Abstract
The deployment of landslide intelligent recognition models in non-training regions encounters substantial challenges, primarily attributed to heterogeneous remote sensing acquisition parameters and inherent geospatial variability in factors such as topography, vegetation cover, and soil characteristics across distinct geographic zones. Addressing the issue of underutilization of landslide contextual information and morphological integrity in domain adaptation methods, this paper introduces a cross-domain landslide extraction approach that integrates image masking with enhanced morphological information. Specifically, our approach implements a pixel-level mask on target domain imagery, facilitating the utilization of context information from the masked images. Furthermore, it establishes a morphological information extraction module, grounded in predefined thresholds and rules, to produce morphological pseudo-labels for the target domain. The results demonstrate that our method achieves an IoU (intersection over union) improvement of 1.78% and 6.02% over the suboptimal method in two cross-domain tasks, respectively, and a remarkable performance enhancement of 33.13% and 31.79% compared to scenarios without domain adaptation. This cross-domain extraction method not only substantially boosts the accuracy of cross-domain landslide identification but also enhances the completeness of landslide morphology information, offering robust technical support for landslide disaster monitoring and early warning systems.
1. Introduction
In recent years, the risk and scale of landslide hazards have escalated due to intensifying global climate change and rapid urban expansion [1]. Natural factors, including earthquakes, volcanic eruptions, and heavy rainfall, alongside human activities such as mining and road construction [2], frequently disrupt the structural integrity of geomaterials on steep slopes. As a result, these bodies are susceptible to gravitational movement, culminating in landslide events. Consequently, landslide-prone areas cluster in steep, mountainous/hilly terrains [3]. Accurate identification of landslides is crucial for disaster prevention and control, as well as for assessing disaster-related damage.
Rapid advancements in remote sensing sensor technology have dramatically enhanced the spatial and temporal resolution of satellite imagery. Due to its wide coverage, timeliness, and distinct ability to identify landslides in remote areas [4,5,6], remote sensing has demonstrated substantial potential in monitoring and identifying landslides. Meanwhile, the rapid development of computing technology provides technical support for efficient large-scale monitoring of large-scale landslides [7]. The determination of whether an area is affected by a landslide, based on the pixel values of remote sensing images as features, can be primarily classified into supervised and unsupervised methods. Unsupervised methods such as K-means [8] and ISODATA [9] do not require prior labeling of samples. However, the classification accuracy of these methods is relatively low, and the clustering results often require further manual verification to identify the landslide area [10]. Supervised classification methods, relying on the spectral features of individual pixels, distinguish landslides from non-landslide areas using classifiers like Support Vector Machines [11], random forests [12], and artificial neural networks [13]. Yet these methods neglect other attribute information and contextual information, such as shape, texture, and spatial relationships, and are vulnerable to noise and parameter settings, resulting in limited recognition accuracy. To address these limitations, object-oriented methods [14,15,16,17] have been introduced into the field of remotely sensed landslide identification. While object-oriented methods improve landslide segmentation accuracy to some extent, they rely heavily on segmentation algorithms and can be inefficient when dealing with complex images [18,19]. Compared with traditional machine learning methods, the Convolutional Neural Network (CNN) framework has demonstrated superior ability to utilize the comprehensive information embedded in remote sensing images [20,21,22]. Through its hierarchical architecture, the CNN approach effectively extracts high-level features from the imagery, thereby enabling accurate landslide identification [23,24,25,26,27]. It is noteworthy that detection accuracy is predominantly contingent upon the computational capabilities and architectural sophistication of the implemented deep learning models [28]. Consequently, the integration of advanced computational models [29], innovative methodologies [30,31], and multi-source data fusion [32] has emerged as a pivotal strategy for enhancing landslide detection accuracy. In addition, the Transformer architecture provides robust performance in landslide detection applications [22], significantly improving the efficiency and accuracy of rapid landslide detection [33,34]. Another report shows that the enhanced SegFormer implementation outperforms traditional CNN-based approaches in seismic landslide identification [35].
In summary, while existing studies have demonstrated effective landslide recognition within single domains, several critical limitations persist, including heavy reliance on abundant training datasets and single forms of dataset [36,37]. Given that landslides predominantly occur in mountainous and geographically complex regions, the collection of representative training samples is severely constrained [38], resulting in limited generalization capability of recognition models. When substantial discrepancies exist between training and testing domains, deep learning models often fail to accurately characterize features in unseen regions, significantly degrading their practical performance [39]. Consequently, the effective utilization of limited labeled data and the achievement of cross-domain landslide extraction across diverse geographic regions have emerged as the primary challenges in landslide recognition research. Unsupervised Domain Adaptation (UDA) techniques address this challenge by leveraging labeled source domain data and unlabeled target domain data to minimize inter-domain distribution gaps, thereby enhancing model performance in target environments [40,41]. Several studies have implemented convolutional neural network optimization strategies to align content features with style features, achieving source–target image statistical matching [42,43]. In cross-domain landslide recognition tasks, the inherent limitations in data completeness, particularly the scarcity of reliably labeled landslide samples in target regions, have prompted researchers to explore UDA-based approaches. Several innovative methodologies have been developed: Li et al. [44] integrated adversarial learning with domain distance minimization for cross-scene landslide detection in high-resolution imagery; Zhang et al. [45] implemented prototype learning to generate pseudo-labels for progressive feature alignment; Xu et al. [46] developed an adversarial domain adaptation network that fuses geological features with remote sensing data for cross-domain landslide extraction; and Li et al. [47] introduced a progressive label upgrading and cross-temporal style adaptation method for multi-temporal landslide detection and domain feature alignment. However, current UDA methods exhibit two key limitations:(1) over-emphasis on source–target domain feature alignment and under-utilization of target domain contextual information (e.g., topographic and geologic features); and (2) insufficient handling of landslide morphology complexity, especially in preserving boundary details due to over-reliance on global feature similarity. Given that landslide occurrence is significantly influenced by environmental factors, reliance on isolated pixel-level or object-level features often leads to misclassification (e.g., confusion between landslides and bare rock formations). These limitations manifest as insufficient utilization of contextual information and inadequate incorporation of background knowledge in the target domain. To address these challenges, this study proposes a novel framework incorporating masked image modeling principles [48,49], specifically enhancing context learning [50] through target domain image masking within domain adaptation tasks, thereby improving performance across both upstream and downstream processes. While existing landslide recognition methods primarily focus on classification through spectral, textural, and shape feature analysis of entire landslide regions, they frequently encounter boundary ambiguity issues caused by topographic noise and surrounding landform interference.
This study proposes an unsupervised cross-domain landslide extraction framework that integrates image mask and morphological information enhancement to address the limitations of current domain adaptation methods in contextual information utilization and morphological completeness. The proposed methodology employs a knowledge distillation strategy. The teacher network generates pseudo-labels from complete target domain images, while the student model is trained to produce consistent predictions using randomly masked target domain images. This bidirectional learning process facilitates continuous improvement in pseudo-label quality through iterative context information exchange between the teacher and student models. The morphological information enhancement module leverages the distinct spectral characteristics (brightness/color contrast) between landslide regions and their surrounding environments to extract morphological features, which are subsequently transformed into morphological pseudo-labels. These pseudo-labels guide the student model in learning comprehensive landslide morphological patterns. The synergistic integration of enhanced contextual information utilization and explicit morphological feature incorporation ultimately improves the accuracy and robustness of cross-domain landslide extraction.
The contributions of this study are threefold: (1) the development of an unsupervised cross-domain landslide extraction framework integrating image mask and morphological information enhancement is achieved; (2) a novel mask module is designed, which significantly enhances the model’s ability to learn contextual information; (3) a cross-domain morphological information enhancement module is designed, which dramatically improves the accuracy of landslide morphology recognition.
