
SMEP-DETR: Transformer-Based Ship Detection for SAR Imagery with Multi-Edge Enhancement and Parallel Dilated Convolutions

Abstract

1. Introduction
- 1.
- A denoising module is designed with consideration of the speckle noise characteristics in SAR images and seamlessly integrated into the detection framework, ensuring joint optimization of speckle suppression and feature extraction.
- 2.
- We introduce the multi-edge information enhancement (MEIE) module, which integrates the Sobel operator and max pooling to extract edge information, followed by flexible feature extraction via edge information fusion (EIFusion).
- 3.
- We propose a novel parallel dilated convolution and attention pyramid network (PDC-APN) for feature fusion, replacing traditional sampling operations to ensure the preservation of objects’ contextual information.
- 4.
- Through quantitative and qualitative analyses, extensive experiments on SSDD, HRSID, and LS-SSDD-v1.0 demonstrate substantial improvements, validating the robustness of our scheme in inshore and offshore scenarios.
2. Related Work
2.1. DL-Based General Object Detection
2.2. SAR Ship Detection Algorithms
3. Proposed Method
3.1. Overall Framework
3.2. Speckle Denoising Module
3.3. Multi-Edge Information Enhancement Module
3.4. Parallel Dilated Convolution–Attention Pyramid Network
3.5. Uncertainty in Minimal Query Selection and Predict Head
4. Experiments and Results
4.1. Data and Implementation Details
4.2. Evaluation Metrics
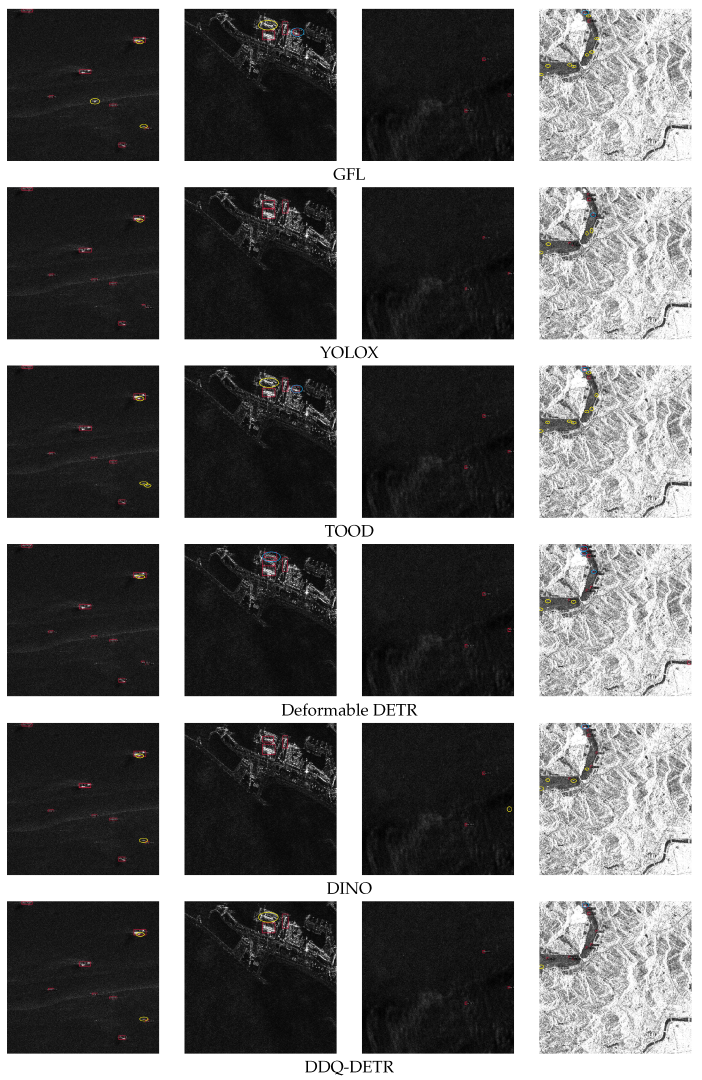
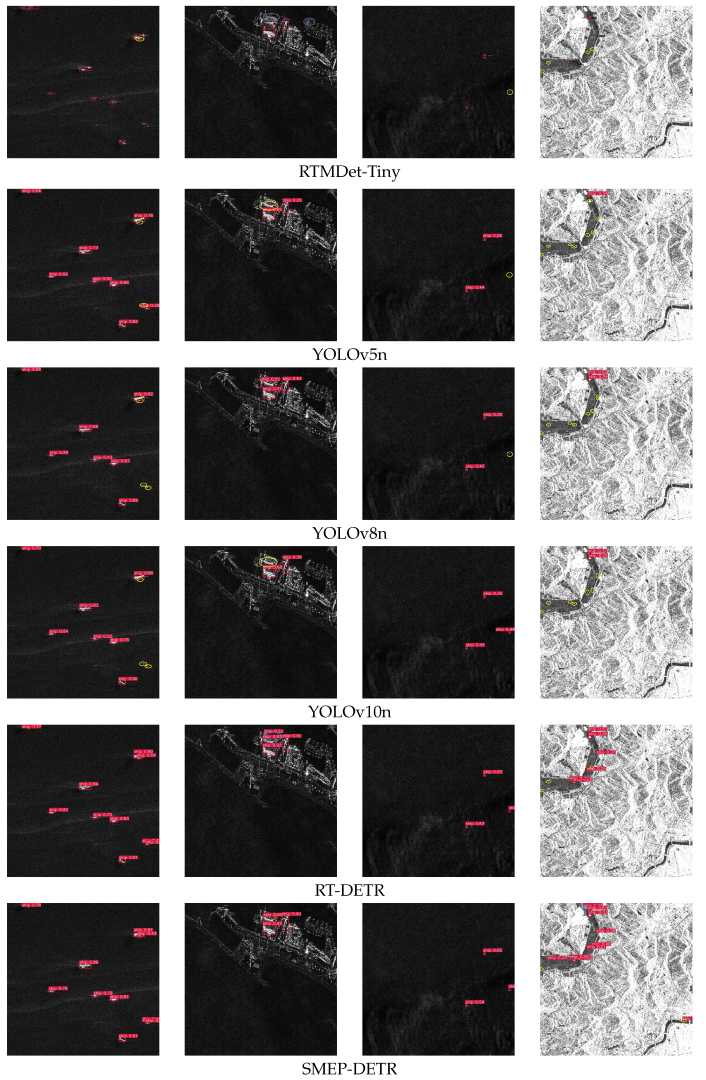
4.3. Comparisons of Performance
4.4. Ablation Experiments
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Campbell, J.B. Introduction to Remote Sensing, 4th ed.; Guilford Press: New York, NY, USA, 2007. [Google Scholar]
- Toth, C.; Jóźków, G. Remote sensing platforms and sensors: A survey. ISPRS J. Photogramm. Remote Sens. 2016, 115, 22–36. [Google Scholar] [CrossRef]
- Li, J.; Xu, C.; Su, H.; Gao, L.; Wang, T. Deep learning for SAR ship detection: Past, present and future. Remote Sens. 2022, 14, 2712. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Terven, J.; Cordova-Esparza, D. A comprehensive review of YOLO architectures in computer vision: From YOLOv1 to YOLOv8 and YOLO-NAS. arXiv 2023, arXiv:2304.00501. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. arXiv 2019, arXiv:1904.01355. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah:, M. Transformers in vision: A survey. arXiv 2021, arXiv:2101.01169. [Google Scholar] [CrossRef]
