
AG-Yolo: Attention-Guided Yolo for Efficient Remote Sensing Oriented Object Detection

Abstract
:
1. Introduction
- An oriented object detection (OOD) method is proposed, namely AG-Yolo. An additional rotation parameter is supplemented to the head of Yolo-v10 to achieve efficient OOD. The dual label assignment strategy is also extended for OOD, which can bring both strong supervision during training and high efficiency during inference. This improves the precision–latency balance.
- In order to deal with the complex background interference in remote sensing images, an attention branch is constructed and paralleled with the backbone. It generates attention maps from the shallow features of inputs, mimicking the human recognition process, to guide the feature aggregation of the neck to focus on foregrounds. The attention branch enables the model to concentrate on the objects themselves, thereby facilitating precision.
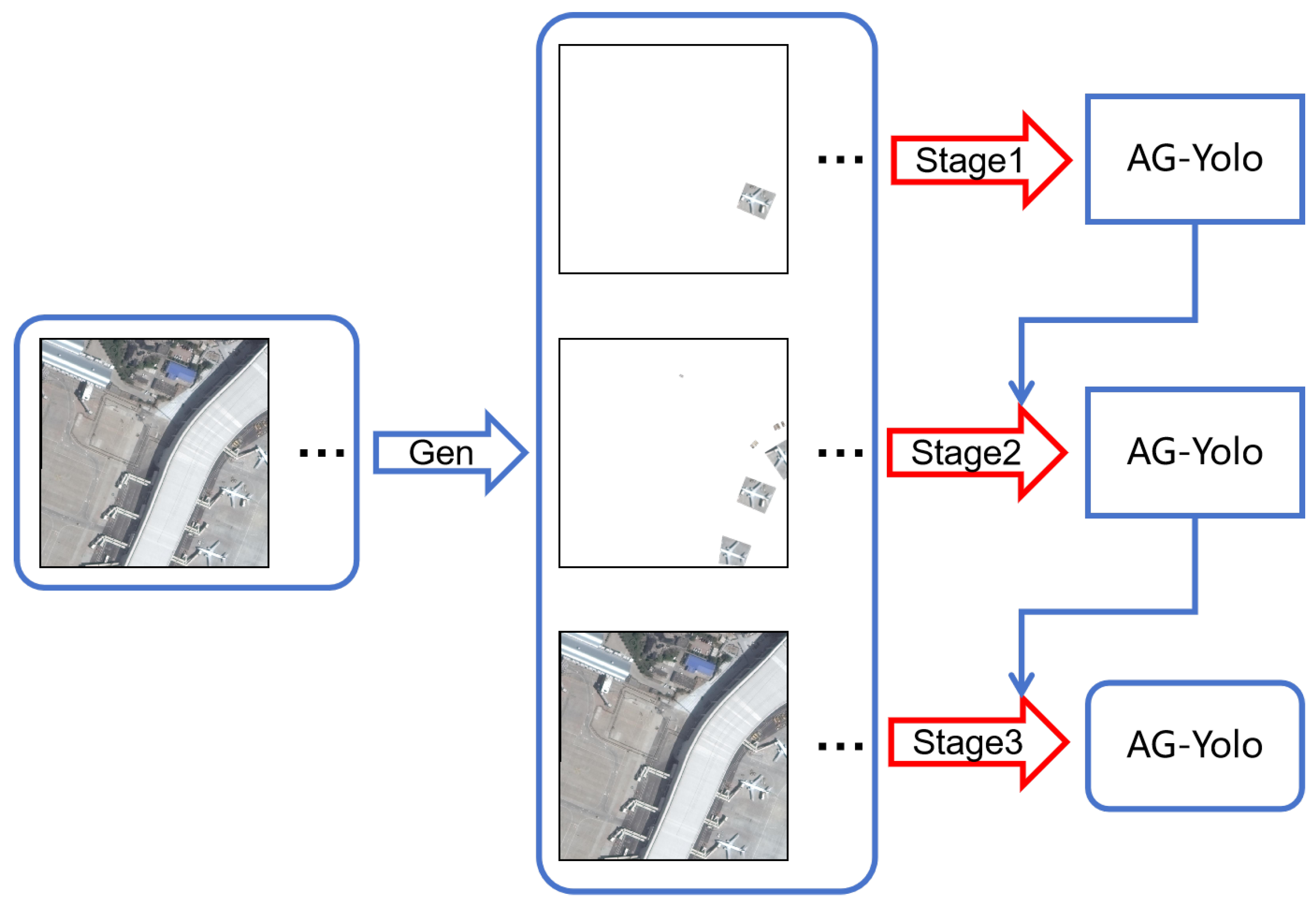
- When targeting complex background issues, a three-stage curriculum learning strategy is designed to further improve detection performance. Derived from the background complexity, some much easier samples are generated from the labeled dataset. Training from these samples step by step provides the model with a better starting point to handle complicated information, which is conducive to precision.