2. Methodology
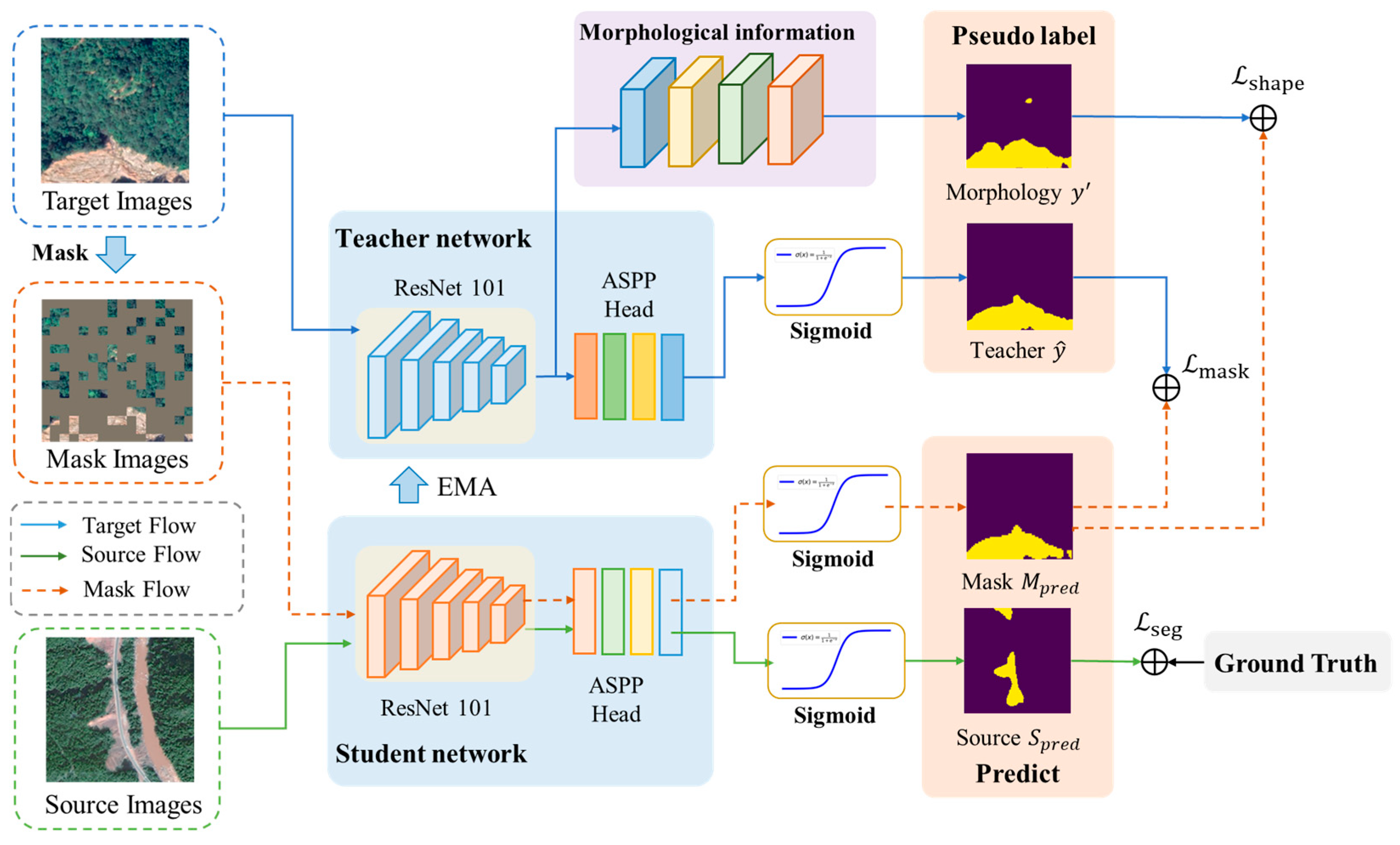
Aiming to solve the problems of insufficient utilization of context information in the target domain and incomplete characterization of landslide morphology in current landslide extraction methods, this study proposes an unsupervised cross-domain landslide extraction framework integrating an image mask and morphological information enhancement. The proposed framework comprises two core modules: (1) an image mask module and (2) a morphological information extraction and optimization module. The methodology operates through a dual-model architecture: complete target domain images are processed by a teacher model to generate pseudo-labels, while randomly masked versions of these images are fed into a student model. The student model is constrained to produce predictions consistent with the teacher-generated pseudo-labels, thereby enhancing its capacity to leverage contextual information from partially obscured inputs. This contextual learning capability is subsequently transferred to the teacher model through exponential moving average (EMA) parameter updates. Furthermore, the morphological information enhancement module analyzes target domain imagery to derive landslide morphological characteristics which are transformed into morphological pseudo-labels. These pseudo-labels guide the student model in learning comprehensive landslide morphological features. The overall architecture of the proposed framework is illustrated in Figure 1.
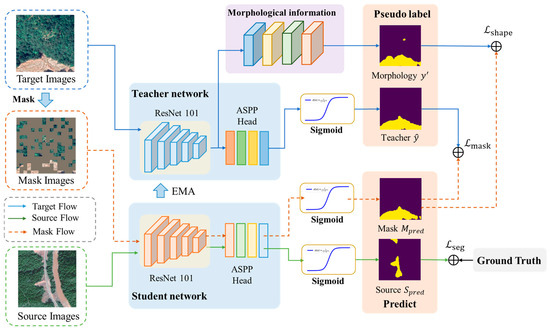
Figure 1.
Technical framework of IMMDA methodology.
2.1. Image Mask Based on Random Sampling
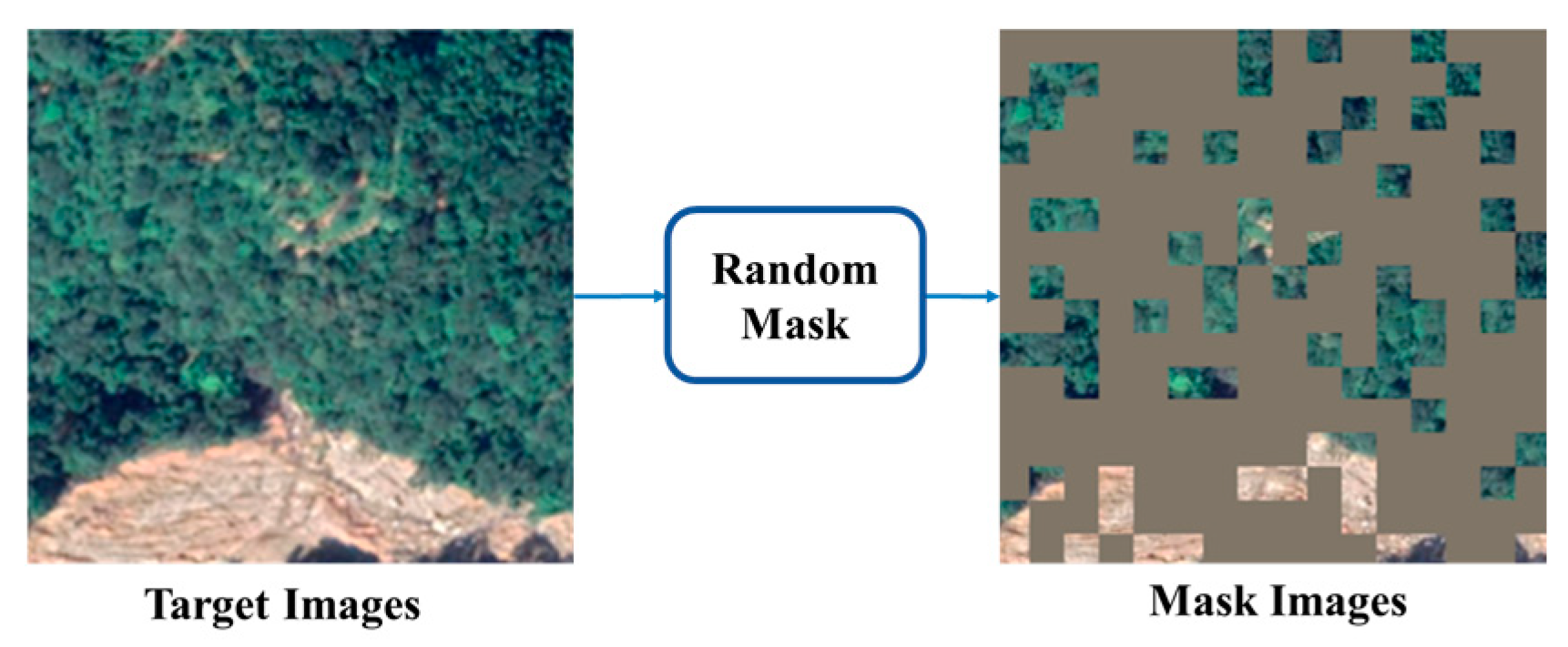
To enhance the utilization of contextual information in target domain images, this module incorporates principles from the mask language model [49] in natural language processing. Specifically, it employs a mask strategy where portions of the target domain image are obscured, requiring the model to predict pixel values for these masked regions. This approach facilitates the learning of robust feature representations by leveraging rich contextual relationships within the image data and is more suitable for cross-domain tasks [51,52]. The mask process is implemented through random sampling of image patches, preventing over-reliance on local features and simulating a real-world mask, where the mask for each patch is generated according to a uniform distribution, as defined by the following formulation:
where denotes the Iverson bracket, denotes the patch size, denotes the mask ratio, and [0 .. W/b − 1] and n ∈ [0 .. W/b − 1] denote the patch index. The mask target image (see Figure 1) is obtained by element-wise multiplication of the mask and image. The specific process is shown in Figure 2.