- Aleissaee, A.A.; Kumar, A.; Anwer, R.M.; Khan, S.; Cholakkal, H.; Xia, G.-S.; Khan, F.S. Transformers in remote sensing: A survey. Remote Sens. 2023, 15, 1860. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs beat YOLOs on real-time object detection. arXiv 2023, arXiv:2304.08069. [Google Scholar]
- Zhang, T.; Zhang, X.; Li, J.; Xu, X.; Wang, B.; Zhan, X.; Xu, Y.; Ke, X.; Zeng, T.; Su, H.; et al. SAR ship detection dataset (SSDD): Official release and comprehensive data analysis. Remote Sens. 2021, 13, 3690. [Google Scholar] [CrossRef]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. HRSID: A high-resolution SAR images dataset for ship detection and instance segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Ke, X.; Zhan, X.; Shi, J.; Wei, S.; Pan, D.; Li, J.; Su, H.; Zhou, Y.; et al. LS-SSDD-v1.0: A deep learning dataset dedicated to small ship detection from large-scale Sentinel-1 SAR images. Remote Sens. 2020, 12, 2997. [Google Scholar] [CrossRef]
- Kanopoulos, N.; Vasanthavada, N.; Baker, R.L. Design of an image edge detection filter using the Sobel operator. IEEE J. Solid-State Circuits 1988, 23, 358–367. [Google Scholar] [CrossRef]
- Liu, H.; Jezek, K.C. Automated extraction of coastline from satellite imagery by integrating Canny edge detection and locally adaptive thresholding methods. Int. J. Remote Sens. 2004, 25, 937–958. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. arXiv 2016, arXiv:1608.06993. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. NAS-FPN: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7036–7045. [Google Scholar]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7373–7382. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, j.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural Info Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. TOOD: Task-aligned one-stage object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3490–3499. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16×16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. DINO: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Zhang, S.; Wang, X.; Wang, J.; Pang, J.; Lyu, C.; Zhang, W.; Luo, P.; Chen, K. Dense distinct query for end-to-end object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7329–7338. [Google Scholar]
