.332 | 0.965 |
| LTTR | 1.898 | 44.597 | 1.321 | 4.163 | 0.992 |
| CTDF | 1.556 | 46.067 | 1.127 | 3.624 | 0.992 |
| SSF | 2.062 | 42.346 | 1.306 | 3.198 | 0.992 |
| ConSSF | 1.777 | 43.977 | 1.105 | 2.801 | 0.994 |
| TFNet | 1.531 | 45.169 | 0.963 | 3.017 | 0.995 |
| ResTFNet | 1.338 | 45.980 | 0.850 | 2.917 | 0.995 |
| MSDCNN | 1.629 | 44.402 | 1.031 | 2.992 | 0.995 |
| SSRNet | 1.860 | 43.646 | 1.246 | 3.268 | 0.995 |
| MSST | 1.623 | 45.845 | 1.161 | 3.786 | 0.990 |
| DCFormer | 2.326 | 41.357 | 1.480 | 3.460 | 0.991 |
| 3DCNet | 1.446 | 46.092 | 0.916 | 2.998 | 0.994 |
| Dataset | Class |
|---|---|
| Pavia University | asphalt, meadows, trees, painted metal sheets, bare soil, bitumen, self-blocking bricks, shadows |
| Pavia | water, trees, asphalt, self-blocking bricks, bitumen, tiles, bare soil |
| Indian Pines | corn-notill, corn-mintill, corn, grass-pasture, grass-trees, oats, soybean-notill, soybean-mintill, soybean-clean, buildings-grass-trees-drives, stone-steel-towers |
| Botswana | water, hippo grass, reeds 1, firescar 2, Acacia woodlands, exposed soils |
| Class | Count | SSF | ConSS | TFNet | ResTF | MSD | SSR | MSST | DCFor | Ours |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 365 | 100.0 | 89.59 | 100.0 | 94.80 | 98.08 | 96.71 | 98.36 | 96.99 | 100.0 |
| 2 | 570 | 100.0 | 100.0 | 99.83 | 100.0 | 100.0 | 100.00 | 100.0 | 100.0 | 100.0 |
| 3 | 114 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100.0 |
| 4 | 580 | 95.86 | 100.0 | 98.62 | 100.0 | 100.0 | 98.83 | 100.0 | 100.0 | 100.0 |
| 5 | 3537 | 40.43 | 50.75 | 37.04 | 36.53 | 36.87 | 54.82 | 56.63 | 43.99 | 100.0 |
| 6 | 753 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 94.42 |
| 7 | 52 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 94.23 |
| 8 | 233 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 92.70 |
| OA | 47.92 | 53.58 | 46.23 | 45.78 | 46.16 | 56.30 | 57.45 | 50.16 | 99.00 | |
| AA | 54.54 | 55.04 | 54.44 | 53.92 | 54.37 | 56.30 | 56.87 | 55.12 | 97.67 | |
| KAPPA | 35.95 | 41.01 | 34.68 | 34.38 | 34.54 | 43.35 | 44.90 | 38.09 | 98.43 | |
| Class | Count | SSF | ConSS | TFNet | ResTF | MSD | SSR | MSST | DCFor | Ours |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 365 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
| 2 | 570 | 97.19 | 100.0 | 84.74 | 100.0 | 100.0 | 100.0 | 96.67 | 97.72 | 100.0 |
| 3 | 114 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
| 4 | 580 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 98.45 | 100.0 | 100.0 | 100.0 |
| 5 | 3537 | 72.75 | 85.58 | 61.86 | 37.38 | 66.64 | 96.16 | 86.32 | 88.01 | 100.0 |
| 6 | 753 | 84.46 | 87.12 | 63.88 | 81.54 | 87.65 | 73.71 | 94.16 | 90.44 | 94.42 |
| 7 | 52 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 94.23 |
| 8 | 233 | 99.57 | 99.14 | 98.71 | 98.71 | 99.57 | 88.41 | 95.28 | 93.99 | 92.70 |
| OA | 82.30 | 90.18 | 72.42 | 62.01 | 79.47 | 94.04 | 91.01 | 91.57 | 99.00 | |
| AA | 94.25 | 96.48 | 88.65 | 89.70 | 94.23 | 94.59 | 96.55 | 96.27 | 97.67 | |
| KAPPA | 75.15 | 85.53 | 62.66 | 53.06 | 71.89 | 90.83 | 86.66 | 87.43 | 98.43 | |