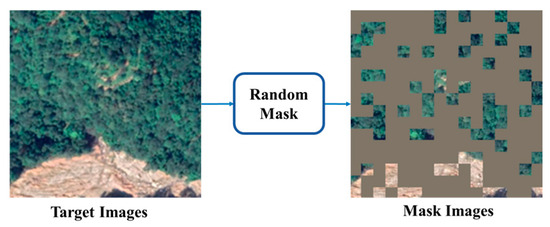
Figure 2.
Image mask flowchart.
Following the image masking process, an exponential moving average (EMA) strategy is employed to update the teacher model () using parameters from the student model (). The teacher model subsequently generates pseudo-labels from target domain images which are used to supervise the student model’s predictions. This framework trains to predict comprehensive semantic segmentation results, including masked regions, by processing randomly obscured target domain images. To accurately reconstruct semantics in masked areas, must infer missing information based on contextual relationships encoded in the teacher-generated pseudo-labels. Through this iterative process, develops enhanced capabilities for representing target domain contextual information. Simultaneously, parameter updates enable to progressively extract more comprehensive contextual clues from target domain images, resulting in higher-confidence pseudo-labels. Notably, the proposed image masking module diverges from conventional image recovery objectives; instead, it utilizes teacher model pseudo-labels to guide the student model in learning contextual relationships within masked images. This design prevents the acquisition of erroneous image features that might otherwise result from incomplete image content during training.
2.2. Morphological Information Extraction Based on Threshold and Rule
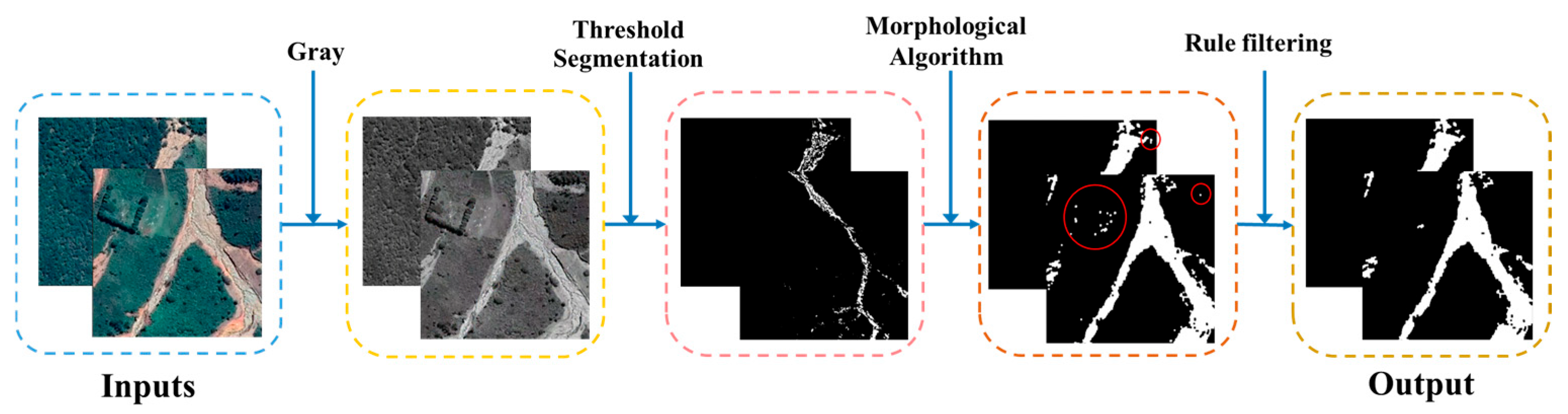
Leveraging prior knowledge of landslide pixel intensity characteristics in remote sensing imagery, the proposed methodology implements threshold segmentation based on the distinct brightness and color contrast between landslide regions and their surrounding environments. This process is further refined through rule-based filtering to eliminate non-landslide elements, thereby optimizing segmentation accuracy. The workflow of the morphological information extraction and optimization module is illustrated in Figure 3. The module operates through the following computational pipeline: For a given target domain image , an adaptive threshold parameter is initialized to represent the range of landslide pixel values in the grayscale intensity space. The parameter is not manually preset but learned during model training. It is initialized based on the empirical distribution of landslide/non-landslide pixel intensities and optimized by back propagation through the morphological consistency loss function. Pixels within this threshold range are extracted to generate a binary segmentation mask. Subsequent morphological processing employs dilation and closure operations to address image imperfections by filling interior holes and smoothing boundary edges. To enhance segmentation precision, two morphological rules are implemented: (1) Area rule establishes a minimum area threshold to eliminate small-area noise. For the minimum area threshold, the minimum value of the source domain is 88.5 square meters obtained after the source domain data statistics, because the minimum landslide threshold is set to 80 square meters in this paper. (2) Shape rule calculates the aspect ratio of candidate regions using bounding box analysis, effectively removing linear features such as roads. By reviewing the highway route design specification standards and studies [53,54] related to the calculation of the aspect ratio of landslides, the aspect ratio of straight sections (50:1 to 100:1) and curved sections can be calculated (10:1 to 30:1). And we calculated the landslide labels in the source domain and found that the aspect ratios were distributed between 0.26 and 3.60, so the threshold of the aspect ratio was set to 10:1. These operations yield an optimized morphological information map . Finally, the morphological-enhanced pseudo-label is generated by computing the union of and the teacher model’s initial pseudo-label , producing a refined output that incorporates both spectral and morphological characteristics.
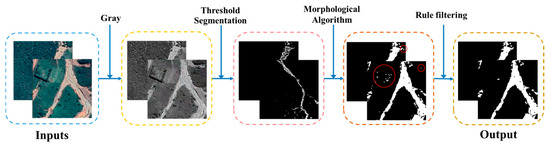
Figure 3.
Schematic diagram of morphological information extraction (Red circles in Figure represent screened non-landslide areas).
2.3. Mask Morphology Loss Functions
The proposed IMMDA framework incorporates three specialized loss functions to optimize model performance: cross-domain pseudo-label loss, mask consistency loss, and shape consistency loss. The cross-domain pseudo-label loss, implemented through self-supervised learning, minimizes distributional discrepancies between source and target domains by leveraging generated pseudo-labels from the target domain. The mask consistency loss enhances the model’s ability to learn contextual relationships within target domain data through the processing of masked images. Complementing these, the shape consistency loss facilitates unsupervised learning of landslide morphological representations from target domain data, utilizing extracted morphological information to improve feature characterization.
- Cross-domain loss function
The cross-domain loss function proposed in this study comprises two components: semantic segmentation loss () and pseudo-label loss (). ensures the model’s effectiveness when trained on source domain images and their corresponding labels, guaranteeing accurate learning of landslide semantic information. For the specific task of landslide recognition, is formulated as a binary cross-entropy loss function, which is computed for each image as follows:
where represents the total number of pixels, denotes the ground truth label for pixel , and corresponds to the predicted probability for pixel .