- Lyu, C.; Zhang, W.; Huang, H.; Zhou, Y.; Wang, Y.; Liu, Y.; Zhang, S.; Chen, K. RTMDet: An empirical study of designing real-time object detectors. arXiv 2022, arXiv:2212.07784. [Google Scholar]
- Zhang, T.; Zhang, X.; Ke, X. Quad-FPN: A novel quad feature pyramid network for SAR ship detection. Remote Sens. 2021, 13, 2771. [Google Scholar] [CrossRef]
- Sun, Z.; Leng, X.; Lei, Y.; Xiong, B.; Ji, K.; Kuang, G. BiFA-YOLO: A novel YOLO-based method for arbitrary-oriented ship detection in high-resolution SAR images. Remote Sens. 2021, 13, 4209. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Liu, C.; Shi, J.; Wei, S.; Ahmad, I.; Zhan, X.; Zhou, Y.; Pan, D.; Li, J.; et al. Balance learning for ship detection from synthetic aperture radar remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 182, 190–207. [Google Scholar] [CrossRef]
- Shi, H.; Fang, Z.; Wang, Y.; Chen, L. An adaptive sample assignment strategy based on feature enhancement for ship detection in SAR images. Remote Sens. 2022, 14, 2238. [Google Scholar] [CrossRef]
- Li, X.; Li, D.; Liu, H.; Wan, J.; Chen, Z.; Liu, Q. A-BFPN: An attention-guided balanced feature pyramid network for SAR ship detection. Remote Sens. 2022, 14, 3829. [Google Scholar] [CrossRef]
- Yang, S.; An, W.; Li, S.; Zhang, S.; Zou, B. An inshore SAR ship detection method based on ghost feature extraction and cross-scale interaction. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Huang, M.; Liu, T.; Chen, Y. CViTF-Net: A convolutional and visual transformer fusion network for small ship target detection in synthetic aperture radar images. Remote Sens. 2023, 15, 4373. [Google Scholar] [CrossRef]
- Qiao, C.; Shen, F.; Wang, X.; Wang, R.; Cao, F.; Zhao, S.; Li, C. A novel multi-frequency coordinated module for SAR ship detection. In Proceedings of the 2022 IEEE 34th International Conference on Tools with Artificial Intelligence (ICTAI), Macao, China, 31 October–2 November 2022; pp. 804–811. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Jocher, G. YOLOv5 by Ultralytics; Version 7.0; Ultralytics: Frederick, MD, USA, 2020. [Google Scholar] [CrossRef]
- Yu, C.S.; Shin, Y. SAR ship detection based on improved YOLOv5 and BiFPN. ICT Express 2024, 10, 28–33. [Google Scholar] [CrossRef]
- Solawetz, J. What Is YOLOv8? The Ultimate Guide. 2023. Available online: https://blog.roboflow.com/whats-new-in-yolov8/ (accessed on 18 December 2023).