2. Related Work
2.1. Oriented Bounding-Box Detection
2.2. Attention Mechanism
2.3. Curriculum Learning
3. Methods
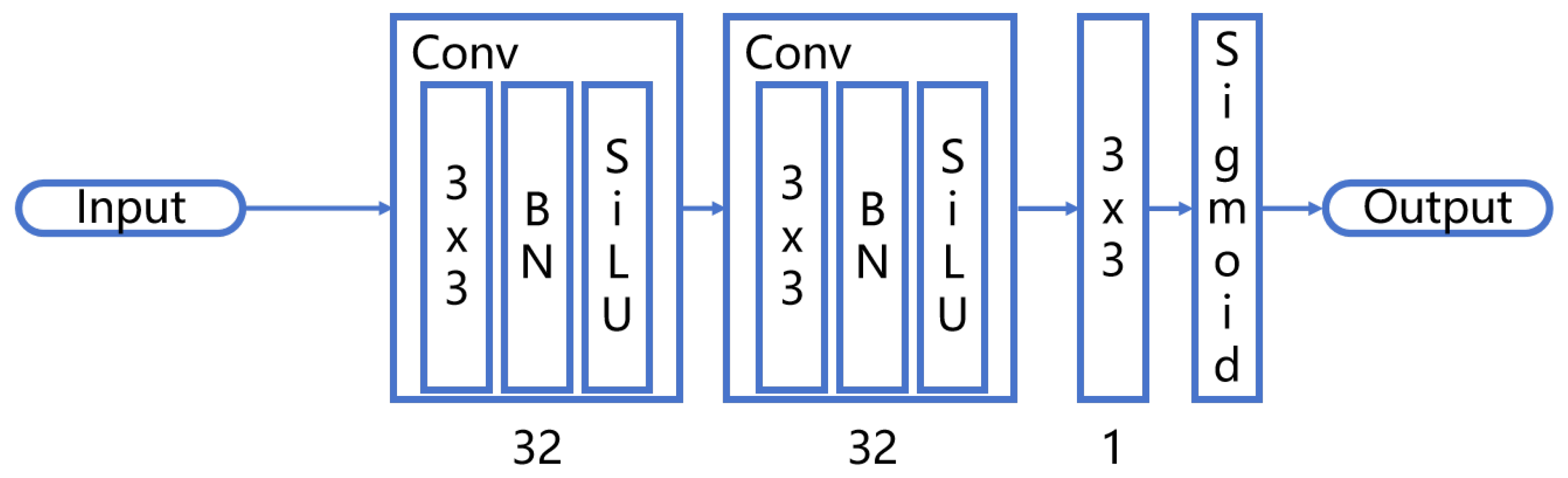
3.1. Attention Branch
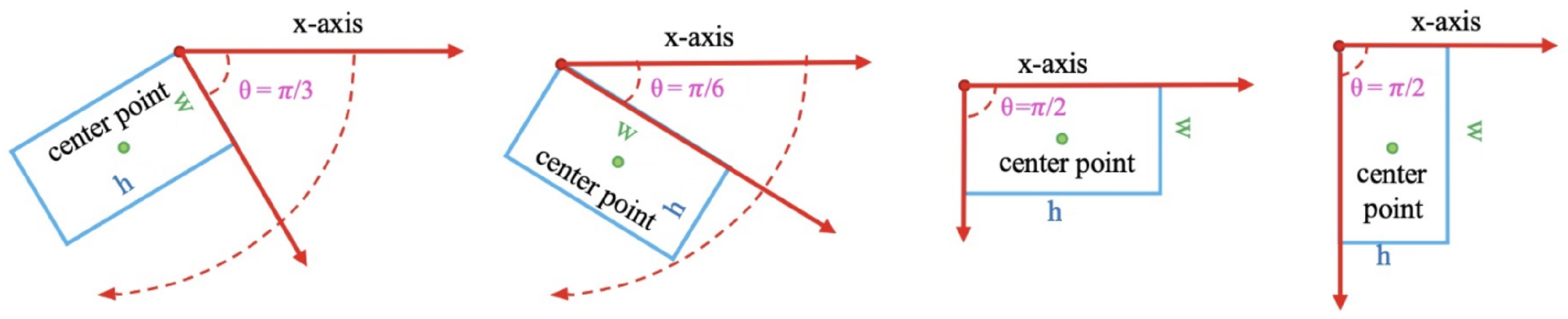
3.2. Oriented Bounding-Box Regression Head
3.3. Curriculum Learning Strategy
4. Experiments and Results
4.1. Benchmark Evaluations
4.1.1. Experimental Configuration
4.1.2. Qualitative Comparison
4.1.3. Quantitative Comparison
4.2. Model Analyses
4.2.1. Ablation Study
4.2.2. Analyses for the Attention Branch
4.2.3. Analyses for the NMS-Free OBB Head
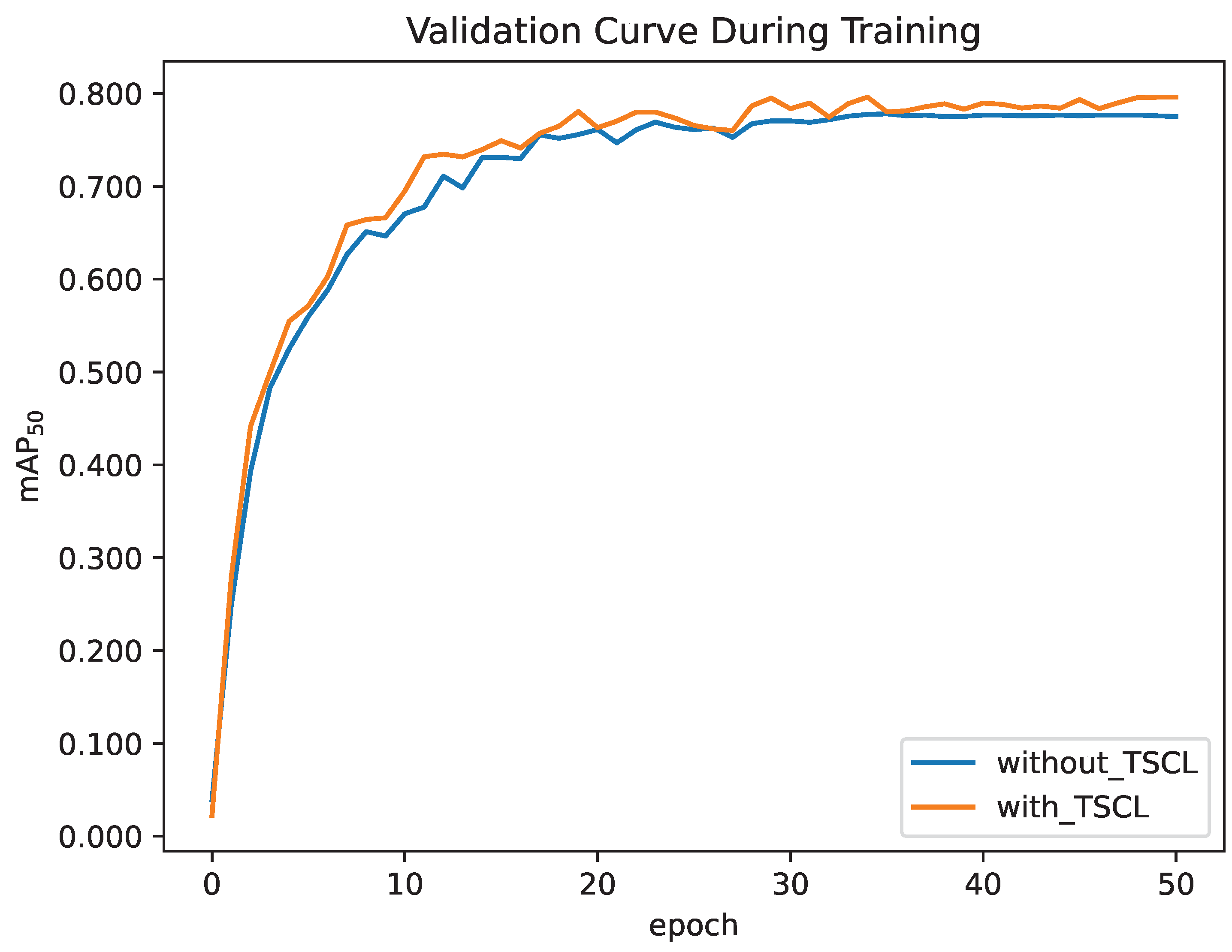
4.2.4. Analyses for the Three-Stage Curriculum Learning Strategy
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zheng, Z.; Wu, M.; Chen, L.; Wang, C.; Xiong, J.; Wei, L.; Huang, X.; Wang, S.; Huang, W.; Du, D. A robust and efficient citrus counting approach for large-scale unstructured orchards. Agric. Syst. 2024, 215, 103867. [Google Scholar] [CrossRef]
- Sun, W.; Dai, L.; Zhang, X.; Chang, P.; He, X. RSOD: Real-time small object detection algorithm in UAV-based traffic monitoring. Appl. Intell. 2022, 52, 8448–8463. [Google Scholar] [CrossRef]
- Liu, H.; Yu, Y.; Liu, S.; Wang, W. A Military Object Detection Model of UAV Reconnaissance Image and Feature Visualization. Appl. Sci. 2022, 12, 12236. [Google Scholar] [CrossRef]