The pseudo-label loss quantifies the discrepancy between the pseudo-labels generated by the teacher model and the predictions of the student model, thereby enhancing the student model’s performance in the target domain. This loss is computed using a weighted binary cross-entropy formulation, expressed as follows:
where denotes the total number of pixels, and for each pixel , represents the generated pseudo-label, denotes the confidence weight of the pseudo-label, and corresponds to the model’s predicted probability.
- 2.
- Mask Consistency Loss Function
The mask consistency loss enhances domain adaptation by selectively masking a region of the image and enforcing consistency between the student model’s predictions in the masked area and the corresponding pseudo-labels. This process strengthens the model’s ability to capture contextual relationships within the target domain data. The loss is computed using the following formulation:
where denotes the data distribution of the target domain, represents the student model, corresponds to the masked target domain image, is the pseudo-label generated by the teacher model from the unmasked target domain image, denotes the cross-entropy loss function, and represents the confidence weight of the pseudo-label.
- 3.
- Morphological consistency loss function
To enhance the model’s capability in capturing morphological features, we introduce the morphological consistency loss, which computes the cross-entropy loss between the morphological pseudo-label and the mask predictions generated by the teacher model. By incorporating morphological information to guide the student model’s predictions, this loss facilitates the learning of landslide morphology and improves the completeness of landslide identification. The loss is formulated as follows:
where represents the data distribution of the target domain, denotes the prediction output of the student model for the target domain image, is the pseudo-label generated by the teacher model, and denotes the cross-entropy loss function.
3. Results
3.1. Experimental Setting
To evaluate the generalization capability of the proposed cross-domain landslide extraction method and assess the effectiveness of the image masking and morphological information extraction modules, a series of experiments are conducted. These include a comparison of domain adaptation methods, computational efficiency analysis, and module effectiveness analysis. The domain adaptation comparison experiment evaluates the proposed IMMDA method against four advanced domain adaptation semantic segmentation methods: FADA [55], DACS [56], HRDA [57], and DAFormer [58]. The models are tested on two distinct target domains to validate the effectiveness of the proposed approach through both quantitative accuracy metrics and qualitative recognition results. The computational efficiency analysis examines the parameter count, training time, and computational efficiency of the domain adaptation model to assess its computational cost. The module effectiveness analysis employs ablation experiments to systematically evaluate the contributions of the image mask and morphological information extraction modules by controlling variables. For these experiments, due to the vastness and topographic diversity of the DMLD [59] dataset which is the source domain and the regional diversity of the GVLM [45] dataset, Jiuzhaigou and Chimanimani as the target domains are used to test the proposed method.
In this study, the F1-Score, accuracy, recall, and intersection over union (IoU), computed based on the confusion matrix, are selected as evaluation metrics to assess model performance. According to the comparison between model predictions and ground truth labels, classification results are categorized into four groups: true positive (TP): the actual label is positive and the model correctly predicts it as positive; false negative (FN): the actual label is positive, but the model incorrectly predicts it as negative; false positive (FP): the actual label is negative, but the model incorrectly predicts it as positive; true negative (TN): the actual label is negative, and the model correctly predicts it as negative.
Precision, also referred to as checking accuracy, is the proportion of samples predicted by the model as positive that are truly in the positive category. It indicates the model’s accuracy in predicting positive instances. The formula for calculating precision is as follows:
Recall is the proportion of all samples that are truly positive and correctly predicted as positive by the model. It measures the model’s ability to identify positive instances. The formula for calculating recall is as follows:
To account for both precision and recall, the F1-Score is commonly used. It represents the harmonic mean of precision and recall, providing a balanced evaluation of the model’s overall performance. A higher F1-Score indicates a more balanced performance between precision and recall. The formula for calculating the F1-Score is as follows:
The intersection over union (IoU) is the ratio of the intersection and union between the predicted region and the ground truth region. It is used to assess the degree of overlap between the model’s predictions and the actual annotations, serving as a key metric to evaluate the performance of image segmentation models. The formula for calculating the intersection over union is as follows:
The method proposed in this paper is implemented using PyTorch with the MMSegmentation framework. Both the teacher and student models utilize DeepLabV3+ with a ResNet-101 backbone. During training, the input images are three-channel remote sensing images of size 512 × 512, with a batch size set to 2. The weights for the mask consistency loss (Equation (4)) and morphological consistency loss (Equation (5)) in the total loss function are both set to 1. The AdamW optimizer is employed with a learning rate of 0.0001, a weight decay of 0.01, and a total of 20,000 iterations. In the image mask experiments, the mask block size is set to 64 × 64, with a mask ratio of 0.7. The experiments are conducted on a single NVIDIA GeForce RTX 2080 Ti GPU.
3.2. Data
The datasets used in this study include the DMLD dataset and the GVLM dataset. Table 1 presents statistical details of the DMLD dataset utilized in this paper, while Table 2 outlines the landslide hazard locations and remote sensing image area sizes selected from the GVLM dataset. The DMLD dataset is a high-resolution remote sensing dataset designed for the semantic segmentation of landslides. It is based on high-resolution remote sensing images taken before and after landslide disaster events (such as earthquakes, heavy precipitation, etc.) across various topographic regions in southwestern China. This dataset includes data from three major topographic regions and nineteen counties and cities. Landslide areas are obtained through change detection and manual labeling, containing a total of 490 landslide images, each of size 1000 × 1000 with a resolution of 1 m. These images include 990 landslides with an area larger than 5.79 km2. The DMLD dataset is selected as the source domain due to its inclusion of landslide samples from diverse topographic regions, providing a broad dataset that supports generalization to other regions and aids in improving the landslide extraction model’s performance. The GVLM dataset is another high-resolution remote sensing dataset for landslide semantic segmentation, with landslide areas identified based on change detection of Google imagery from before and after disaster events. The spatial resolution of this dataset is 0.59 m. As depicted in Figure 4, the GVLM dataset includes landslide events from various global regions with significant geographic diversity. It is suitable as a target domain for testing cross-domain landslide extraction models. Figure 4 shows some example landslide image samples along with their corresponding labels. Notably, the exposed surface of landslides in the dataset often resembles terraces, while the morphology of landslides is varied, which brings challenges to the accurate identification of landslides.

Table 1.
Landslide areas of the DMLD dataset selected for this paper.
Table 2.
Landslide areas of the GVLM dataset selected for this paper.

Figure 4.
Sample landslide dataset. (a) Landslide samples from DMLD dataset; (b) landslide samples from GVLM dataset.
3.3. Landslide Cross-Domain Extraction Results
The quantitative evaluation results for different domain adaptation models in the Chimanimani region, as shown in Table 3, indicate that IMMDA achieves the highest F1-Score of 64.70% and the highest IoU of 47.82%, representing an improvement of 31.79% compared to the use of source domain data alone. The second best model, DAFormer, achieves an IoU of 41.8%. Chimanimani proves to be a more challenging target domain, with an IoU of only 16.03% when no domain adaptation strategy is applied. Despite this, IMMDA significantly improves recognition accuracy, highlighting the adaptability of the IMMDA approach to various regions and tasks. DACS, in comparison, achieves an IoU of 38.09%. When applied to the Chimanimani region, the effectiveness of DACS’s cross-domain hybrid sampling strategy is lower than in Jiuzhaigou. This can be attributed to the increased complexity of the Chimanimani remote sensing imagery, where landslides and vegetation exhibit a wide variety of color and texture characteristics. This results in greater inter-domain differences and highlights the limitations of the source domain dataset in effectively addressing such challenges.
Table 3.
Quantitative assessment results of different domain adaptation methods (%).