- Yu, C.; Shin, Y. An efficient YOLO for ship detection in SAR images via channel shuffled reparameterized convolution blocks and dynamic head. ICT Express 2024, 10, 673–679. [Google Scholar] [CrossRef]
- Yasir, M.; Liu, S.; Pirasteh, S.; Xu, M.; Sheng, H.; Wan, J.; de Figueiredo, F.A.; Aguilar, F.J.; Li, J. YOLOShipTracker: Tracking ships in SAR images using lightweight YOLOv8. Int. J. Appl. Earth Obs. Geoinf. 2024, 134, 104137. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Dumoulin, V.; Visin, F. A guide to convolution arithmetic for deep learning. arXiv 2016, arXiv:1603.07285. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. Mmdetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Details | SSDD | HRSID | LS-SSDD-v1.0 |
|---|---|---|---|
| Sources | RadarSat-2, TerraSAR-X, Sentinel-1 | Sentinel-1, TerraSAR-X, TanDem | Sentinel-1 |
| Polarization | HH, HV, VV, VH | HH, HV, VV | VV, VH |
| Resolution (m) | 1∼15 | 0.5, 1, 3 | 5 × 20 |
| Image Size | 217 × 214∼526 × 646 | 800 × 800 | 24,000 × 16,000 |
| Image Numbers | 1160 | 5604 | 15 |
| Ships | 2456 | 16,961 | 6015 |
| Method | Entire Scenes | Inshore Scenes | Offshore Scenes | Param (M) | FLOPs (G) | FPS | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | mAP | F1 | P | R | mAP | F1 | P | R | mAP | F1 | ||||
| Faster R-CNN [10] | 94.8 | 87.7 | 93.8 | 91.1 | 88.2 | 71.5 | 80.8 | 79.0 | 97.0 | 95.7 | 98.1 | 96.3 | 41.35 | 179.0 | 22.8 |
| Cascade R-CNN [11] | 95.5 | 88.8 | 94.9 | 92.0 | 86.9 | 73.0 | 82.2 | 79.3 | 98.4 | 96.7 | 98.8 | 97.5 | 69.15 | 207.0 | 16.5 |
| GFL [30] | 88.3 | 80.5 | 85.1 | 84.2 | 70.2 | 57.0 | 60.6 | 62.9 | 93.5 | 92.4 | 94.4 | 92.9 | 32.26 | 176.0 | 21.7 |
| YOLOX [31] | 89.0 | 87.2 | 90.5 | 88.1 | 73.5 | 72.7 | 72.4 | 73.1 | 96.0 | 94.7 | 97.3 | 95.3 | 5.03 | 7.6 | 84.2 |
| TOOD [32] | 92.0 | 92.5 | 95.0 | 92.2 | 82.2 | 83.1 | 85.2 | 82.6 | 97.1 | 96.8 | 98.2 | 96.9 | 32.02 | 170.0 | 17.5 |
| Deformable DETR [34] | 83.1 | 80.8 | 85.9 | 81.9 | 72.0 | 67.4 | 70.1 | 69.6 | 85.4 | 89.6 | 92.1 | 87.4 | 40.10 | 167.0 | 25.3 |
| DINO [35] | 88.6 | 70.5 | 84.6 | 78.5 | 68.0 | 57.6 | 66.7 | 62.4 | 89.3 | 82.5 | 91.6 | 85.8 | 47.54 | 238.0 | 11.2 |