- Ju, Y.; Xu, Q.; Jin, S.; Li, W.; Su, Y.; Dong, X.; Guo, Q. Loess Landslide Detection Using Object Detection Algorithms in Northwest China. Remote Sens. 2022, 14, 1182. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Redmon, J. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Yu, J.; Sun, L.; Song, S.; Guo, G.; Chen, K. BAIDet: Remote sensing image object detector based on background and angle information. Signal Image Video Process. 2024, 18, 9295–9304. [Google Scholar] [CrossRef]
- Wang, J.; Yang, W.; Li, H.C.; Zhang, H.; Xia, G.S. Learning center probability map for detecting objects in aerial images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4307–4323. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLOv8. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 31 May 2024).
- Zhang, H.; Yang, K.F.; Li, Y.J.; Chan, L.L.H. Night-Time Vehicle Detection Based on Hierarchical Contextual Information. IEEE Trans. Intell. Transp. Syst. 2024, 25, 14628–14641. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3det: Refined single-stage detector with feature refinement for rotating object. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 3163–3171. [Google Scholar]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. Scrdet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8232–8241. [Google Scholar]
- Han, J.; Ding, J.; Li, J.; Xia, G.S. Align deep features for oriented object detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5602511. [Google Scholar] [CrossRef]
- Yu, Y.; Da, F. On Boundary Discontinuity in Angle Regression Based Arbitrary Oriented Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 6494–6508. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.S.; Bai, X. Gliding vertex on the horizontal bounding box for multi-oriented object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 1452–1459. [Google Scholar] [CrossRef]
- Huang, Z.; Li, W.; Xia, X.G.; Tao, R. A general Gaussian heatmap label assignment for arbitrary-oriented object detection. IEEE Trans. Image Process. 2022, 31, 1895–1910. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Yang, X.; Zhang, G.; Wang, J.; Liu, Y.; Hou, L.; Jiang, X.; Liu, X.; Yan, J.; Lyu, C.; et al. MMRotate: A Rotated Object Detection Benchmark using PyTorch. In Proceedings of the 30th ACM International Conference on Multimedia, New York, NY, USA, 10–14 October 2022; Available online: https://github.com/open-mmlab/mmrotate (accessed on 1 December 2024).