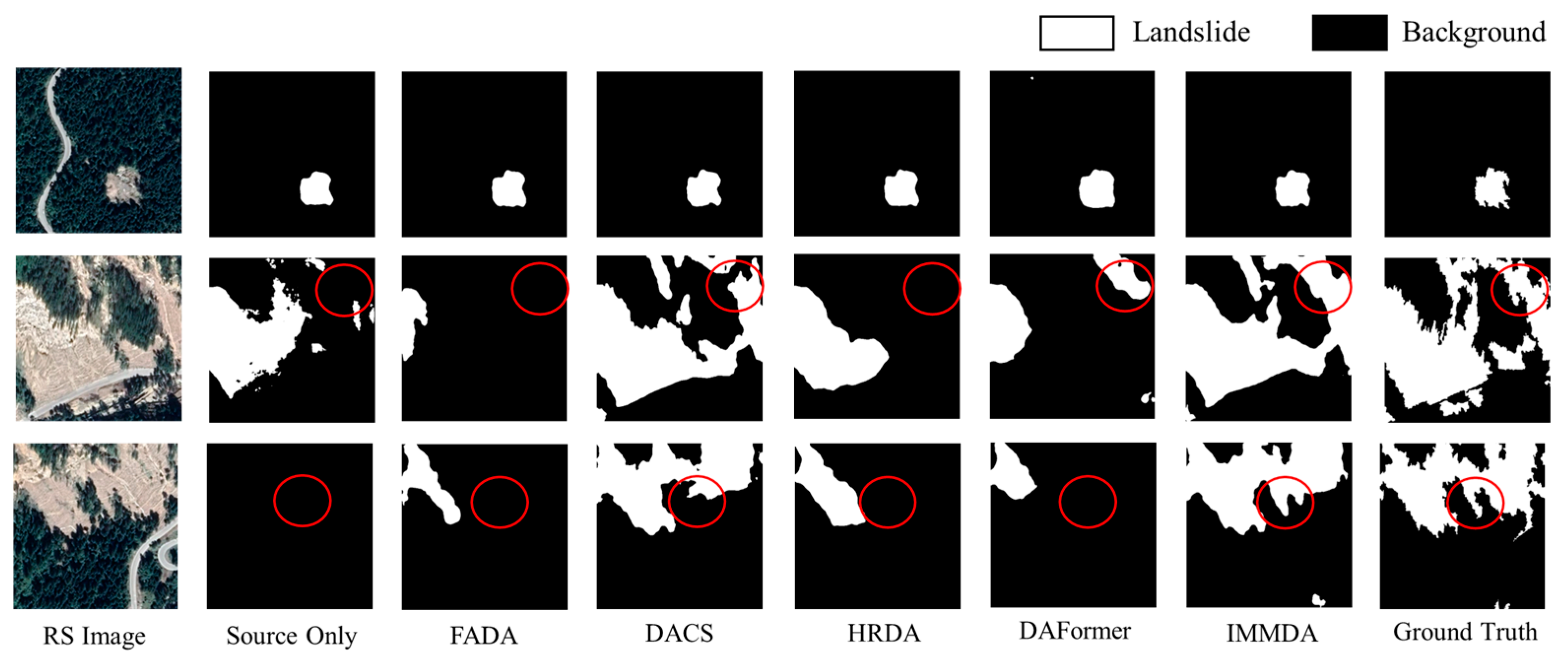
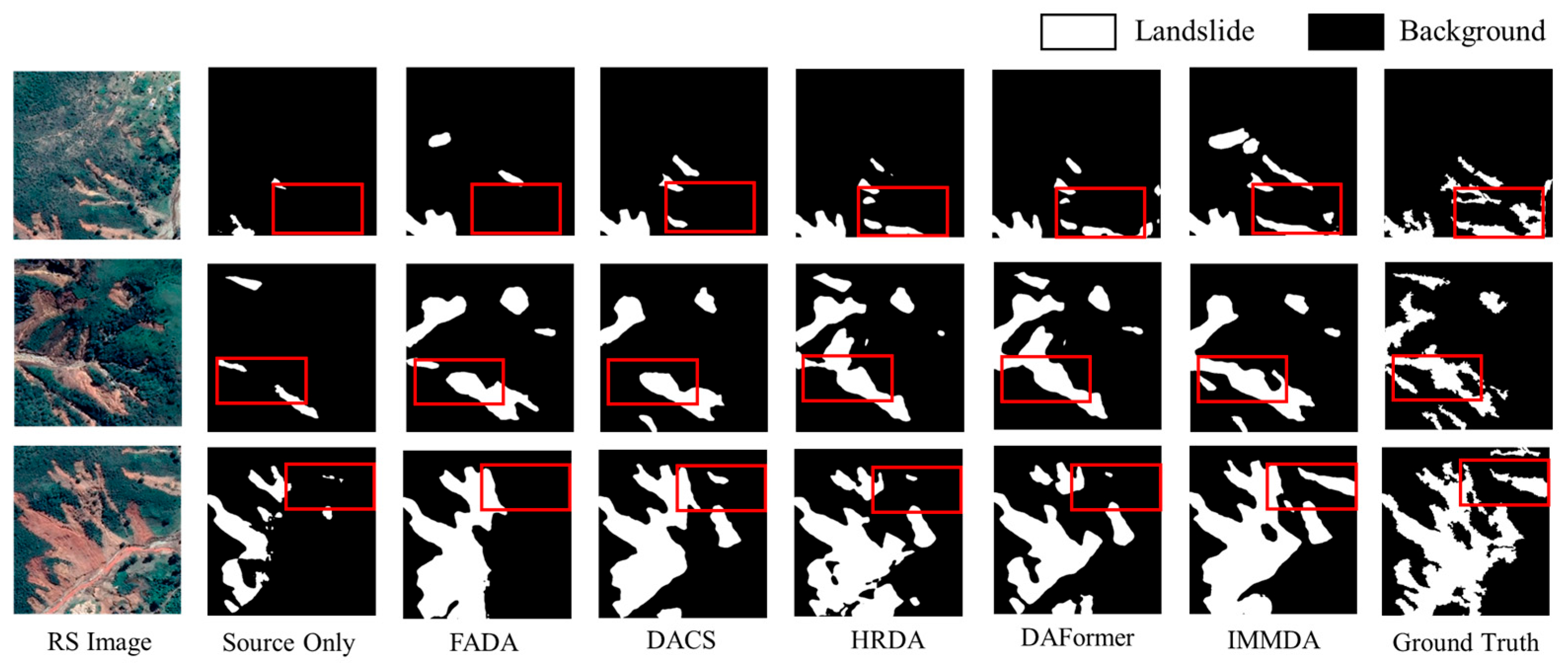
Figure 5 illustrates the qualitative recognition results of different domain adaptation methods in the Jiuzhaigou region. IMMDA provides the most comprehensive landslide identification, with the extracted landslide morphology closely matching the real labels. The area circled in red (used to highlight the recognition effect of the model) shows the effectiveness of the proposed method in cross-domain landslide extraction. Among the other methods, DACS yields results comparable to IMMDA. In contrast, FADA, HRDA, and DAFormer demonstrate poorer recognition performance, characterized by more missed detections and incomplete morphology.

Figure 5.
DMLD to GVLM (Jiuzhaigou) cross-domain landslide identification results.
Figure 6 presents the landslide recognition results of different domain adaptation methods in Chimanimani. By observing the red box (used to highlight the recognition effect of the model) area, it can be found that IMMDA provides more complete landslide boundary information and can effectively distinguish between landslides and non-landslides. This demonstrates the successful integration of contextual information and validates the effectiveness of the image mask strategy. For larger landslide areas, methods such as HRDA and DAFormer struggle with missed detections and incomplete morphology. In contrast, IMMDA delivers particularly effective recognition due to the morphological information enhancement module.
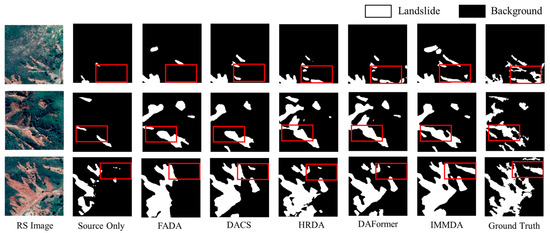
Figure 6.
DMLD to GVLM (Chimanimani) cross-domain landslide identification results.
Based on the qualitative and quantitative analysis results, the IMMDA method proposed in this paper achieves the best landslide extraction performance among the comparative methods. This is accomplished by fully utilizing both the contextual and morphological information of the landslides. IMMDA excels in providing detailed boundary identification of landslides, improving the completeness of the recognition process. Furthermore, the method demonstrates strong applicability across different target areas.