| DDQ-DETR [36] | 91.1 | 82.6 | 89.8 | 86.6 | 81.4 | 62.8 | 74.4 | 70.9 | 95.1 | 91.4 | 95.0 | 93.2 | 48.27 | 203.4 | 18.4 |
| RTMDet-Tiny [37] | 94.9 | 88.9 | 93.3 | 91.8 | 91.9 | 74.4 | 83.5 | 82.2 | 97.4 | 95.5 | 97.5 | 96.4 | 4.87 | 8.0 | 74.3 |
| YOLOv5n [47] | 93.7 | 94.3 | 97.2 | 94.0 | 89.7 | 86.2 | 92.6 | 87.9 | 96.6 | 98.4 | 98.8 | 97.5 | 2.50 | 7.1 | 330.3 |
| YOLOv8n [49] | 94.8 | 93.2 | 98.1 | 94.0 | 85.9 | 84.9 | 93.4 | 85.4 | 98.1 | 98.2 | 99.3 | 98.1 | 3.01 | 8.1 | 340.9 |
| YOLOv10n [55] | 92.1 | 92.3 | 96.8 | 92.2 | 86.5 | 81.7 | 90.5 | 84.0 | 94.3 | 96.7 | 98.6 | 95.5 | 2.27 | 6.5 | 261.5 |
| RT-DETR [16] | 95.2 | 93.8 | 97.2 | 94.5 | 90.3 | 86.0 | 92.6 | 88.1 | 98.0 | 97.6 | 98.4 | 97.8 | 19.87 | 56.9 | 174.3 |
| SMEP-DETR | 96.5 | 95.6 | 98.6 | 96.0 | 91.6 | 90.7 | 96.4 | 91.1 | 97.9 | 97.9 | 99.4 | 97.9 | 21.11 | 60.7 | 50.6 |
| Method | Entire Scenes | Inshore Scenes | Offshore Scenes | Param (M) | FLOPs (G) | FPS | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | mAP | F1 | P | R | mAP | F1 | P | R | mAP | F1 | ||||
| Faster R-CNN [10] | 90.0 | 76.5 | 85.8 | 82.7 | 77.8 | 57.3 | 66.4 | 66.0 | 97.8 | 95.7 | 98.3 | 96.7 | 41.35 | 134.0 | 27.1 |
| Cascade R-CNN [11] | 91.7 | 77.6 | 87.5 | 84.1 | 75.7 | 63.1 | 70.3 | 68.8 | 97.9 | 96.6 | 98.7 | 97.2 | 69.15 | 162.0 | 23.0 |
| GFL [30] | 89.1 | 74.4 | 83.2 | 81.1 | 69.9 | 57.3 | 61.8 | 63.0 | 98.2 | 95.5 | 98.6 | 96.8 | 32.26 | 128.0 | 31.7 |
| YOLOX [31] | 92.3 | 82.6 | 90.8 | 87.2 | 81.3 | 71.1 | 79.0 | 75.8 | 98.7 | 97.0 | 99.0 | 97.8 | 5.03 | 7.6 | 81.1 |
| TOOD [32] | 89.7 | 77.2 | 85.5 | 83.0 | 74.6 | 61.0 | 67.3 | 67.1 | 98.1 | 95.5 | 98.3 | 96.8 | 32.02 | 123.0 | 21.8 |
| Deformable DETR [34] | 90.1 | 74.5 | 82.2 | 81.6 | 77.2 | 56.9 | 63.6 | 65.5 | 97.1 | 95.9 | 98.3 | 96.5 | 40.10 | 158.5 | 43.5 |
| DINO [35] | 90.8 | 74.9 | 86.4 | 82.1 | 73.0 | 59.5 | 68.6 | 65.6 | 97.6 | 95.2 | 98.3 | 96.4 | 47.54 | 179.0 | 18.1 |
| DDQ-DETR [36] | 91.4 | 79.2 | 87.8 | 84.9 | 78.6 | 65.2 | 73.7 | 71.3 | 97.9 | 96.5 | 98.6 | 97.2 | 48.27 | 203.4 | 27.8 |
| RTMDet-Tiny [37] | 90.1 | 77.9 | 85.5 | 83.5 | 76.6 | 63.4 | 70.2 | 69.4 | 98.0 | 94.7 | 97.5 | 96.3 | 4.87 | 8.0 | 61.7 |
| YOLOv5n [47] | 89.8 | 78.5 | 87.6 | 83.8 | 77.6 | 63.0 | 71.6 | 69.5 | 97.6 | 93.9 | 98.2 | 95.7 | 2.50 | 7.1 | 537.5 |