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent models of visual attention. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Soviany, P.; Ionescu, R.T.; Rota, P.; Sebe, N. Curriculum learning: A survey. Int. J. Comput. Vis. 2022, 130, 1526–1565. [Google Scholar] [CrossRef]
- Li, B.; Liu, T.; Wang, B.; Wang, L. Label noise robust curriculum for deep paraphrase identification. In Proceedings of the 2020 International Joint Conference On Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Jafarpour, B.; Sepehr, D.; Pogrebnyakov, N. Active curriculum learning. In Proceedings of the First Workshop on Interactive Learning for Natural Language Processing, Virtual, 7 November 2021; pp. 40–45. [Google Scholar]
- Dogan, Ü.; Deshmukh, A.A.; Machura, M.B.; Igel, C. Label-similarity curriculum learning. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXIX 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 174–190. [Google Scholar]
- Zhang, B.; Wang, Y.; Hou, W.; Wu, H.; Wang, J.; Okumura, M.; Shinozaki, T. Flexmatch: Boosting semi-supervised learning with curriculum pseudo labeling. Adv. Neural Inf. Process. Syst. 2021, 34, 18408–18419. [Google Scholar]
- Soviany, P.; Ardei, C.; Ionescu, R.T.; Leordeanu, M. Image difficulty curriculum for generative adversarial networks (CuGAN). In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 3463–3472. [Google Scholar]
- Doan, T.; Monteiro, J.; Albuquerque, I.; Mazoure, B.; Durand, A.; Pineau, J.; Hjelm, R.D. On-line adaptative curriculum learning for gans. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 3470–3477. [Google Scholar]
- Wang, J.; Wang, X.; Liu, W. Weakly-and semi-supervised faster r-cnn with curriculum learning. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2416–2421. [Google Scholar]
- Feng, J.; Jiang, Q.; Zhang, J.; Liang, Y.; Shang, R.; Jiao, L. CFDRM: Coarse-to-Fine Dynamic Refinement Model for Weakly Supervised Moving Vehicle Detection in Satellite Videos. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5626413. [Google Scholar] [CrossRef]
- Zhang, Y.J.; Li, N.N.; Xie, B.H.; Zhang, R.; Lu, W.D. Semi-supervised object detection framework guided by curriculum learning. J. Comput. Appl. 2023, 43, 1234–1245. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Howard, A.G. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
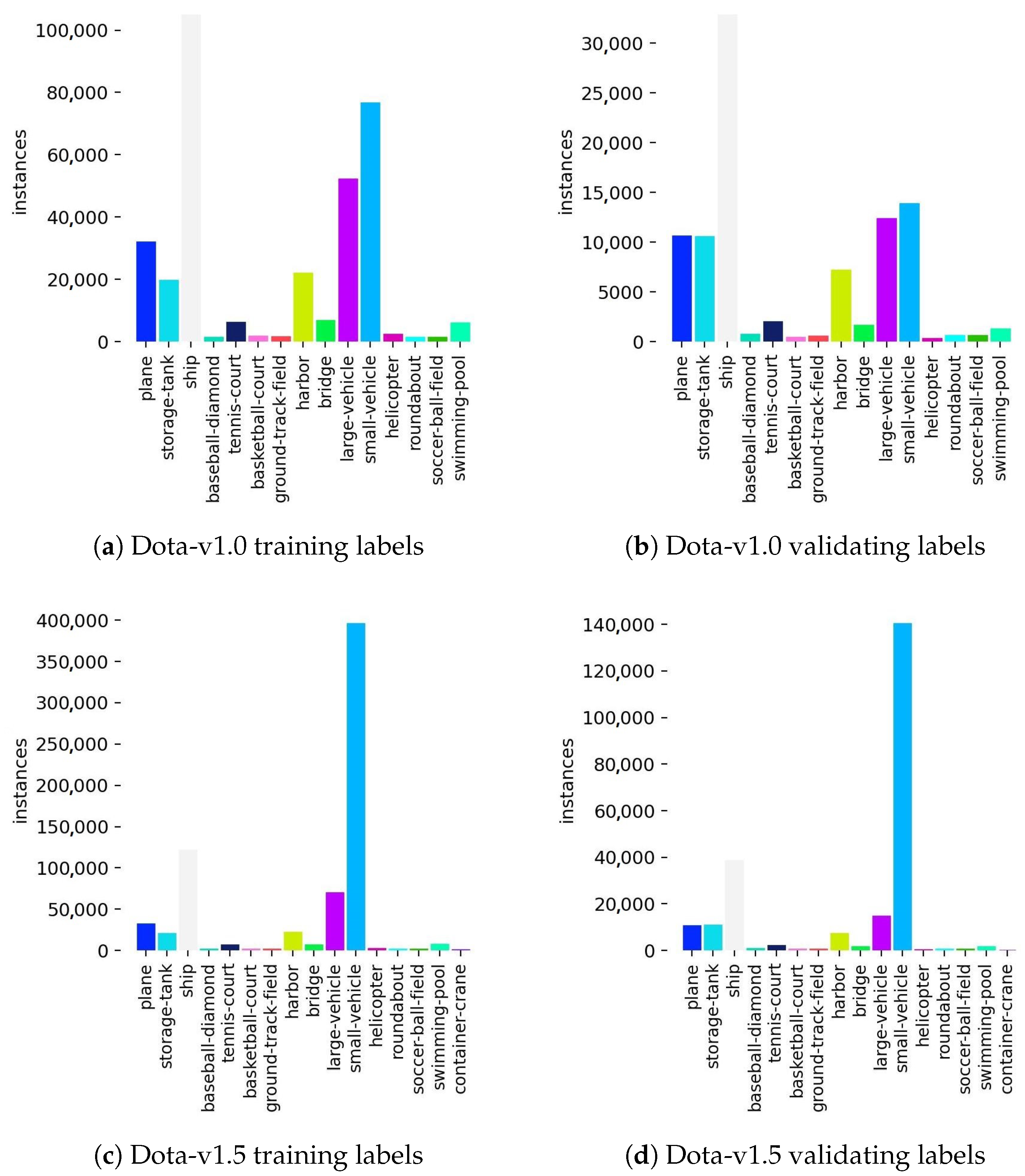