In order to assess the limitations of the methodology of this paper in depth, this study has added the visualization and discussion of typical misclassification cases in the result analysis, as shown in Figure 7 below. In the Chimanimani area, the sections circled in red (used to highlight the recognition effect of the model) show that the model is prone to misdetection when the spectral response of an isolated building (not spatially related to the landslide) is highly similar to the landslide area (e.g., bare earth roof). Such misclassification stems from the sensitivity of the morphological enhancement module to localized areas. To address this issue, future studies can realize misdetection filtering by continuing to construct morphological constraint rules (excluding the influence of residential areas) or introducing building masks (based on OpenStreetMap or nighttime lighting data). In the Jiuzhaigou area, the sections circled in red (used to highlight the recognition effect of the model) show that the morphological enhancement module employs closed operations to fill small-scale internal voids in order to improve the topological integrity of the landslide boundary. However, when there are residual vegetation patches inside the landslide, such post-processing may result in the vegetation-covered area being incorrectly subsumed into the landslide area. In this regard, a multi-scale morphological operation chain can be designed in future studies to dynamically adjust the size of structural elements in combination with the local texture complexity so as to retain the vegetation micro-areas while filling the real terrain hollows. In addition, improvements in overall landslide identification accuracy need to be made, as there are cases where spectral features and vegetation are very similar and can be mistaken as non-landslide areas. These situations can be further explored in future research by introducing spectral index or texture feature information and by incorporating time-series dynamic data before and after landslides.

Figure 7.
Landslide cross-domain identification “Failure Case” display.
3.4. Analysis of Model Computational Efficiency
This section of the experiment evaluates the computational efficiency of the model by calculating the number of parameters and GFLOPs (billion floating-point operations per second) and recording the training and inference time of the model (in the case of Chimanimani), as shown in Table 4. The IMMDA method proposed in this paper exhibits almost no increase in parameters compared to DACS as the image mask module and morphological information extraction module only introduce a single learnable morphological threshold parameter, which has a negligible impact on the total number of parameters. The training and inference time is slightly longer compared to with DAFormer and HRDA models. In contrast, methods such as HRDA and DAFormer, which use SegFormer as the backbone, involve significantly more parameters. By using DeepLabV3+ as the backbone, the method proposed here achieves a notable reduction in the number of parameters. When comparing the experimental results with computational efficiency, the proposed method demonstrates the highest cross-domain landslide extraction accuracy while maintaining a low parameter count, highlighting its superior overall performance.
Table 4.
Number of model parameters and training efficiency.
3.5. Module Validity Analysis
To validate the effectiveness of the image mask and morphological information extraction and optimization modules in the proposed method, ablation experiments are conducted for quantitative analysis. The results of these experiments, presented in Table 5, are based on the Chimanimani region, with DACS as the benchmark method. When only the image mask module is used, the model achieves an IoU of 46.29%, representing an 8.2% improvement over the benchmark method, and an F1-Score of 63.29%, which is an 8.12% increase compared to DACS. When only the morphological information enhancement module is applied, the model’s IoU increases to 47.33% and the F1-Score to 64.25%, showing significant improvement as well. When both the image mask module and the morphological information enhancement module are combined, the model reaches the highest IoU of 47.82% and an F1-Score of 64.70%, demonstrating that the synergistic effect of both modules effectively enhances the accuracy of landslide extraction.
Table 5.
Module effectiveness assessed via ablation experiments (%). Among them, √ and × indicate whether the module is adopted or not. √ represents yes and x represents no.
4. Discussion
In this section, we discuss the choice of the two hyperparameters mask ratio and mask pixel size used in the mask module. In addition, we perform comparative experiments on how the optimizer and the learning rate are chosen. Meanwhile, considering the wide range of applications of this paper’s method, the experimental results are tested in three larger scales and complex regions.
The image-based mask module in this study utilizes two hyperparameters: the mask ratio and the mask pixel size. The mask ratio controls the proportion of the image area that is masked, while the mask pixel size regulates the scale of the mask block. To determine the optimal values for these hyperparameters in IMMDA, quantitative analysis was performed for different settings. The results for the mask ratio hyperparameter are shown in Table 6, with the mask pixel size fixed at 64 × 64. The experimental findings indicate that the model achieves the highest accuracy when the mask ratio is set to 70%. When the mask ratio is lower than 70%, the accuracy improves as the ratio increases, suggesting that a higher mask ratio allows the model to better capture contextual information from the masked images. However, if the mask ratio becomes too large, critical image information may be masked, leading to a decrease in recognition accuracy.
Table 6.
Results of quantitative analysis of mask ratio hyperparameters (%).
The results of the quantitative analysis for mask pixel size are presented in Table 7, with the mask ratio set to 70% for this experiment. The findings indicate that as mask pixel size increases, the model’s learning performance improves, achieving the best results when the pixel size is set to 64 × 64. Given that the input image size is 512 × 512, larger pixel sizes lead to unstable training performance. Therefore, a mask pixel size of 64 × 64 is determined to be the optimal value for the hyperparameter in the experiments conducted in this paper.
Table 7.
Results of quantitative analysis of mask pixel size hyperparameters (%).
In the experiments of this paper, the AdamW optimizer is used with a learning rate of 0.0001 and a weight decay of 0.01 for a total of 20,000 iterations. Different model configurations are quantitatively analyzed and the results are shown in Table 8. It is found that different optimizers or attenuation modes do not have much effect on the experimental results, and the difference between the IoU and F1-Score under different configurations is only about 0.1 to 0.5 percentage points. Compared to the AdamW optimizer, the Adam optimizer has a slightly lower performance. This also indicates that in the cross-domain landslide extraction task, the model is less sensitive to hyperparameters, and the SGD converges slower, with slightly lower results.
Table 8.
Model configuration comparison experiment (%).
In order to test the effectiveness of the method of this paper in a larger spatial range of complex regions, the target domain datasets of Iceland (scale size: 4151×2763), Kupang (scale size: 1946×1319), and Tbilisi (scale size: 5588×5632) were selected for testing, and the results are shown in Figure 8 below, where a sliding window was taken in the testing process to perform the chunking test. In the Iceland region, the image and label given by the target domain dataset are a one-sit volcanic region, and it can be found from the image that the spectral features of the landslide region and the non-landslide region have obvious differences, so the model of the present method basically recognizes all the landslide regions, which proves the effectiveness of the morphology enhancement module in cross-domain landslide extraction. However, in the more obvious bright areas, there may also be cases of misidentification of landslide areas due to the similarity of spectral and other features. In response to this situation, methods such as multi-source data fusion and texture feature endomorphism can be used to screen non-landslide areas in future studies. In the Kupang region, the landslide area is brighter and the method in this paper recognizes the more complete morphology of the landslide. However, this method fills the smaller voids in the landslide and there is a problem of incorrectly filling the smaller areas. For example, the small trees in the landslide area may be filled. In the Tbilisi region, the difference between the spectral characteristics of the landslides and those of the surrounding area is less pronounced. The lower right landslide area in this region is more similar to the surrounding area, resulting in incomplete morphological identification of the lower right landslide area. In order to recognize all landslide areas, the thresholds for landslide areas were set smaller, and there were cases where brighter houses and bare land were mistaken for landslides. In subsequent processing, larger area thresholds can be set for large landslide areas.

Figure 8.
Test results of landslide cross-domain identification of large-scale area.
5. Conclusions and Future Work
This paper proposes a cross-domain landslide extraction method that integrates image masking and morphological information enhancement to tackle the underutilization of crucial contextual information and incomplete landslide shapes in existing domain adaptation methods. The results demonstrate that the proposed method significantly outperforms existing techniques across different landslide regions in the GLVM dataset. It not only achieves substantial improvements in landslide extraction accuracy but also ensures the completeness of the landslide morphological information.