| YOLOv8n [49] | 89.5 | 80.6 | 89.0 | 84.8 | 75.8 | 68.7 | 74.1 | 72.1 | 96.6 | 95.3 | 98.6 | 95.9 | 3.01 | 8.1 | 595.8 |
| YOLOv10n [55] | 89.9 | 76.3 | 87.5 | 82.5 | 75.4 | 60.8 | 71.1 | 67.3 | 97.1 | 93.1 | 98.0 | 95.0 | 2.27 | 6.5 | 417.8 |
| RT-DETR [16] | 92.9 | 84.6 | 92.2 | 88.5 | 83.8 | 73.3 | 81.3 | 78.2 | 98.5 | 96.8 | 99.2 | 97.6 | 19.87 | 56.9 | 174.8 |
| SMEP-DETR | 92.7 | 86.5 | 93.2 | 89.5 | 84.1 | 77.5 | 83.7 | 80.7 | 98.3 | 97.3 | 99.2 | 97.8 | 21.11 | 60.7 | 49.9 |
| Method | Entire Scenes | Inshore Scenes | Offshore Scenes | Param (M) | FLOPs (G) | FPS | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | mAP | F1 | P | R | mAP | F1 | P | R | mAP | F1 | ||||
| Faster R-CNN [10] | 86.0 | 63.8 | 75.5 | 73.3 | 60.9 | 37.4 | 47.1 | 46.3 | 89.4 | 82.9 | 88.9 | 86.0 | 41.35 | 134.0 | 24.2 |
| Cascade R-CNN [11] | 84.0 | 71.4 | 80.6 | 77.2 | 67.4 | 43.9 | 54.5 | 53.2 | 90.8 | 87.4 | 92.1 | 89.1 | 69.15 | 162.0 | 19.0 |
| GFL [30] | 83.7 | 68.7 | 74.4 | 75.5 | 62.1 | 41.3 | 43.9 | 49.6 | 89.4 | 86.7 | 89.3 | 88.0 | 32.26 | 128.0 | 50.9 |
| YOLOX [31] | 84.0 | 74.0 | 79.1 | 78.7 | 66.2 | 51.7 | 55.1 | 58.1 | 89.0 | 89.2 | 91.2 | 89.1 | 5.03 | 7.6 | 230.3 |
| TOOD [32] | 84.0 | 65.3 | 70.5 | 73.5 | 57.3 | 40.3 | 41.2 | 47.3 | 89.0 | 83.6 | 86.0 | 86.2 | 32.02 | 123.0 | 22.6 |
| Deformable DETR [34] | 80.2 | 66.7 | 71.2 | 72.8 | 58.5 | 40.7 | 39.9 | 48.0 | 89.0 | 82.6 | 87.3 | 85.7 | 40.10 | 158.5 | 47.8 |
| DINO [35] | 75.1 | 63.2 | 67.5 | 68.6 | 54.4 | 39.6 | 38.0 | 45.8 | 82.0 | 78.4 | 82.8 | 80.1 | 47.54 | 179.0 | 17.5 |
| DDQ-DETR [36] | 83.6 | 70.3 | 75.8 | 76.4 | 60.0 | 45.6 | 47.9 | 51.8 | 90.0 | 86.9 | 90.1 | 88.4 | 48.27 | 203.4 | 27.7 |
| RTMDet-Tiny [37] | 80.1 | 62.3 | 72.5 | 70.1 | 62.4 | 45.2 | 49.5 | 52.4 | 87.8 | 76.3 | 86.1 | 81.6 | 4.87 | 8.0 | 167.7 |
| YOLOv5n [47] | 83.9 | 67.8 | 75.1 | 75.0 | 59.5 | 44.3 | 47.0 | 50.8 | 88.1 | 85.6 | 89.9 | 86.8 | 2.50 | 7.1 | 296.7 |
| YOLOv8n [49] | 83.9 | 67.0 | 75.4 | 74.5 | 66.8 | 43.5 | 50.5 | 52.7 | 88.6 | 84.5 | 89.4 | 86.5 | 3.01 | 8.1 | 306.0 |
| YOLOv10n [55] | 78.8 | 65.7 | 73.7 | 71.7 | 60.5 | 44.7 | 47.5 | 51.4 | 84.7 | 79.6 | 87.2 | 82.1 | 2.27 | 6.5 | 250.3 |