| Class | Count | SSF | ConSS | TFNet | ResTF | MSD | SSR | MSST | DCFor | Ours |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 563 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
| 2 | 41 | 19.51 | 58.54 | 46.34 | 19.51 | 19.51 | 60.98 | 100.0 | 100.0 | 97.56 |
| 3 | 327 | 99.69 | 99.69 | 74.62 | 100.0 | 85.93 | 73.09 | 52.60 | 45.87 | 66.36 |
| 4 | 524 | 43.70 | 50.57 | 60.12 | 58.78 | 75.38 | 93.89 | 99.24 | 100.0 | 97.71 |
| 5 | 3437 | 99.97 | 100.0 | 99.80 | 99.51 | 100.0 | 99.94 | 100.0 | 100.0 | 100.0 |
| 6 | 635 | 100.0 | 100.0 | 98.27 | 100.0 | 100.0 | 99.84 | 100.0 | 100.0 | 100.0 |
| 7 | 24 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
| OA | 94.06 | 95.01 | 94.02 | 95.21 | 96.25 | 97.46 | 97.14 | 96.81 | 97.78 | |
| AA | 80.41 | 86.97 | 82.73 | 82.54 | 82.98 | 89.68 | 93.12 | 92.27 | 94.52 | |
| KAPPA | 89.24 | 91.03 | 89.19 | 91.47 | 93.35 | 95.54 | 94.95 | 94.34 | 96.10 | |
| Class | Count | SSF | ConSS | TFNet | ResTF | MSD | SSR | MSST | DCFor | Ours |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 732 | 96.45 | 89.21 | 93.58 | 94.95 | 97.81 | 98.09 | 98.63 | 93.44 | 93.44 |
| 2 | 434 | 85.95 | 99.08 | 99.08 | 99.77 | 97.47 | 98.85 | 94.70 | 91.48 | 98.16 |
| 3 | 237 | 67.09 | 73.84 | 63.29 | 88.19 | 79.75 | 73.00 | 85.23 | 80.17 | 83.12 |
| 4 | 18 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 190 | 100.0 | 98.95 | 100.0 | 100.0 | 100.0 | 99.47 | 99.47 | 99.47 | 94.21 |
| 6 | 6 | 66.67 | 66.67 | 100.0 | 100.0 | 83.33 | 100.0 | 100.0 | 100.0 | 100.0 |
| 7 | 60 | 21.67 | 40.00 | 40.00 | 68.33 | 80.00 | 46.67 | 61.67 | 61.67 | 66.67 |
| 8 | 252 | 82.94 | 84.13 | 98.41 | 88.89 | 78.97 | 59.13 | 53.18 | 94.05 | 93.25 |
| 9 | 510 | 91.37 | 81.37 | 80.39 | 54.90 | 84.31 | 87.06 | 85.69 | 82.55 | 82.75 |
| 10 | 89 | 100.0 | 98.88 | 95.51 | 89.89 | 95.51 | 97.75 | 92.14 | 95.51 | 95.51 |
| 11 | 93 | 95.67 | 100.0 | 95.70 | 100.0 | 94.62 | 97.85 | 100.0 | 100.0 | 98.93 |
| OA | 87.67 | 87.07 | 88.40 | 85.88 | 90.54 | 88.29 | 88.25 | 89.24 | 90.27 | |
| AA | 73.44 | 75.65 | 78.72 | 80.45 | 81.07 | 77.99 | 79.16 | 81.67 | 82.37 | |
| KAPPA | 85.06 | 84.48 | 86.02 | 83.07 | 88.62 | 85.85 | 85.75 | 87.09 | 88.34 | |
| Class | Count | SSF | ConSS | TFNet | ResTF | MSD | SSR | MSST | DCFor | Ours |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 34 | 100.0 | 100.0 | 100.0 | 100.0 | 97.06 | 100.0 | 100.0 | 100.0 | 100.0 |
| 2 | 58 | 100.0 | 100.0 | 89.66 | 86.21 | 100.0 | 98.28 | 100.0 | 86.21 | 100.0 |
| 3 | 3 | 0 | 0 | 100.0 | 0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
| 4 | 43 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
| 5 | 33 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
| 6 | 16 | 62.50 | 43.75 | 0.00 | 50.00 | 62.50 | 37.50 | 62.50 | 87.50 | 87.50 |
| OA | 95.19 | 93.58 | 88.24 | 89.84 | 91.44 | 94.12 | 96.79 | 94.65 | 98.93 | |
| AA | 77.08 | 73.96 | 81.61 | 72.70 | 83.89 | 89.30 | 93.75 | 95.62 | 97.92 | |
| KAPPA | 93.80 | 91.77 | 85.21 | 87.23 | 89.09 | 92.51 | 95.90 | 93.26 | 98.63 | |
| Strategy | Urban Ablation Experiment | ||||
|---|---|---|---|---|---|
| RMSE | PSNR | ERGAS | SAM | SSIM | |
| w/o-spat | 2.547 | 37.762 | 1.249 | 2.580 | 0.987 |