Although the cross-domain landslide identification method proposed in this paper shows effectiveness in improving model cross-domain landslide identification accuracy and morphological integrity, there is still a need for further optimization in terms of the blurring of boundaries and confusion with other features. Future research can further improve it by introducing finer boundary optimization modules or post-processing techniques, aiming to combine high-resolution remote sensing data or multi-source data to enhance the representation of complex landslides.
Author Contributions
Conceptualization, J.C. and J.L.; methodology, J.C. and J.L.; software, J.Z.; validation, S.Z., X.Z., and G.S.; formal analysis, S.Z. and X.Z.; investigation, G.S. and S.R.; resources, J.C.; data curation, J.L.; writing—original draft preparation, J.L.; writing—review and editing, J.C. and Y.G.; visualization Y.G.; supervision, J.Z.; project administration, J.C.; funding acquisition, S.Z. and S.R. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Open Fund of Key Laboratory of Urban Land Resources Monitoring and Simulation, Ministry of Natural Resources, grant number KF-2023-08-06.
Data Availability Statement
The DMLD dataset is available for download at https://github.com/ RS-CSU/DMLD-Dataset, accessed on 18 July 2024.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Guzzetti, F.; Gariano, S.L.; Peruccacci, S.; Brunetti, M.T.; Melillo, M. Chapter 15—Rainfall and Landslide Initiation. In Rainfall; Morbidelli, R., Ed.; Elsevier: Amsterdam, The Netherlands, 2022; pp. 427–450. ISBN 978-0-12-822544-8. [Google Scholar]
- Berger, A.R. Abrupt Geological Changes: Causes, Effects, and Public Issues. Quat. Int. 2006, 151, 3–9. [Google Scholar] [CrossRef]
- Zhu, J.; Guo, Y.; Sun, G.; Yang, L.; Deng, M.; Chen, J. Unsupervised Domain Adaptation Semantic Segmentation of High-Resolution Remote Sensing Imagery With Invariant Domain-Level Prototype Memory. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5603518. [Google Scholar] [CrossRef]
- Shi, W.; Zhang, M.; Ke, H.; Fang, X.; Zhan, Z.; Chen, S. Landslide Recognition by Deep Convolutional Neural Network and Change Detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4654–4672. [Google Scholar] [CrossRef]
- Samodra, G.; Chen, G.; Sartohadi, J.; Kasama, K. Generating Landslide Inventory by Participatory Mapping: An Example in Purwosari Area, Yogyakarta, Java. Geomorphology 2018, 306, 306–313. [Google Scholar] [CrossRef]
- Xu, C. Preparation of Earthquake-Triggered Landslide Inventory Maps Using Remote Sensing and GIS Technologies: Principles and Case Studies. Geosci. Front. 2015, 6, 825–836. [Google Scholar] [CrossRef]
- Bao, H.; Zeng, C.; Peng, Y.; Wu, S. The Use of Digital Technologies for Landslide Disaster Risk Research and Disaster Risk Management: Progress and Prospects. Environ. Earth Sci. 2022, 81, 446. [Google Scholar] [CrossRef]
- Kusak, L.; Unel, F.B.; Alptekin, A.; Celik, M.O.; Yakar, M. Apriori Association Rule and K-Means Clustering Algorithms for Interpretation of Pre-Event Landslide Areas and Landslide Inventory Mapping. Open Geosci. 2021, 13, 1226–1244. [Google Scholar] [CrossRef]
- Lodhi, M.A. Earthquake-Induced Landslide Mapping in the Western Himalayas Using Medium Resolution ASTER Imagery. Int. J. Remote Sens. 2011, 32, 5331–5346. [Google Scholar] [CrossRef]
- He, S.; Tang, H.; Li, J.; Tang, Z.; Li, S. Landslide Detection with Two Satellite Images of Different Spatial Resolutions in a Probabilistic Topic Model. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 409–412. [Google Scholar]
- Huang, Y.; Zhao, L. Review on Landslide Susceptibility Mapping Using Support Vector Machines. CATENA 2018, 165, 520–529. [Google Scholar] [CrossRef]
- Arabameri, A.; Pradhan, B.; Rezaei, K.; Lee, C.-W. Assessment of Landslide Susceptibility Using Statistical- and Artificial Intelligence-Based FR–RF Integrated Model and Multiresolution DEMs. Remote Sens. 2019, 11, 999. [Google Scholar] [CrossRef]
- Mandal, S.; Mondal, S. Artificial Neural Network (ANN) Model and Landslide Susceptibility. In Statistical Approaches for Landslide Susceptibility Assessment and Prediction; Mandal, S., Mondal, S., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 123–133. ISBN 978-3-319-93897-4. [Google Scholar]
- Lu, P.; Stumpf, A.; Kerle, N.; Casagli, N. Object-Oriented Change Detection for Landslide Rapid Mapping. IEEE Geosci. Remote Sens. Lett. 2011, 8, 701–705. [Google Scholar] [CrossRef]
- Garcia Ugarriza, L.; Saber, E.; Vantaram, S.R.; Amuso, V.; Shaw, M.; Bhaskar, R. Automatic Image Segmentation by Dynamic Region Growth and Multiresolution Merging. IEEE Trans. Image Process. 2009, 18, 2275–2288. [Google Scholar] [CrossRef] [PubMed]
- Tien Bui, D.; Shirzadi, A.; Shahabi, H.; Geertsema, M.; Omidvar, E.; Clague, J.J.; Thai Pham, B.; Dou, J.; Talebpour Asl, D.; Bin Ahmad, B.; et al. New Ensemble Models for Shallow Landslide Susceptibility Modeling in a Semi-Arid Watershed. Forests 2019, 10, 743. [Google Scholar] [CrossRef]
- Yang, Y.; Song, S.; Yue, F.; He, W.; Shao, W.; Zhao, K.; Nie, W. Superpixel-Based Automatic Image Recognition for Landslide Deformation Areas. Eng. Geol. 2019, 259, 105166. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional Neural Networks for Large-Scale Remote-Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef]
- Zhu, M.; He, Y.; He, Q. A Review of Researches on Deep Learning in Remote Sensing Application. Int. J. Geosci. 2019, 10, 93. [Google Scholar] [CrossRef]
- Meena, S.R.; Soares, L.P.; Grohmann, C.H.; van Westen, C.; Bhuyan, K.; Singh, R.P.; Floris, M.; Catani, F. Landslide Detection in the Himalayas Using Machine Learning Algorithms and U-Net. Landslides 2022, 19, 1209–1229. [Google Scholar] [CrossRef]
- Ye, C.; Li, Y.; Cui, P.; Liang, L.; Pirasteh, S.; Marcato, J.; Gonçalves, W.N.; Li, J. Landslide Detection of Hyperspectral Remote Sensing Data Based on Deep Learning With Constrains. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 5047–5060. [Google Scholar] [CrossRef]
- Song, Y.; Guo, J.; Wu, G.; Ma, F.; Li, F. Automatic Recognition of Landslides Based on YOLOv7 and Attention Mechanism. J. Mt. Sci. 2024, 21, 2681–2695. [Google Scholar] [CrossRef]
- Chai, J.; Nan, Y.; Guo, R.; Lin, Y.; Liu, Y. Recognition Method of Landslide Remote Sensing Image Based on EfficientNet. In Proceedings of the 2022 IEEE 2nd International Conference on Electronic Technology, Communication and Information (ICETCI), Changchun, China, 27–29 May 2022; pp. 1224–1228. [Google Scholar]
- Wan, Y.; Huang, J.; Ji, Y.; Yu, Z.; Luo, M. Combining BotNet and ResNet Feature Maps for Accurate Landslide Identification Using DeepLabV3+. In Proceedings of the 2023 6th International Conference on Artificial Intelligence and Big Data (ICAIBD), Chengdu, China, 26–29 May 2023; pp. 777–782. [Google Scholar]