| RT-DETR [16] | 85.3 | 73.0 | 79.2 | 78.7 | 66.4 | 49.8 | 55.6 | 56.9 | 88.7 | 88.9 | 90.4 | 88.8 | 19.87 | 56.9 | 174.8 |
| SMEP-DETR | 88.2 | 72.9 | 80.0 | 80.1 | 71.9 | 48.9 | 56.8 | 58.2 | 92.0 | 88.4 | 91.1 | 90.2 | 21.11 | 60.7 | 48.7 |
| Method | Entire Scenes | Inshore Scenes | Offshore Scenes | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | mAP | mAP50:95 | P | R | mAP | mAP50:95 | P | R | mAP | mAP50:95 | ||
| RT-DETR (Baseline) | 95.2 | 93.8 | 97.2 | 68.3 | 90.3 | 86.0 | 92.6 | 59.8 | 98.0 | 97.6 | 98.4 | 71.7 | |
| Speckle Denoising | +GaBiFilter | 95.5 | 93.9 | 98.3 | 71.9 | 94.9 | 85.8 | 96.2 | 68.0 | 98.1 | 96.3 | 98.6 | 74.0 |
| +LeeFilter | 96.0 | 94.1 | 97.6 | 69.4 | 87.3 | 88.3 | 93.4 | 60.5 | 98.7 | 98.0 | 99.0 | 72.9 | |
| MEIE Module | +AveragePool | 97.4 | 94.0 | 98.4 | 69.3 | 95.5 | 84.3 | 94.4 | 60.3 | 98.4 | 98.7 | 99.3 | 73.0 |
| +MaxPool | 95.2 | 93.8 | 98.4 | 72.1 | 86.4 | 88.8 | 94.7 | 66.5 | 99.0 | 97.3 | 99.2 | 74.3 | |
| Feature Fusion | +RepC3-APN | 96.1 | 93.4 | 97.9 | 72.9 | 86.3 | 91.5 | 93.8 | 67.9 | 97.2 | 98.7 | 99.3 | 74.6 |
| +PDC-APN | 96.3 | 94.1 | 98.2 | 71.2 | 91.5 | 89.5 | 95.1 | 66.1 | 97.4 | 98.6 | 99.2 | 73.4 | |
| SMEP-DETR (Ours) | 96.5 | 95.6 | 98.6 | 72.2 | 91.6 | 90.7 | 96.4 | 68.6 | 97.9 | 97.9 | 99.4 | 74.5 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, C.; Shin, Y. SMEP-DETR: Transformer-Based Ship Detection for SAR Imagery with Multi-Edge Enhancement and Parallel Dilated Convolutions. Remote Sens. 2025, 17, 953. https://doi.org/10.3390/rs17060953
Yu C, Shin Y. SMEP-DETR: Transformer-Based Ship Detection for SAR Imagery with Multi-Edge Enhancement and Parallel Dilated Convolutions. Remote Sensing. 2025; 17(6):953. https://doi.org/10.3390/rs17060953
Chicago/Turabian StyleYu, Chushi, and Yoan Shin. 2025. "SMEP-DETR: Transformer-Based Ship Detection for SAR Imagery with Multi-Edge Enhancement and Parallel Dilated Convolutions" Remote Sensing 17, no. 6: 953. https://doi.org/10.3390/rs17060953
APA StyleYu, C., & Shin, Y. (2025). SMEP-DETR: Transformer-Based Ship Detection for SAR Imagery with Multi-Edge Enhancement and Parallel Dilated Convolutions. Remote Sensing, 17(6), 953. https://doi.org/10.3390/rs17060953