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Jian, D.; Nan, X.; Yang, L.; Xia, G.-S.; Lu, Q. Learning RoI Transformer for Detecting Oriented Objects in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. arXiv 2019, arXiv:1904.01355. [Google Scholar]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3520–3529. [Google Scholar]
- Wentong, L.; Yijie, C.; Kaixuan, H.; Jianke, Z. Oriented RepPoints for Aerial Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLO. 2024. Available online: https://github.com/ultralytics/ultralytics (accessed on 1 December 2024).
- Kingma, D.P. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Value |
|---|---|
| CPU | Intel (R) Core (TM) i7-10870H |
| GPU | NVIDIA RTX A6000 |
| OS | Ubuntu22.04 |
| Batch Size | Epochs | Learning Rate | ||
|---|---|---|---|---|
| AG-Yolo | Stage 1 | 4 | 1 | |
| Stage 2 | 4 | 1 | ||
| Stage 3 | 4 | 36 | ||
| 4 | 12 | |||
| 4 | 2 | |||
| Other compared methods | 4 | 36 | ||
| 4 | 12 | |||
| 4 | 2 | |||
| S2ANet | Rotated_FCOS | Oriented_RCNN | Oriented_Reppoints | Yolov8-obb | AG-Yolo | |
|---|---|---|---|---|---|---|
| plane | 0.777 | 0.794 | 0.793 | 0.780 | 0.915 | 0.913 |
| ship | 0.792 | 0.869 | 0.875 | 0.858 | 0.905 | 0.897 |
| storage tank | 0.704 | 0.687 | 0.693 | 0.750 | 0.849 | 0.852 |
| baseball diamond | 0.732 | 0.718 | 0.752 | 0.742 | 0.831 | 0.842 |
| tennis court | 0.891 | 0.895 | 0.896 | 0.892 | 0.940 | 0.931 |
| basketball court | 0.766 | 0.753 | 0.810 | 0.717 | 0.723 | 0.741 |
| ground track field | 0.524 | 0.413 | 0.627 | 0.505 | 0.629 | 0.659 |
| harbor | 0.680 | 0.657 | 0.759 | 0.671 | 0.858 | 0.853 |
| bridge | 0.517 | 0.485 | 0.575 | 0.504 | 0.649 | 0.655 |
| large vehicle | 0.773 | 0.818 | 0.842 | 0.791 | 0.855 | 0.862 |
| small vehicle | 0.586 | 0.612 | 0.593 | 0.657 | 0.631 | 0.643 |
| helicopter | 0.626 | 0.649 | 0.733 | 0.665 | 0.823 | 0.840 |
| roundabout | 0.694 | 0.666 | 0.662 | 0.653 | 0.704 | 0.726 |
| soccer ball field | 0.513 | 0.631 | 0.684 | 0.410 | 0.659 | 0.702 |
| swimming pool | 0.661 | 0.701 | 0.705 | 0.663 | 0.812 | 0.827 |
| 0.682 | 0.690 | 0.733 | 0.684 | 0.786 | 0.796 | |
| latency/ms | 38.89 | 47.06 | 61.29 | 78.57 | 33.80 | 19.70 |
| #Params/M | 35.58 | 31.92 | 41.14 | 35.43 | 26.41 | 16.56 |
| S2ANet | Rotated_FCOS | Oriented_RCNN | Oriented_Reppoints | Yolov8-obb | AG-Yolo | |
|---|---|---|---|---|---|---|
| plane | 0.705 | 0.794 | 0.774 | 0.776 | 0.862 | 0.840 |
| ship | 0.762 | 0.773 | 0.821 | 0.790 | 0.839 | 0.847 |