- Prakash, N.; Manconi, A.; Loew, S. Mapping Landslides on EO Data: Performance of Deep Learning Models vs. Traditional Machine Learning Models. Remote Sens. 2020, 12, 346. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Meena, S.R.; Tiede, D.; Aryal, J. Evaluation of Different Machine Learning Methods and Deep-Learning Convolutional Neural Networks for Landslide Detection. Remote Sens. 2019, 11, 196. [Google Scholar] [CrossRef]
- Yang, S.; Wang, Y.; Wang, P.; Mu, J.; Jiao, S.; Zhao, X.; Wang, Z.; Wang, K.; Zhu, Y. Automatic Identification of Landslides Based on Deep Learning. Appl. Sci. 2022, 12, 8153. [Google Scholar] [CrossRef]
- Ji, S.; Yu, D.; Shen, C.; Li, W.; Xu, Q. Landslide Detection from an Open Satellite Imagery and Digital Elevation Model Dataset Using Attention Boosted Convolutional Neural Networks. Landslides 2020, 17, 1337–1352. [Google Scholar] [CrossRef]
- Chandra, N.; Sawant, S.; Vaidya, H. An Efficient U-Net Model for Improved Landslide Detection from Satellite Images. PFG J. Photogramm. Remote Sens. Geoinf. Sci. 2023, 91, 13–28. [Google Scholar] [CrossRef]
- Xu, B.; Zhang, C.; Liu, W.; Huang, J.; Su, Y.; Yang, Y.; Jiang, W.; Sun, W. Landslide Identification Method Based on the FKGRNet Model for Remote Sensing Images. Remote Sens. 2023, 15, 3407. [Google Scholar] [CrossRef]
- Liu, X.; Peng, Y.; Lu, Z.; Li, W.; Yu, J.; Ge, D.; Xiang, W. Feature-Fusion Segmentation Network for Landslide Detection Using High-Resolution Remote Sensing Images and Digital Elevation Model Data. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4500314. [Google Scholar] [CrossRef]
- Sameen, M.I.; Pradhan, B. Landslide Detection Using Residual Networks and the Fusion of Spectral and Topographic Information. IEEE Access 2019, 7, 114363–114373. [Google Scholar] [CrossRef]
- Huang, R.; Chen, T. Landslide Recognition from Multi-Feature Remote Sensing Data Based on Improved Transformers. Remote Sens. 2023, 15, 3340. [Google Scholar] [CrossRef]
- Lv, P.; Ma, L.; Li, Q.; Du, F. ShapeFormer: A Shape-Enhanced Vision Transformer Model for Optical Remote Sensing Image Landslide Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 2681–2689. [Google Scholar] [CrossRef]
- Tang, X.; Tu, Z.; Wang, Y.; Liu, M.; Li, D.; Fan, X. Automatic Detection of Coseismic Landslides Using a New Transformer Method. Remote Sens. 2022, 14, 2884. [Google Scholar] [CrossRef]
- Xu, Y.; Ouyang, C.; Xu, Q.; Wang, D.; Zhao, B.; Luo, Y. CAS Landslide Dataset: A Large-Scale and Multisensor Dataset for Deep Learning-Based Landslide Detection. Sci Data 2024, 11, 12. [Google Scholar] [CrossRef] [PubMed]
- Fang, C.; Fan, X.; Wang, X.; Nava, L.; Zhong, H.; Dong, X.; Qi, J.; Catani, F. A Globally Distributed Dataset of Coseismic Landslide Mapping via Multi-Source High-Resolution Remote Sensing Images. Earth Syst. Sci. Data 2024, 16, 4817–4842. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, Y.; Ouyang, C.; Zhang, F.; Ma, J. Automated Landslides Detection for Mountain Cities Using Multi-Temporal Remote Sensing Imagery. Sensors 2018, 18, 821. [Google Scholar] [CrossRef]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Kulesza, A.; Pereira, F.; Vaughan, J.W. A Theory of Learning from Different Domains. Mach. Learn. 2010, 79, 151–175. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, Y.; Zhang, Y.; Zhong, L.; Wang, J.; Chen, J. DKDFN: Domain Knowledge-Guided Deep Collaborative Fusion Network for Multimodal Unitemporal Remote Sensing Land Cover Classification. ISPRS J. Photogramm. Remote Sens. 2022, 186, 170–189. [Google Scholar] [CrossRef]
- Li, X.; Caragea, D.; Caragea, C.; Imran, M. Identifying Disaster Damage Images Using a Domain Adaptation Approach; Universitat Politecnica de Valencia: Valencia, Spain, 2019. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: New York, NY, USA, 2017; pp. 1510–1519. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Li, P.; Wang, Y.; Si, T.; Ullah, K.; Han, W.; Wang, L. DSFA: Cross-Scene Domain Style and Feature Adaptation for Landslide Detection from High Spatial Resolution Images. Int. J. Digit. Earth 2023, 16, 2426–2447. [Google Scholar] [CrossRef]
- Zhang, X.; Yu, W.; Pun, M.-O.; Shi, W. Cross-Domain Landslide Mapping from Large-Scale Remote Sensing Images Using Prototype-Guided Domain-Aware Progressive Representation Learning. ISPRS J. Photogramm. Remote Sens. 2023, 197, 1–17. [Google Scholar] [CrossRef]
- Xu, Q.; Ouyang, C.; Jiang, T.; Yuan, X.; Fan, X.; Cheng, D. MFFENet and ADANet: A Robust Deep Transfer Learning Method and Its Application in High Precision and Fast Cross-Scene Recognition of Earthquake-Induced Landslides. Landslides 2022, 19, 1617–1647. [Google Scholar] [CrossRef]
- Li, P.; Wang, Y.; Liu, G.; Fang, Z.; Ullah, K. Unsupervised Landslide Detection From Multitemporal High-Resolution Images Based on Progressive Label Upgradation and Cross-Temporal Style Adaption. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4410715. [Google Scholar] [CrossRef]
- Xie, Z.; Zhang, Z.; Cao, Y.; Lin, Y.; Bao, J.; Yao, Z.; Dai, Q.; Hu, H. SimMIM: A Simple Framework for Masked Image Modeling. arXiv 2022, 9653–9663. arXiv:2111.09886. [Google Scholar]
- Hoyer, L.; Dai, D.; Wang, H.; Van Gool, L. MIC: Masked Image Consistency for Context-Enhanced Domain Adaptation. arXiv 2023, 11721–11732. arXiv:2212.01322. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved Regularization of Convolutional Neural Networks with Cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked Autoencoders Are Scalable Vision Learners. arXiv 2022, 16000–16009. arXiv:2111.06377. [Google Scholar]
- Li, L.; Lan, H.; Strom, A.; Macciotta, R. Landslide Length, Width, and Aspect Ratio: Path-Dependent Measurement and a Revisit of Nomenclature. Landslides 2022, 19, 3009–3029. [Google Scholar] [CrossRef]
- Taylor, F.E.; Malamud, B.D.; Witt, A.; Guzzetti, F. Landslide Shape, Ellipticity and Length-to-Width Ratios. Earth Surf. Process. Landf. 2018, 43, 3164–3189. [Google Scholar] [CrossRef]
- Wang, H.; Shen, T.; Zhang, W.; Duan, L.-Y.; Mei, T. Classes Matter: A Fine-Grained Adversarial Approach to Cross-Domain Semantic Segmentation. In Proceedings of the Computer Vision–ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 642–659. [Google Scholar]
- Tranheden, W.; Olsson, V.; Pinto, J.; Svensson, L. DACS: Domain Adaptation via Cross-Domain Mixed Sampling. arXiv 2021, 1379–1389. arXiv:2007.08702. [Google Scholar]
- Hoyer, L.; Dai, D.; Van Gool, L. HRDA: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentation. In Proceedings of the Computer Vision–ECCV 2022, Glasgow, UK, 23–28 August 2020; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer Nature Switzerland: Cham, Switzerland, 2022; pp. 372–391. [Google Scholar]
- Hoyer, L.; Dai, D.; Van Gool, L. DAFormer: Improving Network Architectures and Training Strategies for Domain-Adaptive Semantic Segmentation. arXiv 2022, 9924–9935. arXiv:2111.14887. [Google Scholar]
- Chen, J.; Zeng, X.; Zhu, J.; Guo, Y.; Hong, L.; Deng, M.; Chen, K. The Diverse Mountainous Landslide Dataset (DMLD): A High-Resolution Remote Sensing Landslide Dataset in Diverse Mountainous Regions. Remote Sens. 2024, 16, 1886. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).