| w/o-spec | 2.302 | 38.641 | 1.152 | 2.291 | 0.989 |
| w/o-2stream | 2.264 | 38.787 | 1.174 | 2.252 | 0.990 |
| w/o-canny | 2.358 | 38.433 | 1.179 | 2.135 | 0.990 |
| w/o-angle | 2.147 | 39.245 | 1.124 | 2.126 | 0.990 |
| 3DCNet | 2.062 | 39.598 | 1.079 | 2.062 | 0.991 |
| Strategy | Class | Metric | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | OA | AA | KAPPA | |
| classification on the reference | 100.0 | 100.0 | 100.0 | 100.0 | 98.90 | 95.88 | 100.0 | 99.57 | 98.86 | 99.29 | 98.22 |
| transferred classification model | 100.0 | 100.0 | 100.0 | 100.0 | 80.24 | 82.74 | 100.0 | 99.57 | 86.62 | 95.32 | 80.70 |
| one stage training | 88.49 | 100.0 | 95.61 | 92.24 | 73.40 | 0 | 100.0 | 0 | 67.46 | 68.72 | 54.89 |
| without loss interaction | 100.0 | 93.33 | 100.0 | 100.0 | 93.36 | 97.74 | 92.31 | 89.70 | 94.87 | 95.81 | 92.15 |
| our ATIS | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 94.42 | 94.23 | 92.70 | 99.00 | 97.67 | 98.43 |
| Strategy | Pavia University | ||||
|---|---|---|---|---|---|
| RMSE | PSNR | ERGAS | SAM | SSIM | |
| one-stage | 1.777 | 43.139 | 1.375 | 1.993 | 0.986 |
| ATIS | 1.645 | 43.491 | 1.131 | 1.899 | 0.987 |
| only fusion | 1.601 | 43.729 | 1.101 | 1.885 | 0.988 |
| Dataset | OA | AA | KAPPA | |||
|---|---|---|---|---|---|---|
| 3DCFormer | DBDA | 3DCFormer | DBDA | 3DCFormer | DBDA | |
| Pavia University | 97.10 | 99.00 | 99.16 | 97.67 | 95.54 | 98.43 |
| Pavia Center | 98.58 | 97.78 | 96.78 | 94.52 | 98.46 | 96.10 |
| Indian Pines | 89.62 | 90.27 | 80.07 | 82.37 | 91.17 | 88.34 |
| Botswana | 99.47 | 98.93 | 99.71 | 97.92 | 97.33 | 98.63 |
| Model | Urban Complexity Experiment | ||
|---|---|---|---|
| Params (M) | FLOPs (G) | Testing (ms) | |
| SSF | 1.136 | 37.217 | 174 |
| ConSSF | 1.163 | 38.119 | 115 |
| TFNet | 2.501 | 19.891 | 159 |
| ResTFNet | 2.376 | 18.618 | 111 |
| MSDCNN | 1.823 | 59.741 | 177 |
| SSRNet | 0.709 | 23.219 | 41 |
| MSST | 41.01 | 527.58 | 464 |
| DCFormer | 5.410 | 318.51 | 294 |
| 3DCNet | 0.708 | 15.923 | 94 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Q.; Long, J.; Li, J.; Li, C.; Si, J.; Peng, Y. ATIS-Driven 3DCNet: A Novel Three-Stream Hyperspectral Fusion Framework with Knowledge from Downstream Classification Performance. Remote Sens. 2025, 17, 825. https://doi.org/10.3390/rs17050825
Zhang Q, Long J, Li J, Li C, Si J, Peng Y. ATIS-Driven 3DCNet: A Novel Three-Stream Hyperspectral Fusion Framework with Knowledge from Downstream Classification Performance. Remote Sensing. 2025; 17(5):825. https://doi.org/10.3390/rs17050825
Chicago/Turabian StyleZhang, Quan, Jian Long, Jun Li, Chunchao Li, Jianxin Si, and Yuanxi Peng. 2025. "ATIS-Driven 3DCNet: A Novel Three-Stream Hyperspectral Fusion Framework with Knowledge from Downstream Classification Performance" Remote Sensing 17, no. 5: 825. https://doi.org/10.3390/rs17050825
APA StyleZhang, Q., Long, J., Li, J., Li, C., Si, J., & Peng, Y. (2025). ATIS-Driven 3DCNet: A Novel Three-Stream Hyperspectral Fusion Framework with Knowledge from Downstream Classification Performance. Remote Sensing, 17(5), 825. https://doi.org/10.3390/rs17050825