| storage tank | 0.605 | 0.611 | 0.614 | 0.697 | 0.796 | 0.793 |
| baseball diamond | 0.718 | 0.726 | 0.718 | 0.705 | 0.800 | 0.761 |
| tennis court | 0.868 | 0.812 | 0.885 | 0.883 | 0.857 | 0.855 |
| basketball court | 0.776 | 0.709 | 0.719 | 0.671 | 0.640 | 0.744 |
| ground track field | 0.463 | 0.327 | 0.543 | 0.463 | 0.556 | 0.560 |
| harbor | 0.604 | 0.687 | 0.673 | 0.682 | 0.767 | 0.773 |
| bridge | 0.464 | 0.484 | 0.479 | 0.485 | 0.636 | 0.577 |
| large vehicle | 0.693 | 0.771 | 0.780 | 0.710 | 0.791 | 0.804 |
| small vehicle | 0.591 | 0.639 | 0.628 | 0.661 | 0.659 | 0.663 |
| helicopter | 0.534 | 0.654 | 0.642 | 0.595 | 0.736 | 0.739 |
| roundabout | 0.620 | 0.658 | 0.651 | 0.654 | 0.666 | 0.689 |
| soccer ball field | 0.475 | 0.550 | 0.657 | 0.360 | 0.601 | 0.609 |
| swimming pool | 0.653 | 0.611 | 0.657 | 0.609 | 0.795 | 0.811 |
| container crane | 0.471 | 0.492 | 0.527 | 0.486 | 0.566 | 0.579 |
| 0.625 | 0.644 | 0.673 | 0.639 | 0.723 | 0.728 | |
| latency/ms | 38.89 | 47.06 | 61.29 | 78.57 | 33.80 | 19.70 |
| #Params/M | 35.58 | 31.92 | 41.14 | 35.43 | 26.41 | 16.56 |
| Att. Bran. | NMS-Free. | Three-Stage C.L. | Latency/ms | ||
|---|---|---|---|---|---|
| Yolov10m-obb | 0.782 | 23.86 | |||
| ✓ | 0.803 | 24.61 | |||
| ✓ | ✓ | 0.778 | 19.70 | ||
| ✓ | ✓ | ✓ | 0.796 | 19.70 |
| o2m | o2o | Latency/ms | |
|---|---|---|---|
| ✓ | 0.817 | 24.61 | |
| 0.781 | 19.70 | ||
| ✓ | ✓ | 0.796 | 19.70 |
| CL | Latency/ms | |
|---|---|---|
| ✓ | 0.803 | 33.80 |
| 0.786 | 33.80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Han, C.; Huang, L.; Nie, T.; Liu, X.; Liu, H.; Li, M. AG-Yolo: Attention-Guided Yolo for Efficient Remote Sensing Oriented Object Detection. Remote Sens. 2025, 17, 1027. https://doi.org/10.3390/rs17061027
Wang X, Han C, Huang L, Nie T, Liu X, Liu H, Li M. AG-Yolo: Attention-Guided Yolo for Efficient Remote Sensing Oriented Object Detection. Remote Sensing. 2025; 17(6):1027. https://doi.org/10.3390/rs17061027
Chicago/Turabian StyleWang, Xiaofeng, Chengshan Han, Liang Huang, Ting Nie, Xin Liu, Hao Liu, and Mingxuan Li. 2025. "AG-Yolo: Attention-Guided Yolo for Efficient Remote Sensing Oriented Object Detection" Remote Sensing 17, no. 6: 1027. https://doi.org/10.3390/rs17061027
APA StyleWang, X., Han, C., Huang, L., Nie, T., Liu, X., Liu, H., & Li, M. (2025). AG-Yolo: Attention-Guided Yolo for Efficient Remote Sensing Oriented Object Detection. Remote Sensing, 17(6), 1027. https://doi.org/10.3390/rs17061027